Как автоматизировать построение архитектурных схем в большой микросервисной системе
Если у вас есть большая система, состоящая из множества микросервисов, то вы наверняка задавались вопросом: «Что сделать, чтобы архитектурная схема этой махины была на 100% актуальной?». Это необходимо, чтобы понимать:
Какие сервисы есть в системе, за что они отвечают и какая команда ими владеет?
Какие БД и файловые хранилища они используют?
Как сервисы взаимодействуют синхронно?
Как сервисы взаимодействуют асинхронно (какие сообщения и в какие топики Kafka отправляют)?
Меня зовут Кирилл Ветчинкин, я архитектор в СберМаркете. Наша система состоит более чем из 300 микросервисов. И с увеличением их количества связи между ними стали неочевидны.
Обычно, в компаниях есть свои практики формирования архитектурных схем и ведения документации, что частично решает поставленный вопрос. Но проблема такова, что часто схемы со временем начинают расходиться с реальностью. Новые интеграции добавляются, старые — уходят, а актуализация схем вручную происходит не всегда своевременно.
Обычно эта проблема решается архитектурным аудитом, котороый происходит время от времени. Но это достаточно длительная, дорогая и тяжелая работа, требующая большого ресурса архитекторов или системных аналитиков.
Мы в СберМаркете пробовали решить эту проблему таким способом. За каждым департаментовм был закрепелен архитектор, который следил за актуальностью схем. Но они всё равно, хоть и немного, отставали от реальности. А ещё это тратило много ресурса архитектора.
В итоге мы автоматизировали отрисовку схем, опираясь на метаданные IT-систем — создали отдельный микросервис Architect. О том как это происходит и как работает этот сервис я и расскажу в этой статье. А также дам несколько советов, которые помогут внедрить то же самое у вас в компании.

Этот и другие технологические кейсы актуальные для e-com мы разбирали на конференции E-community. Посмотреть выступления можно в плейлисте.
Зачем всё это нужно?
В чём, собственно, состоят проблемы с неактуальными схемами:
Архитектору сложно принимать решения. Растёт риск совершить ошибку из-за того, что данные ложные или неполные.
Разработчики и аналитики начинают не доверять архитектурным схемам. Как только они понимают, что та схема, на которую они опирались, стала неактуальна, они просто перестают ей пользоваться.
Внешним аудиторам сложно анализировать общее состояние системы. Иногда требуется показать схемы кому-то извне компании. Например, перед добавлением новых интеграций или систем. Если мы предоставим неактуальные архитектурные схемы, то можем получить проблемы при интеграции.
Администраторы и поддержка не могут полагаться на схемы при решении инцидентов. Из-за неактуальных схем у специалистов складывается ложная картина: они думают что система работает одним образом, когда на деле всё совсем иначе.
Всё это приводит к тому, что в компании принимаются ошибочные решения. Соответственно, система развивается некорректно и не так хорошо, как могла бы.
Как решить эти проблемы?
Есть 2 варианта:
Актуализировать вручную — это дорого, мучительно и долго.
Генерировать архитектурные схемы из метаданных систем — быстро, дешево, но есть техническе нюансы.
Мы выбрали 2-ой вариант, именно о нем и расскажу в этой статье. Обо всём по порядку.
#1 Выбираем подход для отрисовки схем
Если посмотреть на мировые тенденции, то можно заметить, что некоторое время назад было популярно преимущественно ручное тестирование, но спустя время тесты стали кодом. А после популяризации DevOps ручная настройка инфраструктурных систем так же сменилась на настройку с помощью кода. Мы описываем Doker-файлы, пишем Ansible-скрипты, создаем конфигурации в Terraform и так далее. Инфра также стала кодом.
Архитектура не отстает от тенденции — такой подход называться Arch as Code. Мы решили его применять при описании наших архитектурных схем, а в качестве нотации взяли C4 model и UML. В качестве инструментов использовали такую связку: PlantUML, C4-PlantUML, GitLab.
На рисунки ниже показан пример кода, который отрисовывает архитектурную схему с помощью C4-PlantUML в нотации C4 model.

Описание архитектурной схемы кодом
Удобство подхода в том, что вы описываете компоненты и их связи с помощью кода, затем движок C4-PlantUML производит рендеринг и получается схема.
C4 model— это довольно простая аннотация, ориентированная на то, что схему могут создать любые IT-специалисты, не обязательно только архитекторы.
Нотация предлагает 4 уровня детализации для описания системы. Это чем-то схоже с принципом работы географических карт в онлайне: сначала мы смотрим на планету Земля, потом на континент, потом на город и в конце концов на конкретную улицу. То есть мы зумим от общего к частному.
Тоже самое происходит и в нотации C4 model. Мы описываем общую схему системы, потом более детально какую-то ее часть, потом компонент и можем опуститься дальше вплоть до описания классов.
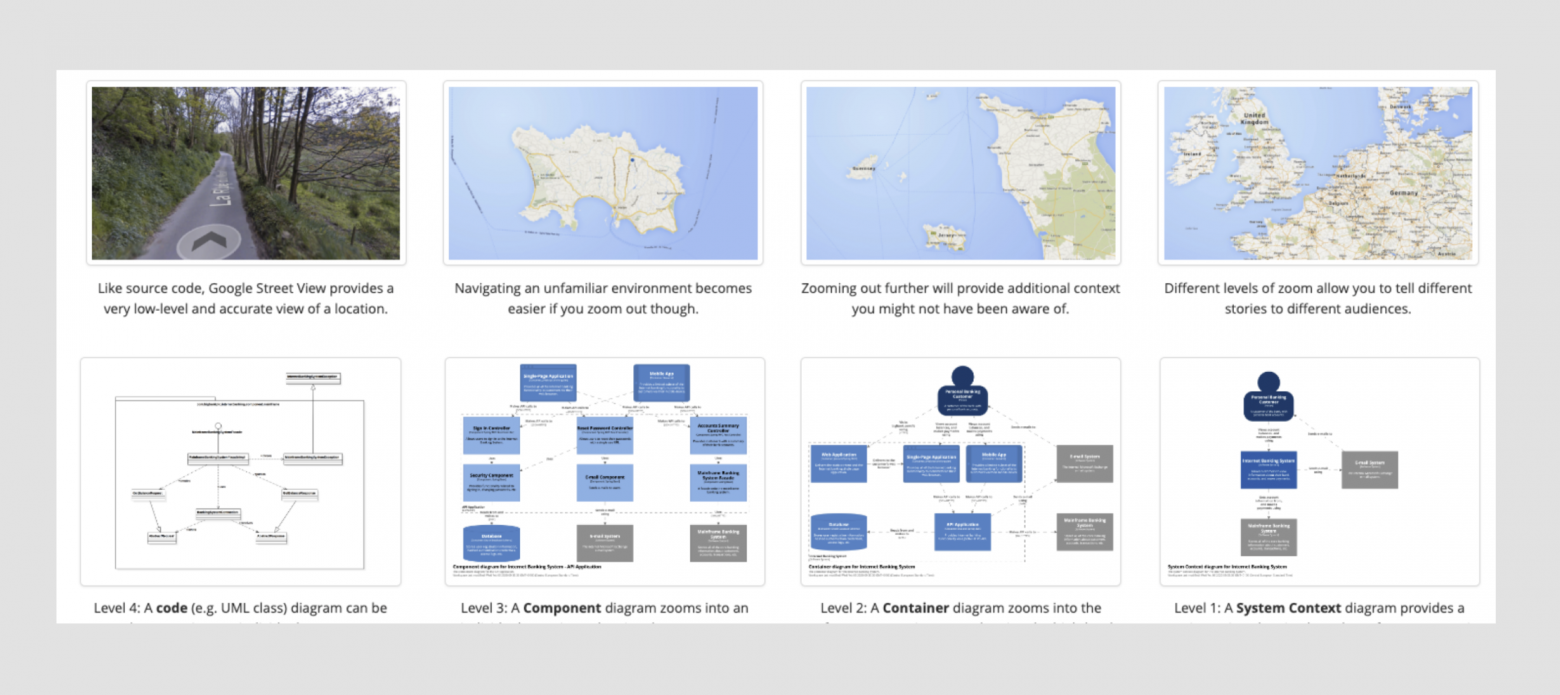
Сходство принципа работы C4 model и Google Карт
С4 model нотация состоит из 4-х видов схем:
Context diagram
Container diagram
Component diagram
Code diagram
При генерации схем мы отрисовываем Container diagram, показывая какие у сервиса есть зависимости от баз данных, топиков Kafka и от других сервисов.
#2 Выбираем метафайлы для генерации схем
Первое, что нам нужно понять — откуда мы будем брать метаданные сервиса, и что это вообще такое.
У нас в компании используется подход PaaS. Фактически, это заготовка сервиса с некими дополнительными библиотеками и настройками Kubernetes, позволяющая за 15 минут запускать сервис в прод с мониторингом и получением конфигураций.
Подробнее о том, как устроен наш PaaS можно прочитать в статье моего коллеги Димы Лукиянчука: PaaS два года спустя. Обзор инструментов и какие задачи они решают.
Если быть кратким, то с точки зрения деплоя PaaS — это обертка над Helm. Поэтому всё, что вы прочитаете дальше в статье, можно применить относительно ваших Helm-чартов и брать метаданные из них.
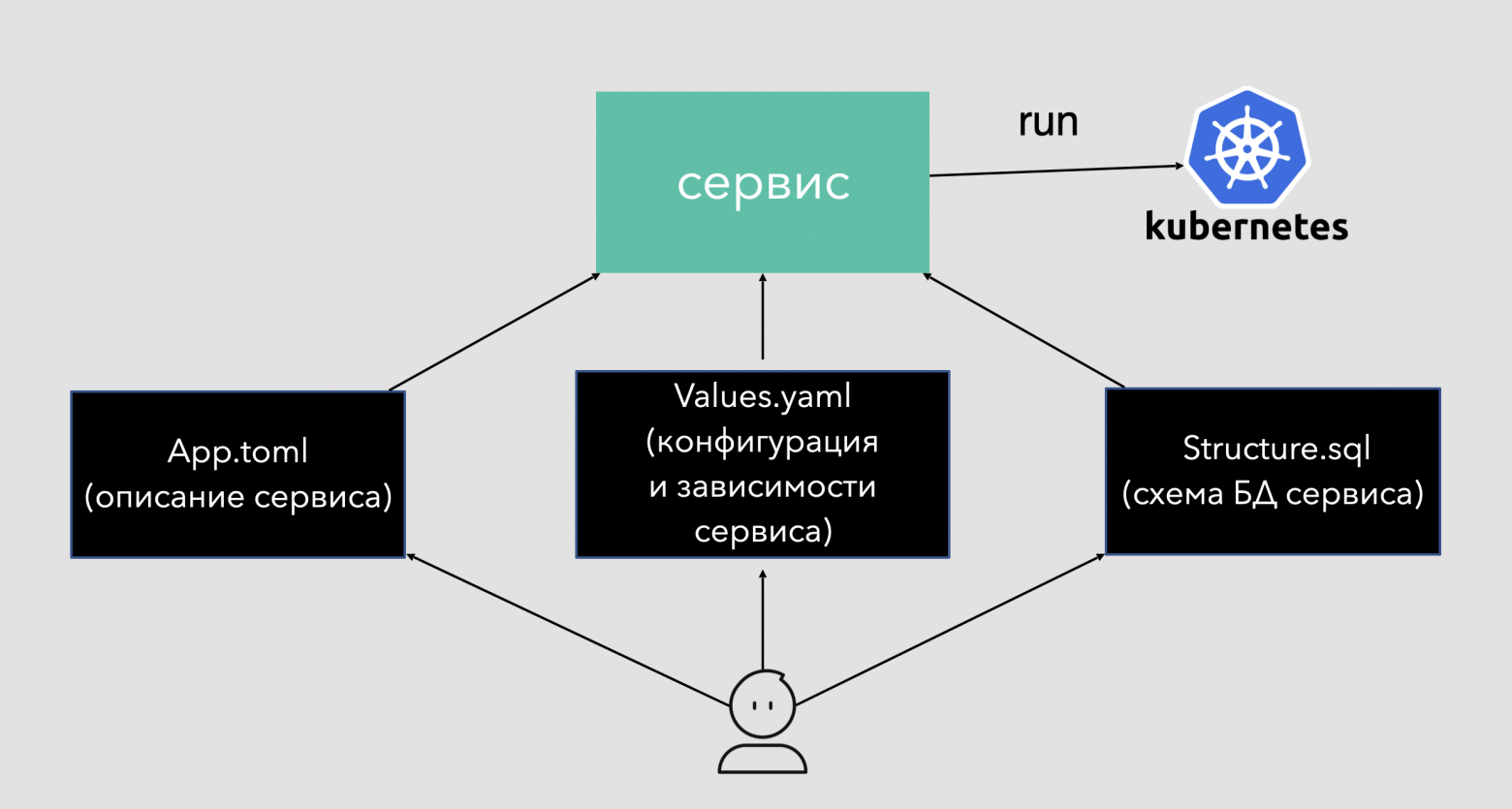
Какие метаданные есть у сервиса
В нашей системе PaaS чтобы сервис развернулся и запустился, разработчик должен заполнить 2 файла:
App.toml — это, можно сказать, паспорт сервиса, в нем описывается вся ключевая информация:
название;
описание (что делает, за что отвечает);
технологии, на которых сервис реализован;
ссылка на GitLab репозиторий с исходным кодом;
данные о команде, которая поддерживает сервис.
Из App.toml файла мы будем брать данные для описания Container (сервиса) на Container diagram. Из него мы возьмем «Название» и «Описание».

Структура App.toml
Values.yaml — это файл, из которого сервис берет конфигурации для подключения к базам данных, топикам Kafka, обращения к другим сервисам. Анализируя этот файл, можно понять:
в какие сервисы наш сервис обращается;
в какие топики он отправляет данные;
из каких топиков данные получает;
какие базы данных у сервиса;
в какие API Gateway выставляет свои API.
То есть в Values.yaml хранятся все зависимости сервиса, из него мы их возмем для отрисовки интеграций между сервисами в Container diagram.

Зависимости, которые отражены в Values.yaml
Structure.sql — это схема баз данных сервиса. Анализируя её, мы можем понять, из каких таблиц и каких полей в этих таблицах состоит БД. Этот файл никак не используется при развертывании, но его можно создавать из миграций при каждой сборки сервиса, а значит что он отражает реальную структуру БД сервиса. Считав и преобразовав данный файл, мы сможем построить ER diagram в нотации UML.

Structure.sql как структура баз данных
Почему этим файлам можно доверять?
Как уже говорилось выше, при развертывании сервиса в Production он опирается на файлы Values.yaml и App.toml. Если, например в Values.yaml, не указана какая-то зависимость, то в проде этой зависимости у сервиса не будет. И наоборот: если сервис в Values.yaml укажет какую-то зависимость, то в проде он ее получит.
А значит, что эти файлы содержат 100% достоверную информацию — поэтому если мы опираемся на них как на данные при генерации схемы, то мы получаем по-настоящему актуальную архитектурную схему, которая отображает сервисы и их зависимости.
Какие схемы мы будем генерировать?
Для решения нашей задачи нам хватит двух схем, на них мы и сконцентрируемся:
Container diagram, которая показывает зависимости сервиса;
ER diagram, которая показывает структуру его БД.
Остальные схемы тоже можно сгенерировать, но это требует анализа кода, что пока находится за рамками текущей задачи.
#3 Генерация схем. Как это происходит?
Разберём процесс на примере. Допустим, в одном сервисе произошли изменения. Вот что происходит дальше:
Разработчики вносят настройки и описания сервиса в файлы Values.yaml и App.toml. Structure.sql генерируется автоматически из миграций.
Изменения фиксируются в GitLab репозитории сервиса.
Сервис собирается и развертывается в проде. Там самым мы убеждаемся, что файлы заполнены корректно и с ними все в порядке. Если в них ошибка, то сервис просто не развернется, либо будет ошибка во время его работы.
Далее начинается процесс генерации схемы. Он состоит из двух этапов:
Получение данных о сервисах. Cпециальный микросервис Architect каждый день в 10:00 утра по Москве опрашивает GitLab репозитории всех сервисов компании, считывает Values.yaml, App.tom и Structure.sql файлы и помещает их к себе в базу данных.

Как происходит генерация схем
Происходит обработка полученных данных и генерация схем.
После получения данных обо всех сервисах запускается логика обработки данных файлов и они преобразуются в объекты. Верхний уровень иерархии —это сам сервис. В нем могут быть вложенные объекты (БД, S3, синхронные/асинхронные зависимости и т.п).
Затем алгоритм анализируя объекты сервисов генерирует PlantUML код.
На последнем шаге с помощью библиотеки PlantUML код преобразуется в архитектурную схему в виде SVG картинки. Она сохраняется в базе данных микросервиса Architect.
Frontend обращаясь по API к микросервису «Architect» и может получить как сам PlantUML код, так и архитектурную схему в виде SVG.

Алгоритм генерации
В итоге мы получаем 2 схемы:
Container diagram — на ней отражен сервис и его зависимости. Кроме того, мы видим, в какой gateway выставлен его API.
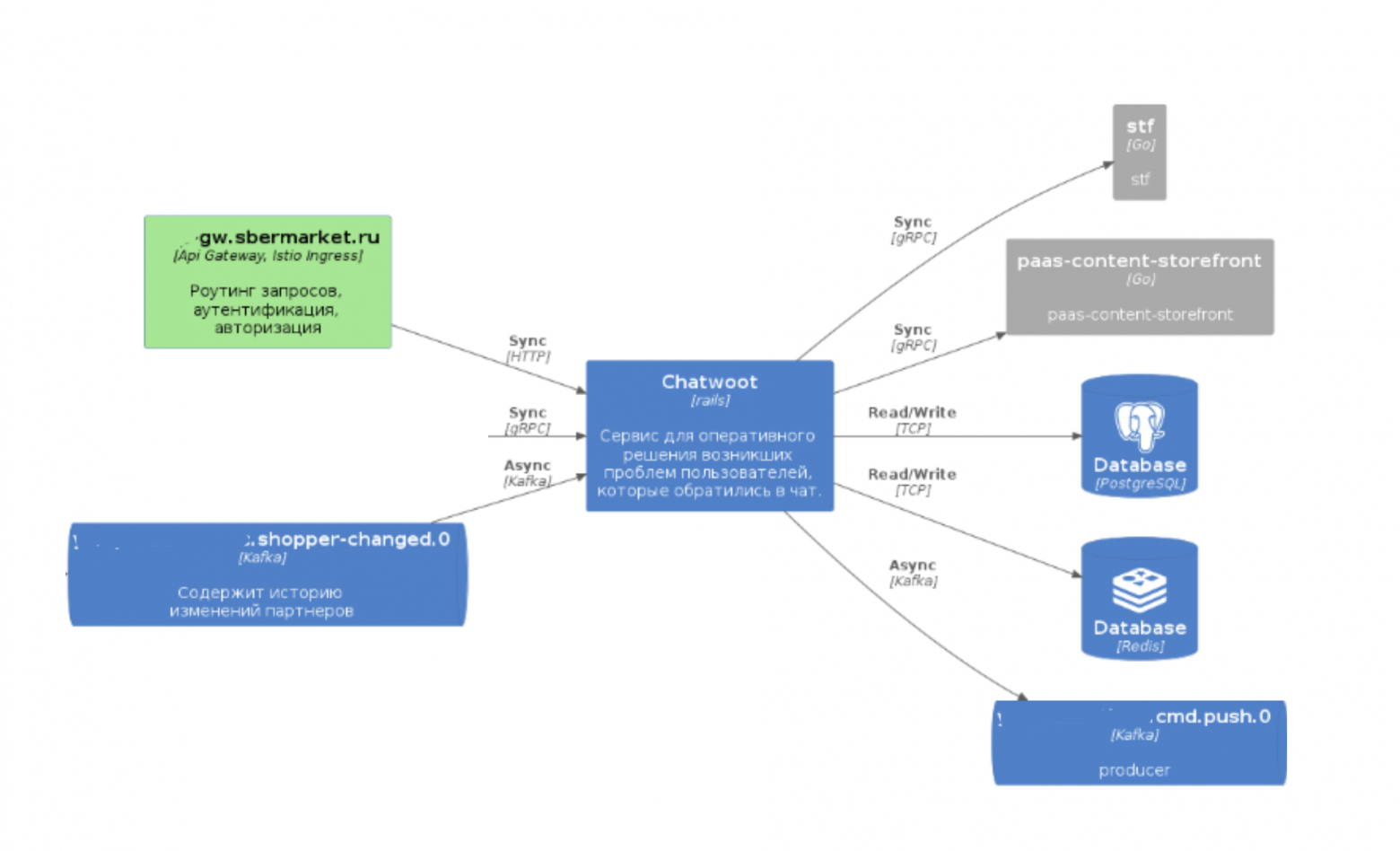
Container diagram
Однако здесь скрывается новая проблема. Мы не просто хотим видеть, в какие топики сервис пишет, и в какие ходит синхронно. Мы хотели бы получить информацию, кто пишет в топики, которые наш сервис читает. И если в наш сервис обращается другой сервис, то мы хотим видеть его на схеме. Без этой информации схема будет неполной, и нам нужно решить эту проблему.
ER diagram — на ней отражена структура БД сервиса. Здесь мы сразу плучаем всё, что нужно.

ER-диаграмма
#4 Обогащение схемы. Как происходит магия?
Можно декомпозировать эту поблему на несколько кейсов:
На схеме показано в какие сервисы сервис обращается синхронно, но не отражено какие сервисы обращаются в него.
На схеме есть топики Kafka, в которые сервис стримит данные, но нет информации о том какие сервисы из них читают.
На схеме есть топики Kafka, из которых сервис получает данные, но нет информации кто в них стримит.
Эти проблемы связаны с тем что в файле Values.yaml есть информация только об исходящих синхронных зависимостях, но нет информации о входящих. Также в файле есть информация о топиках, из которых сервис читает и в которые пишет, но нет информации о том какие сервисы связаны с этими топиками.
Итак, как нам понять, что конкретный сервис входящую синхронную интеграцию с другим сервисом? Это происходит на этапе, который на рисунке ниже подсвечен красным.
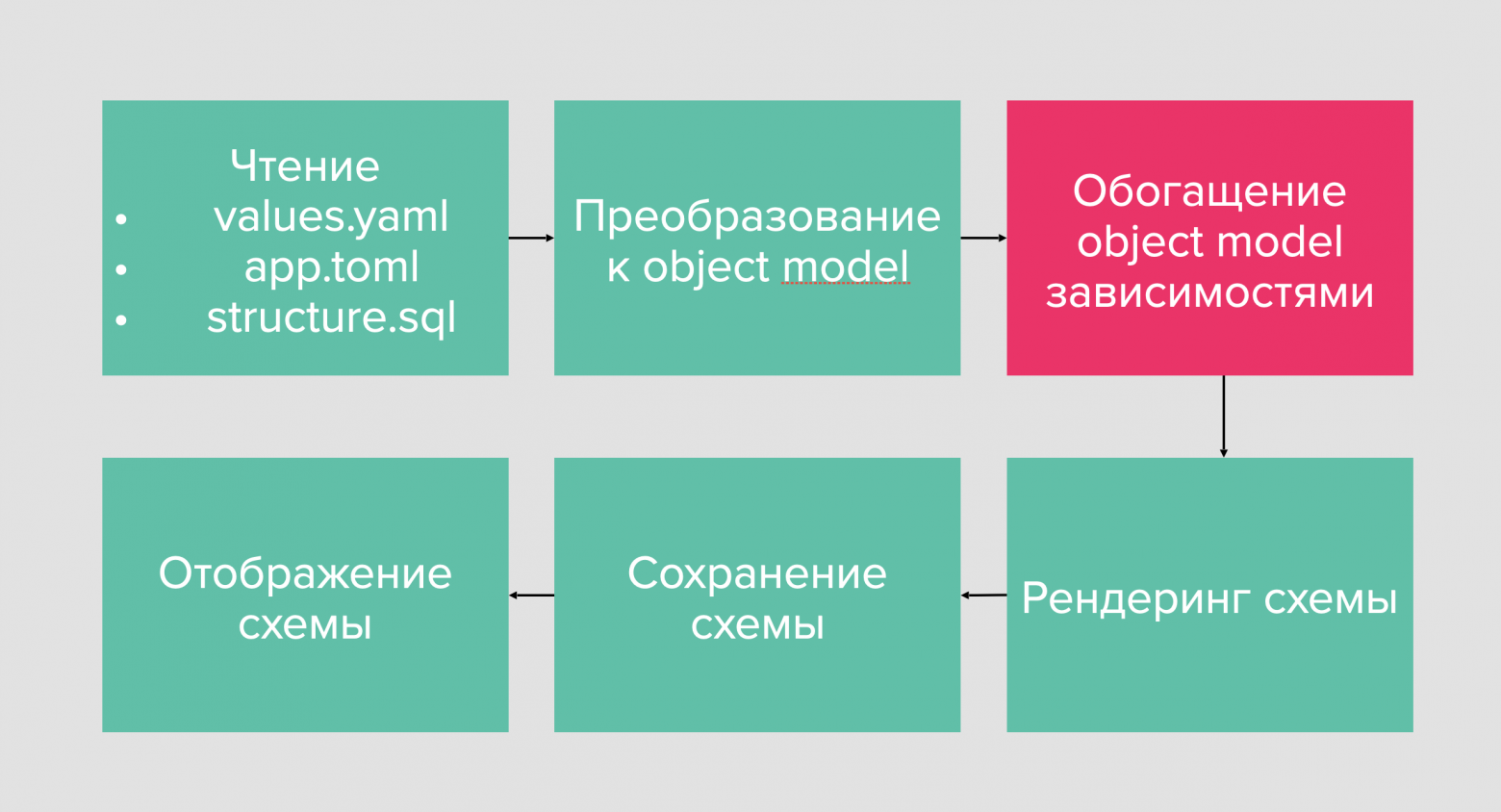
Этап, на котором происходит магия
Каждый сервис в Architect App — это объект. Внутри каждого объекта описаны его зависимости от топиков Kafka, БД и от других сервисов. И теперь, просто сделав матрицу пересечения этих объектов, мы можем понять, всё, что нам нужно. Таким образом происходит некоторое обогащение этих объектных моделей из других сервисов. А затем при рендеринге на схеме все сервисы отрисовываются с учетом всех зависимостей, которых ранее не хватало.

Обогащенная контейнерная диаграмма
Итак, мы решили четвертую проблему и реализовали алгоритм генерации метаданных.
Результат — 100% актуальные схемы
Развертывание сервисов в продакшен и построение архитектурных схем теперь опирается на одни и те же метаданные. Так схема всегда соответствует действительности.
Как применить наш подход
Напоследок оставляю небольшой список советов на случай, если вы захотите применить такой же подход у себя.
Изучите демо-репозиторий Plant Uml.
Начните описывать архитектуру с помощью любого движка: например, Plant Uml или Mermaid.
Постарайтесь хранить метаданные ваших систем в GitLab.
Используйте метаданные сервисов как для конфигурирования Production, так и для построения схем.
Собирайте с помощью специального алгоритма метаданные о сервисах и создавайте схемы ваших систем.
Буду рад ответить на вопросы в комментариях!
Tech-команда СберМаркета ведет соцсети с новостями и анонсами. Если хочешь узнать, что под капотом высоконагруженного e-commerce, следи за нами в Telegram и на YouTube. А также слушай подкаст «Для tech и этих» от наших it-менеджеров.
