Подбор гиперпараметров RAG-системы с помощью Optuna
Как гласит народная мудрость: «Плох тот датасаентист, который не хочет свалить все на Optuna«у.
RAG-система это такой персональный карманный поисковик (а-ля Гугл или Яндекс), который может искать по локальным документам вашего кровавого энтерпрайза :)
Если чуть более по-научному: Retrieval Augmented Generation (RAG) — это технология, которая использует большие языковые модели (LLM) для генерации ответа на вопрос с учётом переданного ей контекста. Всесторонний рассказ о RAG-системах выходит за рамки этой статьи, поэтому вот тут вы сможете ознакомиться с соновами: https://habr.com/ru/articles/779526/ и https://habr.com/ru/companies/raft/articles/791034/
Под капотом у RAG-системы можно найти несколько различных компонентов. Причем набор и структура этих компонентов может серьезно различаться в зависимости от задачи и выбранного подхода. И каждый их этих компонентов обладает собственным набором параметров. И весь этот зоопарк надо как-то настраивать, потому что от этого сильно зависит качество поиска.
Можно делать это вручную. [Спойлер] Долго, утомительно и не эффективно [/Спойлер] :) А можно попробовать свалить эту задачу на Optuna«у (а че она бездельничает :) Чем мы и займемся в этой статье.
Для примера мы рассмотрим очень простой вариант RAG-системы, но достаточный для понимания концепции.
Задача
Но для начала формализуем задачу, т.к. от этого сильно зависит архитектура системы.
Итак, наша RAG-система должна выполнять следующие функции:
Поиск в различной технической документации: ТЗ, инструкции, регламенты и пр.
Поддержка только трех форматов документов: DOCX, PDF и TXT.
В одном документе могут быть ответы на многие вопросы. Но ответ на любой вопрос содержится только в одном документе, в одной его части (например, абзаце).
Т.е. не может быть ситуации, что ответ на один и тот же вопрос можно найти в разных файлах.Язык документации, преимущественно, — русский. Исключения — имена собственные на английском.
Работа в закрытом контуре (т.е. никаких OpenAI и прочих товарищей).
Работа на одной GPU A100 40Мб.
Архитектура
Архитектура нашей RAG-системы будет состоять из трех основных компонентов и двух процессов.
Начнем с процессов:
1. Парсинг документов

Этапы:
Загружаем в «систему» документ (ы).
Документ разбивается на чанки (небольшие куски текста) по определенной логике.
Каждый чанк посредством bi-encoder«а конвертируется в вектор (он же эмбеддинг).
Вектор вместе с самим чанком (и другой сопутствующей информацией) сохраняется в векторной БД.
По фэн-шую тут еще должен быть процесс удаления документа, но для нашего эксперимента он сейчас не нужен.
2. Ответ на вопрос

Этапы:
Пользователь формулирует вопрос.
Вопрос конвертируется в вектор посредством bi-encoder«а (причем того же самого, который используется для кодирования чанков).
По сформированному вектору ищем в БД похожие вектора. Возвращаем топ-N похожих векторов (а также связанные с ними чанки).
Формируем промт для LLM. Для этого склеиваем воедино: системный промт, вопрос пользователя и чанки.
Отправляем промт в LLM и получаем ответ.
Эти два процесс взаимосвязаны, поэтому и тестироваться они будут вместе.
Компоненты
В этой архитектуре можно выделить три основных компонента:
Bi-encoder — производит кодирование строки в вектор.
Для чего это нужно? Две строки закодированные в вектор можно сравнивать между собой посредством косинусного расстояния и сказать насколько они похожи. Таким способом, например, можно приблизительно подобрать ответы на вопрос.Векторная БД. Нужна для хранения векторов. А еще она может очень быстро находить (и возвращать) близкие вектора по косинусному (и некоторым другим) расстоянию.
В вектора мы будем кодировать чанки документов и вопросы пользователей. И по косиносному расстоянию будем искать наиболее похожие на вопрос чанки. И уже эти чанки будем скармливать LLM.
Зачем это нужно? Почему сразу не скормить все чанки в LLM? Причины две:У LLM есть ограниченный контекст и все чанки в нее тупо не влезут.
Чем больше текста вы скормите LLM, тем дольше она будет генерировать ответ. Поэтому лучше подавать в нее какой-то минимально необходимый объем данных.
Следовательно, нам нужно предварительно отобрать ограниченное количество чанков. Что мы и будем делать посредством косинусного расстояния.
В качестве векторной БД будем использовать Qdrant.LLM — сердце нашей системы — занимается «осмысливанием» вопроса и генерирует ответа на него. Для теста будем использовать недавно разинутую Llama 3 (а точнее затюненую версию IlyaGusev/saiga_llama3_8b). Отвечает неплохо, работает ооочень быстро и влазит на одну карточку. В общем, то что нам нужно :)
На второй картинке вы можете увидеть (затенен) еще один компонент — Cross-encoder (еще его называют re-ranker). В этом решении он не используется, но он часто встречается в других решениях. Его основная функция — дополнительная фильтрация отобранных чанков. Cross-encoder типа умнее bi-энкодера, но работает заметно дольше bi-энкодера. А если у вас миллионы векторов — это может быть существенно снизить производительность системы. Поэтому поступают так: с помощью косинусного расстояния отбирают, например, топ-100 чанков. Их скармливают сross-encoder«у, который отбирает из них 3–5 чанков, которые уже поступают в LLM.
Или еще более хитрый вариант: просят LLM переформулировать вопрос пользователя 2 раза. По каждому из получившихся 3 вопросов ищут чанки в БД (например, по 30 чанков на вопрос). Затем cross-encoder отбирает из общего списка чанков 3–5 лучших.
Более подробно можете почитать тут: https://www.sbert.net/examples/applications/cross-encoder/README.html
З.Ы. К сожалению, для русского языка существует только один приличный cross-encoder: PitKoro/cross-encoder-ru-msmarco-passage
Тесты
Чтобы оценить качество работы RAG-системы необходимо подготовить тестовые вопросы и ответы к ним. И лучше чтобы в их составлении участвовали конечные пользователи RAG-системы (или заказчики), поскольку ваше представление о «прекрасном» может отличаться от необходимого. Вопросов нужно порядка 20–30 на 5–10 файлов.
В результате у вас должна получится примерно такая таблица:
# | Вопрос | Правильный ответ | Контекст | Файл | № страницы |
Где:
Вопрос — вопрос по содержимому файла.
Правильный ответ — что мы хотели бы видеть в качестве ответа на соответствующий вопрос.
Контекст — цельный кусок текста (например, абзац), из которого сформулирован правильный ответ.
Файл — название файла, в котором содержится ответ.
№ страницы — номер страницы, на которой находится контекст.
Вопросы желательно подбирать так, чтобы протестировать различные варианты ответов:
Простые факты из документов.
Вопросы на суммаризацию.
Описания процессов.
Перечисления фактов.
Вопросы с условием.
Числа, даты, имена собственные.
И пр.
Теория это хорошо, но нам сейчас нужно на чем-то экспериментировать :)
Ru RAG Test Dataset
Специально для этой статьи я собрал датасет для тестирования RAG-системы: https://github.com/slivka83/ru_rag_test_dataset
Датасет основан на датасете RuBQ. В этом датасете есть все нужные нам столбцы (кроме страниц — в вебе и txt их нет :). Всего 923 вопроса.

Из RuBQ я отобрал только те вопросы, ответ на который есть только в одном месте одной статьи. Но там есть и вопросы, ответы на которые встречаются в нескольких статьях/абзацах. Если они вам нужны можете скачать их самостоятельно — код я приложил.
З.Ы. Если что, датасет не идеальный, но может служить отправной точкой для вашего собственного теста:
Ответы на вопросы очень простые (если не сказать примитивные:)
Возможно википедия (особенно английская) не очень подходят для оценки RAG-системы, поскольку LLM зачастую обучаются и на ее текстах. И иногда может быть не понятно откуда модель взяла ответ — из чанков или из своих собственных знаний.
Встречаются ошибки в правильных ответах.
Оценка
Учитывая задачу, мы хотим в результате тестирования получить ответ на три вопроса:
Найден ли правильный файл?
Найден ли правильный контекст?
Оценить ответ LLM.
Метрик для оценки ответов LLM довольно много: BERTScore, BLEURT, METEOR и пр. И все они довольно мудреные. Но если посмотреть на ответы в наших тестовых вопросах — они очень просты. Буквально слово или два. А LLM бывают довольно «разговорчивы». Соответственно, чтобы оценить ответ LLM нам достаточно (для нашего случая) просто определить, содержится ли правильное слово в ответе LLM. Для этого идеально подходит метрика Rouge-1, которая просто сравнивает униграммы.
Есть даже вариант оценивать ответы LLM также с помощью LLM: подают в LLM вопрос и ответ и просят оценить (от 1 до 10) насколько ответ корректный.
Правильность контекста мы будем оценивать по пересечению. Т.е. будем искать, какой наибольший кусок контекста содержится в отобранных чанках.
Файл мы будем оценивать просто по факту его нахождения: вернула ли нам БД нужный файл (к каждому чанку у нас будет привязано название файла из которого он взят).
Код
Далее рассмотрим отдельные функции, из которых будет состоять наш код.
Весь код вы можете найти здесь: https://github.com/slivka83/rag_optuna_optimization
Чанки
from langchain_community.document_loaders import TextLoader, Docx2txtLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def file_to_chunks(file_name, sep, chunk_size, chunk_overlap):
file_ext = file_name.split('.')[-1]
file_path = f'{TEST_FOLDER_PATH}/{file_name}'
# Загружаем содержимое файла
if file_ext == 'txt':
loader = TextLoader(file_path, encoding='utf-8')
elif file_ext == 'docx':
loader = Docx2txtLoader(file_path)
elif file_ext == 'pdf':
loader = PyPDFLoader(file_path)
else:
return
file = loader.load()
content = file[0].page_content
# Разбиваем текст на чанки
text_splitter = RecursiveCharacterTextSplitter(
separators = sep,
chunk_size = chunk_size,
chunk_overlap = chunk_overlap,
length_function = len,
is_separator_regex = False,
add_start_index = False
)
chunks = text_splitter.split_text(content)
return chunksФункция file_to_chunks, принимает название файла, загружает его и разбивает на чанки с помощью библиотеки langchain. И эти чанки возвращает.
И здесь у нас появляются первые гиперпараметры:
sep — разделитель по которому мы будем шинковать файл.
chunk_size — размер чанков (в символах).
chunk_overlap — с каким перехлестом будут делаться чанки.
Bi-encoder
from sentence_transformers import SentenceTransformer
from sentence_transformers.models import Pooling, Transformer
# Подгружаем bi-encoder
def get_bi_encoder(bi_encoder_name):
raw_model = Transformer(model_name_or_path=f'{bi_encoder_name}')
# Вытаскиваем размер векторов
bi_encoder_dim = raw_model.get_word_embedding_dimension()
pooling_model = Pooling(
bi_encoder_dim,
pooling_mode_cls_token = False,
pooling_mode_mean_tokens = True
)
bi_encoder = SentenceTransformer(
modules = [raw_model, pooling_model],
device = 'cuda' # помещаем его на GPU
)
return bi_encoder, bi_encoder_dim
# Формируем из строки вектор
def str_to_vec(bi_encoder, text):
embeddings = bi_encoder.encode(
text,
convert_to_tensor = True,
show_progress_bar = False
)
return embeddingsЗдесь у нас две функции:
get_bi_encoder — загружает и возвращает bi-encoder по его имени.
str_to_vec — конвертирует строку в вектор с помощью bi-encoder«а.
Тут стоит поподробнее остановиться на двух важных свойствах bi-encoder«а:
Сколько текста он может скушать за раз — остальное будет отброшено.
Если у вас длинные чанки и/или длинные вопросы, то вам, возможно, стоит подобрать bi-encoder с бОльшей длиной контекста.Какого размера вектора он возвращает. При прочих равных, чем больше длина вектора, тем больше информации в нем можно закодировать.
Оба этих параметра «зашиты» в bi-энкодер и оба важны для RAG-системы. Поэтому у нас сам bi-энкодер будет гиперпараметром. Т.е. мы будем пробовать разные bi-энкодеры и смотреть какой из них лучше себя покажет.
Есть даже лидерборд bi-энкодеров, в котором вы можете подобрать нужный вам: https://github.com/avidale/encodechka
Qdrant
import uuid
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams, PointStruct
# Создаем подключение к векторной БД
qdrant_client = QdrantClient('my_qdrant_server.ru', port=6333)
# Помещаем чанки и доп. информаицю в векторую БД
def save_chunks(bi_encoder, chunks, file_name):
# Конвертируем чанки в векитора
chunk_embeddings = str_to_vec(bi_encoder, chunks)
# Содаем объект(ы) для БД
points = []
for i in range(len(chunk_embeddings)):
point = PointStruct(
id=str(uuid.uuid4()), # генерируем GUID
vector = chunk_embeddings[i],
payload={'file': file_name, 'chunk': chunks[i]}
)
points.append(point)
# Сохраняем вектора в БД
operation_info = qdrant_client.upsert(
collection_name = COLL_NAME,
wait = True,
points = points
)
return operation_info
def files_to_vecdb(files, bi_encoder, vec_size, sep, chunk_size, chunk_overlap):
# Удаляем и заново создаем коллекцию
qdrant_client.delete_collection(collection_name=COLL_NAME)
qdrant_client.create_collection(
collection_name = COLL_NAME,
vectors_config = VectorParams(size=vec_size, distance=Distance.COSINE),
)
# Каждый файл по одному...
for file_name in files:
# делим на чанки ...
chunks = file_to_chunks(file_name, sep, chunk_size, chunk_overlap)
# помещаем чанки в векторную БД
operation_status = save_chunks(bi_encoder, chunks, file_name)Здесь мы:
Создаем подключение к векторной БД Qdrant.
З.Ы. Процесс установки выходит за рамки статьи, но вы можете ознакомится с ним в официальной документации: https://qdrant.tech/documentation/guides/installation/Объявляем две функции:
save_chunks — конвертирует переданные чанки в эмбединги и помещает их в Qdrant.
files_to_vecdb — делает две вещи:
Удаляет и вновь создает коллекцию в БД Qdrant, в которой мы будем складировать чанки.
З.Ы. Коллекция это аналог таблицы в реляционной БД.Последовательно перебирает переданные файлы. Каждый из которых делит на чанки и кладет в БД Qdrant.
Обратите внимание:
Коллекцию мы создаем такого же размера, какого размера вектора возвращает bi-encoder.
Вместе с вектором мы будем хранить сам чанк, из которого он сформирован и название файла, из которого он взят.
Да, мы будет при каждом прогоне теста заново разбивать все файлы на чанки и создавать из них коллекцию. Но не стоит об этом переживать. На фоне скорости генерации ответа LLM это происходит почти мгновенно :)
Поиск векторов
def vec_search(bi_encoder, query, n_top_cos):
# Кодируем запрос в вектор
query_emb = str_to_vec(bi_encoder, query)
# Поиск в БД
search_result = qdrant_client.search(
collection_name = COLL_NAME,
query_vector = query_emb,
limit = n_top_cos,
with_vectors = False
)
top_chunks = [x.payload['chunk'] for x in search_result]
top_files = list(set([x.payload['file'] for x in search_result]))
return top_chunks, top_filesФункция vec_search сначала кодирует вопрос в вектор, а затем ищет по косиносному расстоянию наиболее похожие вектора в БД Qdrant. Возвращает топ-N векторов:, а точнее содержимое чанков (и названия файлов) привязанных к отобранным векторам.
LLM
Сначала загрузим саму LLM:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = 'IlyaGusev/saiga_llama3_8b'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype = torch.bfloat16,
device_map = "auto"
)Как мы помним, в качестве подопытной LLM«и у нас будет использоваться новомодная Llama3.
Далее определим функцию, которая будет скармливать LLM промт и обрабатывать ответ:
def get_llm_answer(query, chunks_join, max_new_tokens, temperature, top_p, top_k):
user_prompt = '''Используй только следующий контекст, чтобы очень кратко ответить на вопрос в конце.
Не пытайся выдумывать ответ.
Контекст:
===========
{chunks_join}
===========
Вопрос:
===========
{query}'''.format(chunks_join=chunks_join, query=query)
SYSTEM_PROMPT = "Ты — Сайга, русскоязычный автоматический ассистент. Ты разговариваешь с людьми и помогаешь им."
RESPONSE_TEMPLATE = "<|im_start|>assistant\n"
prompt = f'''<|im_start|>system\n{SYSTEM_PROMPT}<|im_end|>\n<|im_start|>user\n{user_prompt}<|im_end|>\n{RESPONSE_TEMPLATE}'''
def generate(model, tokenizer, prompt):
data = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
data = {k: v.to(model.device) for k, v in data.items()}
output_ids = model.generate(
**data,
bos_token_id=128000,
eos_token_id=128001,
pad_token_id=128001,
do_sample=True,
max_new_tokens=max_new_tokens,
no_repeat_ngram_size=15,
repetition_penalty=1.1,
temperature=temperature,
top_k=top_k,
top_p=top_p
)[0]
output_ids = output_ids[len(data["input_ids"][0]) :]
output = tokenizer.decode(output_ids, skip_special_tokens=True)
return output.strip()
response = generate(model, tokenizer, prompt)
return responseПрибавилось гиперпараметров и все они относятся к LLM:
max_new_tokens — максимальное количество токенов, которое будет сгенерировано LLM (не считая токены в промте).
temperature — определяет насколько «творческим» будет ответ LLM. Чем выше значение, тем выше «творчество».
top_p — также отвечает за степень детерминированности модели. Чем больше значение, тем более разнообразными будут ответы. Меньшие значения будут давать более точные и фактические ответы.
З.Ы. Рекомендуется изменить либо температуру, либо top_p, но не оба сразу.top_k — ограничивает количество вариантов, которые модель рассматривает при генерации следующего токена.
З.Ы. Здесь напрашивается в качестве гиперпараметра системный промт. Точнее различные варианты его формулировки. Но пока оставим его статичным.
Т.к. ответы у нас состоят из одного-двух слов — просим ламу отвечать очень кратко.
Оценка
Оценкой ответа LLM (от 0 до 100) будут заниматься две функции. Одна будет лемматизировать текст, а вторая непосредственно оценивать ответ посредством метрики Rouge-1.
import re
import json
from rouge import Rouge
from pymorphy2 import MorphAnalyzer
f = open('stopwords-ru.json', encoding='utf-8')
stop_words = json.load(f)
#print(stop_words)
morph = MorphAnalyzer()
patterns = "[«»°!#$%&'()*+,./:;<=>?@[\]^_`{|}~—\"\-]+"
def lemmatize(string):
clear = re.sub(patterns, ' ', string)
tokens = []
for token in clear.split():
if token:
token = token.strip()
token = morph.normal_forms(token)[0]
if token not in stop_words:
tokens.append(token)
tokens = ' '.join(tokens)
return tokens
def get_llm_score(answer, answer_true):
answer = lemmatize(answer)
answer_true = lemmatize(answer_true)
if len(answer) == 0:
answer = '-'
rouge = Rouge()
scores = rouge.get_scores(answer, answer_true)[0]
rouge_1 = round(scores['rouge-1']['r']*100, 2)
return rouge_1Оценка контекста (от 0 до 100) будет также производится метрикой Rouge. Точнее одной из ее версий (Rouge-L), которая измеряет максимальную общую длину между двумя строками:
def get_context_score(chunks_join, context):
rouge = Rouge()
scores = rouge.get_scores(chunks_join, context)[0]
score = round(scores['rouge-l']['r'] * 100)
return scoreНайден ли нужный файл (0 или 1) мы будет определять просто по отобранным чанкам: к каждому из них привязано название файла (из которого он взят). Код сравнения вы найдете в следующем разделе.
Запуск одного теста
Все части пазла готовы и теперь нужно собрать их вместе и один раз прогнать через них все строки тестовых вопросов:
def run_one_test(df, encoder_name, sep, chunk_size, chunk_overlap, n_top_cos, max_new_tokens, temperature, top_p, top_k):
try:
bi_encoder, vec_size = get_bi_encoder(encoder_name)
files = df['Файл'].unique()
files_to_vecdb(files, bi_encoder, vec_size, sep, chunk_size, chunk_overlap)
result = []
for i, row in df.iterrows():
query = row['Вопрос']
answer_true = row['Правильный ответ']
file_name = row['Файл']
context = row['Контекст']
top_chunks, top_files = vec_search(bi_encoder, query, n_top_cos)
row['top_files'] = top_files
row['top_chunks'] = top_chunks
top_chunks_join = '\n'.join(top_chunks) # объединяем чанки
answer = get_llm_answer(query, top_chunks_join, max_new_tokens, temperature, top_p, top_k)
row['Ответ'] = answer
row['file_score'] = int(file_name in top_files)
row['context_score'] = get_context_score(top_chunks_join, context)
row['llm_score'] = get_llm_score(answer, answer_true)
result.append(row)
result = pd.DataFrame(result)
result = result.sort_values(by=['llm_score','context_score','file_score'], ascending=False)
result = result.reset_index(drop=True)
score = result['llm_score'].mean()
return result, score
except:
return None, 0Здесь мы:
Подгружаем bi-encoder
Все файлы из тестового датасета разбиваем на чанки, конвертируем в вектора и помещаем в Qdrant.
Для каждого вопроса из теста:
Конвертируем вопрос в вектор.
Ищем похожие (на вопрос) чанки в БД Qdrant.
Объединяем чанки и формируем из них промт для LLM.
З.Ы. Способ объединения чанков также может быть гиперпараметром.Скармливаем промт LLM и получаем ответ.
Оцениваем ответ LLM, найденный контекст и файл.
Сохраняем оценки и служебную информацию в датасете.
Возвращаем датасет и оценку. Общая оценка всего датасета это просто усредненная оценка ответа LLM. Для нашего случая этого пока достаточно.
С оценкой можно поиграться. Например можно усреднить оценку файла, контекста и LLM. Или можно усреднить только оценки LLM и контекста и умножить все это на оценку файла (если файл найден неправильно, то вся оценка занулится). В общем простор для фантазии большой.
Обратите внимание, что код внутри функции run_one_test мы обернули в try-except. Это нужно обязательно сделать на случай, если оптуна захочет передать в RAG-систему слишком жирные параметры. От которых модель просто упадет. В этом случаем мы не прекращаем обучение, а просто возвращаем скор 0. Оптуна быстро выучит границы дозволенного и суваться за их пределы почти не будет.
Запуск Optuna’ы
Вот мы и подобрались к вишенке на торте.
Сначала определим loss-функцию, которую будет максимизировать опутна:
import optuna
def objective(trial):
global best_score, best_result
encoder_name = trial.suggest_categorical('encoder_name', ['cointegrated/rubert-tiny2',
'kazzand/ru-longformer-large-4096',
'cointegrated/LaBSE-en-ru'])
sep = trial.suggest_categorical('sep', ['.',' ','\n'])
chunk_size = trial.suggest_int('chunk_size', 100, 2000)
chunk_overlap = trial.suggest_int('chunk_overlap', 50, 600)
n_top_cos = trial.suggest_int('n_top_cos', 1, 8)
max_new_tokens = trial.suggest_int('max_new_tokens', 100, 1600)
temperature = trial.suggest_float('temperature', 0.01, 0.99)
top_p = trial.suggest_float('top_p', 0.01, 0.99)
top_k = trial.suggest_int('top_k', 10, 150)
result, score = run_one_test(
TEST_DF,
encoder_name,
sep, chunk_size, chunk_overlap, n_top_cos,
max_new_tokens, temperature, top_p, top_k
)
if score > best_score:
best_score = score
best_score_tag = ' <--'
best_result = result
else:
best_score_tag = ''
print(f'{score:.2f}', best_score_tag)
return score
optuna.logging.set_verbosity(optuna.logging.WARNING) Здесь мы:
Определяем все наши гиперпараметры и задаем диапазон для их перебора.
Скармливаем функции run_one_test параметры текущего цикла и получаем в виде ответа датасет с результатами и оценку.
Сравниваем полученный скор с лучшим значением и если оно превосходит заменяем его и сохраняем таблицу с ответами (в глобальной переменной).
Возвращаем скор оптуне.
В качестве разделителя для чанков мы используем только один символ (точку, запятую или пробел). Но в функцию RecursiveCharacterTextSplitter можно передать сразу последовательность символов. Примерно так: ['/n', '.', ',', ' ']. Тогда, она сначала попробует первый знак, затем перейдет ко второму и т.д. Так можно получить чанки более равномерной длины. Ну, а возможности комбинаций этих символов оставляют большой простор для фантазии :)
Ну и запустим наконец оптуну:
import pandas as pd
COLL_NAME = 'optuna_test_llama3_1'
TEST_FILE_PATH = 'ru_rag_test_dataset.pkl'
TEST_FOLDER_PATH = 'Тест_RuBQ'
TEST_DF = pd.read_pickle(TEST_FILE_PATH)[::15]
print('Кол-во строк:', TEST_DF.shape[0])
best_score = 0
best_result = None
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=5000, timeout=60*60*24)Здесь мы:
Определяем глобальные переменные: название коллекции в БД Qdrant в которой будет хранить чанки, пути до датасета с вопросами и путь в папке, в которой лежат файлы.
Подгружаем тестовые вопросы. При этом отбираем каждый 15 вопрос, чтобы уменьшить общее их количество и сократить время на один тест. В итоге у нас получается 62 вопроса (из 923), чего вполне достаточно для оценки.
Запускаем оптуну и ставим ей задачу максимизировать скор.
Ну и смотрим как увеличивается скор:
0.00
42.60 <--
0.00
29.01
0.00
46.47 <--
30.48
40.38
38.78
32.56
39.10
38.94
43.59
42.87
59.62 <--
64.42 <--
62.18
65.70 <--
58.81
65.38
...Как гласит еще одна народная мудрость, можно бесконечно смотреть на три вещи: как горит огонь, как течет вода и как падает лосс :)
З.Ы. Если хотите прогонять много примеров, то можете воспользоваться техникой Pruners, чтобы сократить время обучения: https://t.me/ds_private_sharing/76
Результат
Я гонял оптуну 24 часа и провел 482 теста. Лучший скор — 77.95%. Если сравнить его с медианным (69.72%) или средним скором (66.56%), то результат лучше примерно на 10%.
Глянем на распределение скоров:
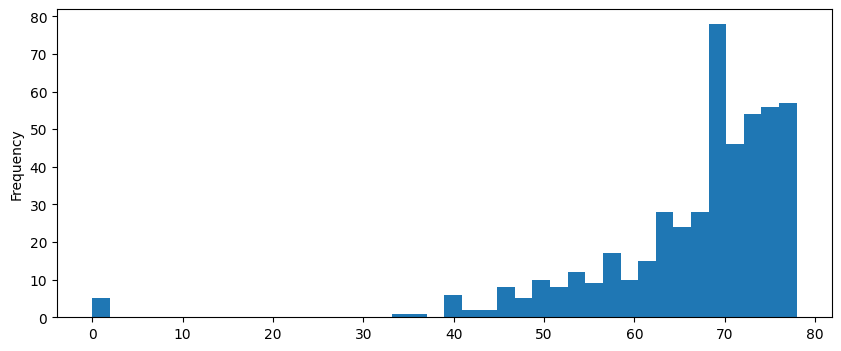
Нулевых скоров почти нет.
Посмотрим на лучшие гиперпараметры:
{'encoder_name': 'cointegrated/LaBSE-en-ru',
'sep': '\n',
'chunk_size': 1977,
'chunk_overlap': 61,
'n_top_cos': 8,
'max_new_tokens': 302,
'temperature': 0.6095279086616815,
'top_p': 0.1871688966686985,
'top_k': 129}Тут мы явно уперлись в chunk_size и n_top_cos. Можно еще раз запустить подбор, увеличив эти параметры.
Посмотрим на лучшие ответы:

Выглядит неплохо. Теперь посмотрим на худшие ответы:

Можно заметить, что на некоторые вопросы ответы даны правильно. Т.е. в самом «правильном ответе» содержится либо неправильный ответ, либо ответ который можно трактовать двояко. А это значит, что скор у лучшей «модели» еще выше.
Также не нашли три раза нужный файл. Можно еще добавить разнообразных bi-encider«ов для перебора.
Может показаться, что лучший результат случаен. Но давайте посмотрим на топ лучших скоров:

Видно, что большинство лучших значений обладают примерно схожими гиперпараметрами. А значит результат вполне закономерен.
З.Ы. Дополнительно я вручную запустил тестирование с лучшими найденными гшиперпараметрами. Скор был примерно равен лучшему скору оптуны.
По фэн-шую еще можно выделить из общего теста отдельный кусок (холдаут) и на нем прогнать модель с лучшими параметры. Для финальной оценки.
-----------------------------
Мой телеграм-канал
