Организация хранения исторических данных в Oracle
Привет! Сегодня поговорим о разных способах организации хранения исторических данных в Oracle. Если вам известно более двух способов, то вы молодец и уже почти всё знаете, в чём вам и остаётся убедиться, просмотрев разделы статьи.

Под историческими данными будем понимать историю (лог) изменения данных в таблице.
Потребность логировать данные может возникнуть по разным причинам. Например,
И какие бы причины у вас ни были, можно выделить 4 основных подхода. Вообще, их больше, но мы рассмотрим наиболее применимые (с точки зрения адекватности).
Простой триггер DML
Подход, с которого начинают многие. Как его использовать для логирования, описано даже в 2 Day Developer’s Guide от Oracle.
Синтаксис
CREATE [OR REPLACE] TRIGGER <имя_триггера>
{BEFORE | AFTER}
{INSERT | DELETE | UPDATE | UPDATE OF <список_столбцов> }
ON <имя_таблицы>
[FOR EACH ROW]
[WHEN (...)]
[DECLARE ... ]
BEGIN
<исполняемый код>
[EXCEPTION ... ]
END <имя_триггера>;DML-триггер — это именованный PL/SQL-блок кода, который хранится в базе данных и вызывается по событию и по времени срабатывания. Событием запуска может быть вставка, удаление или обновление данных, также можно выбрать, когда будет вызываться триггер: до или после изменения.
Внутри триггера обязательно нужно указать код, который должен выполняться.
Достоинства
Недостатки
Снижение производительности при больших объёмах изменяемых данных.
Нужно поддерживать таблицу логов и триггер при изменении структуры таблицы.
Если вас беспокоит первый недостаток простого DML-триггера, можно использовать его более оптимизированный вариант — составной DML-триггер.
Составной DML-триггер
Синтаксис
CREATE [ OR REPLACE ] TRIGGER <имя_триггера>
-- событие запуска
FOR {INSERT | DELETE | UPDATE |
UPDATE OF <список_столбцов>}
ON <имя_таблицы>
[DECLARE ... ]
-- Выполняется один раз перед выполнением DML-выражения
BEFORE STATEMENT IS
BEGIN
<исполняемый код>;
END BEFORE STATEMENT;
-- Выполняется один раз для каждой строки перед самим действием
BEFORE EACH ROW IS
BEGIN
<исполняемый код>;
END EACH ROW;
-- Выполняется один раз для каждой строки после действия- :NEW, :OLD доступны
AFTER EACH ROW IS
BEGIN
<исполняемый код>;
END AFTER EACH ROW;
--Выполняется один раз для всего DML-выражения
AFTER STATEMENT IS
BEGIN
<исполняемый код>;
END AFTER STATEMENT;
END <имя_триггера>;При создании составного триггера нужно указать событие запуска (вставка, обновление или удаление записей), а также определить действия для каждой из четырех временных точек: перед и после выполнения команды DML, перед и после обработки каждой строки.
Достоинства
Недостатки
Как и в предыдущем варианте, нужно поддерживать таблицу логов и триггер при изменении структуры таблицы.
Слишком много логики в триггере.
Если перечисленные недостатки для вас являются весомыми (или у вас есть другие причины не использовать составной DML-триггер), можно использовать ручное логирование.
Ручное логирование
Этот подход более гибок. Итоговая производительность зависит от фантазии разработчика.
Так, можно сделать логирование, которое по скорости не обгоняет логирование через обычный триггер. Например, много раз вставлять в таблицу логов по одной строке. А можно реализовать логирование так, что оно обгонит по скорости составной триггер. Например, собирать данные пачками в коллекцию и вставлять в таблицу логов через команду forall.
Достоинства
Недостатки
Нужно поддерживать API и таблицу логов.
Merge-боль. Это когда вам нужно залогировать то, что происходит в
merge, а нельзя (т.к. не поддерживается командаreturning). И поэтому нужно развернутьmergeдо атомарных операций, таких какinsert,update,delete. Но есть приятная новость — в 23-й версии дляmergeбудет работать конмандаreturning, иmergeуже не нужно будет разворачивать. Остаётся немного подождать.
Если есть причины не использовать перечисленные выше подходы, то можно использовать другой способ логирования — flashback archive. Это более современный метод, его рекомендуют некоторые широко известные в узких кругах специалисты, такие как К. Макдональд и Т. Кайт.
Flashback archive (архив ретроспективных данных)
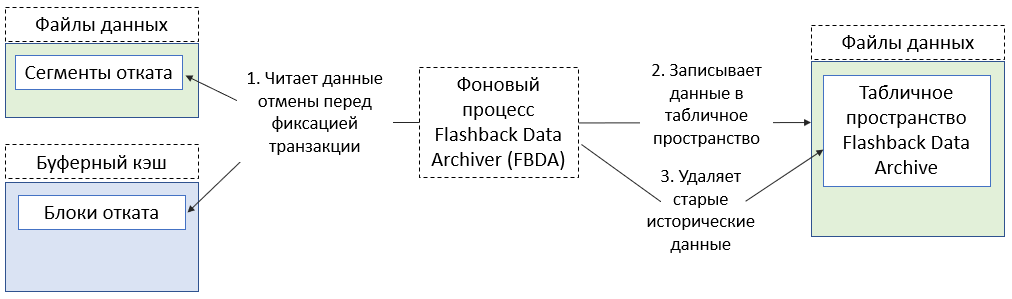
Фоновый процесс Flashback Data Archiver Process (FBDA) позволяет отслеживать и сохранять транзакционные изменения в таблице в течение всего срока ее службы. После 11g Release 2 (11.2.0.4) Flashback Archive доступен во всех редакциях бесплатно.
Перед коммитом транзакции на отслеживаемой таблице FBDA проверяет наличие новых сгенерированных UNDO-блоков, соответствующих этой таблице, и копирует информацию во внутренние секционированные таблицы.
Синтаксис
-- выдать права на создание архива
GRANT FLASHBACK ARCHIVE ADMINISTER TO <пользователь_dba>;
...
-- создать архив
CREATE FLASHBACK ARCHIVE [DEFAULT] <имя_архива>
TABLESPACE <имя_табличного_пространства>
[QUOTA <лимит_объёма_данных> { M | G | T | P | E }]
[ [NO] OPTIMIZE DATA ]
RETENTION <срок_хранения> {YEAR | MONTH | DAY};
...
-- выдать права на использование архива
GRANT FLASHBACK ARCHIVE ON <имя_архива> TO <пользователь>;
...
-- включить архив для таблицы
ALTER TABLE <имя_таблицы> FLASHBACK ARCHIVE <имя_архива>;
...
-- просмотр истории
SELECT
<столбцы>
FROM
<имя_таблицы>
{ VERSIONS BETWEEN { SCN | TIMESTAMP }
{ expr | MINVALUE } AND { expr | MAXVALUE }
| VERSIONS PERIOD FOR valid_time_column BETWEEN
{ expr | MINVALUE } AND { expr | MAXVALUE }
| AS OF { SCN | TIMESTAMP } expr
| AS OF PERIOD FOR valid_time_column expr
}Эта технология даёт возможность ничего не делать — Oracle всё сделает за вас (ну, почти всё).
Преимущества
Автоматические создание и очистка архивных таблиц.
Выгрузка истории.
Сжатие данных (платная опция OPTIMIZE DATA в Oracle Advanced Compression).
Oracle сам соберёт данные о пользователе и выполняемой программе из контекста.
Можно объединять логируемые таблицы в группы (и включать-выключать логирование на группах).
Недостатки
Ограничения на ddl-операции (см. General Guidelines for Oracle Flashback Technology). Например, если вам нужно сделать exchange partition, нужно «приостанавливать» логирование, а потом включать его обратно (иначе получим ошибку ORA-55610: Invalid DDL Statement On History-tracked Table).
Долгий поиск по логам при использовании сортировки. Но можно поэкспериментировать с оптимизацией и ускорить.
Скорость логирования
Можно посмотреть на скорость работы перечисленных методов относительно друг друга.
Произведём некоторые замеры времени вставки строк с использованием разных подходов к логированию. Замеры времени произведём через dbms_sql_monitor. Вставки будем делать пачками по 1000 и 100 000 строк.

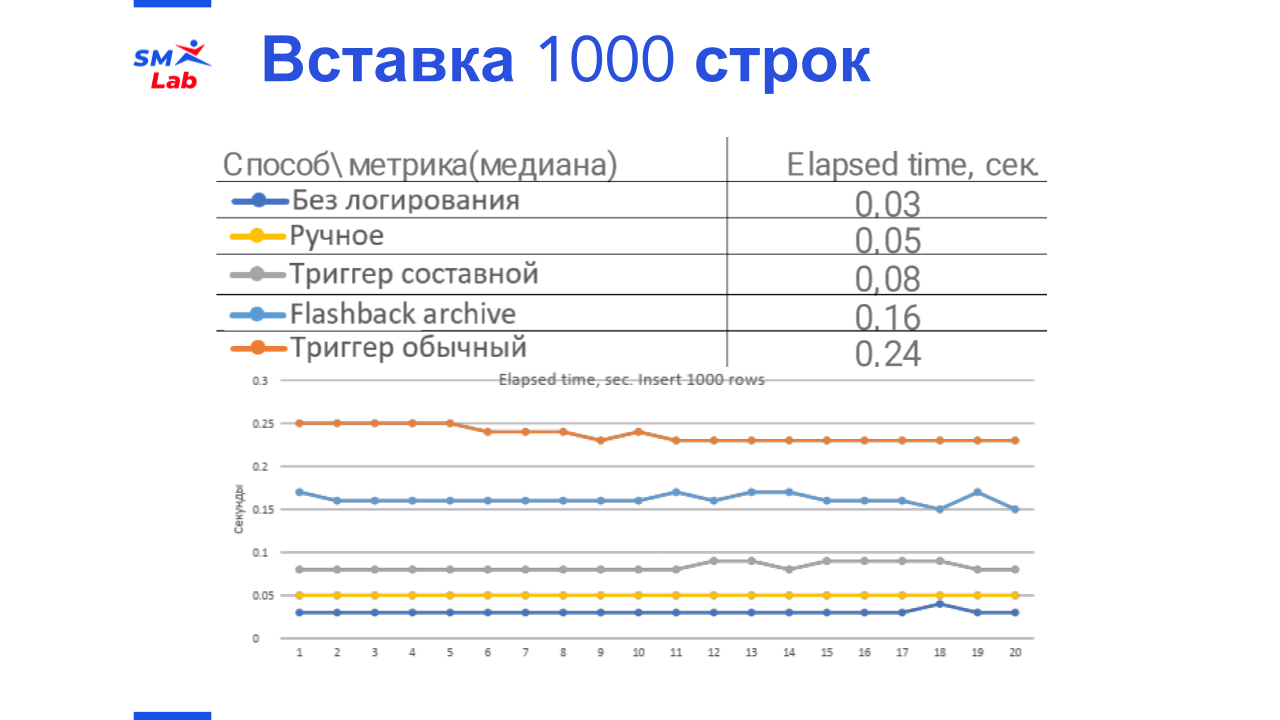
Вставка 1000 строк
На вставке небольшого количества строк самым быстрым оказалось ручное логирование, составной триггер чуть медленнее. Эти два метода будут конкурировать в зависимости от реализации.
Еще медленнее flashback-архив, а обычный триггер оказался самым медленным. Стоит отметить, что все подходы отрабатывают в пределах четверти секунды.
Вставка 100 000
Увеличивая объем данных, мы замечаем большой разбег у методов. Медленнее всех оказался flashback archive, ручное логирование по-прежнему конкурирует с составным триггером.
Выводы и рекомендации
Нет одинаково хорошего решения для всех случаев.
Если не знаете, что выбрать, можно воспользоваться следующими рекомендациями.
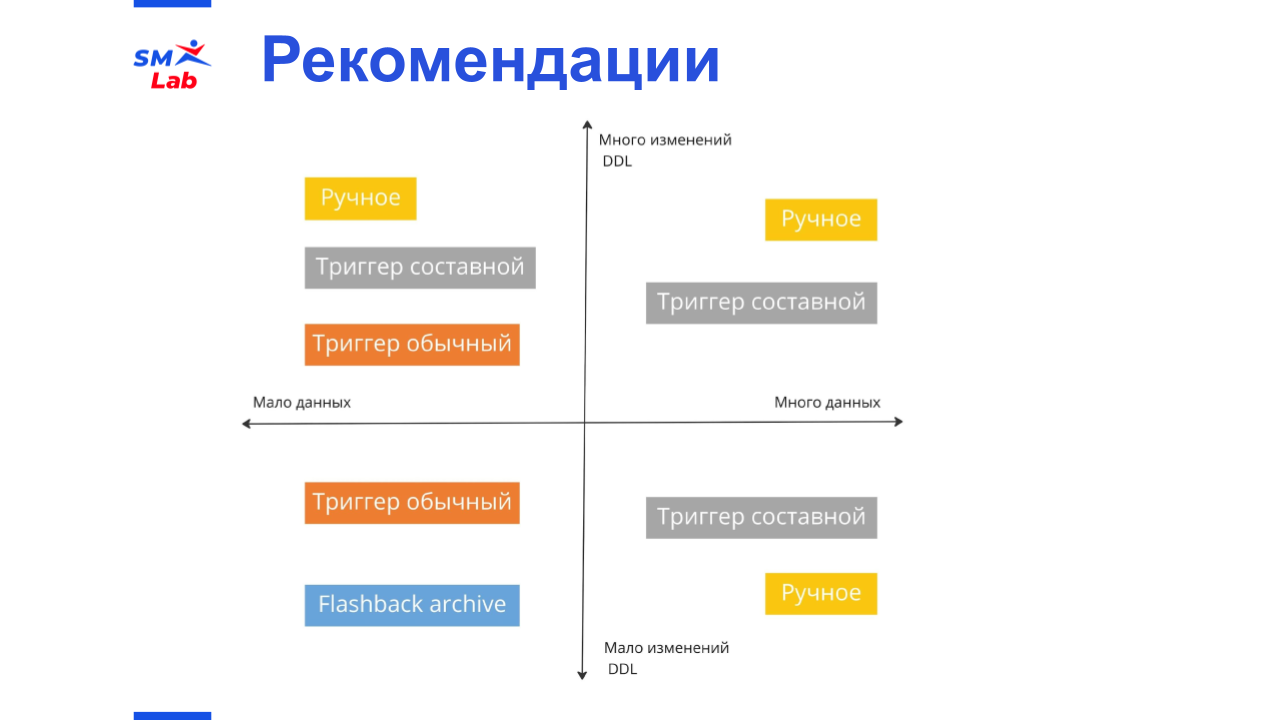
Рекомендации по выбору способа логирования
Если у вас мало данных и мало изменений, то стоит обратить внимание на обычный триггер и flashback-архив.
Ручное логирование вы можете использовать везде, но нужно следить за вызовами.
Составной триггер лучше использовать, если в данных происходит много изменений, и вы по каким-то причинам не можете использовать ручное логирование.
