Индексация рукописного текста в изображениях: от европейских языков к азиатским
 Автор: Евгений Лившиц, руководитель исследовательской группы в московском офисе Evernote
Автор: Евгений Лившиц, руководитель исследовательской группы в московском офисе Evernote
С учетом недавно добавленной поддержки китайского система распознавания Evernote (ENRS, Evernote Recognition System) сейчас индексирует рукописные заметки на 24 языках. Каждый раз, когда мы беремся за новый язык, перед нами встают новые задачи, связанные со спецификой конкретного алфавита и стиля письма.
Дополнительные сложности возникли, когда мы взялись за восточноазиатские языки: китайский, японский и корейский (CJK). Эти языки требуют поддержки на два порядка большего числа символов, при этом каждый из них значительно сложнее тех, с которыми мы имели дело раньше; пробелы между словами необязательны; при высоком темпе письма люди часто переходят на скоропись, что делает интерпретацию в значительной степени зависимой от контекста.
Прежде чем погружаться в специфику поддержки CJK, давайте быстро пройдемся по трудностям, которые нам пришлось преодолеть при распознавании рукописного текста на европейских языках. Наш движок распознавания начинает парсинг рукописной страницы с нахождения текстовых строк. Это уже может быть нетривиальной задачей. Рассмотрим такой пример:

Строки могут быть неровными, буквы из разных строк пересекаться друг с другом, а расстояние между строками изменяться в широком диапозоне. Алгоритм сегментации строк должен распутывать случайные пересечения траекторий соседних строк.
После того, как строки построены, перед нами встает следующая задача — как правильным образом разделить их на слова. Это, как правило, несложно для печатного текста, где относительно четко определена разница в расстоянии между буквами и между словами. В случае рукописного текста во многих случах нельзя просто по расстоянию между буквами определить, столкнулись ли мы с межсловным или внутрисловным пробелом.

Здесь может помочь понимание того, что написано в тексте. Затем, понимая слова, мы сможем определить, где у них начало, а где конец. Однако для этого требуется умение понимать строку целиком, а не просто читать одно слово за другим — как это обычно делает большинство движков распознавания текста. Для европейских языков задача распознавания рукописного текста зачастую ненамного проще, чем для азиатских текстов. Для примера приведем образец рукописного текста на корейском языке:

Аналогично нужно выделить линии текста, распутав возможные пересечения. При это ясно, что построение отдельного блока, занимающегося словной сегментацией, малореально. Как и в случае с европейским рукописным текстом, решением стало распознавание и сегментация в рамках единого алгоритма с помощью понимания распознанных слов и соответствующего определения их границ.
Теперь взглянем на процесс символьного распознавания. Прежде всего нам небходимо найти границы символов. Они могут проходить по маленьким пробелам между штрихами или по соединительным линиям характерным для быстрого письма. У нас нет надежного способа определения точек границ между символами, поэтому мы вынуждены выделять потенциальные точки межсимвольного деления с некоторым запасом (делаем oversegmentation). При этом на данном этапе у нас нет четкого понимания, находится ли та или иная потенциальная точка деления в правильном месте и разделяет символы, или попадает внутрь одного из них. В результате все строка распадается на маленькие блоки.
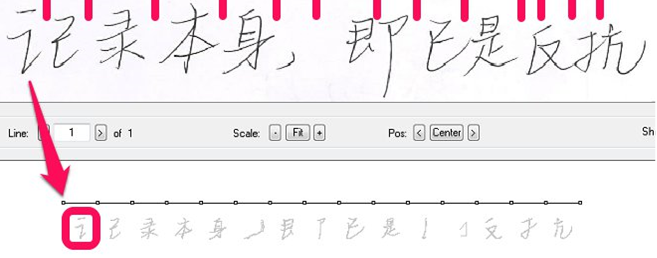
Чтобы собрать реальные символы, мы пробуем объединить эти маленькие блоки в блоки побольше, оценивая каждую такую комбинацию. На изображении ниже показана попытка распознать комбинацию первых двух блоков.

Конечно, это означает, что нам придется распознать гораздо больше вариантов символов, чем было написано на самом деле. И для языков CJK это в свою очередь означает, что процесс распознавания будет гораздо медленнее, чем для европейских языков, поскольку оценка различных комбинаций требует рассмотрения гораздо большего числа «кандидатов». Ядро нашей системы распознавания символов — это набор SVM-решателей (Support Vector Machine), каждый из которых решает задачу «один против всех» для назначенного ему символа.
И если для английского языка нам нужно около 50 таких решателей (все латинские буквы + символы), то для поддержки наиболее распространенных китайских иероглифов нам понадобилось бы уже 3 750! Это сделало бы процесс медленнее в 75 раз, если только мы бы не нашли способ запускать каждый раз только часть из всех этих решателей.
Чтобы сделать это, мы сначала запускаем набор значительно более простых и быстрых SVM, которые бы отобрали группу похожих по написанию символов. А стандартные SVM работают только на символах, найденных на первом этапе. Такой подход обычно позволяет нам задействовать только 5–6% от всего набора символов, что ускоряет процесс распознавания в целом примерно в 20 раз.
Чтобы решить, какие варианты из множества возможных интерпретаций написанных символов нужно выбрать для окончательного ответа, нам нужно обратиться к различным языковым моделям — это контекст, который бы позволил нам создать более осмысленную интерпретацию всех возможных вариантов, сгененированных SVM. Интерпретация начинается с простого взвешивания наиболее распространенных двухсимвольных комбинаций, затем уровень контекста расширяется до частых трехсимвольных последовательностей и далее к словам из словарей и знакомым структурированным моделям — даты, телефоны, адреса электронной почты. Далее идут вероятные комбинации предлагаемых слов и моделей. И без взвешивания всех возможностей мы не можем сказать наверняка, как лучше всего интерпретировать ту или иную строку. Только сравнительная оценка миллионов и миллионов возможных комбинаций, похожая на то, как Deep Blue анализировал множество шахматных позиций, играя против Каспарова, позволяет приблизиться к оптимальной интерпретации.
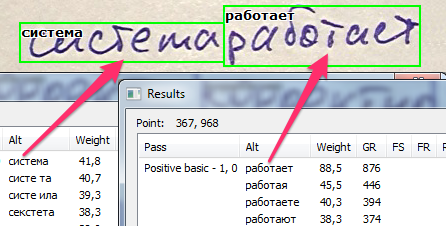
Как только лучшая интерпретация для строки представлена, мы, наконец, можем определить границы слов. Зеленые рамки на изображении ниже показывают лучший вариант разделения слов, из тех что удалось придумать.
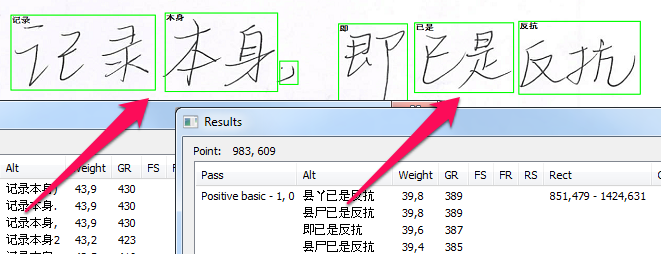
И, как видите, процесс получается во многом одинаковым как для европейских рукописных текстов, так и для CJK.
