Может ли ChatGPT заменить визит к врачу? Проверяем эффективность ChatGPT в определении диагноза и выборе лечения
Сейчас люди многие важные проблемы решают с использованием сил искусственного интеллекта, однако вопросы здоровья всегда стоят остро и требуют большей квалификации.
Возможно ли заменить визит к врачу обращением к ChatGPT? Наверняка у многих есть плачевный опыт использования Google, когда на простые симптомы пищевого отравления Вам предоставляли всевозможные разновидности рака в качестве вероятного диагноза.
Есть ли шанс избежать этой проблемы и получить правильные рекомендации по перспективам обследований и вариантами лечения (с формулированием нескольких наиболее реалистичных диагнозов!)?
В данной статья я расскажу о тестировании ChatGPT в качестве квалифицированного специалиста в постановке верного диагноза, определении списка необходимых обследований и пути лечения. Ниже будут подробно представлены все методы исследования и его результаты!
Приятного прочтения :)
Введение в исследование
Языковые модели, такие как ChatGPT, первоначально не разрабатывались для медицинских целей, но исследования указывают на их потенциал в этой сфере. ChatGPT смог успешно пройти экзамен USMLE, необходимый для получения медицинской лицензии в США. Это открывает путь к применению ИИ для поддержания деятельности врачей и помощи пациентам.
В новом исследовании ученые сосредоточились на оценке точности GPT-3.5 и GPT-4, в трех основных задачах: постановке первичного диагноза, предоставлении рекомендаций по необходимым обследованиям и выборе лечения. Особое внимание уделяется редким заболеваниям, которые, хотя и встречаются нечасто, в совокупности затрагивают значительную часть населения и требуют диагностической поддержки.
Исследование использует клинические описания, адаптированные для непрофессионалов и выведенные из лицензированных источников, что уменьшает вероятность того, что ChatGPT был заранее обучен на этих данных.
Исследователи также сравнивали возможности ИИ с поисковой системой Google и оценивали открытые модели, такие как Llama 2, отмечая их превосходство в задачах общего чата.
В целом, исследование направлено на всестороннюю оценку возможностей последних языковых моделей в облегчении диагностики и лечения заболеваний разной степени распространенности, что может революционизировать медицинскую практику и предоставить врачам мощный инструмент для улучшения качества и доступности медицинского обслуживания. Помимо улучшения диагностики, ИИ может помочь врачам в интерпретации сложных медицинских изображений, управлении данными пациентов и предоставлении персонализированных рекомендаций по лечению.
Методы исследования
Отбор отчетов о клинических случаях
Для проведения исследования были изучены истории болезни, опубликованные в немецких сборниках двух издательств: Thieme и Elsevier. Основными клиническими сферами были хирургия, неврология, гинекология и педиатрия. Также были добавлены еще два сборника клинических случаев от Elsevier, посвященные редким заболеваниям и общей медицине, чтобы дополнительно включить случаи заболеваний с очень низкой частотой и в амбулаторных условиях. В результате отбора было отобрано 1020 кейсов.
Для изучения производительности ChatGPT в зависимости от частоты заболеваний, случаи были разделены на три подгруппы: заболевание считалось частым или менее частым, если его частота превышала 1:1000 или 1:10,000 в год соответственно. Заболевание считалось редким, если частота была ниже 1:10,000. Если информация о частоте не была доступна, заболевание считалось редким. Расчеты мощности были проведены для определения размера выборки в 33–38 случаев на подгруппу, чтобы достичь общей мощности 0,9.
Для ограничения объема последующего анализа была проведена случайная выборка 40% от общего числа 1020 случаев, что обеспечило равномерное распределение источников, в результате чего было изучено 408 случаев.
Отбором случаев для дальнейшего анализа занимались специалисты. Включались только те случаи, которые удовлетворяли следующим требованиям: (1) пациент или кто-либо другой может предоставить информацию об истории болезни (например, исключая пациентов с тяжелой травмой), (2) фотографии не требуются для диагностических целей, (3) диагноз не слишком полагается на лабораторные исследования, (4) дело не является дубликатом.
Шаги 2 и 3 были необходимы, так как задача диагностики заключалась только в оценке первоначального диагноза, при котором у пациента нет никаких визуализационных или лабораторных данных. В общей сложности было выявлено 153 случая, соответствующих установленному критерию включения.
Чтобы обеспечить сбалансированное представительство, исследователи стремились включить одинаковое количество случаев по каждому медицинскому направлению, принимая во внимание как частотные показатели заболеваемости, так и источник публикации, в результате чего был сделан окончательный набор из 110 случаев.
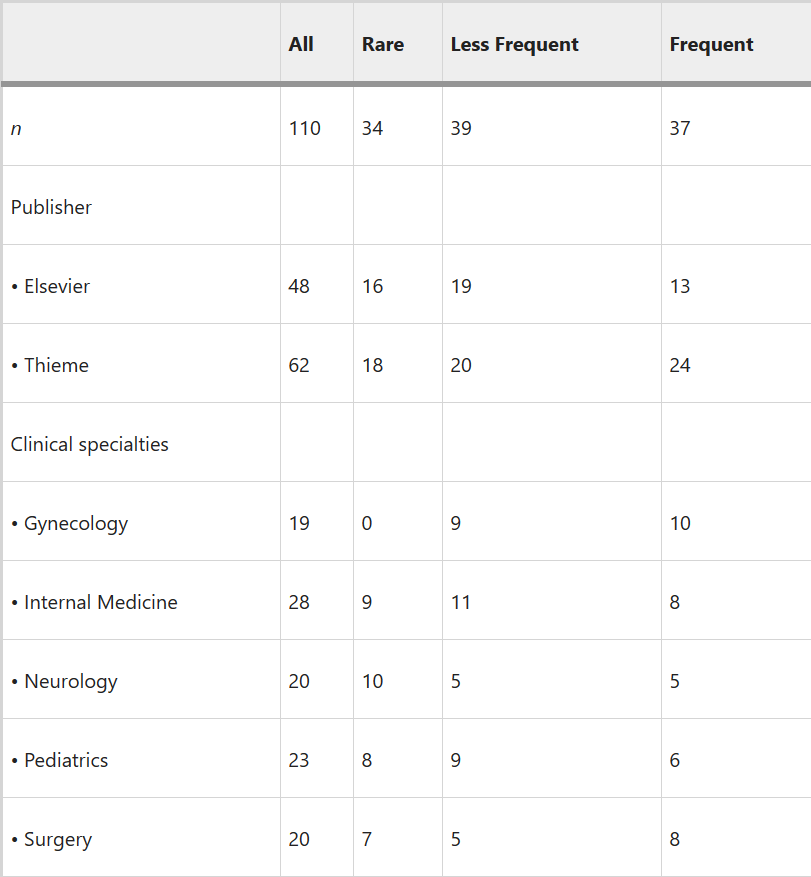
Для того, чтобы имитировать реальную ситуацию пациента, случаи обрабатывались на языке непрофессионалов. История болезни была представлена от первого лица, содержала только общую информацию и избегала терминологии клинических экспертов.
Запрос GPT-3.5 и GPT-4
Для формирования запросов пациентов план анализа выглядит следующим образом:
Откройте новый диалог ChatGPT;
Предполагаемый диагноз: Запишите историю болезни пациента и текущие симптомы, добавьте «Каковы наиболее вероятные диагнозы? Назовите до пяти штук»;
Варианты обследования: «Какие наиболее важные обследования следует рассмотреть в моем случае? Назовите до пяти штук»;
Откройте новой диалог ChatGPT;
Варианты лечения: Запишите историю болезни пациента и текущие симптомы и добавьте: «Мой врач поставил мне диагноз (конкретный диагноз X). Какие методы лечения являются наиболее подходящими в моем случае? Назовите до пяти штук».
Запрос Google
Был проведен поиск симптомов, наиболее вероятный диагноз был определен на основе первых 10 результатов, о которых сообщил Google. Поиск, извлечение и интерпретация осуществлялись немедицинским специалистом, имитирующим ситуацию пациента.
Оценивалась только информация, доступная на веб-сайтах. Дальнейший подробный поиск по конкретному диагнозу не проводился, если, например, на веб-сайте была предоставлена лишь ограниченная информация о характеристиках заболевания.
Дальнейшее исследование с использованием Llama 2
Ученые использовали Llama 2 с двумя разными размерами модели: Llama-2–7b-chat (Ll2–7B с 7 миллиардами параметров) и Llama-2–70b-chat (Ll2–70B с 70 миллиардами параметров). Запросы пациентов были сгенерированы аналогично GPT-3.5 и GPT-4: начиная с системной подсказки «Вы — полезный ассистент», за которой следовал формат запроса, согласующийся с использованным для GPT.
Все запросы были сформулированы с определенными параметрами: установка температуры 0.6, top_p установлено в 0.9, и максимальная длина последовательности 2048.
Оценка эффективности
Оценка ответов, полученных с помощью GPT-3.5, GPT-4, Google, Ll2–7B и Ll2–70B, проводилась двумя независимыми врачами. Каждый врач оценивал клиническую точность по 5-балльной шкале Лайкерта в соответствии с таблицей. Окончательный балл рассчитывается как среднее арифметическое двух отдельных баллов.

Для определения надежности оценок разными специалистами были рассчитаны взвешенные коэффициенты каппа Коэна и 95% доверительные интервалы для каждой из трех задач с использованием пакета R DescTools 0.99.54.
Для исследования производительности GPT-3.5, GPT-4 и Google была проведена независимая оценка диагностики, вариантов обследования и лечения. Производительность GPT-3.5 по сравнению с GPT-4 оценивали с помощью одностороннего теста Манна-Уитни. Для постановки диагноза дополнительно были проведены парные односторонние тесты Манна-Уитни, сравнивающие GPT-3.5 с Google и GPT-4 с Google. Возможное влияние частоты встречаемости исследовалось с помощью непарного одностороннего теста Манна-Уитни.
Тест Манна-Уитни, также известный как тест Вилкоксона, является непараметрическим методом статистического тестирования, который используется для сравнения двух независимых выборок. Он предназначен для определения, существуют ли значимые различия между двумя группами в отношении их центральной тенденции (например, медианы).
Результаты исследования
Межоценочная надежность
*Межоценочная надежность — это статистический показатель, который используется для определения степени согласованности между разными оценщиками. Он необходим, чтобы определить насколько согласуются различные версии языковых моделей ИИ при постановке диагноза, рекомендации обследований и выборе лечения.
В качестве меры межоценочной надежности исследователи использовали коэффициент Каппа Коэна (k). Он учитывает возможность случайного согласия, и поэтому считается более надежным, чем простой процент совпадений. Кроме того, коэффициент может варьироваться от 0 (полное несогласие) до 1 (полное согласие). В соответствии с разработанной классификацией, разные значения оцениваются как:
0,81–1,00 — почти идеальное согласие;
0,61–0,80 — существенное согласие;
0,41–0,60 — умеренное согласие;
0,21–0,40 — справедливое согласие;
0,00–0,20 — слабое согласие;
< 0,00 — отсутствие согласия.
Что касается постановки диагноза, самые высокие уровни согласия наблюдаются при k=0,8 для GPT-3.5, k=0,76 для GPT-4 и k=0,84 для Google. Грамотные рекомендации по осмотру характеризуется значениями k=0,53 для GPT-3.5 и 0,64 для GPT-4. В отношении лечения наблюдается k=0,67 для GPT-3.5 и k=0,73 для GPT-4.
Согласно классификации результаты соответствует уровню согласия от существенного до почти идеального. Наилучшие показатели относятся к возможности постановки диагноза.

Оценка производительности GPT-3.5, GPT-4 и Google
На рисунке ниже подведены итоги парных сравнений и также показана производительность для каждой из трех подгрупп частоты заболеваний (графики кумулятивной частоты).
Графики кумулятивной частоты — это визуальные инструменты для представления накопленного (кумулятивного) количества случаев или наблюдений, которые соответствуют определенному критерию или попадают в определенную категорию. Эти графики показывают, как накапливаются данные при движении вдоль одной из осей.
На таких графиках обычно по оси Y отображается кумулятивное количество случаев, а по оси X — значения, по которым происходит кумуляция, например, оценки точности. Использование разных оттенков цвета на графике может помочь визуально разделить данные на подгруппы, например, по частоте возникновения заболеваний:
Светло-синий цвет обозначает редкие заболевания;
Средне-синий цвет — менее частые;
Темно-синий цвет — частые заболевания.
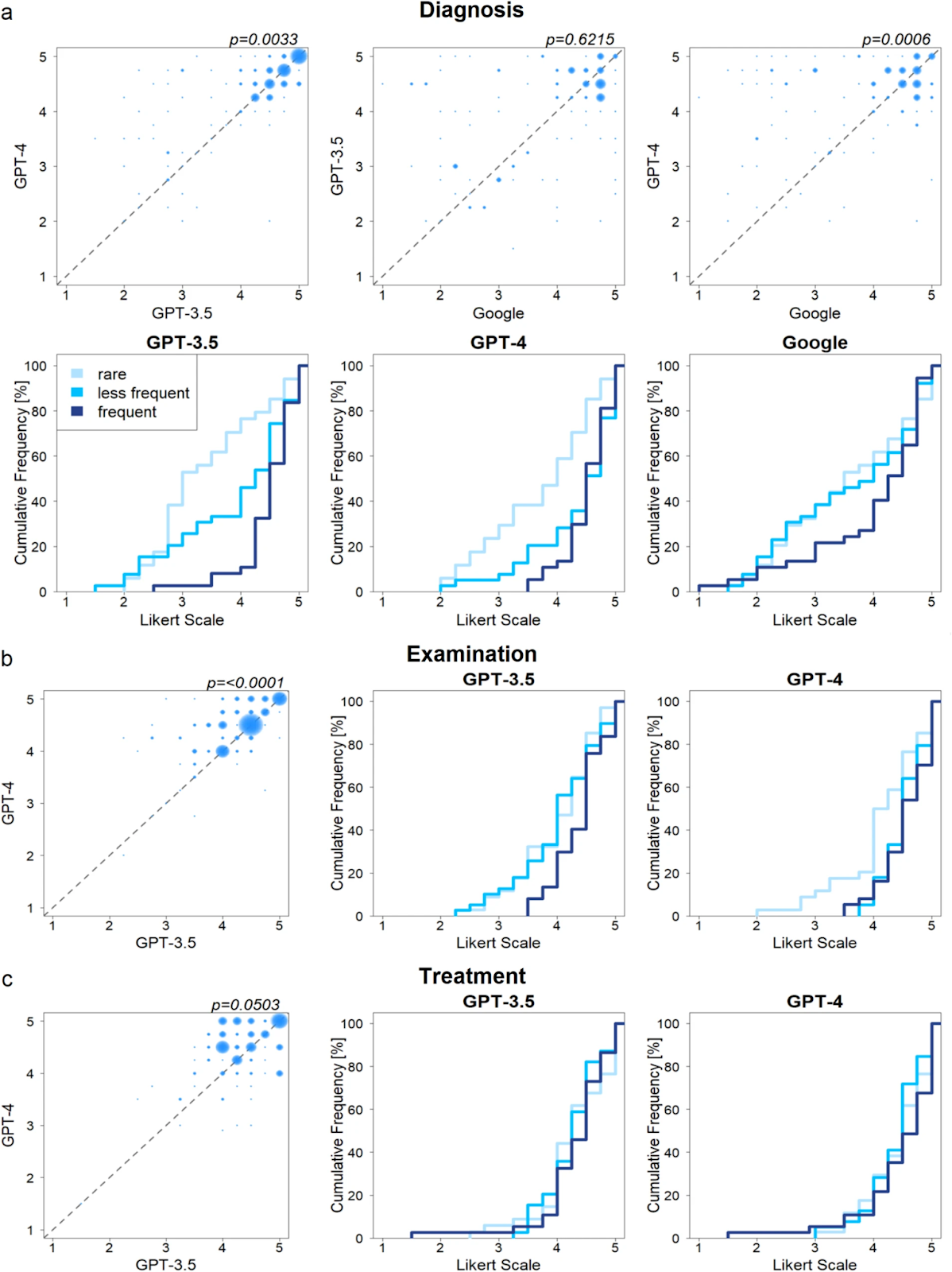
Рис. 4: a) Сравнение производительности моделей в выборе диагноза. b) Сравнение производительности моделей в приведении рекомендаций по осмотру (точное скорректированное p = 3.2241·10^-6). c) Сравнение производительности моделей в подборе лечения. Пузырьковые диаграммы показывают попарное сравнение двух подходов. Графики кумулятивной частоты показывают кумулятивное количество случаев (по оси Y) и их оценки точности (по оси X) для каждой подгруппы частоты заболеваний (светло-синий: редкие, средне-синий: менее частые, темно-синий: частые). Для статистического тестирования применялся односторонний тест Манна-Уитни (с учетом поправки Бонферрони для множественного тестирования, учитывая n = 12 тестов для диагностики, n = 7 тестов для осмотра и лечения).
Распределение производительности всех моделей для различных задач обобщено с помощью столбчатых диаграмм и скрипичных графиков:
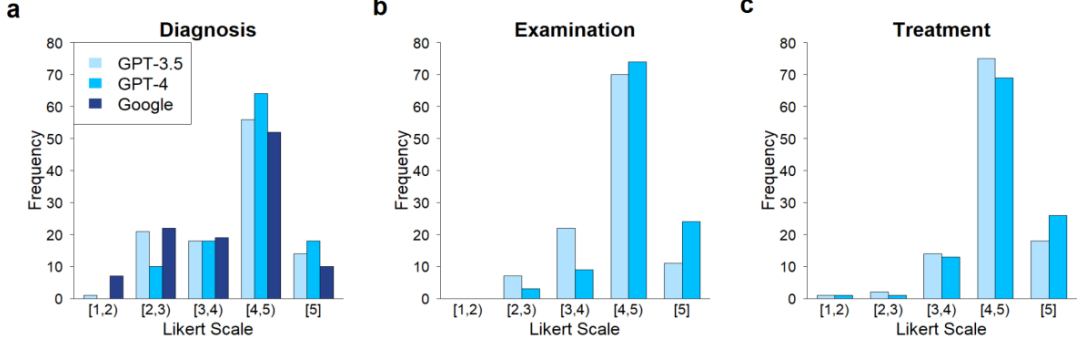
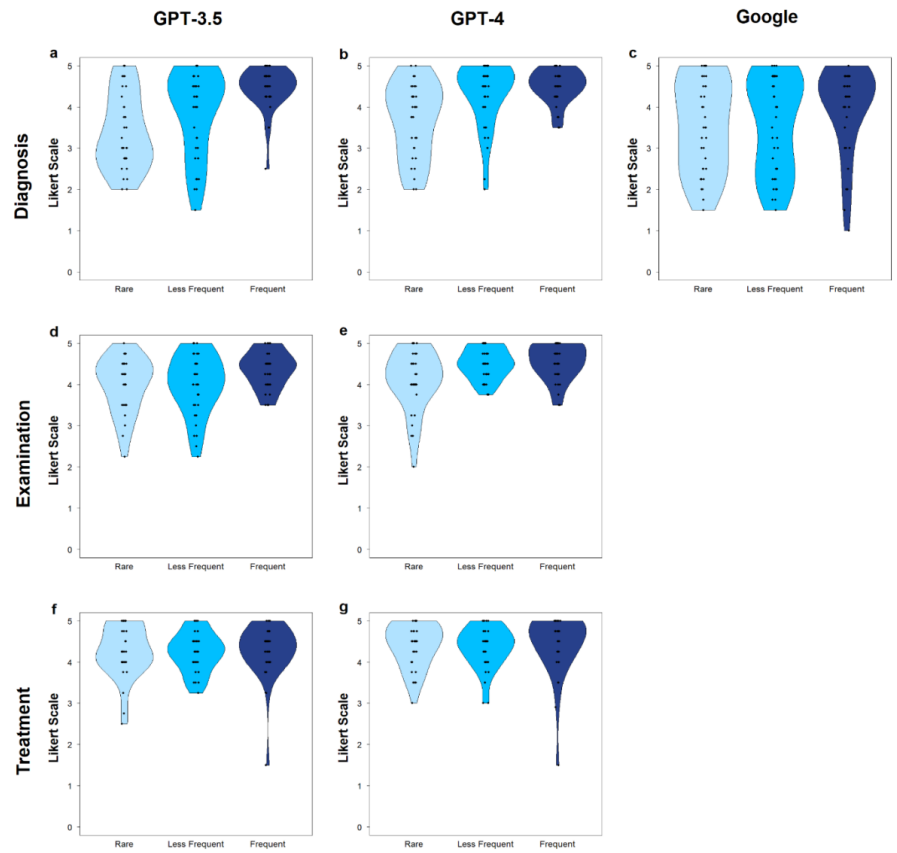
Что касается постановки диагноза, то были оценены все три инструмента. Попарное сравнение показало достоверно лучшую производительность GPT-4 (медиана: 4,5, IQR = [3,81; 4,75]) против как GPT-3.5 (медиана: 4,25, IQR = [3,0; 4,75], p = 0,0033), так и Google (медиана: 4,0, IQR = [2,75; 4,75], p = 0,0006). Тем не менее, значимой разницы между GPT-3.5 и Google не наблюдалось.
Учитывая частоту заболеваний, графики на рисунке 4а показывают постоянно лучшую производительность для частых в сравнении с редкими заболеваниями. Это наблюдение было сделано для всех инструментов (темно-синяя линия — частые — поднимается круче по сравнению со светло-синей линией — редкие). GPT-3.5 значимо лучше справлялся с частыми по сравнению с редкими заболеваниями (p < 0,0001), в то время как GPT-4 показал значимые результаты как для частых, так и редких (p = 0,0003), а также для менее частых и редких (p = 0,0067). Для Google различия между редкими и менее частыми заболеваниями не наблюдались.
Рассматривая возможности рекомендаций для обследований, сравнили GPT-4 (медиана: 4,5, IQR = [4,0; 4,75]) и GPT-3.5 (медиана: 4,25, IQR = [3,75; 4,5]). Попарное сравнение показало превосходные характеристики GPT-4 (p < 0,0001). Оценивая эффективность двух моделей в отношении частоты заболеваний, результаты показали эффективность GPT-3.5 в отношении частых заболеваний. Однако эти результаты не были значимыми. GPT-4 показал сопоставимую производительность как при частых, так и при менее частых заболеваниях, но значительно лучшую производительность по сравнению с редкими (p = 0,0203).
Что касается способности предоставления вариантов лечения, проводилось сравнение эффективности GPT-4 (медиана, 4,5, IQR = [4,0; 4,75]) и GPT-3.5 (медиана: 4,25 (IQR = [4,0; 4,69]). В данной ситуации наблюдалось меньше различий. Результаты на рисунке 4с показали лучшую, но не значимую производительность GPT-4 (p = 0,0503). Какого-либо влияния частоты заболеваний на работоспособность не наблюдалось.
Сравнение с Llama 2
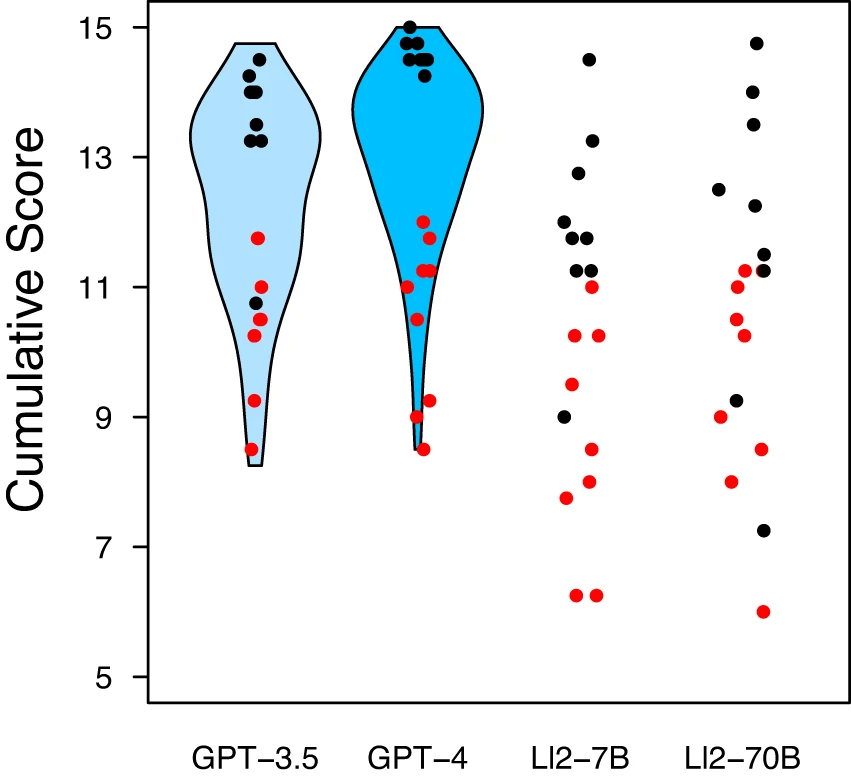
На рисунке ниже визуализирована производительность GPT-3.5 и GPT-4 со скрипичными графиками, учитывающими все 110 случаев, и точками, подчеркивающими производительность 18 выбранных случаев по сравнению с Llama-2–7b-chat (Ll2–7B) и Llama-2–70b-chat (Ll2–70B).
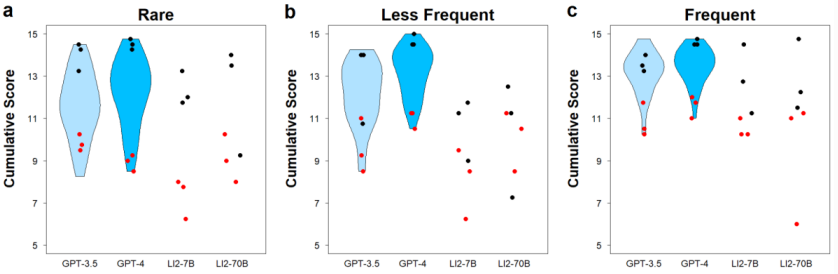
Производительность всех моделей, разделенных по частоте заболеваний, приведена ниже.
Медианные оценки и межквартильные диапазоны для девяти лучших случаев были 14,5 [14,5; 14,75], 14,0 [13,25; 14,0], 12,25 [11,25; 13,5] и 11,75 [11,25; 12,75] для GPT-4, GPT-3.5, Ll2–7B и Ll2–70B соответственно. Аналогично, для девяти худших случаев оценки составили: 11,0 [9,25; 11,25], 10,25 [9,5; 10,5], 10,25 [8,5; 11,0] и 8,5 [7,75; 10,25].
В целом, можно наблюдать несколько худшую производительность открытых языковых моделей по сравнению с GPT-3.5 и GPT-4. Кроме того, нет заметной разницы в производительности между двумя конфигурациями открытых языковых моделей.
Вывод
Данное исследование продемонстрировало, что модели искусственного интеллекта, такие как GPT-3.5 и GPT-4, показывают значительный прогресс в производительности по сравнению с наивным поиском в Google при поддержке принятия клинических решений. Однако даже при высоких медианных показателях эти модели не всегда могут достичь положительных результатов в сложных задачах, например, в первоначальной диагностике.
Также важно отметить, что использование Llama 2, может потребовать тонкой настройки и обновлений для поддержания высокой производительности в медицинских сценариях. Такие модели, несмотря на небольшие улучшения производительности, могут быть более непостоянными в сравнении с коммерческими аналогами, такими как ChatGPT.
Авторами основного исследования являются Sarah Sandmann и Sarah Riepenhausen: https://www.nature.com/articles/s41467–024–46411–8
Также Вы можете прочитать мою прошлую статью о возможности применение GPT-4 для РНК-секвенирования: https://habr.com/ru/companies/bothub/articles/805869/
На этом все!
Спасибо за прочтение! Будем ждать Вас в комментариях :)
