Flaky tests
Что неприятнее «красного теста»? Тест, который то зелёный, то красный, и непонятно, почему. На нашей конференции Heisenbug 2017 Moscow Андрей Солнцев (Codeborne) рассказывал, из-за чего они могут возникать и как снижать их число. Примеры в его докладе такие, что прямо-таки кожей ощущаешь боль, возникавшую при столкновении с ними. А советы полезные — причём ознакомиться с ними стоит как тестировщикам, так и разработчикам. Есть и неожиданное: можно узнать, как порой можно разобраться в проблеме, если оторваться от экрана и поиграть с дочкой в кубики.
В итоге зрители высоко оценили доклад, и мы решили не просто опубликовать видеозапись, а ещё и сделать для Хабра текстовую версию доклада.
На мой взгляд, flaky-тесты — это самая актуальная тема в мире автоматизации. Потому что на вопрос «что вообще в мире делается, как у вас дела с автоматизацией?» все отвечают: «Стабильности нет! Падают наши тесты периодически».
Ты запустил у себя тест, он зелёный, ещё два дня зелёный, а потом раз и внезапно упал на Jenkins. Ты пытаешься это повторить, запускаешь, а он снова зелёный. И в итоге никогда не знаешь: это баг или это просто тест глюканул? И каждый раз надо разбираться.
Зачастую после ночного запуска тестов на Jenkins тестировщик сначала видит »30 тестов упало, надо изучить», но все знают, что происходит дальше…

Вы, конечно, догадались, какое неприличное слово замаскировано: «перезапущу». Мол, «сегодня неохота разбираться…» Вот так это обычно происходит, и это прямо беда.
Точной статистики нет, но я часто слышал от разных людей, что у них примерно 30% тестов — flaky. Грубо говоря, запускают тысячу, из них 300 периодически красные, и дальше руками проверяют, а на самом ли деле они упали.
Google пару лет выпустил статью: там сообщается, что у них 1,5% процента flaky-тестов, и рассказано, как они бьются за снижение их числа. Я могу чуть похвастаться и сказать, что в моём проекте в Codeborne сейчас 0,1%. Но на самом деле всё это плохо, даже 0,1%. Почему?
Возьмём 1,5%, это число кажется маленьким, но что оно значит на практике? Допустим, в проекте тысяча тестов. Это может значить, что в одном билде упало 15 тестов, в следующем 12, затем 18. И это ужасно плохо, потому что в этом случае почти все билды красные, и постоянно нужно проверять руками, правда это или нет.
И даже наш один промилле (0,1%) — всё равно плохо. Допустим, у нас 1000 тестов, тогда 0,1% означает, что регулярно один билд из десяти валится с 1–2 красными тестами. Вот реальная картина с нашего Jenkins, так и получается: при одном запуске упал один flaky-тест, при другом запуске другой.
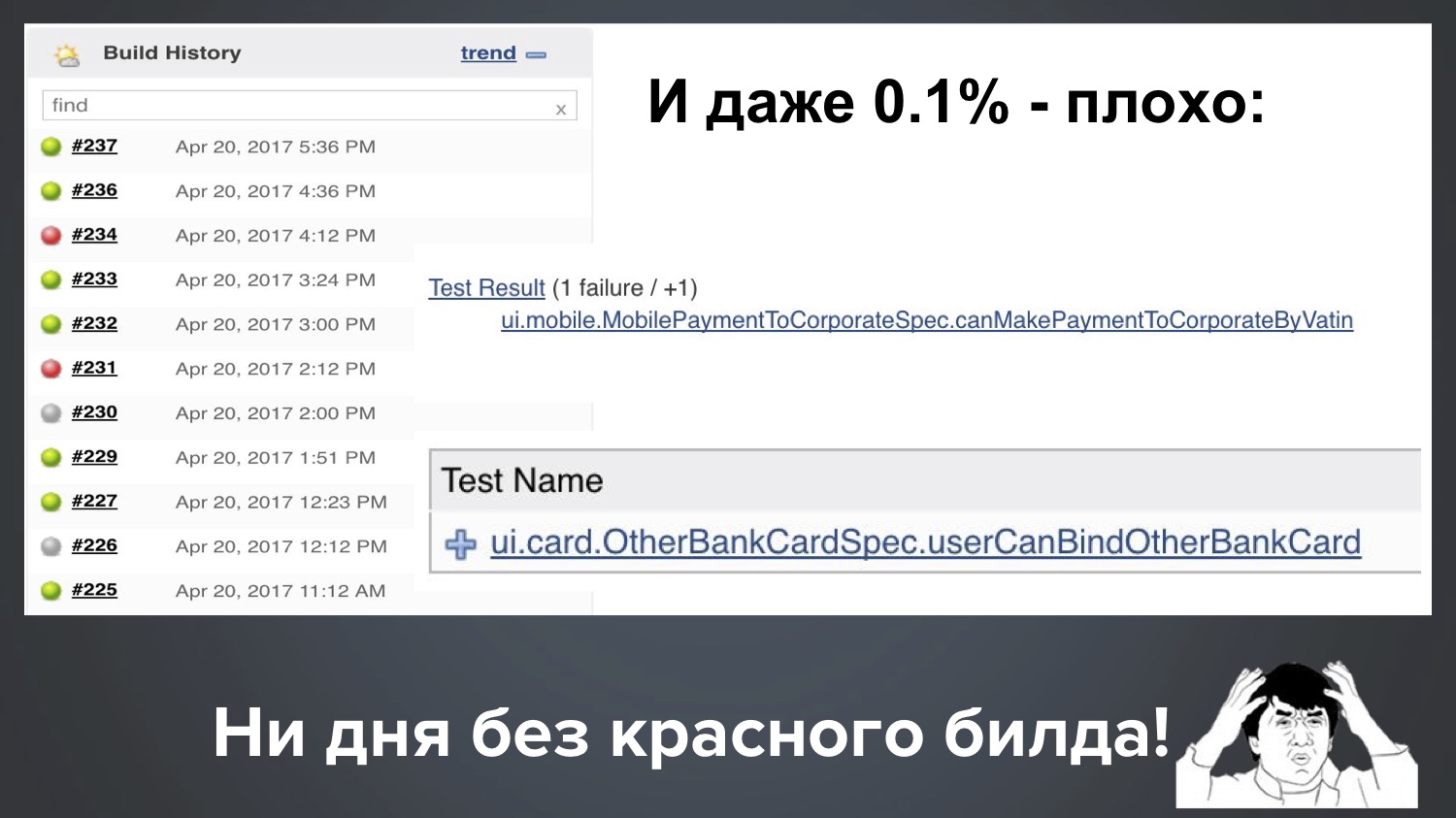
Получается, ни дня без красного билда у нас не проходит. Так как много зелёного, вроде бы всё хорошо, но клиент вправе спросить нас: «Ребята, мы вам платим деньги, а вы нам постоянно красноту поставляете! Что за дела?»
Я бы на месте клиента был недоволен, и объяснять «вообще-то по отрасли это нормально, у всех всё красное» нехорошо, да? Поэтому, на мой взгляд, это очень актуальная проблема, и давайте вместе разбираться, как же с ней бороться.
План такой:
- Моя коллекция нестабильных тестов (из моей практики, абсолютно реальные случаи, сложные и интересные детективные истории)
- Причины нестабильности (на исследование некоторых уходили даже годы)
- Как с ними бороться? (надеюсь, это будет самая полезная часть)
Итак, начнём с моей коллекции, которой я очень дорожу: она стоила мне многих ночных часов жизни и дебага. Начнем с простого примера.
Пример 1: классика
Для затравки — классический Selenium-скрипт:
driver.navigate().to("https://www.google.com/");
driver.findElement(By.name("q")).sendKeys("selenide");
driver.findElement(By.name("btnK")).click();
assertEquals(9, driver.findElements(By.cssSelector("#ires .g")).size());
- Мы открываем WebDriver;
- Находим элемент q, вбиваем туда слово для поиска;
- Находим элемент «Кнопка» и кликаем;
- Проверяем, что в ответе девять результатов.
Вопрос: какая строчка здесь может сломаться?
Правильно, мы все хорошо знаем, что любая! Может сломаться абсолютно любая строчка, по совершенно разным причинам:
Первая строчка — медленный интернет, сервис упал, админы что-то не настроили.
Вторая строчка — элемент еще не успел отрисоваться, если он динамически отрисовывается.
Что может сломаться в третьей строчке? Тут для меня было неожиданно: я написал это тест для конференции, запустил локально, и он именно на третьей строчке свалился с вот такой ошибкой:

Это говорит, что элемент в этой точке некликабельный. Казалось бы, простая элементарная Google-форма. Секрет оказался в том, что во второй строке мы вбили слово, и пока мы его вводили, Google уже нашёл первые результаты, показал несколько первых результатов в таком поп-апчике, и они закрыли следующую кнопку. И это происходит не во всех браузерах и не всегда. У меня с этим скриптом такое происходило примерно один раз из пяти.
Четвёртая же строчка может упасть, например, потому что этот элемент отрисовывается динамически и еще не успел отрисоваться.
На этом примере хочу сказать, что, по моему опыту, 90% flaky-тестов имеют в основе одни и те же причины:
- Скорость Ajax-запросов: иногда они запускаются медленнее, иногда быстрее;
- Порядок Ajax-запросов;
- Скорость JS.
К счастью, для этих причин есть лекарство! Selenide решает эти проблемы. Как решает? Перепишем наш гугловский тест на Selenide — почти всё похоже, только знаки $ используются:
@Test
public void userCanLogin() {
open("http://localhost:8080/login”);
$(By.name("username”).setValue("john”);
$("#submit”).click();
$(".menu”).shouldHave(text("Hello, John!”));
}
Вот этот тест проходит всегда. За счёт того, что методы setValue (), click () и shouldHave () — умные: если что-то не успело подрисоваться, они чуть-чуть ждут и пробуют ещё (это называется «умные ожидания»).
Если посмотреть чуть подробнее, то все эти should*-методы умные:

Они могут подождать, если надо. По умолчанию ждут до 4 секунд, и этот тайм-аут, конечно, настраивается, можно задать любой другой. К примеру, так: mvn -Dselenide.timeout=8000.
Пример 2: nbob
Итак, 90% проблем с flaky-тестами решаются с помощью Selenide. Но остаются 10% гораздо более изощрённых случаев со сложными запутанными причинами. Вот именно о них я и хочу сегодня поговорить, потому что это такая «серая область». Приведу один из примеров: flaky-тест, на который я сразу же наткнулся в новом проекте. На первый взгляд, этого просто не может случиться, вот это-то и интересно.
Тестировали приложение-клавиатуру для логина в киосках. Тест хотел залогиниться как юзер «bob», то есть в поле «логин» ввести три буквы: b-o-b. Для этого использовались кнопки на экране. Как правило, это срабатывало, но иногда тест падал, и в поле «логин» оставалось значение «nbob»:

Естественно, ломишься искать по коду, где у нас могло быть написано «nbob» —, но в целом проекте этого вообще нет (ни в базе данных, ни в коде, ни даже в Excel-файлах). Как это возможно?
Смотрим подробнее код — казалось бы, всё просто, никаких загадок:
@Test
public void loginKiosk() {
open("http://localhost:9000/kiosk”);
$("body”).click();
$(By.name("username”)).sendKeys("bob”);
$("#login”).click();
}
Стали дальше дебажить, идти по шагам, и таким методом удалось понять: это ошибка иногда появляется после строки $(«body»).click (). То есть на этом шаге в поле «логин» появляется «n», затем уже на последующих добавляется «bob». Кто уже догадался, откуда берется «n»?
Так получилось, что буква N находилась посередине экрана, а функция click () как минимум в Chrome работает так: высчитывает центральную координату элемента и кликает в неё. Поскольку body — это большой элемент, она кликала в центр всего экрана.
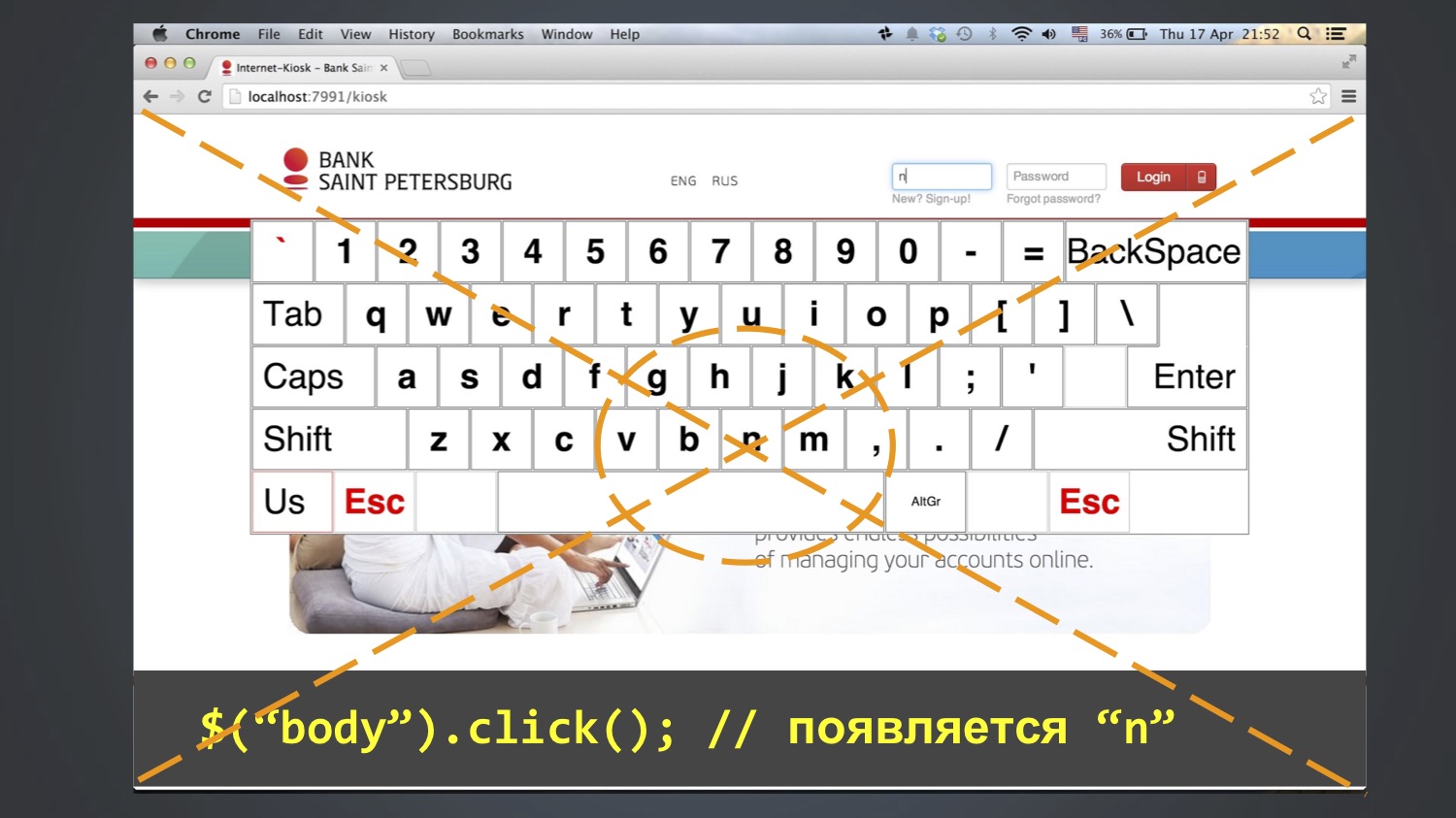
И это падало не всегда. Кто знает, почему? На самом деле, я сам не до конца знаю. Возможно, из-за того, что окно браузера всё время открывалось разного размера, и это не всегда попадало в букву N.
У вас, вероятно, возник вопрос: зачем кто-то делал $(«body»).click ()? Тоже до конца не знаю, но предполагаю, чтобы убрать фокус с поля. В Selenium есть такая проблема, что click () есть, а unclick () нет. Если фокус в поле есть, то его никак оттуда ни снять, можно только кликнуть на какой-нибудь другой элемент. А поскольку там не было никаких других разумных элементов, кликнули на body, и получили такой эффект.
Отсюда мораль: не надо вставлять что попало в
. Другими словами, не нужно в панике делать какие-то лишние движения. На самом деле, это нередко случается: поскольку я занимаюсь Selenide, мне часто приходят жалобы «что-то не работает», а потом выясняется что у них где-то в setup-методах было 15 лишних строчек, которые ничего полезного не делают и мешают. Не нужно суетиться и вставлять абы что в тесты типа «вдруг будет надёжнее».В итоге расширяем список причин нестабильных тестов:
- Скорость Ajax-запросов;
- Порядок Ajax-запросов;
- Скорость JS;
- Размер окна браузера;
- Суета!
И заодно моя рекомендация: не запускать тесты в maximized (то есть не открывать браузер на полное окно). Как правило, все так делают, и в Selenide так было по умолчанию (или до сих пор есть). Вместо этого я советую всегда запускать браузер со строго определенным разрешением экрана, потому что тогда исключается вот этот случайный фактор. И советую выставлять на минимальный размер, который ваше приложение поддерживает по спецификации.
Пример 3: фантомные счета
Пример интересен тем, что тут совпало сразу всё, что только может совпасть.
Был тест, который проверял, что на этом экране должно быть 5 счетов.

Он, как правило, был зелёный, но иногда при непонятно каких условиях падал и говорил, что на экране не пять, а шесть счетов.
Я стал исследовать, откуда берётся лишний счёт. Абсолютно непонятно. Возник вопрос: может быть, у нас есть другой тест, который в ходе теста создает новый счёт? Оказалось, что да, есть такой LoansTest. А между ним и падающим AccountsTest (который ожидает пять счетов) может оказываться миллион каких-то других тестов.
Пытаемся понять, как же так: разве LoansTest, который создаёт счёт, не должен его удалять в конце? Смотрим его код — да, должен, в конце для этого есть функция After. Тогда, по идее, всё должно быть хорошо, в чём же проблема?
Может, тест его удаляет, но он остаётся где-то закэшированным? Смотрим продакшн-код, который грузит счета — в нём действительно есть аннотация @CacheFor, он кэширует счета на пять минут.
Возникает вопрос:, но разве тест не должен был очистить этот кэш? Было бы логично, не может же быть такой косяк? Смотрим его код — да, он действительно очищает кэш перед каждым тестом. Что за дела? Тут уже теряешься, потому что гипотезы закончились: объект удаляется, кэш очищается, ёлки-палки, что же ещё может быть проблемой? Дальше стал уже просто лазать по коду, это заняло некоторое время, возможно, даже несколько дней. Пока я наконец не посмотрел в этот класс и суперкласс, и не нашёл там одну подозрительную вещь:

Кто-то уже заметил, да? Совершенно верно: и в дочернем, и в родительском классе есть метод с одним и тем же названием, и он не вызывает super.
И в Java это очень легко сделать: нажимаешь в IntelliJ IDEA или Eclipse сочетание Alt+Enter или Ctrl+Insert, он по умолчанию создаёт тебе метод setUp (), и не замечаешь, что он оверрайдит метод в суперклассе. То есть кэш все-таки не вызывался. Когда я увидел это, я был дико зол. Это сейчас мне радостно.
Отсюда мораль:
1. В тестах очень важно следить за clean code. Если в продакшн-коде все внимательно к этому относятся, проводят code review, то в тестах — не всегда.
2. Если продакшн-код проверен тестами, то кто проверит тесты? Поэтому тут особенно важно использовать проверки в IDE.
Я после этого случая нашёл в IDEA такую инспекцию, выключенную по умолчанию, которая проверяет: если метод где-то переопределён, но нет аннотации @Overridе, то она помечает это как ошибку. Теперь я всегда истерически ставлю эту галочку.
Давайте подытожим ещё раз: как это получилось, почему тест падал не всегда? Во-первых, он зависел от порядка этих двух тестов, они же всегда запускаются в случайном порядке. Ещё тест зависел от того, сколько времени прошло между ними. Счета кэшируются пять минут, если проходило больше, то тест был зелёный, а если меньше — падал, и такое случалось редко.
Расширяем список того, почему тесты могут быть нестабильны:
- Скорость Ajax-запросов;
- Порядок Ajax-запросов;
- Скорость JS;
- Размер окна браузера;
- Кэш приложения;
- Данные от предыдущих тестов;
- Время.
Пример 4: Время Java
Был тест, который работал на всех наших компьютерах и на нашем Jenkins, но иногда падал на Jenkins заказчика. Смотрим в тест, разбираемся, почему. Оказывается, падал, потому что при проверке «дата платежа должна быть сейчас или в прошлом» она оказывалась «в будущем».
assert payment.time <= new Date();
Смотрим в код, вдруг при каких-то условиях мы можем поставить дату в будущем? Не можем: в единственном месте, где инициализируется время платежа, используется new Date (), а это всегда текущее время (в крайнем случае оно может оказаться в прошлом, если вдруг тест был очень медленным). Как такое вообще возможно? Долго бились головой, не могли понять.
А однажды заглянули в лог приложения. Отсюда первая мораль — очень полезно при исследовании тестов заглядывать в лог самого приложения. Поднимите руки, кто это делает. В общем, не большинство, увы. А там есть полезная информация: к примеру, request log, такой-то URL в такое время выполнился, выдал такой-то ответ.

Здесь есть кое-что подозрительное, заметили? Смотрим время: этот запрос обрабатывался минус три секунды. Как такое может быть? Долго бились, не могли понять. Наконец, когда у нас кончились теории, сделали тупое решение: в Jenkins написали простенький скрипт, который в цикле раз в секунду логирует текущее время. Запустили его. На следующий день, когда этот flaky-тест один раз ночью упал, стали смотреть выдержку из этого файла за то время, когда он упал:

Итак: 34 секунды, 35, 36, 37, 35, 39… Круто, что мы это нашли, но как это вообще возможно? Снова теории закончились, ещё два дня чесали голову. Это реально тот случай, когда Матрица шутит над тобой, да?
Пока наконец не стукнула в голову одна идея… И вот, что оказалось. В Linux есть сервис для синхронизации времени, который бегает на центральный сервер и спрашивает «а столько сейчас милисекунд?» И оказывается, на этом конкретном Jenkins было запущено два разных сервиса. Тест начал падать, когда на этом сервере обновили Ubuntu.
Там раньше был сконфигурирован ntp-сервис, который обращался на специальный банковский сервер и брал время оттуда. А с новой версией Ubuntu по умолчанию включался новый легковесный сервис, к примеру, systemd-timesyncd. И работали оба. Никто этого не заметил. Почему-то центральный банковский сервер и какой-то центральный Ubuntu-сервер выдавали ответ с разницей в 3 секунды. Естественно, эти два сервиса друг другу мешали. Где-то глубоко в документации Ubuntu сказано, что, конечно, не допускайте такой ситуации… Ну, спасибо за информацию :)
Кстати, заодно я узнал один интересный нюанс Java, который до этого, несмотря на мой многолетний опыт, не знал. Один из самых базовых методов в Java называется System.currentTimeMillis (), с помощью него обычно засекают время вызова чего-то, многие писали такой код:
long start = System.currentTimeMillis();
// ...
long en = System.currentTimeMillis();
log.info("Loaded in {} ms", end-start);
Такой код есть в библиотеках Apache Commons, Guava. То есть, если нужно засечь, сколько миллисекунд занял вызов чего-то, обычно делают так. И многие, наверное, слышали, что так делать нельзя. Я тоже слышал, но не знал, почему, и лень было разбираться. Я думал, вопрос в точности, потому что в какой-то версии Java появился System.nanoTime () — он более точный, выдаёт наносекунды, которые в миллион раз точнее. А поскольку, как правило, мои вызовы длятся секунду или полсекунды, то мне такая точность не важна, и я продолжал использовать System.currentTimeMillis (), что мы и увидели в том логе, где было -3 секунды. Так вот, на самом деле правильный способ такой, и вот теперь я узнал, почему:
long start = System.nanoTime();
// ...
long end = System.nanoTime();
log.info("Loaded in {} ms", (end-start)/1000000);
На самом деле, в документации методов это написано, я же просто никогда не читал её. Я всю жизнь думал, что System.currentTimeMillis () и System.nanoTime () — одно и то же, только с разницей в миллион раз. А оказалось, что это принципиально разные вещи. System.currentTimeMillis () возвращает реально текущую дату — сколько сейчас миллисекунд прошло с 1 января 1970-го. А System.nanoTime () — некий абстрактный счётчик, который не привязан к реальному времени: да, он гарантированно растёт каждую наносекунду на единичку, но он не связан с текущим временем, он может быть даже отрицательным. При старте JVM как-то случайным образом выбирается момент времени, и он начинает расти. Это для меня был сюрприз. Для вас тоже? Вот, не зря приехал.
Пример 5: Проклятие зелёной кнопки
Тут у нас тест заполняет некую форму, нажимает зелёную кнопку Confirm, и иногда не идёт дальше. Почему не идёт — непонятно.
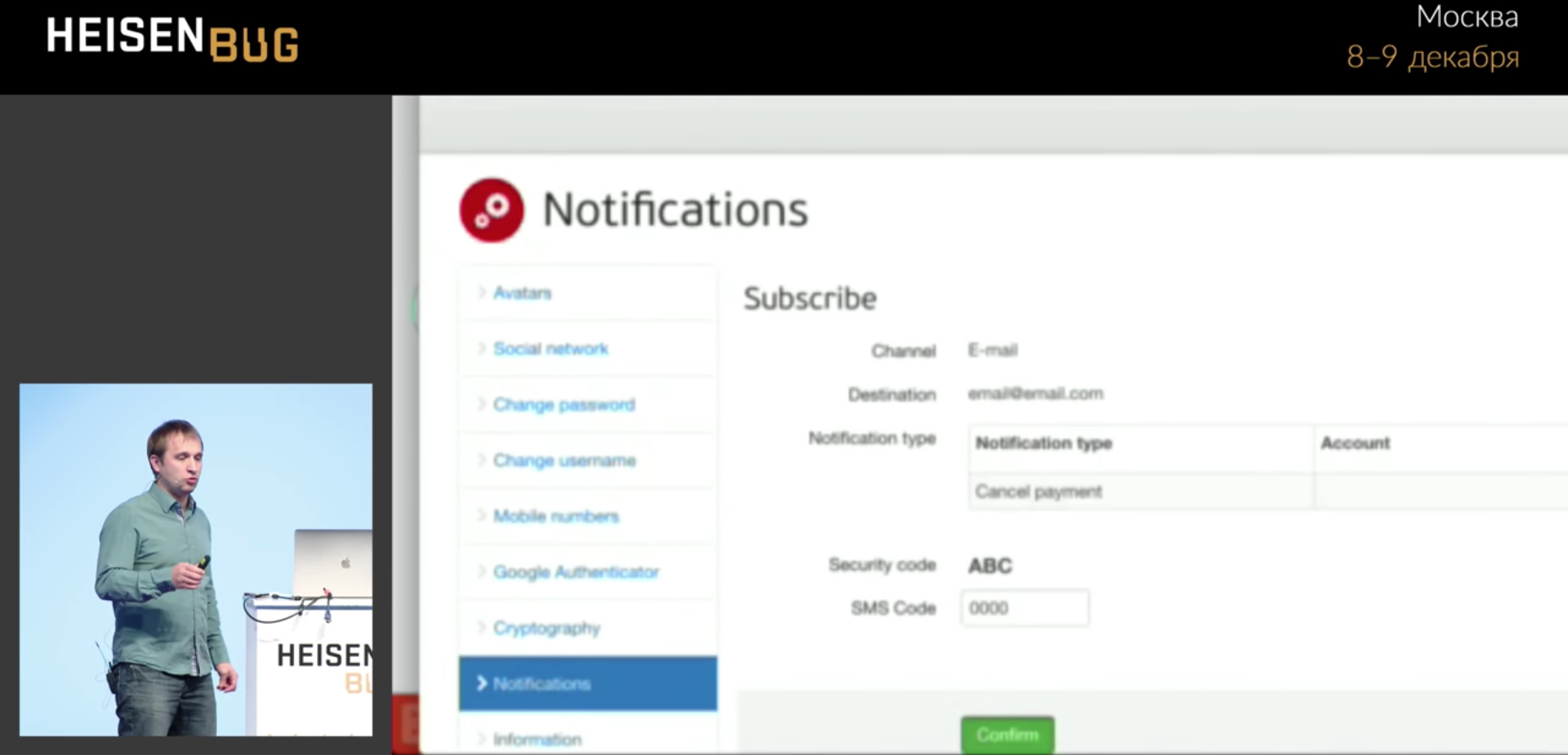
Вбиваем четыре нуля и висим, не идём на следующую страничку. Клик происходит без ошибок. Я посмотрел всё: Ajaх-запросы, ожидание, таймауты, логи приложений, кэш — ничего не нашёл. Пока не появилась библиотека Video Recorder, написанная Сергеем Пироговым. Она позволяет, добавив в код одну аннотацию, записывать видео. Тогда я смог снять видео этого теста, посмотреть его в замедленном виде, и это наконец-то прояснило ситуацию, которую до видео я не мог разгадать несколько месяцев.

Прогресс-бар перекрыл кнопку на доли секунды, а клик сработал ровно в этот момент и попал по этому прогресс-бару. То есть прогресс-бар схавал клик и пропал! И его не будет видно ни на одном скриншоте, ни в одном логе, никогда не узнаешь, что произошло.
В принципе, это в каком-то смысле баг приложения: прогресс-бар появился, потому что приложение реально вылезает за край экрана, и если прокрутить, там оказывается куча полезных данных. Но пользователи на это не жаловались, потому что на большом экране всё помещалось, не помещалось только на маленьком.
Пример 6: почему зависает Chrome?
Детективное расследование длиной в два года, абсолютно реальный случай. Ситуация такая: наши тесты довольно часто были flaky и падали, и в стек-трейсах было видно, что Chrome зависает: не тест наш, а именно Chrome. В логах было видно «Build is running 36 hours…» Стали снимать тред-дампы и стак-трейсы — они показывают, что в тестах всё хорошо, зависает обращение к Chromedriver и, как правило, в момент закрытия (вызываем метод close, и этот метод ничего не делает, висит 36 часов). Если интресно, то стек-трейс выглядел так:

Пытались сделать всё, что только может прийти в голову:
- Сконфигурировать таймаут для открытия/закрытия браузера (если за 15 секунд не смогли открыть/закрыть браузер, пробуем снова через 15 секунд, до трёх попыток). Открывать и закрывать браузер в отдельном потоке. Результат: висело так же все три попытки.
- Убивать старые процессы Chrome. Создали отдельный джоб в Jenkins «kill-chrome», к примеру, вот так можно «убить» все процессы старее часа:
killall --older-than 1h chromedriver
killall --older-than 1h chrome
Это хотя бы освобождало память, но не давало ответ на вопрос «что же происходит?». По сути, эта штука только оттянула нам момент решения. - Включить debug-логи приложения.
- Включить debug-логи WebDriver.
- Переоткрывать браузер после каждых 20 тестов. Может показаться смешным, но мысль была такая: «А вдруг Chrome зависает, потому что он устал?» Ну, утечка памяти или ещё что-то.
Результат последней попытки оказался совершенно неожиданным: проблема стала повторяться чаще! А мы-то надеялись, что это поможет стабилизировать Chrome, чтобы он лучше работал. Это вообще вынос мозга. Но на самом деле, когда проблема начинает повторяться чаще, надо не грустить, а радоваться! Это даёт возможность лучше её изучить. Если она стала чаще повторяться, надо цепляться за это: «Да-да, сейчас добавлю ещё чего-нибудь, логов, брейкпойнтов…»
Пытаемся повторить проблему: пишем цикл от 1 до 1000, в цикле просто открываем браузер, первую страничку в нашем приложении и закрываем. Написали такой цикл, и… бинго! Результат: проблема стала повторяться стабильно (правда, примерно через каждые 80 итераций)! Круто! Правда, это достижение долго ничего не давало. Запустил ты, дождался 80-й итерации, завис Chrome…, а дальше что делать? Смотришь в стак-трейсы, дампы, логи — ничего полезного там нет. Developer Tools в Chrome, возможно, помог бы, но до сентября 2017-го вместе с Selenium эти тулы не работали (конфликтовали порты: запускаешь Chrome из Selenium, и DevTools не открываются). Долгое время не мог придумать, что сделать.
И тут в этой истории начинается сказочный момент. Однажды, после бесконечного количества попыток, я снова запустил эти тесты, он у меня снова на какой-то итерации вроде 56-й завис, я думаю «давай ещё что-нибудь покопаю» (правда, не знаю, куда ещё брейкпойнт поставить или какой-то лог добавить). В этот момент дочка предлагает поиграть в кубики, а у меня тут как раз тест завис. Я говорю «Подожди», она мне: «Ты что, не понял, у меня тут к у б и к и!»
Что поделать, с грустью оставил компьютер, пошёл играть в кубики… И вдруг, примерно через 20 минут, случайно бросаю взгляд на экран, и вижу совершенно неожиданную картину:

Что получается: идёт отсчёт, через сколько минут истечёт сессия, а я строю башню из кубиков, остаётся две, одна… сессия истекает, тест продолжается, бежит до конца и падает (элемента уже нет, сессия истекла).
Что получается: Chrome на самом деле не зависал, как мы думали всё это время, он всё это время что-то ждал. Когда сессия истекала, дожидался, шёл дальше. Чего именно ждал Chrome — абсолютно непонятно, чтобы это понять, пришлось перелопатить весь код методом бинарного поиска: выкидываешь половину JavaScript и HTML, снова пытаешься повторить 80 итераций — не зависло, о, значит, где-то там… В общем, экспериментальным путем поняли, что проблема вот здесь:
var timeout = setTimeout(sessionWatcher);
Был на всех наших страницах JavaScript — тот самый, который показывает окошко, что сессия истекает. Наверно, все JavaScript-программисты знают, что так делать не очень правильно: всё, что запускается в тегах