Перформанс: что в имени тебе моём? — Алексей Шипилёв об оптимизации в крупных проектах
Оптимизация производительности издавна не дает покоя разработчикам, представляясь своеобразным «золотым ключиком» к интересным решениям и хорошему послужном списку. Большую обзорную экскурсию по ключевым вехам оптимизации больших проектов — от общих принципов до ловушек и противоречий — на прошедшем JPoint 2017 провел Алексей Шипилёв, эксперт по производительности.
Под катом — расшифровка его доклада.
А вот тут можно найти саму презентацию: jpoint-April2017-perf-keynote.pdf
О спикере
Алексей Шипилёв — в проблематике производительности Java более 10 лет. Сейчас работает в Red Hat, где разрабатывает OpenJDK и занимается его производительностью. Разрабатывает и поддерживает несколько подпроектов в OpenJDK, в том числе JMH, JOL и JCStress. До Red Hat работал над Apache Harmony в Intel, а затем перешел в Sun Microsystems, которая была поглощена Oracle. Активно участвует в экспертных группах и сообществах, работающих над вопросами производительности и многопоточности.
Я работаю в компании Red Hat. Раньше, когда я работал в Oracle, мы вставляли «Safe Harbor»-слайды, которые говорили, что все, что мы будем вам рассказывать, на самом деле может быть неправдой, поэтому нужно думать своей головой. Если вы пытаетесь внедрить какие-нибудь решения в свои продукты, неплохо было бы нанять профессионалов, которые вам скажут, что там правда, а что — нет.
Крупно: каковы критерии успеха в разработке
Предположим, вы разрабатываете продукт. Что для вас успешный продукт? Мы тут все — коммерческие программисты. Мы можем обманывать себя тем, что нам платят зарплату за то, что мы кодим. Но на самом деле нам платят зарплату для того, чтобы продавались либо сервисы, которые продукты обслуживают, либо продукты целиком.

Но какие существуют чисто разработческие критерии успешности продукта (без учета бизнес-цели)?
- Когда ты общаешься с программистами, они обычно говорят, что хороший (успешный) продукт — тот, у которого корректная реализация.
- Потом приходят безопасники и говорят: «Вы там, конечно, накодили, но неплохо было бы сделать так, чтобы там не было дырок. Потому что иначе мы-то продадим, но потом нас в суд потащат». Однако это тоже не главное.
- Главный критерий успешности проекта — это соответствие того, что получилось, желаниям пользователя. Конечно, если у нас есть хороший маркетинговый департамент, он может объяснить клиенту, что результат — это именно то, что он хочет. Но в большинстве случаев хочется, чтобы клиент сам это понял. Очень много программистов как бы на подкорке это имеют в виду, но очень мало людей это прямо вербализируют.
- Где-то на четвёртом месте — быстрота и удобство разработки. Это удобство и не сумасшествие программистов. Когда вы во время найма разговариваете с HR-ами, они будут обещать всякие плюшки, массаж и тому подобное, но на самом деле бизнесу всё равно, как вам там живётся, при условии, что вы всё ещё работаете и не собираетесь уходить. И что код написан условно хорошо, а не так, что вы хотите выброситься из окна или пойти работать в другую компанию.
- Производительность обычно стоит ещё ниже в списке приоритетов. Часто её даже нет в критериях успеха. Продукт хоть как-то шевелится, да и слава Богу.
Поэтому я удивляюсь, когда читаю на Хабре посты про производительность Java и вижу там подобные комментарии:

Эксперты говорят: «Ну, а что говорить по производительность Java? Она работает нормально. Нас устраивает, все хорошо». Но приходят комментаторы и отвечают: «Очень показательно, что никто из четырех экспертов не оценил Java, как быструю. Скорее, как достаточную и удовлетворяющую».
Вы говорите так, будто это плохо. Если с точки зрения бизнеса технология удовлетворяет бизнес-критериям, то и слава Богу! У меня нет идеалистических представлений о том, что всё должно быть вылизано, гладко, идеально. Так не бывает — обычно продукты содержат ошибки.
Корректная vs быстрая программа
Люди давно научились некоторому двойному мышлению по поводу корректности программ. (спрашивает в зал) Кто может честно сказать, что в его программах есть баги? (в зале много рук) Подавляющее большинство. Но все же считают, что их программы более-менее корректны. Понятие корректной программы обладает симметрией с понятием быстрой программы.

«Корректная программа» — это программа, в которой не видно бесящих пользователя ошибок. То есть ошибки там вообще-то есть, но они не заставляют пользователя отказаться от покупки продукта. С «быстрой программой» симметричная ситуация — в ней не то, чтобы нет перформансных проблем, просто эти проблемы не бьют пользователя по темечку каждый раз, когда он пытается что-то сделать.
«В критерии успеха вложились». Критерии успеха есть как функциональные, так и перформансные: хорошо, если программа отвечает за 100 миллисекунд. Отвечает? Отлично, едем дальше.
«Количество багов в корректной программе обычно известно». Это как раз одна из показательных метрик взрослости проекта, поскольку ноль багов в программе означает, что никто толком не заботится о том, чтобы их в багтрекере регистрировать (потому что у вас и пользователей нет, ха-ха!). С перформансными проблемами такая же история. Перформансные проблемы известны, и тогда мы говорим, что это «быстрая» программа. (делает воздушные кавычки)

Как в корректной, так и в быстрой программе пути обхода этих перформансных и функциональных багов известны. У вас есть FAQ, который говорит: «Если вы сделаете так, то будет больно; ну дак и не делайте так».
Стадии развития проектов — кривая им. Ш
Практически все проекты, где я участвовал в перформансной работе, проходят некоторые стандартные фазы развития. Когда-то я сформулировал, что эти фазы выглядят примерно так:
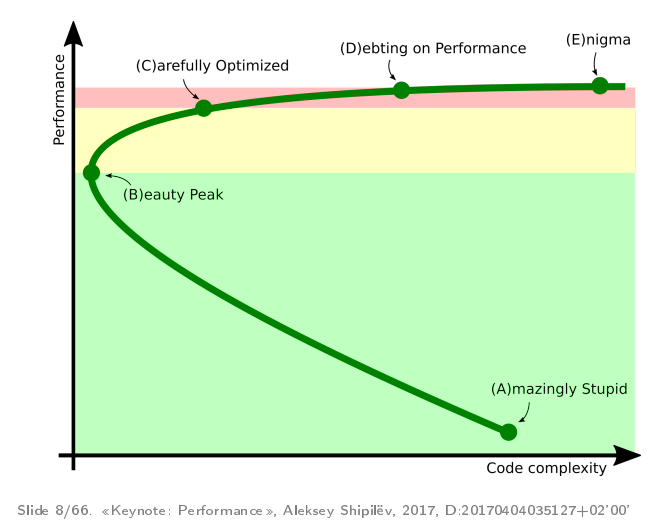
Это параметрический график: время тут течет от точки «A» до точки «B», «C», «D», «E». По оси ординат у нас производительность, по оси абсцисс — некоторая абстрактная сложность кода.
Обычно все начинается с того, что люди велосипедят прототип, который медленно, но работает. Он достаточно сложен, потому что мы навелосипедили просто так, чтобы он не разваливался под собственным весом.
После того как начинается оптимизация — потихонечку начинается переписывание разных частей. Находясь в этой зелёной зоне, разработчики обычно берут профайлеры и переписывают куски кода, которые написаны очевидно ужасно. Это одновременно снижает сложность кода (потому что вы выпиливаете плохие куски) и улучшает производительность.
В точке «B» проект достигает некоторого субъективного пика «красоты», когда у нас вроде и перформанс хороший, и в продукте все неплохо.
Далее, если разработчикам хочется ещё производительности, они переходят в жёлтую зону, когда берут более точный профайлер, пишут хорошие рабочие нагрузки и аккуратненько закручивают гайки. В этом процессе они там делают вещи, которые они бы не делали, если бы не производительность.
Если хочется ещё дальше, то проект приходит в некоторую красную зону, когда разработчики начинают корежить свой продукт, чтобы получить последние проценты производительности. Что делать в этой зоне — не очень понятно. Есть рецепт, по крайней мере, для этой конференции — идёте на JPoint/JokerConf/JBreak и пытаете разработчиков продуктов, как писать код, повторяющий кривизну нижних слоёв. Потому что, как правило, в красной зоне возникают штуки, которые повторяют проблемы, возникающие на нижних слоях.
Остальная часть доклада подробно рассказывает про то, что обычно происходит в этих зонах.
Зелёная зона
Мотивационная карточка зелёной зоны — это борьба с заусенцами в коде грубой силой:

Грубая сила означает, что не надо точных инструментов — просто берём и делаем. В зелёной зоне есть некоторые ментальные ловушки.
Моя любимая звучит так: «Профилировать нормально или никак»:

Я постоянно слышу: «Послушайте доклады Шипилева, он вам скажет, что профилировать нужно нормально или никак». Я ни разу этого не говорил. Когда вы в зелёной зоне, точность диагностики влияет очень мало. И, вообще говоря, профилировка вам нужна, чтобы понять, какую часть из того «микросервисного монолита», который вы умудрились написать, вам нужно переписать в первую очередь.
Профилирование и диагностика
Если вы посмотрите на блоги разных классных перформансных чуваков, например, Брендана Грегга, он будет показывать такие страшные диаграммы, говорить, что вот такими инструментами можно посмотреть туда-сюда:
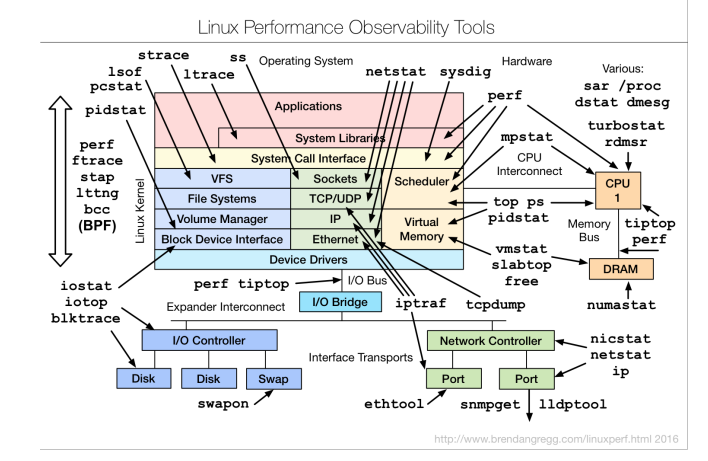
Многие говорят, когда смотрят на эти диаграммы: «Перформанс — это очень сложно, и мы не будем этим заниматься». Хотя на самом деле мысль Брендана не об этом. Она о том, что существуют достаточно простые способы быстро оценить, что в приложении происходит. Когда у нас есть хотя бы крупноклеточное понимание, нам гораздо лучше.
Поэтому диагностика в зелёной зоне опирается на очень простую мысль: мы не должны бояться смотреть на наше приложение. Даже крупноклеточное понимание, чего нам из ресурсов не хватает в нашем стеке, уже даст нам некоторую идею о том, на что стоит обращать внимание, а на что — нет. Даже если какую-нибудь полносистемную профилировку сделать, уже будет примерно понятно, где у вас bottleneck.

Профилирование
Наша цель в зелёной зоне — примерно понять, где мы проводим время.

Даже наивный профайлер, который вы можете собрать из палок и желудей, даст вам достаточно информации, чтобы совершать осознанные действия в зелёной зоне.
Если у вас есть продакшн, на который злые админы не дают устанавливать профайлер, можно просто через ssh взять jstack и сделать «while true; do jstack; sleep 1; done». Собрать тысячу этих jstack, агрегировать их. Это и будет «наколеночный» профайлер, который уже даст достаточно понимания, что в вашем продукте плохо.
Даже если вы руками расставите stopwatch-и в продукте и оцените, что в этой части продукта вы проводите 80% времени, а в этой — 20%, — это уже будет лучше, чем просто гадать на кофейной гуще о том, что будет, если мы в случайно попавшемся классе, написанном Васей в 2005 году, что-то поправим.
Измерение производительности
Следующая ментальная ловушка, связанная с профилированием, говорит, что производительность нужно измерять или нормально, или вообще никак.

Я про это постоянно слышу. Но в зелёной зоне улучшения «плюс-минус километр» обычно можно и глазками увидеть. Обычно это говорят в контексте «у вас плохой бенчмарк, он ничего не показывает, потому что он написан плохо, а нужно правильно мерить производительность», а в то же время у вас там грабля, которую видно практически на любом ворклоаде.
Мораль
Мораль очень простая: в зелёной зоне даже тривиальные нагрузочные тесты покажут вам крупные огрехи.

Я видел случаи, когда люди тратят недели на то, чтобы написать нагрузочные тесты на JMeter, вместо того, чтобы положить публичную ссылку в какой-нибудь Twitter и получить кучу народа, который придёт на бета-тестирование и повалит ваше приложение (а вам останется только сидеть с профайлером и смотреть, где же там упало). Даже обычный Apache Bench достаточно хорошо показывает крупные огрехи.
Чем раньше вы в разработке получите эти перформансные данные о крупных огрехах, тем быстрее вы сможете их исправить. Это вам тем более поможет планировать работы по производительности.
Пример-сюрприз
Я как-то недавно взял JDK 9 Early Access и подумал: надо бы попробовать построить мои проекты с ним, вдруг там что-то поменялось!

Я строю, а у меня время компиляции подрастает с 2 минут до 8. Внезапно. Нужно ли мне в такой ситуации писать какой-то аккуратный бенчмарк на это, доказывать, что это действительно регрессия?

Конечно, нет. У меня в билде есть конкретный баг, он воспроизводим. В профайлере можно обнаружить, что там есть call stack, который ведет в известное место в javac. В этом javac находишь исходный код, и там обнаруживается квадратичный цикл.
Нужно ли доказывать, что это проблема, когда у вас есть: а) ворклоад, на котором плохо; б) когда у вас есть профиль, который показывает туда, и в) теоретические размышления, что квадратичный цикл — это плохо? Нет, этого достаточно.
Оптимизация
Ещё одна ментальная ловушка: «Преждевременная оптимизация — корень всего зла».

Кнут, конечно, ещё жив и здравствует. Но я не знаю, насколько ему икается каждый раз, когда кто-то вспоминает эту фразу, потому что её обычно вспоминают неправильно. Кнут говорил о том, что преждевременная оптимизация — корень всего зла в 99,7% случаев, потому что люди не понимают, где им нужно оптимизировать. Когда вы в зелёной зоне, вам все равно. Вы все равно переписываете ваш прекрасный код. Профилировка вам нужна для того, чтобы определить, что переписывать в первую очередь.
Какие заходы там есть?
Как правило, улучшение производительности там в основном от переписывания «плохого» кода на «хороший». Но «плохой» и «хороший» — в какой-то степени субъективная вкусовщина. Спроси нескольких программистов: один скажет, что надо вот так, так красиво;, а другой скажет: «Что ты тут понаписал!». Все это, конечно, может быть вкусовщиной, но может быть и выстраданными приемами, в том числе выстраданными вами или Джошуа Блохом, который написал книжку «Effective Java».

Например, эффективные структуры данных. Я знаю проекты, в которых глобальный s/LinkedList/ArrayList/g улучшил производительность без всяких раздумий над. Есть случаи, когда LinkedList быстрее, но эти случаи очень специальные, и их обычно видно невооруженным взглядом.
Можно внезапно обнаружить, что у вас линейный поиск по ArrayList в месте, где можно использовать HashMap. Или у вас итерация по паре keySet и get, который можно поменять на entrySet, или навелосипедили свой bubbleSort и вдруг внезапно оказалось, что туда приходят коллекции по миллиону элементов, и вы там проводите кучу времени, и так далее.
Подитог зелёной зоны

Профилирование — необходимая часть ежедневной разработки.
По-моим наблюдениям, 95% перформансных проблем решается на первых же заходах профилировки. Вне зависимости от того, какой сложности проект, какие бы опытные люди его ни разрабатывали, когда ты показываешь людям первую профилировку их проекта, у них возникает гамма эмоций, в частности, «какие же мы идиоты». Потому что более 90% этих проблем тривиально разрешимы и по идее должны были быть пойманы ещё до коммита.
Если вы — техлид, архитектор, технический директор или занимаете какую-то другую руководящую техническую должность и хотите производительности, то, пожалуйста, сделайте так, чтобы в проекте были четкие инструкции по запуску профилировщиков. Если у вас есть однострочник, или однокнопочник, или у вас есть веб-приложение, у которого есть APM, — то очень хорошо! У девелопера всегда должен быть способ быстро это сделать.
По моему опыту, если вы возьмёте девелопера за руку, каким бы «senior» он ни был, сядете с ними и один раз попрофилируете ваш продукт, это уверенно купирует у него боязнь перформансной работы. У многих людей в голове есть такой блочок о том, что производительность — это сложно, что там есть всякие взаимосвязи между компонентами и прочее. И они не профилируют вообще, потому что сложно — значит, пока не надо. Но когда один раз садишься и проделываешь это с ними, у них снимается этот блок, они начинают профилировать самостоятельно. И те 90% ошибок, которые они могут разрешить до того, как к ним кто-нибудь придет, будет показывать профиль и стыдить их, они исправят заранее.
Причем «возьмите девелопера за руку» — это не значит, что вы загоняете их на конференцию, сажаете их в зал на 1000 человек, выходит докладчик и начинает там в профайлере что-то с умным видом возить. Так не работает. Работает по-другому: вы садитесь с конкретным девелопером на вашем проекте и делаете это на пару.
Жёлтая зона
Жёлтая зона — это усложнение кода в обмен на производительность, когда вы делаете вещи, которые вы бы не делали, если бы вам не хотелось больше производительности.

Ментальные ловушки там тоже есть.
Профилирование и диагностика
Первая ментальная ловушка: «Сейчас мы возьмем профайлер, посмотрим, что где, и как начнем оптимизировать».

Оказывается, в жёлтой зоне цена ошибки возросла: вы теперь производительность получаете, а что-то взамен этого теряете — поддерживаемость, сон разработчиков и так далее. Поэтому вам нужно вносить правильные изменения, которые требуют продвинутой диагностики, и профилировка — это только одна из частей диагностики. Ещё есть бенчмаркинг и прочее.
Обычно, когда люди впиливаются в жёлтую зону и начинают думать, что же оптимизировать, они открывают профайлер и видят это:
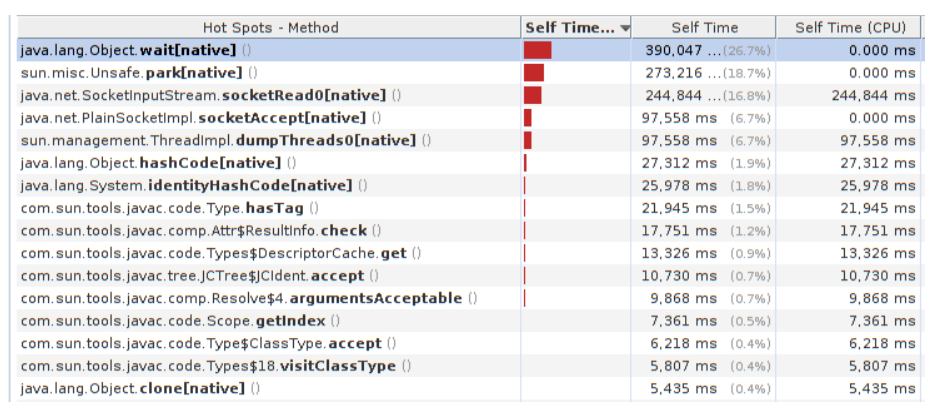
И что мы здесь будем оптимизировать? Перепишем на java.nio или скажем, что самый горячий метод — это java.lang.Object.wait, значит, надо разгонять его. Или там Unsafe.park, значит, нужно разгонять его… или SocketInputStream.socketRead0, или socketAccept — значит, нужно срочно переписывать всё на Netty, потому что сеть же видно. Правда, вся эта фигня из JMX, но об этом мы узнаем потом, через 3 месяца разработки. Или там Object.hashCode — скажем, что плохой HotSpot его не оптимизировал, а «вы нам обещали, что всё будет быстро и хорошо, а наш продукт не виноват».
Modus operandi в жёлтой зоне простой: оптимизируя, вы теперь должны будете объяснять, зачем вы это делаете. Может себе, а может и вашему project manager-у.
При этом желательно иметь иметь на руках:
- численные оценки прироста,
- и желательно иметь их до того, как вы потратили все ресурсы. А не тогда, когда три месяца разработки прошло, и вы сказали: «Ой, вы знаете, задача заняла три месяца, классно».
- Надо иметь понимание, что это самый дешёвый способ, и что этот способ — тот самый, который даст вам улучшение общей производительности.
Закон Амдала
Когда людям задаешь задачи на оценку производительности, неискушенные начинают жутко фейлить, потому что людям очень сложно в голове уложить нелинейные зависимости. Одна из таких нелинейных зависимостей — закон Амдала, и к нему приходят обычно следующим образом.
Предположим, у нас есть приложение. У него есть две независимые части: А и В. И мы, например, знаем, что часть А занимает 70% времени и разгоняется в 2 раза, а часть В занимает 30% времени и разгоняется в 6 раз. Можно разогнать только одну из них — ресурсов хватает только на это. Какую из этих систем мы будем разгонять? Если мы даже просто графически их уменьшим, видно:

Часть А работает на 70% общего времени. Лучше оптимизировать часть А, несмотря на то, что мы разгоняем её всего в 2 раза. Влияние на общий перформанс больше.
А если бы я был отдельно стоящим программистом, я бы, наверное, разгонял часть В в 6 раз. В моем недельном отчете эта цифра будет выглядеть гораздо лучше: «Вася разогнал в два раза, а я разогнал в шесть раз, поэтому мне нужно в три раза повысить зарплату».
Закон Амдала выводится следующим образом:
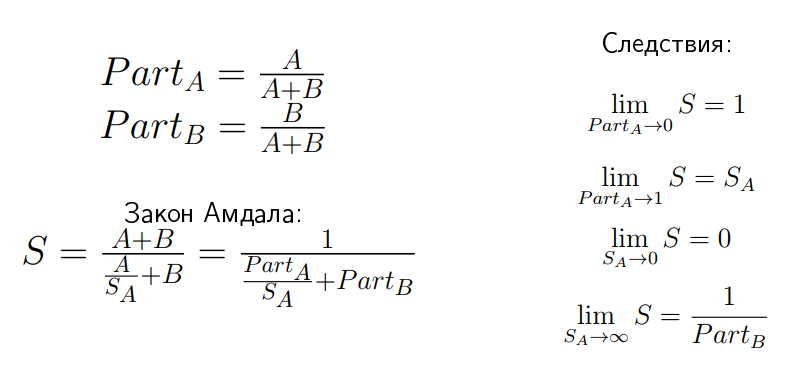
Если у нас есть speedup S, то он по определению — общее время A плюс B, деленное на новое время. Часть B там осталась той же самой, поэтому там «плюс B», а часть А уменьшилась в SA раз. Если мы введем два обозначения: PartA и PartB, которые показывают относительное время частей A и B в этом приложении, то придём к такому выражению:
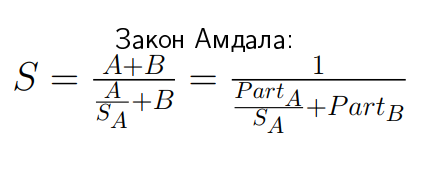
У этого соотношения есть забавные свойства. Например, если вы SA устремите в бесконечность, то предел S:

Это не очевидная штука, её нужно несколько раз почувствовать на своей шкуре, чтобы понять. Вам будут показывать через такие вот графики:
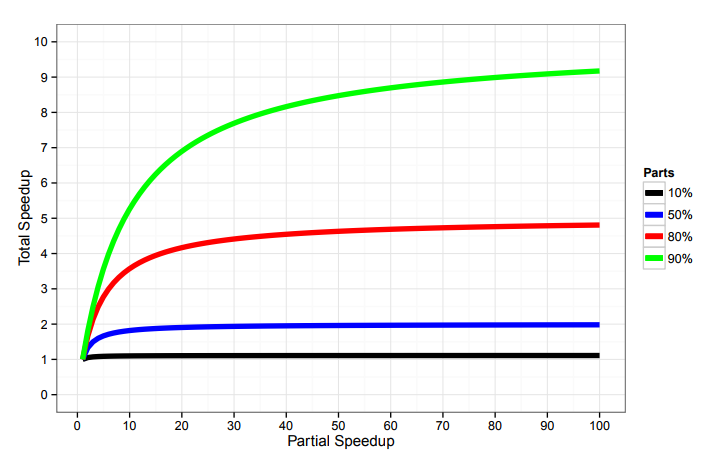
… и говорить: если у вас есть приложение, в котором 80% занимает та часть, которая разгоняется, то разгоните её хоть до опупения, но speedup больше, чем в 5 раз, вы не получите.
Это означает, что если к вам приходит вендор базы данных и говорит: мы знаем, что в вашем ворклоаде 50% занимает база данных. Мы вам гарантируем, если вы поменяете ваш текущий солюшн на наш, не изменяя ни строчки кода, то ваш перформанс вырастет в 10 раз. Что вы должны ему на это сказать? (из аудитории) Bull shit!
Едем дальше: есть обобщение закона Амдала. Если мы немножко перевернем эти члены и введем два новых обозначения: p — это speedup A — это то, во сколько мы разогнали конкретную часть А, а альфа — это сколько всего остального есть, то этот закон можно записать вот в такой форме:

Штука в том, что у этих членов появляется некоторый физический смысл. Первый член обычно называется concurrency. Если мы пока проигнорируем второй член — contention — выражение будет означать: во сколько раз мы ускорили часть A, во столько же у нас получился общий speedup. Contention описывает влияние на производительность всего остального, обеспечивающего эту самую асимптоту в законе Амдала. Кстати, если графики этой функции начертить, получатся те же самые кривые, как в законе Амдала:

Однако, как правило, в большинстве приложений закон Амдала в такой форме не действует. Действует более сложный закон, когда туда добавляется ещё один член, который называется coherence, описывающий взаимодействие между компонентами.
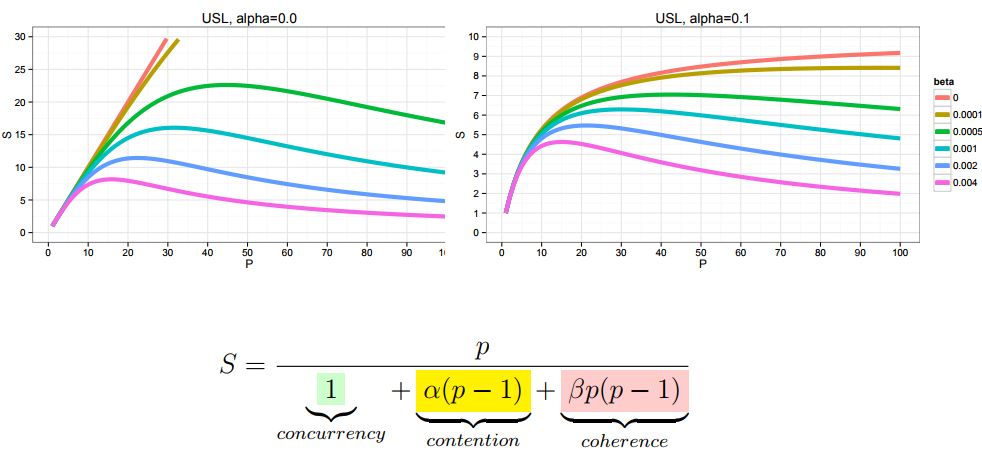
Оказывается, если альфа и бета неотрицательные, то у вас нет асимптоты насыщения. У вас есть какой-то пик эффективности, а после этого производительность начинает падать. Многие люди, которые занимаются перформансом, на своей шкуре чувствовали этот закон, пока его не сформулировали как Universal Scalability Law (USL):

Понятия «universal» и «law» здесь использованы в естественно-научном смысле, то есть у него есть как бы теоретическое обоснование, но он не выведен аналитически. Он выведен как закон, который хорошо натягивается на эмпирические данные.
Систем с альфа и бета, равными нулю, не существует, потому есть много случаев, когда вы добавляете ресурсы в систему или что-то оптимизируете, и становится хуже. Например, вы сняли один bottleneck, но уперлись в другой, более тяжелый.
Измерение производительности
Ментальная ловушка с измерением производительности говорит: «Поскольку там всё сложно, а мы не знаем, как все повлияет на производительность, мы просто находим что-то и смотрим, что нам скажут бенчмарки».

На самом деле перформансное тестирование — дико дорогое, и всё особенно не протестируешь. Перформансные тесты от функциональных отличаются тем, что функциональные (например, юнит-тесты) проходят за 100 миллисекунд или меньше, даже если они пачкой исполняются. С перформансными тестами не всё так гладко. Там тесты проходят от минуты и выше, могут проходить часами. Это означает, что одно изменение может быть протестировано за сотни машинных часов. Если вы делаете кучу коммитов в день, то вам требуется очень большой парк оборудования, чтобы вообще хоть как-то обеспечить проход через тестовую систему.
Перформансные тесты требуют изоляции, иначе они начинают говорить всякую ересь, потому что начинают взаимодействовать друг с другом.
Перформансные тесты, как правило, дают небинарные метрики. Функциональные тесты обычно говорят «PASS» или «FAIL» — бинарные метрики, а перформансные тесты говорят… »67». Хуже того: они говорят не »67», а »67 плюс минус 5». Это кроме всего прочего означает, что ошибки тестирования находятся только после разбора данных, когда вы понимаете, что у вас везде очень всё красиво, а вот здесь, в тёмном углу — данные, которые показывают, что эксперимент был палёный. Это означает, что все остальные данные тоже нужно выбросить и снова потратить сотни машинных часов на новый цикл.
И самое плохое, что бенчмарки вам дают данные-числа, а хочется-то вам результатов — какого-нибудь знания, которое можно достать из этих чисел. И если получение данных хорошо автоматизируется, то часть про извлечение смысла из этих данных, как правило, автоматизируется плохо, поскольку она требует человеческого понимания, что там и как может происходить.
Вывод — в активном проекте практически невозможно протестировать всё. Это означает, что у вас всё равно должны быть в голове некоторые оценки и умение разбираться, куда же копать, не прогоняя все бенчмарки на каждый чих.
Классификация бенчмарков
Многие люди делят бенчмарки на два больших класса: на макробенчмарки и микробенчмарки.

В макробенчмарках, как следует из приставки «макро», мы берём наш большой сайт, приложение или библиотеку целиком, пишем end-to-end тесты и смотрим, сколько же потребовалось времени одному виртуальному юзеру, чтобы купить наши бесконечно ценные товары в интернет-магазине. Нормальный тест.
Микробенчмарки — это маленькие рабочие нагрузки, когда мы берём маленькую часть нашего сайта или библиотеки, делаем маленький изолированный тест и замеряем конкретную часть.
Голоса в голове у разработчика обычно шепчут ему, что макробенчмарк отражает реальный мир, а микробенчмарки — зло.
Смотрите: реальный мир — большой, и макробенчмарк — большой. (заговорщицки) Стало быть, макробенчмарк отражает реальный мир. Поэтому некоторым кажется, что любой макробенчмарк — хороший. Дескать, запустил макробенчмарк — это real world и есть. Это означает, что для любой крутой фичи макробенчмарк даст крутое улучшение, потому что он же «real world». А если макробенчмарк не показывает улучшения, то эта фича плохая. И что для любого крутого бага макробенчмарк даст крутую регрессию, а если нет регрессии, то и бага нет. Это же «real-world», значит, то, что происходит в реальном мире, должно быть и в макробенчмарке.
С микробенчмарками — обратная ситуация. Голоса в голове разработчика подсказывают, что они зло, поэтому их можно игнорировать. Они говорят тебе, что показания микробенчмарка не важны, потому что его можно писать каким угодно, а, значит, регрессия или улучшение на нём ничего не значат. А когда они сталкиваются с реальным миром, приходит мысль, что микробенчмарки пишут враги, чтобы опорочить их продукт. Потому что написать их просто, можно написать какой угодно, значит, можно написать микробенчмарк, благодаря которому мы потом в white paper-е напишем, что наш продукт стал лучше, т.к. на таком ворклоаде он работает лучше.
Жизненный цикл бенчмарков
Если отбросить этот маркетинговый bull shit про микробенчмарки, окажется, что жизненный цикл все бенчмарки проходят примерно одинаково.

Если у вас есть большой бенчмарк — гигабайты кода, в которых дофига библиотек, кода и т.п., обычно он начинается с «невинной» стадии, когда он действительно тестирует многие части вашего продукта, ходит через многие слои и так далее. Допустим, они там занимают примерно одинаковое время. Но потом приходят злые девелоперы и начинают оптимизировать.
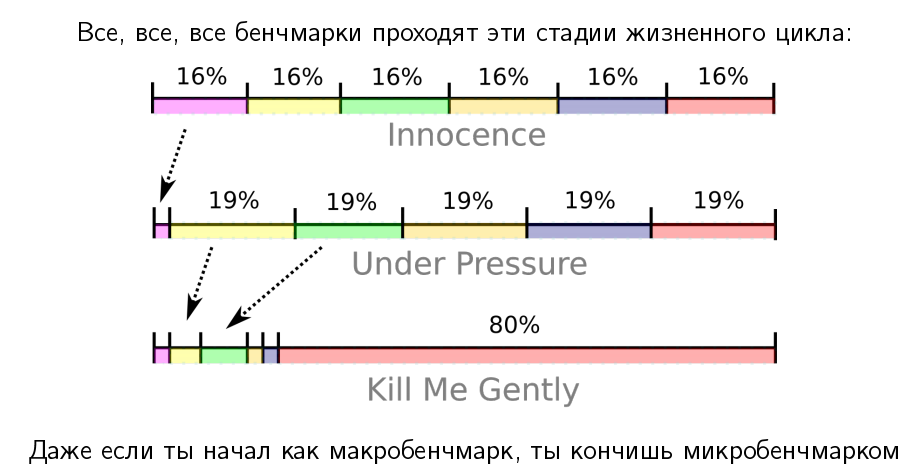
Мы начали с макробенчмарка, который покрывает многие части приложения, но в конце жизненного цикла его производительность утыкается в один большой bottleneck, который нам очень сложно разрешить. И это практически случай микробенчмарка, когда у нас есть изолированный тест, который тестирует одну вещь. Такой выродившийся макробенчмарк тоже тестирует только одну вещь.
Но все же в этом есть некоторые плюсы. Неочевидный плюс следует из закона Амдала.

Возьмем приложение с двумя частями — красной и зелёной, которая оптимизируется. Даже если мы оптимизируем зелёную часть до 0, мы все равно получим speedup всего лишь в два раза. Но если красная часть будет регрессировать (если мы, допустим, в 2 раза её регрессируем), окажется, что закон Амдала, у которого есть асимптота, превратится в линейную зависимость.
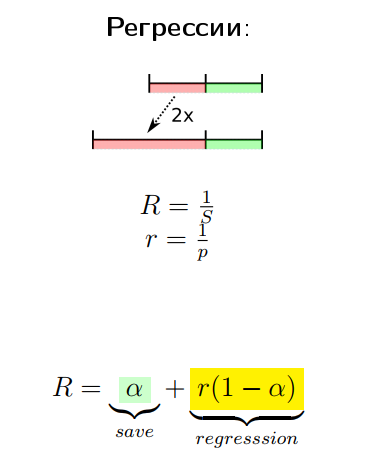
Иными словами, если мы регрессировали маленькую часть в тысячу раз, итоговая метрика тоже в существенное количество раз уменьшится.
Можно на графике это показать следующим образом:

По оси абсцисс у нас speedup конкретной части, а по оси ординат — speedup продукта целиком. В части, где у нас что-то улучшается, у нас есть асимптоты из закона Амдала, а там, где всё ухудшается, у нас практически линейная зависимость.
Проблема с тестированием стоит ещё в том, что эмпирическое перформансное тестирование — шумное. В экспериментах есть систематические и случайные ошибки.

Часто чувствительность теста вам просто может не показать улучшение от конкретного изменения. Если что-то улучшилось в 50 раз, то улучшение в общей системе будет ниже порога чувствительности теста, а если это же регрессировало в 50 раз, будет гораздо лучше видно. Это, кстати, ответ на вопрос, почему, когда вы занимаетесь производительностью, большая часть вещей, которые вы видите в своих автоматических репортах, — это регрессия. Потому что, как правило, тестирование более чувствительно к регрессии, а не к улучшению.
По моим наблюдениям:
Макробенчмарки:
- их мало, они написаны непонятно кем и непонятно как;
- сначала показывают интересные результаты, а потом вырождаются в микробенчмарки;
- в конце жизни всё равно применимы для регрессионного тестирования.
Т.е. сделать перформансное улучшение на макробенчмарках — это душераздирающая история.
Микробенчмарки:
- их тоже много, они тоже написаны непонятно как и непонятно кем, но зато они настолько маленькие, что их можно одним разумом охватить и исправить: понять, что там неправильно, и как-нибудь их модифицировать;
- на всех этапах жизненного цикла они показывают интересные результаты;
- хорошо реагируют и на регрессию, и на улучшение.
Поэтому если мы, к примеру, делаем перформансную оптимизацию, у нас всегда есть корпус микробенчмарков (очень чувствительных ворклоадов), на которых мы делаем изменения и выжимаем максимум. Только потом мы валидируем, что они не регрессировали и улучшили макробенчмарк.
Как вы ни крутитесь, а учиться микробенчмаркать вам придется. Самая интересная мысль состоит в том, что метод «просто возьми какой-нибудь удачный фреймворк и перепиши все ворклоады на нем» не работает, потому что недостаточно просто написать код бенчмарка и получить цифры. Чтобы понять, что происходит, нужно в эти цифры вглядеться, может быть, построить побочные эксперименты, грамотно их провести и проанализировать данные, а потом сделать выводы и построить так называемую перформансную модель — понять, как же ваше приложение или ваш стек реагирует на изменения в коде, конфигурации и так далее. Это вам даст возможность предсказать, что же будет происходить в будущем.
Оптимизация
Обычно, правда, происходит не так. Обычно люди падают в следующую ментальную ловушку:

«Мы попробовали, и оно улучшило метрики — стало не 100 операций в секунду, a 110. Наверное, потому что…» и дальше следует сс
