Обучение с подкреплением: от Павлова до игровых автоматов
История обучения с подкреплением в зависимости от того, как считать насчитывает от полутора веков до 60 лет. Последняя волна (которая захлестывает сейчас нас всех) началась вместе с подъемом всего машинного обучения в середине 90-ых годов 20-ого века. Но люди, которые сейчас на гребне этой волны начинали само собой не сейчас, а во время предыдущего всплеска интереса — в 80-ых. В процессе знакомства с историей нам встретятся многие персонажи, который сыграли роль в становлении учения об искусственном интеллекте (которое мы обсуждали в прошлой статье). Само собой, это неудивительно, ведь обучение с подкреплением — его неотъемлемая часть. Хотя обо всем по порядку.
Само название «обучение с подкреплением» взято из работ известного русского физиолога, нобелевского лауреата Ивана Петровича Павлова. В 1923 вышел его труд «Двадцатилетний опыт объективного изучения высшей нервной деятельности (поведения) животных» [1], известный на западе как Conditional Reflexes [2]. Но психологические подходы были известны и ранее.
Физиологические исследования
Помимо Павлова, давшего название области, стоит упомянуть несколько работ из физиологии, например, работу Петра Кузьмича Анохина 1948-ого года [3], продолжателя научной школы Павлова, Росса Ашби (W. Ross Ashby) 1952-ого «Архитектура мозга» [4]. В дальнейшем эти работы повлияли на вторую волну интереса к обучению с подкреплением, в частности на работы Гарри Клопфа (Harry Klopf).
Психологические истоки
Главной психологической идеей, которая используется в обучении с подкреплением, является метод проб и ошибок. Он был предложен ученым и философом Александром Бэном (Alexander Bain) в 1855 году в книге «Чувство и интеллект» [5]. Объясняя возникновение произвольных движений, Бэн вводит представление о спонтанной активности нервной системы, проявлением которой являются спонтанные движения. Когда какое-либо движение более одного раза совпадает с состоянием удовольствия, то удерживающая сила духа устанавливает между ними ассоциации. Эта идея получит свое развитие не только в психологии, но и в последствии в предмете этой статьи — обучении с подкреплением. Ллойд Морган (Conway Lloyd Morgan) — известный психолог 19-ого века, автор канона своего имени — развил эту идею, в частности, в своем фундаментальном труде «Привычка и инстинкт» [6]. Канон Ллойда Моргана говорит, что «то или иное действие ни в коем случае нельзя интерпретировать как результат проявления какой-либо высшей психической функции, если его можно объяснить на основе наличия у животного способности, занимающей более низкую ступень на психологической шкале», что позволяет отделить безусловные рефлексы от сознательной деятельности (в современном изложении) и выученного поведения. Более явно выражено это у Эдварда Ли Торндайка в его трудах об интеллекте животных [7]. Он вывел так называемый «закон эффекта»: полезное действие, вызывающее удовольствие, закрепляется и усиливает связь между ситуацией и реакцией, а вредное, вызывающее неудовольствие, ослабляет связь и исчезает. Закон эффекта лег в основу многих изыскании впоследствии, из которых стоит выделить работы бихевиористов — «теорию научения» Кларка Леонарда Халла (Clark L. Hull) [8] и эксперименты Берреса Фредерика Скиннера (Burrhus Frederic Skinner), в частности его работу «Концепт рефлекса в описании поведения» [9].
Электро-механические реализации
Идею реализации метода проб и ошибок в «железе» можно считать одной из ранних попыток создать искусственный интеллект. В 1948 году Алан Тьюринг выступил с докладом, где описывал архитектуру системы «боли и наслаждения» (награды и наказания) [10]:
«Когда система приходит в состояние, действие в котором не определено, делается случайный выбор для недостающих данных, делается предварительная запись о том, как действовать, и производится действие. Если возникает болевой стимул, все предварительные записи стираются, а если возникает стимул удовольствия, то они делаются постоянными.»
Было сделано множество машин, демонстрирующий этот подход. Самая ранняя — машина Томаса Росса (Thomas Ross) 1933-ого года могла пройти простейший лабиринт и запомнить последовательность переключателей [11]. В 1952 году Клод Шеннон продемонстрировал лабиринт [12], по которому бегал мышонок по имени Тесей, — это был механизм, который передвигался по лабиринту с помощью трех колес и магнита с обратной стороны лабиринта, он мог запомнить путь по лабиринту, исследуя его тем самым методом проб и ошибок.

Больше деталей можно почерпнуть из этого видео.
В своей диссертации [13] Марвин Минский (1954 г.) представил вычислительные модели обучения с подкреплением, а также описал аналоговую вычислительную машину, построенную на элементах, которые он назвал SNARC — стохастический вычислитель, обучаемый через подкрепление, аналогичный нейрону. Эти элементы должны были соответствовать изменяемым семантическим связям в мозгу. В целом, появление таких электро-механических машин открыло путь к написанию программ для цифровых компьютеров, способных к разным типам обучения, некоторые из которых были способны к обучению методом проб и ошибок. Фарли (Farley) и Кларк (Clark) в 1954 году описали цифровую модель нейронной сети, которая обучалась этим методом [14]. Но уже в 1955-ом их интересы сместились в область распознавания образов и генерализации, то есть в область обучения с учителем. Это положило начало путанице между этими двумя типами обучения (с подкреплением и с учителем). Например, Розенблатт (1962) [15], при создании перцептрона явно руководствовался обучением с подкреплением, используя для описания термины награды и наказания, но тем не менее это было явно обучение с учителем. В 60-ых обучение с подкреплением было популярной идеей в инженерии. Особенно стоит отметить повлиявшую на многих работу Марвина Минского 1961-ого года «На пути к искусственному интеллекту» [16]. В ней обсуждаются такие концепции, как предсказание, ожидание, а также то, что Минский называет проблемой «нахождения виновного» для сложных систем обучаемых через подкрепление: как определить значимость каждого из цепочки решений, приведших к текущему состоянию? Многие из предложенных подходов не утратили свою актуальность и сегодня.
Другой столп истоков — теория управления
Помимо психологического подхода, независимо развивался подход математического программирования. Отсюда происходит термин «оптимальное управление», он был введен в конце 1950-ых годов для описания проблемы управления поведением динамической системы во времени. Один из подходов к этой проблеме был сформулирован в середине 1950-ых Ричардом Беллманом (совместно с коллегами) [17], который в своей основе расширял идеи математиков 19-ого века Уильяма Гамильтона и Карла Якоби. В этом подходе используется понятие состояния системы и функции ценности (value function), иначе оптимальной функции выгоды (optimal return function) для задания функционального уравнения часто называемого уравнением [оптимальности] Беллмана. Класс методов решения проблем оптимального уравнения со временем стал называться динамическим программированием. В 1957-ом году Беллман ввел дискретную стохастическую версию проблемы оптимального управления, известную как марковский процесс принятия решений (MDP), названный так в честь русского математика Андрея Андреевича Маркова, автора понятия марковский процесс. В 1960-ом году Рональд Говард (Ronald Howard) предложил метод итерации по стратегиям для MDP [18].
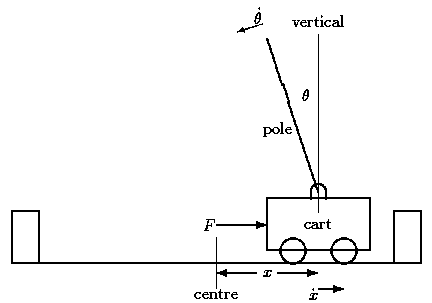
Вторая волна
В 1968 году Дональд Мичи (во Вторую Мировую войну он, как и Алан Тьюринг, работал криптографом) и Р.А. Чамберс представили свою версию задачи про балансировку шеста на платформе (можно посмотреть на заглавной картинке к посту) в работе «BOXES: Эксперимент в контролируемом окружении» [19]. Эта задача вынесена в заглавие не просто так, очень много работ 70-ых и 80-ых годов, например, Эндрю Барто и Рича Саттона [20], предлагали решение именно в этом окружении. Сатон и Барто же — те люди, которые через 15 лет, в конце 90-ых годов, выпустят свой ставший классическим учебник по обучению с подкреплением [21]. Мичи последовательно отстаивал важность метода проб и ошибок и обучения, как необходимых составляющих искусственного интеллекта. Видроу, Гупта и Майтра (Widrow, Gupta, Maitra) в 1973 году представили работу, модифицирующую общеизвестный метод наименьших квадратов для создания правила, которое обучалось на сигналах успеха и неудачи вместо обучающих примеров [22]. Они описывали этот тип обучения, как обучение с критиком, вместо обучения с учителем. Они показали, что с помощью этого правила можно выучить программу играть в блэкджек.
Серия работ Михаила Львовича Цетлина, советского биофизика и математика, по теории массового обслуживания в 1960-ых годах послужила толчком к созданию теории многоруких бандитов (по аналогии с «одноруким бандитом» — игровым автоматом из казино), см. например [23]. В 1975 году Джон Холланд (John Holland) — экономист, не психолог — предложил общую теорию адаптивных систем, основанную на принципах селекции [24]. Его цель была приблизиться к поведению реальных экономических агентов, в 1976 и более полно в 1986 годах он представил системы, обучаемые через подкрепление, умеющие изучать ассоциации и делать выбор. Его системы включали в себя генетические алгоритмы, которые как таковые нельзя считать относящимися к обучению с подкреплением, но системы целиком все-таки можно (обучение через эволюцию).
Пожалуй, самым ярким ученым, поспособствовавшим возрождению интереса к обучению с подкреплением был Гарри Клопф. Он первым указал на то, что важные аспекты адаптивного обучения теряются в обучении с учителем. Например, так называемый гедонистический аспект: что агент хочет получить от окружения в процессе обучения. Именно он, а также его аспиранты Барто и Саттон, указали на различие обучения с подкреплением и с учителем. В 1972 году Клопф [25] описал обучение с течением времени, на основании своего опыта изучения процесса обучения у животных. Параллельно в Советском Союзе во многом аналогичные исследования вел Петр Кузьмич Анохин [26]. Саттон и Барто в 1981 году предложили архитектуру основанную на этом принципе [27]. В том же 1981 году появилась их же архитектура «актор-критик» [28]. Несколько раньше, в 1977 г., вышла прошедшая незамеченной работа Йена Уиттена (Ian Witten) [29], где принцип обучения с течением времени был первый раз применен к обучению с подкреплением. Что важно, в этой работе TD-обучение применялось для решения MDP. Что свело вместе работы по теории управления и психофизиологические работы об обучении. Наконец, в 1989 году Крис Уоткинс (Chris Watkins) завершил это слияние, предложив Q-обучение (Q-learning) [30]. Ну вот и все, мы готовы к современности: кажется, все важные концепты уже изобретены. Конечно, охватить все важные работы в рамках статьи невозможно, но теперь читатель подготовлен к восприятию современного состояния науки на этом поприще.
Современность
В 2013-ом году вышла статья DeepMind (тогда еще небольшой исследовательской компании) об обучении с подкреплением на играх Atari [31]. C тех пор начался настоящий бум обучения с подкреплением, обзор последних работ в виде лекций от молодых исследователей (например, Алексея Досовитского, выигравшего соревнование VizDoom) до ветеранов (тот самый Эндрю Барто) на нашем канале youtube. Кстати, параллельно со школой, на которой проходили лекции, мы проводили хакатон по теме обучения с подкреплением, где результаты также немного подвинули state of the art на сложных играх Atari. Свои подходы в эту субботу (25 февраля) участники хакатона расскажут на тренировке по Machine Learning.
Источники:
- Павлов И.П. Двадцатилетний опыт объективного изучения высшей нервной деятельности (поведения) животных: Условные рефлексы: Сб. ст., докл., лекций и речей. — М.; Пг.: Госиздат, 1923.
- Ivan Pavlov (1927). Conditioned reflexes: An investigation of the physiological activity of the cerebral cortex.
- Анохин П.К. «Системогенез как общая закономерность эволюционного процесса». // Бюллетень экпериментальной биологии и медицины. № 8, т. 26 (1948).
- Ashby, W. R., (1952). Design For a Brain, First Edition, Chapman and Hall: London, UK., John Wiley and Sons: New York, NY, 260 pp.
- Bain, A., (1855). The senses and the intellect. London: Parker.
- Morgan, C. L., (1896). Habit and Instinct. London.
- Thorndike, E. L. (1898, 1911). «Animal Intelligence: an Experimental Study of the Associative Processes in Animals» Psychological Monographs #8
- Hull, C. L., (1943). Principles of Behavior: An Introduction to Behavior Theory. New York: D. Appleton-Century Company.
- Skinner, B. F. (1931). The concept of the reflex in the description of behavior, Ph.D. thesis, Harvard University.
- Turing, A. M. (1948). Intelligent Machinery, A Heretical Theory. Oxford.
- Ross, T. Machines That Think. Scientific American, April, 1933, pp. 206–209.
- Shannon, C. This Mouse Is Smarter Than You Are. Popular Science, March, 1952, pp. 99–101.
- Minsky, M. (1954) «Neural Nets and the Brain Model Problem,» Ph.D. dissertation in Mathematics, Princeton.
- Farley, B. G., & Clark, W. A. (1954). Simulation of self-organizing systems by digital computer. IRE Transactions on Information Theory, 4, 76– 84.
- Rosenblatt, F. (1962): Principles of neurodynamics; perceptrons and the theory of brain mechanisms. Washington: Spartan Books.
- Minsky, M. (1961). Steps toward artificial intelligence. Proceedings of the IRE, 49(1), 8–30.
- Bellman, R. (1956). Dynamic programming and Lagrange multipliers. Proceedings of the National Academy of Sciences, 42(10), 767–769.
- Howard, R.A. (1960). Dynamic Programming and Markov Processes. MIT Press, Cambridge, Massachusetts.
- Michie, D., & Chambers, R. A. (1968). BOXES: An experiment in adaptive control. Machine intelligence, 2(2), 137–152.
- Barto, A.G., Sutton, R.S., and Anderson, C.W. (1983) Neuronlike elements that can solve difficult learning control problems. IEEE Transactions on Systems, Man, and Cybernetics, 13: 835–846
- Р. Саттон, Э. Барто. Обучение с подкреплением. М.: Изд-во Бином, 2011.
- WIDROW, B., GUPTA, N. K., AND MAITRA, S. (1973), Punish/reward: learning with a critic in adaptive threshold systems, IEEE Trans. Systems, Man & Cybernetics SMC-3, 455.
- Конечные автоматы и моделирование простейших форм поведения. М.Л. Цетлин. УМН, 18:4(112) (1963), 3–28
- Holland, J. (1975). Adaptation in natural and artificial systems. University of Michigan Press.
- Klopf, A. H. (1972). Brain function and adaptive systems—A heterostatic theory. Technical Report AFCRL-72–0164, Air Force Cambridge Research Laboratories, Bedford, MA.
- Анохин П.К. Очерки по физиологии функциональных систем. М.: Медицина (1975).
- Barto, A. G., Sutton, R. S. (1981). Goal seeking components for adaptive intelligence: An initial assessment. Technical Report AFWAL-TR-81–1070. Air Force Wright Aeronautical Laboratories/Avionics Laboratory, Wright-Patterson AFB, OH.
- Barto, A. G., Sutton, R. S. (1981). Landmark learning: An illustration of associative search. Biological Cybernetics, 42:1–8.
- Witten, I. H. (1977). An adaptive optimal controller for discrete-time Markov environments. Information and Control, 34:286–295.
- Watkins, C.J. C. H. (1989). Learning from Delayed Rewards. Ph.D. thesis, Cambridge University.
- Mnih, V. et al. Playing Atari With Deep Reinforcement Learning. NIPS Deep Learning Workshop, 2013.
