Как так вышло, что при лишнем шаге сборки моё приложение на Zig ускоряется в 10 раз
Вот уже несколько месяцев я интересуюсь двумя технологиями: языком программирования Zig и криптовалютой Ethereum. Чтобы подробнее изучить обе, я написал на Zig интерпретатор байт-кода для виртуальной машины Ethereum.
Язык Zig отлично подходит для оптимизации производительности, а также предоставляет детализированный контроль над памятью и потоком операций. Чтобы было ещё интереснее, я проставил контрольные точки, по которым сравнил мою реализацию Ethereum с официальной реализацией на Go.

В самом начале описанной работы моя любительская реализация Ethereum на Zig обгоняла официальную реализацию (написанную на Go) примерно на 40%.
Недавно я немного повозился с моим скриптом и, как мне казалось, сделал в нём простой рефакторинг —, а производительность моего приложения посыпалась. Насколько я смог определить, всё дело было в том изменении, которое просматривается на разнице между двумя этими командами:
$ echo '60016000526001601ff3' | xxd -r -p | zig build run -Doptimize=ReleaseFast
execution time: 58.808µs
$ echo '60016000526001601ff3' | xxd -r -p | ./zig-out/bin/eth-zvm
execution time: 438.059µszig build run — это просто шорткат, позволяющий скомпилировать и выполнить двоичный файл. Она должна быть эквивалентна двум следующим командам:
zig build
./zig-out/bin/eth-zvmКак же дополнительный шаг сборки позволяет выполнить эту программу почти в 10 раз быстрее?
Минимальная конфигурация, позволяющая воспроизвести этот феномен
Чтобы отладить такую странность с производительностью, я попытался упрощать моё приложение до тех пор, пока программа не превратилась из интерпретатора байт-кода в приложение, которое просто подсчитывает количество байт и читает их из stdin:
// src/main.zig
const std = @import("std");
pub fn countBytes(reader: anytype) !u32 {
var count: u32 = 0;
while (true) {
_ = reader.readByte() catch |err| switch (err) {
error.EndOfStream => {
return count;
},
else => {
return err;
},
};
count += 1;
}
}
pub fn main() !void {
var reader = std.io.getStdIn().reader();
var timer = try std.time.Timer.start();
const start = timer.lap();
const count = try countBytes(&reader);
const end = timer.read();
const elapsed_micros = @as(f64, @floatFromInt(end - start)) / std.time.ns_per_us;
const output = std.io.getStdOut().writer();
try output.print("bytes: {}\n", .{count});
try output.print("execution time: {d:.3}µs\n", .{elapsed_micros});
}На примере такого упрощённого приложения разница в производительности хорошо видна. Когда я запускаю счётчик байт командой zig build run, он выполняется за 13 микросекунд:
$ echo '00010203040506070809' | xxd -r -p | zig build run -Doptimize=ReleaseFast
bytes: 10
execution time: 13.549µsКогда пытаюсь непосредственно выполнить скомпилированный бинарник, на его работу уходит в 12 раз больше времени, а именно, 162 микросекунды:
$ echo '00010203040506070809' | xxd -r -p | ./zig-out/bin/count-bytes
bytes: 10
execution time: 162.195µsЯ составил тест из трёх команд, объединённых в конвейер bash:
1. echo выводит последовательность из десяти байт в шестнадцатеричной кодировке (0×00, 0×01, …).
2. xxd преобразует байты echo (в шестнадцатеричной кодировке) в байты в двоичной кодировке
3. zig build run компилирует и выполняет мою программу счётчика байт, подсчитывая, сколько байт в двоичной кодировке выдала xxd.
Вся разница между zig build run и ./zig-out/bin/count-bytes заключается в том, что вторая команда запускает уже скомпилированное приложение, а первая сначала перекомпилирует это приложение.
Я вновь был ошеломлён.
Как такое возможно, что при дополнительном шаге компиляции программа получается быстрее? Может быть, приложение Zig бегает быстрее, будучи «с пылу-с жару»?
Как я обратился за помощью в сообщество Zig
Здесь я застрял. Снова и снова перечитывал мой исходный код — и не мог понять, как при «компиляции с запуском» приложение работает быстрее, чем будучи поднято из готового скомпилированного бинарника.
Zig — язык ещё достаточно новый, поэтому логично, что чего-то в нём я могу недопонимать. Решил, что, если показать мой код опытным Zig-программистам, они сразу же найдут у меня ошибку.
Я разместил мой вопрос на Ziggit, это дискуссионный форум по Zig. В первых нескольких ответах предположили, что у меня проблемы с «буферизацией ввода», но не дали никаких конкретных рекомендаций, что можно исправить или какие моменты исследовать подробнее.
К моему удивлению в тред пожаловал Эндрю Келли, основатель и ведущий разработчик языка Zig. Он не смог объяснить тот феномен, что я наблюдал, но указал, что я допускаю иную ошибку, касающуюся производительности:
«Кажется, вы делаете по одному системному вызову на считывание байта? От этого производительность сильнейшим образом страдает. Предположу, что, когда в процессе сборки происходит лишний шаг, на этом шаге случайно делается какая-то буферизация. Правда, не уверен, почему. Система сборки заставляет дочерний процесс напрямую наследовать дескрипторы файла».
Наконец, мой друг Эндрю Эйер заметил мой пост об этом на Mastodon и разгадал загадку:
Майкл, видишь десятикратную разницу в случаях, когда на ввод подаются большие куски (скажем, более 1 МБ)? А сохранится ли эта разница, если ты перенаправишь stdin из файла в канал конвейера?
Думаю, когда ты выполняешь программу напрямую, xxd и count-bytes начинают работать одновременно, поэтому буфер канала пустует в момент, когда count-bytes в первый раз пытается прочитать информацию из stdin, ему приходится ждать, пока xxd его наполнит. Но, если ты пользуешься zig build run, в таком случае xxd получает фору при компиляции программы. Поэтому к тому моменту, когда count-bytes пытается прочитать stdin, буфер канала уже заполнен.
Эндрю Эйер был совершенно прав, и ниже я разложу эту ситуацию по полочкам.
Примечание:, а ещё Эндрю Эйер помог мне разгадать и другой сложный случай с производительностью.
Я неправильно себе представлял, как работают конвейеры bash
Я никогда как следует не задумывался о конвейерах bash, но, благодаря комментарию Эндрю, понял, что неправильно представляю себе принцип их работы.
Представьте себе простой конвейер bash, примерно такой:
./jobA | ./jobBЯ полагал, что jobA запускается и работает до завершения, а после этого запускается jobB, принимающее вывод jobA в качестве ввода.

Вот так неверно я представлял себе выполнение заданий в конвейере bash
Оказывается, что все команды в конвейере bash запускаются одновременно.
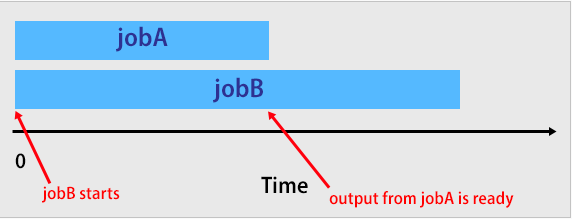
На самом деле задания в конвейере bash выполняются вот так
Чтобы продемонстрировать параллельное выполнение в конвейере bash, я решил проверить концепцию при помощи двух простых скриптов на bash. Вот что у меня получилось.
jobA стартует, затем засыпает на три секунды, выводит результат в stdout, засыпает ещё на две секунды, затем выходит:
#!/usr/bin/env bash
function print_status() {
local message="$1"
local timestamp=$(date +"%T.%3N")
echo "$timestamp $message" >&2
}
print_status 'jobA is starting'
sleep 3
echo 'result of jobA is...'
sleep 2
echo '42'
print_status 'jobA is terminating'jobB стартует, ждёт ввода в stdin, затем выводит всё, что может прочитать из stdin, до тех пор, пока stdin не закрывается:
#!/usr/bin/env bash
function print_status() {
local message="$1"
local timestamp=$(date +"%T.%3N")
echo "$timestamp $message" >&2
}
print_status 'jobB is starting'
print_status 'jobB is waiting on input'
while read line; do
print_status "jobB read '${line}' from input"
done < /dev/stdin
print_status 'jobB is done reading input'
print_status 'jobB is terminating'Если запустить jobA и jobB в конвейере bash, ровно 5,009 секунд проходит между сообщениями jobB is starting и jobB is terminating:
$ ./jobA | ./jobB
09:11:53.326 jobA is starting
09:11:53.326 jobB is starting
09:11:53.328 jobB is waiting on input
09:11:56.330 jobB read 'result of jobA is...' from input
09:11:58.331 jobA is terminating
09:11:58.331 jobB read '42' from input
09:11:58.333 jobB is done reading input
09:11:58.335 jobB is terminatingЕсли откорректировать выполнение так, чтобы jobA и jobB выполнялись последовательно, а не конвейерно, всего 0,008 секунд проходит между сообщениями starting и terminating каждого из заданий:
$ ./jobA > /tmp/output && ./jobB < /tmp/output
16:52:10.406 jobA is starting
16:52:15.410 jobA is terminating
16:52:15.415 jobB is starting
16:52:15.417 jobB is waiting on input
16:52:15.418 jobB read 'result of jobA is...' from input
16:52:15.420 jobB read '42' from input
16:52:15.421 jobB is done reading input
16:52:15.423 jobB is terminatingВозвращаемся к моему счётчику байт
Стоило мне понять, что все команды в конвейере bash выполняются параллельно, я сразу понял, что происходит в моём счётчике байт:
$ echo '00010203040506070809' | xxd -r -p | zig build run -Doptimize=ReleaseFast
bytes: 10
execution time: 13.549µs
$ echo '00010203040506070809' | xxd -r -p | ./zig-out/bin/count-bytes
bytes: 10
execution time: 162.195µsПо-видимому, на выполнение echo '00010203040506070809' | xxd -r -p в рамках конвейера уходит примерно 150 микросекунд. Шаг zig build run должен занимать не менее 150 микросекунд.
К тому моменту, как приложение count-bytes фактически начинает работать в версии с zig build, ему не приходится дожидаться завершения заданий, запущенных ранее. Ввод уже ждёт его в stdin.

В случае с zig build run есть задержка перед выполнением любого приложения, поэтому задания, ранее поступившие в конвейер, уже успевают завершится к тому моменту, как начнёт работу count-bytes.
Если пропустить zig build и непосредственно запустить скомпилированный бинарник, то count-bytes сразу же начинает работу, и тогда же стартует таймер. Проблема в том, что count-bytes приходится вхолостую ожидать ~150 микросекунд, пока команды echo и xxd положат нужный ввод в stdin.
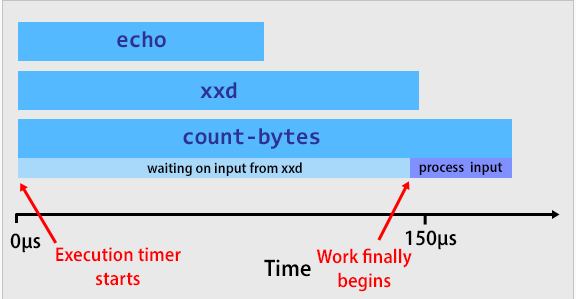
При выполнении count-bytes напрямую приходится ждать около 150 микросекунд, пока echo и xxd запишут будущий ввод в stdin
Исправление бенчмарка
Исправить бенчмарк оказалось просто. Я решил не выполнять приложение в рамках конвейера bash, а вынес этапы подготовки и выполнения в отдельные команды:
# Преобразовать ввод из шестнадцатеричной кодировки в двоичную.
$ INPUT_FILE_BINARY="$(mktemp)"
$ echo '60016000526001601ff3' | xxd -r -p > "${INPUT_FILE_BINARY}"
# Считать ввод в двоичной кодировке в виртуальную машину.
$ ./zig-out/bin/eth-zvm < "${INPUT_FILE_BINARY}"
execution time: 67.378µsТогда наблюдавшийся ранее показатель в 438 микросекунд сократился всего до 67 микросекунд.
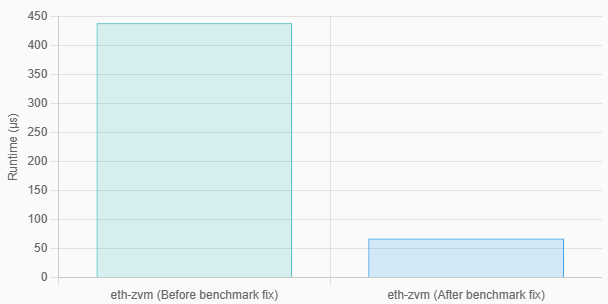
Разница в измеренной производительности моего приложения Zig после того, как я исправил мой бенчмаркинговый скрипт
Как я последовал совету Эндрю Келли и исправил производительность
Напомню: Эндрю Келли указал мне, что я выполняю по одному системному вызову на каждый считываемый байт.
...
while (true) {
_ = reader.readByte() { // Медленно! Один системный вызов на каждый байт!
...
};
...
}Таким образом, всякий раз, когда моё приложение вызывало readByte, работая в цикле, приходилось приостанавливать выполнение, запрашивать у ОС операцию считывания ввода, а затем возобновлять работу после того, как ОС доставит мне единственный байт.
Исправить эту проблему не составило труда. Мне потребовалось использовать буферизацию при чтении. Теперь я не считывал по одному байту за раз из ОС, а воспользовался встроенной функцией std.io.bufferedReader, имеющейся в Zig. С её помощью моё приложение может считывать из ОС большие фрагменты данных. Таким образом, мне осталось выполнять в разы меньше системных вызовов, чем ранее.
Вот код со всеми изменениями:
diff --git a/src/main.zig b/src/main.zig
index d6e50b2..a46f8fa 100644
--- a/src/main.zig
+++ b/src/main.zig
@@ -7,7 +7,9 @@ pub fn main() !void {
const allocator = gpa.allocator();
defer _ = gpa.deinit();
- var reader = std.io.getStdIn().reader();
+ const in = std.io.getStdIn();
+ var buf = std.io.bufferedReader(in.reader());
+ var reader = buf.reader();
var evm = vm.VM{};
evm.init(allocator);Я повторно выполнил мой код и заметил, что он стал быстрее ещё на 11 микросекунд, это весьма скромное ускорение на 16%.
$ zig build -Doptimize=ReleaseFast && ./zig-out/bin/eth-zvm < "${INPUT_FILE_BINARY}"
execution time: 56.602µs
При буферизации операций считывания производительность удалось улучшить ещё на 16%
Что, если проверить более крупный ввод?
В настоящее время мой интерпретатор Ethereum поддерживает лишь небольшое подмножество всех опкодов Ethereum. Самые сложные вычисления, которые он сейчас поддерживает — это сложение чисел.
Вот, например, приложение для Ethereum, которое считает до трёх, трижды записывая 1 в стек, а затем складывая эти значения:
PUSH1 1 # Сейчас стек содержит [1]
PUSH1 1 # Сейчас стек содержит [1, 1]
PUSH1 1 # Сейчас стек содержит [1, 1, 1]
ADD # Сейчас стек содержит [2, 1]
ADD # Сейчас стек содержит [3]Самое крупное приложение, для которого я расставлял бенчмарки — это байт-код Ethereum, считающий до 1 000, складывая единицы.
После того, как мне удалось сократить количество системных вызовов по совету Эндрю Келли, мой «счётчик до 1000» стал справляться с работой не за 2 024 микросекунды, как ранее, а всего за 58 микросекунд — ускорение в 35 раз. Теперь я уделывал официальную реализацию Ethereum почти в два раза.

Буферизуя считывание входной информации, я ускорил мою реализацию на Zig почти в два раза по сравнению с официальной реализацией Ethereum (речь о самом большом приложении из тех, что я протестировал)
Немного жульничества ради максимальной производительности
Я с большим воодушевлением убедился, что моя реализация на Zig наконец-то превосходит официальную версию на Go. Но хотелось увидеть, насколько ещё удастся улучшить производительность, правильно используя Zig.
Типичное узкое место при разработке ПО связано с выделением памяти. Программе приходится запрашивать память у операционной системы и ждать, пока ОС удовлетворит этот запрос.
В Zig есть механизм выделения памяти, работающий с буфером фиксированного размера. С его помощью можно не запрашивать память у ОС, а предоставить выделяющему механизму фиксированный буфер с байтами, и при выделении памяти он будет использовать только эти байты.
Здесь можно пойти на хитрость: я скомпилировал такую версию интерпретатора Ethereum, которая может получить всего 2 КБ памяти, выделяемой из стека:
diff --git a/src/main.zig b/src/main.zig
index a46f8fa..9e462fe 100644
--- a/src/main.zig
+++ b/src/main.zig
@@ -3,9 +3,9 @@ const stack = @import("stack.zig");
const vm = @import("vm.zig");
pub fn main() !void {
- var gpa = std.heap.GeneralPurposeAllocator(.{}){};
- const allocator = gpa.allocator();
- defer _ = gpa.deinit();
+ var buffer: [2000]u8 = undefined;
+ var fba = std.heap.FixedBufferAllocator.init(&buffer);
+ const allocator = fba.allocator();
const in = std.io.getStdIn();
var buf = std.io.bufferedReader(in.reader());Называю этот приём «жульническим», так как специально оптимизирую код под конкретные бенчмарки. Естественно, существуют полноценные программы для Ethereum, которым требуется более 2 КБ памяти, но мне просто любопытно, как сильно можно разогнаться, занимаясь такой оптимизацией.
Допустим, я уже во время компиляции знаю, сколько памяти мне максимально может понадобиться. Посмотрим, как это отразится на производительности:
$ ./zig-out/bin/eth-zvm < "${COUNT_TO_1000_INPUT_BYTECODE_FILE}"
execution time: 34.4578µsКруто! Если применить буфер памяти с фиксированным размером, моя реализация на Ethereum прогоняет байт-код «подсчёта до 1000» всего за 34 микросекунды, то есть, почти втрое быстрее, чем официальная реализация на Go.
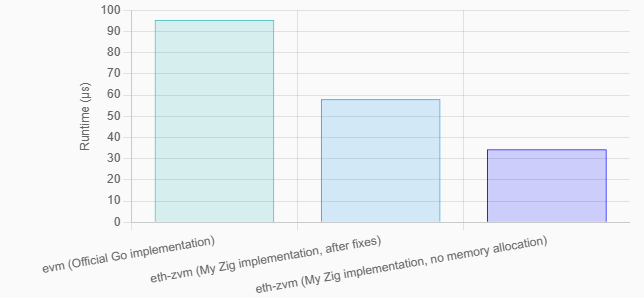
Если уже во время компиляции известно, сколько памяти (по максимуму) понадобится моему интерпретатору Ethereum, я могу обставить официальную реализацию примерно в три раза
Заключение
Вывод, который я делаю из этого эксперимента — бенчмаркинг нужно начинать пораньше и проводить почаще.
Добавив бенчмаркинговый скрипт в мою систему непрерывной интеграции и архивируя результаты, я легко заметил, когда показатели моих замеров изменились. Если бы я делегировал бенчмаркинг, выделив его в отдельную задачу, периодически выполняемую вручную, то мне было бы сложно точно определить, из-за чего возникает разница в замерах.
Также этот опыт подчёркивает, насколько важно понимать те метрики, которые вы измеряете. Прежде, чем наткнуться на этот баг, я полагал, что в моём бенчмарке учитывается время, которое требуется выждать, пока другие процессы заполнят stdin.
Исходный код
eth-zvm: Виртуальная машина для Ethereum, которую я из интереса реализовал на Zig
