Неудачное внедрение Redis Cluster в монолит на PHP 7.2.X

Меня зовут Женя и я у мамы PHP-программист. Сегодня расскажу о том как принес в проект проблему, которую так и не устранил в течение долгого времени.
Осторожно!!! Статья может обострить профессиональные заболевания вплоть до боли ниже поясницы и разделить аудиторию на 3 части:
1. Да что тут такого — я бы сделал легко и просто.
2. Так‑так, посмотрим на какие грабли ты, идиот, наступил — ведь все нужно было делать по‑другому.
3. Сочувствую — это я знаю, это мы проходили.
Хотелось бы почитать комментарии из группы #3, которые реально знают в чем проблема и проходили через подобное.
Причины по-которым это публикуется здесь:
В сообществе мало статей о провалах, а ведь часто учатся именно на них. Если бы я знал о подобных проблемах скорректировал свое поведение на старте проекта;
Возможно, есть победитель подобной проблемы и поделится собственным опытом;
Саморефлексия на тему «ваша самая большая ошибка»;
Поделиться тем что возможны ошибки которые ты никак не ожидаешь;
Показать что иногда классные идеи приводят к проблемам, не бегите за модными и популярными технологиями.
Хочу отметить для понимания статьи что действующие лица распределяются так:
 Я
ЯАвтор статьи
 Множественное число, в т.ч в глаголах
Множественное число, в т.ч в глаголахРазные люди, с разным грейдом: от коллеги по команде до техдира, в разном составе
1. Немного про Redis
Если слово Redis мало о чем говорит или первым делом думаете о корнеплоде (у меня вот правый глаз дергаться начинает), позволю себе дать здесь вводную информацию. Важно быть в контексте так как в статье будут отсылки к реализации, и эта информация поможет понять почему сделано так, а не по-другому. Если знакомы — переходите к следующей части.
Redis — хранилище данных в оперативной памяти с открытым исходным кодом. Используется как база данных, брокер сообщений, для стриминга данных и так далее.
Существует 3 варианта инсталляции:
Standalonе — Redis без намеков на High Availability, но возможна схема с репликацией. Логика следующая: пишешь в мастер, полная копия данных появляется у реплик. Есть понятие «БД» — что-то вроде страницы памяти с числовым индексом, в разных БД могут хранится ключи с одинаковыми именами;
Sentinel — тоже что и Standalonе c отдельным процессом, который призван обеспечивать High Availability и Fault Tolerance. Cхема следующая: инстансы Sentinel, как правило, запущены на тех же серверах что и сами Redis и общаются между собой, постоянно опрашивая друг‑друга, делая на основании ответов выводы о доступности. В случае, если текущий мастер недоступен — быстренько выбирают новый на основе кворума. Для поддержки этого функционала клиент Redis должен уметь общаться с помощью протокола Sentinel и узнавать кто текущий мастер, и уже потом выполнять на нём операции записи. Часто это требование обходится через следующую схему: настраивается HAProxy перед такой сборкой, который уже сам проходит по списку нод и узнает кто там мастер. «Непрокачанный» клиент при этом обращается по виртуальному адресу, который указывает на текущий мастер, что поддерживается средствами HAProxy;
Cluster — подход к шардированию данных в Redis с механизмом для High Availability. Всего есть 16 384 слота. Текстовое имя ключа по нехитрой и быстрой формуле переводится в номер слота. У каждого инстанса в кластере диапазон слотов, которые он обслуживает — все вместе это называется топологией. Если к нему происходит запрос для слота, который он не обслуживает — клиенту выдается перенаправление на нужную ноду. В пределах диапазона слотов работает репликация мастер‑слейв. Нода не способна выполнять никаких операций с данными из слотов которые не принадлежат ей. Из‑за этого факта возможны проблемы — вроде нужно заранее просчитывать атомарность операций в транзакциях чтобы она была в пределах одного диапазона слотов (инстанса). Когда мастер диапазона слотов становится недоступным для большинства нод кластера, из живых и доступных слейвов этого диапазона слотов происходят выборы нового мастера. В случае отсутствия живых слейвов для этого диапазона — кластер переходит в состояние ошибки, и ожидает вмешательства администратора. Понятие БД не поддерживается, но это как правило решается добавлением префикса ключа. т. е. был у вас в БД 1, в ключ supparedis, ключ станет вида 1: supparedis.
2. Немного про persistent-соединения в PHP
Говорить про весь PHP в статье нет никакого смысла, но для погружения в контекст статьи нужно напомнить про persistent (постоянные) подключения. Если очень грубо то это возможность ядра PHP, используемая во многих библиотеках для снижения накладных расходов на создание подключения. Такие соединения не закрываются при завершении работы скрипта, они кешируются и используются повторно, в случае если другой скрипт запрашивает соединение с теми же учётными данными. Постоянные соединения позволяют избежать создания новых подключений каждый раз, когда требуется обмен данными, что в результате даёт прирост скорости работы приложений, использующих их. Как правило для таких подключения или существует отдельный метод pconnect или в свойствах подключения можно отдельно указать perstistent = true.
Я считаю что выступление Сергея Аверина «pconnect, граната в руках обезьяны» незаслуженно прошло мимо PHP‑сообщества. Если не знакомы, всячески рекомендую ознакомится, несмотря на то что материалу много лет, в нем видны боль и опыт.
Для ЛЛ: чтобы такое persistent-подключение работало ожидаемо хорошо нужно убедиться в наличии готовности:
Библиотеки
Серверной части
Кода, обслуживающего бизнес-логику
3. Задача на 15 минут
Веселый ералаш начался с одной из первых задач на новой позиции в новой компании: подготовить переезд с Redis Standalone на Redis Cluster монолитного сервиса, который крутится на PHP 7.2.23.
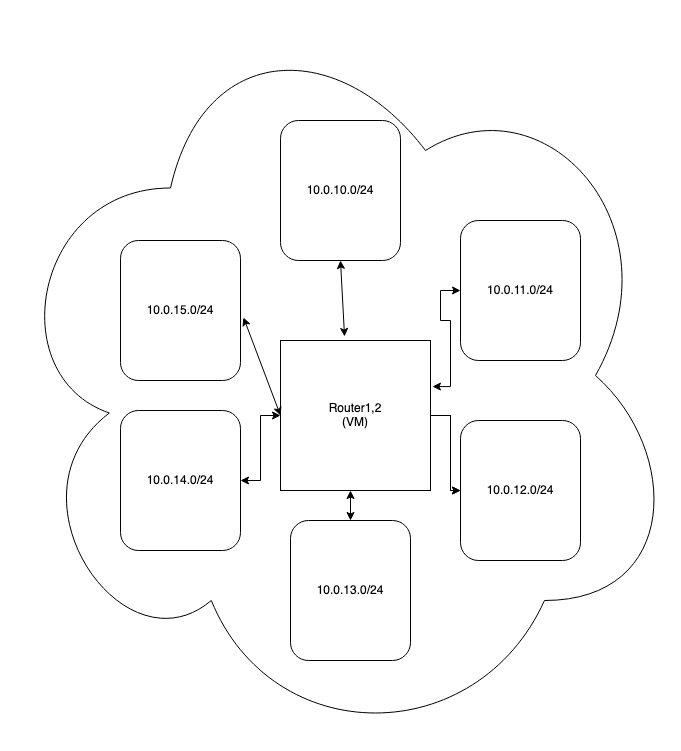
Сервера обслуживающие веб-трафик (физические сервера) и ноды Redis Cluster (qemu-виртуализация) могли быть из разных подсетей и в этом случае весь трафик между ними ходил через один из 2-х виртуальных серверов (да-да, я знаю) на этой схеме маршрутизации.
Бизнес компании благодаря инвестициям рос, данные в подсистеме кэша не отставали.
9 Standalone инстансов с 10 слейвами на каждом уже трещали по швам и падали как по доступности сети так и по Out Of Memory, —, а вслед за ними и монолит. Бизнес не работает, клиенты не получают услуги — непорядок. Внедрение паттерна Circuit Breaker перенесло точку отказа дальше — в ядро приложения или БД. Redis использовался только как распределенный кэш — иначе бы проблем было куда больше, чем сильно возросшая нагрузка на БД после его срабатывания.
В высоконагруженных сервисах использовался Golang — и там эту проблему решили с помощью перехода на Redis Cluster. Результаты впечатляющие — работало практически из коробки, увеличились: гибкость, масштабируемость, аптайм и много других плюсов.
Переход произвели в 5 этапов:
Реализация единого интерфейса для вызова методов кэша;
Создание реализации Redis Cluster, Redis Standalone и Proxy (которая умела работать сразу с 2-мя реализациями) на основе этого интерфейса;
Переход сервиса на использование враппера из пункта 1;
Прогон в режиме dry-mode: запись в оба места, чтение из Standalone и Cluster и сравнение ответов: если ответы расходились, или стреляли какие-то ошибки, что было отражено в логе сервиса — эти сообщения детально изучались, и вносились изменения в бизнес логику или прослойку если требовалось;
Перевод сервиса на работу только с Redis Cluster — верифицированные данные уже находились в нем после прогона предыдущего шага. Standalone через несколько дней выводится из эксплуатации.
Для работы кластерной реализации после авторизации добавляется как минимум еще один запрос — CLUSTER SLOTS, — получение актуальной карты слотов. Если этого не делать будет высокий процент редиректов на другую ноду и общее время ответа сервиса увеличится в разы. Эту карту слотов, называемой топологией кластера нужно где‑то хранить. Обновлять состояние лучше только через время или появления таймаутов или перенаправлений на другую ноду — в зависимости от подхода к рискам в компании и сервисе.
На основе опыта с Golang-сервисами было понимание, что нужно и пошли искать готовые реализации клиента PHP к Redis Cluster.
Казалось что по этому же пути можно сделать и перевод монолита. Но нужно учитывать что с PHP ситуация сложнее: из-за отсутствия асинхронности и вменяемого постоянного процесса — на тот момент монолит работал в режиме FPM.
Для начала я создал Bash-скрипт, который назвал clustershake.sh со следующим функционалом: собирал Redis Cluster в Docker, после этого случайно эмулировал проблемы, на которые на тот момент хватило фантазии:
Запрет случайной ноде общаться с другими по сервисному порту через iptables;
Запрет входящего порта ноды в iptables, режим DROP;
Запрет входящего порта ноды в iptables, режиме REJECT;
Замедление времени ответа через утилиту tc;
Эмуляция сетевых ошибок до 30%;
KILL любой ноды в Redis Cluster.
Казалось с такими функциями отлов большинства проблем у библиотек подключения к Redis Cluster на начальном этапе пройдет эффективно и можно будет понять насколько библиотека готова к реальным условиям.
На тот момент по сути существовала единственная реализация протокола Redis Cluster для PHP — в библиотеке predis. Сама по себе библиотека старая и используется многими проектами, поэтому я был неприятно удивлен когда нашел в ней ошибку реализации работы с кластером. Насколько я помню это приводило к следующему поведению: если во время работы транзакции менялся мастер, логика библиотеки ломалась и она вместо того чтобы выполнить команду на ноде вычитывала ответ — выглядело это так что условно вместо операции SET мог прилететь ответ на GET. Согласитесь — неприятная и неожиданная ситуация.

Поправив локальный форк, убедившись что больше проблем нет решили «катить потихоньку».
Первые результаты: в случае использования predis «из коробки» соединение не было персистентным, поэтому на каждый входящий HTTP‑запрос пользователя нужно было идти в кластер и запрашивать карту слотов. Учитывая что кластеров предполагалось несколько, общий APDEX рос некрасиво. Сразу после того как заметили выключили и пошли думать дальше.
4. Ооооочееееньь странные дела
Решив что с библиотекой predis уже все хорошо — можно включать persistent соединение получили весьма неожиданную картину после выкатки релиза на большинство боевых серверов:

По логике должно было быть так: код создает persistent соединение, внутри которого запоминает карту слотов и после выкатки сначала эти графики должны немного подрасти, а потом упасть или упереться в некое значение и значительно меняться только в случае проблем с процессами или сетевой доступностью.
Почему же росло количество вызовов авторизации в кластере — AUTH, вместе с временем ответа, и не остановилось на некоем значении? RPS на приложение находился на стандартном значении. Ответов не нашлось.
Испугались, откатили релиз, пошли анализировать. Логи, проверка значений таймаутов, кода predis, попытка повторить в разных средах и тд. В итоге пришли к выводу: где-то внутри ядра PHP произошел «залип» и в цикле отправлялся запрос на авторизацию. Почему так случилось не на всех серверах, почему только AUTH, а не AUTH + CLUSTER SLOTS, — разобраться не удалось, как и повторить ошибку в тестовом контуре. Решили что один раз бывает — давайте попробуем. Почему в тот момент было сделано именно такое решение: думаю что так как внутри организации большой авторитет амбассадора Redis Cluster, даже несмотря на то что к этому моменту он покинул компанию, и результаты в сервисах на Go были хорошими — решили продолжать. Да и выглядело как плевое дело на пару недель — на самом деле.
Стали потихоньку переводить не нагруженные базы внимательно смотря на графики и логи — все было в пределах нормы. Оптимизму не давало развиваться время ответа, которое выше ~40% чем с использованием extension phpredis для PHP. Последнее использовалось в монолите для работы с Redis Standalone. «Внезапно!» нашли что после получения щедрого доната в расширении появилась поддержка кластерной реализации.
Ребята сделали красиво: пулинг, persistent-соединения, кеширование карты слотов, так мило сердцу программистов на Golang. Попробовали потестить функциональность: время ответа упало, графики в норме. Из дополнительных плюсов за донат в размере ~15$/месяц можно задавать вопросы по реализации напрямую авторам библиотеки, против predis который на тот момент замер в разработке и активно искал нового мейнтенера.
Выкатили самую свежую версию phpredis с поддержкой кластера на тест, результаты: все хорошо, время ответа упало. На препрод — все хорошо, обновили все железные сервера монолита, катим код с его использованием — все прекрасно, время ответа в норме, ошибок нет. В итоге остановились на этой реализации и стали переводить бизнес-логику на новый коннектор к Redis Cluster.
Начали упираться в бесхозные вещи, где‑то, например, использовалась команда KEYS — которая возвращала все ключи в БД. Но вместе с этим так как Redis однопоточный вешала остальных его клиентов — т. е. запросы от PHP‑FPM вешались наглухо до истечения таймаутов. Или полное очищение БД, что в нашем случае недопустимо, так как в кластере пространство для ключей — общее.
Переделывали и занимались этим, пока как гром среди ясного неба, не стали в Sentry проскакивать ошибки несовпадения типов внутри бизнес логики.
Чтобы было понятнее: ваш код ожидает что из кэша будет извлечен объект, а приходила строка. Или вместо массива чисел одно число и тд. Ошибка проявлялась на одной группе серверов, которая не обрабатывала веб-запросы, но использовалась под обработку очередей. С точки зрения бизнеса — не критически страшно, но очень неприятно, так как запрос обрабатывался не с первого раза, а перезапускался из-за фатальной ошибки. Но для нас это выглядело еще страннее: на этих серверах PHP работает в режиме CLI, а не PHP-FPM, процесс можно назвать постоянным, так как логика работала в режиме демона.
Вот и ACID у нашего кеша, с отсутствующей D: весело при непонятных условиях на каком-то уровне подменяются данные. Но проверки на серверной стороне показывали что по нужному ключу лежат верные данные. Где тогда эти значения берет клиентская библиотека?
Веселая картинка о ситуации:

Джо должен ответить 4
После жалобы на инфраструктуру от этой команды, дежурный инженер призвал меня к решению инцидента. Я после анализа стреляющего ошибкой кода сделал неверный вывод: логика скрипта допускает тот факт что ключ может быть и не установлен в Redis, но надеется на то что там это значение присутствует. Вот же корень проблем, отстаньте от Redis. Попросил это поправить за что, если говорить откровенно, был правильно поруган и получил свои баллы на performance review:)
5. Шаги и действия для решения проблемы
В итоге через пару рабочих дней эта продуктовая команда сама нашла красивое решение: реализовали декоратор к своим данным в кеше и стали проверять несоответствие ожидаемого типа — получаемому, если есть несоответствие — происходило игнорирование данных из кэша, логирование этой ситуации, и перерасчет нужного им по алгоритму значения.
Элегантно, просто, надежно — молодцы.
Но нам стало очевидно что существует проблема где‑то в клиентской библиотеке к Redis Cluster. Причем она трудноуловимая — проявлялась при непрогнозируемых обстоятельствах. Возможное влияние сети нельзя было рассматривать по приказу СТО.
Статья о проблемах pconnect и тот факт что я случайно в процессе изучения predis создал подобную картину на локальной машине и исправил ее в этой библиотеке — помогли не сойти с ума в то непростое время.
Внутри команды мы долго спорили что делать и в итоге было реализовано следующее:
Патч в phpredis чтобы увеличить размер пула persistent-соединений (по умолчанию он там было кажется на уровне хоста кластера, сделал по идентификатору БД);

На CLI-серверах (обработчики очередей в RabbitMq) persistent-подключение к высоконагруженным нодам Redis Cluster было выключено;
Там же было выключено чтение со слейвов для части критических «БД», все операции происходили на мастерах;
Подкрутили таймауты.
После этих действий подобные ошибки практически исчезли, изредка проскакивая пачкой в 5–10 штук рано утром в субботу или понедельник на другой группе серверов, обслуживающей веб-трафик наших клиентов. Учитывая общий RPS в сотни тысяч в минуту — было почти назаметно и SLI практически не портило.
Ура, победа!
6. Зря-зря
Так говорит уточка когда читает предыдущий абзац.
Однажды случился downtime у основного конкурента. Сервис большой и надежный, такой подставы от них никто не ожидал — ни мы ни клиенты.
К нам пришли много людей, желающих получить услуги, быстро вырос RPS, увеличиваясь каждую минуту. И тут: здрааааастееее, не ждали? Все встало колом. Да‑да: ВЕСЬ монолит встал колом. Бизнес не работает, клиенты не получают сервис, алерты об этом и побочных проблемах прилетают каждую секунду. Поиск первоисточника проблемы показал: одна из мастер‑нод Redis Cluster билась в истерике, ее загрузка CPU была 100% Redis по природе однопоточный, поэтому цифра вроде как нестрашная:) —, но по факту это означает: беда! Время ответа всего монолита растет, потому что PHP‑FPM воркеры ждут очереди когда смогут пообщаться с этой нодой кластера, если великий рандом указал что с ней нужно поработать.
Анализ вывода команды MONITOR на этом хромающем пациенте показал что идут запросы на один и тот же ключ с нескольких серверов. Выглядело так, как будто в коде есть вечный цикл. Быстрый анализ кода, работающего с этим ключом не нашел циклов и причин такого поведения.
После рестарта всей системы через php‑fpm restart (Да, SRE — Simply Restart Everything): живем 5 минут, проблема возвращается, но с другим ключом и другой нодой. Делаем руками переголосование в Redis Cluster: выбирается новый мастер, и теперь на другую ноду летит весь этот трафик где больше 90% запросов это GET на один и тот же ключ с небольшой части серверов. Увидели что среди всего прочего была забита таблица conntrack на router1 (смотри таблицу из части 2) — перезагрузили вместе с напарником, проблема ушла.
7. Фаза: «Смирение»
Так и жили, страдая: если входящий трафик на монолит рос, один из критичных высоконагруженных кластеров обслуживающий его, получал сильно возросшую нагрузку на одну из нод. При этом шаблон нагрузки состоял из нескольких простых ключей и не менее простых атомарных операций с ними типа SET/GET. Такая картина представала перед глазами несколько раз, в один из них вообще решили быстро создать более мощный кластер — не помогло и затянулось на несколько часов:) А рестарт router1 уже не всегда помогал. Почему не цепляло все кластера, а только парочку, хотя настройки там +/‑ теже самые — мне до сих пор непонятно.
Что было предпринято в целях борьбы с этой проблемой:
Крутились таймауты и TTL persistent-соединения
Много гуглинга;
Общались с командой разработки phpredis;
Допилили композитный кеш APCU/MemCache/Redis Cluster
Логика была в том чтобы сделать кэш более многоуровневым по схеме: горячо-тепло-холодно, тем самым разгрузив кластер;
Проверка контекста соединения
Не помню — своя реализация или полагались на то что в реализовано в расширении (а может быть и обе). Смысл в следующем: если есть подозрение что соединение может быть «испорченным» и было использовано другим процессом, который оставил его в непонятном состоянии, просто отправляем случайную строку через команду PING строка123. Сервер отвечает PONG строка123 — если строки равны, то мы внутри верного соединения и его контекст верен, можем доверять. Если нет — принудительное пересоздание объекта подключения, через сброс подключения;
Изучал возможности envoy на предмет проксирования перед Redis Cluster
Не подошел. Нас устраивала стабильность работы самого кластера (мастера и слейвы падали — не влияя на монолит, легкость добавления и удаления новых нод в инстанс). И нам хотелось бы поставить что‑то перед ним в виде прозрачного прокси. Для меня была идеальная картина что это что-то поднимает свой процесс на локальном сетевом интерфейсе и проксирует запросы в ноды кластера. При этом подменяя вывод относящийся к адресам нод (сообщения о редиректах, карта слотов и тд). Но envoy сильно ломал уже существующую логику, насколько я помню он предлагал прикинутся обычным Redis Standalone, при этом добавляя новых проблем, в том числе трудноразрешимые без серьезных изменений в бизнес-логике;
Начали разработку требований проекта: CRUD прокси перед Redis Cluster на Go/Rust
Идея возникла так как в истории успехов команды были успешные реализации высоконагруженных сервисов на этих языках, где смогли быстро и эффективно победить глубинные проблемы PHP и их расширений;
Запустили процесс обновления монолита на PHP 7.4
Проект забуксовал и был приостановлен, на 8-ку совсем не решились даже прицеливаться — причин не знаю или не помню;
Со стороны команды эксплуатации был организован процесс переноса и создания нод Redis кластера в одной подсети с основными серверами обслуживающими трафик
Стало значительно легче, даже казалось что проблема решена до тех пор пока опять не стал увеличиваться RPS
Снимали strace с процессов PHP-FPM и дамп трафика на Redis ноды в момент проблем
Никакого криминала не нашли, может из-за объемов, может из-за недостатка экспертизы в том куда смотреть;
Иногда мне удавалось предупредить проблему руками: видя что идет рост трафика и при срабатывании алертов: у ноды Redis высокая нагрузка CPU + выросло время ответа монолита нужно было быстро файерволом вырубить трафик на порт 6379 этой ноды секунд на 5, и потом вернуть обратно — ситуация быстро стабилизировалась. Но после какой‑то продолжительности проблемы трюк уже не срабатывал;
Дискутировали на тему, а может перейдем на KeyDB? Это форк Redis с поддержкой многопоточности;
Ребята из одной продуктовой команды сделали live переключалку кластеров. Т.е. на лету можно было сказать, а теперь вместо кластера-паукочеловек используй кластер зеленыйхалк. Решение интересное и несколько раз помогало в проверке гипотез при проблемах; Нраица!
Допилил анализатор запросов к Redis под наши условия;
Обновили ядра и версии ОС на серверах, участвующих в проблеме;
Circuit Breaker в коде уже реализован, но работало это не очень хорошо так как само подключение было глубоко в недрах расширения, и нельзя было взять и исключить произвольную ноду из списка на подключение.
Проделанное выше только лишь снижало вероятность появления проблемы или помогало быстро купировать ее, не решая корневой источник — который для меня до сих пор остается неизвестным. При росте нагрузки на сервера, обслуживающие трафик пользователей, картина с точки зрения логов сервиса следующая:
ошибки: «слишком много редиректов на другие ноды», или «не успел получить данные из ноды за время таймаута»;
затем начинали проскакивать ошибки несоответствия типов в PHP;
после этого одна из нод Redis Cluster начинала тормозить из-за высокой нагрузки CPU;
ну, а после этого монолит вставал, щедро отдавая 504-ые на любые запросы в него.
Нужно отметить что часто в высоконагруженных системах для Redis Standalone или Sentinel соединений используется прослойка в виде HAProxy. Но использовать его в нашем случае не получилось бы так как, кластер отдает свои реальные IP при запросе CLUSTER SLOTS (чуть позже появилась настройка для маскировки IP‑адресов, если ваши ноды живут внутри контейнеров)
Ломать сетевое взаимодействие указанное на схеме выше было очень дорого, затратно с точки зрения возможных проблем и непредсказуемо, да и была надежда на новые ДЦ и k8s — проекты, которые развивались в командах инфраструктуры и до их внедрения оставалось 1–2 квартала.
У меня осталось только 2 нереализованных идеи:
Попробовать HAProxy + маскировка адресов кластера на новых версиях Redis;
Провернуть весь фарш назад, переехав на Redis Sentinel через HAProxy.
Вы можете спросить: Эй, откуда такая надежда на HAProxy? Мой ответ следующий: Я ожидаю что в такой схеме затраты на создание соединения с локальной копией HAProxy будет настолько малы что ими можно пренебречь и отключить persistent подключение в настройках соединения со стороны приложения, при этом реализация сетевого взаимодействия с полезной нагрузкой на ноде уже будет на совести HAProxy, а не PHP.
8. Выводы
Я явно сильно недооценил проблему, и не смог ее правильно эскалировать, и, видимо решал каким‑то неправильным способом. Допускаю что вместо правильных шагов я подвергся воздействию инженерного азарта: «ну вот же, ну почти уже проблема решена, давай еще немного и попробуем вот это, ну почти получилось же, давай еще так».
Теперь же я просто живу с этим: вся инфраструктура вместе с проектом идут под спил, а я покинул компанию и уже не в силах ничего исправить и найти решение.
У меня вопрос к знатокам: есть у вас идеи где и что могло тут сломаться и как эту проблему можно было бы забороть? Признаю — тут я не справился, но мне очень интересно было бы найти корневую проблему и ее решение.
