Как мы NoSQL в «реляционку» реплицировали
Одним из таких продуктов стала СУБД GT.m, разработанная компанией Graystone Tehnologies в 70–80-х годах прошлого века. СУБД нашла широкое применение в медицине, страховании и банковской сфере.
В нашем банке мы тоже используем GT.m, и этот инструмент прекрасно справляется с обработкой большого количества транзакций. Но… Есть одна проблема: GT.m никакой для аналитики, в нем нет SQL, аналитических запросов и всего того, что делает финансового аналитика счастливым. Поэтому мы разработали собственный «велосипед» для репликации данных из GT.m в «реляционные» СУБД.

А вот здесь должна была быть картинка с летающим велосипедом
Всех заинтересованных приглашаем под кат.
Псс… Не хочешь еще немного GT.m? Уже в те доисторические времена GT.m имела (или имел) подержу ACID, сериализацию транзакций и наличие индексов и процедурного языка MUMPS. Кстати, MUMPS — это не просто язык, это целое направление, появившееся еще в 60-х годах 20 века!
Одной из самых успешных и популярных MUMPS-based СУБД стала Caché, и вы, скорее всего, слышали о ней.
Основой MUMPS СУБД являются иерархические структуры — глобалы. Представьте JSON, XML или структуру папок и файлов на вашем компьютере — примерно то же самое. И всем этим наши отцы и деды наслаждались до того, как это стало мейнстримом.
Один важный момент — в 2000 году СУБД стала Open Source.
Так вот, старушка GT.m надежна и, несмотря на свои преклонные года, обслуживает большое количество специфичных транзакций без каких-либо усилий в отличие, например, от своих SQL собратьев (фраза, конечно, холиварная, но для нас это факт: на определенной нагрузке NoSQL все же шустрее SQL). Однако все проблемы начинаются тогда, когда нам нужно сделать простейшую аналитику, передать данные в аналитические системы или, не дай бог, автоматизировать все это.
Долгое время решением данной проблемы были вездесущие «выгрузки». CSV файлы формировались процедурами, написанными на языке M (MUMPS), и каждая такая выгрузка разрабатывалась, тестировалась и внедрялась высококвалифицированными специалистами. Усилия, затрачиваемые на разработку каждой выгрузки, были огромными, а содержимое двух разных выгрузок могло существенно пересекаться между собой. Случалось такое, что заказчики требовали выгрузки, на несколько полей отличные от существующих, и приходилось делать все заново. При этом сам язык M код достаточно тяжелый для понимания и чтения, что влечет за собой дополнительные «расходы» как на разработку, так и на поддержку всего этого хардкода.

Решение с выгрузками
ODS (Operational Data Store)
У нас уже был реализованный архитектурный паттерн под названием ODS (Operational Data Store), в который мы реплицируем наши источники с минимальными отставаниями от 2 секунд до 15 минут.
Данные из ODS мы загружаем в хранилище данных (DWH) либо строим по ним оперативные отчеты. И с реляционными СУБД типа Oracle, MS SQL, Sybase и т.д. нет проблем — грузим таблицы источников в те же самые таблицы на ODS.
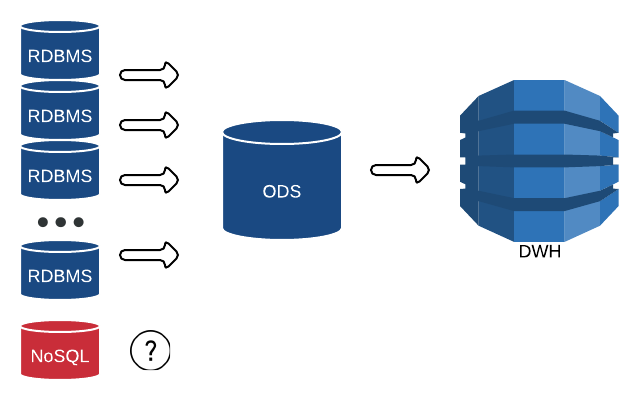
Мы очень хотели реализовать подобную репликацию GT.m в ODS.
Но как же грузить NoSQL структуры в простые таблицы? Как, например, загрузить клиента, у которого может быть 2 телефона, а может и 22?

Мы понимали, что правильнее будет организовать репликацию на основе бинарных логов СУБД (в других СУБД они называются WAL, Redo, transaction log и т.п.), благо, GT.m журналирует каждую транзакцию, изменяемую данные. При этом на рынке уже существовали готовые продукты, одним из которых является Evolve Replicator от компании CAV systems.
Evolve CAV systems
Evolve читает журналы транзакций, трансформирует их и записывает строки в таблицы уже на реляционном приемнике.
Но была одна совсем маленькая проблема — это решение нам не подходило… В наших структурах имелось большое количество вычисляемых значений (Computed Data Items или CDI).
Попробую объяснить на пальцах. Это чем-то напоминает «виртуальное поле» в таких СУБД, как Oracle, в которых значение не хранится, а вычисляется на момент обращения к этому полю. При этом CDI может иметь достаточно сложную логику и базироваться на данных из дочерних узлов и т.д. И, как вы наверно уже догадались, такие Computed Data Items невозможно реплицировать из журналов СУБД, так как информация по ним там не хранится, потому что в журналы записываются только изменения физических полей. Но такие поля-призраки нам очень нужны для аналитики, в них сложная логика, и иметь аналитическую реплику без этих полей было бы бессмысленно.
Реализовать подобную логику с вычисляемыми полями в реплике — нереально. Во-первых, по причине производительности, во-вторых — переписывать весь этот хардкод с языка М на SQL — дело неблагодарное.

FIS Profile
Помимо уровня данных, в нашей системе мы имеем и уровень приложений, написанных на языке М. Да, в наши времена это звучит дико, но большинство банковских систем до сих пор живут в парадигме двухзвенной архитектуры.
Таким приложением является FIS Profile (далее Profile) — это автоматизированная банковская система, полностью интегрированная с GT.m. Кроме функций автоматизации банковской деятельности, Profile обеспечивает следующий функционал:
1. Простейший SQL (select * from table where id=1)
2. Доступ к данным по JDBC
3. Представление глобалов в табличный вид, при этом один глобал может быть представлен в несколько разных таблиц
4. Триггеры
5. Секьюрность
По сути, мы имеем еще одну СУБД поверх другой СУБД. При этом одна из них будет реляционной, а другая — NoSQL.
Profile является полностью проприетарным ПО, но есть и Open Source аналоги, например, Vista Fileman.

Логические уровни нашей GT.m-системы.
Реализация концепции
Для репликации NoSQL-структур данных в SQL СУБД в первую очередь необходимо:
1. Представить глобалы в табличном виде.
При этом один узел «дерева» может быть представлен в виде нескольких, связанных между собой таблиц. Такую возможность уже предоставляет Profile, и все, что нам необходимо, — это правильно настроить такие табличные представления. Задача хоть и сложная, но вполне решаемая.
2. Захват изменений.
К сожалению, наличие CDI в нашей системе не позволяет сделать «правильную репликацию» из журналов СУБД. Единственный возможный вариант — логическая репликация триггерами. Изменилось значение в таблице — триггер это отловил и записал изменение в журнальную таблицу. Кстати, журнальная таблица — это тот же самый глобал. Сейчас все сами увидите!
Вот так выглядит типичный глобал:

Понимаем, выглядит как минимум… странно, но в те далекие годы понятия красоты были совершенно другими. Структура глобала также называется «многомерным разреженным массивом». И ключ — это как бы координата данных, которые в нем лежат.
Кстати, по «данным» можно также строить индексы, что бывает очень удобно для табличного представления.
Собственно, из такого глобала мы можем получить 2 таблицы:
TABLE_HEADER
TABLE_SHED — лог изменений
Кстати, числовые значения преобразовались в даты, например, для поля TJD.
По имеющимся таблицам выполняется запрос
где:
: STARTPOINT — дата последнего запуска;
'Т' — текущая дата (выглядит как минимум странно, но эта функция — аналог sysdate () или now () в нормальных других СУБД)
Как мы видим, происходит соединение «таблиц»; по факту соединение локальное, в пределах каждого узла, что не создает существенной нагрузки.
3. Выборка данных из журнальных таблиц и последующая их передача в ODS.
Существовавший на тот момент данных JDBC-драйвер прекрасно работал с атомарными запросами, но вызывал утечки памяти во время массированных операций Select. Имеющийся драйвер пришлось значительно переписать.
4. Доставка и применение изменений.
Очень важный аспект — быстрое применение данных на приемнике. Если GT.m успешно справляется с большим количеством атомарных транзакций, то для реляционных СУБД типа Oracle это несет большую нагрузку. При этом в наш ODS льются данные из большого количества других источников (всего около 15).
Для решения этой проблем, необходимо собирать все такие операции в пачки и применять их группой. Такие операции называются Bulk и полностью зависят от специфики СУБД приемника.

Текущая архитектура репликации
Наше приложение — кстати, мы его назвали Profile Loader — загружает в ODS два типа таблиц: журнальные и зеркальные. Мы постараемся рассказать про ODS в будущих статьях, но если кратко, то:
журнальные таблицы — таблицы логов изменений, эти таблицы удобны для инкрементальной загрузки, например, в аналитические системы и DWH
зеркальные таблицы — таблицы, содержащие в себе полную копию данных источника, такие таблицы удобно использовать для аудита и для оперативной аналитики.
5. Пункт управления.
Для удобного администрирования мы сделали веб-мордочку для запуска и остановки потоков репликации. Да и вообще, вся основная логика была написала на Java, что позволило использовать уже готовые Open Source компоненты для решения каких-то специфичных кейсов.
Задачи, решаемые SQL репликой
1. Избавление от разрозненных выгрузок. Мы получили единое окно для всех потребителей данных.
2. Аудит. Упрощается процедура аудита за счет того, что данные лежат в удобном виде, а мощь SQL позволяет удобно и быстро этими данными оперировать.
3. Качество данных. Например, в GT.m всего 2 типа данных — числовой и строковый. Когда данные прилетают в ODS, они преобразуется в другие типы, в том числе и в даты. Если дата в неправильном формате, мы можем легко отлавливать такой инцидент и улучшать качество данных уже на источнике.
4. Вычисление инкремента для дальнейшей загрузки в DWH.
Дальнейшие пути развития
На будущее планируем реализовать следующее:
1. Полностью избавиться от существующих CSV-выгрузок. Сейчас они все еще живы, но мы их будем потихоньку «отстреливать».
2. Оптимизировать некоторые проблемы с производительностью.
3. Поделиться идеями с заинтересованным сообществом, возможно и поддерживать проект в OpenSource.
4. Попробовать интеграцию с Oracle GoldenGate на уровне доставки изменений.
5. Возможно, сделать обратную реплику (дополнительную, не ODS) Replica → GT.m, для сервисных процессов повышения качества данных.
6. Развивать оперативную отчетность поверх ODS.
Резюме
В статье мы рассказали о нашем детище — Profile Loader и о том, как NoSQL данные можно анализировать в SQL СУБД. Данное решение возможно не совсем правильное и элегантное, но оно прекрасно работает и выполняет возложенные на него обязательства.
Если вы решитесь реплицировать свою NoSQL БД в «реляционку» для удобной аналитики, в первую очередь оцените объемы изменений, модель данных и возможности тех технологий, которые все это будут обеспечивать.
Желаем успехов в ваших начинаниях!
Всегда готовы ответить на ваши вопросы.
P.S. Также выражаем благодарность коллегам, участвовавшим и активно помогавшим в проекте: Шевелеву Дмитрию, Чебанову Николаю, Бубону Роману, Быстрову Денису, Бейспекову Кайсару, Люфко Андрею, Кудюрову Павлу, Воробьёву Сергею, Лысых Сергею, Кулешову Денису, Никитчик Елене, Мушкет Ольге, Чечёткиной Юлии, Пасынкову Юрию и коллегам из CAV Systems и FIS.
Комментарии (7)
 Kore
Kore
3 августа 2016 в 09:35
+1↑
↓
yusman, интересная статья, спасибо. Подскажите, насколько затратно по ресурсам поддерживать этот велосипед под названием Profile Loader?
С учетом специфики вашей работы не возникало ли серьезных проблем, связанных с такой реализацией переноса данных в реляционную СУБД?
И последний вопрос — неужели нет готовых коммерческих решений? Что сподвигло вас самостоятельно разработать механизм трансфера? yusman
yusman
3 августа 2016 в 09:55
0↑
↓
Разработкой и основной поддержкой Profile Loader занимается один человек, при этом, это не основной его функционал. В целом система достаточно надежная и понятная в обслуживании, при этом работает достаточно быстро. Серьезных проблем с ней у нас не было.
С коммерческими продуктами все сложно, единственное решение, существовашее на рынке, нас не устроило по причине невозможности репликации вычисляемых полей, а в них как раз то и хранится полезная для аналитики информация.-
Kore
3 августа 2016 в 10:25
0↑
↓
Спасибо.
Вы только задумываетесь о распространении вашего решения через OpenSource коммьюнити? Или уже занимаетесь этим?
 kefirfromperm
kefirfromperm
3 августа 2016 в 09:54
0↑
↓
Назвал иерархические СУБД NoSQL и всё сразу стало стильно модно молодежно.Вряд ли корректно называть иерархические СУБД NoSQL, что изначально означало Not Only SQL. Что как бы говорит о следующем шаге, о дополнительных возможностях и снятии ограничений наложенных реляционной моделью. Унаследованные иерархические СУБД — это, всё же, немного не то. Да и класс NoSQL гораздо шире.
-
yusman
3 августа 2016 в 10:11
0↑
↓
Спорить конечно на эту тему можно бесконечно, но по факту в современных NoSQL СУБД структуры примерно такие же, что и в старых, только названы по другому — JSON, Objects store и т.д… Что-то дает больше удобства, что-то большей гибкости, но всегда находится компропис и новые проблемы. История циклична.
Мы постарались описать только подход, его можно попробовать применить и на другие NoSQL СУБД, на какие конкретно — совершенно не важно, буть то Mongo или, например, DocumentDB. 3 августа 2016 в 10:24
+1↑
↓
Назвал иерархические СУБД NoSQL и всё сразу стало стильно модно молодежно
NoSQL это не только иерархические СУБД. Тот же Redis можно назвать NoSQL, что не сделает его иерархической СУБД. Если мы конечно не будем вдаваться в демагогию и называть СУБД типа Ключ-Значение частным случаем иерархической СУБД с одним уровнем вложенности.
3 августа 2016 в 10:22
0↑
↓
Логическая репликация на триггерах — ок. А нету вот такого же, но с перламутровыми для хадупа?
