Концепция BaselineTopology в Apache Ignite 2.4

На момент появления в Apache Software Foundation проекта Ignite он позиционировался как чистое in-memory-решение: распределенный кэш, поднимающий в память данные из традиционной СУБД, чтобы выиграть во времени доступа. Но уже в релизе 2.1 появился модуль встроенной персистентности (Native Persistence), который позволяет классифицировать Ignite как полноценную распределенную базу данных. С тех пор Ignite перестал зависеть от внешних систем обеспечения персистентного хранения данных, и вязанка граблей конфигурации и администрирования, на которые не раз наступали пользователи, исчезла.
Однако persistent-режим порождает свои сценарии и новые вопросы. Как предотвратить неразрешимые конфликты данных в ситуации split-brain? Можем ли мы отказаться от перебалансировки партиций, если выход узла теперь не означает, что данные на нем потеряны? Как автоматизировать дополнительные действия вроде активации кластера? BaselineTopology нам в помощь.
BaselineTopology: первое знакомство
Концептуально кластер в in-memory-режиме устроен просто: выделенных узлов нет, все равноправны, на каждый можно назначить партицию кэша, отправить вычислительную задачу или развернуть сервис. Если же узел выходит из топологии, то запросы пользователей будут обслуживаться другими узлами, а данные вышедшего узла будут более недоступны.
При помощи cluster groups и user attributes пользователь может на основе выбранных признаков распределять узлы по классам. Однако перезапуск любого узла заставляет его «забыть», что происходило с ним до перезапуска. Данные кэшей будут перезапрошены в кластере, вычислительные задачи исполнены повторно, а сервисы развернуты вновь. Раз узлы не хранят состояния, то они полностью взаимозаменяемы.
В режиме персистентности узлы сохраняют свое состояние даже после перезапуска: в процессе старта данные узла считываются с диска, и его состояние восстанавливается. Поэтому перезагрузка узла не приводит к необходимости полного копирования данных с других узлов кластера (процесс, известный как rebalancing): данные на момент падения будут восстановлены с локального диска. Это открывает возможности для очень заманчивых оптимизаций сетевого взаимодействия, и в итоге вырастет производительность всего кластера. Значит, нам нужно как-то отличать множество узлов, способных сохранять своё состояние после перезапуска, от всех остальных. Этой задаче служит BaselineTopology.
Стоит заметить, что пользователь может задействовать persistent-кэши одновременно с in-memory-кэшами. Последние будут продолжать жить той же жизнью, что и раньше: считать все узлы равноправными и взаимозаменяемыми, начинать перераспределение партиций при выходе узлов для поддержания количества копий данных — BaselineTopology будет регулировать только поведение persistent-кэшей.
BaselineTopology (далее BLT) на самом верхнем уровне — это просто коллекция идентификаторов узлов, которые были сконфигурированы для хранения данных. Как создать BLT в кластере и управлять ею, разберемся чуть позже, а сейчас давайте посмотрим, какая от этой концепции польза в реальной жизни.
Persisted-данные: разъезд запрещен
Проблема распределенных систем, известная как split brain, и без того сложная, при использовании persistence становится еще более коварной.
Простой пример: у нас есть кластер и реплицированный кэш.
Стандартным подходом обеспечения отказоустойчивости является поддержание избыточности какого-либо ресурса. Ignite применяет этот подход для обеспечения надежности хранения данных: в зависимости от конфигурации кэш может хранить более одной копии ключа на разных узлах кластера. Реплицированный кэш хранит по одной копии на каждом узле, партицированный — фиксированное количество копий.
Более подробно об этой функции можно узнать из документации.
Произведем над ним простые манипуляции в следующей последовательности:
- Остановим кластер и запустим группу узлов A.
- Обновим какие-либо ключи в кэше.
- Остановим группу A и запустим группу Б.
- Применим другие обновления для тех же самых ключей.
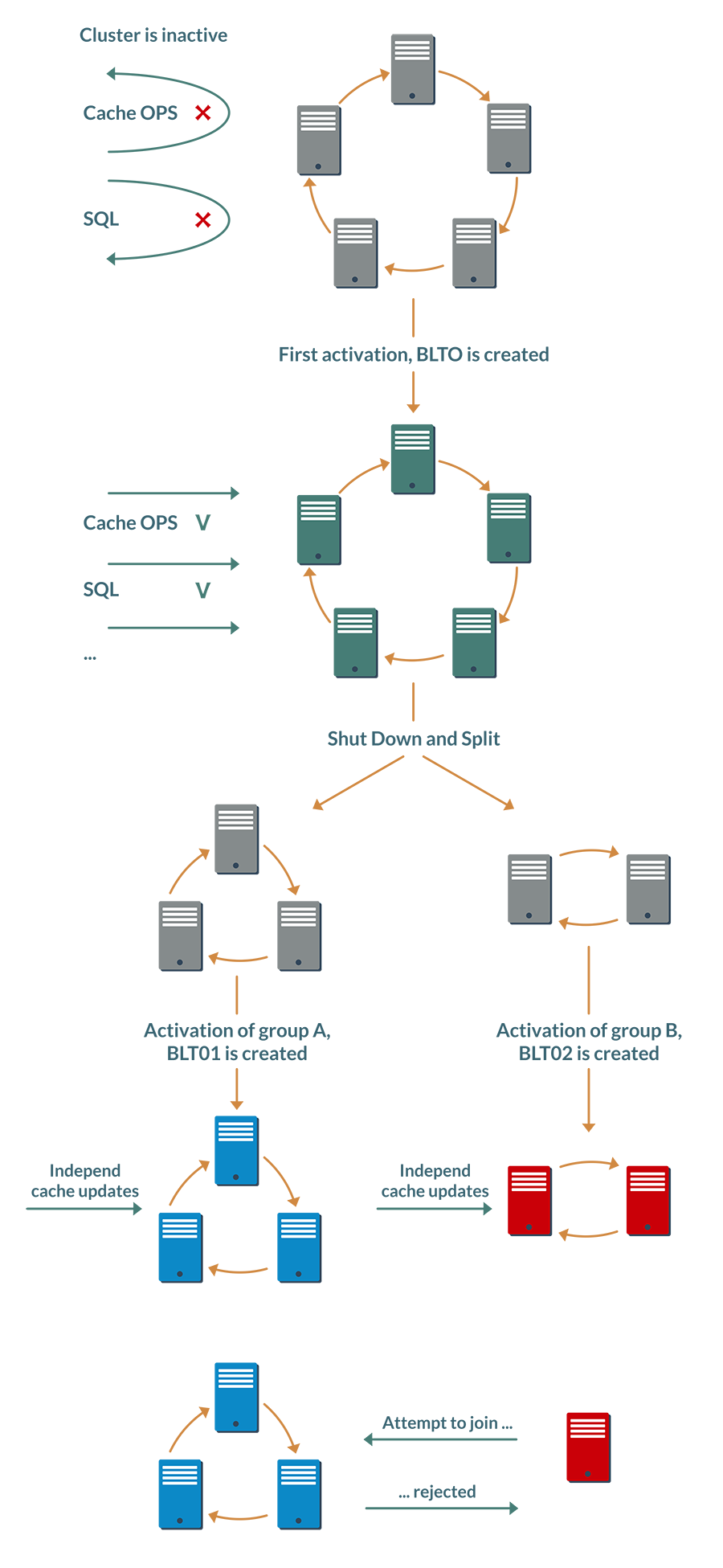
Раз Ignite работает в режиме базы данных, то при остановке узлов второй группы обновления не потеряются: они станут доступны, как только мы снова запустим вторую группу. Так что после восстановления первоначального состояния кластера разные узлы могут иметь разные значения для одного и того же ключа.
Без особых безумств, просто останавливая и запуская узлы, мы смогли привести данные в кластере в неопределенное состояние, разрешить которое автоматически невозможно.
Предотвращение этой ситуации — как раз одна из задач BLT.
Идея в том, что в режиме персистентности запуск кластера проходит через дополнительную стадию, активацию.
При самой первой активации на диске создается и сохраняется первая BaselineTopology, которая содержит информацию обо всех узлах, присутствующих в кластере на момент активации.
Эта информация включает в себя также хэш, вычисленный на основе идентификаторов online-узлов. Если при последующей активации некоторые узлы отсутствуют в топологии (например, кластер перезагружался, а один узел был выведен на обслуживание), то хэш вычисляется заново, а предыдущее значение сохраняется в истории активаций внутри этой же BLT.
Таким образом, BaselineTopology поддерживает цепочку хэшей, описывающих состав кластера на момент каждой активации.
На этапах 1 и 3 после запуска групп узлов пользователю придется явно активировать неполный кластер, и каждый online-узел обновит BLT локально, добавив в нее новый хэш. Все узлы каждой группы смогут вычислить одинаковые хэши, но в разных группах они будут разные.
Вы уже могли догадаться, что произойдет дальше. Если узел попробует присоединиться к «чужой» группе, будет определено, что узел активирован независимо от узлов этой группы, и ему будет отказано в доступе.
Стоит заметить, что этот механизм валидации не даёт полной защиты от конфликтов в ситуации Split-Brain. Если кластер разделился на две половины таким образом, что в каждой половине осталась хотя бы одна копия партиции, и переактивация половин не производилась, то всё равно возможна ситуация, когда в половины поступят конфликтующие изменения одних и тех же данных. BLT не опровергает CAP-теорему, но защищает от конфликтов при явных ошибках администрирования.
Плюшки
Кроме предотвращения конфликтов в данных, BLT позволяет реализовать парочку необязательных, но приятных опций.
Плюшка №1 — минус одно ручное действие. Уже упомянутая выше активация должна была выполняться вручную после каждой перезагрузки кластера; средства автоматизации «из коробки» отсутствовали. При наличии BLT кластер может самостоятельно принять решение об активации.
Хотя Ignite-кластер — эластичная система, и узлы могут добавляться и выводиться динамически, BTL исходит из концепции, что в режиме базы данных пользователь поддерживает стабильный состав кластера.
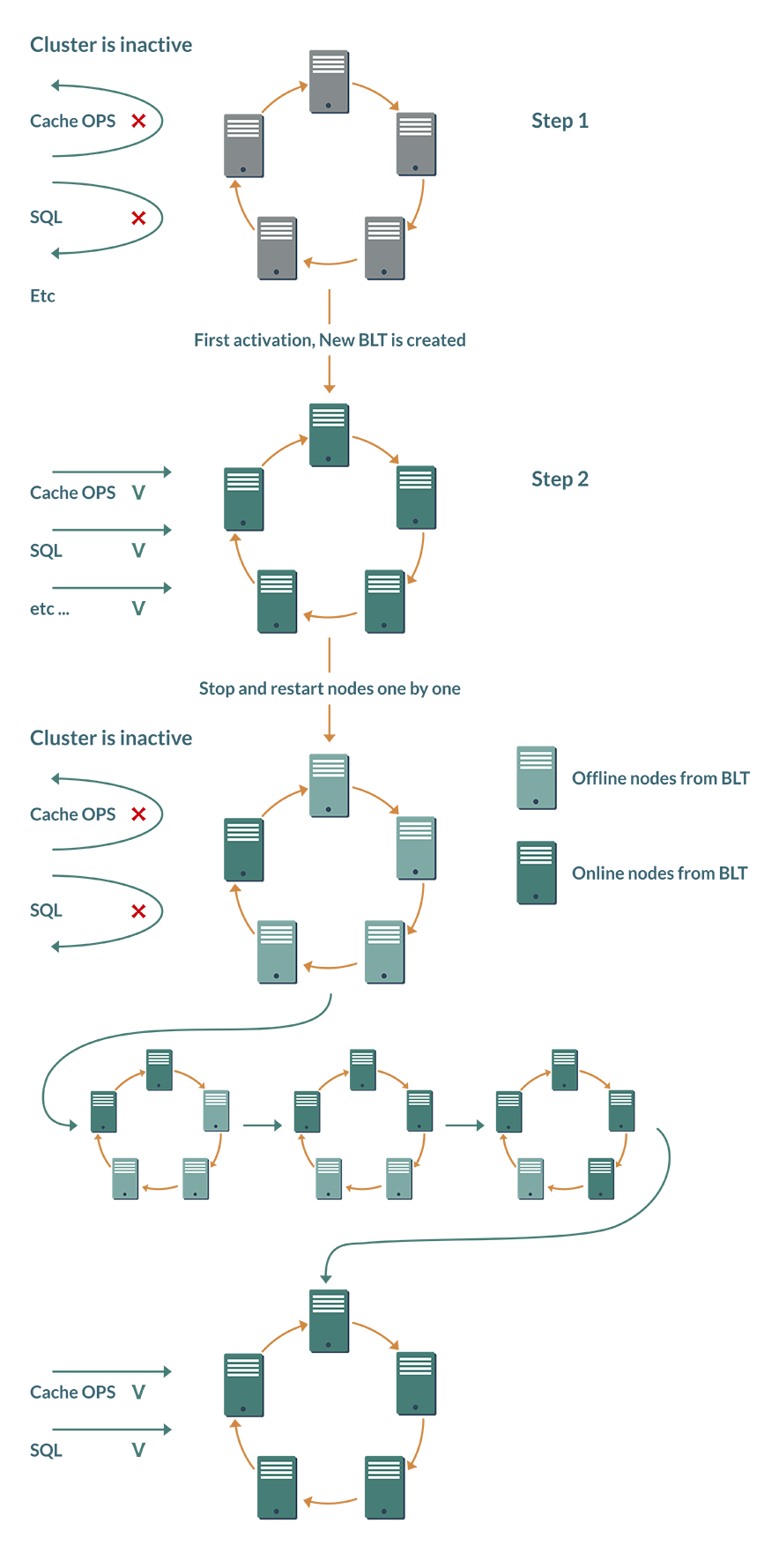
При первой активации кластера свежесозданная BaselineTopology запоминает, какие узлы должны присутствовать в топологии. После перезагрузки каждый узел проверяет статус других узлов BLT. Как только все узлы окажутся в режиме онлайн, кластер активируется автоматически.
Плюшка №2 — экономия на сетевом взаимодействии. Идея, опять же, основана на допущении, что топология будет оставаться стабильной на протяжении длительного времени. Раньше выход узла из топологии даже на 10 минут приводил к запуску ребалансировки партиций кэшей для поддержания количества бэкапов. Но зачем тратить сетевые ресурсы и замедлять работу кластера, если проблемы с узлом решатся в течение минут, и он снова будет в онлайне. BaselineTopology как раз и оптимизирует это поведение.
Теперь кластер по умолчанию предполагает, что проблемный узел скоро вернется в строй. Часть кэшей в течение этого времени будут работать с меньшим количеством бэкапов, однако к прерыванию или замедлению сервиса это не приведет.
Управление BaselineTopology
Что ж, один способ нам уже известен: BaselineTopology автоматически создается при самой первой активации кластера. При этом в BLT попадут все серверные узлы, которые на момент активации были в режиме онлайн.
Ручное администрирование BLT осуществляется с помощью control-скрипта из дистрибутива Ignite, подробнее о котором можно почитать на странице документации, посвященной активации кластера.
Скрипт предоставляет очень простой API и поддерживает всего три операции: добавление узла, удаление узла и установка новой BaselineTopology.
При этом если добавление узлов — достаточно простая операция без особых подвохов, то удаление активного узла из BLT — задача более тонкая. Ее выполнение под нагрузкой чревато гонками, в худшем случае — зависанием всего кластера. Поэтому удаление сопровождается дополнительным условием: удаляемый узел должен быть в оффлайне. При попытке удалить online-узел, control-скрипт вернет ошибку и операция не будет запущена.
Поэтому при удалении узла из BLT по-прежнему требуется одна ручная операция: остановка узла. Впрочем, этот сценарий использования явно не будет основным, так что дополнительные трудозатраты не слишком велики.
Java-интерфейс для управления BLT еще проще и предоставляет всего один метод, позволяющий установить BaselineTopology из списка узлов.
Пример изменения BaselineTopology с помощью Java API:
Ignite ignite = /* ... */;
IgniteCluster cluster = ignite.cluster();
// Получаем BaselineTopology.
Collection curBaselineTop = cluster.baselineTopology();
for (ClusterNode node : cluster.topology(cluster.currentTopologyVersion())) {
// Если мы хотем, чтобы данный узел был в BaselineTopology
// (shouldAdd(ClusterNode) - пользовательская функция)
if (shouldAdd(node)
curTop.add(node);
}
// Обновляем BaselineTopology
cluster.setBaselineTopology(curTop); Заключение
Обеспечение целостности данных — важнейшая задача, которую должно решать любое хранилище данных. В случае распределенных СУБД, к которым относится Apache Ignite, решение этой задачи становится существенно сложнее.
Концепция BaselineTopology позволяет закрыть часть реальных сценариев, в которых целостность данных может нарушиться.
Другим приоритетом Ignite является производительность, и здесь BLT также позволяет заметно экономить ресурсы и улучшать время отклика системы.
Функциональность Native Persistence появилась в проекте совсем недавно, и, без сомнения, будет развиваться, становиться надежнее, производительнее и удобнее в использовании. А вместе с ней будет развиваться и концепция BaselineTopology.
