Key-value для хранения метаданных в СХД. Тестируем встраиваемые базы данных

7–8 ноября 2017 на конференции Highload++ исследователи лаборатории «Рэйдикс» представили доклад «Метаданные для кластера: гонка key-value-героев».
В этой статье мы представили основной материал доклада, касающийся тестирования баз данных key-value. «Зачем их тестировать производителю СХД?», — спрóсите вы. Задача возникла в связи с проблемой хранения метаданных. Такие «фичи», как дедупликация, тиринг, тонкое выделение ресурсов (thin provisioning), лог-структурированная запись, идут вразрез с механизмом прямой адресации — возникает необходимость хранить большое количество служебной информации.
Введение
Предположим, что всё пространство хранения поделено на страницы размером X байт. У каждой из них есть свой адрес — LBA (8 Байт). Для каждой такой страницы мы хотим хранить Y байт метаданных. Таким образом, получаем набор соответствий lba → metadata. Сколько таких соответствий у нас будет? Всё зависит от того, сколько данных мы будем хранить.
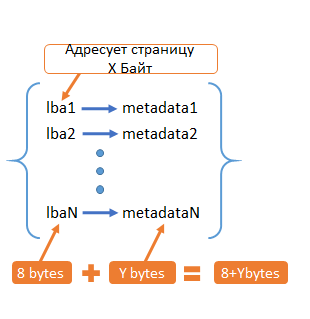
Рис. 1. Метаданные
Например, при X=4KB, Y=16 байта. Получаем следующую таблицу:
Таблица 1. Соотношение объема хранения и метаданных
| Объем данных на узел | Количество ключей на узел | Объем метаданных |
|---|---|---|
| 512ТБ | 137 млрд | 3ТБ |
| 64ТБ | 17 млрд | 384ГБ |
| 4ТБ | 1 млрд | 22.3ГБ |
Объём метаданных достаточно большой, поэтому держать метаданные в RAM не представляется возможным (либо это экономически нецелесообразно). В связи с этим возникает вопрос хранения метаданных, причем с максимальной производительностью доступа.
Варианты хранения метаданных
- Key-value БД. lba — ключ, metadata — значение
- Прямая адресация. Не храним lba = метаданных N*Y, а не N*(8+Y)Б
Что такое прямая адресация? Это когда мы просто размещаем на накопителе наши метаданные по порядку, начиная с самого первого сектора накопителя. При этом нам даже не надо записывать, какому lba соответствуют метаданные, так как всё лежит в порядке возрастания lba.
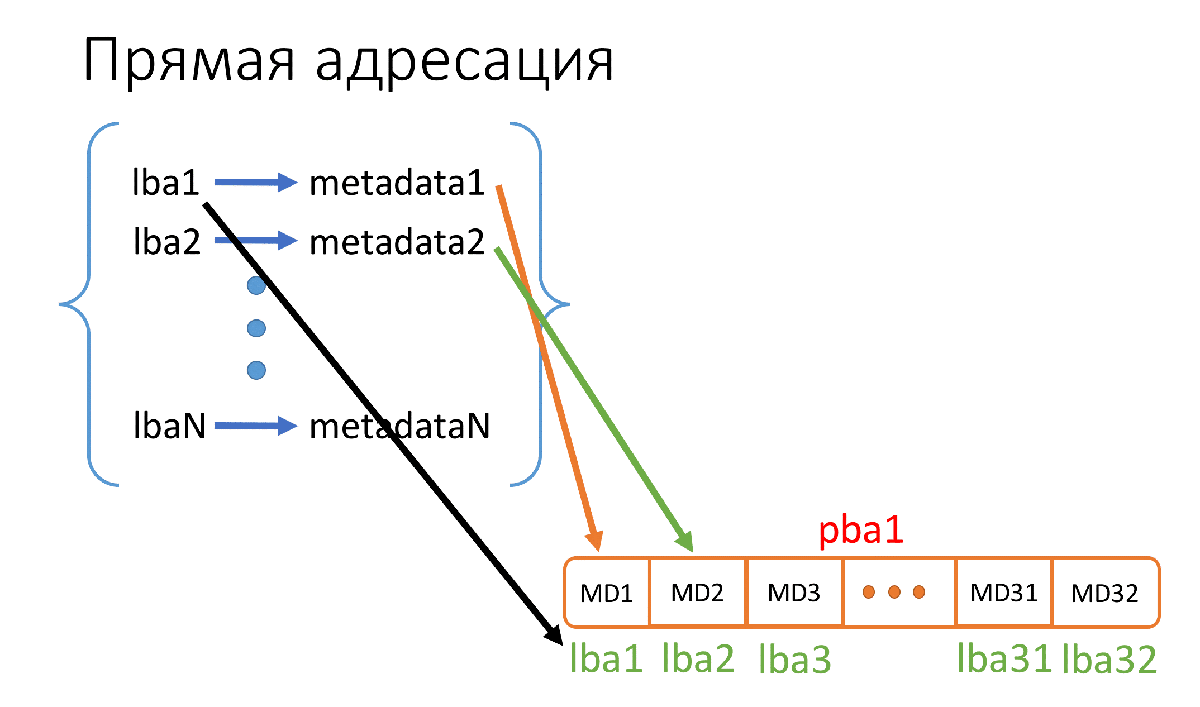
Рис. 2. Принцип работы прямой адресации
На рисунке 2 pba1 — это физический сектор (512Б) накопителя, где мы храним метаданные, а lba1…lba32 (их 32, т.к. 512Б/16Б = 32) — адреса тех страниц, которым эти метаданные соответствуют, и эти адреса нам хранить не надо.
Анализ рабочей нагрузки в СХД
Исходя из нашего опыта рабочих нагрузок, определимся, какие требования по задержкам и пропускной способности нам нужны.
Рабочая нагрузка в медиаиндустрии:
- NLE (нелинейный монтаж) — чтение и запись нескольких больших файлов параллельно.
- VOD (видео по запросу) — чтение множества потоков, иногда с перескоками. Возможна параллельная запись в несколько потоков.
- Транскодинг — 16–128 KB random R/W 50/50.
Рабочая нагрузка в сегменте Enterprise:
- 8–64 KB IO.
- Random read/write примерно 50/50.
- Периодически Seq Read и Write в сотни потоков (Boot, Virus Scan).
Рабочая нагрузка в высокопроизводительных вычислениях (High Performance Computing — HPC):
- 16/32 KB IO.
- Чередование read/write в сотнях и тысячах потоков.
Из представленных рабочих нагрузок в различных отраслях рынка сформируем итоговые требования к производительности All-Flash СХД:
- Показывать:
• Задержки (latency) 1–2 мс (перцентиль 99.99%) для flash.
• От 20ГБ/с, от 300–500k IOPS. - На следующих нагрузках:
• Случайные R/W.
• Соотношение 50/50.
• Размер блоков 8–64K.
Чтобы выбрать, какая БД из десятков существующих нам подойдёт, надо провести тесты на избранных нагрузках. Так мы сможем понять, как та или иная БД справляется с определённым объёмом данных, какие обеспечивает задержки/пропускную способность.
Какие сложности возникают на старте?
- Придётся выбрать всего несколько БД для тестов — все протестировать не получится. Как выбрать эти несколько? Только субъективно.
- В идеале нужно проводить тщательную настройку каждой БД перед тестированием, на что может понадобиться огромное количество времени. Поэтому мы решили сначала посмотреть на то, какие цифры можно получить в стандартной конфигурации, а потом принять решение, насколько перспективно тестирование.
- Сделать тесты полностью объективными и создать одинаковые условия для каждой из БД довольно сложно ввиду принципиальных различий между базами.
- Мало бенчмарков или их сложно найти. Нужны именно унифицированные бенчмарки, которыми можно протестировать любую (или почти любую) key-value БД, или хотя бы несколько самых интересных. При тестировании разных БД разными бенчмарками страдает объективность.
Типы key-value БД
Существует два типа key-value баз данных:
- Встраиваемые — ещё их называют «движки». По сути, это библиотека, которую можно подключить у себя в коде и пользоваться её функциями.
- Выделенные — ещё можно назвать их «сервер БД», «NoSQL БД». Это отдельные процессы, к котором чаще всего можно обращаться по сокетам. Обычно имеют больше функций, чем встраиваемые. Например, репликация.
В этой статье мы рассмотрим тестирование встраиваемых key-value БД (далее по тексту будем называть их «движками»).
Чем тестировать?
Первый вариант, который можно найти, — YCSB.
Особенности YCSB:
- Этот бенчмарк является неким отраслевым стандартом, ему доверяют.
- Workload’ы можно легко настраивать в файлах конфигурации.
- Написан на Java. В данном случае это минус, т.к. Java не слишком быстродействена, и это может вносить в результаты тестирования искажения. К тому же, движки, в основном, написаны на C/C++. Это затрудняет написание драйвера YCSB <-> движок.
Второй вариант — бенчмарк для движков ioarena.
- Написан на C.
- Мало workload’ов. Из тех, которые нам интересны, есть только Random Read. Пришлось дописывать в коде нужные нам workload’ы.
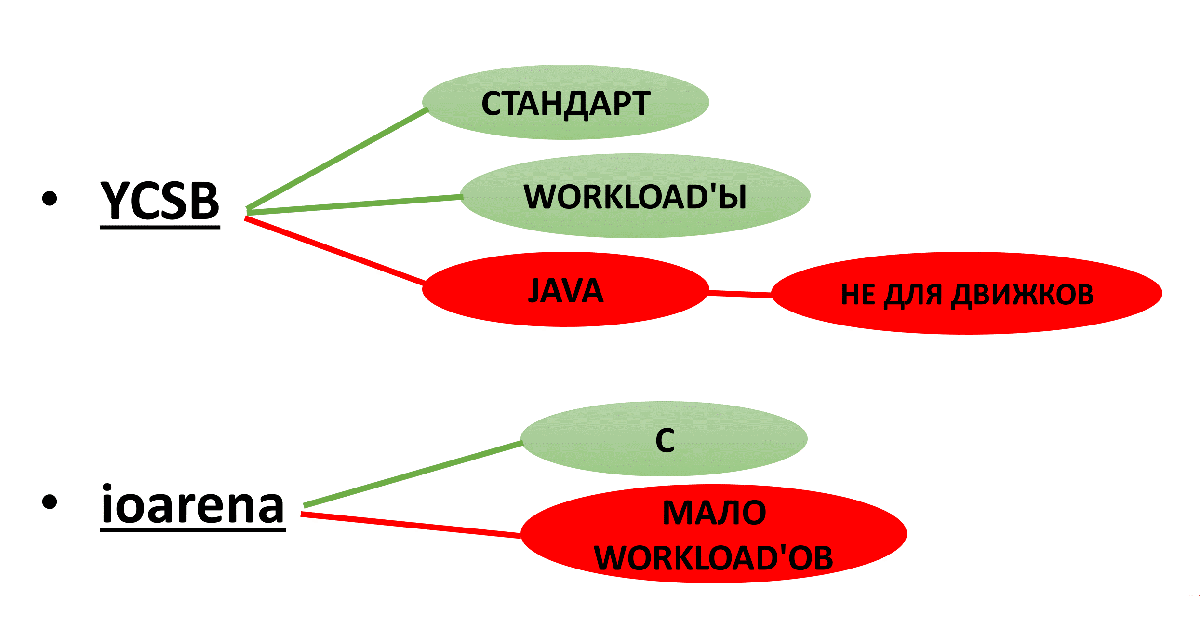
Рис. 3. Варианты тестирований
В итоге для движков выбираем ioarena, а для выделенных — YCSB.
Кроме workload’ов в ioarena нами была добавлена опция (-a), позволяющая указывать при запуске отдельно количество выполняемых операций на поток и отдельно количество ключей в БД.
Все изменения в коде ioarena можно найти на GitHub.
Параметры тестирования key-value БД
Основной workload, который нам интересен, — Mix50/50. Также мы решили посмотреть на RR, Mix70/30 и Mix30/70, чтобы понять, какие БД больше «любят» тот или иной workload.
Методика тестирования
Тестируем в 3 этапа:
- Заполнение БД — заполняем в 1 поток БД до необходимого количества ключей.
1.1 Сбрасываем кэши! Иначе тесты будут нечестными: БД обычно пишут данные поверх файловой системы, поэтому срабатывает кэш операционной системы. Важно сбрасывать его перед каждым тестом. - Тесты на 32 потока — прогоняем workload’ы
2.1 Random Read
• Сбрасываем кэши!
2.2 Mix70/30
• Сбрасываем кэши!
2.3 Mix50/50
• Сбрасываем кэши!
2.4 Mix30/70
• Сбрасываем кэши! - Тесты на 256 потоков.
3.1 То же самое, что и на 32 потока.
Что измеряем?
- Пропускная способности/throughput (IOPS/RPS — кто какие обозначения больше любит).
- Задержки/latency (msec):
• Min.
• Max.
• Среднее квадратическое значение — более показательное значение, чем среднее арифметическое, т.к. учитывает квадратичное отклонение.
• Перцентиль 99.99.
Тестовое окружение
Конфигурация:
| CPU: | 2x Intel Xeon E5–2620 v4 2.10GHz |
| RAM: | 16GB |
| Disk: | [2x] NVMe HGST SN100 1.5TB |
| OS: | CentOS Linux 7.2 kernel 3.11 |
| FS: | EXT4 |
Здесь важно отметить, что такой малый объем RAM взят не случайно. Таким образом, база не сможет полностью поместиться в кэш на тестах с 1 млрд ключей.
Объем доступной RAM регулировался не физически, а программно — часть заполнялась искусственно скриптом на Python, а остаток был свободен для БД и кэшей.
В некоторых тестах было иное количество доступной памяти — об этом будет сказано отдельно.
NVMe в тестах использовался один.
Надёжность записи
Важный момент — режим надёжности записи данных на диск. От этого очень сильно зависит скорость записи и вероятность/объём потерь при сбоях.
В целом, можно выделить 3 режима:
- Sync — честная запись на диск прежде, чем ответить пользователю «OK» на запрос записи. В случае сбоя всё остаётся на месте до последней зафиксированной транзакции.
- Lazy — записываем данные в буфер, отвечаем пользователю «OK», а буфер через небольшой промежуток времени сбрасываем на диск. В случае сбоя можем потерять немного последних изменений.
- Nosync — не осуществляем сброс данных на диск и просто пишем их в буфер с тем, чтобы когда-нибудь (не принципиально когда) скинуть буфер на диск. В этом режиме могут быть большие потери в случае сбоя.
По производительности разница примерно такая (на примере движка MDBX):
- Sync = 10k IOPS
- Lazy = 40k IOPS
- Nosync = 300k IOPS
Цифры здесь ТОЛЬКО для примерного понимания разницы между режимами.
В итоге для тестов был выбран режим lazy как наиболее сбалансированный. Об исключениях будет сказано отдельно.
Тестируем встраиваемые key-value БД
Для тестирования «движков» мы проводили два варианта тестирования: на 1 млрд ключей и на 17 млрд ключей.
Выбранные «движки»:
- RocksDB — про него все знают, это БД от Facebook. LSM-индекс.
- WiredTiger — движок MongoDB. LSM-индекс. Читать тут.
- Sophia — у этого движка свой кастомный индекс, имеющий что-то общее с LSM-деревьями, B-деревьями. Почитать можно тут.
- MDBX — форк LMDB с улучшениями по надёжности и производительности. B+ дерево в качестве индекса.
Результаты тестов. 1 млрд ключей
Заполнение
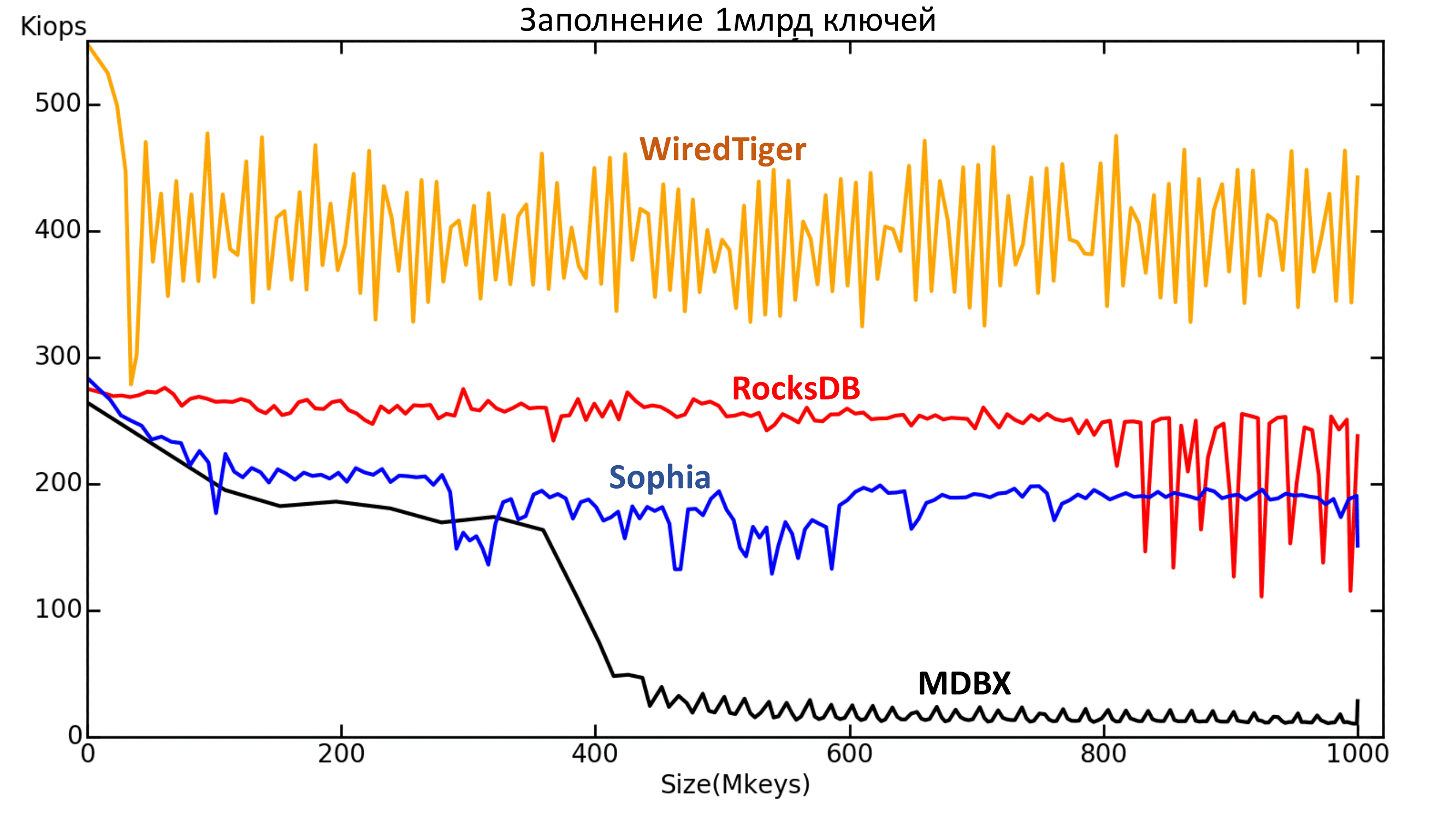
Рис. 4.1. Зависимость текущей скорости (IOPS) от количества ключей (ось абсцисс — миллионы ключей).
Здесь все движки в стандартной конфигурации. Режим надёжности Lazy, кроме MDBX. У него слишком медленная запись в Lazy, поэтому для него был выбран режим Nosync, иначе заполнение продлится слишком долго. Однако видно, что с некоторого момента всё равно скорость записи падает примерно до уровня скорости Sync режима.
Что можно увидеть на этом графике?
Первое: с RocksDB что-то случается после 800 млн ключей. К сожалению, не были выяснены причины происходящего.
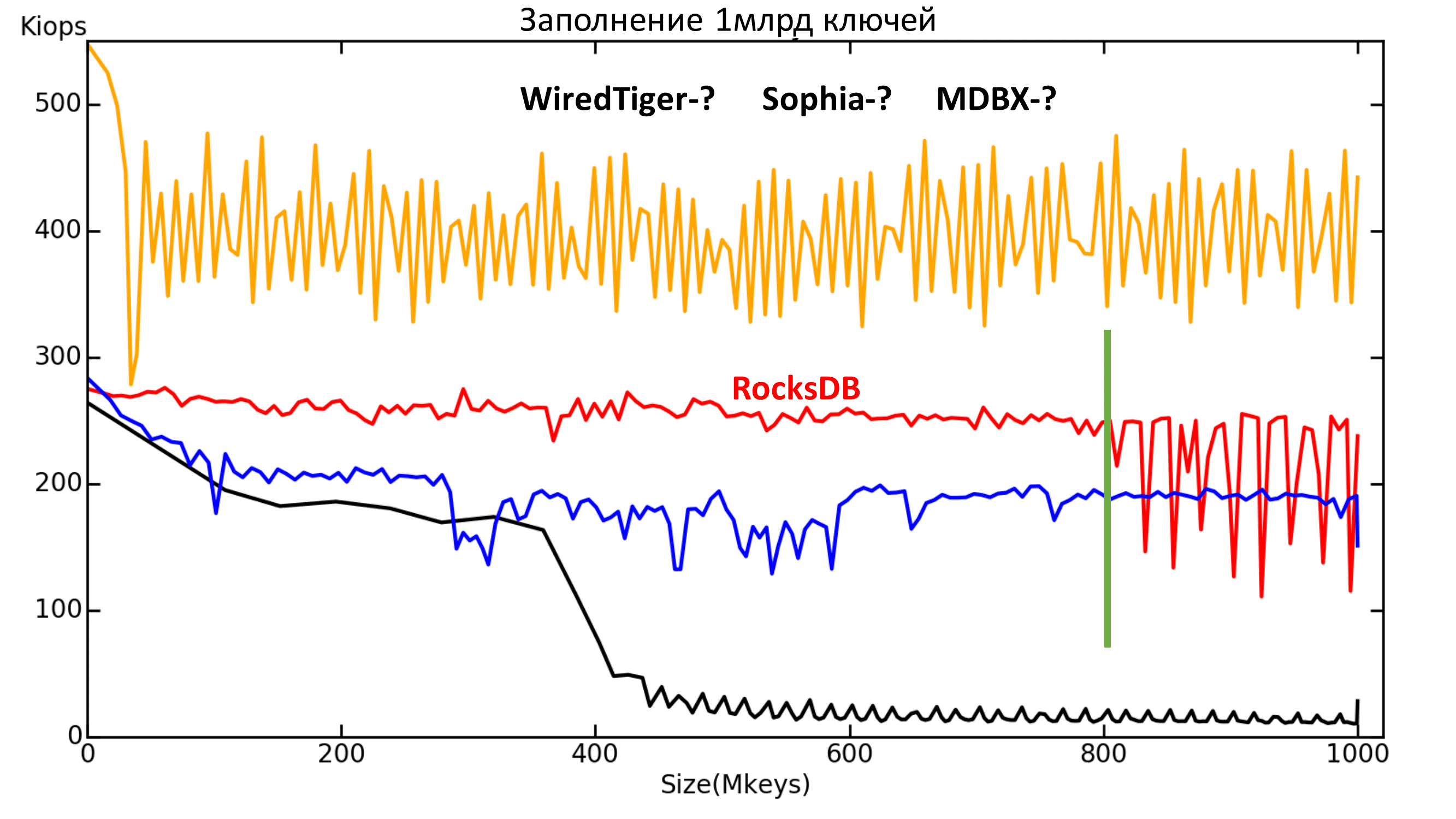
Рис. 4.2. Зависимость текущей скорости (IOPS) от количества ключей (ось абсцисс — миллионы ключей).
Второе: MDBX плохо перенёс момент, когда данных стало больше, чем доступно памяти.
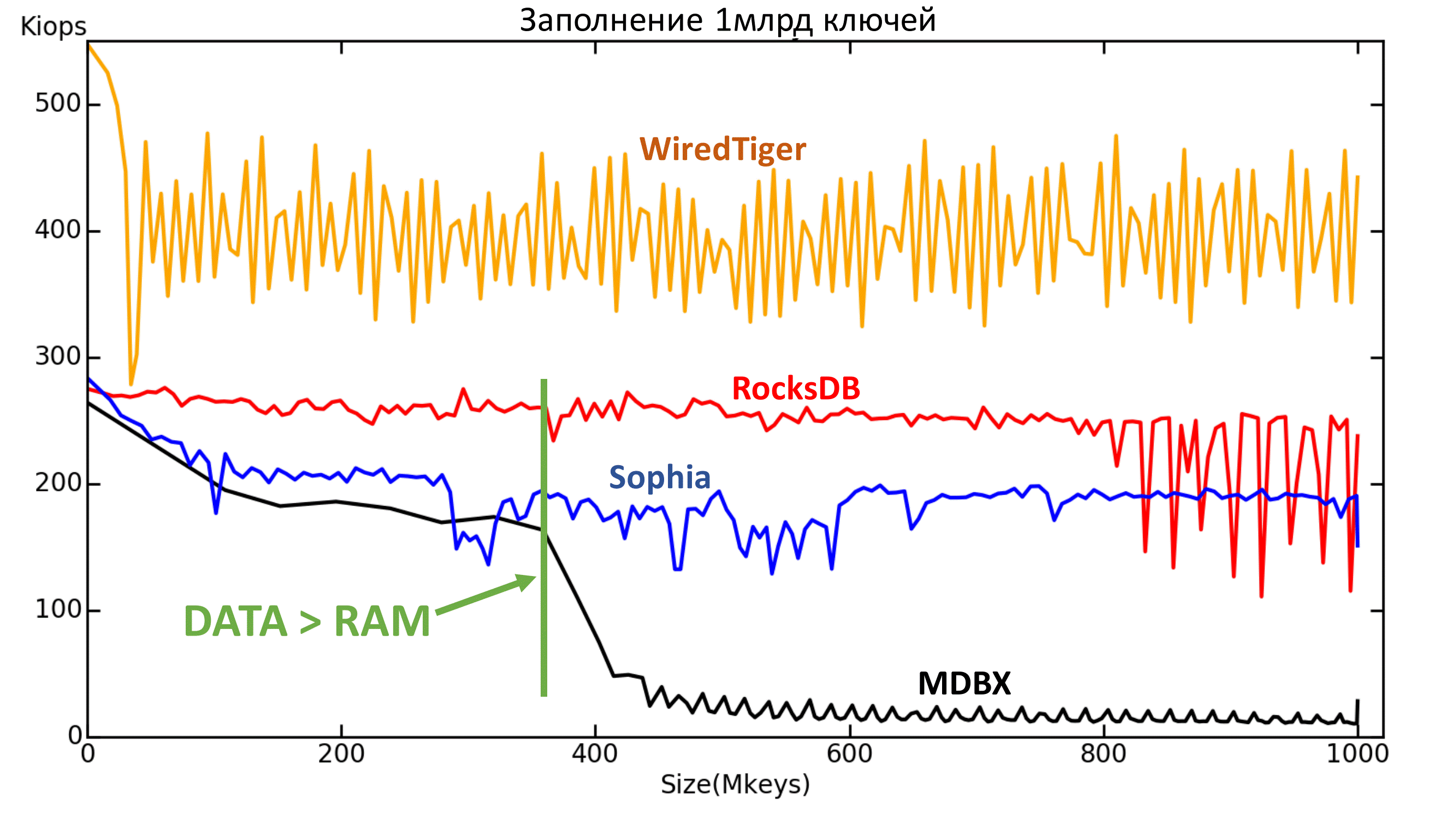
Рис. 4.3. Зависимость текущей скорости (IOPS) от количества ключей (ось абсцисс — миллионы ключей).
Далее можно посмотреть на график максимальной задержки. Тут также видно, что у RocksDB начались вылеты после 800 млн ключей.
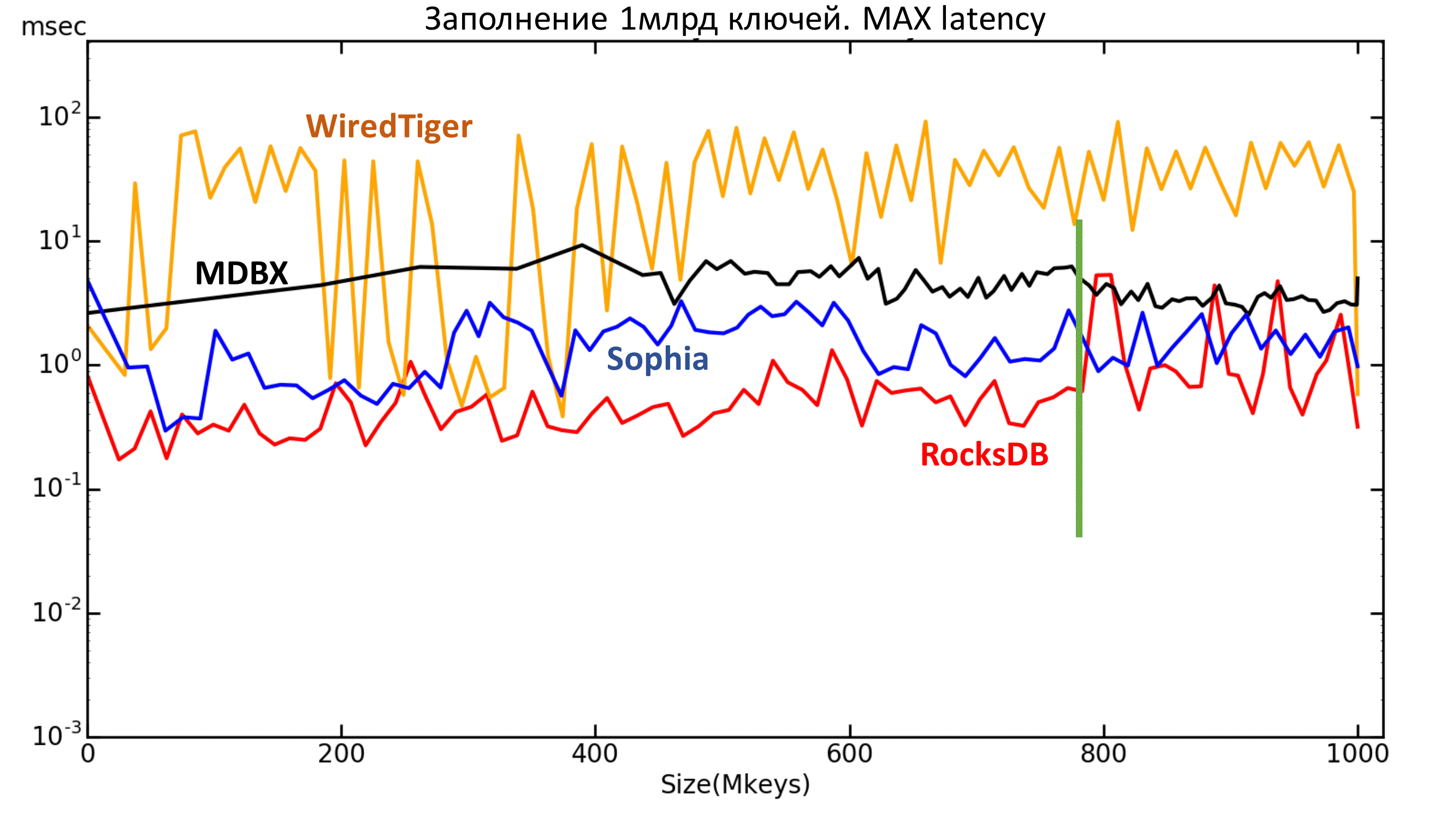
Рис. 5 Максимальная latency
Ниже находится график среднего квадратического значения задержки. Тут также видны те самые границы для RocksDB и MDBX.
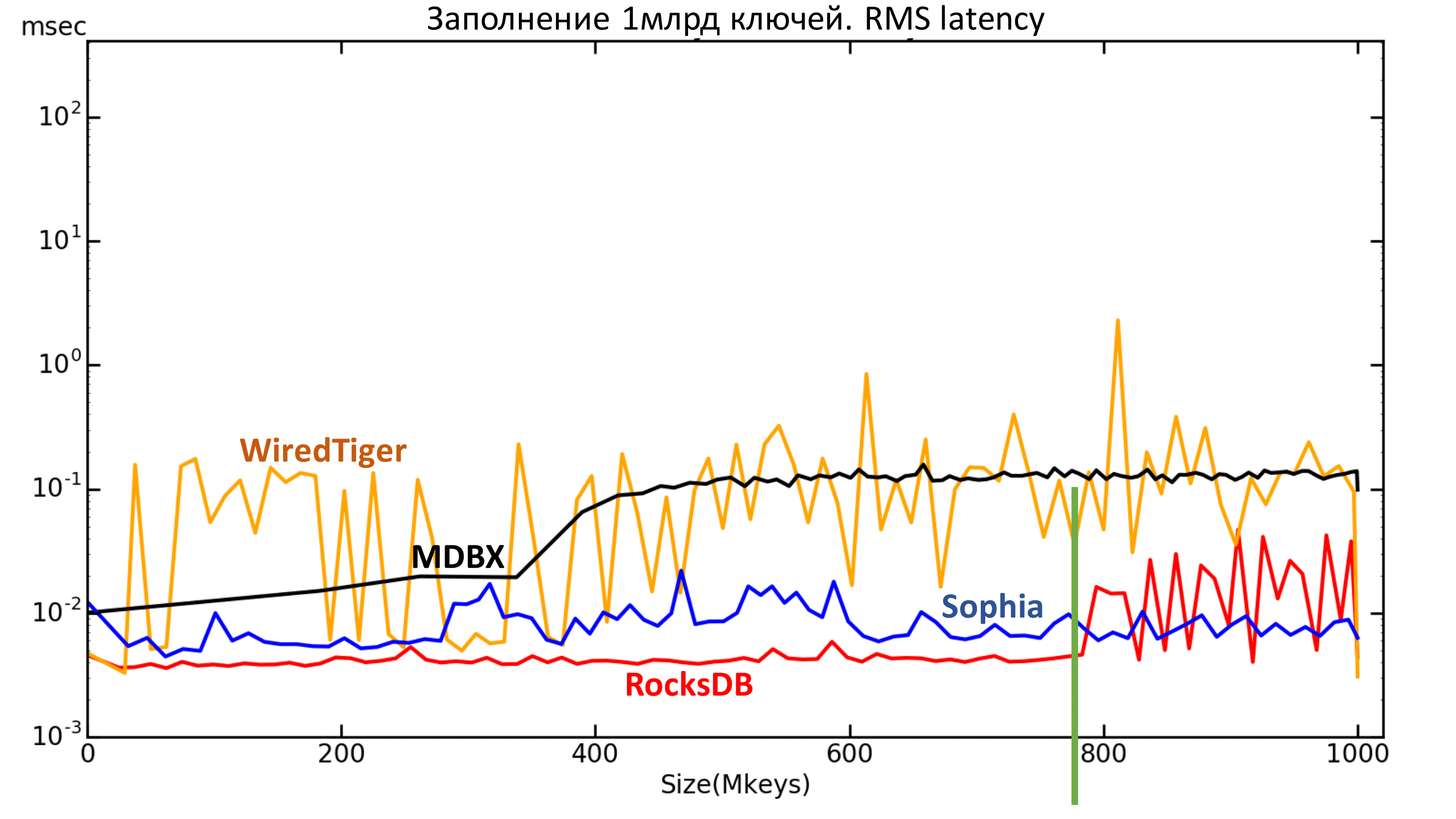
Рис. 6.1. RMS Latency
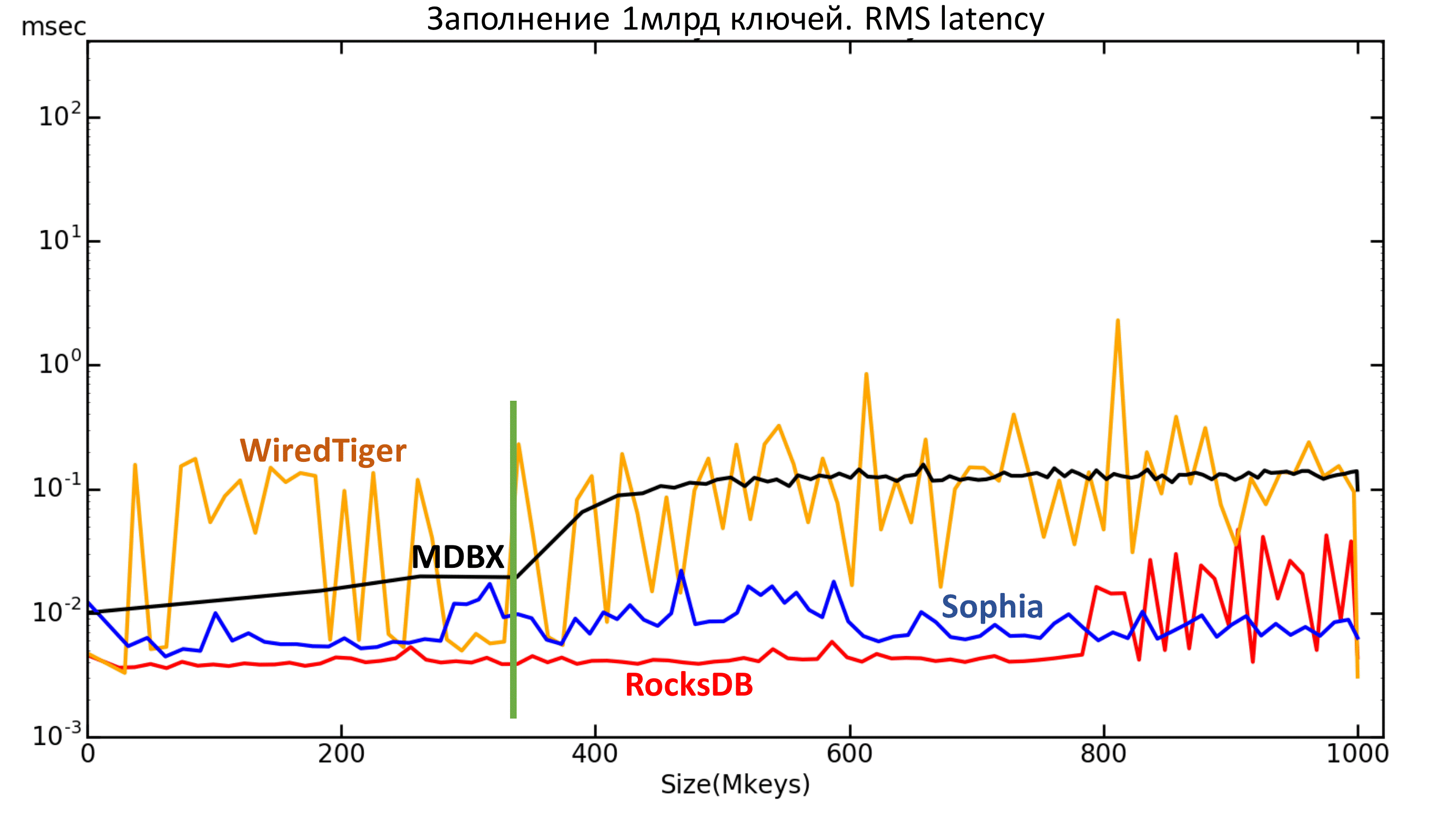
Рис. 6.2. RMS Latency
Тесты
К сожалению, Sophia показала низкий результат во всех тестах. Скорее всего, она не «любит» много потоков (т.е. 32 и более).
WiredTiger сначала показывал очень низкую производительность — на уровне 30 IOPS. Оказалось, что у него есть важный параметр cache_size, который по умолчанию выставлен на 500МБ. После его установки на 8ГБ (или даже 4ГБ) всё становится намного лучше.
Ради интереса был проведён тест с тем же объёмом данных, но с объёмом доступной памяти > 100ГБ. В этом случае MDBX с отрывом уходит вперёд в тесте на чтение.
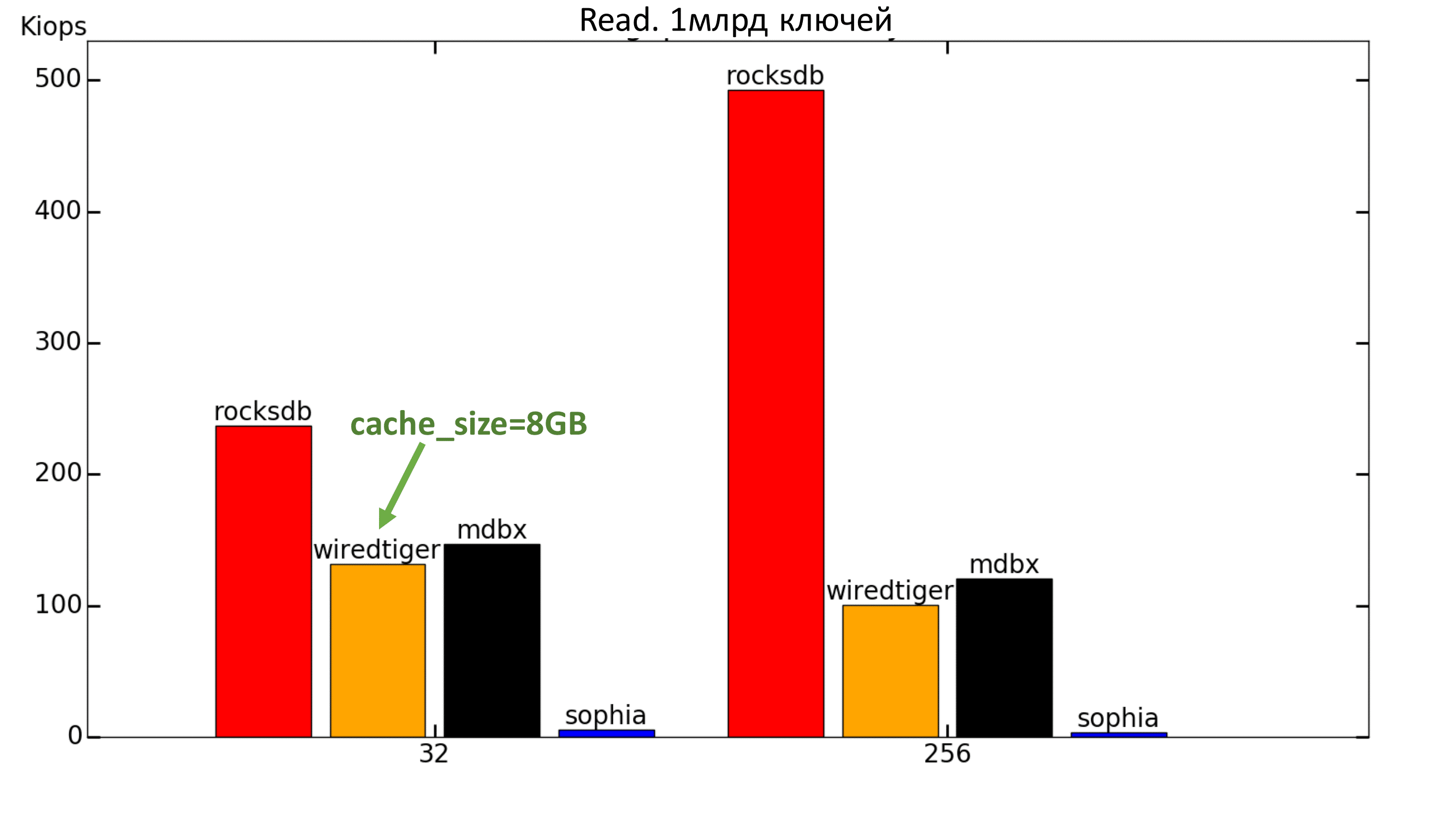
Рис. 7. 100% Read
При добавлении записи в workload получаем сильное падение MDBX (что ожидаемо, т.к. при заполнении скорость была низкой). WiredTiger подрос, а RocksDB снизил скорость.
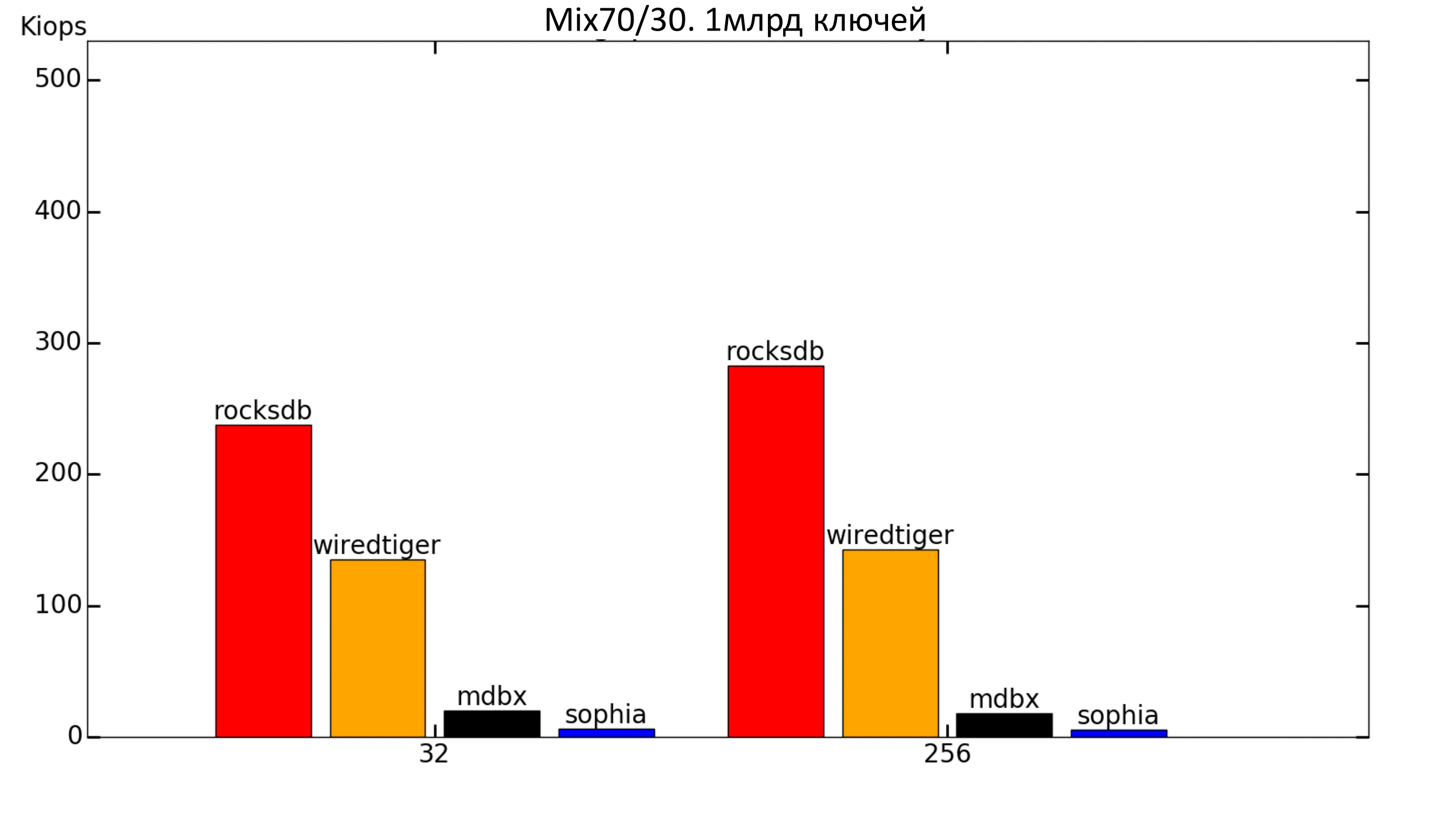
Рис. 8. Mix 70%/30%
Тенденция сохранилась.
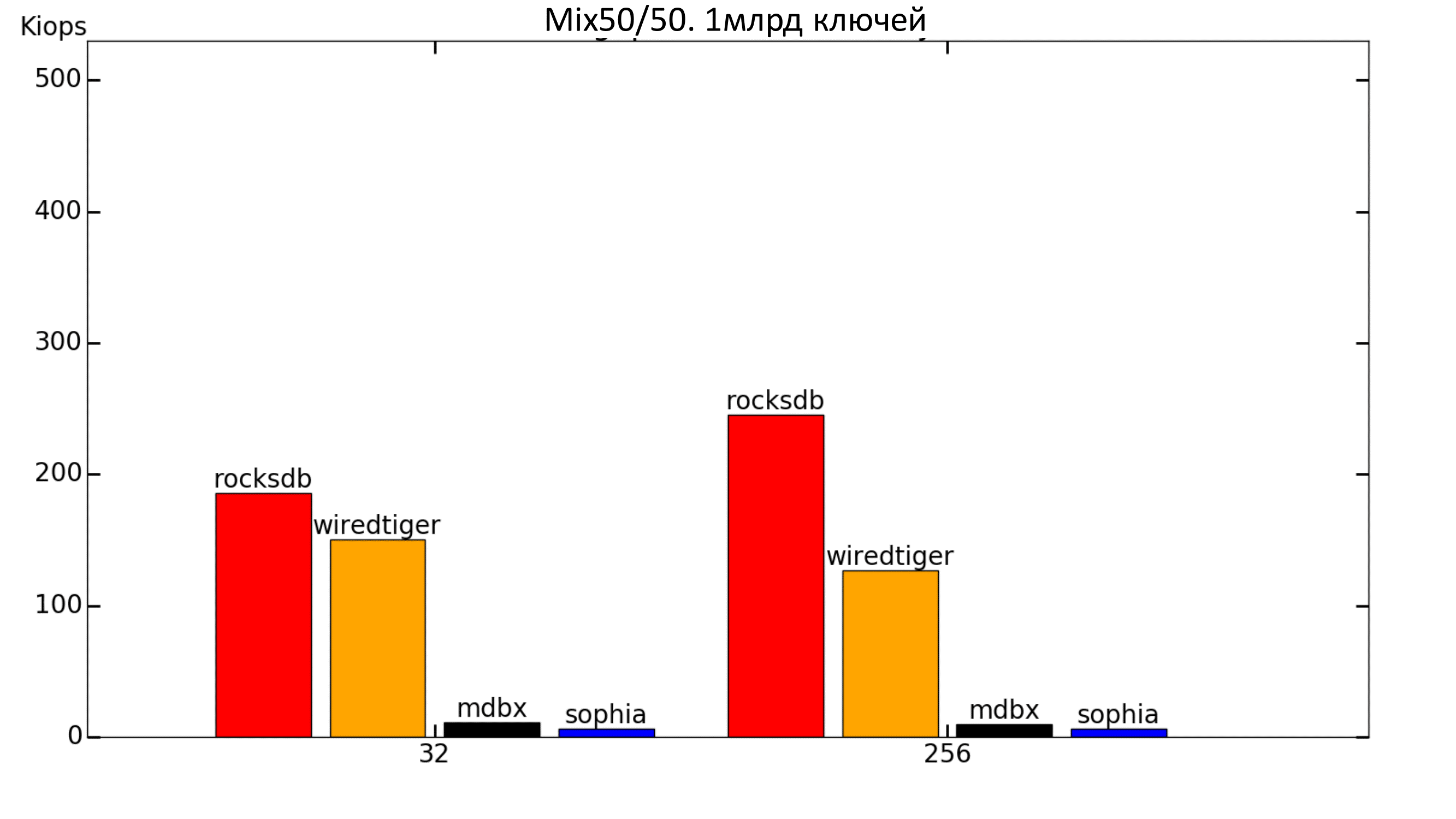
Рис. 9. Mix 50%/50%
Когда записи становится довольно много, WiredTiger начинает обгонять RocksDB на малом количестве потоков.
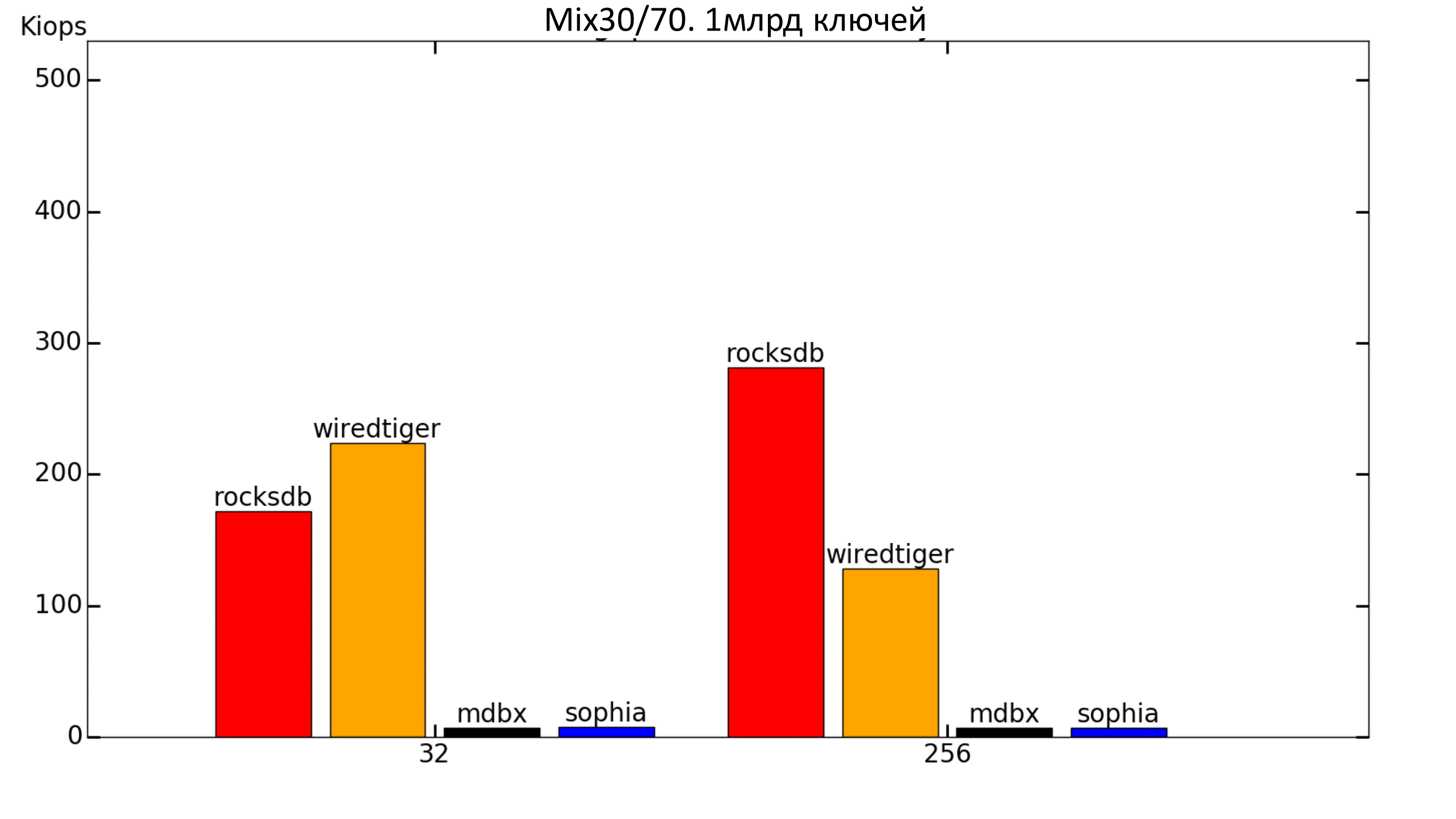
Рис. 10. Mix 30%/70%
Теперь можно посмотреть на графики задержек. Столбцы показывают минимальную и максимальную задержки, оранжевая полоска — средняя квадратическая задержка, а красная полоска — перцентиль 99.99.
Зелёная полоса — это примерно 2 мс. То есть мы хотим, чтобы перцентиль находился не выше зелёной полосы. В данном случае мы этого не получаем (шкала логарифмическая).
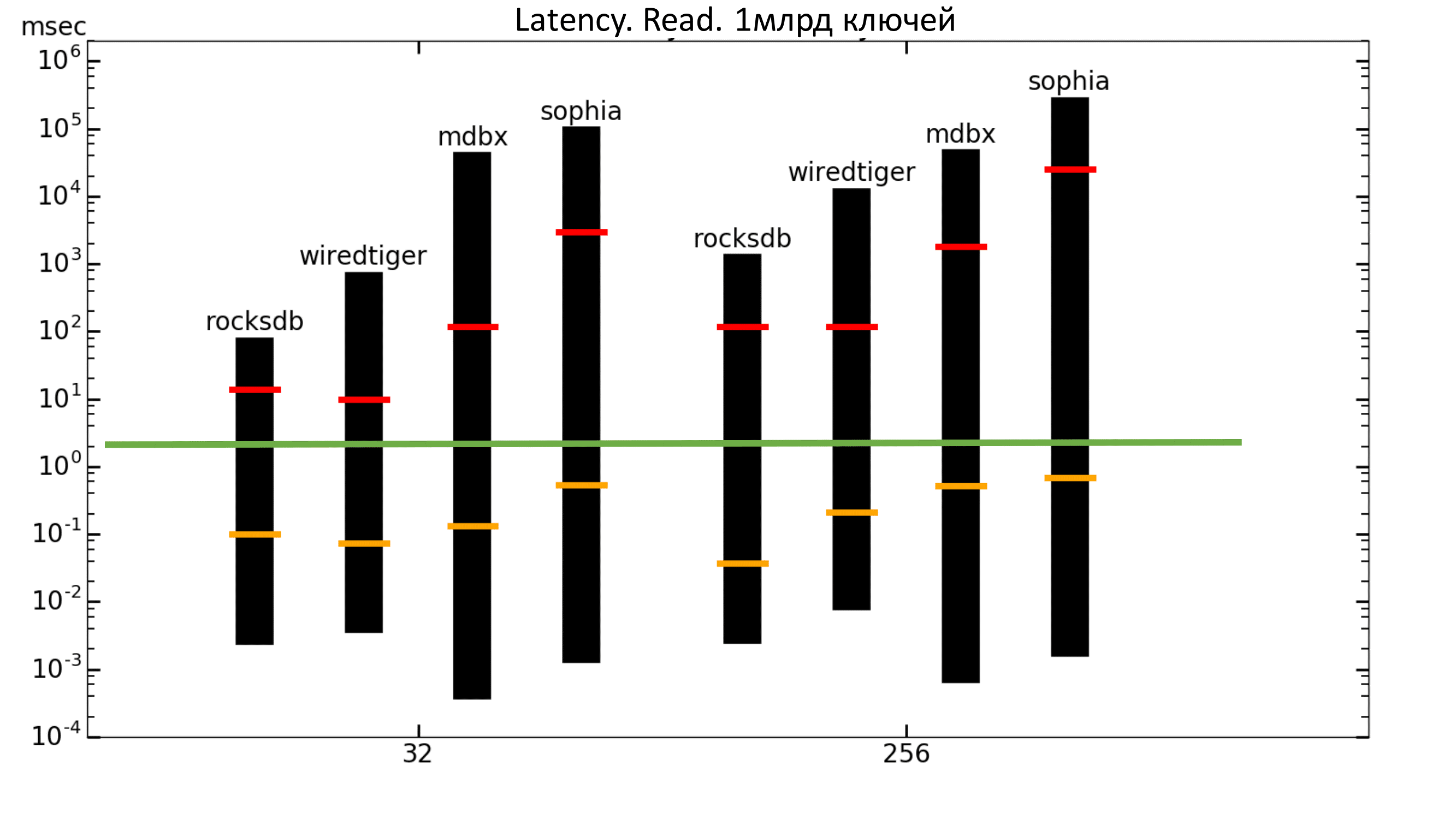
Рис. 11. Latency Read
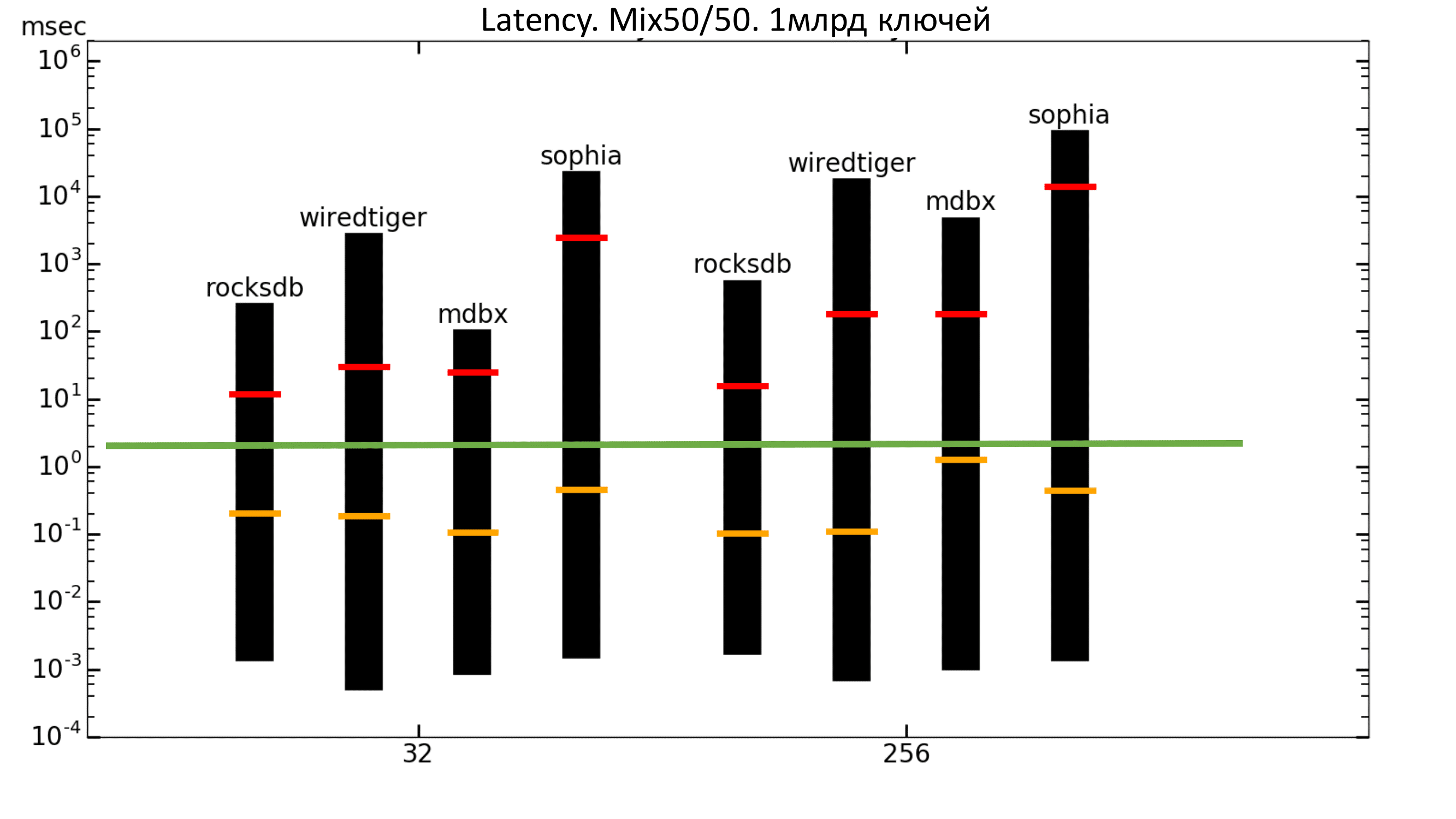
Рис. 12. Latency 50%/50%
Результаты тестов. 17 млрд ключей
Заполнение
Тесты на 17 млрд ключей были проведены только на RocksDB и WiredTiger, т.к. они были лидерами в тестах на 1 млрд ключей.
У WiredTiger начались странные выпады, но в целом он довольно неплохо себя показывает на заполнении, плюс не наблюдается деградации при увеличении объёма данных.
А вот RocksDB в итоге спустился ниже 100k IOPS. Таким образом, в тесте на 1 млрд ключей мы не видели всей картины, поэтому важно проводить тесты на объёмах, сравнимых с реальными!
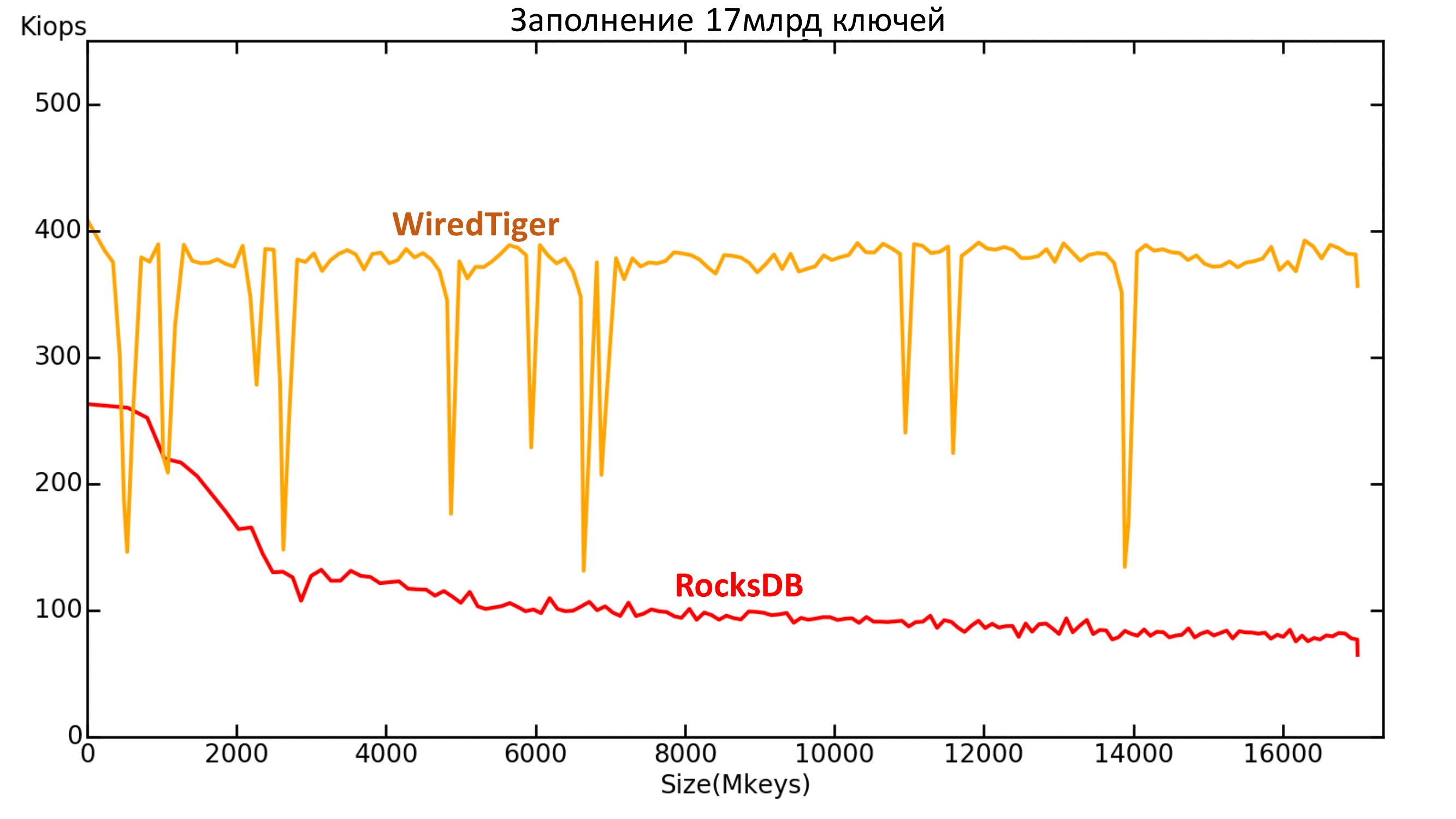
Рис. 13. Производительность 17 млрд ключей
Пунктирной линией изображена средняя квадратическая задержка. Видно, что максимальная задержка у WiredTiger выше, а средняя квадратическая ниже, чем у RocksDB.
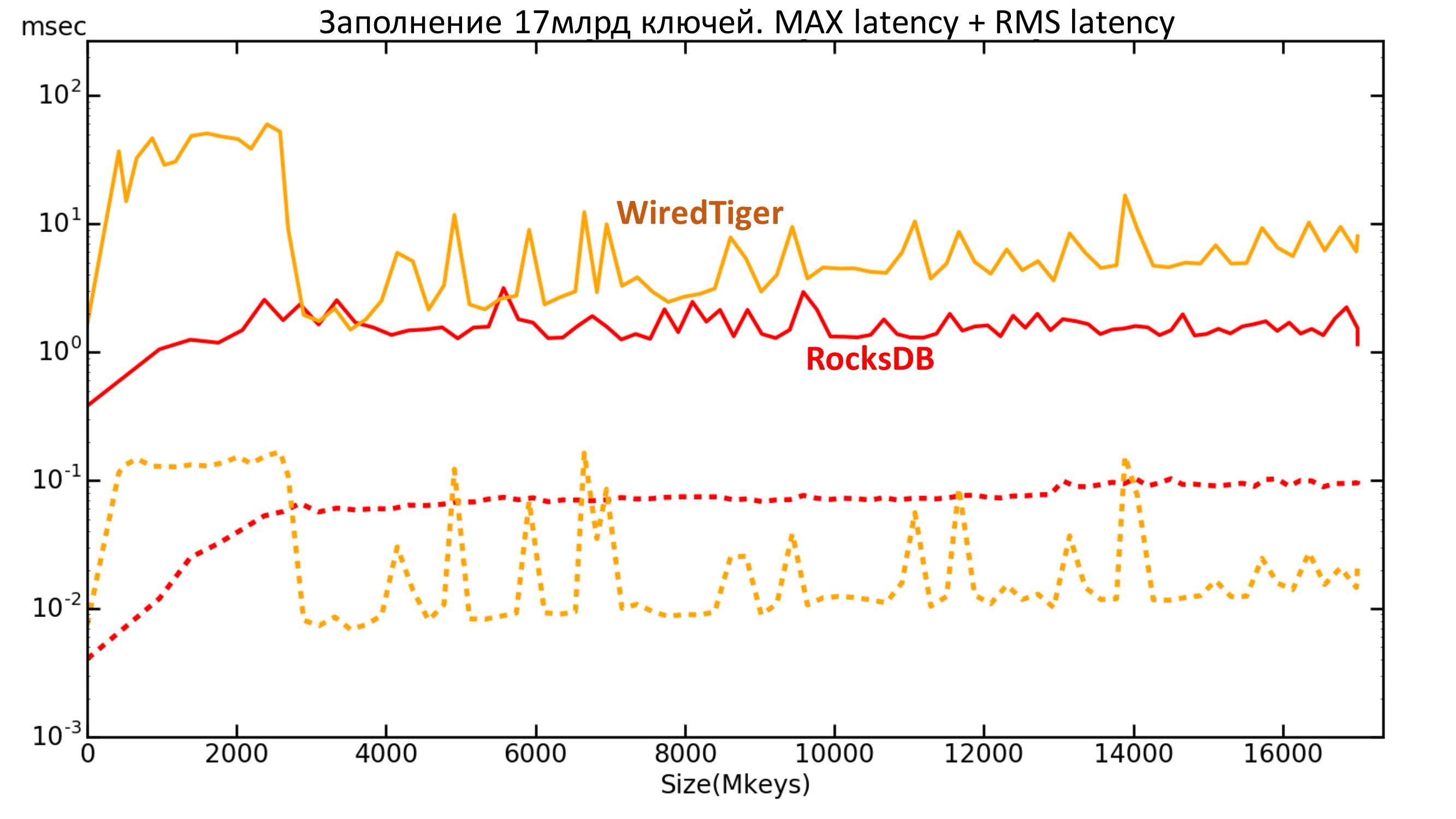
Рис. 14. Latency 17 млрд ключей
Тесты
С WiredTiger’ом случилась та же беда, что и в прошлый раз — он показывал около 30 IOPS на чтение, даже при cache_size=8GB. Было решено ещё увеличить значение параметра cache_size, но и это не помогло: даже при 96ГБ скорость не поднялась выше нескольких тысяч IOPS, хотя выделенная память даже не была заполнена.
При добавлении записи к workload’у WiredTiger традиционно поднимается.
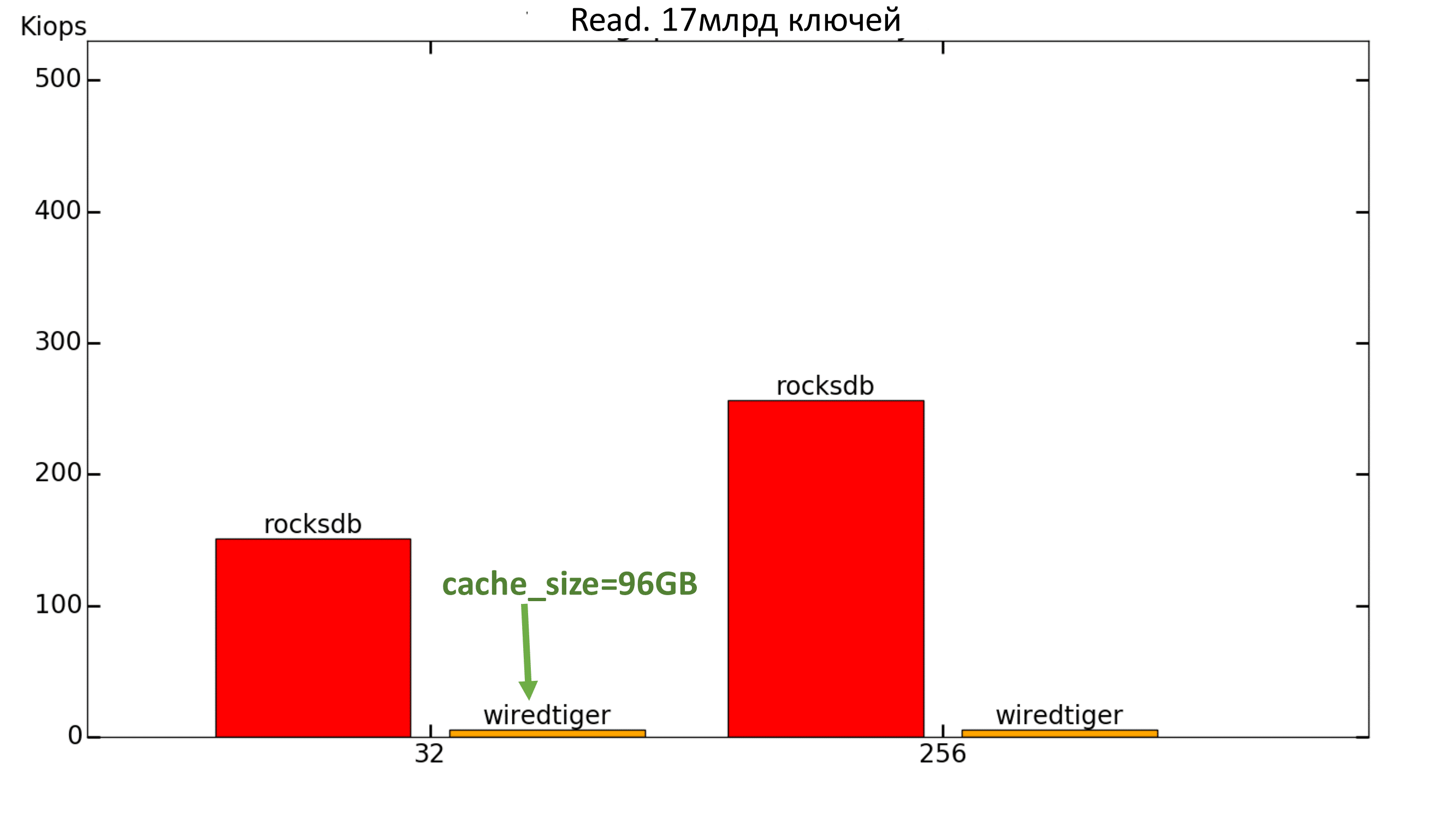
Рис. 15. Производительность 100% Read
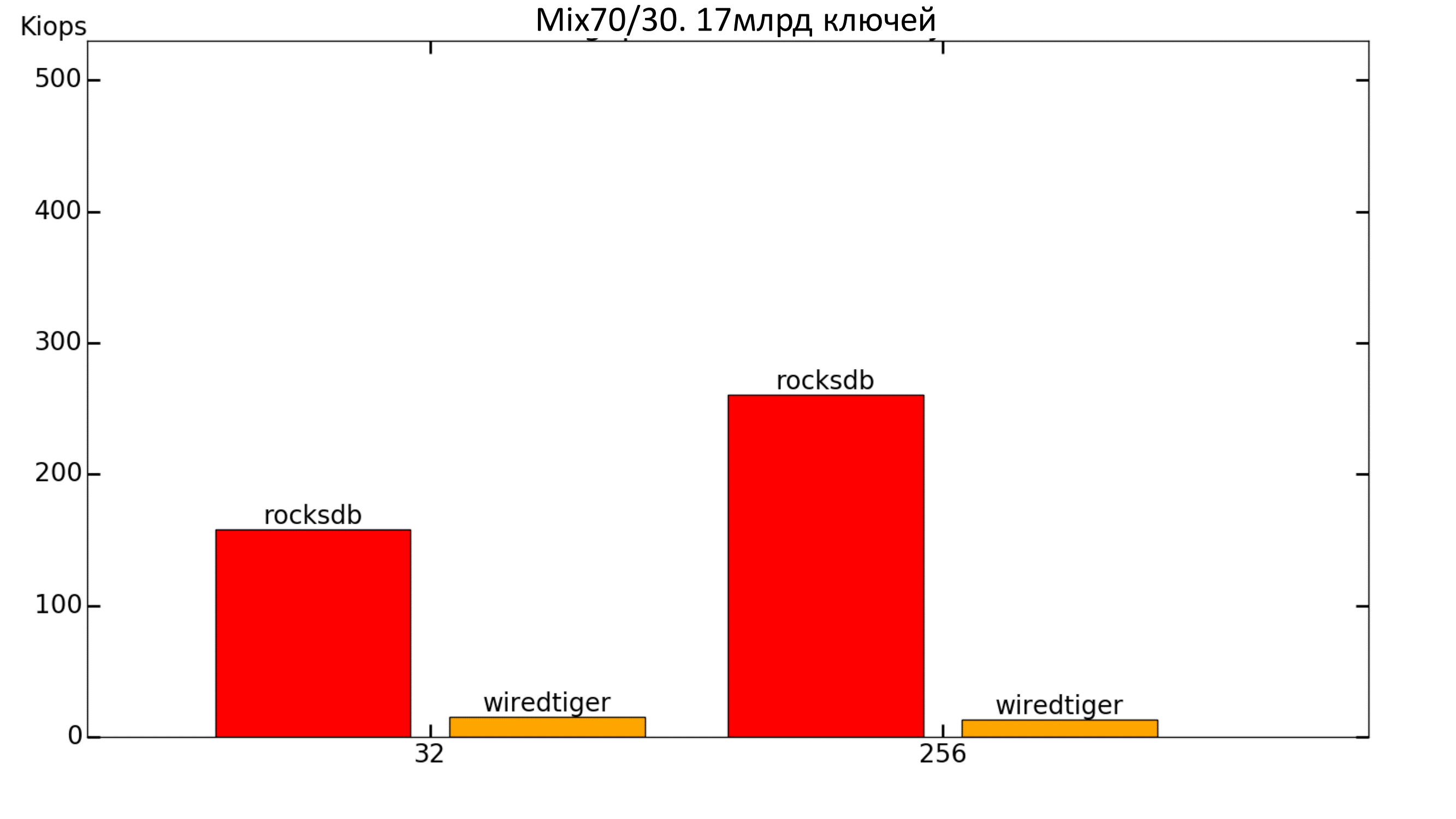
Рис. 16. Производительность 70%/30%
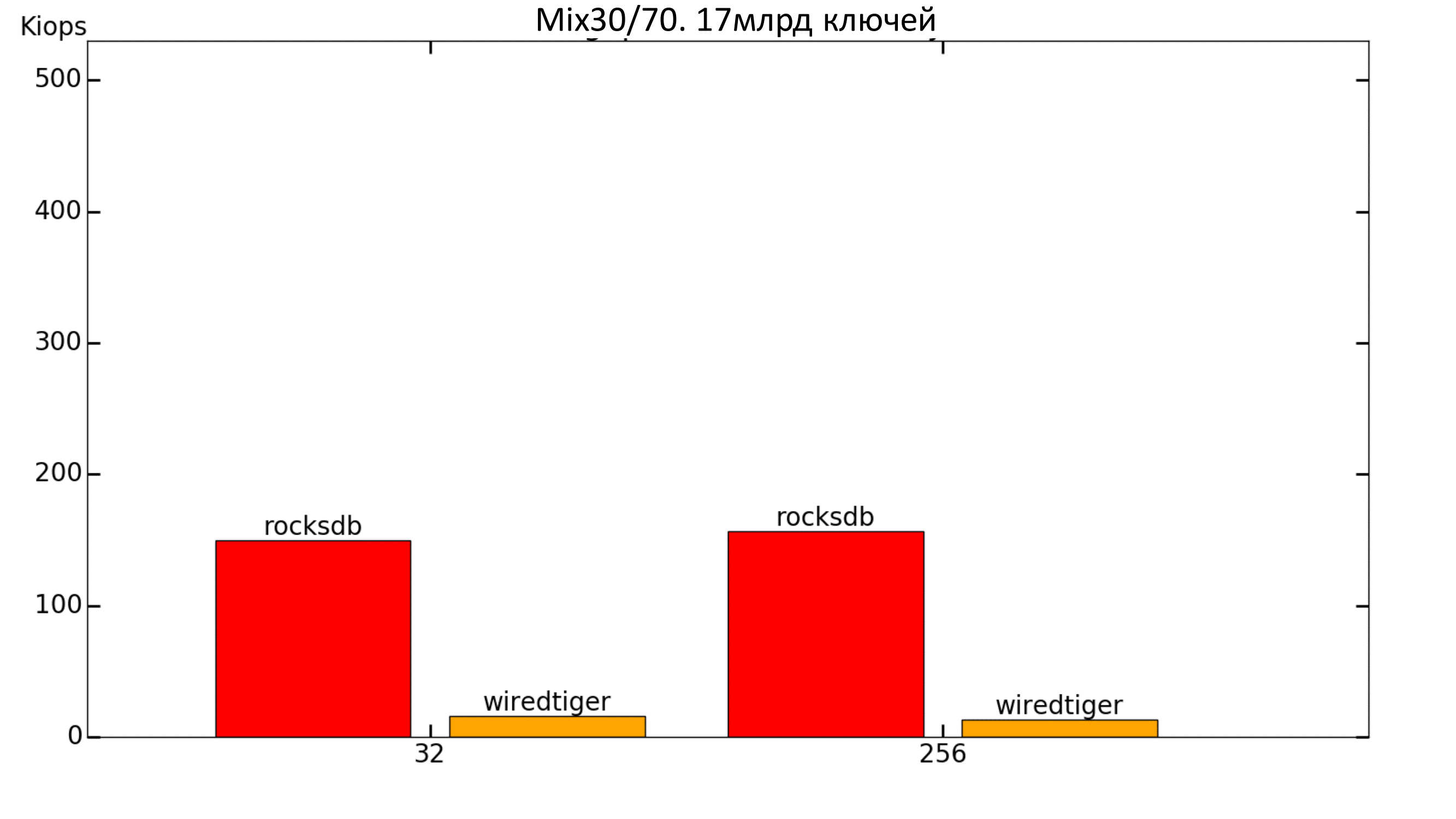
Рис. 17. Производительность 30%/70%
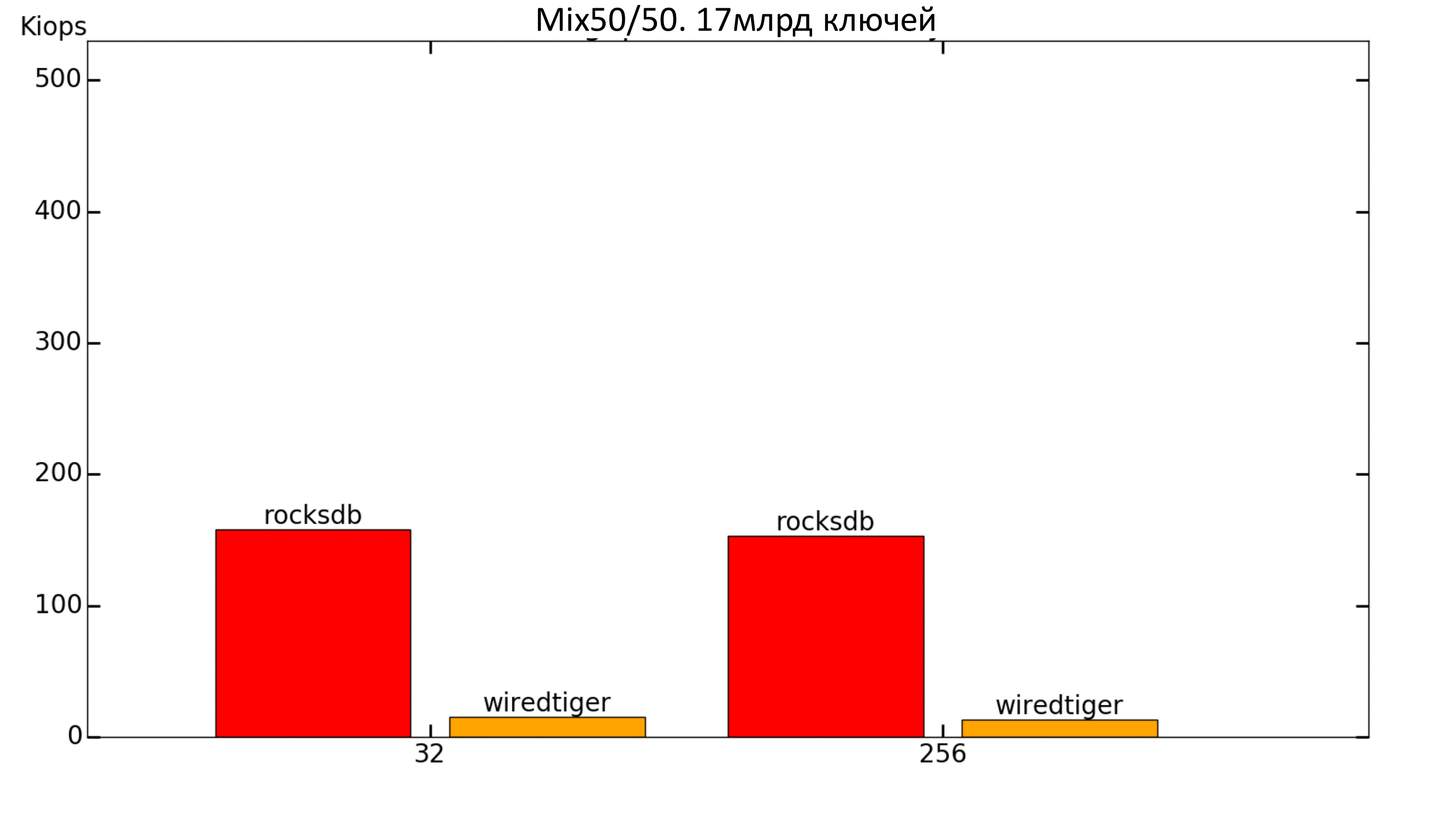
Рис. 18. Производительность 50%/50%
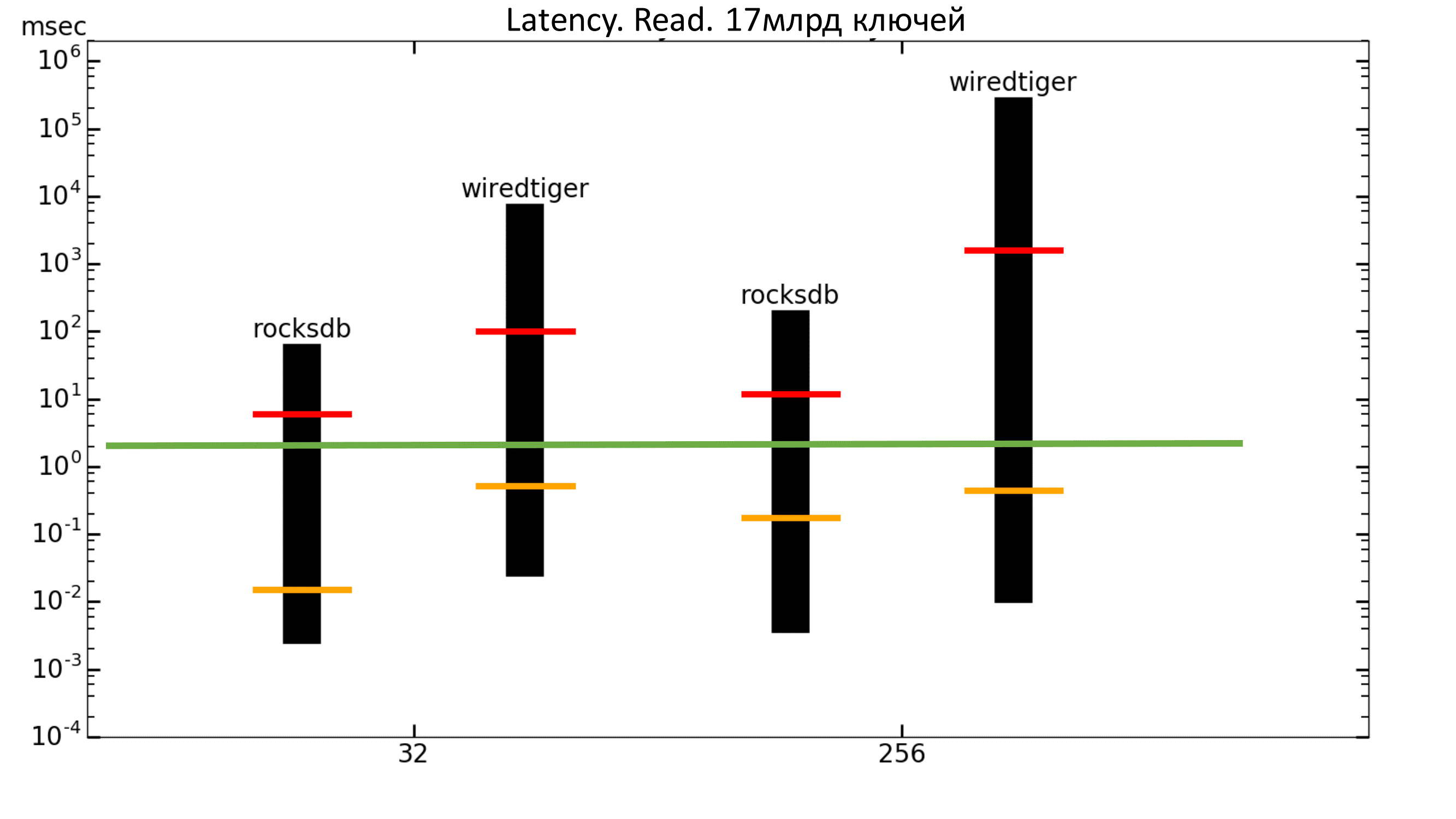
Рис. 19. Latency 100% Read
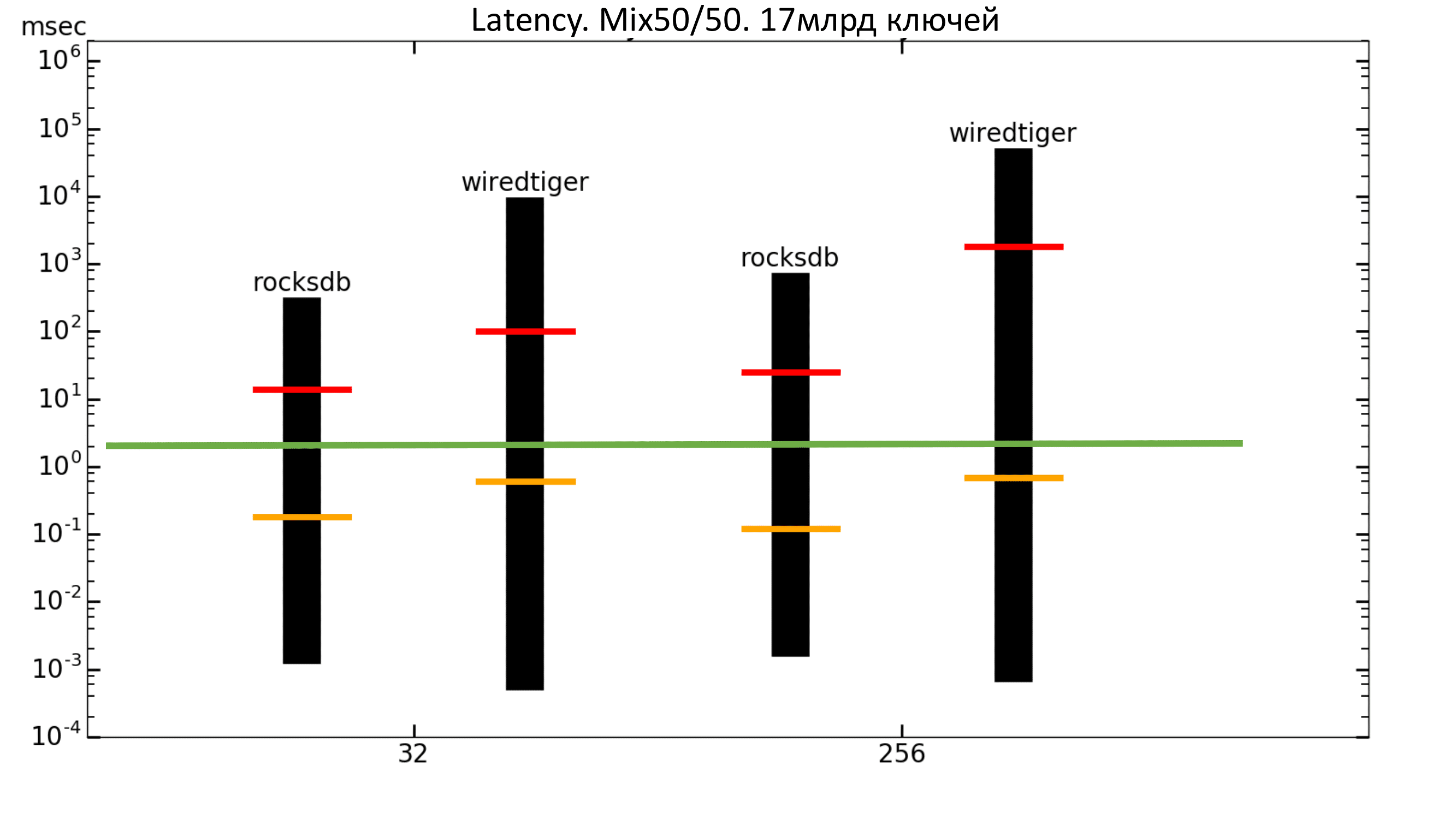
Рис. 20. Latency 50%/50%
Выводы
Из того, что сказано выше, можно сделать следующие выводы:
Для базы объемом в 1 млрд ключей:
- Запись + мало потоков => WiredTiger
- Запись + много потоков => RocksDB
- Чтение + DATA > RAM => RocksDB
- Чтение + DATA < RAM => MDBX
Из чего следует, что:
- Mix50/50 + много потоков + DATA > RAM => RocksDB
Для базы объемом в 17 млрд ключей: однозначное лидерство у RocksDB.
Такова ситуация со встраиваемыми движками. В следующей статье мы расскажем о показателях выделенных баз данных key-value и сделаем выводы о бенчмарках.
