Онтоинженер: от сотворения мира к порождению сущностей
 В этом посте я продолжу рассказ о той части Compreno, которая связана с профессией онтоинженера. Ну или о той работе онтоинженера, которая связана с упомянутой технологией — это уж кому как удобнее воспринимать.Напомню, первая часть подвела нас к тому, что онтоинженеры строят онтологии, чтобы технология могла работать (без них — никуда, так уж всё устроено). А о том, что ещё, и, конечно, зачем делают онтоинженеры, я предлагаю узнать прямо сейчас.
В этом посте я продолжу рассказ о той части Compreno, которая связана с профессией онтоинженера. Ну или о той работе онтоинженера, которая связана с упомянутой технологией — это уж кому как удобнее воспринимать.Напомню, первая часть подвела нас к тому, что онтоинженеры строят онтологии, чтобы технология могла работать (без них — никуда, так уж всё устроено). А о том, что ещё, и, конечно, зачем делают онтоинженеры, я предлагаю узнать прямо сейчас.
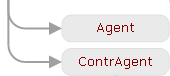
Семь битв — одно поддеревоОсновную часть рабочего времени онтоинженер посвящает не «моделированию мира» (хотя это и звучит очень гордо), а созданию системы извлечения. И хотя мы всё больше экспериментируем со статистикой, машинным обучением и автоматическим извлечением паттернов, пока в наших продуктах и проектах используются правила, написанные вручную. Однако правила эти представляют собой не какие-то жесткие шаблоны, опирающиеся на линейный порядок слов в предложении, а описания фрагментов семантико-синтаксических деревьев ABBYY Compreno. Это позволяет нам сравнительно легко обходить вариативность и неоднозначность языка, кратко задавая множество вариантов, используемых для выражения одного и того же смысла. Простой пример: если мы попросим найти такое поддерево, в котором есть узел-вершина с семантическим классом «CONFLICT_INTERACTION» (достаточно высокий класс нашей иерархии, от которого наследуются все понятия, связанные с противоборством, конфликтами, противостояниями и соревновательной активностью), под которым есть дочерний узел с глубинной позицией Agent (активно действующий участник ситуации) и ContrAgent (специальная глубинная позиция «контрагента»), то будут обнаружены самые разные примеры противоборств:
656 до н. э. — Битва при Туллизе — битва эламитов с ассирийцами474 до н. э. — Битва при Кумах — победа сиракузян под предводительством Гиерона I над этрусками2 февраля — День разгрома советскими войсками немецко-фашистских войск в Сталинградской битвеНа 1 октября первоначально был запланирован бой Поветкина с американцем Томми КоннелиРяд цареубийств ознаменовал собою начало борьбы дворянства с королямиХудожник В.П. Верещагин написал картину «Бой Добрыни со Змеем Горынычем» для дворца великого князя Владимира АлександровичаВ течение почти трёх десятилетий боролся немногочисленный отряд стрельцов с иноплеменникамиКак поссорился Иван Иванович с Иваном Никифоровичемфранцузский посол в Турции стал употреблять все усилия, чтобы поссорить Россию с ТурциейВ 1983 году дело дошло до уличных столкновений панков с полициейв конфликте Медведева с Кудриным Путин «непублично, судя по всему, стал на сторону министра финансовДва раза разбили они сибирских татар, на Туре и в устье ТавдыМужественно, как и тысячи других граждан, сражались шосткинцы с гитлеровскими захватчиками на фронтах Великой Отечественной войны, в партизанских отрядахС 1989 года начинается бескомпромиссное соперничество Граф с югославской теннисисткой Моникой СелешПищевыми конкурентами ягуарунди являются другие кошачьи, особенно длиннохвостые кошки и оцелоты, однако эта кошка избегает прямой конкуренции с ними благодаря дневному образу жизни; конкурируют они также с лисами, койотами, рыжими рысями и пумами

 Дальше мы можем вводить много других условий. Например, легко ограничить семантические классы участников и потребовать, чтобы там был класс «HUMAN» — тогда останутся только примеры вроде Ивана Ивановича с Иваном Никифоровичем, а ссора России с Турцией найдена не будет. Кроме того, можно вводить условия на различные грамматические характеристики (время, число, залог), позиции в поверхностном синтаксисе, семантические свойства — тысячи их. А теперь подробнее о том, как мы ищем такие поддеревья и что еще можно спросить у Compreno.
Дальше мы можем вводить много других условий. Например, легко ограничить семантические классы участников и потребовать, чтобы там был класс «HUMAN» — тогда останутся только примеры вроде Ивана Ивановича с Иваном Никифоровичем, а ссора России с Турцией найдена не будет. Кроме того, можно вводить условия на различные грамматические характеристики (время, число, залог), позиции в поверхностном синтаксисе, семантические свойства — тысячи их. А теперь подробнее о том, как мы ищем такие поддеревья и что еще можно спросить у Compreno.
Шаблоны на поддеревья задаются с помощью продукционных правил. Эти правила состоят из классических «если — то» продукций, в которых левая и правая часть разделяются с помощью оператора =>. В левой части мы записываем условие, задающее некоторое множество поддеревьев. В правой — утверждения о существовании информационных объектов (т.е. сущностей и фактов), их отношениях и привязке к тексту (т.е. к некоторым узлам деревьев). В древесных шаблонах левой части используются стандартные логические связки (конъюнкция, дизъюнкция, отрицание), а также условия на взаимное расположение узлов в дереве. В частности, можно проверить является ли узел непосредственно дочерним либо входит ли он вообще в поддерево другого узла.
Приведем пример — одно из правил для извлечения персон. В нем рассматривается случай, когда персона упоминается с родовым префиксом («фон Бисмарк» и т.п.). Квадратные скобки обозначают переход к дочернему узлу. В левой части правила вводятся две переменные: von и this. В правой части формулируются логические утверждения, в которых используются введенные переменные:
//Проверяем, что вся конструкция не в кавычках.
~
// Задаем аннотацию для нового экземпляра в виде двух отрезков: границы // первого вычисляются по узлу, соответствующему переменной von, а границы // второго — по узлу, соответствующему переменной this. // Служебное слово core означает, что берутся непосредственные координаты // начала и конца соответствующих узлов (слов), без учета зависимых. annotation (P, von.core, this.core),
// Утверждаем, что экземпляр P привязан так же к узлу, соотнесенному с // переменной this. Служебное cлово Coreferential означает, что экземпляр // автоматически будет привязан ко всем узлам, связанных с данным // недревесными связями, обозначающими кореференцию. anchor (P, this, Coreferential),
// Утверждаем, что значением свойства middlename является строка, // получающаяся в результате запуска функции нормализации от множества узлов, // идентификаторы которых являются значениями свойства middlename_cs. Это // динамическое утверждение: при изменениях множества значений свойства // middlename_cs будет меняться значение свойства middlename. P.middlename == Norm (P.middlename_cs),
// Утверждаем, что значением свойства surname является строка, // получающаяся в результате запуска функции нормализации от множества из // двух узлов, соответствующих переменным von и this. P.surname == Norm (von.core, this.core); При разработке системы очень быстро стало понятно, что мы хотим уметь обращаться к уже извлеченным объектам из других правил, опираться на них в условиях, модифицировать их после извлечения и т.п. Для этого был реализован функционал, позволяющий искать в поддереве не только узлы с какими-то лингвистическими свойствами, но и привязанные к этим узлам объекты, созданные другими правилами. Так в наших продукциях появились объектные условия. Вот фрагмент правила, в котором используется такое объектное условие. В этом правиле мы ищем уже извлеченную персону, чтобы добавить ей нужные атрибуты.
// Корень данного шаблона — узел, являющийся личным именем this «PERSON_BY_FIRSTNAME» [ // В поддереве корневого узла найдем узел, являющийся фамилией или // родовым префиксом и обозначим переменной P. Восклицательный знак // обозначает дизъюнктивность — если таких узлов будет несколько, они // будут рассмотрены по-очереди (каждый вариант в отдельном // сопоставлении). За счет дизъюнктивности переменная P гарантировано // уникальная. // Дополнительно проверяем, что все узлы, лежащие на пути между корнем и // узлом P являются личными именами и находятся в поверхностной позиции // Classifier_Name. Все узлы, принадлежащие этому пути, соотнесем с // множественной переменной middle. // Кроме того, к узлу P должен быть привязан информационный объект класса // Person, у которого свойство surname имеет хотя бы одно значение, а // свойство firstname пусто. …(Classifier_Name: middle «PERSON_BY_FIRSTNAME») ! P («PERSON_BY_LASTNAME» | «PART_OF_SURNAME_PREFIX») <% Person, surname ~= null, firstname == null %> ] => // Утверждаем, что множество узлов, соотнесенных с переменной middle, // включено в множество значений свойства middlename_cs. P.o.middlename_cs == middle, … В приведенных выше примерах мы опирались либо на известное нам имя (часть имени), либо на явный указатель имени (дворянскую приставку). Однако понятно, что все персоны (равно как и все организации) в нашу иерархию занесены быть не могут. Часто названия компаний и имена людей распознаются как неизвестные слова.
В этом случае ABBYY Compreno позволяет нам опереться на многочисленные косвенные признаки. Например, если неизвестное слово (да еще и с большой буквы) оказывается «зарегистрировано в Калифорнии», проводит IPO, или, к примеру, «женится» или «простужается», нам все становится понятно. Используя деревья ABBYY Compreno, указывая нужные семантические классы, глубинные позиции и другие признаки, мы можем минимизировать ошибочные извлечения и вылавливать такие нетривиальные организации и персоны.
Кроме того, благодаря объектным условиям мы можем улучшать извлечение одних сущностей с опорой на другие. Например, выделилась у нас в тексте по каким-то признакам персона с неизвестной фамилией «Пыщпыщ». А ниже фраза Пыщпыщ распродает активы. При этом онтоинженер, создающий правила извлечения организаций, знает, что чаще всего распродают активы организации, и хотел бы их извлекать в таких случаях. Тогда он может поставить у себя в условии отрицательное объектное условие ~<% Person%> (=на узле нет объекта Person) — и в этом конкретном случае правило не сработает, т.к. на Пыщпыще уже будет персона.
Теперь о том, как мы извлекаем события и факты, а все эти персоны и организации становятся их участниками. Для примера поэкспериментируем с извлечением факта покупки или продажи чего-либо. Создадим новое правило с единственной продукцией и напишем такое условие:
«TO_ACQUIRE» => PurchaseAndSale P (this), // Утверждаем существование экземпляра концепта PurchaseAndSale annotation (P, this.core); // создаем аннотацию Здесь мы просим найти в дереве узел с семантическим классом TO_ACQUIRE или его потомком. Так выглядит этот семантический класс в иерархии для русского и английского:
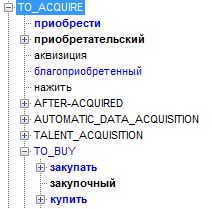
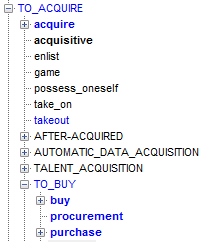
Продукция будет срабатывать во всех случаях, когда кто-то что-то покупает, при этом даже не важно, присутствуют ли в тексте участники действия.
Теперь создадим новое правило:
<%PurchaseAndSale%> [Possessor: ! customer] => CustomerRole CR (customer), // Утверждаем существование экземпляра концепта PurchaseAndSale annotation (CR, customer.core), // создаем аннотацию this.o.customer == CR; // помещаем созданный экземпляр в отношение customer (покупатель) наденного нашим правилом объекта PurchaseAndSale
Это правило ищет под узлом с уже извлеченным фактом PurchaseAndSale дочерний узел в глубинной позиции Possessor (обладатель). Например, в позицию Possessor попадет Вася в высказываниях типа Вася купил, Васей приобретено и т.п.
В правой части мы создаем специальный ролевой объект CustomerRole, который затем помещаем в отношение customer (покупатель) найденного факта. Если на том же узле извлекается какая-то полноценная сущность (например, персона «Вася»), то специальное правило заменит ролевой объект этой сущностью. В конечном счете у нас получится факт PurchaseAndSale, у которого в отношении customer лежит персона Вася.
Аналогично устроены правила для ивзлечения покупателя, товара и цены. Разница лишь в том, что товар в данном случае попадает в глубинную позицию Object (объект, претерпевающий действие), цена — в специальную позицию Ch_Parameter_Price (ценовой параметр), покупатель — в позицию Source (роль источника):
<%PurchaseAndSale%> [Object: ! sold_property] => …
<%PurchaseAndSale%> [Ch_Parameter_Price: ! price] => …
<%PurchaseAndSale%> [Source: ! seller] => … Эти правила сработают для примеров вроде «Вася купил у Маши игрушку», «Петей приобретена машина», «Николай идет покупать розового слона», «Auto.ru был куплен Яндексом за 175 млн. долларов», «Павел Дуров приобрел домен telegram.me» и т.п. Сначала будет извлечен сам факт PurchaseAndSale, а потом для него будут выделены правильные участники: покупатель Вася, продавец Маша и объект купли-продажи «игрушка» и т.д. по всем примерам. При этом нам не важен ни порядок слов («купил игрушку Вася», «игрушку купил Вася», «игрушку Вася купил»), ни конкретные имена, ни время глагола. Мало того, поскольку все элементы деревьев, на которые мы опирались (глубинные позиции и семантические классы), являются в нашей системе универсальными, то есть общими для всех поддерживаемых языков, правило сработает не только для русского, но и для английского. Там гораздо больше синонимов для действия, обозначающего покупку (выражаясь в наших терминах, у семантического класса «TO_ACQUIRE» гораздо больше лексических классов). Поэтому эти простые продукции найдут факт купли-продажи и правильно извлекут участников во всех примерах ниже:
Lenovo buys Motorola from Google.Lenovo purchased Motorola.Lenovo has just acquired Motorola.Motorola has been acquired by Lenovo.Lenovo«s purchase of Motorola.Lenovo«s acquisition of Motorola.Motorola«s acquisition by Lenovo.
Это сработает именно потому, что во всех случаях в разборе есть поддерево, в котором присутствует вершина с семантическим классом «TO_ACQUIRE» (или его потомком) и дочерними в глубинных позициях Possessor (Lenovo), Object (Motorola), Source (Google в первом примере).
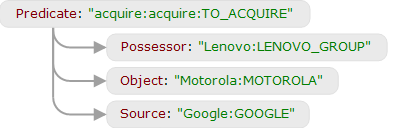
Помимо правил извлечения существует еще один тип правил — правила локальной идентификации. Они позволяют собрать все упоминания одной и той же сущности или факта в рамках одного текста. Например, в одной части текста встречается имя персоны, а в другой — местоимение «он» (о том, как ABBYY Compreno справляется с местоименной анафорой, можно почитать тут, а еще подробнее — тут). Или одну и ту же персону упоминают несколько раз (один раз — полным именем, а дальше — только по фамилии). Правила идентификации работают в пределах одного текста и не обращаются к деревьям, а оперируют уже исключительно объектами, их атрибутами и расстоянием между ними. Например, мы можем написать правило, которое соединит два факта купли продажи в один, если у них пересекаются покупатель и продавец, и они находятся недалеко друг от друга. Они срабатывают в таком (совершенно реальном) примере:
Google is selling Motorola to Lenovo, giving this company a major presence in the US market. Lenovo will buy Motorola for $2.91 billion in a mixture of cash and stock. (The Verge)
То есть здесь система по-настоящему понимает, что речь в обоих предложениях идет об одном и том же факте. В результате вся информация о сделке (цена, покупатель, продавец, товар), разбросанная по ДВУМ отдельным высказываниям, объединяется в ОДНОМ информационном объекте.
Понятно, что проблема идентификации возникает и на более общем уровне — при анализе текстовых коллекций. Часто одни и те же информационные объекты переходят из текста в текст. Для этого реализованы отдельные механизмы глобальной идентификации, основанные на специальных шаблонах и методах машинного обучения, однако для содержательного рассказа о них потребуется отдельная большая статья.
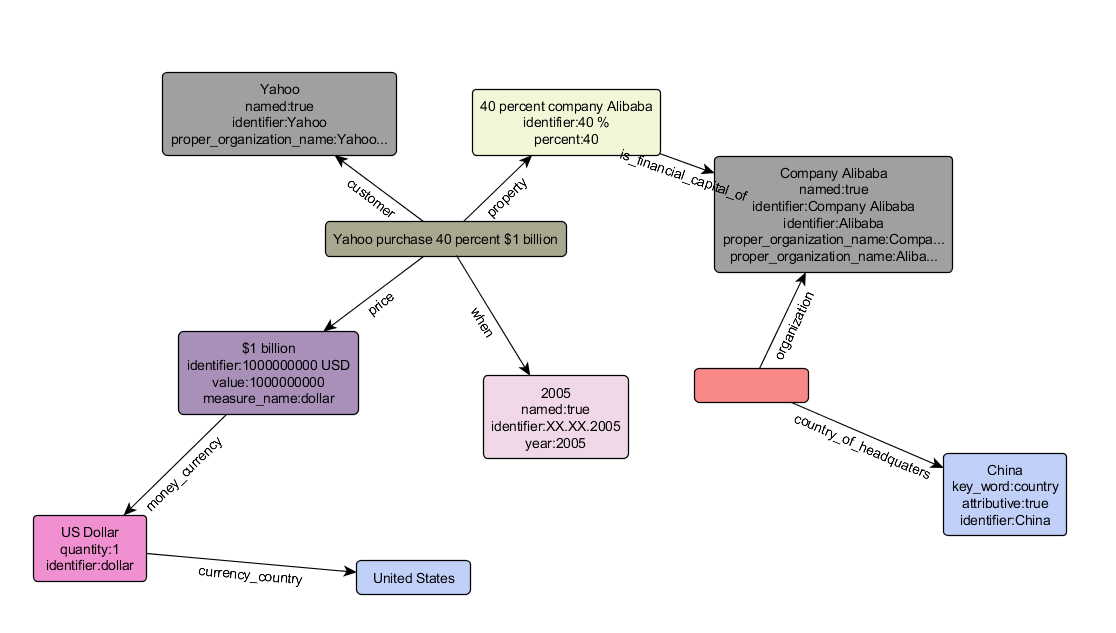
После срабатывания всех правил извлеченные факты и сущности записываются в XML-документ, в соответствии с форматом описания данных RDF. Этот документ задает RDF-граф, в котором видны связи объектов и их привязка к фрагментам текста (=их аннотации). Полученный информационный граф и является конечным результатом работы системы извлечения. Дальше его можно использовать как угодно — заливать полученную информацию в базы данных, визуализировать и т.д. Так, например, выглядит визуализация графа фактов и сущностей, извлеченных из предложения с Техкранча: In 2005, Yahoo purchased 40 percent of the Chinese ecommerce company Alibaba for $1 billion
Зачем все это нужно Описанная выше система по сути представляет собой фабрику создания различных онтологий и соответствующих им моделей извлечения фактов и сущностей. Что именно будет «производиться» на этой фабрике — зависит уже от разнообразных потребностей конкретных заказчиков. И надо сказать, что во многих случаях «семантическая глубина» анализа и умение снимать неоднозначность оказываются для нас просто незаменимыми — например, парсер ABBYY Compreno способен отличить травку, которая на газоне (семантический класс «GRASS»), от той, о которой вы подумали (семантический класс «MARIJUANA»)…В ходе работы возникают не только технические сложности, но и проблемы философско-мировоззренческого характера. Поэтому в онтоинженерском отделе часто можно услышать споры о том, является ли персонами Дед Мороз и Бэтмен, нужно ли извлекать сущность «наркотик» на «героиновых наркоманах», всегда ли убийство является преступлением и какой факт выделять, если кого-то загрызли собаки. В ходе этих дискуссий можно услышать много забавных фраз, и я в свободное от работы время даже начал собирать коллекцию под названием «Так говорят онтонженеры». Вот немного оттуда:
А можно поинтересоваться, как я должна труп отделять от костей? Ей нужен концепт, в котором не сразу полный разврат! А боги выделяются как люди? — Это не люди, но это личности! Убей, пожалуйста, эту персону! Кто сломал Bank account? Кроме сугубо коммерческих начинаний есть и те, которые не про прибыль, а про вечные ценности. Многие наверняка слышали о проекте ABBYY и Музея Толстого «Весь Толстой в один клик», о котором как о впечатляющем краудсорсинговом прорыве писали Guardian и New Yorker. Цели этого проекта — оцифровка и вычитка (силами неравнодушных добровольцев) 90 томов полного собрания сочинений писателя — были достигнуты с опережением всех планов, и теперь появилась новая задача — семантическое издание Толстого. Этот проект призван задать стандарты публикации классического наследия в цифровую эпоху — с семантической разметкой, извлечением и идентификацией вымышленных и реальных сущностей, ссылками на общедоступные базы знаний вроде dbpedia или freebase. Мы надеемся, что использование системы извлечения информации на базе ABBYY Compreno поможет сократить объем ручного труда в этом проекте так же значительно, как использование ABBYY FineReader — при оцифровке 90-томника.Параллельно с работой на заказ мы создаем на базе наших технологий и более универсальный продукт «общего пользования» — InfoExtractor. Он извлекает все традиционные сущности (персон, организации, локации) и факты (купля-продажа, трудоустройство, образование, родственные связи и многое другое), появляющиеся в новостных и публицистических текстах. Сейчас InfoExtractor существует в виде поисково-аналитического SDK IntelligentTagger, в дальнейшем планируется выпуск нескольких новых «умных» продуктов с прицелом на извлечение информации.
