Machine Learning инженер: что/где/как изучать, чтобы въехать
Привет, хаброчеловек!
В этой статье мы обсудим путь среднестатистического обывателя в Machine Learning, а именно — как стать ML-инженером. Поговорим о специфике области, какие требуются знания и скиллы, что нужно делать и с чего начать.
Перед началом пару годных ресурсов в тему:
Поехали!
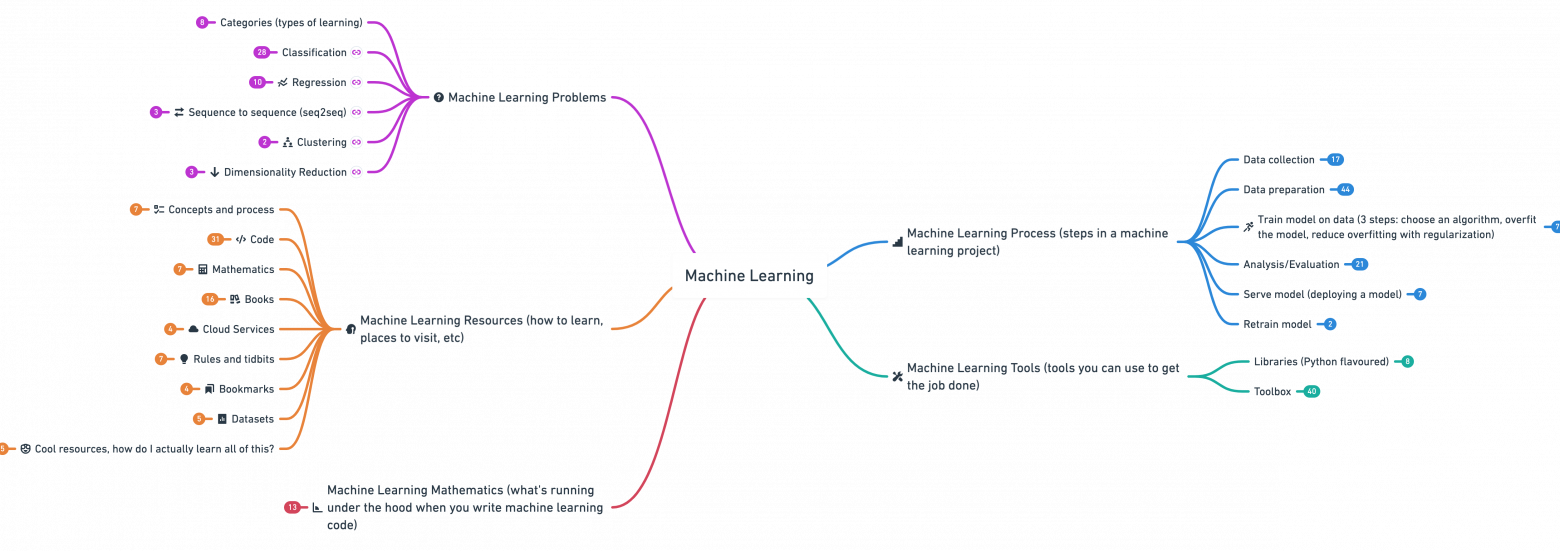
Навигация
Кто такой ML-инженер?
Как стать ML-инженером?
Кто такой ML-инженер?
Перед обсуждением пути в ML-инженеры было бы неплохо описать, а кто же это такой, и в чём суть профессии.
Разница между Machine Learning Engineer и Data Scientist
Вот 4 основных вида машинного обучения: классическое, обучение с подкреплением, ансамбли, нейросети. И всевозможные подвиды этих 4 с названиями известных алгоритмов.

В чём разница между 4 основными видами машинного обучения:

А это детальное рассмотрение одного из 4 основных видов ML — классического обучения:

Сперва определимся в чем разница между Machine Learning Engineer и Data Scientist.
Если Data Scientist может больше работать над моделированием и сосредотачивается на тонкостях алгоритмов, то Machine Learning Engineer более часто работает над развертыванием той же модели в производственной среде. Или же ML-инженер работает над автоматизацией процесса обучения, мониторинга, сбора признаков.
Конечно, в небольших компаниях граница может размываться, и все эти обязанности может выполнять один специалист. Однако с ростом организации узкая специализация становится неизбежной, поэтому задачи распределяются между дата-сайнтистом и ML-инженером.
В общем, одной из основных задач ML-специалиста является развёртывание моделей в производство для постоянной работы. Плюс поддержание работоспособности модели, оптимизация, повышение производительности. По сути, работа ML-инженера больше похожа на работу разраба ПО, чем на работу типичного дата-сайнтиста. Он должен писать производительный, покрытый тестами код, с которым могли бы работать другие люди. И если используемая модель перестаёт работать, то её возвращением к жизни опять же занимается ML-инженер.
Если описать в парадигме «знать-уметь», то ML-инженер:
знает
основные классы задач Machine learning
основную терминологию ML
методы автоматического обучения ML-моделей
основные библиотеки, используемые для ML
критически отбирать методы решения ML-задач
умеет
применять методы ML для решения задач
оценивать полученный результат (качество прогноза, …)
строить математическую модель, формализовать прикладную задачу
читать доки/статьи на английском
собирать, анализировать, организовывать информацию
Чем занимается ML-инженер
Жизненный цикл модели машинного обучения

Как мы выяснили, Machine Learning Engineer гораздо чаще занимается внедрением модели в продакшен. Именно этим он и отличается от специалистов по обработке/анализу данных.
На первый взгляд может показаться, что ML-инженер занимается только эксплуатацией моделей машинного обучения. Конечно, это не совсем так, инженер по машинному обучению может работать над оптимизацией алгоритмов машинного обучения, повышением их производительности, полностью перестраивать их.
Некоторые (чаще маленькие) компании предпочитают всестороннего Data Scientist, который способен как работать с алгоритмами машинного обучения так и внедрять эти решения в продакшен. Но чем компания больше, с большей вероятностью предпочтут разделить эти две роли. Одному человеку может быть сложно сделать все от начала до конца, поэтому наличие двух специалистов, один из которых занимается построением модели, а другой — ее развертыванием, часто является более эффективным подходом.
Примеры простых задач, с которыми может сталкиваться ML-инженер:
научить модель предсказывать эмоции человека по датасету фотографий
увеличить покрытие популярных локаций для предсказания точки вызова такси
сравнить разные функции потерь в ранжирующем алгоритме
обучить и внедрить классификатор поисковых запросов
искусственно восстановить данные в прошлом, чтобы наиболее точно сформировать сэмплы для обучения в будущем
адаптировать нейросетевой шумодав под алгоритмы распознавания речи
провести эксперименты по увеличению размеров модели за счёт изменений в её архитектуре
А вот ниже отдельные области, где внедрение ML-моделей идёт быстрыми темпами и не планирует останавливаться — это медицина, георазведка, финансовая/банковская сфера, поисковые системы, сфера рекламы/анализа покупателей. Подробное описание задач из этих областей ниже.
Задачи медицинской диагностики
Объект: пациент в определённый момент времени.
Классы: диагноз или способ лечения или исход заболевания.
Примеры признаков:
бинарные: пол, головная боль, слабость, тошнота, и т.д.
порядковые: тяжесть состояния, желтушность, и т.д.
количественные: возраст, пульс, артериальное давление, содержание гемоглобина в крови, доза препарата, и т.д.
Особенности задачи:
обычно много «пропусков» в данных
нужен интерпретируемый алгоритм классиикации
нужно выделять синдромы сочетания симптомов
нужна оценка вероятности отрицательного исхода
Задачи распознавания месторождений
Объект: геологический район (рудное поле)
Классы: есть или нет полезное ископаемое.
Примеры признаков:
бинарные: присутствие крупных зон смятия и рассланцевания, и т. д.
порядковые: минеральное разнообразие; мнения экспертов о наличии полезного ископаемого, и т. д.
количественные: содержания сурьмы, присутствие в рудах антимонита, и т. д.
Особенности задачи:
проблема ѕмалых данныхї для редких типов
месторождений объектов много меньше, чем признаков
Задача кредитного скоринга
Объект: заявка на выдачу банком кредита.
Классы: выдавать кредит или нет
Примеры признаков:
бинарные: пол, наличие недвижимости, и т. д.
номинальные: место проживания, профессия, работодатель, и т. д.
порядковые: образование, должность, и т. д.
количественные: возраст, зарплата, стаж работы, доход семьи, сумма кредита, и т. д.
Особенности задачи:
Задача предсказания оттока клиентов (на примере мобильного оператора)
Объект: абонент в определённый момент времени.
Классы: уйдёт или не уйдёт в следующем месяце.
Примеры признаков:
бинарные: корпоративный клиент, включение услуг, и т. д.
номинальные: тарифный план, регион проживания, и т. д.
количественные: длительность разговоров (входящих, исходящих, СМС, и т. д.), частота оплаты, и т. д.
Особенности задачи:
нужно оценивать вероятность ухода
сверхбольшие выборки
признаки приходится вычислять по сырым данным
Задачи биометрической идентификации личности
Особенности задач:
нетривиальная предобработка для извлечения признаков
высочайшие требования к точности
Задача ранжирования поисковой выдачи
Объект: короткий текстовый запрос, документ
Классы: релевантен или не релевантен, разметка делается людьми асессорами.
Примеры количественных признаков:
частота слов запроса в документе,
число ссылок на документ,
число кликов на документ: всего, по данному запросу
Особенности задачи:
сверхбольшие выборки документов
оптимизируется не число ошибок, а качество ранжирования
проблема конструирования признаков по сырым данным
Что должен уметь ML-инженер
Окей, мы выяснили, кто такой ML-инженер, что входит в его обязанности и чем он занимается. Теперь о скиллах и знаниях, которыми он должен обладать, чтобы успешно решать задачи.
ML-инженер работает на стыке computer science и data science. Это требует от него знаний основ алгоритмов, структур данных. Нужно уметь писать продуктовый и поддерживаемый код, покрытый тестами. Для ML-инженера важно знание отдельных областей data science для построения эффективных систем, например, знание computer vision или natural language processing.
Существует множество инструментов, которые необходимы для работы, в частности, для развёртывания моделей. Это конечно Docker, Flask, MLFlow, Airflow, FastAPI и ещё масса других.
Отдельно выделю облачные платформы: AWS, Microsoft Azure. Облачные сервисы сейчас крайне популярны и всё больше компаний, проектов и стартапов разворачивают модели в облаках.
А вот так выглядят 25 важнейших инструментов ML-инженера судя по вакансиям:

Чуть подробнее о некоторых инструментах.
Docker — это платформа для разработки, доставки и запуска приложений в контейнерах. Он может быть использован для создания изолированных сред для запуска моделей машинного обучения, что облегчает их развертывание и масштабирование.
Git — это система управления версиями, которая позволяет отслеживать изменения в коде. GitHub — это хостинг-сервис для Git-репозиториев. Они оба широко используются для разработки и совместной работы над проектами машинного обучения.
FastAPI — это современный веб-фреймворк для Python, предназначенный для создания быстрых и эффективных API. Он использует современные технологии Python, такие как типизация данных и асинхронность, для создания высокопроизводительных веб-сервисов.
Airflow — это инструмент для управления рабочим процессом, который может использоваться для планирования, мониторинга и выполнения задач в системах машинного обучения. Airflow позволяет создавать и запускать пайплайны машинного обучения, которые могут состоять из любого количества задач. Он может быть использован для автоматизации процессов, таких как обучение моделей, тестирование, оценка производительности и развертывание моделей.
И про облака:
Amazon Web Services (AWS) предоставляет множество услуг и инструментов, которые могут быть полезны для машинного обучения, включая Amazon SageMaker, который предоставляет средства для обучения, оптимизации и развертывания моделей машинного обучения. Кроме того, в AWS есть множество других сервисов, таких как хранилище данных, вычислительные ресурсы, базы данных и т.д.
Microsoft Azure: основной продукт для ML Azure Machine Learning, который помогает в обучении моделей и создания приложений машинного обучения. У Azure также есть базы данных, хранилище данных и другие сервисы.
Из языков наиболее важными являются Python и C++. Питон, как обычно, для того, чтобы быстро пилить фичи, C++ — для повышения скорости работы модели. C++ постепенно заменяется всеми любимым Rust, поэтому знания раста было бы неплохим бонусом и конкурентным преимуществом.
Как стать ML-инженером?
Что освоить?
Итак, мы обсудили, кто такой ML-инженер, что входит в список его задач, и какие проблемы он решает.
Собственно, после описания конечного результата гораздо проще ответить на вопрос «Как стать ML-инженером?» Очевидно, нужно сперва изучить хотя бы 10 инструментов из списка выше:
Python, R
SQL
работа с системой Git
питонячие либы Pandas, Numpy, Scikit-learn, PyTorch
Docker (неплохо бы и кубер)
базовые команды терминала Linux
»Изучить» — подразумевает огромное количество практики, нужно писать код, тестить популярные ML-библиотеки, пощупать реальные проекты с гитхаба, написать пару своих проектов. Как ни крути, аккаунт на гитхабе для многих рекрутёров является важным показателем. Больше практики, только так теория закрепится в голове. Можно опираться на реальные ML-проекты с ютуба, делать их параллельно с автором; вот скажем прогнозирование стоимости домов:

Как подготовиться к собесу?
Готовиться к собеседованию лучше, исходя из конкретных секций/частей. Итак, вот что попадается на собесе:
Базовые вопросы по Python, работе с Linux, Computer science в целом, по Machine learning.
Алгоритмическая секция. Чтобы подготовиться, просто нарешиваем задачи с Leetcode: в районе 150 средних и 30 сложных, в целом этого вполне хватит.
Machine learning system design. Эта секция попадается на собесах на позиции Middle+, поэтому в этой статье просто упомянем её. Задача секции — полностью спроектировать ML-решение. От определения задачи и метрик, заканчивая деплоем и оптимизацией.
Вопросы по ML теории. Типичные вопросы: метрики, разобрать модель, написать пару формул. Шадовский учебник помогает вспомнить самую суть, можно использовать его.
Исправить ошибки в коде. Могут дать код обучения модели, необходимо проревьюить, описать, какие есть проблемы. Тут очевидно пригодится умение писать и дебажить код.
Всякое разное: вопросы за жизнь, «кем ты видишь себя через n лет», логические задачи и т.д.
Разберём некоторые пункты чуть подробнее.
Базовые вопросы. Чтобы подготовиться, можно использовать это:
100 вопросов для подготовки к собесу Python
«Теоретический минимум по Computer Science» — Феррейра Фило
«Linux на примерах. Практика практика и только практика» — Колисниченко Д.Н.
«Математические основы машинного обучения и прогнозирования» — Владимир Вьюгин
«Верховный алгоритм» — Педро Домингос
Алгоритмическая секция. На собесах любят давать алгоритмы, а значит Leetcode — ваш лучший друг на этапе подготовки. Хабростатья в тему — «Пройти LeetCode за год: roadmap». Разумеется, не нужно проходить весь литкод, достаточно самостоятельно нарешать около 150 средних (medium) задач. Ну и можно штук 30 сложных (hard), для большинства собесов (кроме гугла :]) этого будет достаточно. Делать упор нужно не на запоминании конкретного решения, а на понимании общих идей, алгоритмов, приёмов. Благо на литкоде есть целый раздел с теорией.
Вообще, важно не только уметь правильно/быстро решать алгоритмические задачи; для успешного собеседования стоит вначале выяснить политику оценивания. Должен ли я проверить алгоритм вручную, поправить все баги и только потом запускать — или я могу запускать свой код, сколько хочу, с самого начала? На собеседованиях можно столкнуться с обоими вариантами, лучше узнать это заранее, а не в середине собеса.
Помимо литкода для подготовки к алгоритмам можно использовать:
Вопросы по ML теории. Чтобы разобраться в теории машинного обучения, можно использовать эти ресурсы:
«Математические основы машинного обучения и прогнозирования» — Владимир Вьюгин
Учебник от ШАД
Основная теория Machine learning включает в себя:
полносвязные нейросети
сверточные нейросети
детекция объектов
сегментация изображений
устройство нейросетей для сегментации изображений
транспонированная свертка, U-Net
генерация изображений
основы обработки текста
задачи обработки текста
предобработка текста перед подачей в ML-модель
библиотеки для работы с текстами в Python
… и много всего другого: рекуррентные нейросети, языковые модели/машинный перевод, трансформеры, GPT, NLP, работа с аудио
Разумеется, не стоит детально углубляться в каждый из пунктов, достаточно иметь общее поверхностное представление.
Полезные ресурсы для понимания Machine Learning в целом:
FAQ — популярные вопросы/ответы
С чего начать изучение ML?
Какой уровень математики необходимо освоить перед изучением машинного обучения (в частности хендбук Яндекса)?
Достаточно ли знаний МатАна и линейной алгебры для карьеры в области машинного обучения?
Изучение machine learning на Python. Можно совет?
С чего начать изучать глубокое обучение?
С чего начать изучение искусственного интеллекта?
Machine Learning и Big Data за три дня?
Как стать data scientist?
Какие есть книги по нейронным сетям и ИИ?
А вот они — заветные вакансии в сфере Machine Learning (взято с Хабр Карьеры, здесь). На большинство позиций, правда, берут Middle+, но в отдельные стартапы можно заскочить и джуну.

Список литературы в дополнение к ресурсам выше — если впитать часть информации из этих книг, можно преисполниться в своём познании:
 «Машинное обучение. Портфолио реальных проектов» — Алексей Григорьев
«Машинное обучение. Портфолио реальных проектов» — Алексей ГригорьевАвтор описывает реалистичные, практичные сценарии машинного обучения, а также предельно понятно раскрывает ключевые концепции. Вы разберете интересные проекты, такие как сервис прогнозирования цен на автомобили с использованием линейной регрессии, сервис прогнозирования оттока клиентов и ещё много других интересных проектов.
 «Python и машинное обучение» — Себастьян Рашка
«Python и машинное обучение» — Себастьян РашкаКнига для новичков, осваивающих Python и машинное обучение. Издание содержит подробные мануалы даже по таким нюансам, как установка специализированного приложения Jupyter Notebook.
 «Создаем нейронную сеть» — Тарик Рашид
«Создаем нейронную сеть» — Тарик РашидЗдесь много наглядных материалов на тему того, как работают конкретные архитектуры сетей, а еще понятно излагаются базовые принципы, которые закладывались в эту технологию. Вывести их самому, по примерам в открытом доступе, довольно сложно.
 «Глубокое обучение. Погружение в мир нейронных сетей» — Николенко С. И.
«Глубокое обучение. Погружение в мир нейронных сетей» — Николенко С. И.Отличная книга, чтобы узнать о ML в целом. За последние годы она уже стала классикой по ML на русском языке, читается легко — почти как художественная.
 «Глубокое обучение» — Ян Гудфеллоу
«Глубокое обучение» — Ян ГудфеллоуЭто хардкор, для тех, кто хочет разобраться в глубинах.
 «Алгоритмы: построение и анализ» — Т. Кормен
«Алгоритмы: построение и анализ» — Т. КорменТут описаны самые разнообразные алгоритмы, сочетается широкий диапазон тем с глубиной и полнотой изложения; при этом изложение доступно для читателей самого разного уровня подготовки.
 «Математические основы машинного обучения и прогнозирования» — Владимир Вьюгин
«Математические основы машинного обучения и прогнозирования» — Владимир ВьюгинЭто пособие рассчитано на студентов и аспирантов и в доступной форме излагает математические основы, необходимые для дальнейшей работы с машинным обучением. Тут раскрываются азы статистической теории машинного обучения, игр с предсказаниями и прогнозирования с применением экспертной стратегии.
 «Верховный алгоритм» — Педро Домингос
«Верховный алгоритм» — Педро ДомингосКлассика) Педро Домингос рассказывает о Machine Learning и о том, как они используют идеи из различных областей — нейробиологии, физики, статистики, биологии, — чтобы помогать людям решать сложные задачи и упрощать рутину с помощью алгоритмов.
 «Крупномасштабное машинное обучение вместе с Python» — Бастиан Шарден, Лука Массарон, Альберто Боскетти
«Крупномасштабное машинное обучение вместе с Python» — Бастиан Шарден, Лука Массарон, Альберто БоскеттиАвторы утверждают, что благодаря книге читатель научится самостоятельно строить модели машинного обучения и развертывать крупномасштабные приложения для прогнозирования. Здесь рассказывается, что такое вычислительная парадигма MapReduce и как работать с машинными алгоритмами на платформах Hadoop и Spark на языке Python.
Напоследок оставлю вот такую подробную roadmap (жёлтым цветом отмечен необходимый минимум; оригинал). Она не кликабельная, но зато наглядно показывает, что и где прокачивать:

Что ещё можно глянуть по ML:
