Мы хотим, чтобы сервера падали одновременно
К нам обратился заказчик из сфера развлекательного видеостриминга с интересной проблемой — у него сервера падали не одновременно. А очень хотелось бы добиться синхронности.
Сервера, которые смущали заказчика работали в роли бэкенда для хранения видеофайлов. По сути, это было множество узлов, содержащих десятки терабайт видеофайлов, которые предварительно были нарезаны в разном разрешении конвертерами. Затем, все эти миллионы файлов отдавались во внешний мир с помощью nginx + kaltura, что позволяло перепаковывать на лету mp4 в сегменты DASH/HLS. Это позволяло хорошо переносить даже высокие нагрузки, отдавая плеером только нужные сегменты без резких всплесков.
Проблемы появились тогда, когда встал вопрос с георезервированием и масштабированием при росте нагрузок. Сервера внутри одной группы резервирования умирали не синхронно, так как представляли были весьма разнообразным зоопарком с разными провайдерами, шириной канала, дисками и RAID-контроллерами. Нам предстояло провести аудит всей этой красоты и перестроить почти с нуля весь мониторинг с методологией управления ресурсами.
Особенности архитектуры
Первый же вопрос, который возник у нас при аудите, почему не использовался полноценный коммерческий CDN? Ответ оказался весьма прозаичен — так дешевле. Архитектура видеохранилища позволяла достаточно хорошее горизонтальное масштабирование, а относительно стабильный трафик позволял делал аренду железных серверов с хорошим каналом более выгодным решением, чем сторонние коробочные решения. Платный CDN был все-таки настроен, но с петабайтными масштабами отдачи контента он был весьма дорог для заказчика и подключался только в аварийных ситуациях. Такое случалось редко, так как в большинстве случаев рост числа посетителей прогнозировался заранее, что позволяло неторопливо заказать еще один сервер и добавить в перегруженную группу.
Весь видео-контент был разделен на десятки групп. Каждая группа содержала в себе 3–8 серверов с идентичным контентом. При этом, каждая группа кроме последней работала полностью в режиме read-only. Схема выглядела весьма работоспособно, но было несколько очень неприятных моментов:
Сервера были разными. Нет, даже не так. Сервера были ЗООПАРКОМ. Политика диверсификации требовала иметь нескольких независимых друг от друга поставщиков с множеством локаций по всему миру. Естественно, железо арендовалось в разное время, с разными дисками, RAID-контроллерами и даже разной шириной канала.
По ряду причин, на этом этапе было невозможно обеспечить полноценную балансировку нагрузки между серверами с health-check. То есть, если один сервер из кластера падал, то пользователи все равно получали его IP адрес в DNS. До ручного снятия нагрузки, часть пользователей продолжала тыкаться в мертвый узел и получала ошибки при загрузке контента.
Из-за того, что в одной группе могли соседствовать сервера с каналом в 1 и 10 гигабит/с, было совершенно непонятно, когда уже пора докупать новые мощности.
В итоге, как потом выяснилось, в какие-то группы сервера докупались избыточно, а в какие-то наоборот.
Сервера падают по очереди
При анализе мы разделили сервера на две большие группы:
Группа серверов с небольшим лимитом upload bandwidth (1G-2.5G)
Группа серверов с большим лимитом upload bandwidth (10G)
Проблема заключалась в том, что иногда случались инциденты. Один из последних выглядел как множество внезапных азиатских пользователей, которые начинали тащить десятками гигабит весь доступный контент. Все это совпало с тем, что один из мощных узлов в группе находился в нерабочем состоянии из-за вылетевшего диска и длительной пересборки массива.
Первыми сдались серверы, которые имели самый широкий канал, упершись в IOPS. При этом, узлы с небольшим каналом отключались позже, но уже по причине лимитов по пропускной способности сети. У заказчика были инструменты для перераспределению трафика между серверами, но применялись они скорее эмпирически. Сравнивать узлы между собой было очень сложно.
Таким образом, мы получили две основные группы:
WAN-limited server group
К этой группе относятся сервера с пропускной способностью менее 2.5G. Порог определен эмпирически при анализе пиковых значений.
При росте нагрузки до критической эти сервера никогда не достигают критических значений CPU iowait — DoS происходит из-за перегрузки сети. При этом внутри этой группы отказ происходит при разной нагрузке — 1G уйдет в DoS раньше, чем 2G. Использовать показатель трафика в чистом виде без нормализации невозможно.
IOPS-limited server group
К этой группе относятся сервера с пропускной способностью более 2.5G.
При росте нагрузки до до критической эти сервера никогда не достигают критических значений upload traffic — DoS происходит из-за перегрузки дисковой подсистемы.
Давайте нормализуем!
В случае, если все данные представлены в разных масштабах, нам надо их нормализовать перед тем, как что-то с ними делать. Именно поэтому, мы сразу решили отказаться на основном дашборде от абсолютных значений. Вместо этого мы выделили два показателя и разметили его от 0 до 100%:
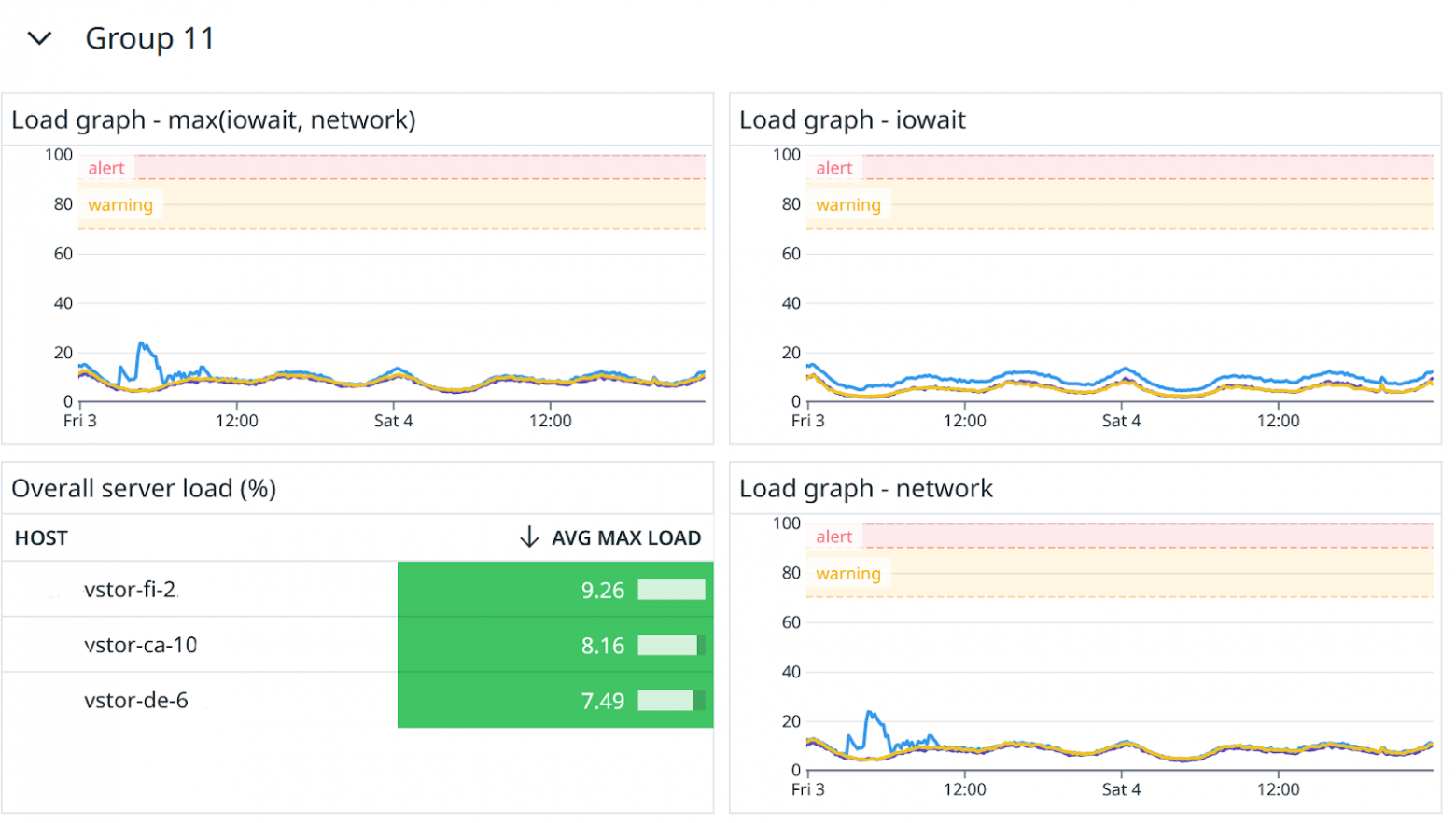
Значение cpu iowait — хорошо показывает перегрузку дисковой подсистемы. Мы эмпирически вывели по историческим данным, что системы заказчика приемлемо функционируют примерно до тех пор, пока iowait ниже 60%.
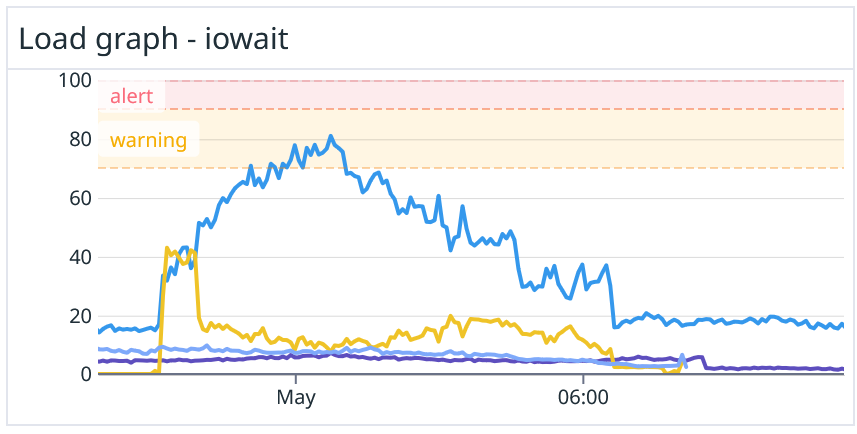
Ширина канала. Здесь тоже все прозрачно — как только нагрузка доходит до лимита, пользователи начинают страдать из-за ограничений на стороне провайдера.
За 100% мы приняли состояние, когда сервер добрался до своего лимита по IOPS или каналу и ушел в DoS.
Нормализация по IOPS
Нормализация по ширине канала
Таким образом, шкала стала относительной, и мы стали видеть, когда сервер стал упираться в свои лимиты. При этом, совершенно неважно, 1 это гигабит или 10 — данные теперь стали нормализованы.
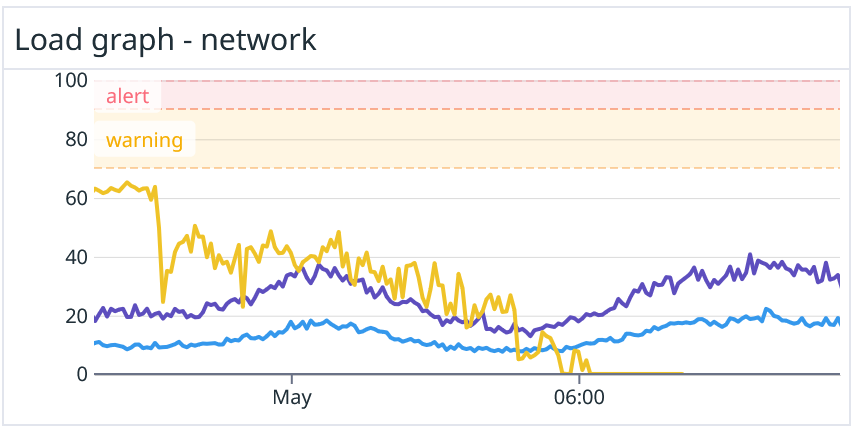
Возникла вторая проблема — сервер может отказать по любой из двух причин, а при финальной диагностике нужно учитывать обе. Добавили еще один слой абстракции, который показывал наихудшее значение по любому из ресурсов.
Что у нас получилось
Мы получили многослойный бутерброд из формул, который совершенно не показывал реальную абсолютную нагрузку на сервер, но зато точно предсказывал, когда именно он откажет.
Представьте себе упряжку, где есть сильные и слабые ездовые собаки. Нам совершенно неважно, сколько именно лошадиных сил (или собачьих?) выдает каждая из них. Нам нужно, чтобы вся повозка ехала равномерно, а каждая из собак была нагружена в равной степени в зависимости от своих возможностей.
В итоге получили вот что:
Автоматизировали весь процесс добавления новых узлов с помощью terraform/ansible с одновременной генерацией дашбордов, которые учитывают физические ограничения каждого сервера в формулах расчета при нормализации.
Подготовили качественную модель, которая позволила добавлять новые узлы в нужный момент без ситуаций «три сервера нагружены наполовину, а четвертый уже лежит».
Сервера действительно стали падать совершенно синхронно. Реальный тест случился некоторое время спустя при мощном DDoS со стороны ботов-парсеров. Нагрузка почти одновременно уткнулась на всех узлах в свои лимиты — где-то в IOPS, где-то в ширину канала.
Заказчик смог сохранить свою модель расширения инфраструктуры с использованием разнородного по мощности оборудования.
В целом, это не было идеальным решением с точки зрения архитектуры, но оно быстро и оптимально закрывало основные проблемы, позволив добиться максимально полной утилизации уже имеющихся ресурсов. В дальнейшем, мы продолжили рефакторинг, внедрили кеширование с bcache, увеличив в десятки раз производительность отдельных узлов, но об этом я расскажу в другой раз.
Ну, а если вам нужно перебрать вашу инфраструктуру по винтику, настроить мониторинг и полностью все автоматизировать, приходите к нам в WiseOps. Мы поможем.
