Как измерить количество информации?
Мы ежедневно работаем с информацией из разных источников. При этом каждый из нас имеет некоторые интуитивные представления о том, что означает, что один источник является для нас более информативным, чем другой. Однако далеко не всегда понятно, как это правильно определить формально. Не всегда большое количество текста означает большое количество информации. Например, среди СМИ распространена практика, когда короткое сообщение из ленты информационного агентства переписывают в большую новость, но при этом не добавляют никакой «новой информации». Или другой пример: рассмотрим текстовый файл с романом Л.Н. Толстого «Война и мир» в кодировке UTF-8. Его размер — 3.2 Мб. Сколько информации содержится в этом файле? Изменится ли это количество, если файл перекодировать в другую кодировку? А если заархивировать? Сколько информации вы получите, если прочитаете этот файл? А если прочитаете его второй раз?
По мотивам открытой лекции для Computer Science центра рассказываю о том, как можно математически подойти к определению понятия «количество информации».
В классической статье А.Н. Колмогорова «Три подхода к определению понятия количества информации» (1965) рассматривают три способа это сделать:
комбинаторный (информация по Хартли),
вероятностный (энтропия Шеннона),
алгоритмический (колмогоровская сложность).
Мы будем следовать этому плану.
Комбинаторный подход: информация по Хартли
Мы начнём самого простого и естественного подхода, предложенного Хартли в 1928 году.
Пусть задано некоторое конечное множество  . Количеством информации в
. Количеством информации в  будем называть
будем называть  .
.
Можно интерпретировать это определение следующим образом: нам нужно  битов для описания элемента из
битов для описания элемента из  .
.
Почему мы используем биты? Можно использовать и другие единицы измерения, например, триты или байты, но тогда нужно изменить основание логарифма на 3 или 256, соответственно. В дальшейшем все логарифмы будут по основанию 2.
Этого определения уже достаточно для того, чтобы измерить количество информации в некотором сообщении. Пусть про  стало известно, что
стало известно, что  . Теперь нам достаточно
. Теперь нам достаточно  битов для описания
битов для описания  , таким образом нам сообщили
, таким образом нам сообщили  битов информации.
битов информации.
Пример
Загадано целое число
от
до
. Нам сообщили, что
делится на
. Сколько информации нам сообщили?
Воспользуемся рассуждением выше.

(Тот факт, что некоторое сообщение может содержать нецелое количество битов, может показаться немного неожиданным.)
Можно ещё сказать, что сообщение, уменшающее пространство поиска в  раз приносит
раз приносит  битов информации. В данном примере пространство поиска уменьшилось в 1000/166 раз.
битов информации. В данном примере пространство поиска уменьшилось в 1000/166 раз.
Интересно, что одного этого определения уже достаточно для того, чтобы решать довольно нетривиальные задачи.
Применение: цена информации
Загадано целое число
от
до
. Разрешается задавать любые вопросы на ДА/НЕТ. Если ответ на вопрос «ДА», то мы должны заплатить рубль, если ответ «НЕТ» — два рубля. Сколько нужно заплатить для отгадывания числа
?
Любой вопрос можно сформулировать как вопрос о принадлежности некоторому множеству, поэтому мы будем считать, что все вопросы имеют вид » ?» для некоторого множества
?» для некоторого множества  .
.
Каким образом нужно задавать вопросы? Нам бы хотелось, чтобы вне зависимости от ответа цена за бит информации была постоянной. Другими словами, в случае ответа «НЕТ» и заплатив два рубля мы должны узнать в два больше информации, чем при ответе «ДА». Давайте запишем это формально.
Потребуем, чтобы

Пусть  , тогда
, тогда  . Подставляем и получаем, что
. Подставляем и получаем, что

Это эквивалентно квадратному уравнению  Положительный корень этого уравнения
Положительный корень этого уравнения  . Таким образом, при любом ответе мы заплатим
. Таким образом, при любом ответе мы заплатим  рублей за бит информации, а в сумме мы заплатим примерно
рублей за бит информации, а в сумме мы заплатим примерно рублей (с точностью до округления).
рублей (с точностью до округления).
Осталось понять, как выбирать такие множества . Будем выбирать в качестве  непрерывные отрезки прямой. Пусть нам известно, что
непрерывные отрезки прямой. Пусть нам известно, что  принадлежит отрезку
принадлежит отрезку ![[a,b]](https://habrastorage.org/getpro/habr/upload_files/9a0/3e7/b69/9a03e7b69911956ef048f0e4f6496a6c.svg) (изначально это отрезок
(изначально это отрезок ![[1,n]](https://habrastorage.org/getpro/habr/upload_files/6a5/ba8/1c6/6a5ba81c6f282d08594b053eb740e8a7.svg) ). В следующего множества
). В следующего множества  возмём отрезок
возмём отрезок ![[a, a+ \alpha\cdot(b-a)]](https://habrastorage.org/getpro/habr/upload_files/9cc/487/bdb/9cc487bdbefd53d5e81016a203868ef7.svg) , где. Тогда за каждый заплаченный рубль текущий отрезок будет уменьшаться в
, где. Тогда за каждый заплаченный рубль текущий отрезок будет уменьшаться в  раз. Когда длина отрезка станет меньше единицы, мы однозначно определим . Поэтому цена отгадывания не будет превосходить
раз. Когда длина отрезка станет меньше единицы, мы однозначно определим . Поэтому цена отгадывания не будет превосходить

Приведённое рассуждение доказывает только верхнюю оценку. Можно доказать и нижнюю оценку: для любого способа задавать вопросы будет такое число , для отгадывания которого придётся заплатить не менее  рублей.
рублей.
Вероятностный подход: энтропия Шеннона
Вероятностный подход, предложенный Клодом Шенноном в 1948 году, обобщает определение Хартли на случай, когда не все элементы множества являются равнозначными. Вместо множества в этом подходе мы будем рассматривать вероятностное распределение на множестве и оценивать среднее по распределению количество информации, которое содержит случайная величина.
Пусть задана случайная величина  , принимающая
, принимающая  различных значений с вероятностями
различных значений с вероятностями  . Энтропия Шеннона случайной величины
. Энтропия Шеннона случайной величины  определяется как
определяется как

(По непрерывности тут нужно доопределить  .)
.)
Энтропия Шеннона оценивает среднее количество информации (математическое ожидание), которое содержится в значениях случайной величины.
При первом взгляде на это определение, может показаться совершенно непонятно откуда оно берётся. Шеннон подошёл к этой задаче чисто математически: сформулировал требования к функции и доказал, что это единственная функция, удовлетворяющая сформулированным требованиям.
Я попробую объяснить происхождение этой формулы как обобщение информации по Хартли. Нам бы хотелось, чтобы это определение согласовывалось с определением Хартли, т.е. должны выполняться следующие «граничные условия»:
Будем искать  в виде математического ожидания количества информации, которую мы получаем от каждого возможного значения .
в виде математического ожидания количества информации, которую мы получаем от каждого возможного значения .

Как оценить, сколько информации содержится в событии  ? Пусть
? Пусть  — всё пространство элементарных исходов. Тогда событие
— всё пространство элементарных исходов. Тогда событие  соответствует множеству элементарных исходов меры
соответствует множеству элементарных исходов меры  . Если произошло событие
. Если произошло событие  , то размер множества согласованных с этим событием элементарных исходов уменьшается с
, то размер множества согласованных с этим событием элементарных исходов уменьшается с  до
до  , т.е. событие
, т.е. событие  сообщает нам
сообщает нам  битов информации. Тут мы пользуемся тем, что количество информации в сообщении, которое уменьшает размер пространство поиска в
битов информации. Тут мы пользуемся тем, что количество информации в сообщении, которое уменьшает размер пространство поиска в  раз приносит
раз приносит  битов информации.
битов информации.
Примеры
Свойства энтропии Шеннона
Для случайной величины  , принимающей
, принимающей  значений с вероятностями
значений с вероятностями  , выполняются следующие соотношения.
, выполняются следующие соотношения.
Чем распределение ближе к равномерному, тем больше энтропия Шеннона.
Энтропия пары
Понятие энтропии Шеннона можно обобщить для пары случайных величин. Аналогично это обощается для тройки, четвёрки и т.д.
Пусть совместно распределённые случайные величины  и
и  принимают значения
принимают значения  и
и  , соответственно. Энтропия пары случайных величин
, соответственно. Энтропия пары случайных величин  и
и  определяется следующим соотношением:
определяется следующим соотношением:
![H(X,Y) = \sum_{i=1}^k\sum_{j=1}^m\Pr[X = a_i, Y=b_j]\cdot \log\frac{1}{\Pr[X = a_i, Y = b_j]}.](https://habrastorage.org/getpro/habr/upload_files/bdb/a99/dd1/bdba99dd141ec64b0456fb6ef5f765e6.svg)
Примеры
Рассмотрим эксперимент с выбрасыванием двух игральных кубиков — синего и красного.
Свойства энтропии Шеннона пары случайных величин
Для энтропии пары выполняются следующие свойства.
Условная энтропия Шеннона
Теперь давайте научимся вычислять условную энтропию одной случайной величины относительно другой.
Условная энтропия  относительно
относительно  определяется следующим соотношением:
определяется следующим соотношением:

Примеры
Рассмотрим снова примеры про два игральных кубика.
Свойства условной энтропии
Условная энтропия обладает следующими свойствами
Взаимная информация
Ещё одна информационная величина, которую мы введём в этом разделе — это взаимная информация двух случайных величин.
Информация в  о величине
о величине  (взаимная информация случайных величин
(взаимная информация случайных величин  и
и  ) определяется следующим соотношением
) определяется следующим соотношением

Примеры
И снова обратимся к примерам с двумя игральными кубиками.
Свойства взаимной информации
Выполняются следующие соотношения.

Все информационные величины, которые мы определили к этому моменту можно проиллюстрировать при помощи кругов Эйлера.
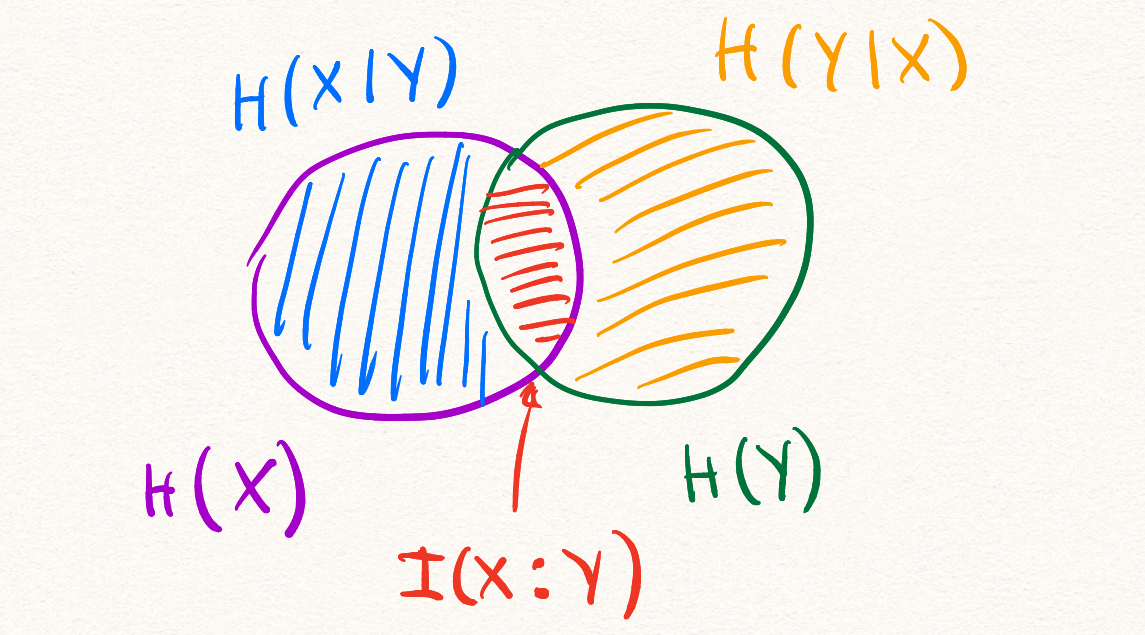
Мы пойдём дальше и рассмотрим информационную величину, зависящую от трёх случайных величин.
Пусть  ,
,  и
и  совместно распределены. Информация в
совместно распределены. Информация в  о
о  при условии
при условии  определяется следующим соотношением:
определяется следующим соотношением:

Свойства такие же как и обычной взаимной информации, нужно только добавить соответствующее условие ко всем членам.
Всё, что мы успели определить можно удобно проиллюстрировать при помощи трёх кругов Эйлера.

Из этой иллюстрации можно вывести все определения и соотношения на информационные величины.
Мы не будем продолжать дальше и рассматривать четыре случайные величины по трём причинам. Во-первых, рисовать четыре круга Эйлера со всеми возможными областями — это непросто. Во-вторых, для двух и трёх случайных величин почти все возможные соотношения можно вывести из кругов Эйлера, а для четырёх случайных величин это уже не так. И в третьих, уже для трёх случайных величин возникают неприятные эффекты, демонстрирующие, что дальше будет хуже.
Рассмотрим треугольник в пересечении всех трёх кругов  ,
,  и
и  . Этот треугольник соответствуют взаимной информации трёх случайных величин
. Этот треугольник соответствуют взаимной информации трёх случайных величин  . Проблема с этой информационной величиной заключается в том, что ей не удаётся придать какой-то «физический» смысл. Более того, в отличие от всех остальных величин на картинке
. Проблема с этой информационной величиной заключается в том, что ей не удаётся придать какой-то «физический» смысл. Более того, в отличие от всех остальных величин на картинке  может быть отрицательной!
может быть отрицательной!
Рассмотрим пример трёх случайных величин равномерно распределённых на  . Пусть
. Пусть  и
и  будут независимы, а
будут независимы, а  . Легко проверить, что
. Легко проверить, что  . При этом
. При этом  . В то же время
. В то же время  . Получается следующая картинка.
. Получается следующая картинка.

Мы знаем, что  . При этом
. При этом  . Получается, что
. Получается, что  , а
, а  , т.е. для таких случайных величин
, т.е. для таких случайных величин .
.
Применение энтропии Шеннона: кодирование
В этом разделе мы обсудим, как энтропия Шеннона возникает в теории кодирования. Будем рассматривать коды, которые кодируют каждый символ по-отдельности.
Пусть задан алфавит  . Код — это отображение из
. Код — это отображение из  в
в  . Код
. Код  называется однозначно декодируемым, если любое сообщение, полученное применением
называется однозначно декодируемым, если любое сообщение, полученное применением  к символам некоторого текста, декодируется однозначно.
к символам некоторого текста, декодируется однозначно.
Код называется префиксным (prefix-free), если нет двух символов  и
и  таких, что
таких, что  является префиксом
является префиксом  .
.
Префиксные коды являются однозначно декодируемыми. Действительно, при декодировании префиксного кода легко понять, где находятся границы кодов отдельных символов.
Теорема [Шеннон]. Для любого однозначно декодируемого кода существует префиксный код с теми же длинами кодов символов.
Таким образом для изучения однозначно декодируемых кодов достаточно рассматривать только префиксные коды.
Задача об оптимальном кодировании.
Дан текст  . Нужно найти такой код
. Нужно найти такой код  , что
, что

Пусть  . Обозначим через
. Обозначим через  частоту, с которой символ
частоту, с которой символ  встречается в
встречается в  . Тогда выражение выше можно переписать как
. Тогда выражение выше можно переписать как

Следующая теорема могла встречаться вам в курсе алгоритмов.
Теорема [Хаффман]. Код Хаффмана, построенный по  , является оптимальным префиксным кодом.
, является оптимальным префиксным кодом.
Алгоритм Хаффмана по набору частот эффективно строит оптимальный код для задачи оптимального кодирования.
Связь с энтропией
Имеют место две следующие оценки.
Теорема [Шеннон]. Для любого однозначно декодируемого кода выполняется

Теорема [Шеннон]. Для любых значений  существует префиксный код
существует префиксный код  , такой что
, такой что

Рассмотрим случайную величину  , равномерно распределённую на символах текста
, равномерно распределённую на символах текста  . Получим, что
. Получим, что  . Таким образом, эти две теоремы задают оценку на среднюю длину кода символа при оптимальном кодировании, т.е. и для кодирования Хаффмана.
. Таким образом, эти две теоремы задают оценку на среднюю длину кода символа при оптимальном кодировании, т.е. и для кодирования Хаффмана.

Следовательно, длину кода Хаффмана текста  можно оценить, как
можно оценить, как

Применение энтропии Шеннона: шифрования с закрытым ключом
Рассмотрим простейшую схему шифрования с закрытым ключом. Шифрование сообщения  с ключом шифрования
с ключом шифрования  выполняется при помощи алгоритма шифрования
выполняется при помощи алгоритма шифрования  . В результате получается шифрограмма
. В результате получается шифрограмма  . Зная
. Зная  получатель шифрограммы восстанавливает исходное сообщение
получатель шифрограммы восстанавливает исходное сообщение  :
:  .
.
Мы будем анализировать эту схему с помощью аппарата энтропии Шеннона. Пусть  и
и  являются случайными величинами. Противник не знает
являются случайными величинами. Противник не знает  и
и  , но знает
, но знает  , которая так же является случайной величиной.
, которая так же является случайной величиной.
Для совершенной схемы шифрования (perfect secrecy) выполняются следующие соотношения:
 , т.е. шифрограмма однозначно определяется по ключу и сообщению.
, т.е. шифрограмма однозначно определяется по ключу и сообщению. , т.е. исходное сообщение однозначно восстанавливается по шифрограмме и ключу.
, т.е. исходное сообщение однозначно восстанавливается по шифрограмме и ключу. , т.е. в отсутствие ключа из шифрограммы нельзя получить никакой информации о пересылаемом сообщении.
, т.е. в отсутствие ключа из шифрограммы нельзя получить никакой информации о пересылаемом сообщении.
Теорема [Шеннон].  , даже если условие
, даже если условие  нарушается (т.е. алгоритм
нарушается (т.е. алгоритм  использует случайные биты).
использует случайные биты).
Эта теорема утверждает, что для совершенной схемы шифрования длина ключа должна быть не менее длины сообщения. Другими словами, если вы хотите зашифровать и передать своему знакомому файл размера 1Гб, то для этого вы заранее должны встретиться и обменяться закрытым ключом размера не менее 1Гб. И конечно, этот ключ можно использовать только однажды. Таким образом, самая оптимальная совершенная схема шифрования — это «одноразовый блокнот», в котором длина ключа совпадает с длиной сообщения.
Если же вы используете ключ, который короче пересылаемого сообщения, то шифрограмма раскрывает некоторую информацию о зашифрованном сообщении. Причём количество этой информации можно оценить, как разницу между энтропией сообщения и энтропией ключа. Если вы используете пароль из 10 символов при пересылке файла размера 1Гб, то вы разглашаете примерно 1Гб — 10 байт.
Это всё звучит очень печально, но не всё так плохо. Мы ведь никак не учитываем вычислительную мощь противника, т.е. мы не ограничиваем количество времени, которое противнику потребуется на выделение этой информации.
Современная криптография строится на предположении об ограниченности вычислительных возможностей противника. Тут есть свои проблемы, а именно отсутствие математического доказательства криптографической стойкости (все доказательства строятся на различных предположениях), так что может оказаться, что вся эта криптография бесполезна (подробнее можно почитать в статье о мирах Рассела Импальяццо, которая переведена на хабре), но это уже совсем другая история.
Доказательство. Нарисуем картинку для трёх случайных величин и отметим то, что нам известно.


В доказательстве мы действительно не воспользовались тем, что .
Алгоритмический подход: колмогоровская сложность
Подход Шеннона хорош для случайных величин, но если мы попробуем применить его к текстам, то выходит, что количество информации в тексте зависит только от частот символов, но не зависит от их порядка. При таком подходе получается, что в «Войне и мире» и в тексте, который получается сортировкой всех знаков в «Войне и мире», содержится одинаковое количество информации. Колмогоров предложил подход, позволяющий измерять количество информации в конкретных объектах (строках), а не в случайных величинах.
Внимание. До этого момента я старался следить за математической строгостью формулировок. Для того, чтобы двигаться дальше в том же ключе, мне потребовалось бы предположить, что читатель неплохо знаком с математической логикой и теорией вычислимости. Я пойду более простым путём и просто буду махать руками, заметая под ковёр некоторые подробности. Однако, все утверждения и рассуждения дальше можно математически строго сформулировать и доказать.
Нам потребуется зафиксировать способ описания битовой строки. Чтобы не углубляться в рассуждения про машины Тьюринга, мы будем описывать строки на языках программирования. Нужно только сделать оговорку, что программы на этих языках будут запускаться на компьютере с неограниченным объёмом оперативной памяти (иначе мы получили бы более слабую вычислительную модель, чем машина Тьюринга).
Сложностью  строки
строки  относительно языка программирования
относительно языка программирования  называется длина кратчайшей программы, которая выводит
называется длина кратчайшей программы, которая выводит  .
.
Таким образом сложность «Войны и мира» относительноя языка Python — это длина кратчайшей программы на Python, которая печатает текст «Войны и мира». Естественным образом сложность отсортированной версии «Войны и мира» относительно языка Python получится значительно меньше, т.к. её можно предварительно закодировать при помощи RLE.
Сравнение языков программирования
Дальше нам потребуется научиться любимой забаве всех программистов — сравнению языков программирования.
Будем говорить, что язык  не хуже языка программирования
не хуже языка программирования  и обозначать
и обозначать  , если существует константа
, если существует константа  такая, что для для всех
такая, что для для всех  выполняется
выполняется 
Исходя из этого определения получается, что язык Python не хуже (!) этого вашего Haskell! И я это докажу. В качестве константы  мы возьмём длину реализации интепретатора Haskell на Python. Таким образом, любая программа на Haskell переделывается в программу на Python просто дописыванием к ней интерпретатора Haskell на Python.
мы возьмём длину реализации интепретатора Haskell на Python. Таким образом, любая программа на Haskell переделывается в программу на Python просто дописыванием к ней интерпретатора Haskell на Python.
Соломонов и Колмогоров пошли дальше доказали существования оптимального языка программирования.
Теорема [Соломонова-Колмогорова]. Существует способ описания (язык программирования)  такой, что для любого другого способа описания
такой, что для любого другого способа описания  выполняется
выполняется  .
.
И да, некоторые уже наверное догадались, что — это JavaScript. Или любой другой Тьюринг полный язык программирования.
Это приводит нас к следующему определению, предложенному Колмогоровым в 1965 году.
Колмогоровской сложностью строки  будем называтьеё сложность относительно оптимального способа описания и будем обозначать
будем называтьеё сложность относительно оптимального способа описания и будем обозначать  .
.
Важно понимать, что при разных выборах оптимального языка программирования колмогоровская сложность будет отличаться, но только на константу. Для любых двух оптимальных языков программирования  и
и  выполняется
выполняется  и
и  , т.е. существует такая константа
, т.е. существует такая константа  , что
, что  Это объясняет, почему в этой науке аддитивные константы принято игнорировать.
Это объясняет, почему в этой науке аддитивные константы принято игнорировать.
При этом для конкретной строки и конкретного выбора колмогоровская сложность определена однозначно.
Свойства колмогоровской сложности
Начнём с простых свойств. Колмогоровская сложность обладает следующими свойствами.
Первое свойство выполняется потому, что мы всегда можем зашить строку в саму программу. Второе свойство верно, т.к. из программы, выводящей строку  , легко сделать программу, которая выводит эту строку дважды.
, легко сделать программу, которая выводит эту строку дважды.
Примеры
Несжимаемые строки
Важнейшее свойство колмогоровской сложности заключается в существовании сложных (несжимаемых строк). Проверьте себя и попробуйте объяснить, почему не бывает идеальных архиваторов, которые умели бы сжимать любые файлы хотя бы на 1 байт, и при этом позволяли бы однозначно разархивировать результат.
В терминах колмогоровской сложности это можно сформулировать так.
Вопрос. Существует ли такая длина строки
, что для любой строки
колмогоровская сложность
меньше
?
Следующая теорема даёт отрицательный ответ на этот вопрос.
Теорема. Для любого  существует
существует  такой, что
такой, что  .
.
Доказательство. Битовых строк длины  всего
всего  . Число строк сложности меньше
. Число строк сложности меньше  не превосходит число программ длины меньше
не превосходит число программ длины меньше  , т.е. таких программ не больше чем
, т.е. таких программ не больше чем

Таким образом, для какой-то строки гарантированно не хватит программы.
Верна и более сильная теорема.
Теорема. Существует  слов длины
слов длины  верно
верно

Другими словами, почти все строки длины  имеют почти максимальную сложность.
имеют почти максимальную сложность.
Колмогоровская сложность: вычислимость
В этом разделе мы поговорим про вычислимость колмогоровской сложности. Я не буду давать формально определение вычислимости, а буду опираться на интуитивные предствления читателей.
Теорема. Не существует программы, которая по двоичной записи числа  выводит строку
выводит строку  , такую что
, такую что  .
.
Эта теорема говорит о том, что не существует программы-генератора, которая умела бы генерировать сложные строки по запросу.
Доказательство. Проведём доказетельство от противного. Пусть такая программа © Habrahabr.ru
