Информационная архитектура и технология DITA. По мотивам лекции в Яндексе
Darwin Information Typing Architecture (DITA) — XML-технология для автоматизации процессов, связанных с технической документацией. За время существования DITA накопилось большое количество разнообразных возможностей, подходов к организации контента, а также конкретных механизмов их реализации. Запутаться в них немудрено, и это часто приводит к появлению непонятных, неэффективных и просто неудобных решений по автоматизации документирования. Директор по проектам компании «Философт» Михаил Острогорский раскладывает всё по полочкам.
Предисловие
Предлагаемая статья написана по мотивам небольшого доклада, сделанного автором на одном из «Гипербатонов», которые время от времени бывают в Яндексе. Не то что бы я был слишком недоволен собой как оратором, но в этом случае публиковать дословную расшифровку устной речи — не лучшая идея, на мой взгляд.
Во-первых, текст на техническую тему требует определенного оформления. В нем нужны списки, таблицы, схемы, фрагменты кода. Но говорить таблицами я не умею, а листинги плохо умещаются на слайды. Во-вторых, за два месяца я успел подготовить пример, который неплохо иллюстрирует материал доклада, и было бы странно не воспользоваться им теперь. Поэтому я прошу расценивать эту статью как важное и довольно объемное дополнение к устному докладу, а не как его переделанную расшифровку.
В заключение я горячо благодарю коллег из Яндекса за возможность обратиться к столь широкой аудитории не только устно, но и письменно. Надеюсь, эти материалы принесут пользу заинтересованным специалистам и техническим руководителям.
Инструменты и задачи. Нет, наоборот
Создатели технологии DITA снабдили ее обширным репертуаром функциональных возможностей. Технически эти возможности реализованы в языке разметки DITA и в пакете программ DITA Open Toolkit, который предназначен для преобразования входного материала (так я дальше буду называть контент) в тот или иной человекочитаемый формат. Кроме того, эти возможности лучше или хуже поддерживаются сторонними программными продуктами. Такая поддержка особенно нужна в XML-редакторах и в системах управления контентом, поэтому сегодня вы обнаружите ее в каждом мало-мальски развитом программном продукте такого класса.
Казалось бы, обилие функциональных возможностей — очевидное достоинство всякой технологии. Однако, оставшись с ним наедине, мы попадаем в положение человека, впервые приглашенного на званый ужин в дорогой ресторан. Незнакомые блюда, много разных и одновременно схожих вилок и ножей. Что чем есть, непонятно.

Кстати о ресторанах. Столы в них обычно сервируют согласно очередности блюд. Поданное в самом начале едим внешней парой приборов, следующее — той, которая в нее вложена, и т. д. Непонятно только, что делать с приборами, которые положили за тарелкой. Поэтому, осваивая нетривиальную технологию, лучше все-таки отталкиваться от задач, а не от инструментов. Сначала изучим меню «обеда» и разберемся в том, что представляет собой каждое из «блюд», затем научимся браться за подходящие вилки с нужного конца.
Понятие информационной архитектуры
Технология DITA несет в себе ряд функциональных возможностей, предназначенных для сборки выходных документов из многочисленных блоков исходного материала. Но на пользу они идут только в том случае, если эти блоки удачно выделены и правильно связаны между собой.
Несмотря на уникальность каждого документационного проекта структурные проблемы, которые авторы вынуждены решать при его ведении, в основном хорошо известны. Последнее позволяет сделать такую декомпозицию материала, чтобы решение этих проблем хорошо поддавалось автоматизации.
Под информационной архитектурой понимается выбранный для конкретного проекта или продукта способ декомпозиции материала. Разумеется, эта декомпозиция должна быть сделана в расчете на возможности сборки, предусмотренные применяемой технологией. Здесь мы сосредоточимся на технологии DITA, но для любой другой технологии этот принцип останется неизменным.
Унификация изложения материала
Значительная часть структурных проблем, решение которых должна обеспечить информационная архитектура, связана с повторами одного и того же текста в разных документах или даже внутри одного документа. Такие повторы обусловлены культурными традициями и особенностями восприятия человека, поэтому отказаться от них не представляется возможным.
При подготовке документации вручную за повторы приходится платить высокую цену:
- повышается нагрузка на авторов, возрастают трудозатраты;
- при обновлении документации в ней накапливаются ошибки.
Ошибки возникают из-за того, что внесение любого изменения в неуникальный текст ведет к полной проверке всего материала и аналогичной правке каждого повтора. При достаточном объеме материала эту операцию практически невозможно выполнить с необходимой аккуратностью.
Кроме того, если документацию разрабатывает группа авторов, каждый из них, будучи предоставлен сам себе, практикует собственные способы изложения материала. Из-за этого изложение в целом получается неунифицированным, что также приходится считать ошибкой. Даже если в каждом отдельном случае информация передана правильно, разнобой (структурный, стилистический, терминологический) может сбить читателя с толку и подтолкнуть его к неверным действиям.
Таким образом, одна из основных задач, на решение которых должна быть нацелена информационная архитектура, состоит в том, чтобы обеспечить необходимые повторы в выходных документах, но устранить их в том материале, с которым работают авторы.
Топики, карты документов, включающие ссылки
Проиллюстрируем сформулированный выше принцип упрощенным примером (табл. 1). Заодно познакомимся с основными элементами любой информационной архитектуры: топиками, картами документов и включающими ссылками. Они присущи не только технологии DITA, но и любой современной технологии автоматизации документирования.
Таблица 1. Упрощенный пример построения информационной архитектуры
| Характер повтора | Вред от повтора | Архитектурное решение | Отдача |
| Разные документы могут включать в себя одни и те же разделы | Если какой-нибудь раздел изменится, то придется вносить изменения всюду с риском пропустить нужное | Каждый документ, входящий в комплект, состоит из небольших разделов, объединенных оглавлением | Автор исправил раздел однократно, а изменения отразились во всех документах. — Сэкономили время. — Исключили ошибки |
| Разные разделы могут содержать одни и те же фрагменты текста, например, типовые врезки по безопасности | Если какой-нибудь фрагмент изменится, то придется вносить изменения всюду с риском пропустить нужное | Каждый типовой фрагмент выносим в отдельный файл. В разделах оставляем только включающие ссылки на него | Автор исправил фрагмент однократно, а изменения отразились во всех документах. — Сэкономили время. — Исключили ошибки |
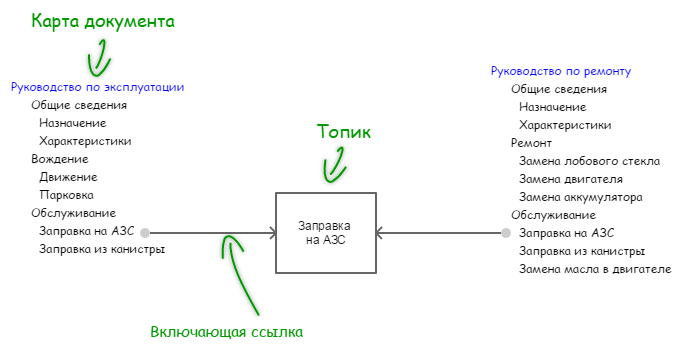
На рис. 1 показано многократное использование раздела. (В англоязычной литературе часто используют термин reuse, но мне не хотелось бы обогащать русский язык словом «переиспользование»).
Разделы, используемые многократно, принято называть топиками. Древовидную структуру (по сути, пустое оглавление), применяемое для объединения топиков в документ, будем называть картой этого документа.
Рисунок 1. Многократное использование топика
Объем топика должен быть по возможности небольшим.
Топик должен касаться какой-нибудь одной темы, имеющий четкие границы. Например, топик может раскрывать смысл того или иного понятия, описывать какую-то процедуру, содержать один набор справочных данных и т. п.
Содержание и стилистика топика должны быть такими, чтобы обеспечивать его относительную обособленность от остальных топиков. Топик должен быть, насколько это возможно, понятен сам по себе, как статья в энциклопедии или хороший ответ на заданный вопрос. В противном случае авторам придется вручную исправлять этот топик всякий раз при его включении в новый контект.
На рис. 2 показан более глубокий уровень информационной архитектуры. На этом уровне декомпозиции подвергаются уже не документы, а топики.
Рисунок 2. Многократное использование врезки
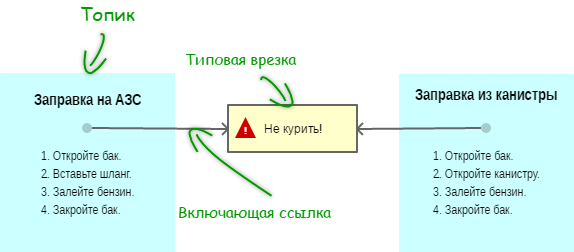
Разделение авторского труда
Информационная архитектура пойдет впрок лишь при соблюдении следующих условий.
Повсеместность. Необходимо строго придерживаться принятых решений по архитектуре, следовать им систематически, а не от случая к случаю. Если используются топики, то нужно поделить на них весь материал; если существуют типовые врезки, то все они должны быть вынесены из топиков и собраны в некоторую библиотеку и т. д.
Коллективность. Как правило, крупные комплекты документации создаются силами нескольких авторов. Информационная архитектура обеспечивает возможность добиться эффективного разделения труда внутри коллектива. Например:
— специалисты по технической безопасности или юристы могут составлять библиотеки врезок, текст которых будет тщательно выверен;
— авторы, которые хорошо разобрались в отельных частных вопросах, могут писать посвященные им топики;
— редактор, который видит задачу целиком, может составлять карты документов и обеспечивать выпуск всего комплекта документации.
Сквозной пример
Дальнейшее рассмотрение приемов построения информационной архитектуры, а также функциональных возможностей технологии DITA, которые делают применение этих приемов возможными, опирается на один сквозной пример.
Фабула примера такова. Представим себе, что нам необходимо наладить выпуск технической документации на электромобили. Сейчас у нас есть две модели электромобиля, но их количество может в дальнейшем увеличиваться.
| Все названия вымышлены, все совпадения случайны |
Описание каждой части примера сделано по следующему принципу:
— требования к выходным документам;
— требования к реализации;
— архитектурное решение;
— реализация средствами DITA.
Полный комплект исходных текстов сквозного примера доступен у меня в блоге.
Компоновка выходных документов из топиков
Требования к выходным документам
В комплект технической документации на каждую модель входят следующие документы:
— руководство по эксплуатации;
— рекламный буклет.
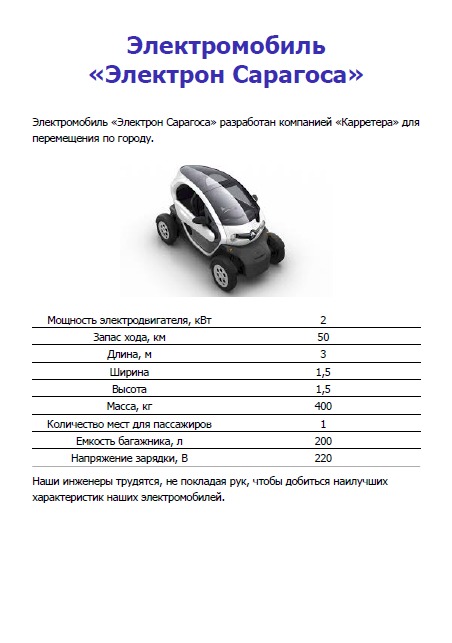
Руководство по эксплуатации описывает модель целиком. Рекламный буклет содержит только общие сведения о ней.
Рисунок 3. Руководство по эксплуатации (содержание) и рекламный буклет

Требования к реализации
Повторение одного и того же текста в проекте (в исходном материале, а не в выходных документах) должно быть сведено к минимуму.
Архитектурное решение
Здесь применяется решение, стандартное для технологии DITA. Оно уже было описано выше. Тем не менее, расскажем о нем еще раз и добавим несколько важных деталей.
Весь материал документации будет представлен в виде набора топиков. Для хранения топиков будем использовать структуру папок в файловой системе.
Каждому выходному документу сопоставим свою карту. Карта документа содержит его структуру, т. е. последовательность всех его разделов с учетом их вложенности. Привязка топика к разделу структуры документа осуществляется с помощью включающей ссылки. Включающая ссылка должна быть определена в карте документа, она указывает на топик, сопоставляемый разделу структуры документа (не наоборот).
Несмотря на техническую возможность использовать одну и ту же карту для формирования разных выходных документов (например, с помощью профилирования, см. ниже), так поступать не рекомендуется. При разрастании проекта, например, при увеличении количества моделей, подобный подход может привести к чересчур запутанной структуре, в которой невозможно будет разобраться. Старайтесь придерживаться простого правила: одна карта — один выходной документ. Хотя и тут, как будет показано ниже, возникают свои издержки.
Предложенное решение выглядит и является банальным. Небанальные решения проявятся в ходе дальнейшей декомпозиции материала проекта.
Реализация средствами DITA
Пример карты документа (в данном случае это рекламный буклет на модель «Сарагоса») приведен ниже.
Использование выносных карт и ссылок на ключи будет рассмотрено в следующих разделах статьи.
Для формирования выходных документов используется пакет DITA Open Toolkit в сочетании с входящим в его состав плагином DITA2PDF2, каковой отвечает за формирование выходных документов в формате PDF.
Поскольку рекламный буклет имеет нестандартное оформление, для него подготовлена так называемся кастомизация. Она представляет собой набор XSLT-стилей, которые изменяют стандартное поведение плагина DITA2PDF2. Эта кастомизация входит в состав сквозного примера.
Вынесение типового текста в библиотеку
Требования к выходным документам
По условию нашей воображаемой задачи, каждая процедура, описывающая тот или иной сценарий использования электромобиля, должна начинаться (не обязательно с самого начала) типовой врезкой. Эта врезка содержит замечание, касающиеся безопасности водителя, а также ссылку на раздел «Безопасность» (рис. 4).
Каждая процедура, описывающая тот или иной сценарий обслуживания электромобиля, тоже должна начинаться типовой врезкой, но немного другой. Позднее в проекте могут потребоваться и другие типовые врезки.
Рисунок 4. Использование типовых врезок

Требования к реализации
Все комплекты документации должны быть устойчивы к изменению текста типовой врезки. Если в текст типовой врезки внесены изменения (например, сделана литературная правка или учтены требования новых нормативно-технических документов), то они должны одинаково отразиться во всех руководствах по эксплуатации.
Архитектурное решение
Создадим библиотеку типового текста. Она будет представлять собой один файл в формате DITA. В этом файле будем хранить все фрагменты типового текста. Ведение библиотеки типового текста поручим одному из авторов, который особенно хорошо разбирается в нормативной базе по технической безопасности.
Реализация средствами DITA
Пример представления врезки в библиотеке типового текста приведен ниже. Для идентификации типовой врезки используется атрибут @ id. Его значение должно быть уникальным, по крайней мере, в пределах библиотечного файла.
Электромобиль — современное экологически чистое транспортное
средство повышенной опасности. Перед использованием электромобиля
ознакомьтесь с разделом «Безопасность».
Электромобиль — современный технически сложный подвижной электромеханический
прибор. Перед обслуживанием электромобиля ознакомьтесь с разделом
«Безопасность».
Пример включающей ссылки из топика на типовую врезку приведен ниже. Для указания на типовую врезку используется атрибут @conref.
Параметризация текста
Требования к выходным документам
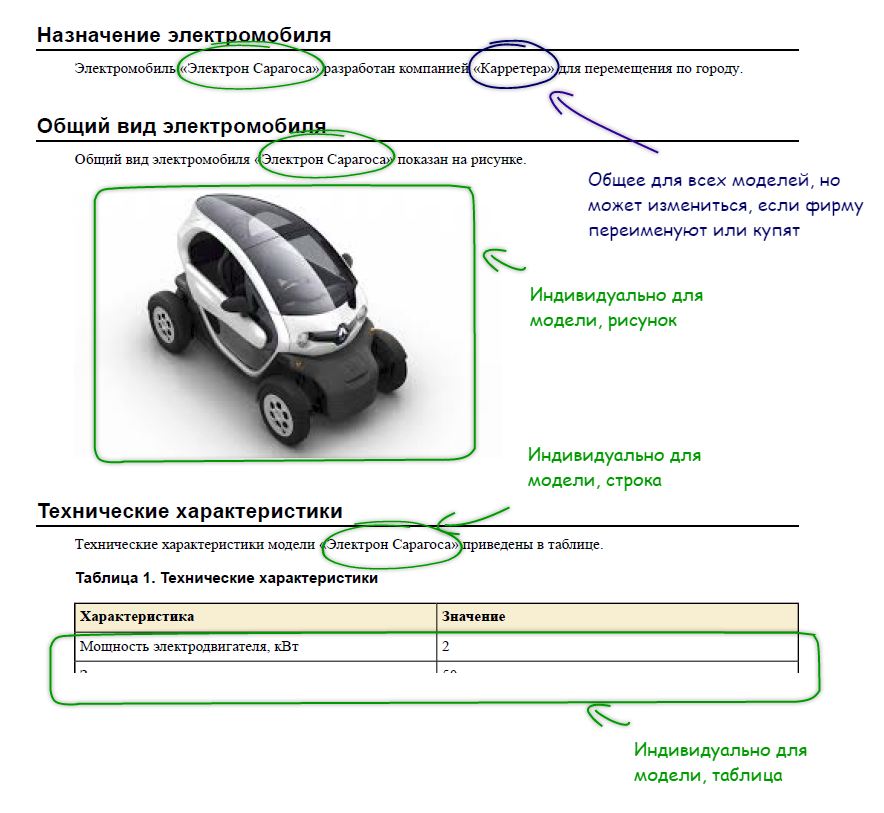
В тексте топиков могут располагаться относительно короткие строковые значения, например, наименование компании, наименование линейки продуктов, наименование конкретной модели (рис. 5). В программной документации такими значениями часто становятся номер версии программного продукта, название аппаратной платформы, версия операционной системы, наименование заказчика и т. п.
Рисунок 5. Параметризация текста и его адаптация к контексту
Если такие строки оказываются в тексте, который иначе был бы во всех документах одинаковым, возникает искушение как-нибудь от них избавиться, а топики сделать общими для всех выходных документов. Например, можно вместо наименования продукта употреблять перифрастическое название изделие, вместо непосредственного названия компании слово разработчик или компания и т. д.
Идея хорошая, но работает она не всегда.
Во-первых, играют роль маркетинговые соображения, да и все равно где-то в документе придется хотя бы один раз указать оригинальные названия явно.
Во-вторых, короткие строки — не обязательно названия. Это могут быть значения каких-нибудь важных параметров, технические ограничения, сетевые адреса, номера портов или другие данные, которые читатель предпочел бы увидеть здесь же, а не искать их где-то в других частях документа.
Поэтому совсем избавиться от строковых значений невозможно. Считать же два текста разными только из-за того, что они отличаются друг от друга десятком-другим символов, и помещать их на этом основании в отдельные топики, согласитесь, обидно.
Требования к реализации
Если текст топика в целом одинаков для всех моделей, то в проекте должен существовать единственный экземпляр этого топика. Значения, которые могут изменяться время от времени или от модели к модели, должны при формировании выходных документов инкорпорироваться внутрь таких топиков автоматически.
Архитектурное решение
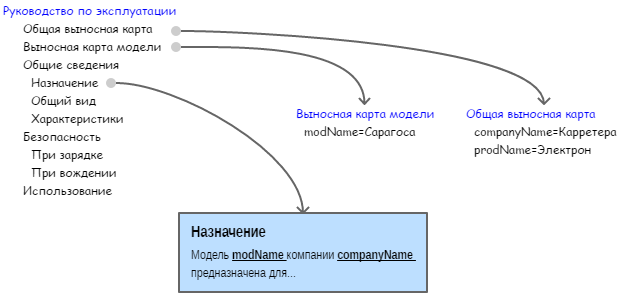
Значениям, которые одинаковы для всех моделей, но могут изменяться время от времени (фирма, вся линейка продуктов), будем присваивать имена и задавать в общей выносной карте. Общая выносная карта будет существовать в единственном экземпляре для всего проекта. Общую выносную карту включим в карту каждого документа в проекте.
Значеним, которые изменяются от модели к модели (например, наименование модели), будем присваивать имена и задавать в выносной карте модели. Выносная карта модели будет существовать в единственном экземпляре для каждой модели. Выносную карту модели включим в карту каждого документа, относящегося к этой модели.
В технологии DITA именованные значения называются ключами.
В тексте топика будем использовать не сами значения, а ссылки на имена ключей. При формировании выходного документа каждая ссылка на имя ключа будут автоматически заменена актуальным значениям этого ключа, заданным в выносной карте (рис. 6).
Рисунок 6. Параметризация текста топика с помощью ключей и выносных карт
Реализация средствами DITA
Пример определения ключа в выносной карте модели показан ниже. В общей выносной карте для определения ключа используется такой же синтаксис.
Сарагоса
Примеры включающих ссылок из карты документа на выносные карты показаны ниже.
Пример ссылки на имя ключа в тексте топика показан ниже. При формировании выходного документа в текст будут вставлены наименование линейки продуктов и наименование модели. Ссылка на имя ключа представлена элементом keyword. Имя ключа указано в атрибуте @keyref.
Технические характеристики модели «
Адаптация общего текста к контексту
Требования к выходным документам
В тексте топиков могут фигурировать не только строковые значения, но и более сложные конструкции. Так, на рис. 5 кроме строковых значений показаны еще рисунок и таблица. Они относятся к определенной модели электромобиля, но инкорпорированы в топик, который является общим для всех моделей.
Требования к реализации
Если текст топика в целом одинаков для всех моделей, то он должен быть общим. Иначе говоря, в проекте должен существовать единственный экземпляр этого топика, а карты всех документов при необходимости должны содержать включающие ссылки на него.
Фрагменты, которые могут изменяться время от времени или от модели к модели, должны быть инкорпорированы внутрь общих топиков автоматически при формировании выходных документов.
Архитектурное решение
Решить эту задачу с помощью параметризации ключами невозможно, поскольку рисунки и таблицы не сводятся к строковым значениям. Для их представления нужна полноценная XML-разметка. Вставка таких фрагментов внутрь общего текста делается с помощью косвенных включающих ссылок.
Фрагменты XML-разметки, инкорпорируемые в общие топики, будем называть подстановочными.
Соберем все подстановочные фрагменты, относящиеся к определенной модели, в один файл. Будем называть этот файл библиотекой модели по аналогии с библиотекой типового текста. Да это и есть библиотека типового текста, только относящегося к определенной модели, а не к проекту в целом.
Для указания на библиотеку модели определим в выносной карте модели специальный ключ. Значением этого ключа будет путь к библиотеке модели.
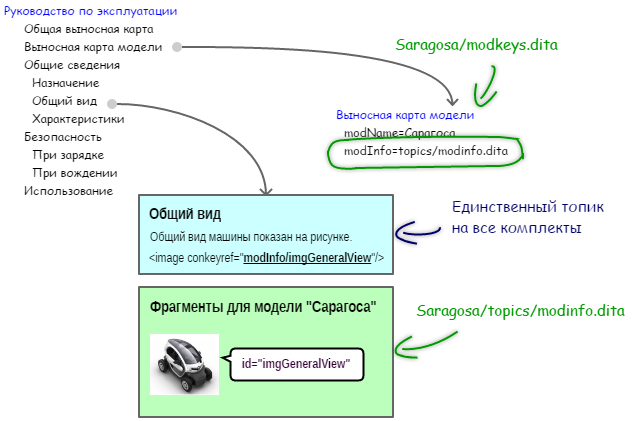
Включающую ссылку из общего топика на нужный подстановочный фрагмент образуем из имени этого ключа и уникального идентификатора этого подстановочного фрагмента в библиотеке модели (рис. 7).
Рисунок 7. Косвенная включающая ссылка из общего топика на подстановочный фрагмент
Реализация средствами DITA
Ниже приведен пример того, как в выносной карте модели задан ключ, указывающий на файл библиотеки этой модели. Для указания на файл, в котором размещены подстановочные фрагменты, используется атрибут href.
Пример косвенной включающей ссылки из текста топика на подстановочный фрагмент показан ниже. Элемент image целиком представляет собой косвенную включающую ссылку. При формировании выходного документа он будет полностью заменен подстановочным фрагментом, на который эта косвенная включающая ссылка указывает. Для указания на подстановочный фрагмент используется атрибут @conkeyref. Его значение составлено из имени ключа (в примере modInfo) и значения атрибута @ id нужного подстановочного фрагмента (в примере imgGeneralView). Эти две части значения атрибута @conkeyref набраны через косую черту.
Фильтрация текста
Требования к выходным документам
Теперь научимся не добавлять текст в топики, а выбрасывать его оттуда.
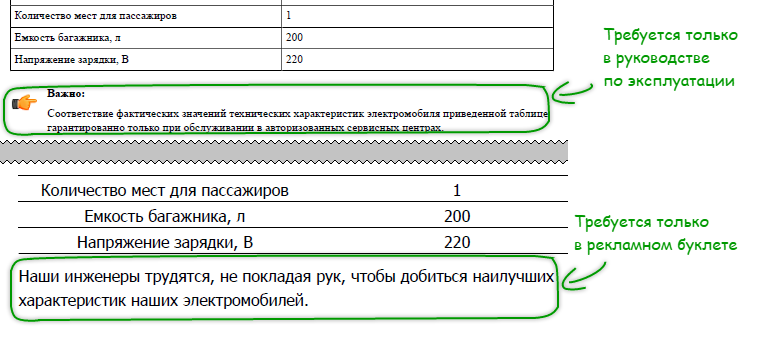
Случается так, что топик содержит всю необходимую информацию, однако, для каждого конкретного выходного документа она оказывается избыточной. Скажем, в топике «Технические характеристики» (напомню, это общий топик уровня проекта) за таблицей технических характеристик следуют такие врезки:
— указание о необходимость обслуживать электромобиль только в фирменном сервисном центре (иначе фирма не гарантирует заявленных параметров);
— рекламные славословия в адрес инженеров, разработавших настолько выдающуюся электрическую машину.
Первая врезка уместна в руководстве по эксплуатации, но невыгодно смотрится в рекламном буклете. Вторая врезка, напротив, нужна только в рекламном буклете, а в руководстве по эксплуатации она уже ни к чему. Потребуем, чтобы каждая из этих врезок отображалась только в том выходном документе, где она нужна (рис. 8).
Рисунок 8. Текст, обусловленный жанром выходного документа
Аналогично, общий топик может содержать фрагменты текста, имеющие отношение лишь к определенной модели (рис. 9).
Рисунок 9. Текст, обусловленный моделью изделия

Легко можно представить себе и другие зависимости, допустим, какие-то деликатные сведения должны входить в расширенную версию руководства для сервисных центров поддержки, но сообщать их д конечным пользователям нецелесообразно.
Требования к реализации
Если топик содержит не слишком многочисленные фрагменты, которые могут оказаться избыточными в том или ином контексте, причем каждый такой контекст можно описать небольшим количеством формальных признаков выходного документа, то к тексту этого топика должны применяться фильтры. Создание нескольких топиков, отличающихся друг от друга только такими фрагментами, не допускается.
Архитектурное решение
Если фрагмент должен быть включен в выходной документ или исключен из выходного документа при выполнении или невыполнении определенных условий, будем называть его условным. Каждый условный фрагмент будем снабжать метками, отражающими условия его включения в документ или исключения из документа.
При формировании выходного документа будем указывать, какие именно условия для него выполняются. Неподходящие условные фрагменты будут автоматически исключены из выходного документа.
Реализация средствами DITA
Для работы с условными фрагментами технология DITA предлагает развитый механизм профилирования. Он позволяет организовать фильтрацию условных фрагментов несколькими разными способами по нескольким атрибутам одновременно.
Спецификация DITA предусматривает несколько не имеющих собственной смысловой нагрузки атрибутов, которые авторы вольны использовать для профилирования, трактуя их значения любым способом, осмысленным в конкретном проекте.
Правила отбора условных фрагментов при профилировании действуют довольно гибко. В одних случаях удобнее оставлять в выходном документе только нейтральные фрагменты и явно подходящие условные фрагменты. В других случаях проще исключать из выходного документа явно неподходящие условные фрагменты.
В общем, главное в этом профилировании не запутаться. Не имея сил описать в небольшой (и без того уже слишком большой?) статье весь этот механизм целиком, приведем пример включения в выходной документ нейтральных и явно подходящих фрагментов.
Пример разметки исходного текста топика с учетом профилирования приведен ниже. Для указания на жанр документа используется атрибут @ props. Допустимые значения этого атрибута не заданы спецификацией DITA. Они выбраны при разработке информационной архитектуры и являются частью соглашения, принятого на уровне данного проекта.
Соответствие фактических значений технических характеристик
электромобиля приведенной таблице гарантированно только
при обслуживании в авторизованных сервисных центрах.
Наши инженеры трудятся, не покладая рук, чтобы добиться
наилучших характеристик наших электромобилей.
Чтобы профилирование состоялось, сборочному сценарию пакета DITA Open Toolkit при формировании выходного документа помимо всего прочего должен быть передан так называемый файл DITAVAL. В него должны быть внесены указания по включению в выходной документ или исключению из выходного документа условных фрагментов, имеющих те или иные значения профилирующих атрибутов. Пример такого файла приведен ниже.
Типизация и шаблонизация топиков
Требования к выходным документам
Один из основных методических и стилистических принципов написания технической документации гласит: подобное следует описывать подобно. Например, если мы описываем процедуры, выполняемые пользователем, мы всегда должны делать это по одному и тому же плану.
Дело не в том, что где-то существует самый правильный в мире план описания пользовательской процедуры. Конечно, нет, и вообще-то пользовательские процедуры можно описывать по-разному. Но в рамках одного проекта следует установить единый для всех авторов план описания пользовательской процедуры, и всем его придерживаться. Иначе начнется разнобой, а он весьма осложняет пользование документацией, поскольку вынуждает читателя постоянно гадать, значимы или случайны наблюдаемые им различия.
Требования к реализации
Разные авторы, участвующие в проекте (или один автор, участвующий в проекте достаточно долго) должны описывать однотипные явления или действия в единообразной манере.
Архитектурное решение
Классифицируем топики, распределив их по нескольким информационных типов. Набор информационных типов в общем случае определяется особенностями конкретного проекта. Существует устойчивая (и закрепленная в DITA) традиция начинать классификацию топиков с их деления на три базовых информационных типа:
— теоретические;
— процедурные;
— справочные.
Дальнейшая классификация может заключаться как в более глубокой специализации трех базовых информационных типов (например, будем различать пользовательские и монтажные процедуры), так и в создании принципиально новых.
Для каждого информационного типа выработаем типовую структуру. Типовой структурой могут быть продиктованы следующие особенности, обязательно присущие топику, который относится к этому информационному типу:
— набор рубрик, которые образуют внутреннюю структуру топика;
— последовательность и вложенность рубрик;
— обязательность заполнения некоторых рубрик;
— обязательное наличие в некоторых рубриках заданного для них типового текста.
При создании нового топика автор обязан сначала выбрать его информационный тип из перечня доступных в данном проекте. После создания топика автор получает не «чистый лист», а относительно жесткий шаблон, которому он обязан следовать при написании топика.
Реализация средствами DITA
Проблему унификации стиля часто пытаются решить с помощью стандартов и тренингов. Отчасти они помогают. Но технология DITA в отличие от многих других позволяет технически принудить авторов к единообразию. Для этого предусмотрены следующие возможности.
— Использование базовых информационных типов DITA: topic, concept, task, reference, troubleshooting. Каждый информационный тип описан с помощью DTD и схемы. Если автор набирает текст топика в более или менее современном XML-редакторе (обычно так и бывает), то последний навязывает ему структуру, предусмотренную выбранным при создании этого топика информационным типом.
— Специализация базовых информационных типов, т.е. создание собственных DTD или схем топиков на основе встроенных.
Использование специализированных информационных типов может потребовать дополнительной настройки XML-редакторов и пакета DITA Open Toolkit.
В рассматриваемом сквозном примере применяется не специализация, а шаблонизация. Это «гибридный» способ навязывания авторам структуры топика. Он позволяет поместить авторов в более жесткие рамки, чем при использовании встроенных информационных типов в чистом виде, но менее трудоемок в реализации, чем полноценная специализация.
Ниже приведен пример исходного текста шаблона пользовательской процедуры. Создав новый топик на основе этого шаблона (если используемые им XML-редактор или система управления контентом это позволяют), автор получит новый топик с включающей ссылкой на типовую врезку по безопасности и с принятой в данном проекте титульной фразой перед описанием шагов процедуры.
Варка варенья
Для того чтобы сварить веренье:
Добрым словом и пистолетом
Вы все еще копи-пейстите?
Тогда мы идем к вам!
Как известно, добрым словом и пистолетом можно добиться намного большего, чем просто добрым словом. До сих пор мы обсуждали доброе слово, но обсудить пистолет тоже необходимо, хотя бы совсем кратко.
Под пистолетом я тут имею в виду язык XSLT (с XSLT-процессорами) и языки написания сценариев (с их runtime-средами).
Дело в том, что некоторые задачи, которые возникают при активном использовании технологии DITA, все еще приходится решать копированием ранее сделанного материала с его дальнейшей очень внимательной правкой вручную. Альтернатива этому позорному рукоделию — дополнительная автоматизация.
Одна из наиболее распространенных задач этого класса — постоянная разработка комплектов документации похожей структуры.
Представьте себе компанию, которая производит какие-нибудь сложные приборы. На каждый прибор она должно выпустить комплект документации по госту, причем в состав комплекта входит десяток документов. Структура документа для каждого жанра (руков
