Мифы о Spark, или Может ли пользоваться Spark обычный Java-разработчик
Итак, Евгений EvgenyBorisov Борисов о Spark, мифах и немного о том, дествительно ли тексты Pink Floyd адекватнее, чем у Кэти Пэрри.
Это будет необычный доклад о Spark.
Обычно много рассказывают про Spark, какой он крутой, показывают код на Scala. Но у меня немного другая цель. Во-первых, я поговорю о том, что такое Spark и зачем он нужен. Но основная цель — показать, что вы, как Java-девелоперы, можете прекрасно им пользоваться. В этом докладе мы развеем несколько мифов о Spark.
Коротко о себе
Я был Java-программистом с 2001 года.
К 2003 году параллельно начал преподавать.
С 2008 начал заниматься консультациями.
С 2009 года занимался архитектурой разных проектов.
Стартап свой открыл в 2014.
С 2015 года я являюсь technical leader по Big data в компании Naya Technologies, которая внедряет big data везде, где только может. У нас огромное количество клиентов, которые хотят, чтобы мы им помогли. Нам катастрофически не хватает людей, которые разбираются в новых технологиях, поэтому мы постоянно ищем работников.
Мифы о Spark
Мифов о Spark ходит довольно много.
Во-первых, есть какие-то концептуальные мифы, о которых мы поговорим подробнее:
- что Spark — это какая-то примочка для Hadoop-а. Многие слышали, что Spark и Hadoop как бы вместе. Поговорим о том, так ли это;
- что Spark надо писать на Scala. Все, наверное, слышали, что Spark можно писать не только на Scala, но правильно это делать именно на Scala, потому что нативный API и т.д. Мы поговорим, правильно ли это;
- я очень люблю Spring и везде, где только можно, использую пост-процессоры. Будут ли здесь пост-процессоры приносить реально какую-то пользу?
- поговорим о том, что там происходит с тестированием Spark. Поскольку Spark — big data, не очень понятно, как его тестировать. Существует миф, что там вообще нельзя написать тесты, а если и напишешь, то все будет выглядеть совсем не так, как мы привыкли.
Есть еще ряд технических мифов (это для людей, которые со Spark работают или более-менее его знают):
- по поводу Broadcast — что в определенных случаях его обязательно нужно использовать, иначе все грохнется. Поговорим о том, так ли это.
- про датафреймы — Говорят, датафреймы можно использовать только для файлов, у которых есть схема, а мы поговорим о том, можно ли использовать их в иных случаях.
А самый главный миф — это про группу Pink Floyd. Ходит миф, что Pink Floyd пишет (писал) умные тексты, совсем не такие, как Бритни Спирс или Кэтти Пэри. И мы сегодня напишем предложение на Spark, которое поможет проанализировать тексты всех этих музыкантов и выявить в них похожие слова. Попробуем доказать, что Pink Floyd пишет такую же белиберду, как и попсовые исполнители.
Посмотрим, какие из этих мифов получится опровергнуть.
Миф 1. Spark и Hadoop
По большому счету Hadoop является просто хранилищем информации. Это распределенная файловая система. Плюс к нему предлагается определенный набор инструментов и API, при помощи которого эту информацию можно процессить.
В контексте Spark правильнее сказать, что это не Spark нуждается в Hadoop, а наоборот, потому что информацию, которую можно хранить в Hadoop и процессить при помощи его инструментов (сталкиваясь с проблемой быстродействия), быстрее можно процессить при помощи Spark.
Вопрос в том, нуждается ли Spark в Hadoop, чтобы работать?
Вот определение Spark:
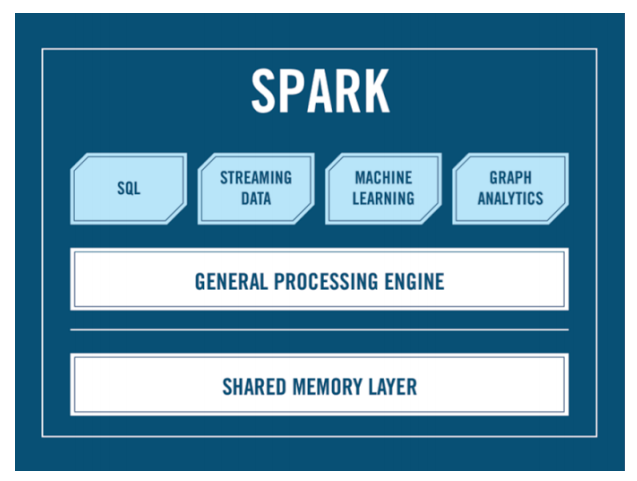
Разве здесь есть слово Hadoop? Тут есть модули Spark:
- Spark Core — это определенный API, который дает возможность процессить ваши данные;
- Spark SQL, который дает возможность писать SQL-подобный синтаксис для людей, хорошо знакомых с SQL (мы про это отдельно поговорим, хорошо это или плохо);
- модуль Machine Learning;
- Streaming, чтобы можно было засовывать информацию при помощи Spark или слушать что-либо.
Но здесь нигде нет слова Hadoop.
Давайте поговорим просто про Spark.
Эта идея зародилась в Университете Беркли примерно в 2009 году. Первый релиз вышел не так давно — в 2012. Сегодня мы находимся на версии 2.1.0 (она вышла в конце 2016 года). На момент озвучивания этого доклада актуальна была версия 1.6.1, но обещали скорый выход Spark 2.0, где почистили API и добавили много новых полезных вещей (нововведения Spark 2.0 здесь не учтены).
Написан сам Spark на Scala, что объясняет миф о том, что использовать Spark лучше при помощи Scala, потому что получается нативный API. Но помимо Scala API существует для:
- Python,
- Java,
- Java 8 (отдельно)
- и R (статистический инструмент).
Писать Spark можно в InteliJ, что я и буду делать сегодня в процессе доклада. Можно использовать Eclipse, и есть еще специальные штуки для Spark — это Spark-shell, который сейчас идет с определенными версиями Hadoop, где вы можете в живую писать команды Spark и получать моментальный результат, и очень похожий на него Notebooks — там еще можно сохранять написанное для повторного использования.
Запускать Spark можно в Spark-shell и Notebooks — там он встроен; можно при помощи команды Spark-submit запустить Spark-приложение на кластер, можно запускать это как обычный Java-процесс (java -jaar и сказать, как называется main и где написан ваш код). Мы сегодня будем в процессе доклада запускать Spark. Для тех задач, которые захотим решить, локальной машины достаточно. Но если бы мы хотели запускать его на кластере, нам понадобился бы cluster manager. Это единственное, что нужно Spark. Поэтому часто и создается иллюзия, что без Hadoop никак, т.к. в Hadoop есть Yarn — кластер менеджер, который можно использовать для распределения задач Spark по всему кластеру. Но есть альтернативный вариант — Mesos — кластер-менеджер, который не имеет никакого отношения к Hadoop. Он существует достаточно давно, и около года назад они получили 70 млн долларов, что говорит о хорошем развитии технологии. В принципе, кто очень не любит Hadoop, может запускать задачи Spark на кластере абсолютно без Yarn и Hadoop.
Скажу буквально два слова про data locality. В чем идея обработки big data, которые находятся не на одной машине, а на большом их количестве?
Когда мы пишем какой-то код, работающий, например, с jdbc или ORM, фактически что происходит? Есть машина, которая запускает Java-процесс, и когда в этом процессе бежит код, обращающийся к базе данных, все данные вычитываются из БД и перегоняется туда, где работает этот Java-процесс. Когда мы говорим про big data, это сделать невозможно, потому что данных слишком много — это неэффективно и у нас образуется горлышко бутылки. Кроме того, data и так уже распределенная и изначально находится на большом количестве машин, поэтому правильнее не data тянуть к этому процессу, а код распределять на те машины, на которых мы хотим эту «дату» обрабатывать. Соответственно, это происходит параллельно на многих машинах, мы задействуем неограниченное количество ресурсов, и вот здесь нам нужен кластер-менеджер, который будет координировать эти процессы.
На этой картинке вы видите, как все это работает в мире Spark.
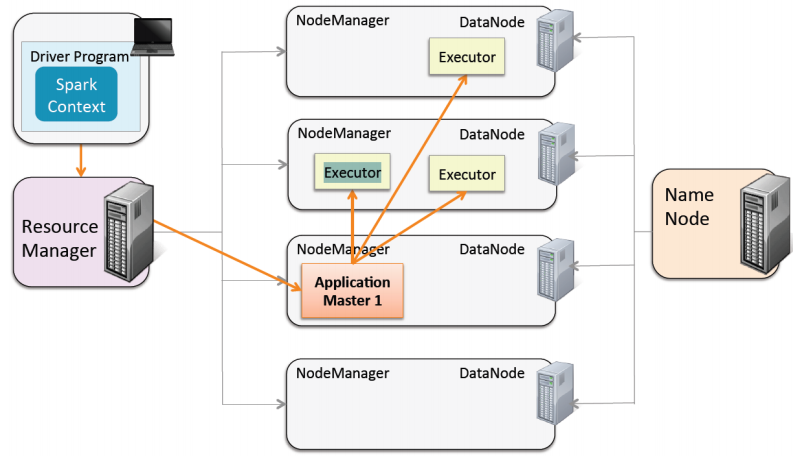
У нас есть Driver — наш main, который запускается на отдельной машине (не имеющей отношения к кластеру). Когда мы сабмитим наше Spark-приложение, мы обращаемся к Yarn, который является ресурс-менеджером. Мы ему говорим, сколько worker-ов задействовать под наш Java-процесс (например, 3). Он из кластерных машин выбирает одну машину, которая будет называться Application Master. Ее задача — получить код и найти в кластере три машины для его выполнения. Находятся три машины, поднимаются три отдельных Java-процесса (три executor-а), где запускается наш код. Потом это все возвращается Application Master, и в конечном итоге он возвращает это напрямую на Driver, если мы хотим результат операции над big data получить обратно туда, откуда код вышел.
Это напрямую не связано с тем, о чем я сегодня буду говорить. Просто в двух словах о том, как Spark работает с Cluster Manager (в данном примере с Yarn) и почему мы не ограничены в ресурсах (разве что в денежных — сколько мы можем позволить себе машин, памяти и т.д.). Это все немного похоже на классический MapReduce — старый API, который был в Hadoop (в принципе он есть и сейчас), с той только разницей, что когда этот API писался, машины были недостаточно сильными, промежуточные результаты данных можно было хранить только на диске, потому что в оперативной памяти не было достаточно места. Поэтому все это работало медленно. В качестве примера могу сказать, что мы недавно переписали код, который был написан на старом MapReduce и он бежал в районе 2,5 часов. Сейчас он работает 1,5 минуты на Spark, поскольку Spark хранит все в оперативной памяти — намного быстрее получается.
Очень важно понимать, когда вы пишите код, что одна его часть будет исполняться на кластере, а другая — на Driver-е. У людей, которые этого не понимают, очень часто случаются всякие OutOfMemory и т.д. (мы про это поговорим — я покажу примеры этих ошибок).
Итак, Spark… поехали
RDD (resilient distributed dataset) — это основной компонент, на котором работает весь Spark.
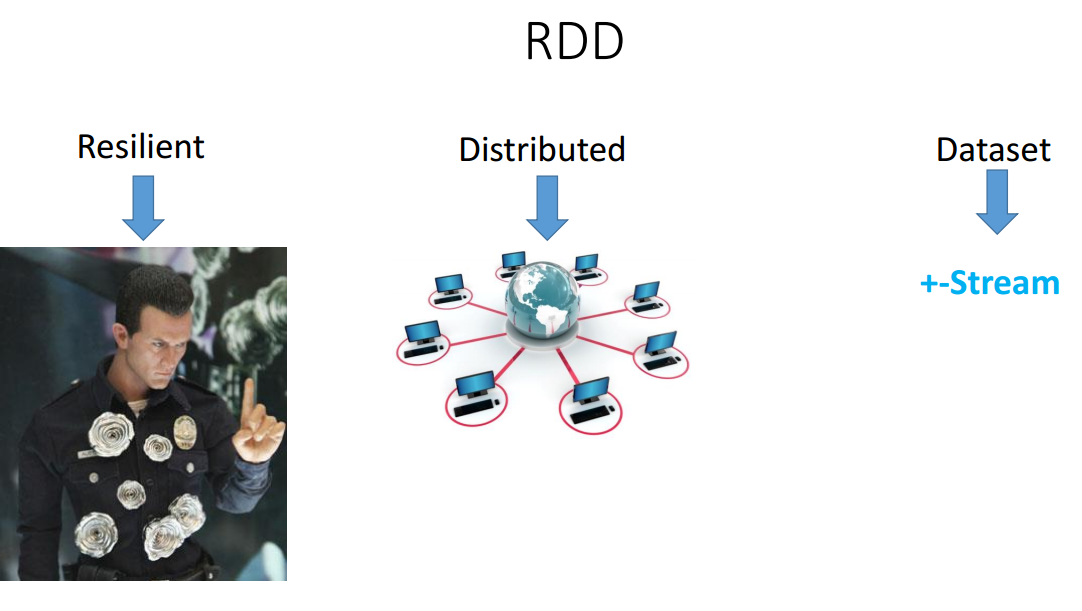
Давайте начнем с термина dataset — это просто хранилище информации (Collection). У него API очень похож на Stream. По сути, как и Stream, он не является хранилищем данных, а некой абстракцией на данными (в данном случае ещё и распределёнными) и позволяет запускать на эти данные всякие функции. В отличие от Stream, RDD изначально Distributed — находится не на одной машине RDD, а на том количестве машин, которое при запуске Spark мы разрешили использовать.
Resilient говорит том, что его не убьешь, потому что если какая-то машина в процессе обработки данных отключилась (что-то там случилось, например, вырубили свет), кластер-менеджер сможет поднять другую машину и передиплоить туда java-процесс, и RDD восстановится. Мы даже этого не почувствуем.
Откуда можно получить RDD?
- самый распространенный вариант — из файлов или директории, в которой есть файлы определенного типа. Я могу из какого-то файла создать RDD (точно также как для Stream нужен источник данных);
- из памяти — из какого-то collection или list. Это чаще всего используется для тестов. Например, написал я какой-то сервис, который принимает на вход RDD с какими-то начальными данными и на выходе отдает RDD с обработанными данными. Когда я это буду тестировать, я не захочу реально с диска читать данные. Мне захочется в тесте создать какой-то collection. У меня есть возможность превратить этот collection в RDD и тестировать свой сервис;
- из другого RDD точно так же, как стримы. Большинство методов стримов возвращает stream обратно — все очень похоже.
Вот несколько примеров, как мы создаем RDD:
// from local file system
JavaRDD rdd = sc.textFile("file:/home/data/data.txt");
// from Hadoop using relative path of user, who run spark
application
rdd = sc.textFile("/data/data.txt")
// from hadoop
rdd = sc.textFile("hdfs://data/data.txt")
// all files from directory
rdd = sc.textFile("s3://data/*")
// all txt files from directory
rdd = sc.textFile("s3://data/*.txt")
Мы чуть позже обсудим, что такое sc (это такой стартовой объект Spark). Здесь мы создаем RDD:
- из текстового файла, который лежит в локальной директории (никакого отношения к Hadoop тут нет);
- из файла по реляционному пути;
- с Hadoop-а — тут я беру файл, который находится в Hadoop. Он на самом деле разбит на куски, но он соберется в один RDD. Скорее всего RDD будет располагаться на тех машинах, где находится эта data;
- можно прочитать с s3 storage, можно использовать всякие wildcard или взять только текстовые файлы из директории data.
Что в этом RDD будет? Здесь написано, что это RDD (в текстовом файле есть string). Причем, не важно, создал я RDD из файла (это будут строчки данного файла) или из директории (это будут строчки всех файлов в этой директории).
Так создается RDD из памяти:
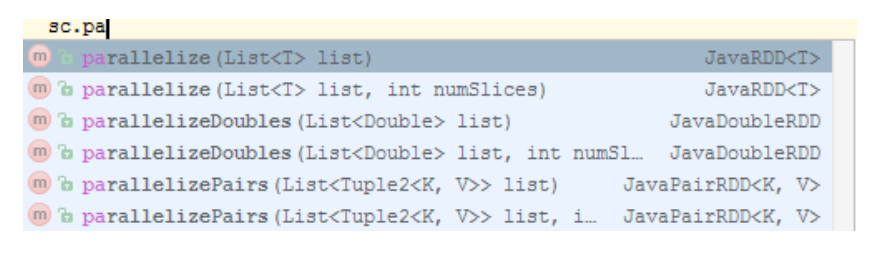
У вас есть метод parallelize, который принимает list и превращает его в RDD.
Теперь мы подходим к вопросу, что такое sc, который мы постоянно использовали для получения RDD. Если мы работаем со Scala, этот объект называется SparkContext. В мире Java API он называется JavaSparkContext. Это основная точка, с которой мы начинаем писать код, связанный со Spark, потому что оттуда мы получаем RDD.
Вот пример, как конфигурируется объект Spark-контекста на Java:
SparkConf conf = new SparkConf();
conf.setAppName("my spark application");
conf.setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
Создается сначала объект Spark-конфигурации, он настраивается (вы говорите, как называется запускаемое приложение), далее указываете, работаем мы локально или нет (звездочка говорит, сколько найдешь thread-ов, столько и можно использовать; можно указать 1, 2 и т.д.). И потом я создаю JavaSparkContext и передаю сюда конфигурацию.
Тут возникает первый вопрос:, а как же все разделить? Если я SparkContext создаю таким образом и передаю ему сюда конфигурацию, это не будет работать на кластере. Мне надо разделить, чтобы на кластере здесь у меня вообще ничего не было написано (потому что в момент запуска Spark-процесса нужно сказать, сколько надо использовать машин, кто у нас мастер, кто у нас кластер-менеджер и так далее). Я не хочу, чтобы эта конфигурация здесь была; я хочу оставить только application name.
И тут на помощь приходит Spring: мы делаем два bean-а. Один у нас под профилем production (он вообще никакой информации не передает о том, кто у нас мастер, сколько машин и т.д.), другой под профилем local (и здесь я эту информацию передаю; можно сразу легко разделить). Для тестов будет один bean работать из SparkContext, а для продакшн — другой.
@Bean
@Profile("LOCAL")
public JavaSparkContext sc() {
SparkConf conf = new SparkConf();
conf.setAppName("music analyst");
conf.setMaster("local[1]");
return new JavaSparkContext(conf);
}
@Bean
@Profile("PROD")
public JavaSparkContext sc() {
SparkConf conf = new SparkConf();
conf.setAppName("music analyst");
return new JavaSparkContext(conf);
}
Вот список функций, которые есть у RDD.
map
flatMap
filter
mapPartitions, mapPartitionsWithIndex
sample
union, intersection, join, cogroup, cartesian (otherDataset)
distinct
reduceByKey, aggregateByKey, sortByKey
pipe
coalesce, repartition, repartitionAndSortWithinPartitions
Они очень похожи на функции Stream: тоже все Immutable, тоже возвращают RDD (в мире Stream это называлось intermediate operations, а тут — transformations). В подробности мы сейчас вдаваться не будем.
Также есть Actions (в мире Stream-ов это называлось terminal operations).
reduce
collect
count, countByKey, countByValue
first
take, takeSample, takeOrdered
saveAsTextFile, saveAsSequenceFile, saveAsObjectFile
foreach
Как определить, что Action, а что Transformation? Как и в стримах, если RDD-метод возвращает RDD, это Transformation. Если нет — значит это Action.
Action существует двух видов:
- те, что возвращают нечто обратно на Driver (важно подчеркнуть, что это будет не на кластере; ответ вернется на Driver). Например, reduce принимает функцию, как надо собрать все данные, и в конечном итоге вернется один ответ (в общем случае он не обязательно должен быть один);
- те, что не возвращают ответ на Driver. Например, можно сохранить данные после обработки в тот же Hadoop или другой storage (для этого есть метод saveAsTextFile).
Как все работает?
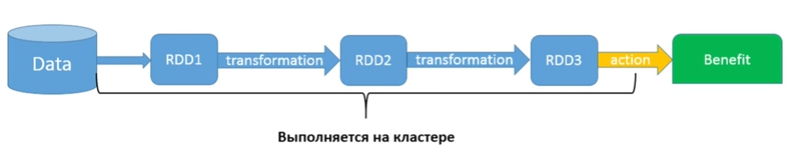
Эта схема похожа на стримы, но здесь есть один маленький нюанс. У нас есть какая-то data, которая находится, допустим, в s3 storage. Я при помощи SparkContext создал свой первый RDD1. Потом я делаю всякие разные трансформации, каждая из которых возвращает мне RDD. В конечном итоге я выполняю Action и получаю какую-то пользу (сохранил, распечатал или переслал то, что у меня получилось). Этот кусок, естественно, выполняется на кластере (все RDD-методы запускаются на кластере). Маленький кусочек в конце будет запускаться на Driver в том случае, если итогом станет какой-то ответ. Все, что слева от Data (т.е. до того, как я начал пользоваться кодом Spark) — тоже будет запускаться на Driver, а не на кластере.
Все это Lazy — точно так же, как в стримах. Каждый метод RDD, который является трансформацией, ничего не делает, а ждет Action. Когда будет Action, вся цепочка запустится. И тут возникает классический вопрос:, а что мы делаем вот в таком случае?
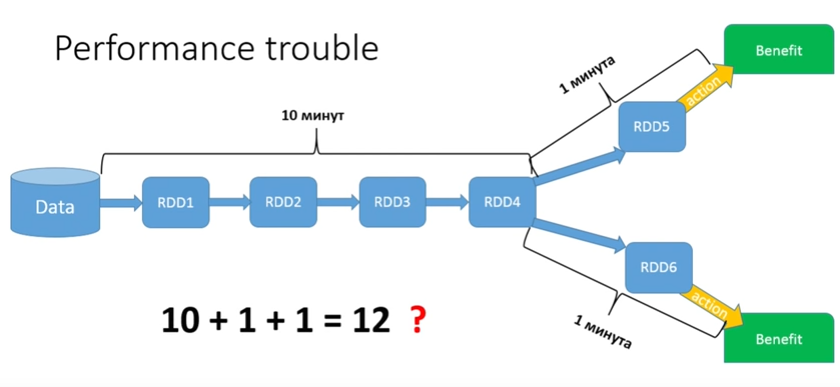
Представьте, что моя data — это все денежные транзакции за последние 5 лет в каком-то банке. И мне надо провести достаточно длинную обработку, а дальше она разделяется: для всех мужчин я хочу сделать один Action, а для всех женщин — другой. Допустим, у меня первая часть процесса займет 10 минут. Вторые части процесса потребуют по минуте. Казалось бы, у нас должно получиться в сумме 12 минут?
Нет, у нас получается 22 минуты, потому что Lazy — каждый раз, когда запускается Action, прогоняется вся цепочка от начала до конца. В нашем случае общий кусок запускается только 2 раза, но если бы у нас было 15 разветвлений?
Естественно, это очень сильно бьёт по перформансу. В мире Spark очень легко писать код, особенно людям, которые хорошо знакомы с функциональным программированием. Но ерунда получается. Если хотите писать эффективный код, надо знать многие особенности.
Давайте попробуем решить проблему. Чтобы мы сделали в стримах? Сделали бы какой-то collect, собрали это все в collection, а потом из нее вытаскивали бы стримы.
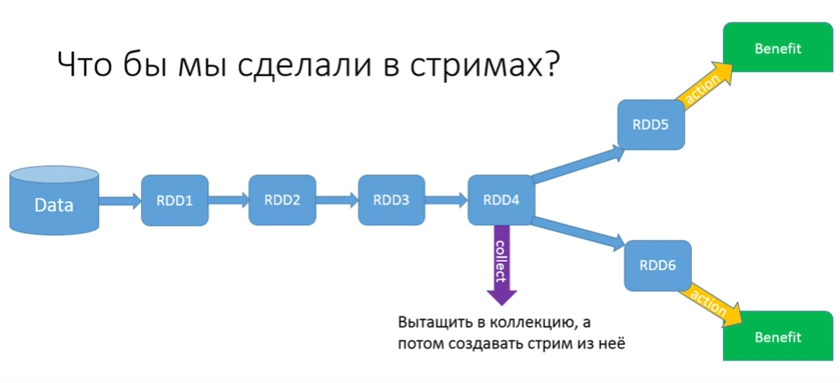
В GetTaxi пробовали, но получилось вот так:

Причем, они собирались докупить еще машин на кластер, чтобы их было 40 штук и у каждой по 20 джигабайт оперативной памяти.
Надо понимать: если мы говорим про big data, в тот момент, когда вы делаете collect, вся информация из всех RDD возвращается к вам на Driver. Поэтому джигабайты и машины им никак не помогают: когда они делают collect, вся информация сливается в одно место, откуда запустилось приложение. Естественно, получается out of memory.
Как решаем эту проблему (дважды цепочку прогонять не хочется, 15 — тем более, а collect делать нельзя)? Для этого в Spark есть метод persist:
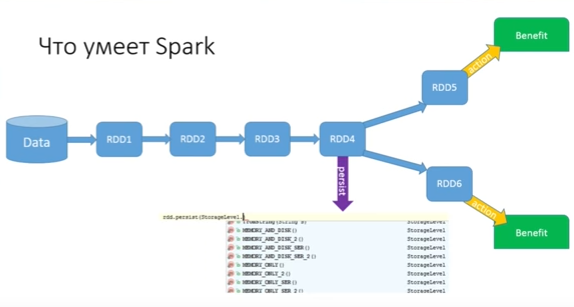
Persist позволяет сохранить state RDD, причем можно выбрать, куда сохранять. Вариантов сохранения много. Самый оптимальный — в память (есть memory only, а есть memory only 2 — с двумя бекапами). Можно даже написать свой custom storage и сказать, как это сохранять. Можно сохранять memory and disk — попытаться сохранить в память, но если у данного worker (у машины, которая этот RDD запускает) нет достаточного объема оперативной памяти, часть запишется в память, а остатки сбросятся на диск. Вы можете сохранять данные как объект или делать сериализацию. У каждого из вариантов есть свои плюсы и минусы, но такая возможность есть, и это прекрасно.
Мы победили эту проблему. Persist — это не action. Если не будет никаких action, persist не сделает ничего. Когда запустится первый action, вся цепочка прогоняется и в конце первой части цепочки RDD персистится на все машины, где находится data. Когда мы запускаем action RDD6, начинаем уже с persist (если бы были другие ответвления, то продолжали бы с точки, которую «запомнили» или «пометили» persist).
Миф 2. Spark пишем только на Scala
Spark — здорово, его можно применять даже для каких-то локальных нужд, не обязательно для big data. Можно просто использовать его API для обработки данных (он реально удобный). Возникает вопрос: на чем писать? Python и R я отмел сразу. Будем выяснять: Scala или Java?
Что думает обычный Java-девелопер о Scala?

Продвинутый Java-девелопер видит чуть больше.
Он знает, что там есть какой-то play, какие-то классные фреймворки, лямбды и очень много китайского.
Помните попу? Вот она. Так выглядит код на Scala.
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(_.length)
val totalLength = lineLengths.reduce(_+_)
Я не буду вдаваться сейчас в API Scala, потому что моя конечная цель — убедить вас, что писать на Java ничуть не хуже, но этот код считает длину каждой строки и суммирует все это дело.
Очень сильный аргумент против Java в том, что тот же самый код на Java выглядит вот так:
JavaRDD lines = sc.textFile("data.txt");
JavaRDD lineLengths = lines.map(new Function() {
@Override
public Integer call(String lines) throws Exception {
return lines.length();
}
});
Integer totalLength = lineLengths.reduce(new Function2() {
@Override
public Integer call(Integer a, Integer b) throws Exception {
return a + b;
}
});
Когда я начинал первый проект, начальство спрашивало, уверен ли я? Ведь когда мы будем писать, кода будет все больше и больше. Но это все ложь. Сегодняшний код выглядит так:
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(_.length)
val totalLength = lineLengths.reduce(_+_)
JavaRDD lines = sc.textFile("data.txt");
JavaRDD lineLengths = lines.map(String::length);
int totalLength = lineLengths.reduce((a, b) -> a + b);
Вы видите сильную разницу между Scala и Java 8? Мне кажется, для Java-программистов это более читабельно. Но даже несмотря на Java 8, мы приходим к мифу, что Spark надо писать на Scala. Чем люди, которые знают, что в Java 8 все не так плохо, аргументируют, что надо писать на Scala?
За Scala:
- Scala — это круто, хипстерно, модно, правильно, надо двигаться вперед. Нафиг этот Groovy, в Scala все однозначно прикольнее;
- Scala — лаконичный и удобный синтаксис. Там есть попа;
- Spark API, поскольку написан на Scala, в первую очередь заточен под Scala. Это серьезный плюс;
- Java API выходит чуть позже, потому что они должны его подпиливать, подделывать. Там не всегда все есть.
За Java:
- большинство Java-программистов знает Java. Эти люди не знают Scala. В больших компаниях куча Java-программистов, которые более-менее с Java разобрались. Давать им Scala, чтобы писать Spark? Нет;
- знакомый мир — есть Spring, знакомые шаблоны проектирования, Maven или даже лучше — Gradle, синглетоны и т.д. Мы привыкли там работать. А Scala — не только другой синтаксис, это много других концепций. В Scala не нужна инверсия контроля, т.к. там все по-другому.
Почему же Java все-таки лучше? Потому что мы, конечно, любим Scala, но деньги в Java.

Послушайте подкаст — Выпуск 104 — в котором обсуждают, что произошло.
Я в двух словах расскажу.
Год назад Martin Odersky, который в 2010 году открыл компанию Typesafe, закрыл ее. Нет больше компании Typesafe, которая поддерживает Scala.
Это не значит, что Scala умерла, поскольку вместо Typesafe открылась другая компания — Lightbend, но у нее совершенно другая бизнес-модель. Они пришли к выводу, что даже благодаря классным вещам, написанным на Scala, как Play, Akka и Spark, и даже благодаря упомянутой выше попе, невозможно заставить массы перейти работать на Scala. Год назад Scala находилась на пике популярности, несмотря на это она не входила даже в первые 40 мест в рейтинге. Для сравнения — Groovy был на двадцатом, Java — на первом.
Когда они поняли, что даже на пике популярности все равно не заставили людей использовать Scala в массах, то признали свою бизнес-модель неправильной. У компании, которая сегодня будет пилить Scala, другая бизнес модель. Они говорят, что все продукты, которые будут делаться для масс, вроде Spark, будут иметь отличный Java API. И когда мы дойдем до датафреймов, вы увидите, что там уже нет никакой разницы, писать на Scala или на Java.
Миф 3. Spark и Spring несовместимы
Во-первых, я вам уже показал, что у меня есть SparkContext, который прописан как bean. Далее мы увидим, как при bean постпроцессора мы сможем поддерживать некоторый функционал для Spark.
Давайте уже писать код.
Мы хотим написать сервис (вспомогательный), который принимает RDD строк и количество топовых слов. Его задача — вернуть топовые слова. Давайте посмотрим в коде, что мы делаем.
@service
public class PopularWordsServiceImpl implements PopularWordsService {
@Override
public List topX(JavaRDD lines, int x) {
return lines.map(String::toLowerCase)
.flatMap(WordsUtil::getWords)
.mapToPair(w -> new Tuple2<>(w, 1))
.reduceByKey((a, b) -> a + b)
.mapToPair(Tuple2::swap)
.sortByKey().map(Tuple2::_2).take(x);
}
}
Во-первых, поскольку мы не знаем, в lowercase или в uppercase у нас слова песен, нам надо все перевести в lowercase, чтобы слова с большой и с маленькой буквы мы не считали два раза. Поэтому мы пользуемся функцией map. После этого нужно превратить строки в слова с помощью функции flatmap.
Теперь у нас есть RDD, в котором присутствуют слова. Мы его map-ируем против их количества. Но сначала надо просто каждому слову единичку приписать. Это будет классический паттерн: у нас будет слово — 1, слово — 1, потом все еденички против одинаковых слов надо будет суммировать и отсортировать (все работает в памяти, и никакие промежуточные результаты не сохраняются на диске если памяти достаточно).
У нас есть функция mapToPair — сейчас мы уже будем создавать пары. Проблема в том, что в Java нет класса Pair. На самом деле это большое упущение, потому что очень часто у нас есть какая-то информация, которую в определенном контексте хочется соединить, но писать под это класс глупо.
У Скалы есть готовые классы (их очень много) — Tuple. Есть Tuple2, 3, 4 и т.п. до 22. Почему до 22? Не знает никто. Нам нужен Tuple2, потому что мы мапируем 2.
Теперь все это надо reduce-ить. У нас есть метод reduceByKey, который все одинаковые слова оставит ключом, а со всеми value сделает то, что попрошу. Нам надо сложить. У нас получились пары: слово — количество.
Теперь надо отсортировать. Тут у нас опять небольшая проблема с Java, т.к. единственное, что у нас есть sort — это sorkByKey. В API Scala есть просто sortby и там вы берете этот Tuple и вытаскиваете из него все, что хотите. А здесь — только SortByKey.
Как я и говорил, пока еще в некоторых местах мы чувствуем, что Java API недостаточно богат. Но выкрутиться можно. К примеру, можно перевернуть нашу пару. Для этого мы еще раз делаем mapToPair, и у Tuple есть встроенная функция swap (получилась пара количество — слова). Теперь мы можем делать sortByKey.
После этого надо вытащить не первую, а вторую часть. Поэтому делаем map. Для вытаскивания второй части у Tuple есть готовая функция »_2». Теперь делаем Take (x) (нам же нужно только x слов — метод называется TopX), и этому всему можно будет сделать return.
Я покажу, как делается тест. Но до этого посмотрите, что у меня в Java config на Spring (мы работаем на Spring, и это не просто класс, а сервис).
@Configuration
@ComponentScan(basePackages = "ru.jug.jpoint.core")
@PropertySource("classpath:user.properties")
public class AppConfig {
@Bean
public JavaSparkContext sc() {
SparkConf conf = new SparkConf().setAppName("music analytst").setMaster("local[*]");
return new JavaSparkContext(conf);
}
@Bean
public static PropertySourcesPlaceholderConfigurer configurer(){
return new PropertySourcesPlaceholderConfigurer();
}
}В Java config я читаю какой-то user.properties (я потом объясню, зачем; сейчас я его все равно не использую). Также я сканирую все классы и прописываю два bean: PropertySourcePlceholderConfigurer — чтобы можно было инжектить что-то из property-файлов, это пока не актуально; и единственный bean, который нас сейчас интересует — это обычный JavaSparkContext.
Я создал SparkConf, настроил его (программа называется music analyst), сказал ему, что у нас мастер (мы работаем локально). Мы создали JavaSparkContext — все замечательно.
Теперь смотрите тест.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = AppConfig.class)
public class PopularWordsServiceImplTest {
@Autowired
JavaSparkContext sc;
@Autowired
PopularWordsService popularWordsService;
@Test
public void textTopX() throws Exception {
JavaRDD rdd = sc.parallelize(Arrays.asList("java java java scala grovy grovy”);
List top1 = popularWordsService.topX(rdd, 1);
Assert.assertEquals("java”,top1.get(0));
}
} Поскольку мы работаем со Spring, раннер, естественно, спринговый. Наша конфигурация — это AppConfig (правильно было бы сделать разные конфигурации для тестирования и для продакшн). Далее мы инжектим сюда JavaSparkContext и тот сервис, который хотим проверять. При помощи SparkContext я пользуюсь методом parallelize и передаю туда строку «java java java scala grovy grovy». Далее запускаю метод и проверяю, что Java — это самое популярное слово.
Тест упал. Потому что самое популярное — scala.
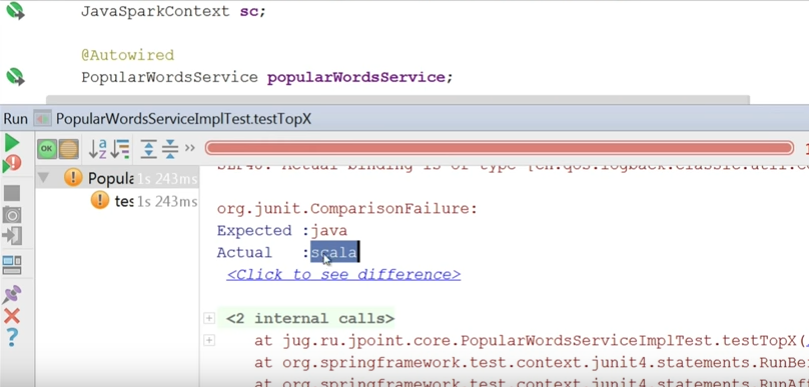
Что я забыл сделать? Когда я делал Sort, надо было сортировать в другую сторону.
Исправляем в нашем сервисе:
@service
public class PopularWordsServiceImpl implements PopularWordsService {
@Override
public List topX(JavaRDD lines, int x) {
return lines.map(String::toLowerCase)
.flatMap(WordsUtil::getWords)
.mapToPair(w -> new Tuple2<>(w, 1))
.reduceByKey((a, b) -> a + b)
.mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x);
}
} Тест прошел.
Теперь попробуем запустить main и посмотреть результат на реальной песне.
У меня есть директория data, там есть папка Beatles, в которой лежит текст единственной песни: yesterday. Как вы думаете, какое самое популярное слово в yesterday?
Здесь у меня сервис ArtistsJudge. Мы имплементировали метод TopX — он принимает имя артиста, добавляет директорию, в которой находятся песни этого артиста, а дальше использует метод topX уже написанного сервиса.
@Service
public class ArtistJudgeImpl implements ArtistJudge {
@Autowired
private PopularDFWordsService popularDFWordsService;
@Autowired
private WordDataFrameCreator wordDataFrameCreator;
@Value("${path2Dir}")
private String path;
@Override
public List topX(String artist, int x) {
DataFrame dataFrame = wordDataFrameCreator.create(path + "data/songs/" + artist + "/*");
System.out.println(artist);
return popularDFWordsService.topX(dataFrame, x);
}
@Override
public int compare(String artist1, String artist2, int x) {
List artist1Words = topX(artist1, x);
List artist2Words = topX(artist2, x);
int size = artist1Words.size();
artist1Words.removeAll(artist2Words);
return size - artist1Words.size();
}
public static void main(String[] args) {
List list = Arrays.asList("Вронский", null, "Анна");
Comparator cmp = Comparator.nullsLast(Comparator.naturalOrder());
System.out.println(Collections.max(list, cmp));
/* System.out.println(list.stream().collect(Collectors.maxBy(cmp)).get());
System.out.println(list.stream().max(cmp).get());
*/
}
} Main у меня выглядит так:
package ru.jug.jpoint;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import ru.jug.jpoint.core.ArtistJudge;
import java.util.List;
import java.util.Set;
/**
* Created by Evegeny on 20/04/2016.
*/
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
ArtistJudge judge = context.getBean(ArtistJudge.class);
List topX = judge.topX("beatles", 3);
System.out.println(topX);
}
}
Итак, самое популярное слово — это не yesterday, это «i»:
[i, yesterday, to]
Согласитесь, это не очень хорошо. У нас есть мусорные слова, которые не несут смысловой нагрузки (в конечном итоге мы хотим анализировать, насколько песни Pink Floyd более глубокие и нам такие слова будут сильно мешать).
Поэтому у меня был файл userProperties, в котором определены мусорные слова:
garbage = the,you,and,a,get,got,m,chorus,to,i,in,of,on,me,is,all,your,my,that,it,for
Можно было бы сразу инжектить этот garbage в наш сервис, но я так делать не люблю. У нас есть UserConfig, который будет передаваться в разные сервисы. Каждый будет вытаскивать из него то, что ему нужно.
@Component
public class UserConfig implements Serializable{
public List garbage;
@Value("${garbage}")
private void setGarbage(String[] garbage) {
this.garbage = Arrays.asList(garbage);
}
}
Обратите внимание, я использую private для сеттера и public для самого property. Но не будем на этом зацикливаться.
Мы идем в наш PopularWordsServiceImpl, делаем Autowired этому UserConfig и фильтруем все слова.
@service
public class PopularWordsServiceImpl implements PopularWordsService {
@Override
public List topX(JavaRDD lines, int x) {
return lines.map(String::toLowerCase)
.flatMap(WordsUtil::getWords)
.mapToPair(w -> new Tuple2<>(w, 1))
.reduceByKey((a, b) -> a + b)
.mapToPair(Tuple2::swap).sortByKey(false).map(Tuple2::_2).take(x);
}
}
Запускаем тот же main.
Смотрите, что у нас произошло (это важный момент):
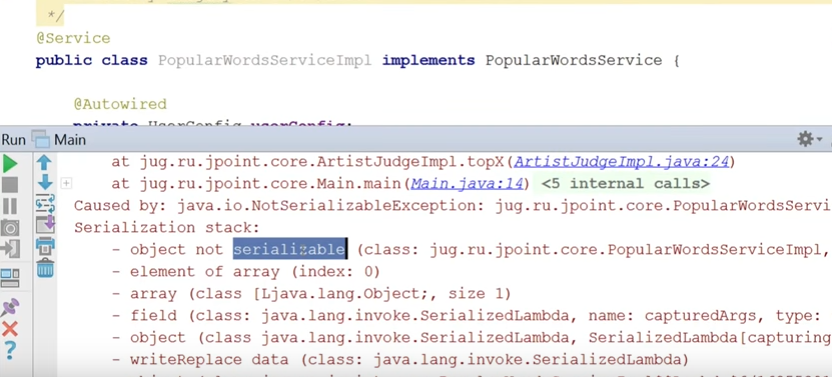
Все упало, потому что not serializable.
Давайте об этом поговорим.
Чтобы вы не сомневались, UserConfig — serializable.
Component
public class UserConfig implements Serializable{
public List garbage;
@Value("${garbage}")
private void setGarbage(String[] garbage) {
this.garbage = Arrays.asList(garbage);
}
}
Но у меня не serializable мой PopularWordsServiceImpl:
@Service
public class PopularWordsServiceImpl implements PopularWordsService {
Сейчас я его сделаю serializable:
public interface PopularWordsService extends Serializable {
List topX(JavaRDD lines, int x);
}
Когда вы в map-функции (или любой другой функции, которая бежит на кластере) начинаете пользоваться state-ом какого-то объекта, этот объект должен на кластер уходить и сериализоваться. Т.е. если я использую UserConfig внутри своих функций, он должен быть serializable. Но фишка в том, что этот UserConfig является частью моего сервиса, значит сервис тоже должен сериализоваться. Это можно хитро обойти, но проще сделать serializable.
В итоге все работает. На первое место попал yesterday. На втором месте — oh, на третьем — believe. Я специально не вносил oh в слова-мусор, потому что для Бритни Спирс это очень важное слово.
Но что происходит, когда я говорю, что UserConfig должен пойти на все worker? Он будет для каждой строчки туда идти? Не будет ли это бить по перформансу? Тут мы снова возвращаемся к тому, что писать код на Spark легко, а вот чтобы писать эффективный код, надо кое-что знать.
Давайте поговорим о следующем мифе, который связан с broadcast-ом.
Миф 4. Есть случаи, когда без broadcast не работает
Вам надо позаботиться о том, чтобы на worker-ы попала общая для них data (как UserConfig в примере выше). Я встречал людей, которые говорили, что обязательно надо делать broadcast, иначе это не будет работать. Но это будет работать (как вы видели), broadcast делать не обязательно.
Есть 2 варианта, как это реализовать:
- можно ничего не делать. Spark разберется сам;
- можно ему заранее сказать, что эти переменные, информацию, конфиги — распредели туда. Это делается через broadcast.
Пример типичной ситуации:
Israel, +9725423632
Israel, +9725454232
Israel, +9721454232
Israel, +9721454232
Spain, +34441323432
Spain, +34441323432
Israel, +9725423232
Israel, +9725423232
Spain, +34441323432
Russia, +78123343434
Russia, +78123343434
Это сокращенный пример из одного из рабочих проектов.
У меня есть строки в файле (там их миллиарды), где указаны страна и номер телефона. Мне надо отфильтровать те страны, которые нас не интересуют. Какие именно — прописано в конфиге в каком-то property-файле и его надо дистрибьютить на все worker-ы. После этого мне опять же из конфига надо взять информацию о префиксах телефона и смапировать это против оператора, чтобы получить названия телефонных компаний, обслуживающих номера:
