Отказоустойчивая обработка 10M OAuth-токенов на Tarantool

Многие уже наслышаны о производительности СУБД Tarantool, её возможностях и особенностях. Например, у него есть классное дисковое хранилище — Vinyl, кроме того, он умеет работать с JSON-документами. Но в многочисленных публикациях обходят стороной одну важную особенность. Обычно БД рассматривают просто как хранилище, но всё же отличительная черта Tarantool — это возможность писать код внутри и очень эффективно работать с этими данными. Под катом рассказ, как мы строили одну систему почти полностью внутри Tarantool, написанный в соавторстве с Игорем igorcoding Латкиным.
Все вы сталкивались с Почтой Mail.Ru и, наверное, знаете, что в ней можно настроить сбор писем из других почтовых ящиков. Для этого нам не нужно просить у пользователя логин и пароль от стороннего сервиса, если поддерживается протокол OAuth. В этом случае для доступа используются OAuth–токены. Кроме того, в Mail.Ru Group есть множество других проектов, которым также нужна авторизация через сторонние сервисы, и которым необходимо выдавать OAuth–токены пользователей для работы с тем или иным приложением. Разработкой такого сервиса по хранению и обновлению токенов мы и занимались.
Наверное, все знают, что представляет собой OAuth–токен. Напомним, чаще всего это структура из трёх-четырёх полей:
{
"token_type" : "bearer",
"access_token" : "XXXXXX",
"refresh_token" : "YYYYYY",
"expires_in" : 3600
} - access_token, с помощью которого вы можете осуществлять действие, получить информацию о пользователе, скачать список его друзей и так далее;
- refresh_token, с помощью которого вы можете получать новый
access_token, причём сколько угодно; - expires_in — временная отметка либо окончания срока действия токена, либо иное заранее заданное время. Если вы придёте с access-токеном с истёкшим сроком действия, у вас не будет доступа к ресурсу.
Рассмотрим теперь приблизительную архитектуру сервиса. Представим, что есть некоторые фронтенды, которые просто кладут в наш сервис токены и читают их, и есть отдельная сущность, называемая рефрешерами. Задача рефрешера — ходить в OAuth-провайдер за новым access_token примерно в тот момент, когда закончится его срок действия.

Структура базы тоже довольно проста. У нас есть два узла БД (master и slave реплики). Вертикальная черта представляет собой условное разделение дата-центров. В одном дата-центре стоит master со своим фронтендом и рефрешером, а в другом — slave со своим фронтендом и рефрешером, который ходит в master.
Какие возникают сложности?
Основная проблема заключается во времени (один час), в течение которого живёт токен. Если посмотреть на проект, то возникает мысль: «Разве это highload-масштабы — 10 млн записей, которые надо рефрешить в течение часа? Если поделить одно на другое, посмотреть, мы получаем RPS порядка 3000». Проблемы начинаются в тот момент, когда что-то перестаёт рефрешиться, например, какой-нибудь maintenance базы, или она упала, или упала машина — всякое случается. Дело в том, что если наш сервис, мастер-база, по какой-то причине не работает 15 минут — мы получаем 25% outage, т.е. четверть наших данных не валидна, не обновлена, ею нельзя пользоваться. Если сервис лежит 30 минут, то без обновления уже половина данных. Час — нет ни одного действующего токена. Предположим, база лежала час, мы её подняли, и нужно все 10 млн токенов очень быстро обновить. А это уже не 3000 RPS, это вполне себе высоконагруженный сервис.
Надо сказать, что изначально все нормально обрабатывалось, но спустя два года после запуска мы добавили разной логики, дополнительные индексы, стали добавлять вторичную логику — в общем, у Tarantool кончился процессор. Это было неожиданно, но ведь любой ресурс можно израсходовать.
В первый раз нам помогли админы. Поставили самый мощный процессор, который нашли, это позволило нам расти ещё полгода, но за это время надо было как-то решить проблему. Нам попался на глаза новый Tarantool (система была написана на старом Tarantool 1.5, который за пределами Mail.Ru Group практически не встречается). В Tarantool 1.6 на тот момент уже была master-master репликация. И первое, что пришло в голову: давайте поставим в три дата-центра по копии БД, между ними запустим master-master репликацию, и всё будет прекрасно.
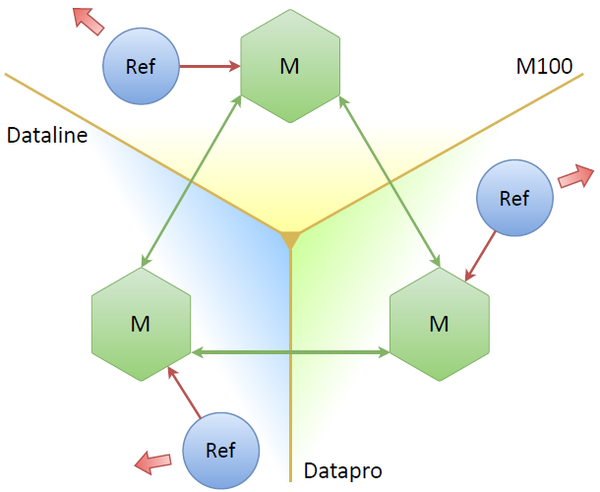
Три мастера, три дата-центра, три рефрешера, каждый работает со своим мастером. Можем уронить один или два, вроде бы всё будет работать. Но какие здесь потенциальные проблемы? Основная проблема, заключается в том, что мы в три раза увеличиваем количество запросов на OAuth-провайдер. Мы рефрешим практически одни и те же токены, причём столько раз, сколько у нас реплик. Это совсем не дело. Очевидное решение: сами ноды должны каким-то образом решать, кто из них будет в данный момент лидером (т.е. вести рефреш токенов лишь с одной реплики).
Выбор лидера
Существует несколько консенсус-алгоритмов. Первый из них — Paxos. Довольно сложная штука. Нам не удалось нормально разобраться, как на его основе сделать что-то простое. В итоге мы остановились на Raft. Это очень простой консенсус-алгоритм, в котором происходит выбор лидера, с которым мы можем работать, пока не будет выбран новый лидер при разрыве соединения или по другим обстоятельствам. Вот так мы это сделали:

В Tarantool из коробки нет ни Raft, ни Paxos. Но мы берем готовый модуль, который есть в поставке, — net.box. Этот модуль позволяет нам соединять узлы между собой по схеме full mesh: каждая нода подключается ко всем остальным. А дальше всё просто: мы поверх этих подключений реализуем выбор лидера, который описан в Raft. После этого каждая нода начинает обладать свойством: она либо лидер, либо фолловер, либо не видит ни лидера, ни фолловера.
Если вы думаете, что реализовать Raft сложно, вот пример кода на Lua:
local r = self.pool.call(self.FUNC.request_vote, self.term, self.uuid)
self._vote_count = self:count_votes(r)
if self._vote_count > self._nodes_count / 2 then
log.info("[raft-srv] node %d won elections", self.id)
self:_set_state(self.S.LEADER)
self:_set_leader({ id=self.id, uuid=self.uuid })
self._vote_count = 0
self:stop_election_timer()
self:start_heartbeater()
else
log.info("[raft-srv] node %d lost elections", self.id)
self:_set_state(self.S.IDLE)
self:_set_leader(msgpack.NULL)
self._vote_count = 0
self:start_election_timer()
endЗдесь мы делаем запросы к удалённым серверам, на другие реплики Tarantool, подсчитываем количество голосов, которые мы получили с ноды. Если набрался кворум, за нас проголосовали, мы становимся лидером и начинаем heart-beat — оповещаем остальные ноды о том, что мы живы. Если мы проиграли выборы, то инициируем их вновь. Через некоторое мы сможем проголосовать или быть выбранными.
После получения кворума и определения лидера, мы можем направить наши рефрешеры во все ноды, но при этом сказать им работать только с лидером.
Таким образом мы получаем нормальный трафик. Так как задания раздаёт одна нода, на каждый рефрешер уйдёт где-то одна треть.Только здесь мы можем спокойно потерять любого из мастеров — случатся перевыборы, рефрешеры переключатся на другую ноду. Но, как и в любой распределённой системе, с кворумом возникают проблемы.
«Заброшенная» нода
Если потерялась связность между дата-центрами, то нужен механизм, который заставляет систему продолжать жить, а также механизм, который должен восстановить целостность системы. Эту проблему решает Raft.
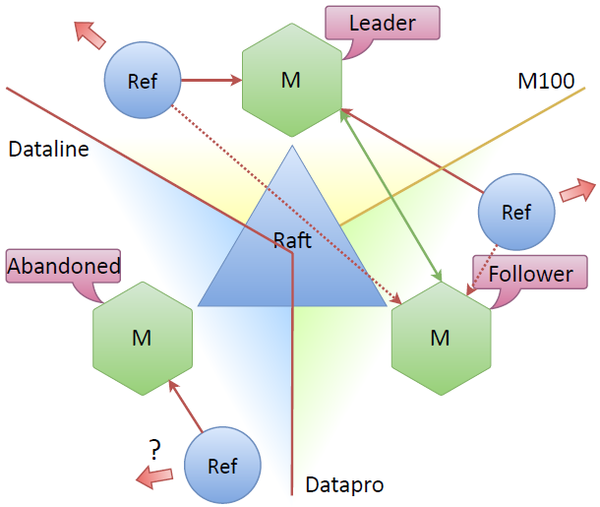
Допустим, ушёл дата-центр Dataline. Получается, что стоявшая там нода становится «заброшенной» — она не видит других узлов. Остальная часть кластера видит, что нода потерялась, происходят перевыборы, лидером становится новый узел в кластере, скажем, верхний. И система продолжает работать, потому что между нодами по-прежнему сохранялся консенсус, т.к. больше половины нод видят друг друга.
Основной вопрос: что происходит с рефрешером, который находится в ушедшем дата-центре при потере связности? В спецификации Raft нет отдельного названия для такого узла. Обычно нода, не имеющая кворума и связи с лидером, бездействует. Но ведь он всё ещё может ходить в сеть, самостоятельно обновлять токены. Обычно токены обновляются в режиме связности, но может быть можно обновлять токены рефрешером, который подключен к «заброшенной» ноде? Вначале было непонятно, есть ли смысл обновлять токены? Не будет ли излишних операций обновления?
Этим вопросом мы занялись в процессе реализации системы. Первая мысль — у нас же консенсус, кворум, и если мы потеряли кого-то из кворума, то обновлений не выполняем. Но потом появилась другая идея. Посмотрим на реализацию master-master в Tarantool. Предположим, в определённый момент существует две ноды, обе master. Есть переменная, ключ Х, значение которого 1. Допустим, в одно и то же время, пока репликация не дошла до этой ноды, мы одновременно изменяем этот ключ на два разных значения: в одной ноде ставим 2, в другой — 3. Далее ноды обмениваются репликационными логами, то есть значениями. С точки зрения консистентности, такая реализация master-master — это какой-то ужас, да простят меня разработчики Tarantool.
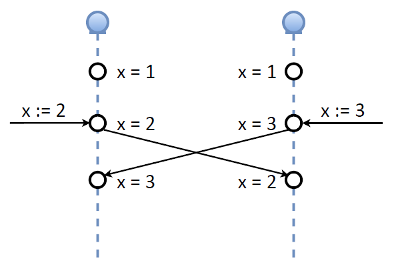
Если нам нужна строгая консистентность — это не работает. Однако, вспомним наш OAuth-токен, который состоит из двух важных частей:
- refresh-токена, который, условно, живёт бесконечно,
- и access-токена — живёт один час.
Но при этом наш рефрешер несёт функцию refresh, которая из refresh-токена всегда может получить любое количество access-токенов. И все они будут действовать в течение часа с момента выдачи.
Рассмотрим схему: две ноды нормально работали с лидером, обновили токены, получили первый access-токен. Он отреплицировался, теперь этот access-токен есть у всех. Случился разрыв, фолловер стал «заброшенной» нодой, у него нет кворума, он не видит ни лидера, ни других фолловеров. При этом мы разрешаем нашему рефрешеру обновлять токены, которые живут на «заброшенной» ноде. Если там не будет сети, схема работать не будет. Но если это простой сплит — сеть порвалась, — то ничего страшного, эта часть будет работать автономно.
После того, как разрыв связи закончится и нода присоединится, то либо пройдут перевыборы, либо произойдёт обмен данными. При этом второй и третий токен — одинаково «хорошие».
После воссоединения кластера очередная процедура обновления выполнится только на одной ноде, и она реплицируется. То есть на какое-то время наш кластер разделяется, и каждый обновляет по-своему, а после воссоединения мы возвращаемся к нормальным консистентным данным. Это даёт нам следующее: обычно для работы кластера нужно N/2 + 1 активных узлов (в случае трёх нод — это два). В нашем же случае для работы системы достаточно хотя бы одного активного узла. Наружу будет идти ровно столько запросов, сколько нужно.
Мы говорили про проблему увеличения количества запросов. На время сплита или даунтайма, мы можем себе позволить, чтобы жила хотя бы одна нода. Мы будем её обновлять, будем складывать данные. Если это предельный сплит, то есть разделены все ноды и у всех есть сеть, то мы получим то самое утроение количества запросов на OAuth-провайдера. Но благодаря кратковременности события — это не страшно, и мы не предполагаем постоянно работать в режиме разделения. Обычно система находится в кворуме, связности, и вообще все ноды работают.
Шардинг
Осталась одна проблема — мы упёрлись в потолок по CPU. Очевидное решение: шардинг.

Допустим, есть два шарда — базы данных, каждая из них реплицируется. Есть некая функция, которой на вход приходит какой-то ключ, по этому ключу мы можем определить, в каком шарде лежат данные. Если мы шардируемся по e-mail, то часть адресов хранится в одном шарде, часть — в другом, и мы всегда знаем, где лежат наши данные.
Существует два подхода к реализации шардинга. Первый — клиентский. Выбираем функцию консистентного хеширования, возвращающую номер, шарда, например, CRC32 ключа, Guava, Sumbur. Эта функция одинаковым образом реализуется на всех клиентах. У этого подхода есть несомненное преимущество: БД вообще ничего не знает про шардинг. Вы подняли базу, она стандартно работает, а шардинг где-то сбоку.
Но есть и серьезный недостаток. Во-первых, клиенты довольно толстые. Если вы хотите сделать новый, то нужно добавить в него логику шардинга. Но самая страшная проблема в том, что одни клиенты могут работать по одной схеме, а другие — по другой. При этом сама база ничего не знает о том, что вы по-разному шардитесь.
Мы выбрали другой подход — шардинг внутри базы данных. В этом случае её код становится сложнее, но зато мы можем использовать простые клиенты. Любой клиент, подключающийся к этой базе, идёт в любую ноду, там выполняется функция, которая вычисляет, с какой нодой нужно связаться, и какой передать управление. Клиенты проще — база сложнее, но при этом она полностью отвечает за свои данные. К тому же самое сложное — это решардинг. Когда база отвечает за свои данные, решардинг делать намного проще, чем когда у вас есть клиенты, которых вы ещё и не можете обновить.
Как мы это сделали?
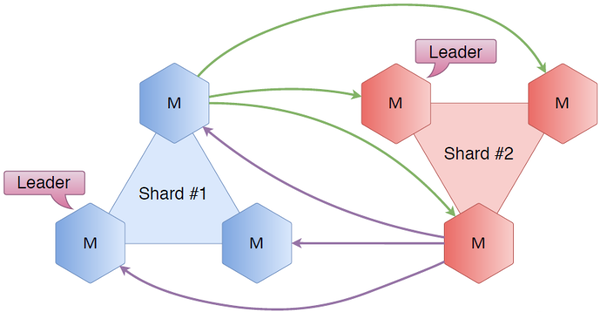
Шестиугольники — это Tarantool«ы. Возьмём тройку нод, назовём шардом номер один. Поставим точно такой же кластер и назовём шардом номер два. Соединим все ноды друг с другом. Что это дает? Во-первых, у нас есть Raft, где внутри тройки серверов мы знаем, кто лидер, кто фолловер, каково состояние кластера. Благодаря новым связям шардинга мы теперь знаем состояние чужого шарда. Мы прекрасно знаем, кто является лидером во втором шарде, кто является фолловером, и так далее. В общем случае, мы всегда знаем, куда перенаправить пришедшего на первый шард пользователя, если ему нужен не первый шард.
Рассмотрим простые примеры.
Допустим, пользователь запрашивает какой-то ключ, который лежит на первом шарде. Он приходит в узел из первого шарда. Т.к. он знает, кто является лидером, запрос перенаправляется в лидера, тот в свою очередь, получает или пишет ключ, и ответ затем возвращается пользователю.
Допустим теперь, что пользователь приходит в ту же ноду, и ему нужен ключ, который лежит на самом деле на втором шарде. То же самое: первый шард знает, кто является лидером во втором, идёт в эту ноду, получает или пишет данные, возвращает пользователю.
Очень простая схема, но с ней есть сложности. Основная проблема: не слишком ли много соединений? В схеме, когда каждая нода соединена с каждой, получается 6×5 — 30 соединений. Ставим ещё один шард — получаем уже 72 соединения в кластере. Многовато.
Мы решаем эту проблему так: просто ставим парочку Tarantool«ов, только называем их уже не шардами или базами, а прокси, которые будут заниматься исключительно шардированием: вычислять ключ, выяснять, кто является лидером в том или ином шарде, а сами Raft-кластеры останутся замкнутыми в себе и будут работать только внутри самого шарда. Когда клиент приходит на прокси, она вычисляет — какой шард ему нужен, и, если ему нужен лидер, — перенаправляем на лидера. Если неважно кто — перенаправляем на любую ноду из этого шарда.

Сложность получается линейной, зависящей от количества узлов. Если у нас будет три шарда по три узлам в каждом, то мы получим в разы меньше соединений.
Схема с прокси рассчитана на дальнейшее масштабирование, когда шардов становится больше двух. При двух шардах мы имеем одинаковое количество соединений, но с ростом количества шардов мы заметно экономим на соединениях. Список шардов хранится в конфиге Lua, и чтобы получить новый список, просто перезагружаем код, и всё работает.
Итак, мы начали с master-master, реализовали Raft, прикрутили к нему шардинг, потом прокси, переписали всё это. Получился кирпичик, кластер. Наша схема стала выглядеть довольно просто.
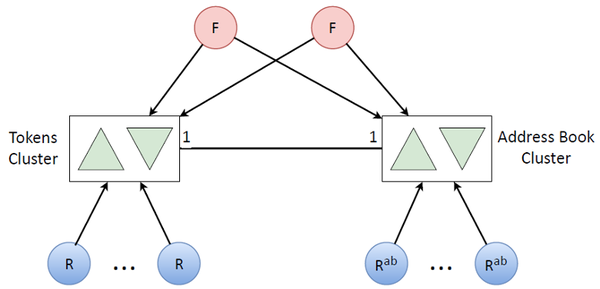
Остаются наши фронтенды, которые только кладут или забирают токены. Есть рефрешеры, которые обновляют токены, забирают refresh-токен, отдают в OAuth-провайдер, кладут новый access-токен.
Мы говорили, что у нас есть ещё вторичная логика, из-за которой кончились ресурсы процессора. Давайте перенесём её на другой кластер.
К такой вторичной логике в основном относятся адресные книги. Если есть токен пользователя, то ему соответствует адресная книга этого пользователя. И данных по количеству там столько же, сколько и токенов. Чтобы не исчерпать ресурсы процессора на одной машине, нужен, очевидно, такой же кластер, опять реплицироваться и так далее. Мы ставим ещё пачку других рефрешеров для обновления уже адресных книг (это более редкая задача, поэтому мы не обновляем адресные книги вместе с токенами).
В итоге, объединив два таких кластера, мы получили такую достаточно простую архитектуру всей системы:
Очередь обновления токенов
Зачем мы городили свою очередь? Можно же было взять что-то стандартное. Дело в нашей модели обновления токенов. После получения токен живёт один час. Когда подходит время окончания его действия, он должен быть обновлён. Это дедлайн-очередь: токен должен быть обновлён до определённого времени.

Предположим, случился outage, кратковременный или нет, но у нас есть некоторый объём токенов с истёкшим сроком действия. Если мы будем их обновлять, то устареет ещё какое-то количество. Мы, конечно, всё догоним, но лучше было бы сначала обновить те, что вот-вот умрут (через 60 сек), а потом с оставшимися ресурсами обновлять те, которые всё равно уже умерли. В последнюю очередь мы обновляем более дальний горизонт (5 минут до смерти).
Чтобы реализовать такую логику на чём-то стороннем, придётся попотеть. В случае с Tarantool это реализуется очень просто. Рассмотрим простенькую схему: есть tuple, где лежат данные Tarantool, у него есть какой-то идентификатор ID, по которому есть первичный ключ. И чтобы сделать очередь, которая нам нужна, мы просто добавляем два поля: статус и время. Статус обозначает состояние токена в очереди, время — то самое expire time, или какое-нибудь другое.
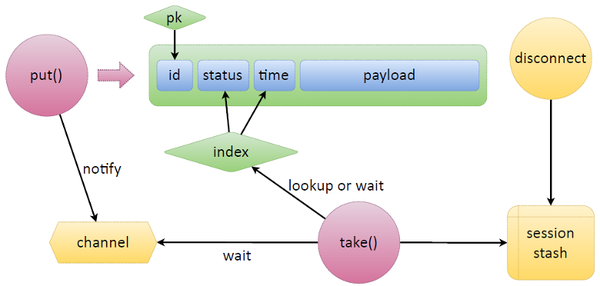
Возьмём две основные функции из очереди — put и take. Задача put — принести и положить данные. Нам дают какую-то полезную нагрузку, put сам выставляет статус, время и кладёт данные. Появляется новый tuple.
Приходит take, смотрит на индекс. Создаёт итератор, начинает в него смотреть. Выбирает ждущие задачи (ready), проверяет, пришло ли время их брать, или они устарели. Если задач нет, take переходит в режим ожидания. Помимо встроенного Lua в Tarantool есть ещё примитивы синхронизации между файберами — каналы. Любой файбер может создать канал и сказать: «Я здесь жду». Любой другой файбер может этот канал разбудить и передать в него сообщения.
Функция, которая чего-то ждёт — освобождения задач, прихода времени или ещё чего-то, — создаёт канал, особым образом его маркирует, помещает куда-то, и дальше ждёт на нём. Если нам принесут токен, который нужно срочно обновить, допустим, put, то он отправит notify в этот канал.
У Tarantool есть одна особенность: если какой-то токен случайно зарелизится, его кто-то взял take«ом на refresh или просто берёт задачу, то можно отслеживать обрывы соединений клиентов. Мы запоминаем в session stash, какому соединению какую задачу выдали. Мы ассоциируем, что с этой сессией были связаны такие-то задачи. Предположим, процесс refresh падает, просто рвётся сеть — мы не знаем, обновит он токен или нет, сможет он его положить обратно или нет. У нас срабатывает дисконнект, который находит в сессии все задачи и автоматически их высвобождает. При этом высвобожденная задача через тот же канал может передать задачу другому put, он её быстро возьмёт и обработает.
За этой схемой кроется не очень много кода, на самом деле:
function put(data)
local t = box.space.queue:auto_increment({
'r', --[[ status ]]
util.time(), --[[ time ]]
data --[[ any payload ]]
})
return t
end
function take(timeout)
local start_time = util.time()
local q_ind = box.space.tokens.index.queue
local _,t
while true do
local it = util.iter(q_ind, {'r'}, { iterator = box.index.GE })
_,t = it()
if t and t[F.tokens.status] ~= 't' then
break
end
local left = (start_time + timeout) - util.time()
if left <= 0 then return end
t = q:wait(left)
if t then break end
end
t = q:taken(t)
return t
end
function queue:taken(task)
local sid = box.session.id()
if self._consumers[sid] == nil then
self._consumers[sid] = {}
end
local k = task[self.f_id]
local t = self:set_status(k, 't')
self._consumers[sid][k] = { util.time(), box.session.peer(sid), t }
self._taken[k] = sid
return t
end
function on_disconnect()
local sid = box.session.id
local now = util.time()
if self._consumers[sid] then
local consumers = self._consumers[sid]
for k,rec in pairs(consumers) do
time, peer, task = unpack(rec)
local v = box.space[self.space].index[self.index_primary]:get({k})
if v and v[self.f_status] == 't' then
v = self:release(v[self.f_id])
end
end
self._consumers[sid] = nil
end
endPut просто кладёт в space данные, которые пользователь захотел положить в очередь, указывает статус и текущее время, если это простая FIFO-очередь, по которой будет индекс, и возвращает задачу.
С take чуть посложнее, но тоже просто: заводим итератор и ждём появления новой задачи. Функция taken просто помечает задачу взятой, но самое главное — она запоминает, кто что взял. На on_disconnect мы можем высвободить все задачи, взятые конкретным пользователем, конкретное соединение.
Возможны ли альтернативы?
Конечно. Мы могли взять любую БД. При этом нам всё равно пришлось бы построить очередь для логики работы с внешней системой, с обновлениями, и так далее. Мы не можем просто обновлять токены по запросу, у нас тогда будет непрогнозируемая нагрузка. Нам всё равно нужно поддерживать систему живой, но тогда мы бы клали отложенные задачи в очередь. Нам нужно было бы следить за консистентностью (наличие записей в базе и в очереди). Нам всё равно пришлось бы сделать отказоустойчивую очередь с кворумом. К тому же, если мы помещаем одновременно данные и в память, и в очередь, которая, скорее всего, при наших нагрузках понадобилась бы in memory, то мы бы потребляли больше ресурсов.
А в нашем случае БД одновременно и хранит токены, и за логику очереди мы заплатили двумя байтами, плюс ещё пятью. Итого — плюс 7 байт на tuple, и есть логика очереди. В любом другом варианте очереди мы бы потратили намного больше, вплоть до двукратного увеличения потребления памяти.
Подведём итог
Для начала мы решили нашу проблему с outage, она возникала регулярно. Внедрение вышеописанной системы позволило избавиться от этой неприятности.
Мы получили возможность горизонтально масштабироваться за счёт шардинга. Снизили количество соединений с N2 до линейной зависимости, попутно улучшили логику очереди под нашу бизнес-задачу: обновляем то, что мы ещё можем обновить в случае каких-то задержек. Они возникают не только по нашей вине: те же Google, Microsoft, и другие сервисы могут что-то выкатить у себя на OAuth-провайдере, и у нас возникает куча необновлённых токенов.
Делайте расчёты в БД непосредственно рядом с данными, это очень удобно, производительно, масштабируемо и гибко. И вообще Tarantool прикольный. Спасибо.
