Пишем свой протокол поверх UDP
Первые прямые трансляции с места событий появились в России почти 70 лет назад и вели их из передвижной телевизионной станции (ПТС), которая внешне походила на «троллейбус» и позволяла вести эфиры не из студии. А всего лишь три года назад Periscope позволил вместо «троллейбуса» использовать мобильный телефон.
Но это приложение имело ряд проблем, связанных, например, с задержками в эфирах, с невозможностью смотреть трансляции в высоком качестве и т.д.
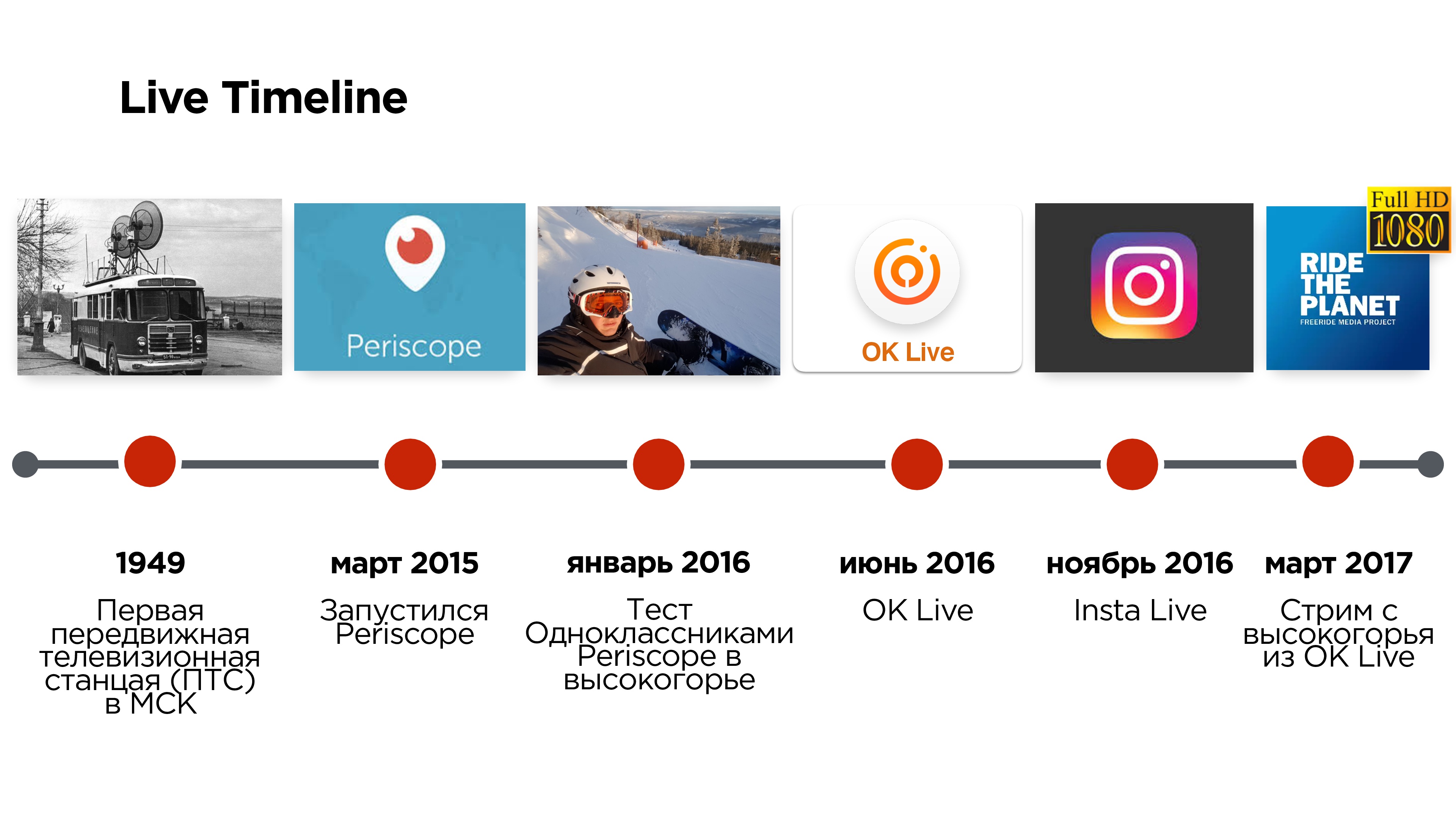
Еще через полгода, летом 2016, Одноклассники запустили свое мобильное приложение OK Live для стриминга, в котором постарались решить эти проблемы.
Александр Тоболь отвечает за техническую часть видео в Одноклассниках и на Highload++ 2017 рассказал про то, как писать свой UDP протокол, и зачем это может потребоваться.
Из расшифровки его доклада вы узнаете все про другие протоколы стриминга видео, какие есть нюансы, и про то, какие уловки иногда требуются.
Говорят, что надо всегда начинать с архитектуры и ТЗ — якобы без этого нельзя! Так и сделаем.
Архитектура и ТЗ
На слайде ниже схема архитектуры любого стримингового сервиса: видео подается на вход, преобразуется и передается на выход. К этой архитектуре мы добавили еще немножко требований: видео должно подаваться с десктопов и мобильных телефонов, а на выход — попадать на те же десктопы, мобильные телефоны, smartTV, Chromcast, AppleTV и другие устройства — все, на чем можно играть видео.
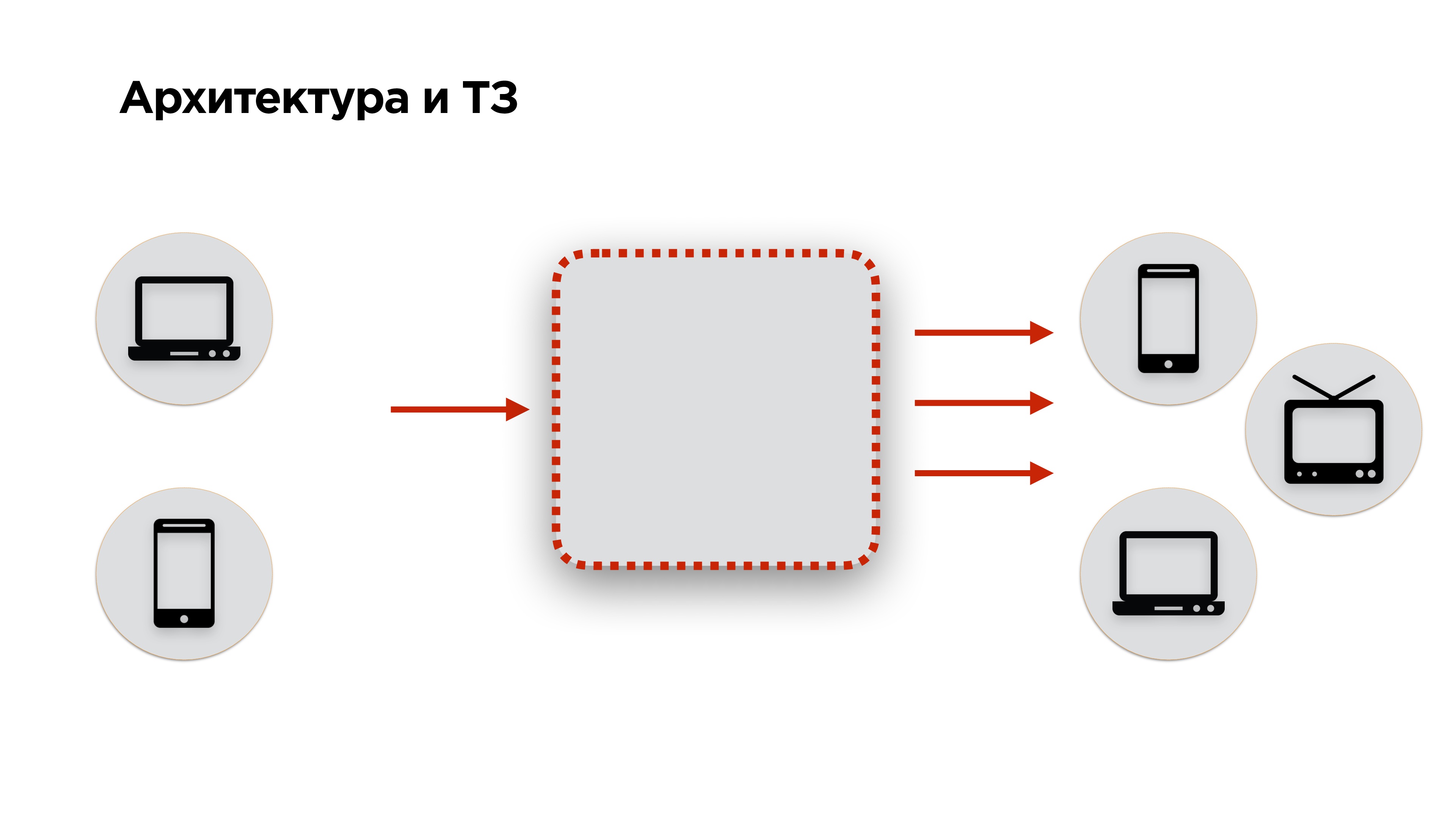
Дальше переходим к техническому заданию. Если у вас есть заказчик, у вас есть ТЗ. Если вы — социальная сеть, ТЗ у вас нет. Как его составить?
Можно конечно опросить пользователей и узнать все, что они хотят. Но это будет целая куча желаний, которые никак не коррелируют с тем, что людям действительно надо.
Мы решили пойти методом от противного и посмотрели, что пользователи НЕ хотят видеть от сервиса трансляции.
- Первое, что не хочет пользователь — это видеть задержку на старте трансляции.
- Пользователь не хочет видеть некачественную картинку стрима.
- Если в трансляции есть интерактив, когда пользователь общается со своей аудиторией (встречные прямые эфиры, звонки и т.д.), то он не хочет видеть задержку между стримером и зрителем.
Так выглядит обычный стриминговый сервис. Посмотрим, что можно сделать, чтобы вместо обычного сделать — крутой стриминговый сервис.

Начать можно было бы с просмотра всех протоколов стриминга, выбрать наиболее интересные и сравнить их. Но мы сделали по-другому.
Что у конкурентов?
Мы начали с изучения сервисов конкурентов. Открываем Periscope — что у них?
Как всегда, главное — архитектура.
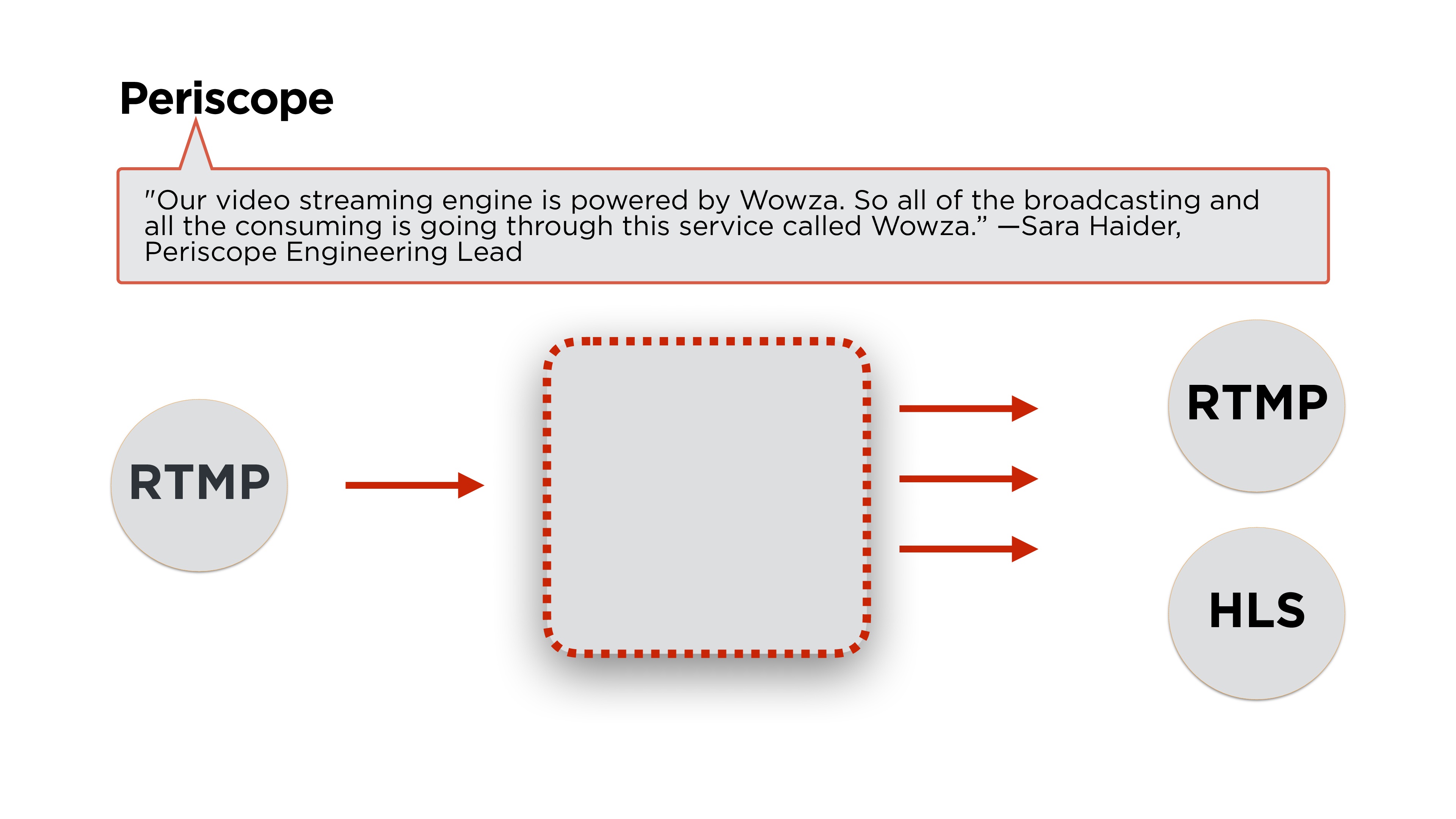
Сара Хайдер, ведущий инженер Periscope, пишет, что для бэкенда они используют Wowza. Если еще немножко почитать статьи, то мы увидим, что стрим они делают с использованием протокола RTMP, а раздают его либо в RTMP, либо в HLS. Посмотрим, что это за протоколы и как они работают.
Протестируем Periscope на три наших главных требования.

Скорость старта у них приемлемая (меньше секунды на хороших сетях), постоянноекачество порядка 600 px (не HD) и при этом задержки могут составлять до 12 секунд.
Кстати, как померить задержку в трансляции?
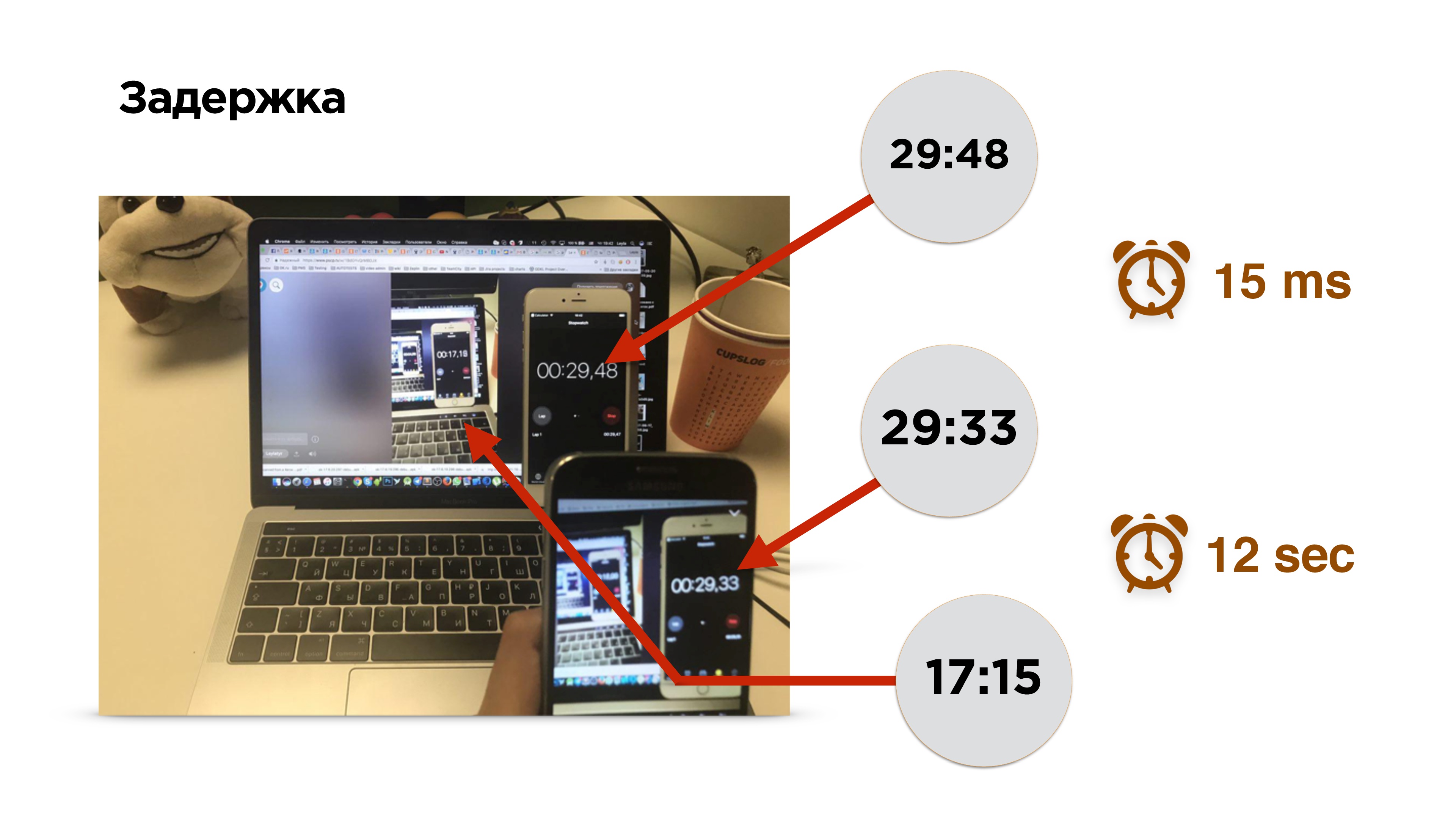
Это фотография измерения задержки. Есть мобильный телефон с таймером. Мы включаем трансляцию и видим изображение этого телефона на экране. За 15 миллисекунд изображение попало на сенсор камеры и вывелось из видеопамяти на экран телефона. После этого мы включаем браузер и смотрим трансляцию.
Ой! Она немножко отстала — примерно на 12 секунд.
Чтобы найти причины задержки, попрофилируем стриминг видео.
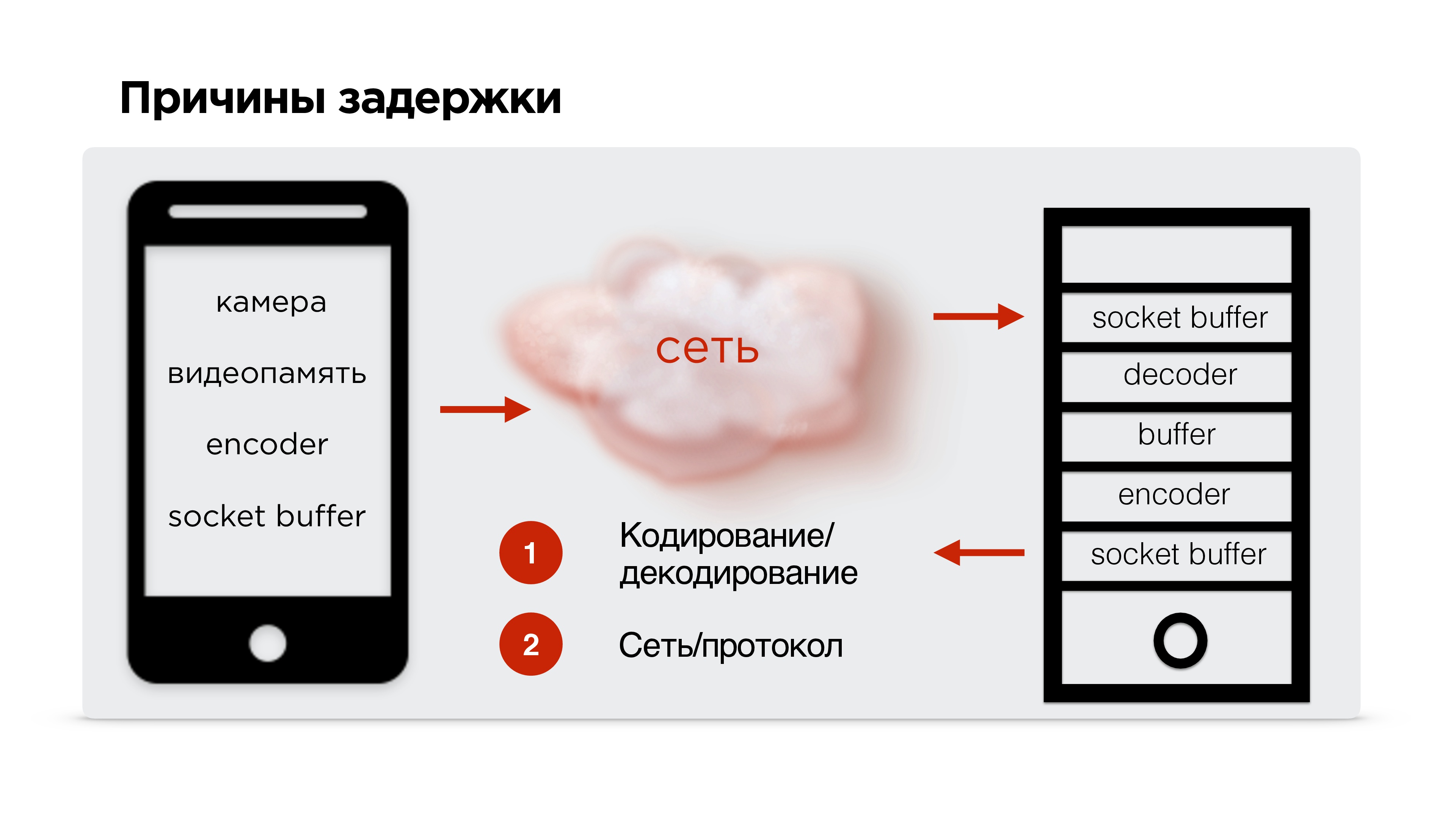
Итак, есть мобильный телефон, видео идет с камеры и попадает в видеобуфер. Тут задержки минимальны (≈15 мс). Потом кодировщик кодирует сигнал, упаковывает в пакет и отправляет в socket-буфер. Это все летит в сеть. Дальше на принимающем устройстве происходит все то же самое.
В принципе, есть две основные трудные точки, которые нужно рассмотреть:
- кодирование/декодирование видео;
- сетевые протоколы.
Кодирование/декодирование видео
Немного расскажу про кодирование. Вы все равно с ним столкнетесь, если будете делать Low Latency Live Streaming.
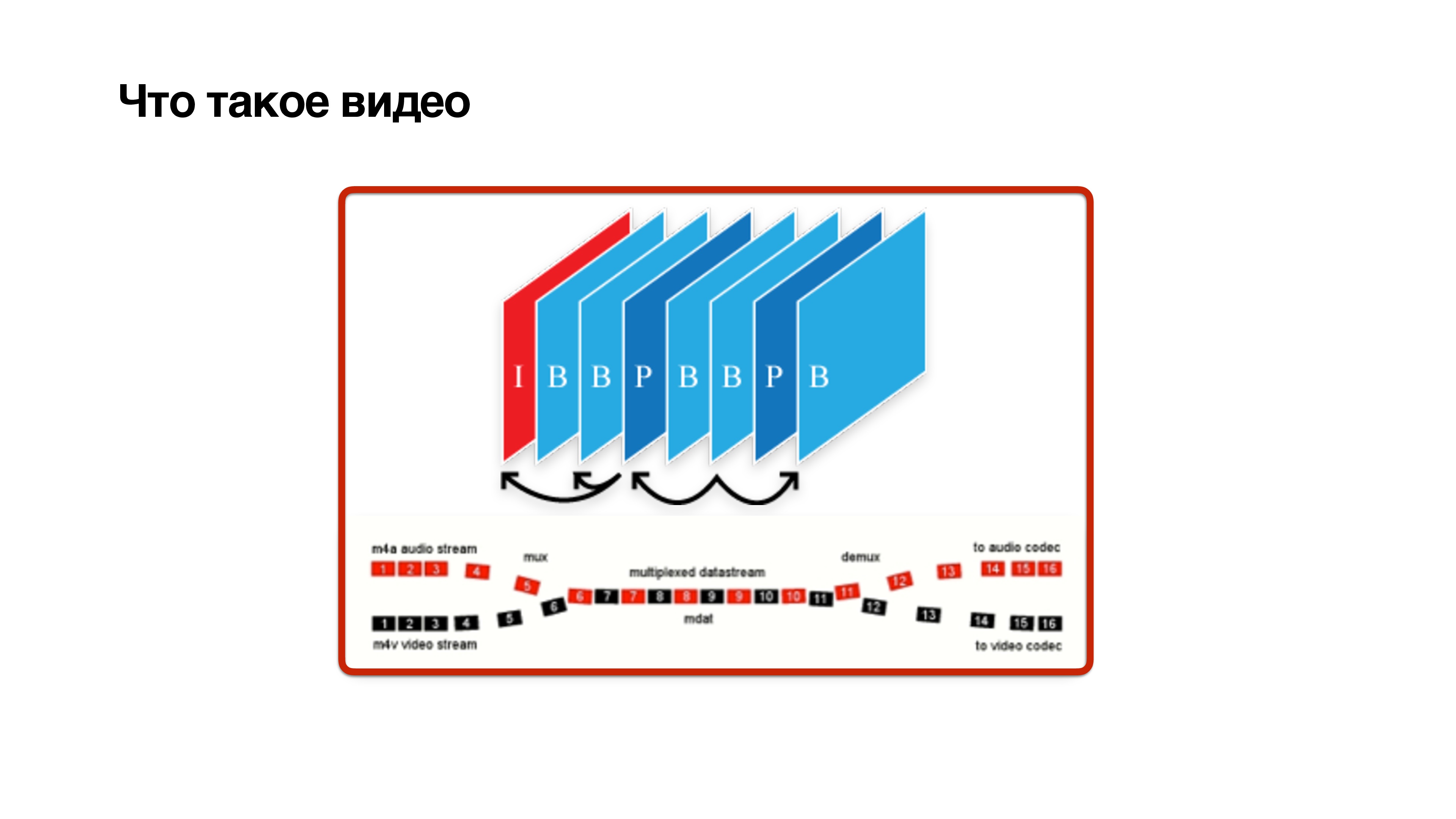
Что такое видео? Это набор кадров, но не совсем простых. Кадры бывают трех типов: I, P и B-frame:
- I-frame — это просто jpg. По сути, это опорный кадр, он ни от кого не зависит и содержит четкую картинку.
- P-frame зависит исключительно от предыдущих кадров.
- Хитрые B-frame могут зависеть от будущего. Это означает, что чтобы посчитать b-frame, нужно, чтобы с камеры пришли еще и будущие кадры. Только тогда с некоторой задержкой можно декодировать b-frame.
Отсюда видно, что B-кадры вредны. Попробуем их убрать.
- Если вы стримите с мобильного устройства, можно попробовать включить профайл baseline. Он отключит B-frame.
- Можно попробовать настроить кодек и уменьшить задержку на будущие кадры, чтобы кадры приходили быстрее.
- Еще одна важная штука в тюнинге кодека — это включение CBR (константного битрейта).
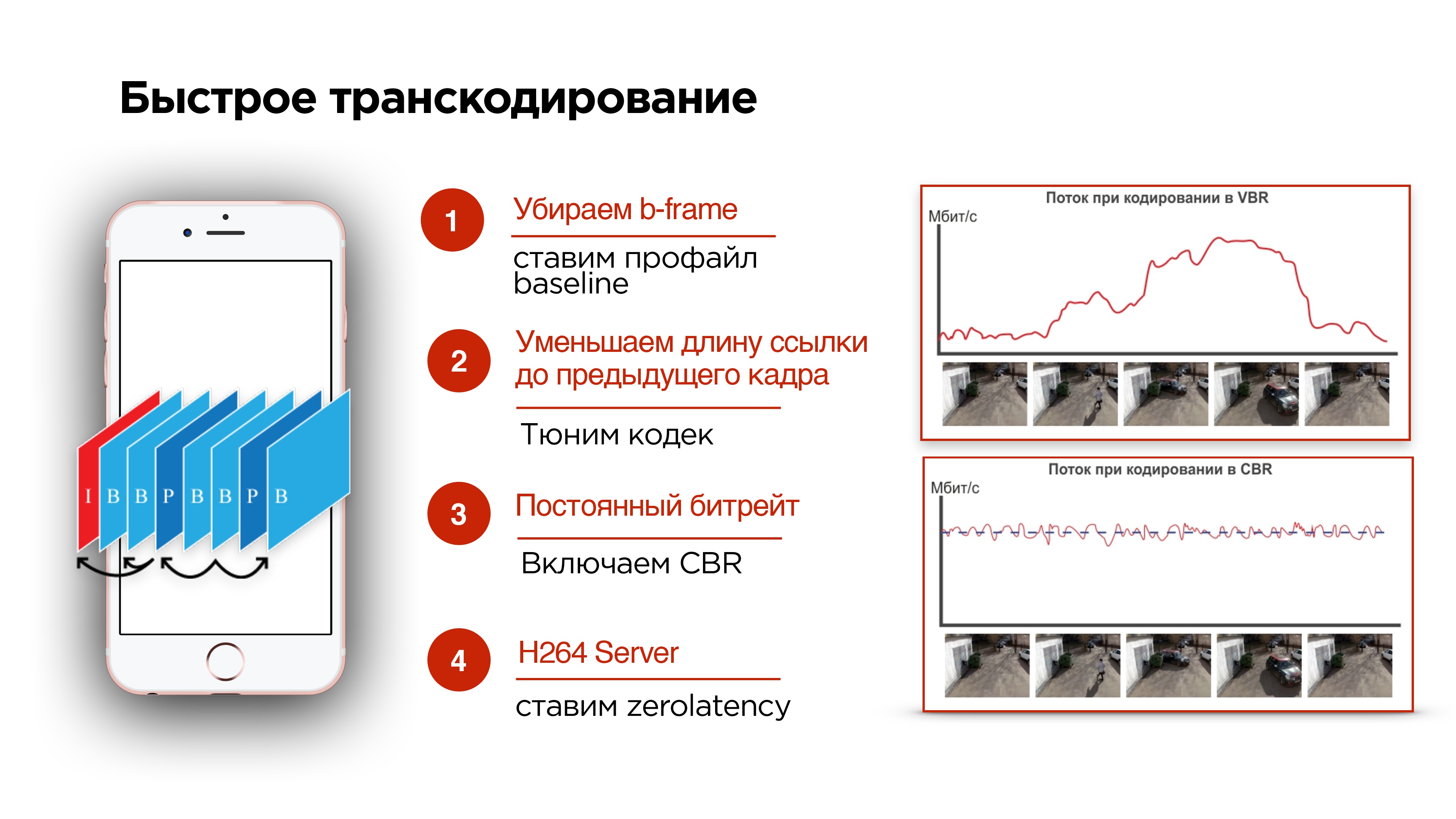
Как работают кодеки, проиллюстрировано на слайде выше. В рассматриваемом примере на видео статическая картинка, ее кодирование экономит место на диске, т.к. там почти ничего не меняется, и битрейт видео низкий. Происходят изменения — растет энтропия, растет битрейт видео — для хранения на диске это здорово.
Но в тот момент, когда начались активные изменения, и вырос битрейт, скорее всего все данные в сеть не пролезут. Это как раз то, что происходит, когда вы делаете видеозвонок и начинаете поворачиваться, а у вашего абонента подтормаживает картинка. Это связано с тем, что сеть не успевает адаптироваться под изменение битрейта.
Надо включать CBR. Не все кодеки на Android будут его корректно поддерживать, но они будут к этому стремиться. То есть нужно понимать, что с CBR идеальной картины мира, как на нижней картинке, вы не получите, но включить его все-таки стоит.
4. А на бэкенде необходимо добавить к H264 кодеку zerolatency — это позволит как раз не делать зависимости в кадрах на будущее.
Протоколы передачи видео
Рассмотрим, какие протоколы стриминга предлагает индустрия. Я их условно разбил на два типа:
- потоковые протоколы;
- cегментные протоколы.

Потоковые протоколы — это протоколы из мира p2p звонков: RTMP, webRTC, RTSP/RTP. Они отличаются тем, что пользователи договариваются о том, какой у них канал, подбирают битрейт кодека соответственно каналу. А еще у них есть дополнительные команды такого рода, как «дай мне опорный кадр». Если вы потеряли кадр, в этих протоколах вы можете заново его запросить.
Отличие сегментных протоколов в том, что никто ни с кем никак не договаривается. Они режут видео на сегменты, хранят каждый сегмент в различных качествах, и клиент сам может выбирать, какой сегмент смотреть. Каждый сегмент начинается с опорного кадра.
Рассмотрим протоколы более детально. Начнем с потоковых протоколов и разберемся, с какими проблемами мы можем столкнуться, если будем использовать потоковые протоколы для broadcast-стриминга.
Потоковые протоколы
Periscope использует RTMP. Этот протокол появился в 2009 году, и Adobe сначала не полностью его специфицировал. Потом у него были определенного рода трудности с тем, что Adobe хотел продавать исключительно свой сервер. То есть RTMP развивался довольно трудно. Его основная проблема в том, что он использует TCP, но почему-то именно его выбрал Periscope.

Если почитать детально, то оказывается, что Periscope использует RTMP для трансляции с малым количеством зрителей. Как раз такие трансляции, если у вас недостаточный канал, скорее всего, вы не сможете посмотреть.
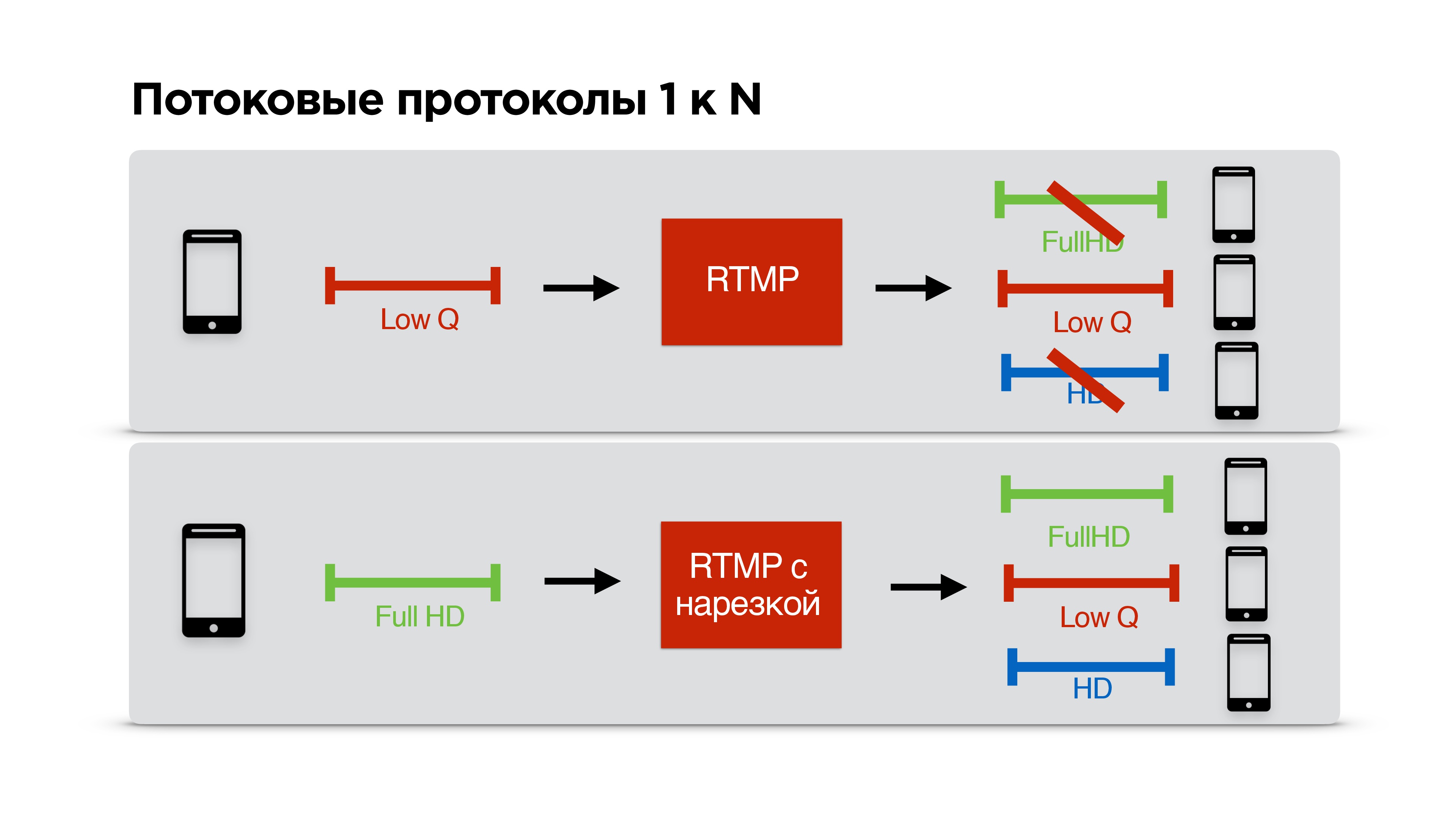
Рассмотрим на конкретном примере. Есть пользователь с узким каналом связи, который смотрит вашу трансляцию. Вы с ним договариваетесь по RTMP о низком битрейте и начинаете персонально для него стримить.
К вам приходит еще пользователь с классным интернетом, у вас тоже классный интернет, но вы уже с кем-то договорились о низком качестве, и получается так, что этот третий с классным интернетом смотрит стрим в плохом качестве, несмотря на то, что мог бы смотреть в хорошем.
Эту проблему мы решили устранить. Мы сделали, чтобы можно было RTMP подрезать для каждого клиента персонально, то есть стримящие договариваются с сервером, стримят на максимально возможном качестве, а каждый клиент получает то качество, которое позволяет ему сеть.
Здорово!
Но все равно RTMP у нас поверх TCP, и никто нас от блокировки начала очереди не застраховал.
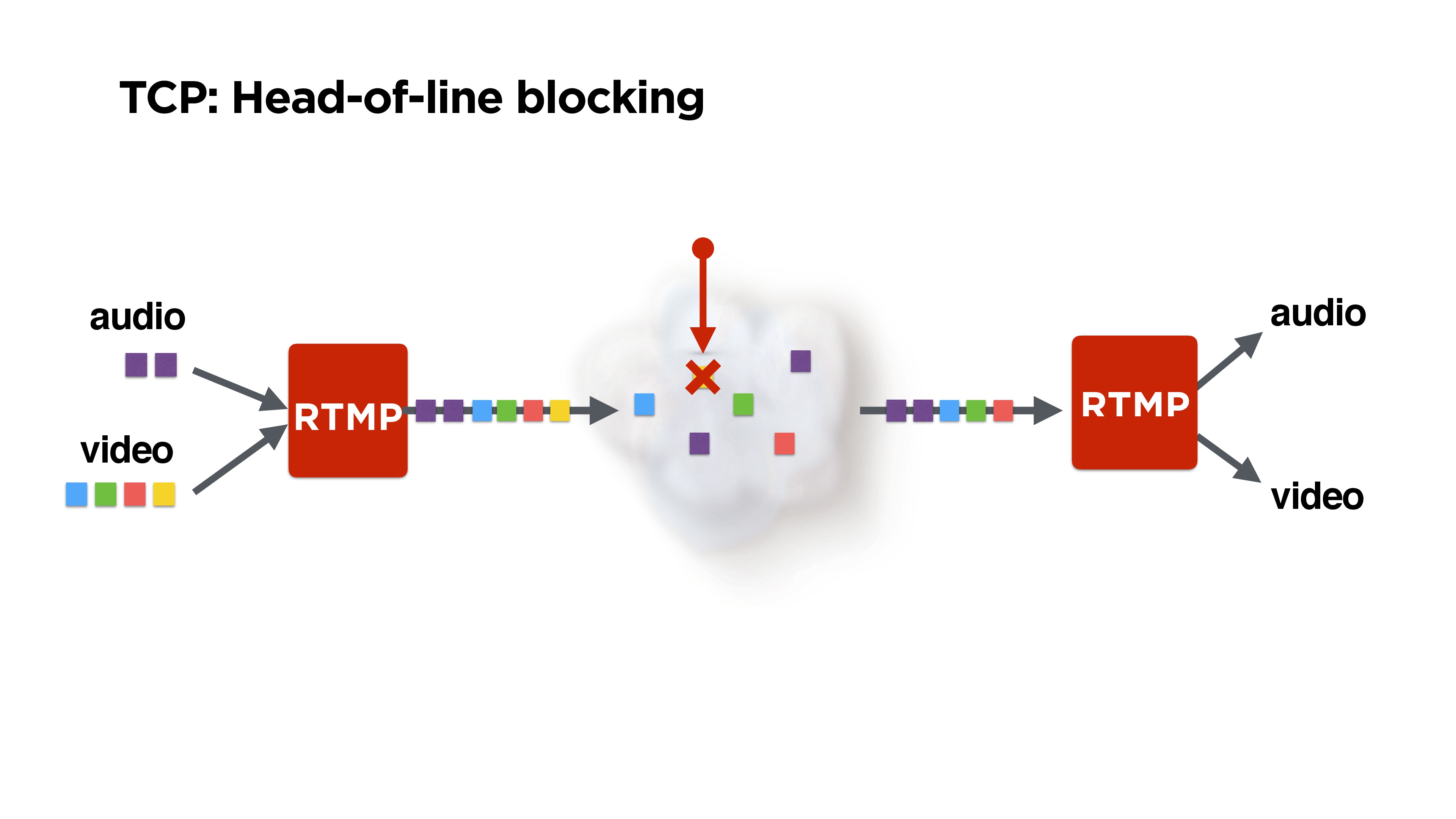
На рисунке это проиллюстрировано: к нам поступают аудио и видео фреймы, RTMP их пакует, возможно их как-то перемешивает, и они улетают в сеть.
Но допустим, мы теряем один пакет. Возможно, что тот самый желтый потерянный пакет — это вообще P-frame от какого-то предыдущего — его можно было бы дропнуть. Возможно, как минимум, можно было бы играть аудио. Но TCP нам не отдаст остальные пакеты, так как он гарантирует доставку и последовательность пакетов. С этим надо как-то бороться.
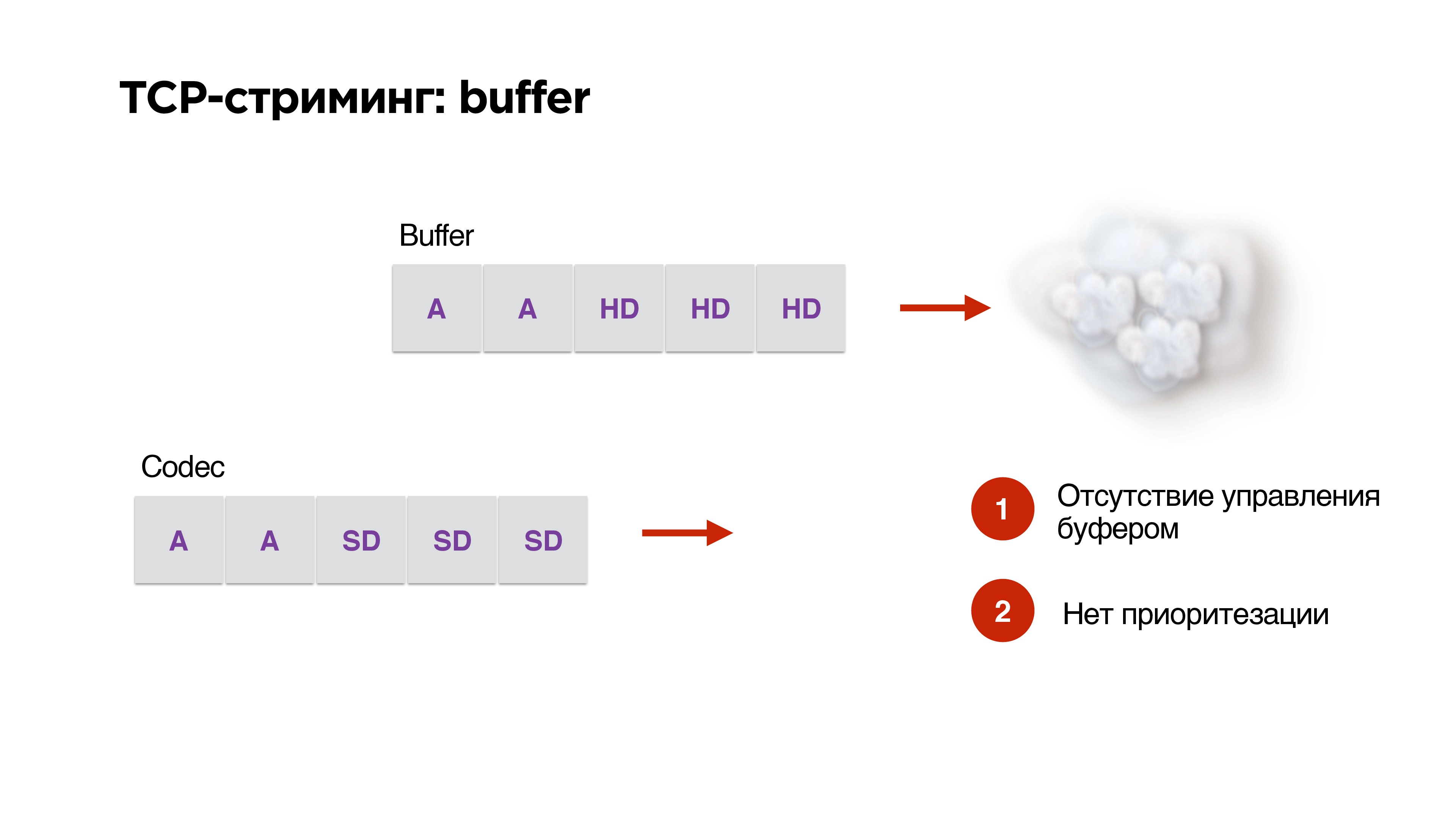
Существует еще одна проблема использования протокола TCP в стриминге.
Допустим, у нас есть буфер и высокая пропускная способность сети. Мы генерируем туда из нашего кодека пакеты в высоком разрешении. Потом — оп! — сеть стала работать хуже. На кодеке мы уже указали, что битрейт нужно понизить, но готовые пакеты уже в очереди и никаким образом изъять их оттуда нельзя. TCP отчаянно пытается пропихнуть HD-пакеты через наш 3G.
У нас нет никакого управления буфером, нет приоритезации, поэтому TCP крайне не подходит для стриминга.

Давайте теперь взглянем на мобильные сети. Возможно для жителей столиц это будет удивительно, но наша средняя мобильная сеть выглядит примерно так:
- 1,1 Мбит/с трафика;
- 0,1% packet loss;
- 300 мс средний RTT.
А если посмотреть некоторые регионы и конкретных операторов, то у них среднедневной процент потери пакетов более 3%, а RTT от 600 мс — это нормально.
TCP — это, с одной стороны, классный протокол — очень трудно научить машину ездить сразу же и по хайвэю, и по бездорожью. Но научить ее потом еще и летать по беспроводным сетям оказалось очень сложно.

Потеря даже 0,001% пакетов приводит к снижению пропускной способности на 30%. То есть наш пользователь не доутилизирует канал на 30% из-за неэффективности работы TCP протокола в сетях со случайной потерей пакетов.
В определенных регионах packet loss доходит до 1%, тогда у пользователя остается порядка 10% процентов пропускной способности.
Поэтому на TCP делать не будем.
Посмотрим, что есть еще в мире стриминга из UDP.
Протокол WebRTC очень хорошо зарекомендовал себя для p2p звонков. На очень популярных сайтах пишут, что использовать для звонков его очень здорово, а вот для доставки видео и музыки — не хорошо.
Его основная проблема в том, что он пренебрегает потерями. При всех непонятных ситуациях он просто дропает.
Есть еще некоторая проблема в его привязанности к звонкам, дело в том, что он шифрует все. Поэтому, если вы ведете броадкаст на трансляцию, и нет необходимости шифровать весь аудио/видео поток, запуская WebRTC, вы все равно напрягаете свой процессор. Возможно, вам это не нужно.

RTP-стриминг — это базовый протокол передачи данных по UDP. Ниже на слайде справа приведен набор расширений и RFC, которые пришлось реализовать в WebRTC для того, чтобы адаптировать этот протокол для звонков. В принципе, можно попробовать сделать что-то подобное — набрать набор расширений к RTP и получить UDP стриминг. Но это очень сложно.
Вторая проблема в том, что если кто-то из ваших клиентов не поддерживает какой-либо extension, то протокол не заработает.

Сегментные протоколы
Хорошим примером сегментного протокола видео является MPEG-Dash. Он состоит из manifest-файла, который вы выкладываете у себя на портале. Он содержит ссылки на файлы в разных качествах, в начале файла есть некоторый индекс, который говорит, в каком месте файла начинается какой сегмент.
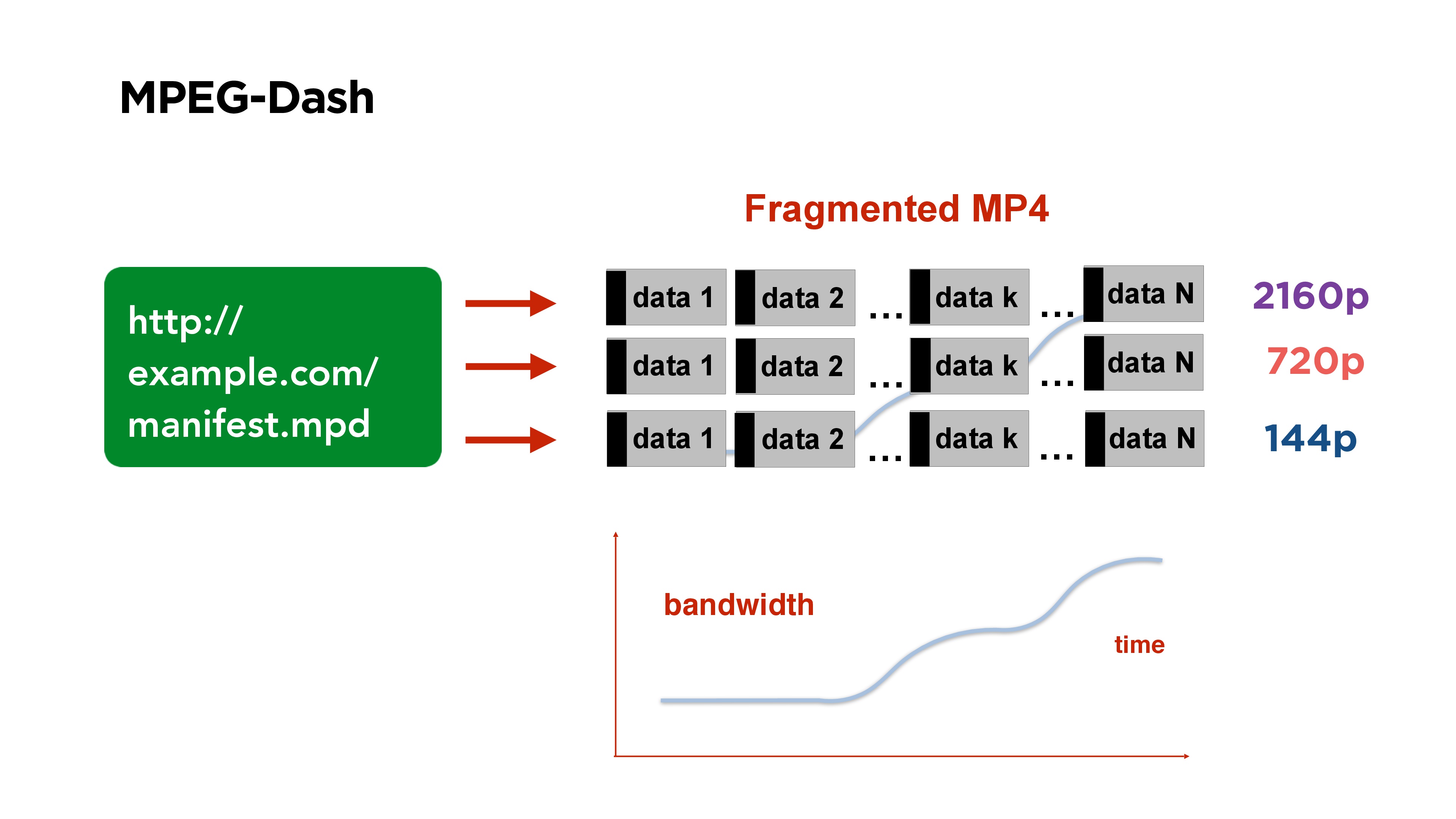
Все видео разбито на сегменты, например, по 3 секунды, каждый сегмент начинается с опорного кадра. Если вы смотрите такое видео и у вас меняется битрейт, то вы просто на стороне клиента начинаете брать сегмент того качества, которое вам нужно.
Еще одним примером сегментного стриминга является HLS.
MPEG-Dash — решение от Google, оно хорошо работает в Android, а Apple-решение более старое, у него есть ряд определенных недостатков.

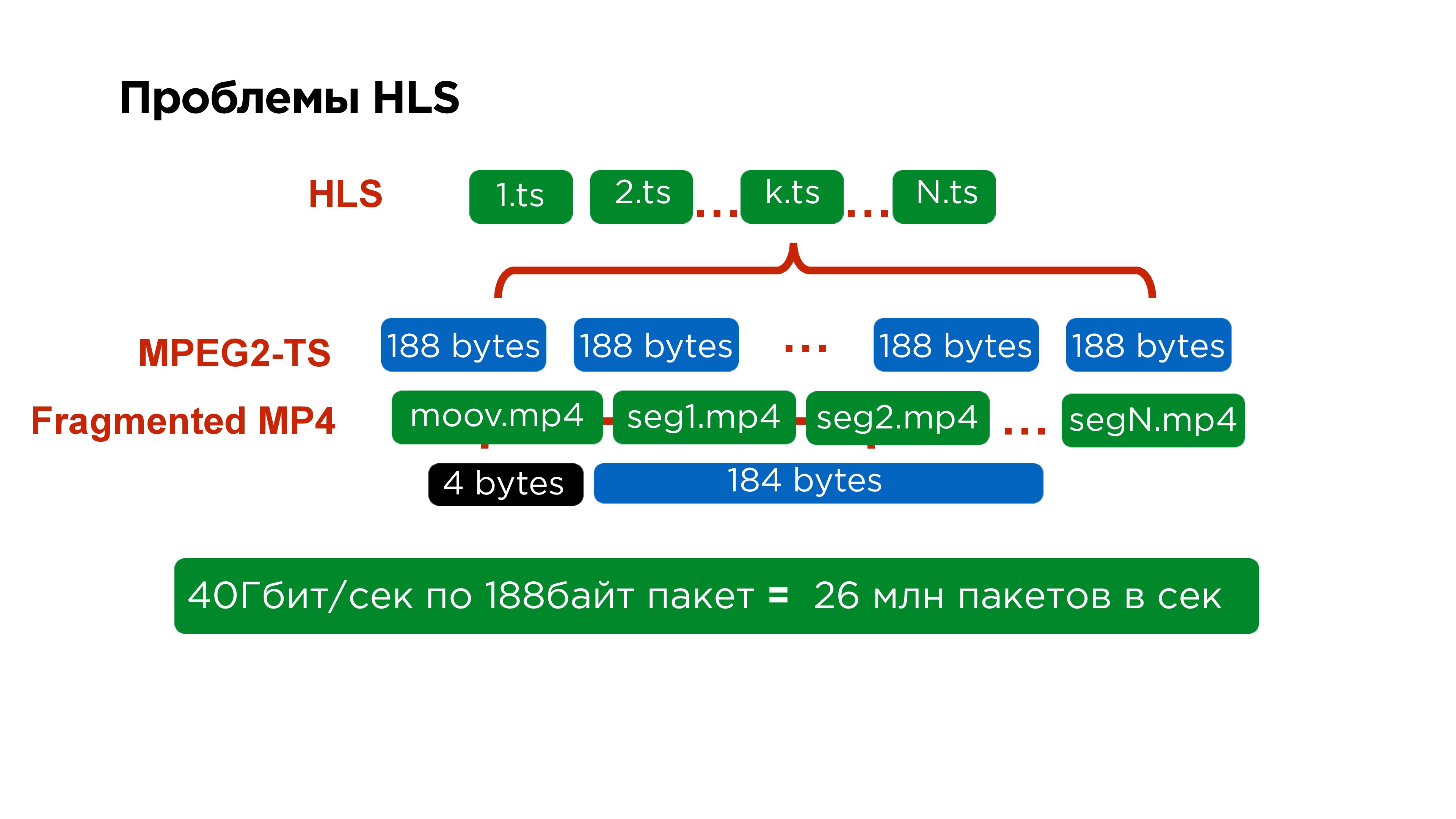
Первый из них — это то, что основной манифест содержит ссылки на вторичные манифесты, вторичные манифесты по каждому конкретному качеству содержат ссылки на каждый отдельный сегмент, а каждый отдельный сегмент представлен отдельным файлом.
Если взглянуть еще более детально, то внутри каждого сегмента находится MPEG2-TS. Этот протокол делали еще для спутника, размер его пакета 188 байт. Упаковывать видео в такой размер очень неудобно, особенно потому, что вы все время его снабжаете небольшим хедером.
На самом деле это трудно не только серверам, которые для того, чтобы обработать 40 Гб трафика должны собрать 26 млн пакетов, но это еще трудно и на клиенте. Поэтому, когда мы переписали iOS плеер на MPEG-Dash, мы даже увидели некоторый прирост производительности.
Но Apple не стоит на месте. В 2016 году они наконец-то анонсировали, что у них есть возможность запихнуть фрагмент от MPEG4 в HLS. Тогда они обещали это добавить только для разработчиков, но вроде бы сейчас должна появиться поддержка на macOS и iOS.
То есть, казалось бы, фрагментный стриминг удобный — приходите, берете нужный фрагмент, с опорного кадра стартуете — работает.
Минус: понятно, что опорный кадр, с которого вы стартовали — это не тот кадр, который сейчас у того, кто стримит. Поэтому всегда появляется задержка.
Вообще есть возможность допилить HLS до задержек порядка 5 секунд, кто-то говорит, что ему удалось получить 4, но в принципе решение использовать фрагментный стриминг для трансляции не очень хорошее.

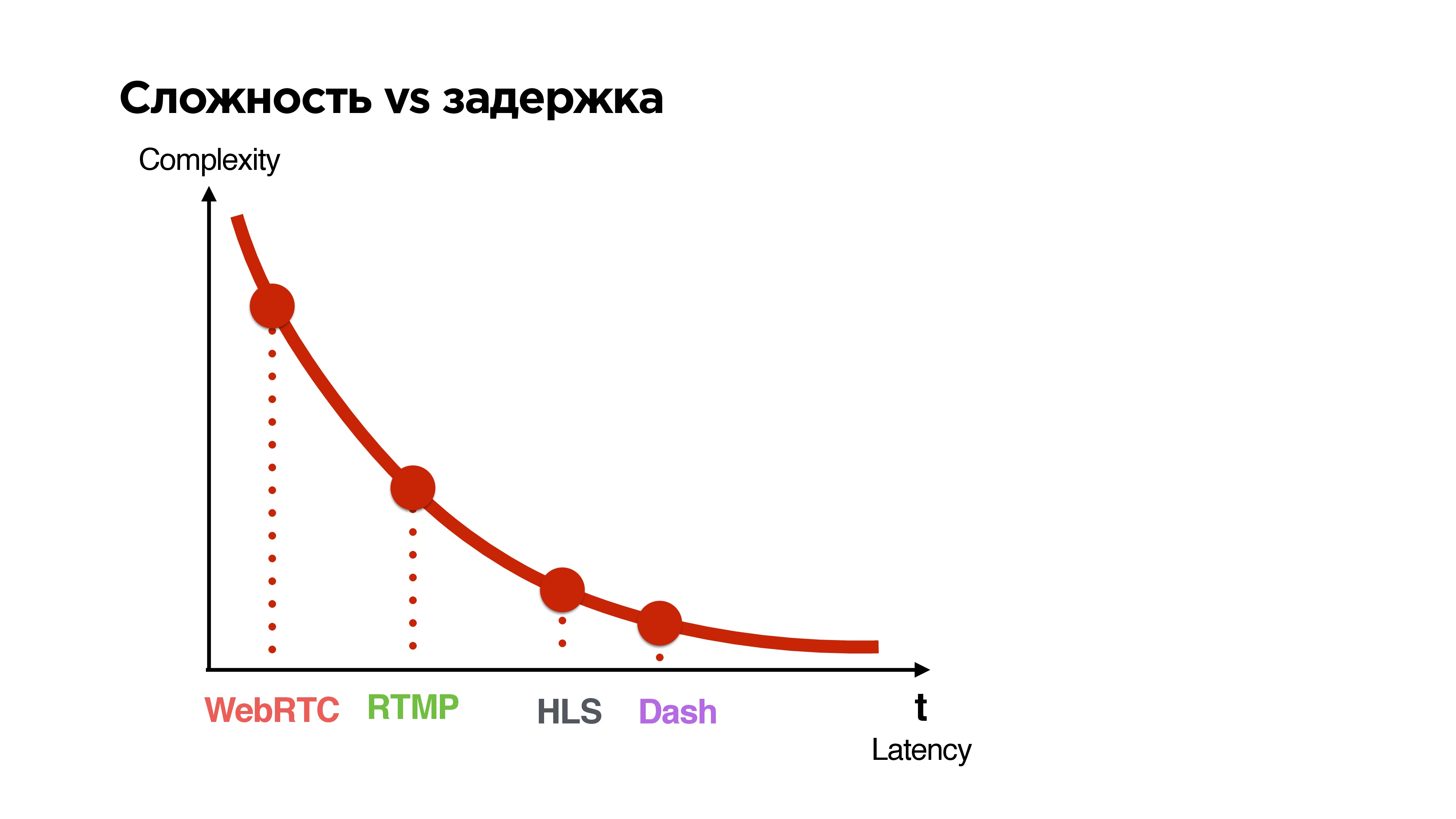
Сложность vs задержка
Посмотрим на все имеющиеся протоколы и рассортируем их по двум параметрам:
- latency, который они дают между трансляцией и смотрящим;
- complexity (сложность).
Чем меньшую задержку гарантирует протокол, тем он более сложный.
Что мы хотим?
Мы хотим сделать UDP-протокол для стриминга от 1 к N с задержкой, сравнимой с p2p связью, с возможностью опционального шифрования пакетов в зависимости от того, приватная или публичная трансляция.
Какие есть еще варианты? Можно подождать, например, когда Google выпустит свой QUIC.
Расскажу немного, что это такое. Google позиционирует Google QUIC, как замену TCP — некий TCP 2.0. Его разрабатывают с 2013 года, сейчас спецификации у него нет, зато он полностью доступен в Google Chrome, и мне кажется, что они иногда включают его некоторым пользователям для того, чтобы посмотреть, как он работает. В принципе, можно зайти в настройки, включить себе QUIC, зайти на любой Google сайт и получить этот ресурс по UDP.
Мы решили не ждать, пока они все специфицируют, и запилить свое решение.
Требования к протоколу:
- Многопоточность, то есть мы имеем несколько потоков — управляющий, видео, аудио.
- Опциональная гарантия доставки — управляющий поток имеет 100% гарантию, видео нам нужно меньше всего — мы там можем дропать фрейм, аудио нам все-таки бы хотелось.
- Приоритезация потоков — чтобы аудио уходило вперед, а управляющий вообще летел.
- Опциональное шифрование: или все данные, или только заголовки и критичные данные.
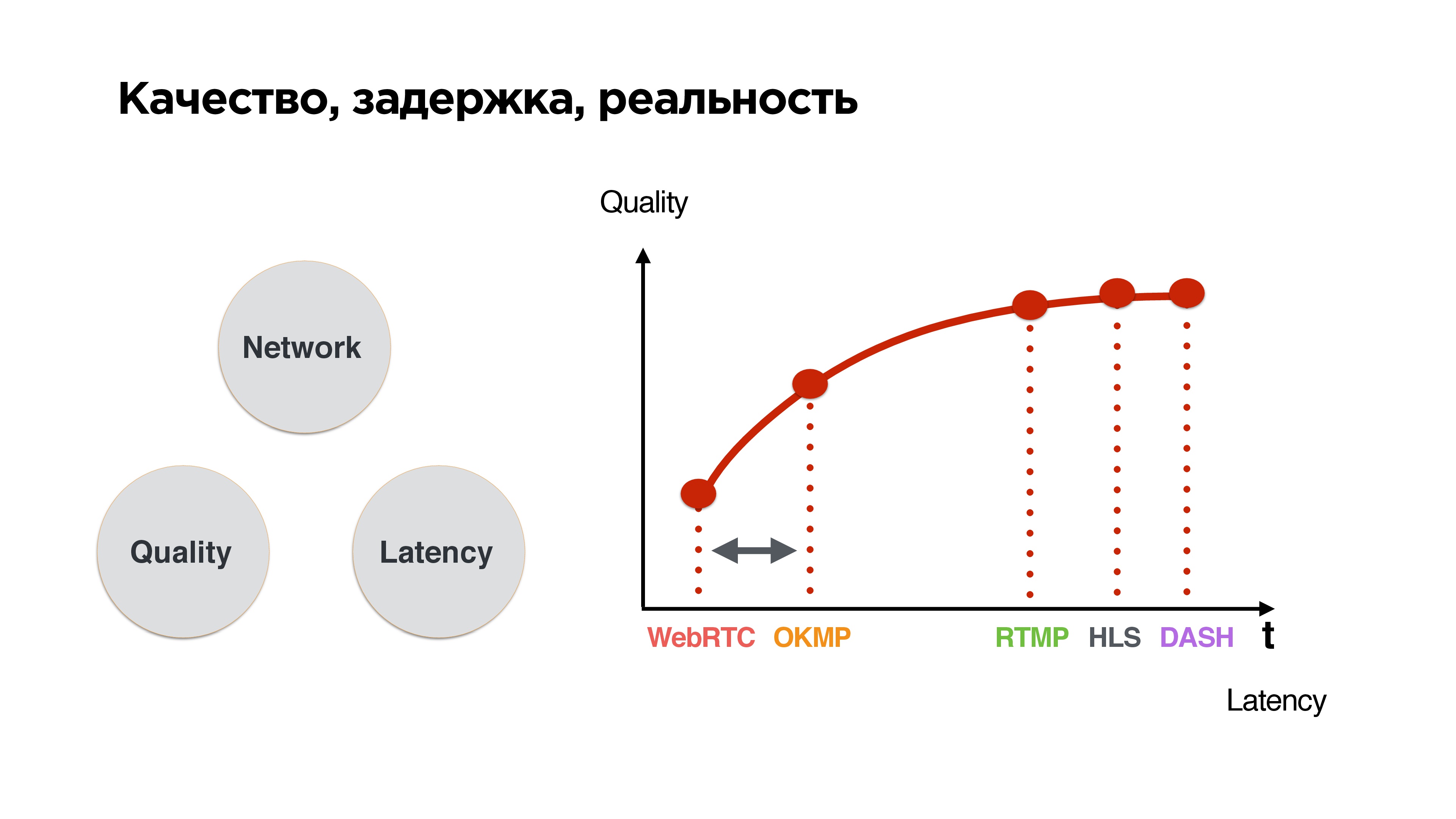
Это стандартный треугольник: если хорошая сеть, то высокое качество и низкие задержки. Как только появляется нестабильная сеть, начинают пропадать пакеты, мы балансируем между качеством и задержкой. У нас есть выбор: либо подождать, пока сеть наладится и отправить все, что накопилось, либо дропнуть и как-то с этим жить.
Если сортировать протоколы по такому принципу, то видно, что чем меньше время ожидания, тем хуже качество — довольно простой вывод.
Мы хотим свой протокол вклинить в зону, где задержки близки к WebRTC, но при этом иметь возможность его немножко отодвинуть, потому что все-таки у нас не звонки, а трансляции. Пользователь хочет в конечном итоге получать качественный стрим.
Разработка
Давайте уже начнем писать UDP протокол, но сначала посмотрим на статистику.
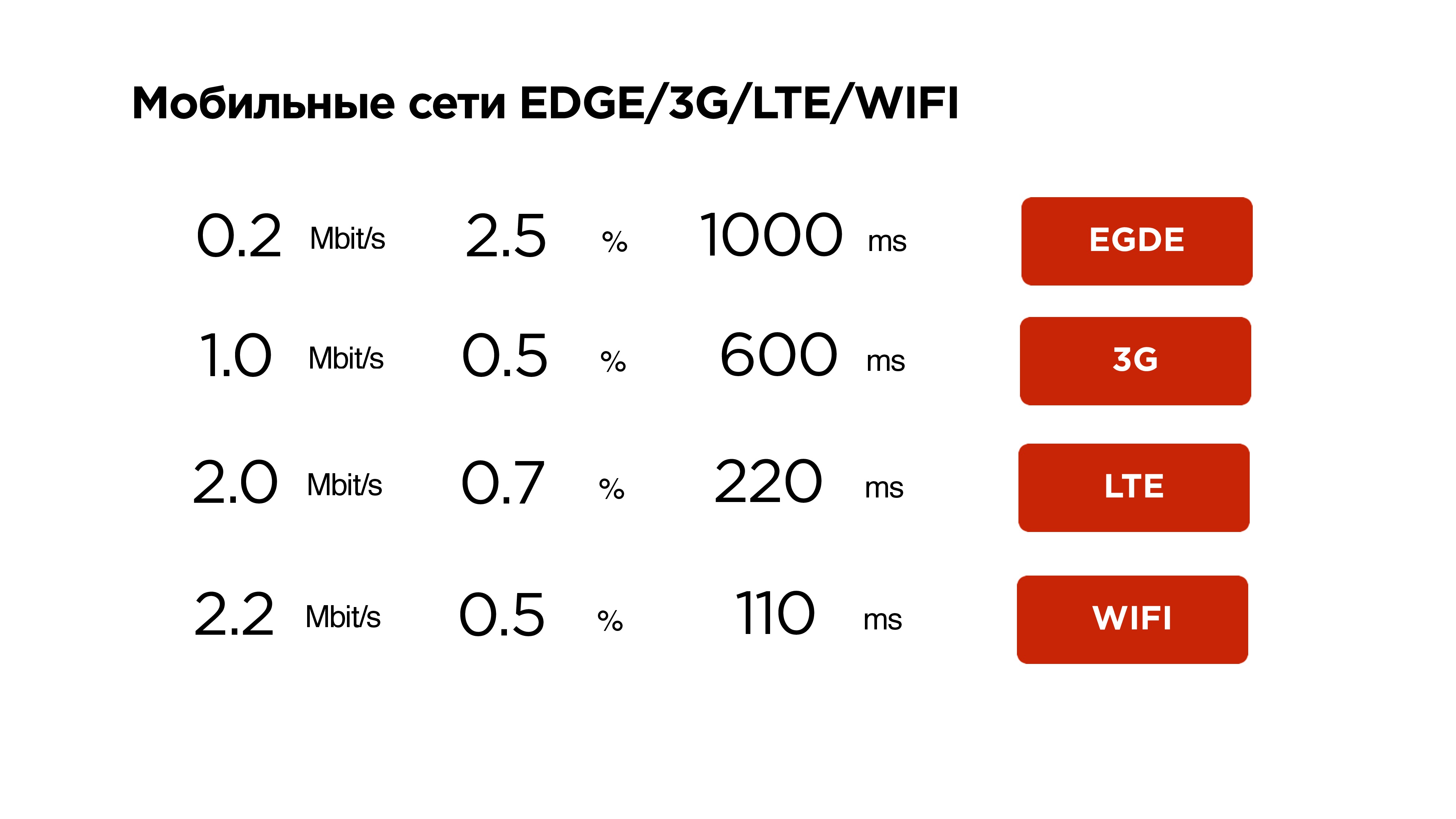
Это наша статистика по мобильным сетям. Тут видно, что средний интернет чуть больше мегабита, packet loss около 1% — это нормально, и RTT в районе 600 мс — на 3G это просто средние величины.
Будем на это ориентироваться при написании протокола — поехали!
UDP-протокол
Открываем socket UDP, забираем данные, упаковываем, отправляем. Берем вторую пачку от кодека, еще отправляем. Вроде бы все здорово!

Но мы получим такую картину: если мы начинаем беспорядочно слать UDP пакеты в socket, то по статистике к 21-му пакету вероятность того, что он дойдет, будет всего лишь 85%. То есть packet loss уже будет 15%, что никуда не годится. Это нужно исправлять.

Исправляется это стандартно. На рисунке проиллюстрирована жизнь без Pacer и жизнь с Pacer.
Pacer — это такая штука, которая раздвигает пакеты во времени и контролирует их потерю; смотрит, какой сейчас packet loss, в зависимости от этого адаптируется под скорость канала.
Как мы помним, для мобильных сетей 1–3% packet loss — это норма. Соответственно, надо с этим как-то работать. Что делать, если мы теряем пакеты?
Retransmit
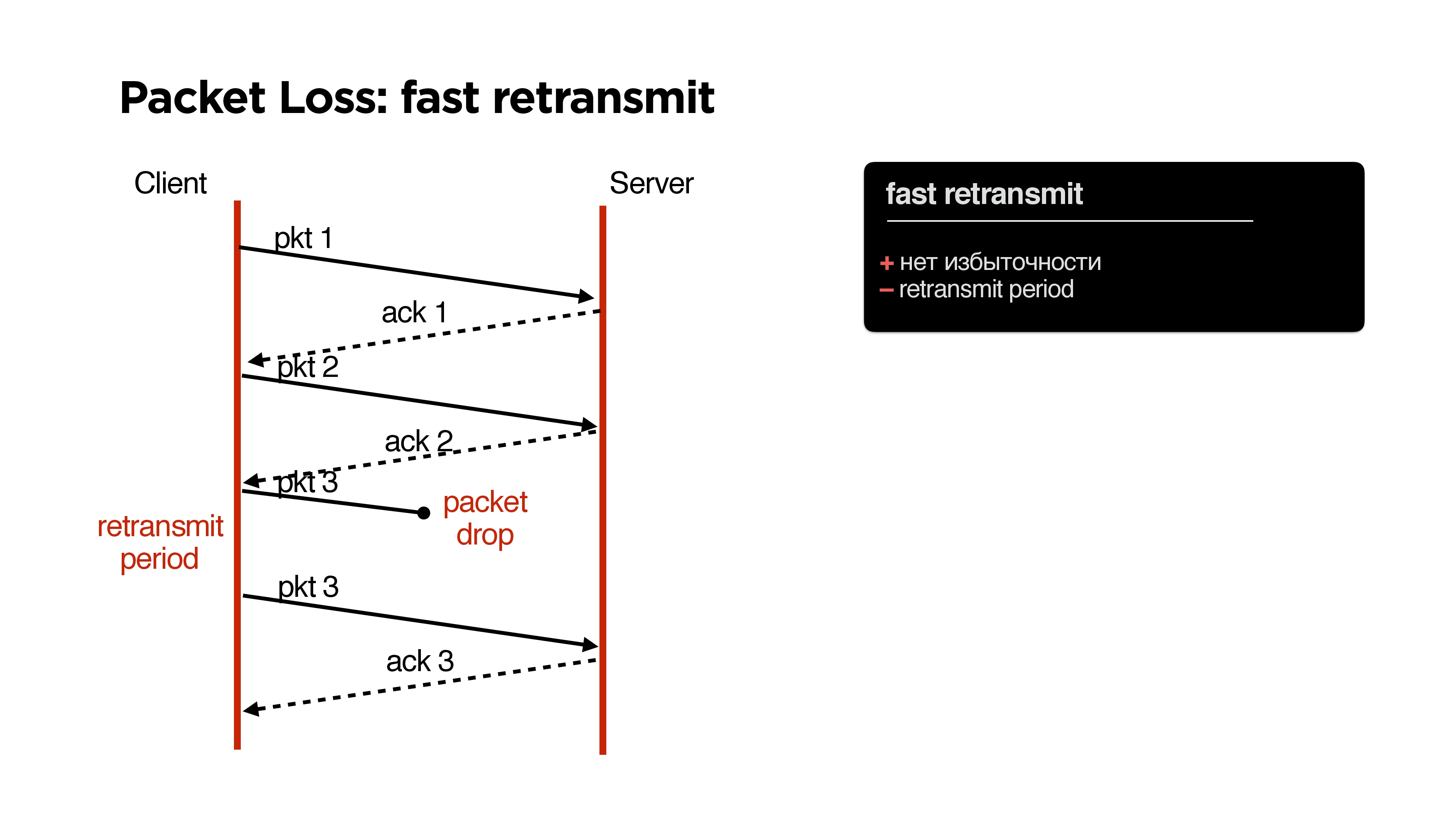
В TCP, как известно, есть алгоритм fast retransmit: мы отправляем один пакет, второй, если пакет потеряли, то через некоторое время (retransmit period) отправляем этот же пакет.
Какие здесь плюсы? Никаких проблем, никакой избыточности, но есть минус — некоторый retransmit period.
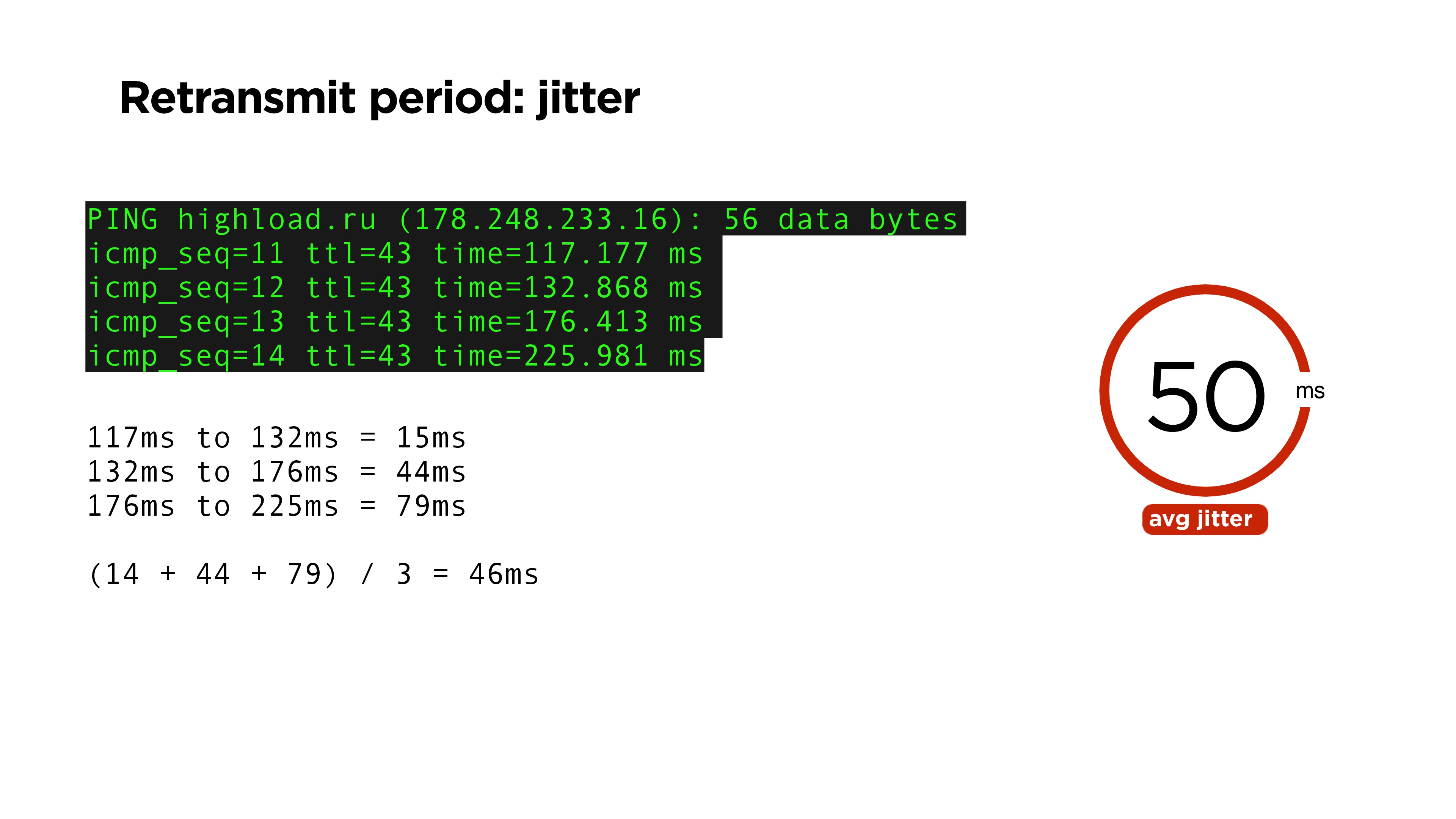
Кажется, что очень просто: через какое-то время нужно повторить пакет, если вы не получили на него подтверждение. Логично, что это может быть время равное времени пинга. Но ping — это величина не стабильная, и поэтому точно через средний RTT time определить, что потерян пакет, мы не можем.
Для того, чтобы это оценить можно, например, использовать такую величину, как jitter: мы считаем разницу между всеми нашими ping-пакетами. Например, в примере выше, средняя величина равна 46 мс. На нашем портале средний jitter — 50.

Посмотрим на распределение вероятности приходов пакетов ко времени. Есть некоторый RTT и некоторая величина, после которой мы можем действительно понять, что acknowledge не пришел и повторить отправку пакета. В принципе, есть RFC6298, который в TCP говорит, как это можно хитро посчитать.
Мы это делаем через jitter. На портале у нас jitter по ping примерно 15%. Понятно, что retransmit period должен быть, как минимум, на 20% больше, чем RTT.
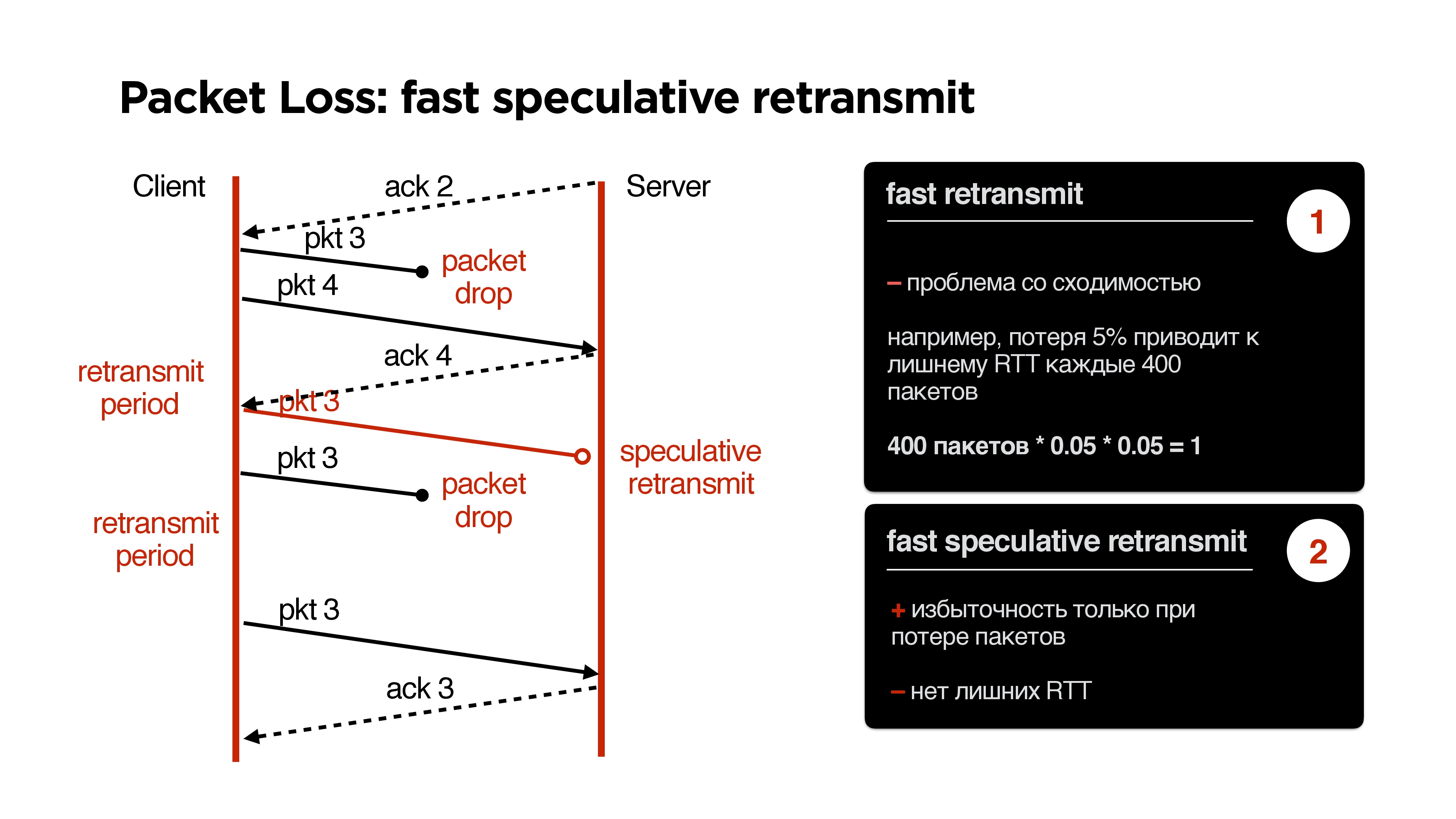
Еще один кейс с retransmit. С прошлого раза у нас был acknowledge на второй пакет. Мы отправляем третий пакет, который теряется, другие пакеты пока ходят. После этого наступает retransmit period, и мы отправляем третий пакет еще раз. Он еще раз дропнулся, и мы еще раз отправляем его.
Если у нас случается двойная потеря пакета, то на retransmit появляется новая проблема. Если у нас, например, packet loss 5%, и мы отправляем 400 пакетов, то на 400 пакетов у нас 1 раз точно будет ситуация двойного packet-drop, то есть, когда мы через retransmit period отправили пакет, и он еще раз не дошел.
Эту ситуацию можно исправить, добавив некоторую избыточность. Можно начать отправлять пакет, например, если мы получили acknowledge от другого пакета. Считаем, что опережение — это редкая ситуация, можем начать отправку третьего пакет в момент, обозначенный speculative retransmit на слайде выше.
Можно еще пошаманить со спекулятивным retransmit, и все будет неплохо работать.
Но тут мы заговорили про избыточность. А что, если добавить Forward Error Correction? Давайте просто все наши пакеты снабдим, например, XOR. Если мы точно знаем, что в мобильных сетях все так печально, то давайте просто добавим еще один пакетик.
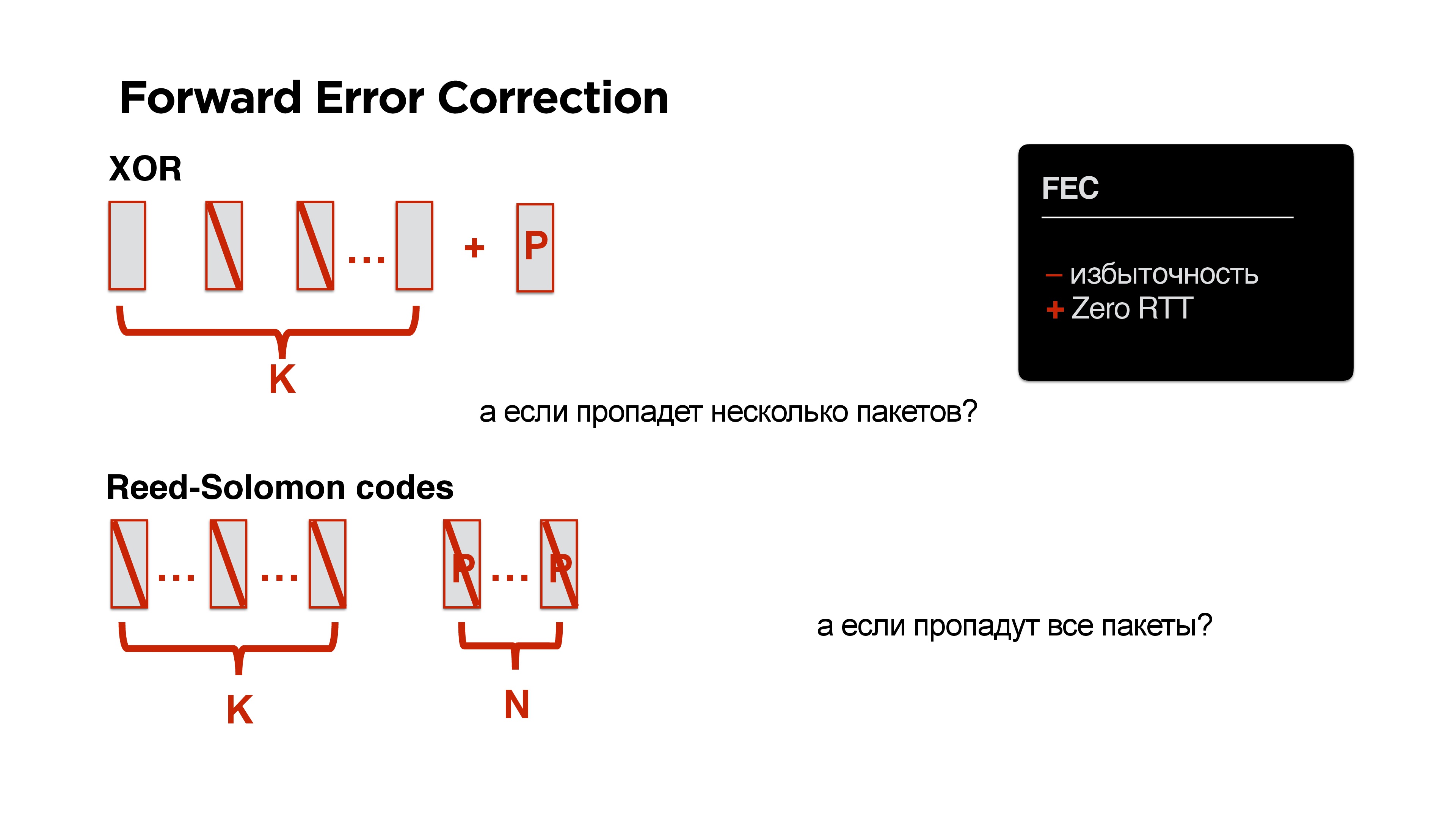
Здорово! Нам не нужны никакие round trip, но у нас уже появилась избыточность.
А что, если пропадет не один пакет, а сразу два? Давайте вместо XOR возьмем другое решение — например, есть код Reed-Solomon, Fountain codes и т.д. Идея такая: если есть K пакетов, можно добавить к ним N пакетов так, что любые N можно было потерять.
Вроде бы классно!
Хорошо, если у нас такая плохая сеть, что пропали просто все пакеты, то к нашему Forward Error Correction очень удобно добавляется negative acknowledgement.
NACK
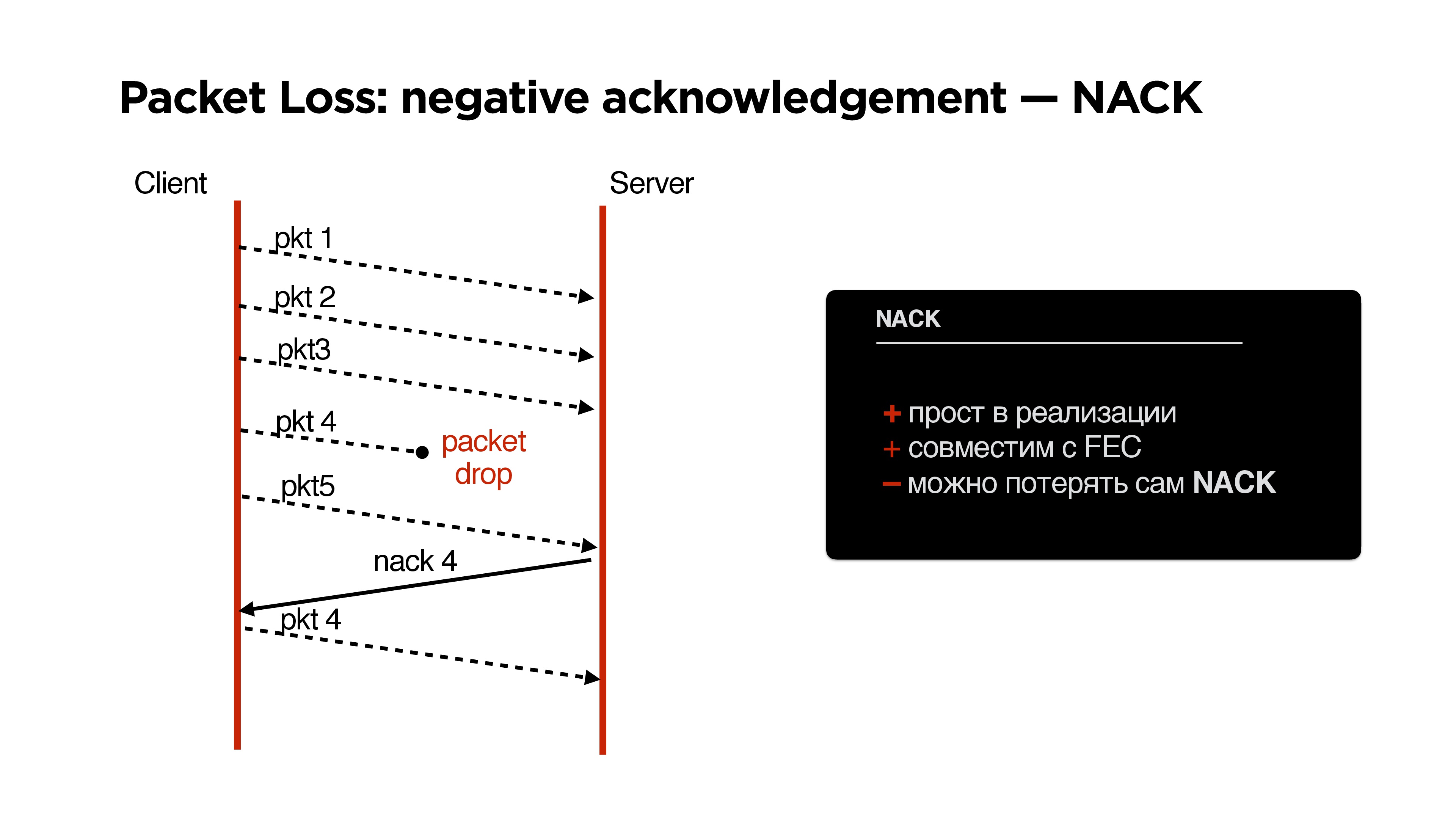
Если мы потеряли столько пакетов, что наш parity protection (назовем его так) нас уже не спасает, запрашиваем этот пакет дополнительно.
Плюсы NACK:
- Простой в реализации, правда можно потерять и сам negative acknowledgement, но это мелкая проблема.
- Хорошо совместим с FEC.
Итого, есть два интересных решения:
- С одной стороны, FEC + NACK;
- С другой стороны, Fast retransmit.
Посмотрим, как распределены потери пакетов.

Оказывается, что пакеты теряются не равномерно по одной штучке, а пачками (выше график распределений). Причем есть интересные пики, например, на 11 пакетах, есть еще пики на 60–80 пакетах. Они повторяются, и мы изучаем, откуда они берутся.
В среднем на нашем портале теряется по 6 пакетов.

Детальное рассмотрение по сетям показывает, что чем хуже сеть, тем больше это количество. В таблице указано время, которое сеть была недоступна. Например, Wi-Fi недоступен 22 мс и теряет 5 пакетов, 3G может за 24 мс потерять 8 пакетов.

Вопрос: если мы знаем, что у нас 90% packet loss на портале укладывается в 10 пакетов, и при этом средний gap равен 25 мс, что будет работать лучше — FEC + NACK или Fast retransmit?
Тут, наверное, надо рассказать, что Google, когда делал свой протокол QUIC в 2013 году, ставил Forward Error Correction во главу, думая, что он решит все проблемы. Но в 2015 они его отключили.
Мы протестировали оба варианта и у нас не получилось завести FEC + NACK, но мы еще пытаемся и не отчаиваемся.
Рассмотрим, как он работает.
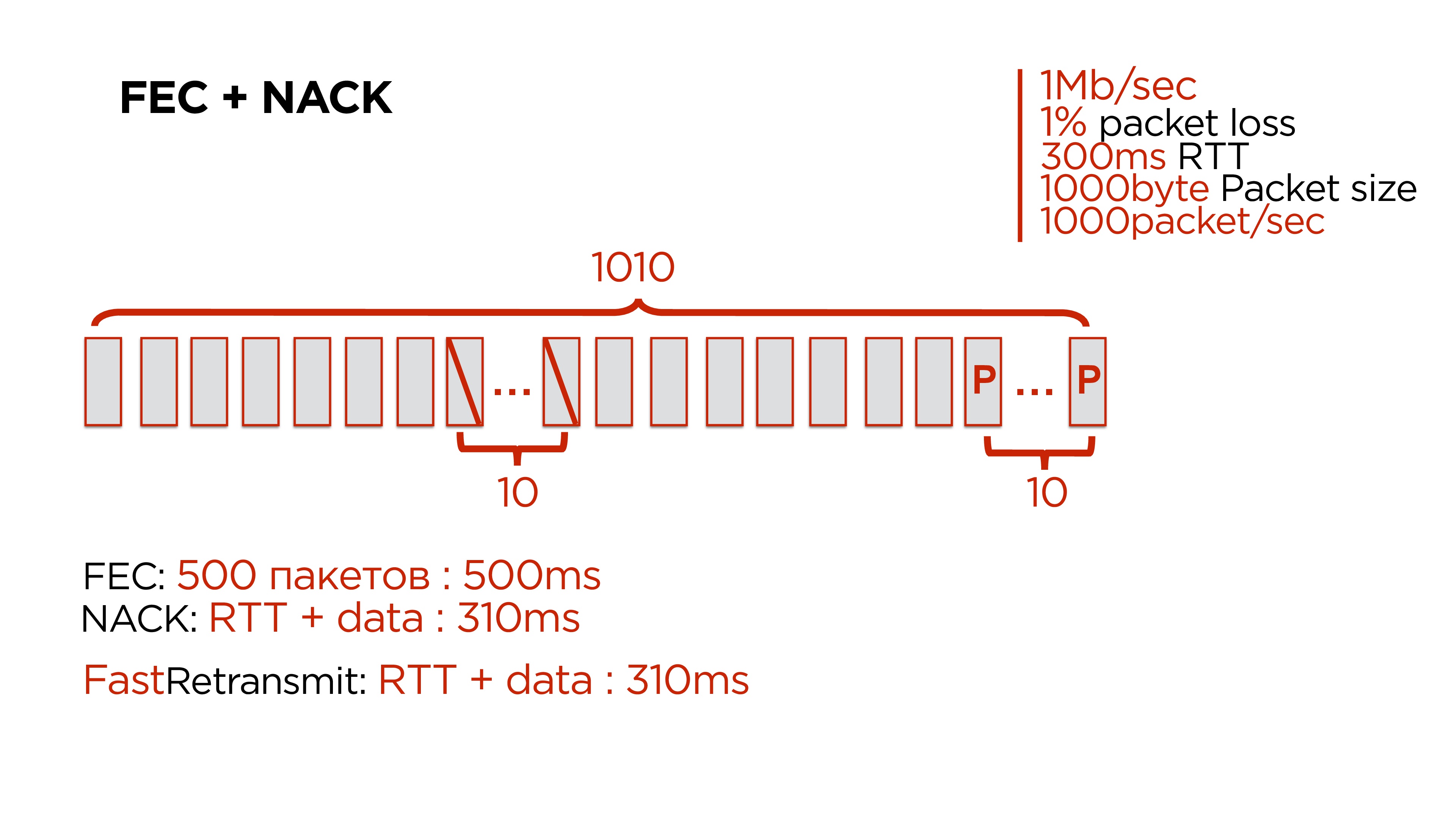
Это цифры, близкие к средней сети, проcто чтобы было удобно считать:
- 1 Мб/с сеть;
- 1% packet loss;
- 300 мс RTT;
- 1 000 байт — размер пересылаемых пакетов;
- 1 000 пакетов в секунду уходит.
Мы хотим справляться с потерей сразу до 10 пакетов. Соответственно при packet loss в 1% нам нужно к 1 000 пакетов добавлять 10. Логично — почему нельзя к 100 пакетам добавлять 1 — потому что, если мы потеряли интервал хотя бы в 2 пакета, мы не восстановимся.
Мы начинаем делать такие добавки, и вроде бы все здорово. И тут на 500-м пакете, теряем ту самую пачку из 10 штук.
У нас есть варианты:
- Дождаться оставшиеся 500 пакетов и восстановить данные через Forward Error Correction. Но на это у нас потратится примерно полсекунды, а пользователь эти данные ждет.
- Можно воспользоваться NACK, причем это дешевле, чем дожидаться кодов коррекции.
- А еще можно просто взять Fast Retransmit, не добавлять никаких кодов коррекции и получить тот же самый результат.
Поэтому Forward Error Correction действительно работает, но работает на очень узком диапазоне — когда gap небольшой и можно раз в 200–300 пакетов вставлять это избыточное кодирование.
Fast Retransmit
Это работает так: после того, как мы потеряли пачку в 10 пакетов, отправив пока другие пакеты, понимаем, что у нас retransmit period прошел, и отправляем эти пакеты заново.

Самое интересное в том, что retransmit period на такой сети будет 350 мс, а средняя длительность этого packet gap — 25–30 мс, пусть даже 100. Это означает, что к моменту, когда retransmit начнет обрабатывать пакеты, в большинстве случаев сеть уже восстановится и они уйдут.
У нас получилось, что эта штука работает лучше и быстрее.
Дополнительные опции
Когда вы пишете свой протокол поверх UDP и у вас есть возможность отправки пакетов, вы получаете дополнительные плюшки.
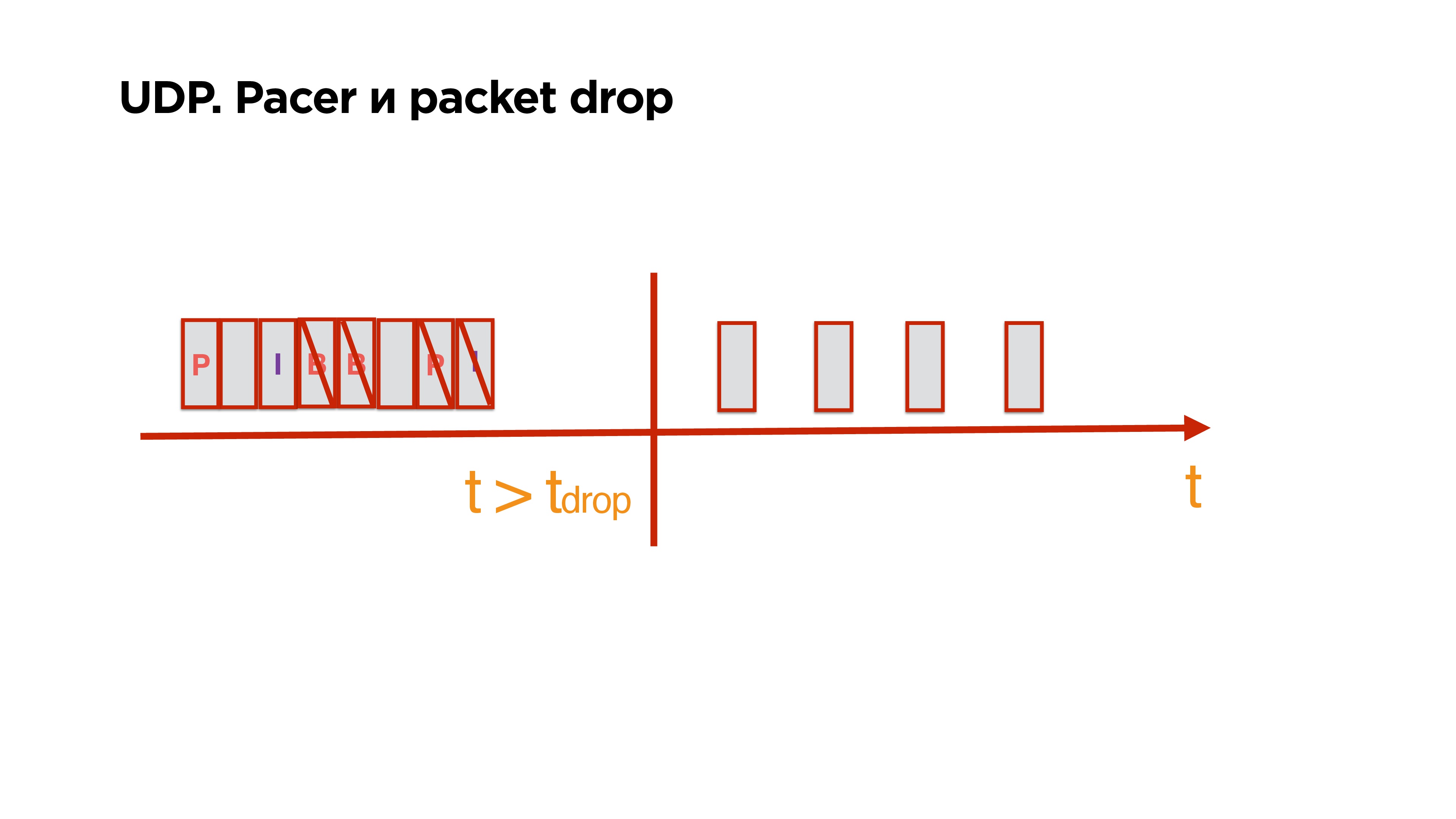
Есть буфер отправки, в нем лежит опорный кадр, к нему p/b-кадры. Они равномерно уходят в сеть. Тут они перестали уходить в сеть, а в очередь прилетели еще пакеты.
Вы понимаете, что на самом деле все пакеты, которые лежат в очереди, уже больше не интересны клиенту, потому что прошло, например, больше 0,5с и надо на клиенте просто склеить разрыв и жить дальше.
Вы можете, имея информацию о том, что у вас хранится в этих пакетах, почистить не только опорный кадр, но и все p/b, от него зависящие, и оставить исключительно нужные и целостные данные, которые потом могут потребоваться клиенту.
MTU
Так как мы сами пишем протокол, то придется столкнуться с IP fragmentation. Думаю, многие про это знают, но на всякий случай вкратце расскажу.
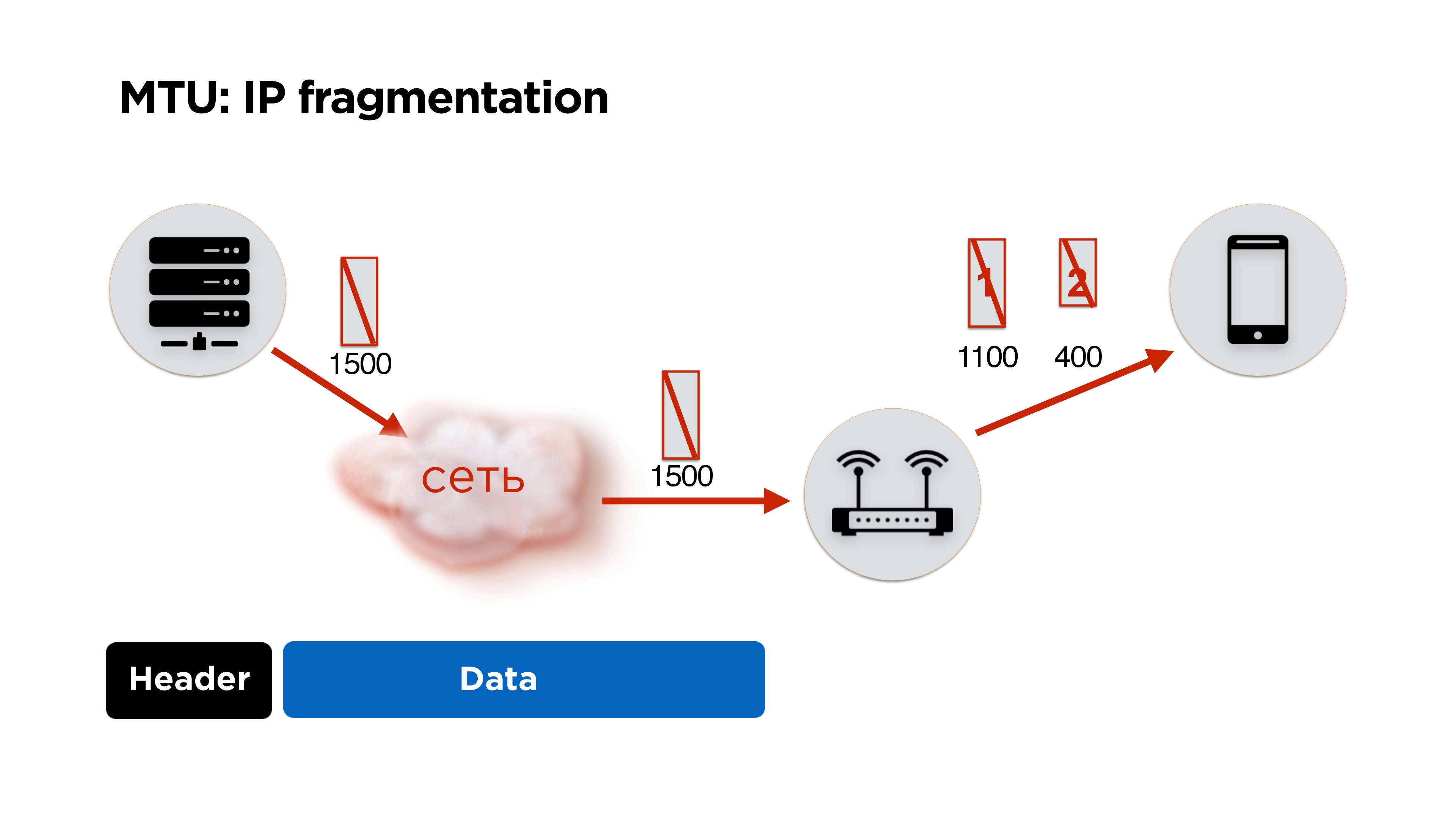
У нас есть сервер, он отправляет какие-то пакеты в сеть, они приходят к маршрутизатору и на его уровне MTU (maximum transmission unit) становится ниже, чем размер пакета, который пришел. Он дробит пакет на большой и маленький (здесь 1100 и 400 байт) и отправляет.
В принципе, проблемы нет, это все соберется на клиенте и будет работать. Но если мы теряем 1 пакет, мы дропаем все пакеты, плюс получаем дополнительные издержки на header«ы пакетов. Поэтому, если вы пишете свой протокол, идеально работать в размере MTU.
Как его посчитать?
На самом деле Google не заморачивается, ставит порядка 1200 байт в своем QUIC и не занимается его подбором, потому что IP фрагментация потом все пакетики соберет.
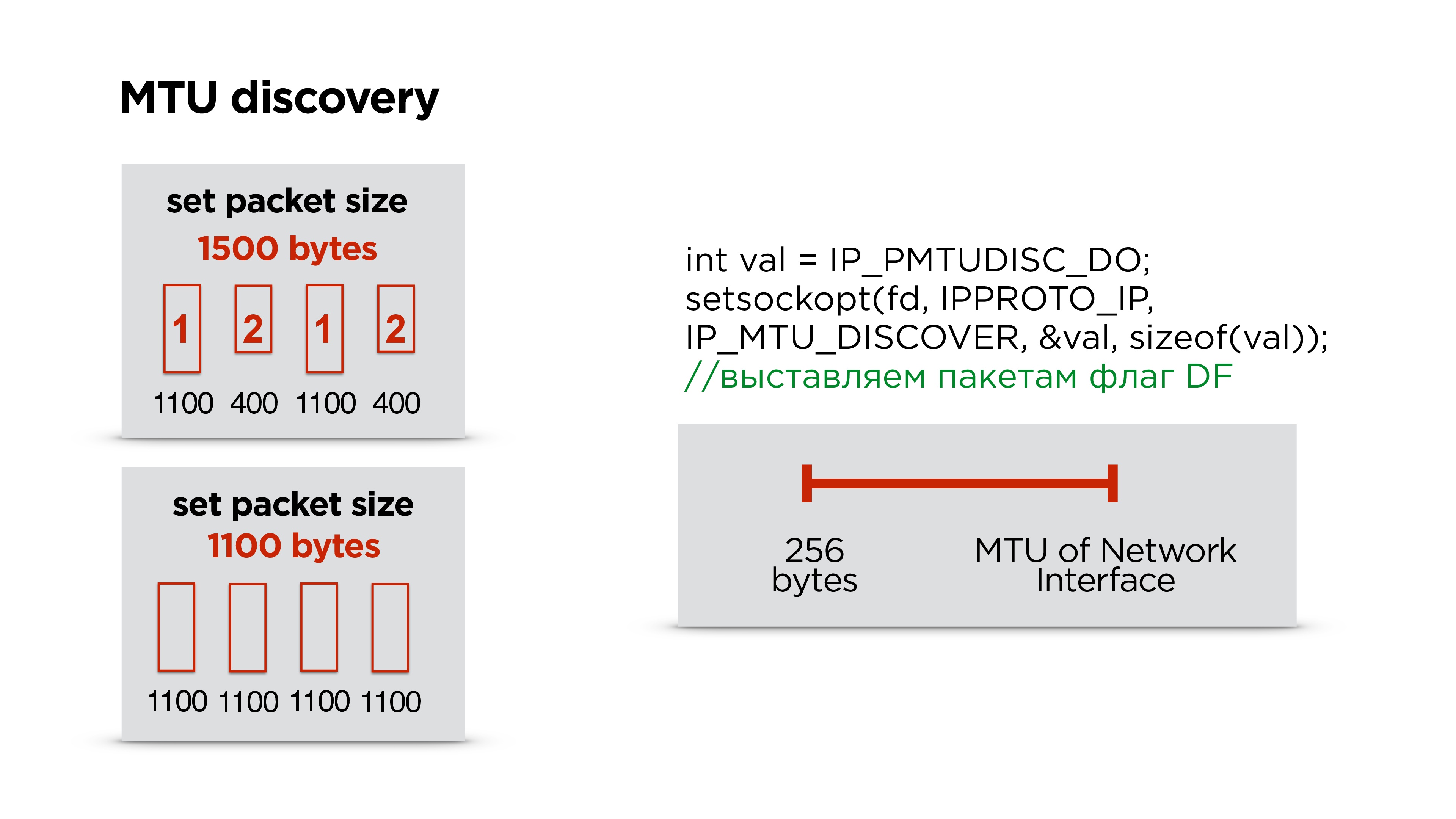
Мы делаем точно также — сначала ставим какой-то дефолтный размер и начинаем слать пакеты — пусть он их фрагментирует.
Параллельно запускаем отдельный поток и создаем socket с флагом запрета фрагментации для всех пакетов. Если маршрутизатор встречает такой пакет и не может эти данные фрагментировать, то он дропнет пакет и возможно по ICMP вам отправит, что есть проблемы, но скорее всего, ICMP будет закрыт и этого не будет. Поэтому мы просто, например, три раза пытаемся отправить пакет определенного размера с каким-то интервалом. Если он не дошел, мы считаем, что MTU превышен и дальше его уменьшаем.
Таким образом, имея MTU интернет интерфейса, который есть на устройстве, и какое-то минимальное MTU, просто одномерным поиском подбираем правильный MTU. После этого корректируем размер пакета в протоколе.
На самом деле, он иногда меняется. Мы были удивлены, но в процессе переключения Wi-Fi и пр. MTU меняется. Этот параллельный процесс лучше не останавливать и время от времени подправлять MTU.
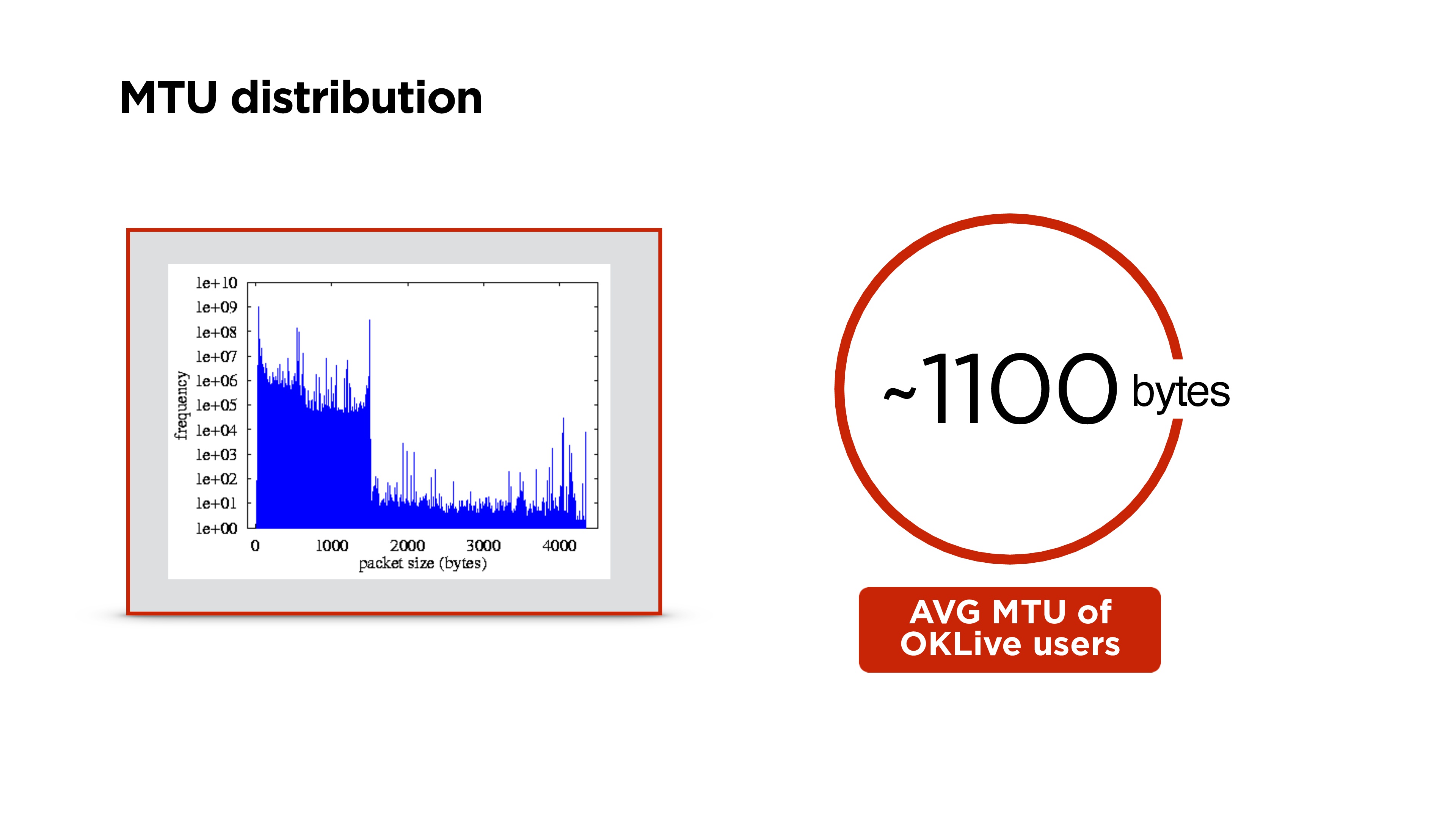
Выше распределение MTU в мире. У нас на портале получилось около 1100 байт.
Шифрование
Мы говорили, что мы хотим опционально управлять шифрованием. Делаем самый простой вариант — Diffie-Hellman на эллиптических кривых. Делаем его опционально — шифруем только управляющие пакеты и заголовки, чтобы man-in-the-middle не мог получить ключ трансляции, перехватить и так далее.
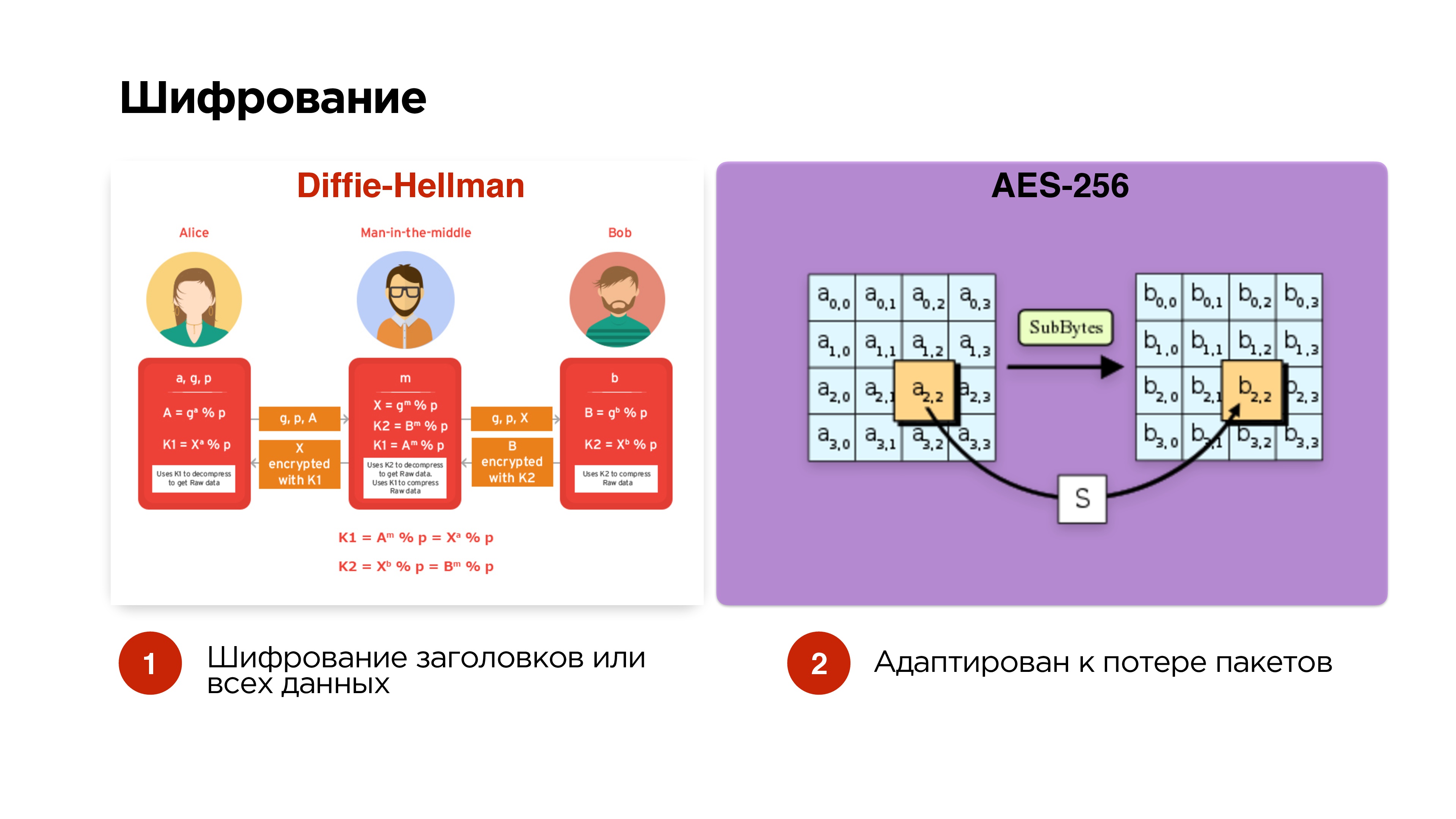
Если трансляция приватная, то можем добавить еще и шифрование всех данных.
Пакеты шифруем AES-256 независимо, чтобы packet drop никак не влиял на дальнейшее шифрование пакетов.
Приоритезация
Помните, мы хотели от протокола еще приоритезацию.
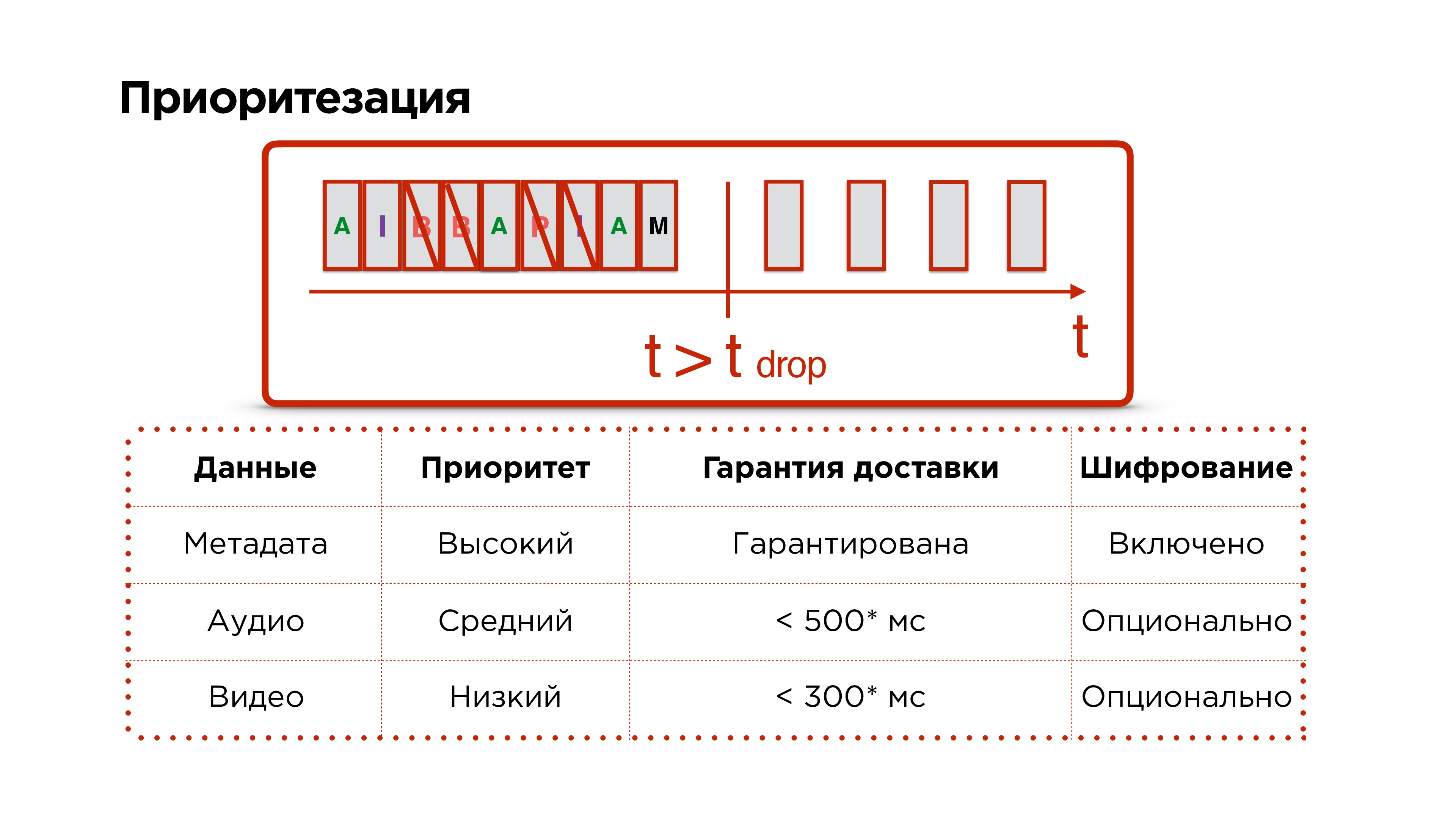
У нас есть метаданные, аудио и видеофреймы, мы их успешно отправляем в сеть. Потом наша сеть сгорает в аду и долго-долго не работает — мы понимаем, что нам нужно дропать пакеты.
Мы приоритетно дропаем видеопакеты, потом пытаемся дропать аудио и никогда не трогаем управляющие пакеты, потому что по ним могут ходить такие данные, как изменение разрешения и другие важные вопросы.
Дополнительная плюшка по поводу UDP
Если вы будете писать свой UDP протокол, например, с двухсторонней связью, то нужно понимать, что есть NAT Unbinding и шанс, что вы не сможете обратно с сервера найти клиента.
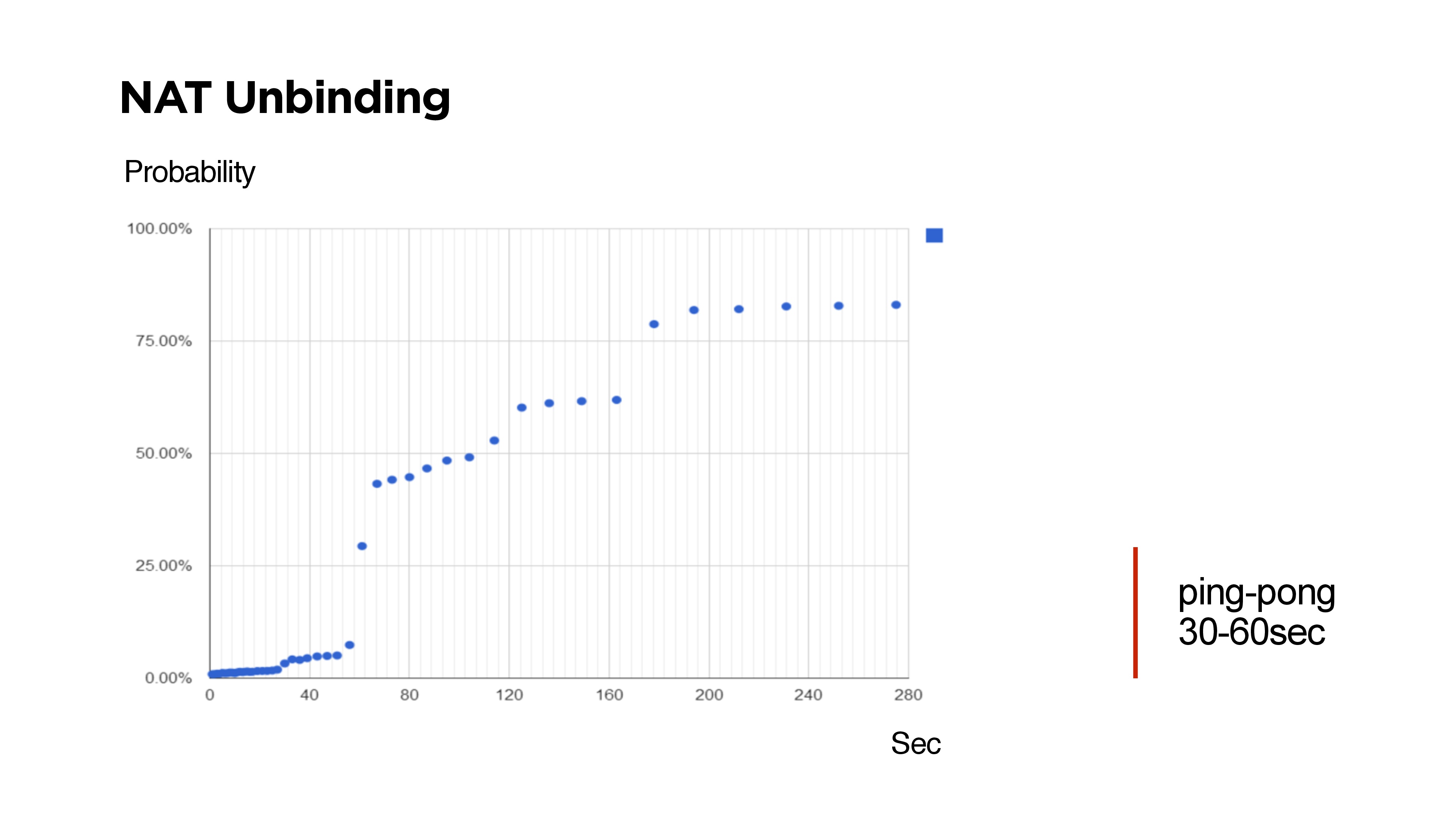
На слайде как раз времена, когда не удалось достучаться до клиента с сервера по UDP.
Многие скептики говорят, что маршрутизаторы устроены так, что NAT Unbinding вытесняет в первую очередь именно UDP маршруты. Но выше видно, что если Keep-Alive или ping будет меньше 30 секунд, то с вероятностью 99% будет возможно достичь клиента.
Доступность UDP на мобильных устройствах в мире

Google говорит, что 6%, но у нас получилось, что 7% мобильных пользователей не могут пользоваться UDP. В этом случае мы оставляем наш прекрасный протокол с приоритезацией, шифрованием и всем, только на TCP.
На UDP сейчас работает VOIP по WebRTC, Google OUIC, и многие игры работают по UDP. Поэтому верить, что UDP на мобильных устройствах закроют, я бы не стал.
В итоге мы:
- Снизили задержку между стримером и смотрящим до 1 с.
- Избавились от накопительного эффекта в буферах, то есть трансляция не отстает.
- Снизилось количество stall«ов у зрителей.
- Смогли поддержать на мобильных устройствах FullHD стриминг.

- Задержка в нашем мобильном приложении OK Live 25 мс — на 10 мс дольше, чем работает сканер камеры, но это не так страшно.
- Трансляция на Web показывает задержку всего 690 мс — космос!
Что еще умеет стриминг на Одноклассниках
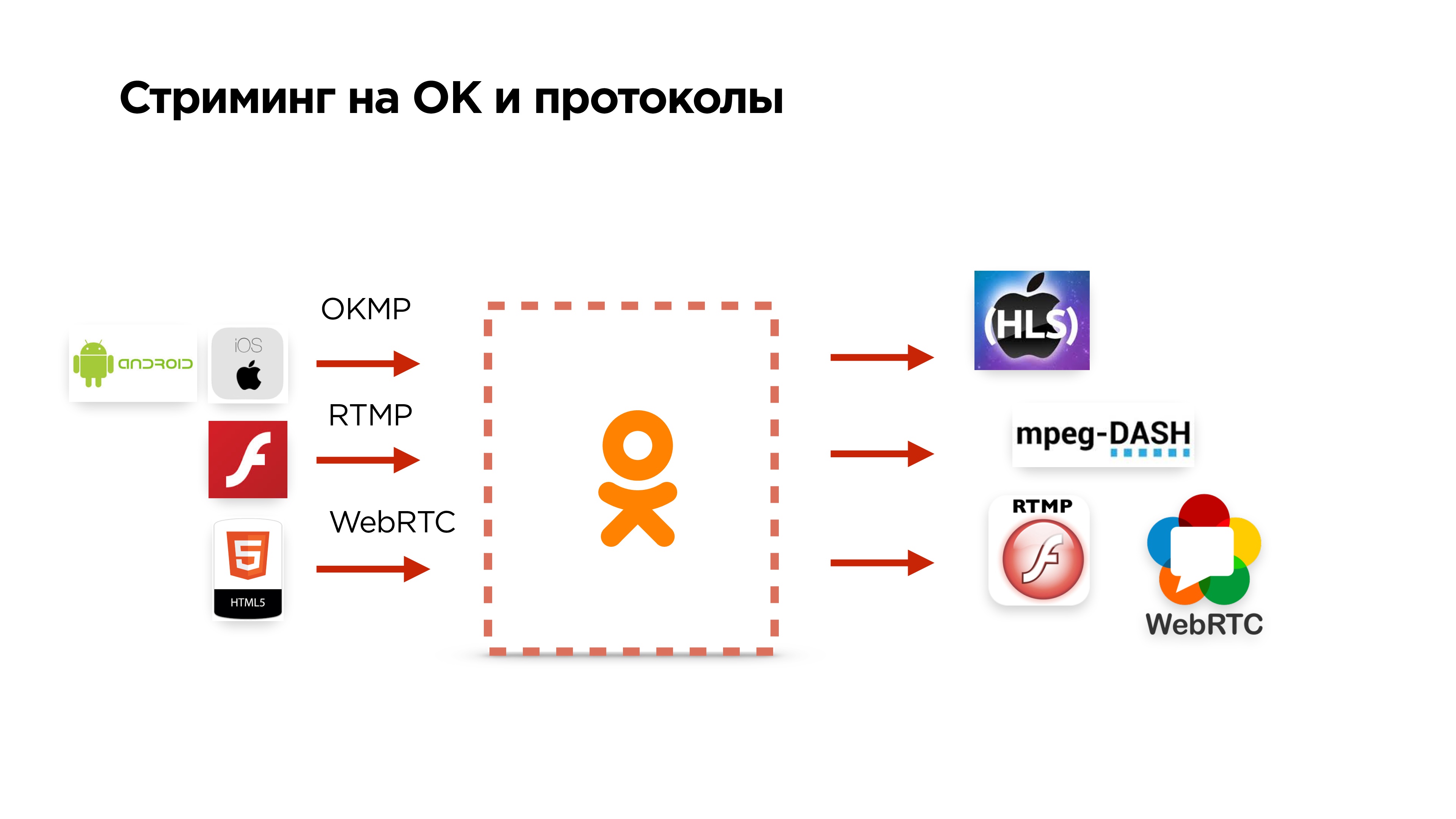
- Принимает наш протокол OKMP с мобильных устройств;
- может принимать RTMP и WebRTC;
- выдает на выходе HLS, MPEG-Dash и т.д.
Если вы были внимательны, то заметили, что я сказал, что мы можем взять у пользователя, например, WebRTC и сконвертировать его в RTMP.

Тут есть нюанс. На самом деле WebRTC — протокол, ориентированный на дроп пакетов, и у него используется аудио кодек OPUS. В RTMP использовать OPUS нельзя.
На серверах бэкенда мы везде используем RTMP. Поэтому нам пришлось сделать еще некоторый фикс в FF MPEG, который позволяет запихнуть OPUS в RTMP, его сконвертировать в AAC и отдать пользователям уже в HLS или еще в чем-то.
Как это выглядит у нас внутри?
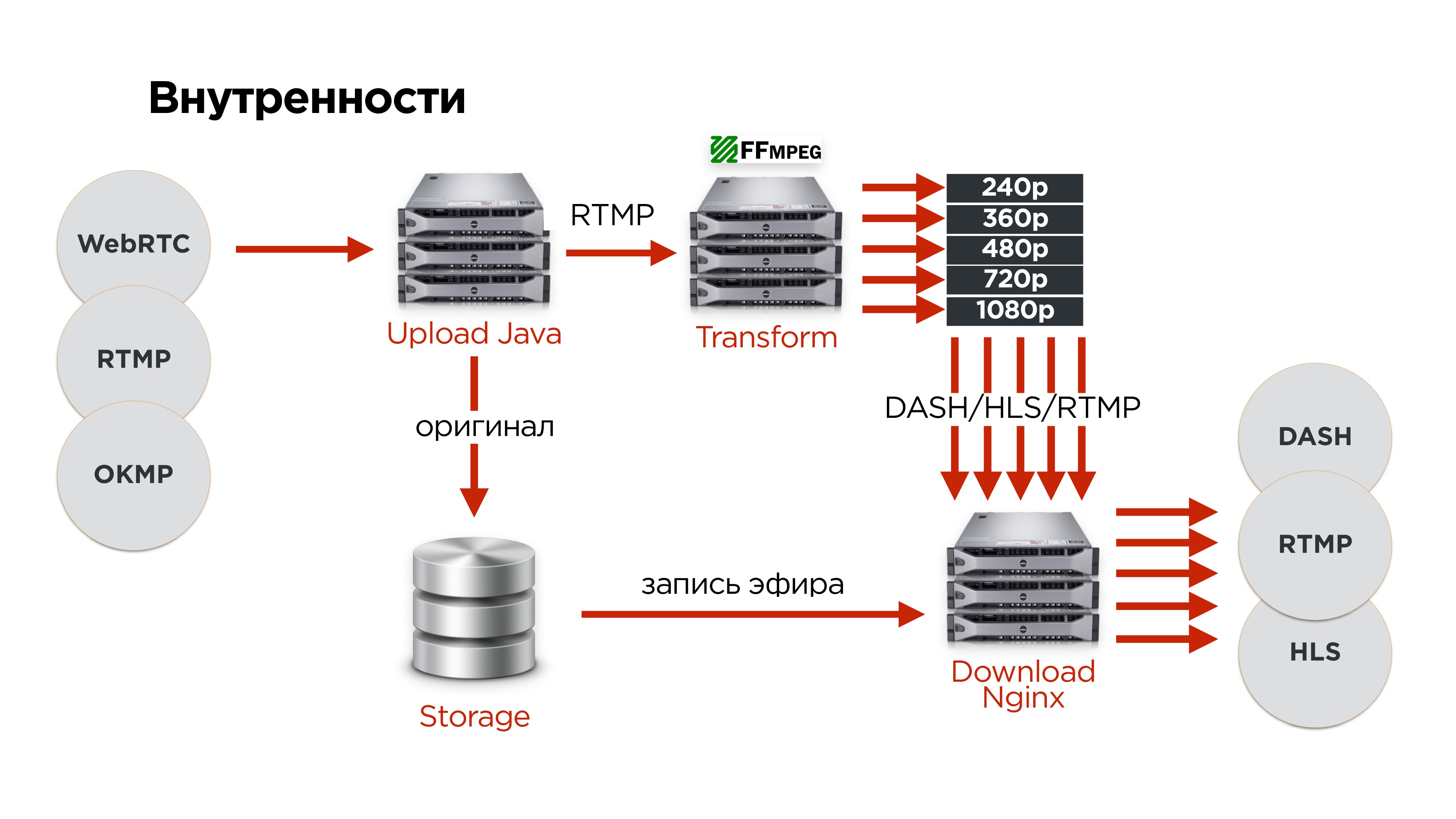
- Пользователи по
