Об анализе исходного кода и автоматической генерации эксплоитов
В последнее время об анализе защищенности исходного кода не написал только ленивый. Оно и понятно, ведь тот парень из Gartner, как предложил рассматривать анализ исходного кода в качестве нового хайпа несколько лет назад, так до сих пор и не дал отмашку на то, чтобы прекратить это делать. А, учитывая текущее направление моей работы (участие в разработке PT Application Inspector, далее AI), и тот факт, что в последнее время годных статей на тему анализа исходного кода в общем-то не было, как-то даже странно, что до сегодняшнего дня в этом блоге не было ни одной грязной подробности на эту животрепещущую тему. Что ж, исправляюсь :) Собственно все, что можно было сказать о нашем подходе к автоматизации анализа защищенности исходного кода в AI уже сказали Сергей Плехов и Алексей Москвин в докладе «Проблемы автоматической генерации эксплоитов по исходному коду» на PHDays IV. Тем, кто не присутствовал на докладе и не смотрел его запись — крайне рекомендую сделать это прежде, чем читать статью дальше. Однако, в конце доклада от Ивана Новикова aka d0znpp прозвучало сразу несколько вопросов на тему «в чем кейс?», «чем ваш подход отличается от того же RIPS?» и «как вы тогда получаете точки входа?» в контексте утверждения о том, что без развертывания приложения невозможно получить внешние данные, необходимые для построения эксплоита (такие к примеру, как имя привилегированного пользователя и его пароль, маршруты к точкам входа и т.п). Хочу сразу оговориться, что здесь имеет место некоторая (внесенная безусловно с нашей стороны) терминологическая путаница: название «проблемы автоматического вывода множеств векторов атак по исходному коду» гораздо более точно отражало бы суть решенных в ходе работы над AI задач. Называть то, что получается на выходе AI эксплоитом действительно не вполне корректно. Хотя бы потому, что это круче, чем просто эксплоит в традиционном понимании этого термина :) И далее я постараюсь раскрыть эту мысль и дополнить своих коллег более развернутым ответом на заданные Иваном вопросы.
В чем кейс? В первую очередь, кейс заключается в поиске недостатков в коде и подтверждении их уязвимости к тем или иным классам атак. Задача по автоматической генерации эксплоитов в рамках данного кейса сводится к выводу минимального вектора атаки, подтверждающего существование уязвимости. При этом, под вектором подразумевается не конкретный HTTP-запрос, а некоторая совокупность факторов, приводящая систему в состояние уязвимости и позволяющая провести на нее успешную атаку. Скажу даже больше: в общем случае, выразить вектор атаки в виде только HTTP запроса не представляется возможным. Во-первых, потому что данный вектор может требовать выполнения нескольких запросов. Во-вторых (и это главное), потому что вектор может включать в себя условия на какие-либо свойства окружения, которые невозможно описать в контексте запроса HTTP. Тем не менее, в рамках рассматриваемого кейса мы должны: а) вывести все подобные условия; б) каким-то образом оформить их в результатах анализа. Именно это и привело к столь замысловатому определению вектора. Приведу простой пример (здесь и далее рассматривается код на C# под ASP.NET Web Forms): var settings = Settings.ReadFromFile («settings.xml»); string str1; if (settings[«key1»] == «validkey») { Response.Write (Request.Params[«parm»]); } else { Response.Write («Wrong key!»); } Очевидно, что в данном случае уязвимость к атаке XSS зависит от значения параметра key1 в конфигурационном файле settings.xml. И, если мы по-честному прочитаем его (т.е. фактически, а не символьно осуществим вызов Settings.ReadFromFile («settings.xml») и присвоим переменной settings полученный результат), то далее мы пойдем только по одному из двух возможных путей выполнения, что неизбежно приведет нас к пропуску уязвимости в том случае, если параметр key1 в файле не будет установлен в значение «validkey». Выполняя же первый вызов символьно, мы придем в итоге к следующей формуле, которая и будет являться искомым вектором: Settings.ReadFromFile («setings.xml»)[«key1»] == «validkey» → {Request.Params[«Parm»] = } Мы также можем вывести из этого и HTTP-эксплоит: GET http://host.domain/path/to/document.aspx? parm=%3Cscript%3Ealert%280%29%3C%2fscript%3E HTTP/1.1 который, тем не менее, не является самодостаточным и зависит от условий, накладываемых на окружение веб-приложения. Получение каких-либо значений из базы данных, файловой системы или любого другого внешнего источника, приводит к простой дилемме: либо мы получаем внешние данные и имеем возможность строить полноценные эксплоиты (там, где это теоретически возможно), но пропускаем при этом потенциальные уязвимости из-за потери путей выполнения, либо обрабатываем вызовы ко внешним источникам символьно и, тем самым, покрываем все возможные множества значений и пути выполнения, которые могут иметь место в результате таких вызовов. И поскольку перед нами стояла задача не создать универсальный аттакер-всемогутер, а максимально автоматизировать человеческую рутину по анализу защищенности кода, то получение векторов в виде доказанных логических формул, требующих дальнейшей работы человека в плане построения полноценных эксплоитов, предпочтительнее автоматизированного получения таких эксплоитов в ущерб основному функционалу.
Однако же возможны ситуации, где без чтения внешних данных действительно никуда: это и определение маршрутов к точкам входа в веб-приложение в том случае, если они определены во внешних файлах конфигурации, а не в коде приложения, и подключение дополнительных файлов с исходным кодом через их перечисление в файлах конфигурации (актуально для динамических языков), и ряд аналогичных задач. Но тут и вопросов нет: раз надо — значит, скрестив пальцы, читаем. Где можем, конечно :)
Подытоживая: в настоящий момент, нет никаких препятствий к тому, чтобы научить AI читать данные из БД и использовать их в ходе символьного выполнения анализируемого кода. Однако, это потребует развертывания, как минимум, БД веб-приложения с одной стороны и существенно просадит возможности анализатора по обнаружению уязвимостей с другой, не дав при этом каких-либо ощутимых преимуществ в рамках поставленной перед нами задачи, которую я описывал выше.
Чем ваш подход отличается от RIPS? Насколько я могу судить о подходе принятом в RIPS, AI’шный — отличается чуть более, чем всем. Начиная с того, что в RIPS реализован классический static-taint-analysis через разметку тегами путей в графе потока данных с эмуляцией ряда стандартных библиотечных функций, а поход AI предполагает построение модели (по одной на каждую точку входа) в виде системы логических утверждений, описывающих состояние приложения в каждом узле CFG и условия его достижости, что дает возможность разрешать любые пути в нем (включая if’ы, условные return’ы, обработку исключений и т.п) еще и с частичным выполнением реального кода вместо его эмуляции там, где это дает лучший результат по сравнению с символьным выполнением. И заканчивая (но не ограничиваясь) тем, что RIPS тупо обламывается на кастомных фильтрующих функциях, в то время, как AI пытается с ними работать (причем весьма успешно в большинстве реальных случаев). Наверное, лучше показать на примере. Допустим, у нас есть следующий фрагмент исходного кода[1]:
string name = Request.Params[«name»]; string key1 = Request.Params[«key1»]; string parm = Request.Params[«parm»]; byte[] data; if (string.IsNullOrEmpty (parm)) { data = new byte[0]; } else { data = Convert.FromBase64String (parm); } string str1; if (name + «in» == «admin») { if (key1 == «validkey») { str1 = Encoding.UTF8.GetString (data); } else { str1 = «Wrong key!»; Response.Write (str1); return; } } else { str1 = «Wrong role!»; } Response.Write (»Click me»); Очевидно, что здесь дважды имеет место выполнение потенциально-опасной операции (далее PVO — Potentially Vulnerable Operation) — вызова метода Response.Write, осуществляющего запись в поток формируемого сервером ответа на HTTP-запроса. В первом случае методу передается константа «Wrong Key!», что не представляет для нас никакого интереса. Зато во втором, в ответ отправляется результат вызова метода CustomSanitize с аргументом, значение которого вычисляется из значений параметров полученного запроса. Но какими они должны быть, чтобы мы получили возможность пробросить в str1 значение, достаточное для подтверждения возможности проведения атаки XSS через инъекцию элементов разметки HTML? Давайте рассмотрим, как приблизительно может выглядеть процесс поиска ответа на этот вопрос[2]. Для начала, выведем условие достижимости второго Response.Write. Несмотря на то, что сам он не вложен в какие-либо конструкции, влияющие на поток управления, в предшествующих ему блоках кода имеет место возврат из общей для всего кода функции, условие достижимости которого одновременно является условием недостижимости нашей PVO. Очевидно, что условием выполнения оператора return будет являться логическое выражение: (name == «adm» && key1!= «validkey»). Следовательно, условием его недостижимости будет являться выражение: (name!= «adm» || name == «adm» && key1 == «validkey»). Поскольку этот return — единственный оператор, влияющий на достижимость второго Response.Write, последнее выражение и будет являться условием достижимости PVO.
Фактически, выражение (name!= «adm» || name == «adm» && key1 == «validkey») дает нам два взаимоисключающих условия формирования пути к PVO на графе потока управления. Рассмотрим возможные значения str1 при выполнении каждого из них. При выполнение (name!= «adm») переменная str1 получает константное значение «Wrong role!», что определенно не может привести нас к успешной атаке. Но при (name == «adm» && key1 == «validkey») в str1 попадает результат вызова метода Encoding.UTF8.GetString с аргументом data, который в свою очередь может принимать два значения: new byte[0] при string.IsNullOrEmpty (parm) и Convert.FromBase64String (parm) при ! string.IsNullOrEmpty (parm). Отбрасывая неинтересные с т.ч. эксплуатируемости уязвимости значения и раскручивая значения всех переменных вплоть до их taint-источников, получаем следующую формулу:
(Request.Params[«name»] == «adm» && Request.Params[«key1»] == «validkey» && ! string.IsNullOrEmpty (Request.Params[«parm»])) → Response.Write (»Click me»)
Графическое представление модели выполнения, построенной в данном случае, будет иметь вид (кликабельно): 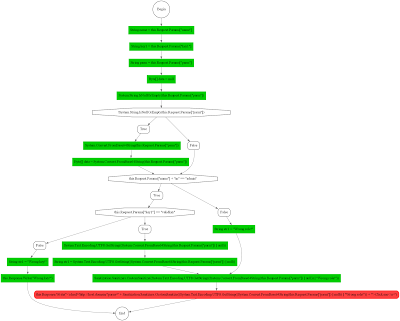 Таким образом, значения параметров запроса name и key1 у нас уже есть и все, что осталось сделать — это найти такое значение Request.Params[«parm»], при котором конечное значение выражения CustomSanitize (Convert.FromBase64String (Request.Params[«parm»])) даст нам эксплуатацию уязвимости, приводящей к XSS.
Таким образом, значения параметров запроса name и key1 у нас уже есть и все, что осталось сделать — это найти такое значение Request.Params[«parm»], при котором конечное значение выражения CustomSanitize (Convert.FromBase64String (Request.Params[«parm»])) даст нам эксплуатацию уязвимости, приводящей к XSS.
И вот здесь возникает проблема, справиться с которой традиционные средства статанализа не в состоянии. Метод Convert.FromBase64String является библиотечным и может быть описан в базе знаний анализатора, как имеющий обратную функцию Convert.ToBase64String, из чего мы можем сделать вывод, что результат выполнения CustomSanitize должен попасть на вход Convert.ToBase64String. Но что делать с CustomSanitize, который не является библиотечным, нигде не описан и представляет из себя на данном этапе анализа черный-пречерный ящик? Хорошо, если нам доступны исходники этого метода — в этом случае, мы можем «провалиться» в его тело и продолжить символьное выполнение кода образом, аналогичным описанному выше. Но что же делать, если исходников нет? Ответ прозвучал в предыдущем предложении: забыть на некоторое время про то, наш анализ является статическим и работать с данным методом, как с черным ящиком. У нас есть уже выведенное ранее выражение Convert.ToBase64String (CustomSanitize (Request.Params[«parm»])), есть множество возможных векторов XSS (пусть это будет {``, `'onmouseover='a[alert]; a[0].call (a[1],1)` и `«onmouseover=«a[alert]; a[0].apply (a[1],[1])`}) — так почему бы не профаззить эту формулу, специфицируя символьную переменнную Request.Params[«parm»] значениями векторов и непосредственно выполняя получившееся выражение?
Допустим, CustomSanitize удаляет исключительно символы угловых скобок. Тогда, в результате фаззинга, получаем три значения:
scriptalert (0)/script 'onmouseover='a[alert]; a[0].call (a[1],1) «onmouseover=«a[alert]; a[0].apply (a[1],[1]) из которых два последних представляются достойными рассмотрения в качестве векторов атаки. Итак, мы знаем полное выражение, передаваемое в качестве аргумента PVO. Мы знаем точное место, в которое попадет значение символьной переменной Request.Params[«parm»] при ее спецификации значениями векторов. Что еще нам нужно для того, чтобы выбрать из этих двух тот вектор, использование которого приведет к инъекции? Те, кто внимательно слушали вебинар «Как разработать защищенное веб-приложение и не сойти при этом с ума?» или разобрались с алгоритмом детектирования XSS в IRV, сразу ответят, что больше нам ровным счетом ничего не нужно :) Т.о. конечным результатом анализа этого кода является контекстный (определяющий значения символьных переменных в контексте выполнения PVO) эксплоит:
Request.Params[«name»] = «adm»
Request.Params[«key1»] = «validkey»
Request.Params[«parm»] = »'onmouseover='a[alert]; a[0].call (a[1],1)»
из которого уже можно вывести и HTTP (определяющий требования к фактическим параметрам HTTP-запроса) эксплоит:
GET http://host.domain/path/to/document.aspx? name=adm&key1=validkey&parm=%27onmouseover%3D%27a%5Balert%5D%3Ba%5B0%5D.call%28a%5B1%5D%2C1%29 HTTP/1.1
В AI, если интересно, это выглядит так (кликабельно): 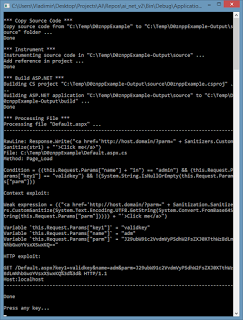
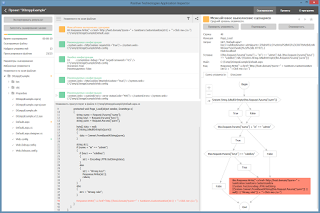 Разумеется, в жестокой реальности все слегка сложнее: даже измененный фильтрующей функцией вектор может «выстрелить», что вместе с появлением регулярных выражений в таких функциях приводит к необходимости манипулировать описывающими их конечными автоматами вместо константных значений; тот факт, что входной параметр запроса может воткнуться в произвольную грамматическую конструкцию выходного языка приводит к необходимости парсинга и/или эвристического вывода свойств островных языков и т.д. и т.п. Но это уже темы для отдельных (и, вероятно, чуть более научных) статей. Замечу лишь, что в рамках нашей задачи, эти проблемы также были успешно решены.
Разумеется, в жестокой реальности все слегка сложнее: даже измененный фильтрующей функцией вектор может «выстрелить», что вместе с появлением регулярных выражений в таких функциях приводит к необходимости манипулировать описывающими их конечными автоматами вместо константных значений; тот факт, что входной параметр запроса может воткнуться в произвольную грамматическую конструкцию выходного языка приводит к необходимости парсинга и/или эвристического вывода свойств островных языков и т.д. и т.п. Но это уже темы для отдельных (и, вероятно, чуть более научных) статей. Замечу лишь, что в рамках нашей задачи, эти проблемы также были успешно решены.
Как вы получаете точки входа? Я намеренно опустил во всех примерах вопрос получения »/path/to/document.aspx» (т.е. маршрута к точки входа в веб-приложение), т.к. данная задача не имеет универсального решения и требует описания специфики различных фреймворков в базе знаний анализатора. Для ASP.NET Webforms, например, точками входа являются методы-обработчики т.н. postback’ов элементов управления веб-форм (что требует разбора .aspx файлов и связывания их с соответствующими codebehind-файлами). В ASP.NET MVC маршруты задаются через наполнение коллекции RouteCollection прямо в коде инициализации приложения. Нельзя также забывать и о возможности появления в WebConfig секциий urlMappings, urlrewritingnet и им подобных, также влияющих на маршрутизацию HTTP-запросов к приложению. Да и разработчику ничего не мешает определить собственный HTTP-обработчик, реализующий кастомную логику роутинга, реверс которой является алгоритмически неразрешимой задачей. В этом случае, нам ничего не остается, кроме как рассматривать в качестве точек входа все public и protected методы в случае Java/C# либо все .php-файлы в случае с PHP, смирившись с ростом вероятности словить false-positive на недостижимом снаружи коде. Однако живьем, лично я пока таких .NET приложений не встречал, а существующий зоопарк PHP-фреймворков хоть и внушает, но вполне формализуется в базе знаний анализатора, в том числе и в части, касающейся получения маршрутов к точкам входа. Экзотику типа описания правил роутинга в БД, как уже наверное понятно, мы пока обрабатываем упомянутым выше прямом перебором всех потенциальных точек входа (что, кстати, дает вовсе не такие плохие результаты, как может показаться на первый взгляд).That’s all Надеюсь, что на поставленные вопросы ответить все же удалось. Но если вдруг возникли новые, или остались непонятные моменты — welcome, как говорится :)↑ Сразу оговорюсь, что пример безусловно синтетический и призван продемонстрировать, скорее, возможные проблемы на пути анализа кода среднестатистической паршивости, нежели какой-то реальный пример из живой системы. Если кто-то из читателей захочет предложить свой вариант фрагмента кода, то можно будет рассмотреть процесс анализа и на нем — вообще не вопрос ↑ Описание пошагового выполнения процесса анализа даже такого простого кода вылилось бы в многостраничную цепочку преобразований однообразных логических формул, поэтому выкладки здесь не приводятся. Интересующиеся могут ознакомиться с достаточно подробным описанием подхода и отдельных его этапов в записи доклада, упомянутого в начале статьи.
