Классификация больших объемов данных на Apache Spark с использованием произвольных моделей машинного обучения
Часть 2: Решение
И снова здравствуйте! Сегодня я продолжу свой рассказ о том, как мы классифицируем большие объёмы данных на Apache Spark, используя произвольные модели машинного обучения. В первой части статьи мы рассмотрели саму постановку задачи, а также основные проблемы, которые возникают при организации взаимодействия между кластером, на котором хранятся и обрабатываются исходные данные, и внешним сервисом классификации. Во второй части мы рассмотрим один из вариантов решения данной задачи с использованием подхода Reactive Streams и его реализации с использованием библиотеки akka-streams.
Понятие Reactive Streams
Для решения этих проблем можно использовать подход, получивший название Reactive Streams. Он позволяет управлять процессом передачи потоков данных между этапами обработки, работающими с разной скоростью и независимо друг от друга без необходимости буферизации. В случае, если одна из стадий обработки является более медленной, чем предыдущая, то необходимо сигнализировать более быстрой стадии о том, какой объем входных данных она готова обработать в данный момент. Такое взаимодействие получило название back pressure. Оно заключается в том, что более быстрые стадии обрабатывают ровно столько элементов, сколько требуется для работы более медленной стадии, и не больше, а затем освобождают вычислительные ресурсы.
В целом, Reactive Streams представляет собой спецификацию для реализации шаблона Publisher-Subscriber. Эта спецификация определяет набор из четырех интерфейсов (Publisher, Subscriber, Processor и Subscription) и контракт на их методы.
Рассмотрим эти интерфейсы более подробно:
public interface Publisher {
public void subscribe(Subscriber s);
}
public interface Subscriber {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
public interface Subscription {
public void request(long n);
public void cancel();
}
public interface Processor extends Subscriber, Publisher { }
В модели Publisher-Subscriber есть две стороны: передающая и принимающая. При реализации Reactive Streams за передачу данных отвечает класс, реализующий интерфейс Publisher, а за прием — Subscriber. Для установки связи между ними Subscriber должен быть зарегистрирован у Publisher-а путем вызова у него метода subscribe. Согласно спецификации, после регистрации Subscriber-а Publisher обязан вызывать его методы в следующем порядке:
- onSubscribe. Данный метод вызывается сразу же после регистрации Subscriber-а в Publisher-е. В качестве параметра ему передается объект Subscription, через который Subscriber будет запрашивать данные у Publisher-а. Этот объект должен храниться и вызываться только в контексте данного Subscriber-а.
- После того, как Subscriber запросил данные у Publisher-а через вызов метода request у соответствующего объекта Subscription, Publisher может вызвать у Subscriber-а метод onNext, передав следующий элемент.
- Далее Subscriber может периодически вызывать метод request у Subscription, Publisher же не может вызвать метод onNext больше, чем суммарно было запрошено через метод request.
- В случае, если поток данных является конечным, после передачи всех элементов через метод onNext Publisher должен вызвать метод onComplete.
- В случае, если в Publisher-е произошла ошибка и дальнейшая обработка элементов не представляется возможной, он должен вызвать метод onError
- После вызова методов onComplete или onError дальнейшее взаимодействие Publisher-а с Subscriber-ом должно быть исключено.
Вызовы методов могут быть рассмотрены как отправка сигналов между Publisher-ом и Subscriber-ом. Subscriber сигнализирует Publisher-у о том, какое количество элементов он готов обработать, а Publisher, в свою очередь, сигнализирует ему о том, что либо есть следующий элемент, либо больше нет элементов, либо произошла некоторая ошибка.
Для того, чтобы исключить иное влияние Publisher-а и Subscriber-а друг на друга, вызовы всех методов, реализующих интерфейсы Reactive Streams, должны быть неблокирующими. В этом случае взаимодействие между ними будет полностью асинхронным.
Более подробно со спецификацией на интерфейсы Reactive Streams можно ознакомиться здесь.
Таким образом, связав исходный и результирующий итераторы через преобразование их в Publisher и Subscriber соответственно, мы можем решить проблемы, обозначенные в предыдущем разделе. Проблема переполнения буфера между стадиями решается запросом определенного количества элементов Subscriber-ом. Проблема успешного или неуспешного завершения решается путем отправки сигналов Subscriber-у через методы onComplete или onError соответственно. Ответственным за отправку этих сигналов становится Publisher, который в нашем случае должен контролировать, сколько HTTP запросов было отправлено и на сколько из них были получены ответы. После получения последнего ответа и обработки всех пришедших в нем результатов он должен послать сигнал onComplete. В случае, если один из запросов завершился с ошибкой, он должен послать сигнал onError, и прекратить дальнейшую отправку элементов Subscriber-у, а также вычитывание элементов из исходного итератора.
Результирующий итератор должен быть реализован как Subscriber. В этом случае нам не обойтись без буфера, в который будут записываться элементы при вызове метода onNext из интерфейса Subscriber, и вычитываться при помощи методов hasNext и next из интерфейса Iterator. В качестве реализации буфера можно использовать блокирующую очередь, например, LinkedBlockedQueue.
Внимательный читатель сразу же задаст вопрос: почему блокирующая очередь, ведь по спецификации Reactive Streams реализация всех методов должна быть неблокирующей? Но с этим здесь все в порядке: так как мы запрашиваем у Publisher-а строго определенное количество элементов, то метод onNext будет вызван не больше этого количества раз, и очередь всегда сможет добавить новый элемент без блокировки.
С другой стороны, блокировка может возникнуть при вызове метода hasNext в случае пустой очереди. Однако и с этим все в порядке: метод hasNext не является частью контракта интерфейса Subscriber, он определен в интерфейсе Iterator, который, как мы уже выяснили ранее, является блокирующей структурой данных. При вызове метода next мы вычитываем следующий элемент из очереди, и когда ее размер станет меньше определенного порога, мы должны будем запросить следующую порцию элементов через вызов метода request.
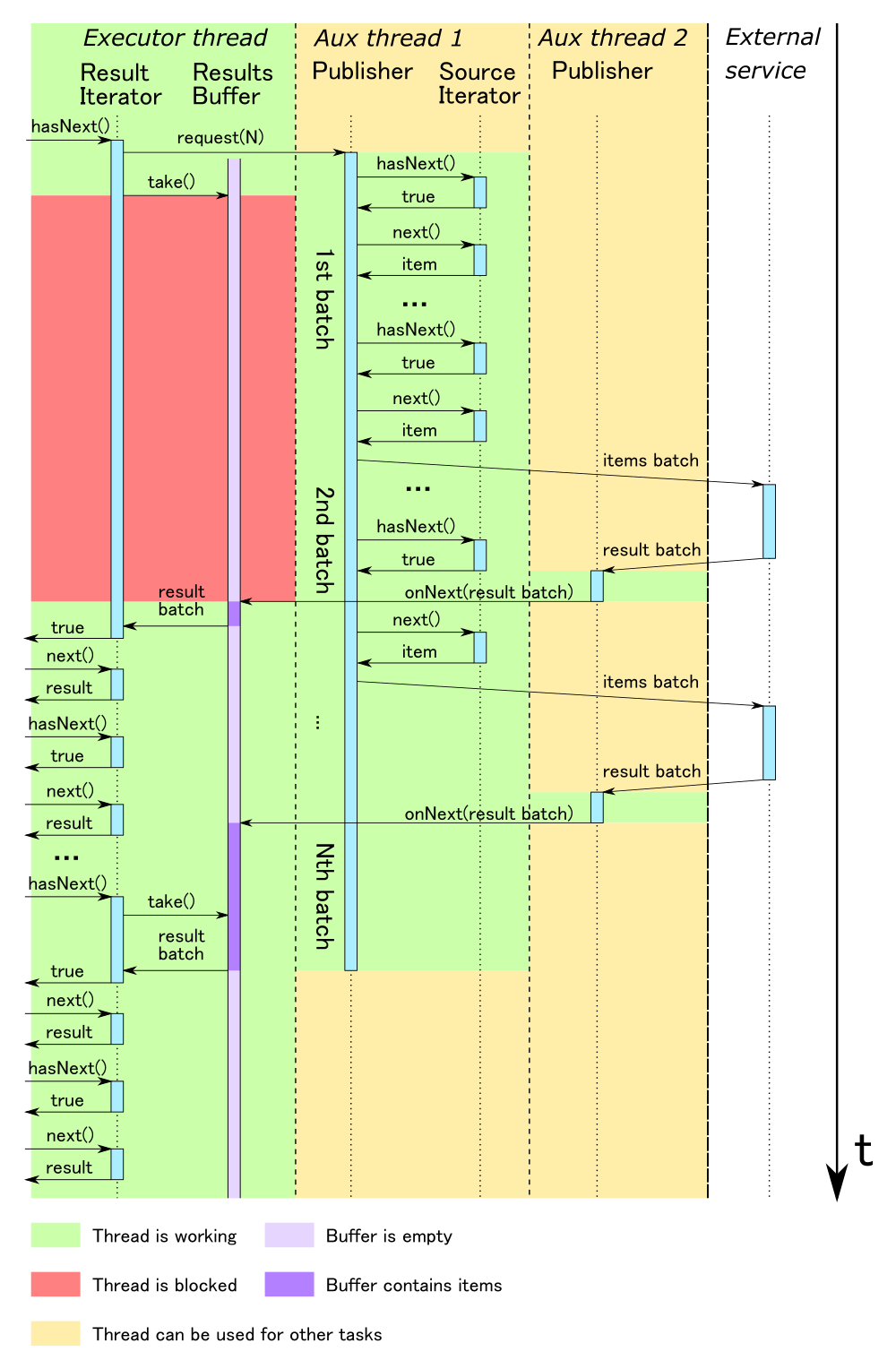
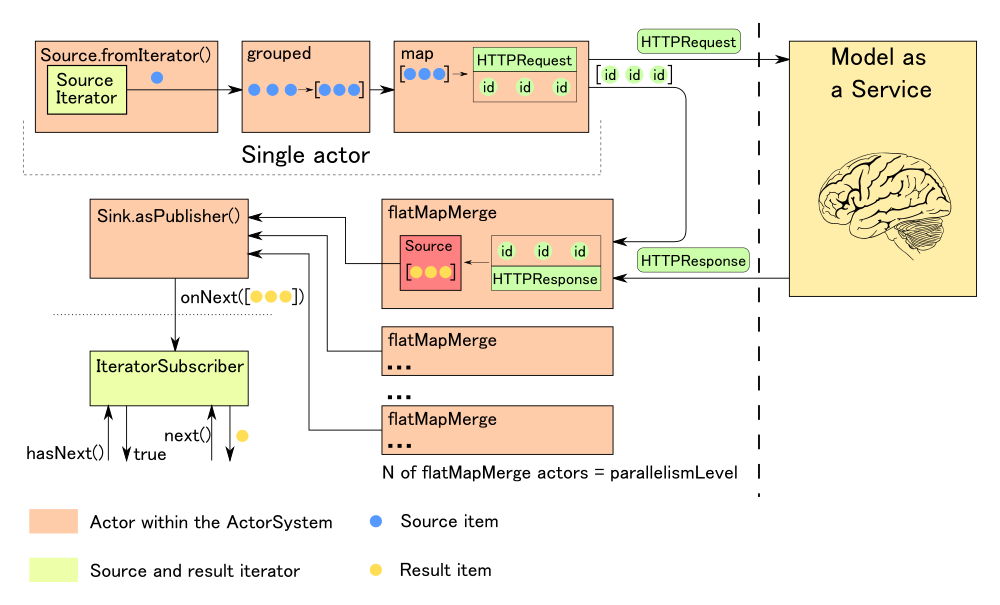
Рисунок 7. Асинхронное взаимодействие с внешним сервисом, используя подход Reactive Streams
Конечно, в данном случае мы полностью не избавимся от блокирующих вызовов. Это вызвано несоответствием парадигм между Reactive streams, которые предполагают полностью асинхронное взаимодействие, и итератором, который на вызов метода hasNext должен обязательно вернуть true или false. Однако в отличие от синхронного взаимодействия с внешним сервисом время простоя из-за блокировок можно существенно сократить, повысив общую загрузку ядер процессора.
Было бы удобно, если бы разработчики Apache Spark в будущих версиях реализовали аналог метода mapPartitions, работающего с Publisher и Subscriber. Это позволило бы реализовать полностью асинхронное взаимодействие, исключив таким образом возможность блокировки потоков.
Akka-streams и akka-http как реализация спецификации Reactive Streams
В настоящее время существует уже более десятка реализаций спецификации Reactive Streams. Одной из таких реализаций является модуль akka-streams из библиотеки akka. В мире JVM akka зарекомендовала себя как одно из наиболее эффективных средств для написания параллельных и распределенных систем. Это достигается за счет того, что основным принципом, заложенным в её основу, является модель акторов, которая позволяет писать высококонкурентные приложения без прямого управления потоками и их пулами.
Про реализацию концепции акторов в akka написано достаточно большое количество литературы, поэтому не будем здесь на этом останавливаться (очень хорошим источником информации является официальный сайт akka, также рекомендую книгу akka in action. Здесь же более подробно рассмотрим технологическую сторону реализации под JVM.
В целом, акторы не существуют сами по себе, а образуют иерархическую систему. Для того, чтобы создать систему акторов, необходимо выделить под нее ресурсы, поэтому первым шагом при работе с akka является создание экземпляра объекта ActorSystem. При запуске ActorSystem создаётся отдельный пул потоков, называемый диспетчером (dispatcher), в которых и выполняется весь код, определенный в акторах. Как правило, один поток выполняет код множества акторов, однако при необходимости можно сконфигурировать отдельный диспетчер под определенную группу акторов (например, для акторов, непосредственно взаимодействующих с блокирующим API).
Одной из наиболее распространенных задач, решаемых с применением акторов, является последовательная обработка потоков данных. Раньше для этого приходилось вручную строить цепочки из акторов и следить за тем, чтобы между ними не возникало узких мест (например, если один актор обрабатывает сообщения быстрее, чем следующий, то у него может возникнуть переполнение очереди входящих сообщений, приводящее к ошибке OutOfMemoryError).
Начиная с версии 2.4, в akka был добавлен модуль akka-streams, который позволяет декларативно определить процесс обработки данных, а затем создать необходимые акторы для его исполнения. В akka-streams также реализован принцип BackPressure, благодаря которому исключается возможность переполнения очереди входящих сообщений у всех участвующих в процессе обработки акторов.
Основными элементами для определения схемы обработки потоков данных в akka-streams являются Source, Flow и Sink. Путем их комбинации между собой мы получаем граф операций (Runnable Graph). Для запуска процесса обработки используется материализатор, который создает акторы, работающие в соответствии с определенным нами графом (интерфейс Materializer и его реализация ActorMaterializer).
Рассмотрим стадии Source, Flow и Sink более подробно. Source определяет источник данных. Akka-streams поддерживает более десятка различных способов создания источников, в том числе и из итератора:
val featuresSource: Source[Array[Float], NotUsed] = Source.fromIterator(() => featuresIterator)
Также Source можно получить путем преобразования имеющегося источника:
Val newSource: Source[String, NotUsed] = source.map(item => transform(item))
В случае, если преобразование является нетривиальной операцией, ее можно представить в виде сущности Flow. Akka-streams поддерживает множество различных способов создания Flow. Самым простым способом является создание из функции:
val someFlow: Flow[String, Int, NotUsed] = Flow.fromFunction((x: String) => x.length)
Объединив Source и Flow, мы получаем новый Source.
Val newSource: Source[Int, NotUsed] = oldSource.via(someFlow)
В качестве финальной стадии обработки данных используется Sink. Как и в случае с Source, akka-streams предоставляет более десятка различных вариантов Sink, например, Sink.foreach выполняет определенную операцию для каждого элемента, Sink.seq собирает все элементы в коллекцию и т.д.
val printSink: Sink[Any, Future[Done]] = Sink.foreach(println)
Source, Flow и Sink параметризованы типами входных и/или выходных элементов соответственно. Помимо этого, каждая стадия обработки может иметь некоторый результат своей работы. Для этого Source, Flow и Sink также параметризованы дополнительным типом, определяющим результат операции. Этот тип называется типом материализуемого значения. В случае, если операция не предполагает наличие дополнительного результата своей работы, например, когда мы определяем Flow через функцию, то в качестве материализуемого значения используется тип NotUsed.
Объединив между собой необходимые Source, Flow и Sink, мы получаем RunnableGraph. Он параметризован одним типом, определяющим тип значения, получаемым в результате выполнения данного графа. В случае необходимости при объединении стадий можно указать, результат работы какой из стадий будет являться результатом выполнения всего графа операций. По умолчанию берется результат выполнения стадии Source:
Val graph: RunnableGraph[NotUsed] = someSource.to(Sink.foreach(println))
Однако если для нас больше важен результат выполнения стадии Sink, то мы должны это явно указать:
val graph: RunnableGraph[Future[Done]] = someSource.toMat(Sink.foreach(println))(Keep.right)
После того, как мы определили граф операций, мы должны его запустить. Для этого у RunnableGraph необходимо вызвать метод run. В качестве параметра этот метод принимает объект ActorMaterializer (который также может находиться в implicit scope), отвечающий за создание акторов, которые будут выполнять операции. Как правило, ActorMaterializer создается сразу же после создания ActorSystem, привязан к ее жизненному циклу и использует ее для создания акторов. Рассмотрим пример:
Implicit val system = ActorSystem("system name”)
//здесь создается новая ActorSystem, под нее выделяется отдельный пул потоков
Implicit val materializer = ActorMaterializer()
//Создаем материализатор, который будет создавать акторы в нашей ActorSystem (поэтому она тоже implicit)
val graph: RunnableGraph[Future[immutable.Seq[Int]]] =
Source.fromIterator(() => (1 to 10).iterator).toMat(Sink.seq)(Keep.right)
//Определяем граф операций и указываем, что нам важен результат выполнения стадии Sink
val result: Future[immutable.Seq[Int]] = graph.run()
//Запускаем граф на выполнение, используя материализатор из implicit scope.
В случае простых комбинаций можно обойтись без создания отдельного RunnableGraph, а просто подключить Source к Sink и запустить их вызовом метода runWith у Source. Данный метод также предполагает, что в implicit scope присутствует объект ActorMaterializer. Кроме того, в этом случае будет использовано материализуемое значение, определенное в Sink. Например, при помощи следующего кода мы можем преобразовать Source в Publisher из спецификации Reactive Streams:
Val source: Source[Score, NotUsed] = Source.fromIterator(() => sourceIterator).map(item => transform(item))
Val publisher: Publisher[Score] = source.runWith(Sink.asPublisher(false))
Итак, сейчас мы показали, как можно получить Reactive Streams Publisher путем создания Source из исходного итератора и выполнив некоторые преобразования над его элементами. Теперь мы можем связать его с Subscriber-ом, поставляющим данные в результирующий итератор. Осталось рассмотреть последний вопрос: как организовать HTTP взаимодействие с внешним сервисом.
В состав akka входит модуль akka-http, который позволяет организовать асинхронное неблокирующее взаимодействие по HTTP. Кроме того, этот модуль построен на основе akka streams, что позволяет добавить HTTP-взаимодействие как дополнительную стадию в графе операций по обработке потока данных.
Для подключения к внешним сервисам akka-http предоставляет три различных интерфейса.
- Request-Level API ‑ является наиболее простым вариантом для случая единичных запросов к произвольной машине. На этом уровне управление HTTP-соединениями происходит полностью автоматически, а в каждом запросе необходимо передавать полный адрес машины, к которой идет запрос.
- Host-Level API — подходит в случае, когда мы знаем, к какому порту на какой машине мы будем обращаться. В этом случае akka-http берет на себя управление пулом HTTP-соединений, а в запросах достаточно указать относительный путь к запрашиваемому ресурсу.
- Connection-Level API — позволяет получить полный контроль над управлением HTTP-соединениями, то есть их открытием, закрытием, и распределением запросов по соединениям.
В нашем случае адрес сервиса классификации нам заранее известен, поэтому необходимо организовать HTTP-взаимодействие только с этой конкретной машиной. Следовательно, для нас лучше всего подходит Host-Level API. Теперь рассмотрим, как происходит создание пула HTTP-соединений при его использовании:
val httpFlow: Flow[(HttpRequest, Id), (Try[HttpResponse], Id), Http.HostConnectionPool] = Http().cachedHostConnectionPool[Id](hostAddress, portNumber)
При вызове Http ().cachedHostConnectionPool[T](hostAddress, portNumber) в ActorSystem, которая находится в implicit scope выделяются ресурсы для создания пула соединений, однако сами соединения не устанавливаются. В качестве значения в результате данного вызова возвращается Flow, который на вход принимает пару из HTTP-запроса и некоторого идентификационного объекта Id. Идентификационный объект нужен для того, чтобы сопоставить запрос с соответствующим ему ответом вследствие того, что HTTP вызов в akka-http является асинхронной операцией, и порядок, в котором поступают ответы, не обязательно соответствует порядку отправки запросов. Поэтому на выходе Flow дает пару из результата выполнения запроса и соответствующего ему идентификационного объекта.
Непосредственно HTTP-соединения устанавливаются тогда, когда происходит запуск (материализация) графа, включающего в себя данный Flow. Akka-http реализована так, что независимо от того, сколько раз были материализованы графы, содержащие httpFlow, в рамках одной ActorSystem всегда будет один общий пул HTTP-соединений, который будет использоваться всеми материализациями. Это позволяет лучше контролировать использование сетевых ресурсов и избегать их перегрузки.
Таким образом, жизненный цикл пула HTTP-соединений привязан к ActorSystem. Как уже было упомянуто ранее, к ней также привязан жизненный цикл пула потоков, в которых выполняются операции, определенные в акторах (или в нашем случае определенные как стадии akka-streams и akka-http). Следовательно, для достижения максимальной эффективности мы должны переиспользовать один экземпляр ActorSystem в рамках одного JVM процесса.
Putting this all together: пример реализации взаимодействия с сервисом классификации
Итак, теперь мы можем перейти к рассмотрению процесса классификации больших объемов распределенных данных на Apache Spark с использованием асинхронного взаимодействия с внешними сервисами. Общая схема такого взаимодействия уже была приведена на рисунке 7.
Предположим, что у нас определен некоторый исходный Dataset [Features]. Применяя к нему операцию mapPartitions, мы должны получить Dataset, в котором каждому id из исходного набора проставлено некоторое значение, полученное в результате классификации (Dataset[Score]). Для организации асинхронной обработки на исполнителях мы должны обернуть исходный и результирующий итераторы соответственно в Publisher и Subscriber из спецификации Reactive streams и связать их между собой.
case class Features(id: String, vector: Array[Float])
case class Score(id: String, score: Float) //(1)
val batchesRequestCount = config.getInt("scoreService. batchesRequestCount”)//(2)
...
Val scoreDataset: Dataset[Score] = featuresDataset.mapPartitions {fi: Iterator[Features] =>
Val publisher: Publisher[Iterable[Score]] = createPublisher(fi) //(3)
Val iteratorSubscriber: Iterator[Score] = new IteratorSubscriber(batchesRequestCount) //(4)
publisher.subscribe(batchesRequestCount) //(5)
iteratorSubscriber //(6)
}
В данной реализации учтено, что сервис классификации за одно обращение может обработать сразу группу feature-векторов, следовательно, результат классификации после обращения к нему также будет доступен сразу для всей группы. Поэтому в качестве типа-параметра у Publisher у нас не просто Score, как можно было бы ожидать, а Iterable[Score]. Таким образом, мы отправляем в результирующий итератор (являющийся также Subscriber-ом) результаты классификации для этой группы однократным вызовом метода onNext. Это гораздо эффективнее, чем вызывать onNext для каждого элемента. Теперь разберем этот код более детально.
- Определяем структуру входных и выходных данных. В качестве входных данных у нас будет связка некоторого идентификатора id с feature-вектором, в качестве выходных — связка идентификатора с числовым значением, полученным в результате классификации.
- Определяем количество групп, которые Subscriber будет запрашивать у Publisher-а за один раз. Так как предполагается, что эти значения будут лежать в буфере и ждать, пока их прочитают из результирующего итератора, то эта величина зависит от объема памяти, выделенного исполнителю.
- Создаем Publisher из исходного итератора. Он и будет отвечать за взаимодействие с сервисом классификации. Функция createPublisher рассмотрена чуть ниже.
- Создаем Subscriber, который будет являться результирующем итератором. Код класса IteratorSubscriber также приведен ниже.
- Регистрируем Subscriber у Publisher-а.
- Возвращаем IteratorSubscriber в качестве результата операции mapPartitions.
Теперь рассмотрим реализацию функции createPublisher.
type Ids = Seq[String] //(1)
val batchSize = config.getInt("scoreService.batchSize”)
val parallelismLevel = config.getInt("scoreService.parallelismLevel”) //(2)
...
def createPublisher(fi: Iterator[Features]): Publisher[Iterable[Score]] = {
import ActorSystemHolder._ //(3)
Source
.fromIterator(() => fi) //(4)
.grouped(batchSize) //(5)
.map { groupedFeatures: Seq[Features] =>
val request: (HttpRequest, Ids) = createHttpRequest(groupedFeatures) //(6)
logger.debug(s"Sending request for the first id: ${request._2(0)}")
request
}
.via(httpFlow) //(7)
.flatMapMerge(parallelismLevel, { //(8)
case (Success(response), ids) if response.status.isSuccess() =>
logger.debug(s"Processing successful result for the first id: ${ids(0)}")
val resultSource: Source[Iterable[Score], _] = response.entity.dataBytes.reduce(_ ++ _).map { responseBytes =>
processSuccessfulResponse(responseBytes, ids)
} //(9)
resultScore
case (Success(response), ids) =>
logger.warn(s"Failed result for the first id: ${ids(0)}: the server has returned ${response.status} status")
response.discardEntityBytes()
Source.failed(new IOException(s"Non-successful HTTP response status has been returned: ${response.status}")) //(10)
case (Failure(ex), ids) =>
logger.warn(s"Failed result: an exception has occured", ex)
Source.failed(ex) //(11)
})
.runWith(Sink.asPublisher(false)) //(12)
}
def createHttpRequest(featuresSeq: Seq[Features]): (HttpRequest, ProfileIds) = {
val requestBytes: Array[Byte] = featuresToMatrixBytes(featuresSeq)
val ids: ProfileIds = extractIds(featuresSeq)
val httpRequest = HttpRequest(
method = HttpMethods.PUT,
uri = "/score",
entity = requestBytes
)
httpRequest -> ids
}
- Здесь мы определяем тип-алиас для списка идентификаторов, входящих в группу. Он нужен в первую очередь для удобства использования http flow, чтобы мы могли сопоставить результат классификации для группы с соответствующими идентификаторами.
- Получаем необходимые параметры из конфигурации: число исходных элементов в группе, отправляемой в одном запросе (batchSize) и уровень параллелизма для стадии обработки ответов (parallelismLevel).
- Импортируем в implicit scope ActorSystem, ActorMaterializer и httpFlow. Данные объекты являются глобальными в контексте отдельного Spark-исполнителя. Объект ActorSystemHolder будет рассмотрен чуть ниже.
- Здесь начинается определение стадий akka-streams для организации взаимодействия. Для начала мы создаем Source[Features] из исходного итератора.
- Затем мы объединяем исходные элементы в группы размером не более величины batchSize для отправки одним запросом во внешний сервис.
- После этого мы создаем HttpRequest и связываем его со списком идентификаторов группы. За формирование HttpRequest из исходных данных отвечает функция createHttpRequest. Ее код приведен после метода createPublisher. В ней мы берем все feature-векторы, входящие в группу, и объединяем их в матрицу (которая на стороне сервиса классификации будет передана в качестве аргумента для метода predict). Затем мы сериализуем ее в массив байтов, который будет передан в теле HTTP-запроса. Далее выделяется последовательность идентификаторов для группы, и формируется HTTP-запрос, в котором указываются HTTP-метод, URI ресурса для классификации и тело запроса.
- Отправляем полученный запрос ко внешнему сервису используя httpFlow.
- Далее следует стадия обработки ответов, полученных от сервиса. Для этого мы используем операцию flatMapMerge, так как бинарное представление тела ответа в akka-http представлено в виде Source[ByteString], который мы должны преобразовать таким образом, чтобы он содержал результаты классификации для группы. После этого мы должны подключить его к нашему основному графу операций. Параметр parallelismLevel определяет, сколько ответов может обрабатываться одновременно (смотри схему в конце данного раздела). Мы рассмотрим три варианта результата HTTP-взаимодействия: получение успешного ответа, получение ответа, содержащего ошибку, и ошибка коммуникации.
- Обработка результата успешного выполнения происходит следующим образом: сначала мы объединяем все части тела ответа в один массив. Для представления бинарных массивов в akka есть специальный класс ByteString. Он реализован таким образом, что конкатенация двух ByteString является операцией с O (1), то есть два ByteString просто связываются друг с другом без копирования содержимого. Так как мы знаем максимальный размер группы, то мы можем гарантировать, что объединение всех частей ответа не вызовет переполнение памяти. После получения массива со всеми байтами ответа мы объединяем его со списком идентификаторов и формируем коллекцию, содержащую результаты классификации для группы.
- В случае получения ответа с неуспешным HTTP-статусом мы должны прекратить дальнейшую обработку, завершив Stream ошибкой. В этом случае нас не интересует содержание тела запроса, поэтому мы должны вызвать метод discardEntityBytes у ответа для того, чтобы освободить ресурсы пула, занимаемые им.
- В случае ошибки коммуникации мы также должны прекратить обработку. При проблемах на уровне коммуникации akka-http автоматически пытается повторить запрос, однако при превышении определенного порога выбрасывает исключение.
- Здесь происходит материализация всего процесса обработки данных, результатом которой является Publisher, отдающий результаты классификации для групп. Именно здесь запускаются акторы, отвечающие за его работу. Параметр false у метода Sink.asPublisher показывает, что результирующий Publisher поддерживает только одного Subscriber-а.
Как мы отметили в предыдущем разделе, для работы с akka нужна ActorSystem, которую необходимо один раз создать и затем переиспользовать. К сожалению, у нас нет возможности вызвать глобальное окружение Spark исполнителя, но мы можем прибегнуть к стандартным методом создания глобальных объектов. Так как Spark исполнитель является отдельным JVM процессом, следовательно, в рамках него мы можем создать глобальный объект, в котором будем хранить ActorSystem и использующие её ActorMatrializer и httpFlow.
object ActorSystemHolder {
implicit lazy val actorSystem: ActorSystem = { //(1)
val actorSystemName = s"score-service-client"
logger.debug(s"Creating actor system $actorSystemName")
val as = ActorSystem(actorSystemName) //(2)
logger.debug("Adding shutdown hook for the actor system")
scala.sys.addShutdownHook { //(3)
logger.debug(s"Terminating actor system $actorSystemName")
Await.result(as.terminate(), 30.seconds) //to Mars :)
logger.debug(s"The actor system $actorSystemName has been successfully terminated")
}
as
}
implicit lazy val materializer: ActorMaterializer = { //(4)
logger.debug(s"Creating actor materializer for actor system ${actorSystem.name}")
ActorMaterializer()
}
lazy val httpFlow: Flow[(HttpRequest, ProfileIds), (Try[HttpResponse], ProfileIds), Http.HostConnectionPool] = { //(5)
val httpFlowSettings = ConnectionPoolSettings(actorSystem)
logger.debug(s"Creating http flow for actor system ${actorSystem.name} with settings $httpFlowSettings")
Http().cachedHostConnectionPool[ProfileIds](
config.getString("scoreService.host”),
config.getInt("scoreService.int”),
settings = httpFlowSettings
)
}
}
- Все глобальные переменные мы создаем, используя ленивую инициализацию, то есть фактически они будут созданы тогда, когда будут первый раз востребованы.
- Здесь создается новая ActorSystem с определенным именем.
- Для того, чтобы корректно завершить все процессы, исполняемые в рамках ActorSystem, мы должны вызвать у нее метод terminate, который, в свою очередь, остановит все акторы, используя их стандартный механизм остановки. Для этого мы должны зарегистрировать хук, вызываемый при завершении работы JVM-процесса.
- Далее мы создаем ActorMaterializer, который будет запускать выполнение процессов akka-streams, используя нашу ActorSystem.
- Наконец, мы создаем httpFlow для взаимодействия с внешним сервисом. Как было упомянуто в предыдущем разделе, здесь мы выделяем ресурсы для пула HTTP-соединений в рамках ActorSystem.
Теперь рассмотрим реализацию результирующего итератора как Subscriber-а у нашего процесса HTTP-взаимодействия.
sealed trait QueueItem[+T]
case class Item[+T](item: T) extends QueueItem[T]
case object Done extends QueueItem[Nothing]
case class Failure(cause: Throwable) extends QueueItem[Nothing] //(1)
class StreamErrorCompletionException(cause: Throwable) extends Exception(cause) //(2)
class IteratorSubscriber[T](requestSize: Int) extends Subscriber[Iterable[T]] with Iterator[T] { //(3)
private val buffer: BlockingQueue[QueueItem[Iterable[T]]] = new LinkedBlockingQueue[QueueItem[Iterable[T]]]() //(4)
private var expecting: Int = 0 //(5)
private val subscriptionPromise: Promise[Subscription] = Promise()
private lazy val subscription: Subscription = Await.result(subscriptionPromise.future, 5.minutes) //(6)
private var currentIterator: Iterator[T] = Iterator.empty //(7)
override def onSubscribe(s: Subscription): Unit = {
subscriptionPromise.success(s) //(8)
logger.trace("The iterator has been subscribed")
}
override def onNext(t: Iterable[T]): Unit = {
logger.trace("Putting a next batch to the buffer")
buffer.put(Item(t)) //(9)
}
override def onComplete(): Unit = {
logger.debug("The stream has been completed")
buffer.put(Done) //(10)
}
override def onError(t: Throwable): Unit = {
logger.warn("The stream has been completed with error", t)
buffer.put(Failure(t)) //(11)
}
override def hasNext: Boolean = {
logger.trace("Asking hasNext")
if (currentIterator.hasNext) { //(12)
true
} else {
if (expecting < requestSize) {
requestNextBatches() //(13)
}
buffer.take() match { //(14)
case Item(batch) =>
currentIterator = batch.iterator
expecting -= 1
this.hasNext //(15)
case Done =>
false //(16)
case Failure(exception) =>
throw new StreamErrorCompletionException(exception) //(17)
}
}
}
override def next(): T = {
val out = currentIterator.next()
logger.trace("The next element is {}", out)
out //(18)
}
private def requestNextBatches(): Unit = {
logger.debug(s"Requesting {} batches", requestSize)
subscription.request(requestSize)
expecting += requestSize //(19)
}
}
Класс IteratorSubscriber является реализацией модели Producer-Consumer. Та его часть, которая реализует интерфейс Subscriber, является Producer-ом, а та, которая реализует Iterator, — Consumer-ом. В качестве средства коммуникации используется буфер, реализованный в виде блокирующей очереди. Методы из интерфейса Iterator вызываются в потоке из пула исполнителя Apache Spark, а методы интерфейса Subscriber — в пуле, принадлежащем ActorSystem.
Теперь рассмотрим приведенный код реализации IteratorSubscriber более подробно.
- Для начала мы определяем алгебраический тип данных для элементов буфера. В буфере у нас могут лежать либо следующая группа элементов, либо признак успешного завершения Done, либо признак неуспешного завершения, содержащий Throwable, который послужил причиной ошибки.
- Также мы определяем класс для исключения, который мы должны будем выбросить из метода hasNext в случае неуспешного завершения.
- Определяем конструктор, который принимает количество групп, которые будем запрашивать за один раз у Publisher-а.
- Создаем экземпляр блокирующей очереди, используемой в качестве коммуникационного буфера. Так как используется LinkedBlockingQueue, то размер буфера потенциально не ограничен. Следовательно, мы можем класть туда элементы без необходимости блокировки потока.
- Данная переменная содержит количество запрошенных, но не обработанных элементов. Она нам необходима для того, чтобы знать суммарное количество элементов в буфере и тех, которые сейчас находятся в процессе подготовки Publisher-ом. Используя это значение, мы сможем определить момент, когда нам нужно запросить у Publisher-а следующую порцию данных. Так как данная переменная используется только в методах hasNext и next (метод requestNextBatches вызывается только из hasNext), то с ней взаимодействует только один поток, поэтому к ней не нужно синхронизировать доступ.
- Поля subscriptionPromise и subscription используются для хранения объекта Subscription, который нам передаст Publisher при вызове метода onSubscribe. Напомню, что по спецификации Reactive Streams данный метод должен быть вызван при регистрации Subscriber-а у Publisher-а перед вызовом всех остальных методов, однако существует вероятность, что метод hasNext будет вызван раньше, чем onSubscribe. В этом случае нам необходимо дождаться, когда будет доступен объект subscription, через который мы сможем запросить первую группу элементов у Publisher-а. Для этого используется модификатор lazy у поля subscription, которое инициализируется через Promise.
- Здесь будет храниться итератор для текущей группы. Взаимодействие с этой переменной также происходит только в методах hasNext и next, то есть из одного потока, поэтому к ней не нужно синхронизировать доступ.
- При вызове метода onSubscribe мы сохраняем переданный Publisher-ом объект Subscription путем успешного завершения Promise, из которого он будет сохранен в поле subscription.
- onNext вызывается Publisher-ом, когда будет готов результат классификации для очередной группы. Полученный результат кладется в конец очереди.
- В случае успешного завершения процесса обработки Publisher вызывает метод onComplete, и мы ставим в очередь признак успешного окончания обработки Done.
- В случае ошибки Publisher вызывает метод onError. В очередь ставится признак неуспешного окончания обработки.
- При вызове метода hasNext мы в первую очередь проверяем, остались ли элементы в текущем итераторе. Если элементы в нем еще есть, то мы возвращаем true, таким образом исключая необходимость взаимодействия с буфером. Если же текущий итератор пуст, то мы должны достать следующую группу результатов из очереди.
- В случае, если количество запрошенных, но не обработанных групп становится меньше величины requestSize, мы запрашиваем следующую порцию данных у Publisher. Для запроса следующей порции мы не должны дожидаться момента, когда буфер станет пустым, а запросить новые данные заранее, так как Publisher-у нужно время на то, чтобы выполнить HTTP-запрос и обработать результат его выполнения.
- Здесь мы берем следующую группу элементов из очереди. В случае, если очередь пуста, мы блокируем поток до того момента, как в буфере появится следующий элемент. По сути, это единственное место во всей нашей схеме, где используется блокирующее взаимодействие (еще одним местом, где возможно блокирующее взаимодействие, является запрос первой группы элементов через объект subscription), но, как мы уже показали ранее, это вызвано тем, что сам итератор является блокирующей структурой.
- Если в очереди содержится следующая группа результатов, то мы преобразуем ее в итератор и сохраняем в поле currentIterator. Также мы уменьшаем количество ожидаемых элементов на единицу, так как мы только что обработали очередной элемент из буфера. Наконец, мы делаем рекурсивный вызов к методу hasNext для того, что если вдруг в очереди окажется пустая группа (этого вообще не должно быть, но мало ли), то мы бы сразу перешли к обработке следующей.
- Когда данные подойдут к концу, мы должны вернуть false в полном соответствии с семантикой вызова метода hasNext.
- Если произошла ошибка в процессе обработки потока данных, мы должны выбросить исключение, сигнализировав вызывающей стороне о том, что необходимо прекратить дальнейшую обработку.
- Метод next отдает следующий элемент из текущего итератора. Согласно семантике его вызова, перед этим вызывающая сторона должна вызвать метод hasNext, поэтому при вызове next в текущем итераторе всегда должен быть следующий элемент.
- Здесь мы отправляем сигнал Publisher-у о том, что мы готовы обработать следующую группу результатов, используя объект subscription, который мы получили при регистрации у Publisher-а. Количество групп определяется значением requestSize. Также мы увеличиваем количество ожидаемых элементов на эту величину.
Таким образом, общая схема полной обработки для блока данных, запускаемая на исполнителе, выглядит вот так:
Рисунок 8. Взаимодействие акторов с исходным и результирующим итераторами.
В заключение: преимущества и недостатки данного решения
К безусловным преимуществам можно отнести то, что данная схема позволяет работать с моделями машинного обучения, реализованными с использованием любых доступных средств. Это достигается за счет того, что для обращения к модели используется HTTP протокол, являющийся стандартным средством коммуникации между приложениями. Благодаря этому реализация модели не привязана к ее интерфейсу.
Еще одно
