Фильтр Калмана для минимизации энтропийного значения случайной погрешности с не Гауссовым распределением

Введение
На Habr математическое описание работы фильтра Калмана и особенности его применения рассматривались в следующих публикациях [1÷10]. В публикации [2] в простой и доходчивой форме рассмотрен алгоритм работы фильтра Калмана (ФК) в модели «пространства состояний», Следует отметить, что исследование систем контроля и управления во временной области с помощью переменных состояния широко используется в последнее время благодаря простоте проведения анализа [11].
Публикация [8] представляет значительный интерес именно для обучения. Очень эффективен методический приём автора, который начал свою статью с рассмотрения распределения случайной погрешности Гаусса, рассмотрел алгоритм ФК и закончил простой итерационной формулой для подбора коэффициента усиления ФК. Автор ограничился рассмотрением распределения Гаусса мотивируя это тем, что при достаточно больших  (многократных измерений) закон распределения суммы случайных величин стремится к распределению Гаусса.
(многократных измерений) закон распределения суммы случайных величин стремится к распределению Гаусса.
Теоретически такое утверждение, безусловно, справедливо, однако на практике число измерений в каждой точке диапазона не может быть очень большим. Сам R.E. Kalman получил результаты о минимуме ковариации фильтра на базе ортогональных проекций, без предположения о гауссовости ошибок измерений [12].
Целью настоящей публикации является исследование возможностей фильтра Калмана для минимизации энтропийного значения случайной погрешности с не Гауссовым распределением.
Для оценки эффективности фильтра Калмана при идентификации закона распределения или суперпозицией законов по экспериментальным данным воспользуемся информационная теорией измерений основанной на теории информации К. Шеннона, согласно которой информация, подобно физической величине, может быть измерена и оценена.
Основное достоинство информационного подхода к описанию измерений состоит в том, что размер энтропийного интервала неопределенности может быть найден строго математически для любого закона распределения. Что устраняет исторически сложившийся произвол, неизбежный при волевом назначении различных значений доверительной вероятности.Это особенно важно и в учебном процессе, когда обучающий может наблюдать уменьшение неопределённости измерений при применении фильтрации Калмана на заданной ему числовой выборке[13,14].
Кроме того, по совокупности вероятностных и информационных характеристикам выборки можно более точно определить характер распределения случайной погрешности. Это объясняется обширной базой численных значений таких параметров, как энтропийный коэффициент и контрэксцесс для различных законов распределения и их суперпозицией.
Оценка суперпозиции законов распределения случайной величины по энтропийному коэффициенту и контрэксцессу (полученных из экспериментальных данных)
Плотность распределения вероятностей для каждого столбца гистограммы [14] шириной  равна
равна  , отсюда оценка вероятностей энтропии определяется как
, отсюда оценка вероятностей энтропии определяется как  при нахождении энтропии по гистограмме из
при нахождении энтропии по гистограмме из  столбцов получим соотношение:
столбцов получим соотношение:

Представим выражение для оценки энтропии в виде:
![$H\left (x\right )= \ln \left [ d\prod_{i=1}^{m}\left (\frac{n}{n_{i}} \right)^{\frac{n_{i}}{n}}\right ]$](https://habrastorage.org/getpro/habr/formulas/c9a/9a0/87c/c9a9a087c6bd09b446630127f5f3afc3.svg)
Получим выражение для оценки энтропийного значения случайной величины:

Классификацию законов распределения осуществляют на плоскости в координатах энтропийного коэффициента  и контрэксцесса
и контрэксцесса  где
где  .
.
Для всех возможных законов распределения \psi изменяется от 0 до 1, а k от 0 до 2,066, поэтому каждый закон может характеризоваться некоторой точкой. Покажем это, используя следующую программу:
import matplotlib.pyplot as plt
from numpy import*
from scipy.stats import *
def graf(a):#группировка данных
a.sort()
n=len(a)
m= int(10+sqrt(n))
d=(max(a)-min(a))/m
x=[];y=[]
for i in arange(0,m,1):
x.append(min(a)+d*i)
k=0
for j in a:
if min(a)+d*i <=j
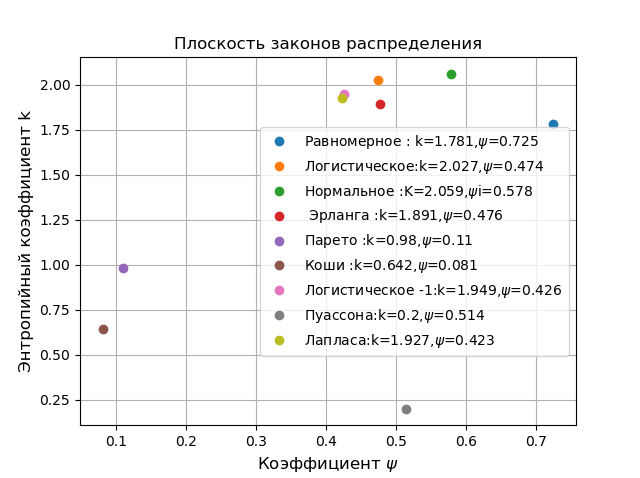
На плоскости в координатах  удалены от остальных распределений, распределения Парето, Коши хотя они и относятся к разным областям применения первое в физике, а второе в экономике. Для сравнения следует выбрать находящееся в вершине классификации нормальное распределение Гаусса. Все приведенные ниже сравнения выполняются на ограниченной выборке и носят характер демонстрации возможностей ФК на примере численного определения энтропийной погрешности.
удалены от остальных распределений, распределения Парето, Коши хотя они и относятся к разным областям применения первое в физике, а второе в экономике. Для сравнения следует выбрать находящееся в вершине классификации нормальное распределение Гаусса. Все приведенные ниже сравнения выполняются на ограниченной выборке и носят характер демонстрации возможностей ФК на примере численного определения энтропийной погрешности.
Выбор алгоритма фильтра Калмана
В каждой выбранной точке диапазона измерений проводятся многократные измерения и их результат сравнивается с мерой которую ФК «не знает». Поэтому следует выбрать ФК, например Kalman Filter to Estimate a Constant [16]. Однако я предпочитаю Python и остановился на варианте [16] с обширной документацией. Приведу описание алгоритма:
Поскольку константа всегда одна модель системы можно представить в виде:
 , (1)
, (1)
Для модели матрица перехода вырождается в единицу, а матрица управления в ноль.Модель измерения примет вид:
 , (2)
, (2)
Для модели (2) матрица измерений превращаются в единицу, а ковариационные матрицы  превращаются в дисперсии.На очередном
превращаются в дисперсии.На очередном  -м шаге, до прихода результатов измерения, скалярный фильтр Калмана пытается по формуле (1) оценить новое состояние системы:
-м шаге, до прихода результатов измерения, скалярный фильтр Калмана пытается по формуле (1) оценить новое состояние системы:
 , (3)
, (3)
Уравнение (3) показывает, что априорная оценка на следующем шаге равна апостериорной оценке, сделанной на предыдущем шаге. Априорная оценка дисперсии ошибки:
 , (4)
, (4)
По априорной оценке состояния  можно вычислить прогноз измерения:
можно вычислить прогноз измерения:
 , (5)
, (5)
После того, как получено очередное измерение  , фильтр рассчитывает ошибку своего прогноза -го измерения:
, фильтр рассчитывает ошибку своего прогноза -го измерения:
 , (6)
, (6)
Фильтр корректирует свою оценку состояния системы, выбирая точку, лежащую где-то между первоначальной оценкой и точкой, соответствующей новому измерению :
, (7)
где  — коэффициент усиления фильтра.
— коэффициент усиления фильтра.
Также корректируется оценка дисперсии ошибки:
 , (8)
, (8)
Можно доказать, что дисперсия ошибки  равна:
равна:
 , (9)
, (9)
Коэффициент усиления фильтра, при котором достигается минимальная ошибка оценки состояния системы определяется из соотношения:
 , (10)
, (10)
Минимизация энтропийной погрешности ФК для шумов с распределением Коши, Парето и Гаусса
1. В теории вероятности плотность распределения Коши определяется из соотношения:

Для этого распределения невозможно оценить погрешность методами теории вероятности ( ), но информационная теория позволяет это сделать:
), но информационная теория позволяет это сделать:
from numpy import *
import matplotlib.pyplot as plt
from scipy.stats import *
def graf(a):#группировка данных для определения энтропийной погрешности
a.sort()
n=len(a)
m= int(10+sqrt(n))
d=(max(a)-min(a))/m
x=[];y=[]
for i in arange(0,m,1):
x.append(min(a)+d*i)
k=0
for j in a:
if min(a)+d*i <=j
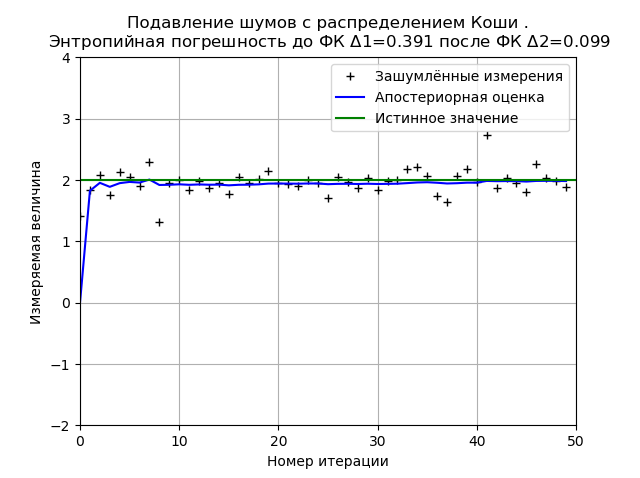
Вид графика может изменяться как при перезагрузке программы (новой генерации выборки распределения), так и в зависимости от числа измерений и параметров распределения, но одно останется неизменным ФК минимизирует значение энтропийной погрешности вычисленной на основе информационной теории измерений. Для приведенного графика ФК снижает энтропийную погрешность в 3,9 раза.
2. В теории вероятности плотность распределения Парето с параметрами  и определяется из соотношения:
и определяется из соотношения:

Следует отметить, что распределение Парето встречается не только в экономике. Можно привести следующий пример распределение размера файла в интернет-трафике по TCP-протоколу.
3. В теории вероятности плотность нормального распределения (Гаусса) с математическим ожиданием  и среднеквадратическим отклонением
и среднеквадратическим отклонением  определяется из соотношения:
определяется из соотношения:

Определение минимизации ФК энтропийной погрешности от шумов с распределением Гаусса приводим для сравнения с не Гауссовыми распределениями Коши и Парето.
from numpy import *
import matplotlib.pyplot as plt
from scipy.stats import *
def graf(a):#группировка данных для определения энтропийной погрешности
a.sort()
n=len(a)
m= int(10+sqrt(n))
d=(max(a)-min(a))/m
x=[];y=[]
for i in arange(0,m,1):
x.append(min(a)+d*i)
k=0
for j in a:
if min(a)+d*i <=j
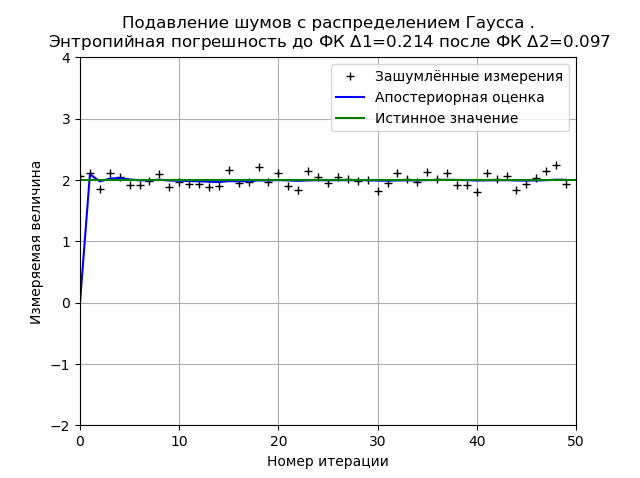
Распределение Гаусса обеспечивает более высокую стабильность результата при 50 измерениях и для приведенного графика энтропийная погрешность уменьшается в 2,2 раза.
Минимизация ФК энтропийной погрешности по выборке экспериментальных данных с неизвестным законом распределения шумов
from numpy import *
import matplotlib.pyplot as plt
from scipy.stats import *
def graf(a):#группировка данных для определения энтропийной погрешности
a.sort()
n=len(a)
m= int(10+sqrt(n))
d=(max(a)-min(a))/m
x=[];y=[]
for i in arange(0,m,1):
x.append(min(a)+d*i)
k=0
for j in a:
if min(a)+d*i <=j
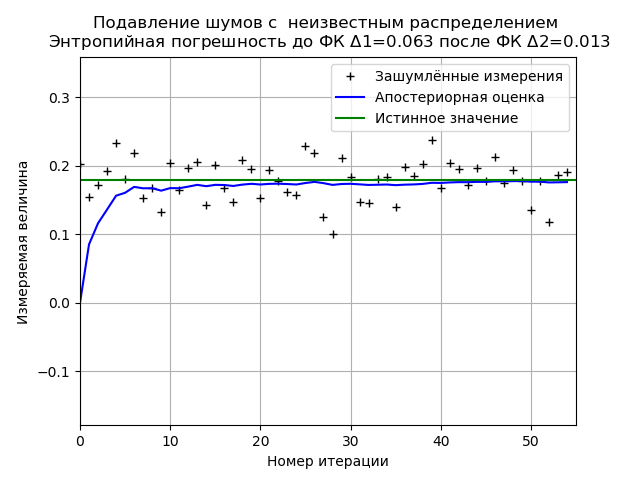
При анализе выборки экспериментальных данных получаем стабильные результаты по минимизации ФК энтропийной погрешности. Для данной выборки ФК уменьшает энтропийную погрешность в 4,85 раза.
Вывод
Все приведенные в данной статье сравнения проводились на ограниченных выборках данных, поэтому от основополагающих выводов следует воздержаться, однако использование энтропийной погрешности позволяет количественно оценить эффективность фильтра Калмана в приведенной реализации, поэтому учебную задачу данной статьи можно считать выполненной.
Ссылки
