Мы хотим заменить девопсов скриптом (на самом деле нет): разработчики, нужно ваше мнение
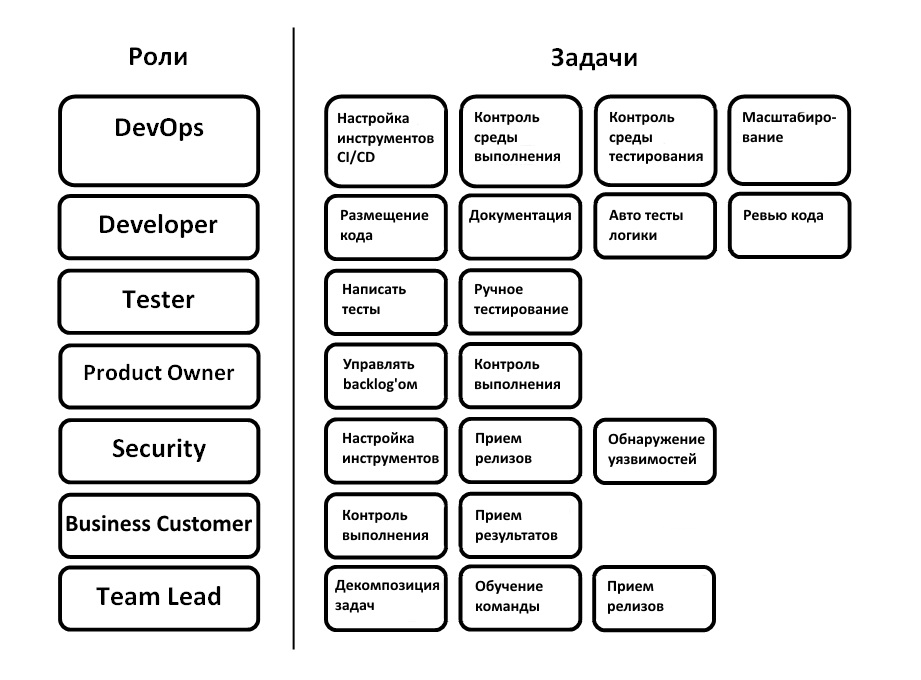
Мы делаем проект облака для разработки — платформу, способную максимально упросить жизнь девопсам, разработчикам, тестировщикам, тимлидам и другим вовлеченным в процесс разработки специалистам. Это продукт не для сейчас и не для завтра, и потребность в нём только-только формируется.
Основанная идея — вы можете разворачивать конвейер с уже преднастроенными инструментами, но при этом с возможностью внесения целого ряда настроек, и вам останется только деплоить код.
Откуда такое извращение? Мы видим чёткий тренд, что сейчас скорость развёртывания новых проектов влияет на рынок. От того, как быстро будут поставляться релизы, зависит коммерция. От того, как быстро будут исправляется баги, как быстро будут заниматься новые ниши. В начале 2018 глобальная компания »451 Research» провела опрос, какие технологии будут приоритетным при развитии. В первую десятку вошли технологии создания и управления контейнерами, а также бессерверная архитектура приложений и микросервисы, обогнав даже такую хайповую тему, как блокчейн.
И вот теперь у нас есть к вам пара вопросов.
Диаграмма из опроса: 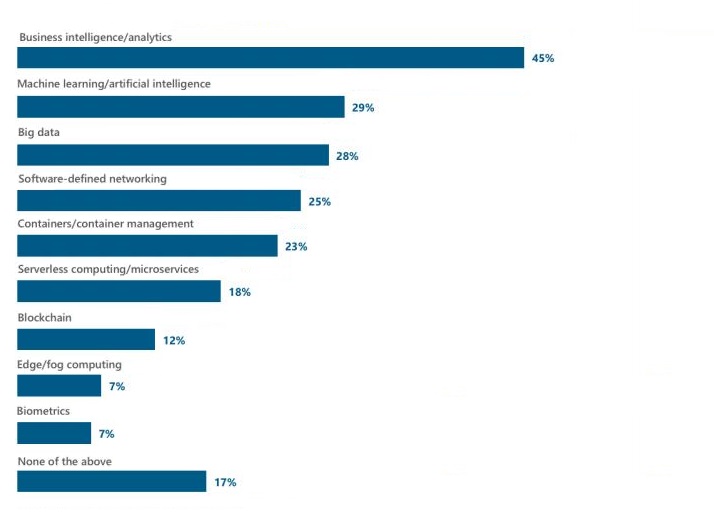
А нужно ли это?
Использование контейнеров при разработке нового продукта имеет как свои достоинства, так и недостатки. Использовать данную технологию или нет нужно решать исходя из поставленных задач. Для ряда задач без использования контейнеров не обойтись, а для некоторых они попросту лишние. Например, что для сайтов, с низкой посещаемостью будет вполне достаточно простой архитектуры из двух серверов. Но если же планируется значительный рост разработки, а так же огромный прирост посетителей за короткое время, в таком случае стоит рассматривать инфраструктуру с использованием контейнеров.
У использования контейнеров есть ряд преимуществ:
- Каждое приложение запускается изолированно в собственном контейнере, что позволяет свести проблемы, связанные с конфигурированием к минимуму.
- Безопасность приложений достигается также за счет изоляции каждого контейнера.
- В связи с тем, что контейнеры используют ядро операционной системы, теперь не нужна гостевая операционка, за счет чего освобождается большое количество ресурсов.
- Также благодаря использованию ядра операционной системы и потому, что не нужно полагаться на гипервизор контейнерам требуют гораздо меньше ресурсов в сравнении с другими стеками.
- Опять же в связи с тем, что контейнеры не требуют гостевой операционной системы, их легко мигрировать с одного сервера на другой.
- Благодаря тому, что каждое приложение запускается в изолированном контейнере, легко можно осуществить перенос с локальной машины в облако;
- Очень «дешево» запустить и остановить контейнер из-за использования ядра операционной системы.
В связи со всем вышеизложенным, мы считаем, что технология контейнеризации на текущий момент самый быстрый, ресурсоэффективный и наиболее безопасный стек. Благодаря преимуществам контейнеров можно иметь одинаковую среду как на локальной машине, так и в продакшене, что облегчает процесс непрерывной интеграции и непрерывной поставки. Преимущества контейнеров настолько убедительны, что они определенно будут использоваться еще долгое время.
При чём тут облако для разработки?
В идеальном мире разработчика любой commit кода должен по нажатию кнопки, как по мановению волшебной палочки, выкатываться в продакшн.
У нас было так: есть Гитлабчик с задачами и исходником. Когда нужно что-то собрать — GitLab Runner. Работаем по Git Flow, все фичи по отдельным веткам. Когда ветка попадает в хранилище, в GitLab«е запускаются тесты по этому коду. Если тесты прошли, разработчик этой ветки может сделать мердж реквест, фактически запрос на ревью кода. После ревью ветка принимается, вливается в dev-ветку, по ней еще раз проходят тесты. При деполее GitLab Runner собирает Docker-контейнер и выкатывает на стеджинговый сервер, где его можно будет покликать и порадоваться. И вот тут первый затык — код мы просматриваем руками на предмет соответствия функционалу и это первое, что мы исправляем. После этого мы вливаем код в ветку релиза. И для неё у нас раскатывается отдельный пред-продуктивный вариант нашего решения, который смотрят наши бизнес-заказчики. После того, как заопрувлена версия на пре-проде, мы ее катим в продакшн и она раскатывается на продуктовые ноды. Есть автогенерация release notes и отчёты по багам. Скорость сборки была больше 30 минут, сейчас на порядок меньше. Мы подобрали набор инструментов для себя, и теперь думаем о том, как сделать такой же готовый SaaS.
Непосредственно типовой процесс вывода релиза для нас выглядит следующим образом:
- Постановка задач на реализацию новых фич
- Локализация кода
- Внесение изменений согласно поставленным задачам. Написание автоматических тестов перед билдом.
- Проверка кода, как ручная, так и автотестами
- Сливание кода в dev-ветку
- Сборка dev-ветки
- Разворачивание тестовой инфраструктуры
- Деполой релиза на тестовой инфраструктуре
- Запуск тестирования, функционального, интеграционного и т.д.
- В случае возникновения багов, допиливание их сразу в dev-ветке
- Перенос dev-ветки в master-ветку
Вот схема с деталями для нашего процесса: 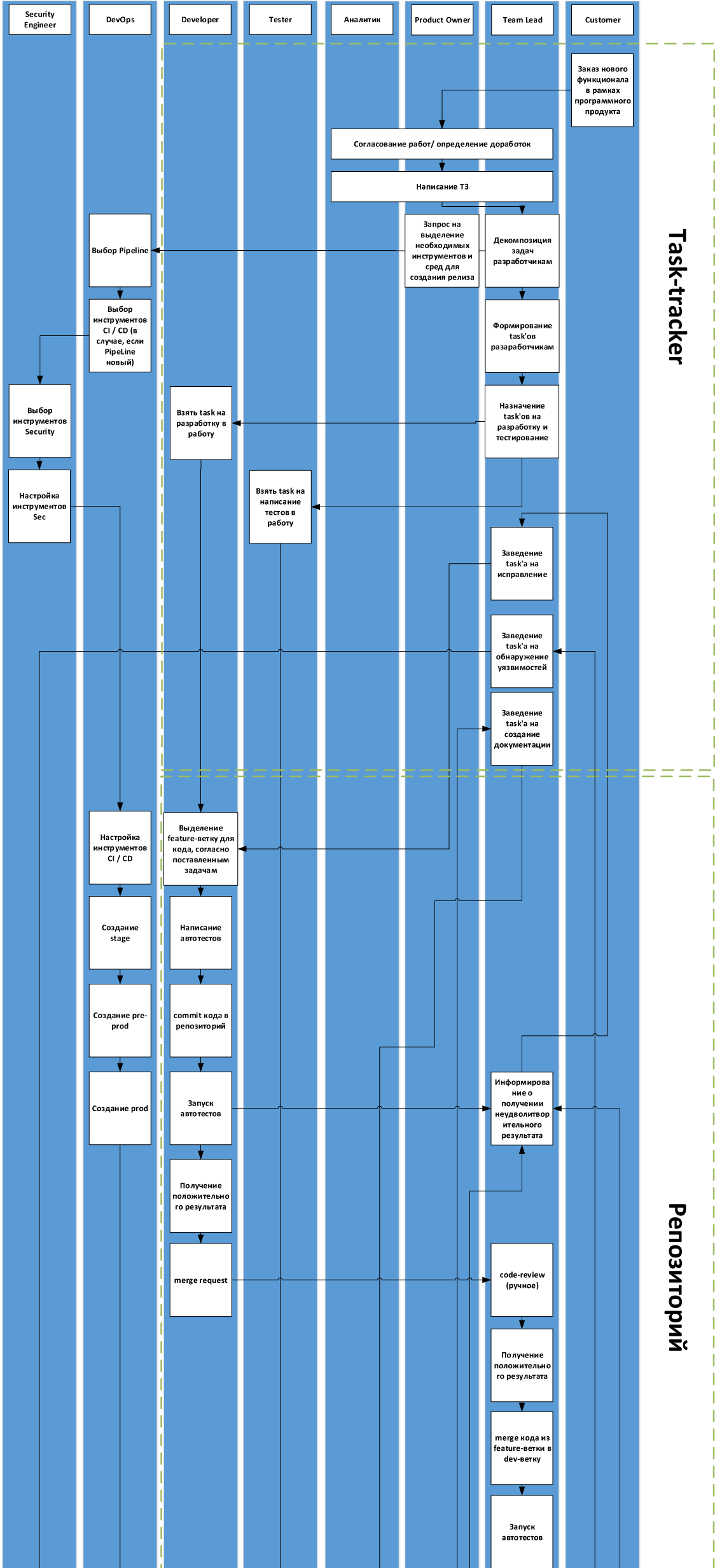
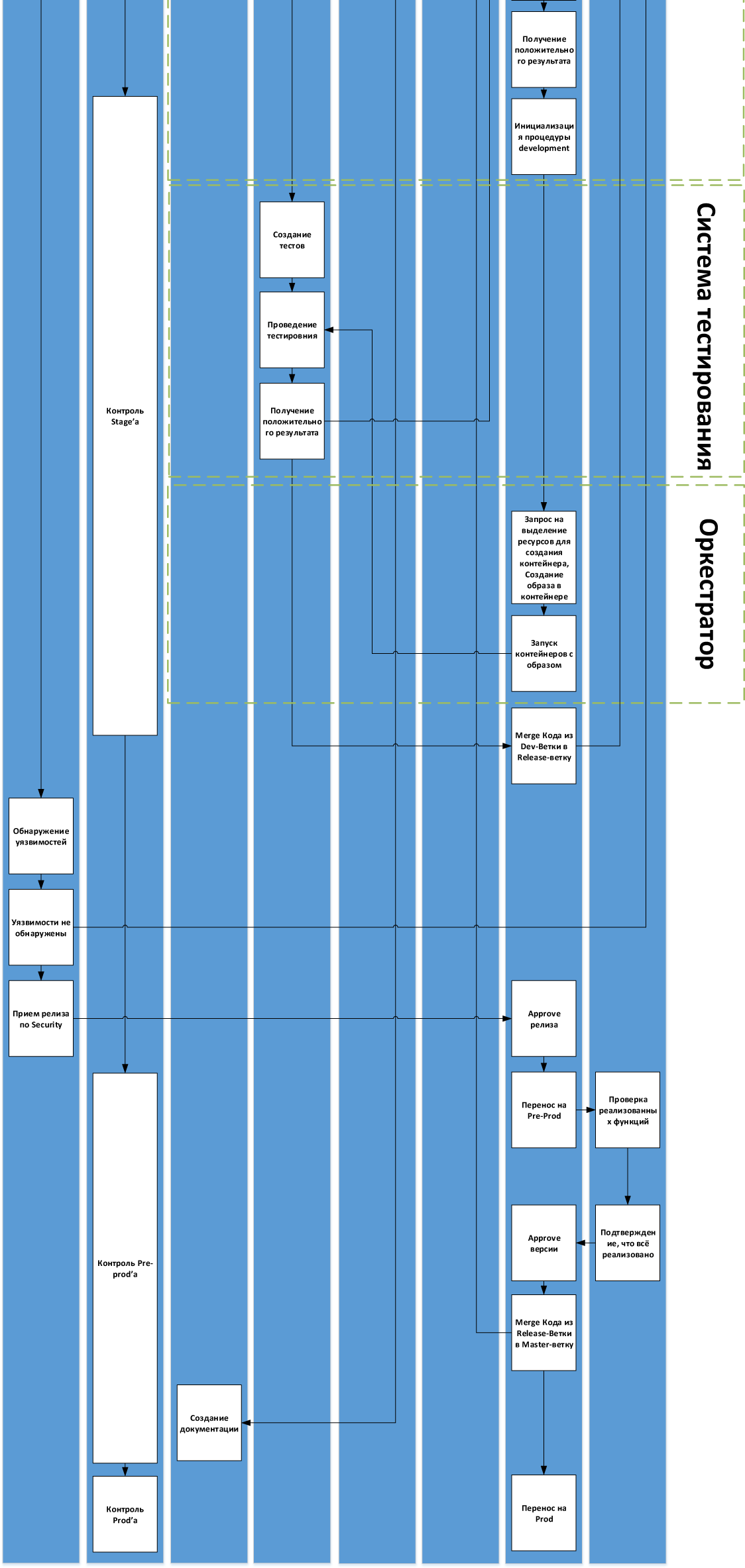
Собственно, первый вопрос — расскажите, пожалуйста, где какие грабли у вас были, и насколько универсальна или нет эта схема. Если вы используете воркфлоу, очень отличающийся от этого — то добавьте пару слов, почему так, пожалуйста.
Что за продукт мы планируем?
Мы решили не копировать Amazon в этом плане, а вести свою разработку с учётом специфики рынка. Сразу оговоримся, что все выкладки — наше субъективное мнение, основанное на нашем анализе. Мы открыты к конструктивному диалогу и готовы менять roadmap продукта.
При анализе существующего pipeline от Amazon мы пришли к выводу, что он обладает колоссальными возможностями, но при этом акцент сделан на очень крупные корпоративные команды. Как нам показалось, выкатить в Docker«е микросервис нужно необоснованно много времени, чем если бы, например, выкатывали в Kubernetes, т.к. имеет место быть настройка внутренних конфигов, определение внутренних соглашений и т.д. и во всем этом нужно долго разбираться.
С другой стороны есть, например, Heroku, где можно деплоить в один клик. Но в силу того, что проекты, как правило, довольно разветвленные, со сторонними микросервисами — в какой-то момент становится нужно выкатывать кастомные docker-образы с DBaaS«шными сервисами и все это в Herocku не особо помещается, потому что либо дорого, либо неудобно.
Мы хотим найти другой вариант. Золотую середину. В зависимости от типа проекта и задач предоставить вам набор уже преднастроенных инструментов, уже интегрированных в единый конвейер, при этом оставить как возможность глубокого изменения настроек, так и возможность замены самих инструментов.
Так что это будет?
Экосистема, включающая в себя портал и набор инструментов и сервисов, позволяющих минимизировать взаимодействие разработчиков с инфраструктурным уровнем. Вы определяете параметры среды, не привязанные к физическому окружению:
- Среда разработки (система управления конфигурациям, система постановки задач, репозиторий для хранения кода и артефактов, таск-трекер)
- CI — Continuous Integration (сборка, инфраструктура и оркестрация)
- QA — Quality Assurance (тестирование, мониторинг и логирование)
- Staging — Среда интеграции / Предрелизный контур
- Production — Продуктивный контур
Выбирая инструменты, мы ориентировались на best-practice на рынке.

Мы будем выстраивать инфраструктуру с Stage«ом и Prod«ом, с использованием Docker и Kubernetes с параллельно запиливанием фич.
Это будет происходить итерационно — на первом этапе запланирован сервис, который позволит брать Docker-файл из проекта, после чего собрать требуемый контейнер и раскладывает их Kubernetes.
Также мы планируем уделять особое внимание сервису по контролю процесса разработки и непрерывной поставки. Что мы понимаем под этим сервисом? Это возможность сформировать иерархическую модель KPI с показателями типа % покрытия юнит-тестами, среднее время устранения инцидента или дефекта, среднее время от коммита до поставки и т.д.
Сбором исходных данных из разных систем — систем управления тестированием, управления задачами, компонентов CI/CD, средств мониторинга инфры и т.д
А самое главное — это показать в адекватном, доступном для быстрого анализа виде — дашборды с возможностью дриллдауна, сравнительного анализа показателей.
Что мы хотим сделать
Собственно, от вас мне бы очень хотелось услышать мнение по поводу всего вот этого и наших планов по шагам. Сейчас они такие:
- Инфраструктура и оркестрация — Docker & Kubernetes
- Постановка задач, хранение кода и артефактов, task-tracker — Gitlab, Redmine, S3
- Производство и разработка — Chef / Ansible
- Сборка — Jenkins
- Тестирование — Selenium, LoadRunner
- Мониторинг и логирование — Prometheus & ELK
- Кстати, а как вы смотрите на то, если в рамках платформы будет возможность выбора — захотел, выбрал Jenkins, не захотел — GitLab Runner?
- Или же не важно, что внутри, главное, чтобы всё как надо билдилось, тестилось и деплоилось?
Как можно помочь?
Продукт будет развиваться для отечественных разработчиков. Если вы сейчас расскажете нам, как лучше сделать, с высокой вероятностью это войдёт в релиз.
Прямо сейчас расскажите, пожалуйста, какие стеки вы используете. Можно — в комментах или письмом на почту team@ts-cloud.ru.
Дальше мы будем держать вас в курсе разработки — и в какой-то момент дадим помогавшим участникам доступы в бету (по сути, бесплатный доступ к хорошим вычислительным ресурсам облака в обмен на обратную связь).
