Есть ли стекирование в коммутаторах Cisco Nexus?

Когда речь заходит о коммутаторах Cisco Nexus, один из первых вопросов, который мне задают: поддерживается ли на них стекирование? Услышав отрицательней ответ, следует логичное «Почему?».
Ответ — стек коммутаторов может служить единой точкой отказа. При этом Nexus позиционируется, как коммутатор в ЦОД, где отказоустойчивость стоит на одном из первых мест.
«Но вы ведь сами писали (часть 1, часть 2, VSS/IRF), что на базе стека можно построить отказоустойчивую инфраструктуру! Получается, обманывали?». Нет, ни в коем случае. Каждая технология уместна там, где её минусы не настолько критичны для работы сети, а плюсы дают ощутимые преимущества. Вот и со стеком ситуация аналогичная.
Стекирование обладает двумя основными преимуществами:
- единой точкой управления всеми коммутаторами (management plane),
- возможностью агрегации каналов, подключённых к разным устройствам в стеке (Multi-Chassis Link Aggregation — MC-LAG).
Настройка и обслуживание всех коммутаторов в стеке происходит через один общий интерфейс.
Поддержка MC-LAG (в терминах Cisco — Port channel) позволяет:
- минимизировать использование в сети протоколов семейства Spanning Tree Protocols (STP),
- использовать агрегированную полосу пропускания (все каналы активны),
- обеспечивать отказоустойчивое подключение устройств (коммутаторов, серверов и пр.).
В стеке работа MC-LAG возможна за счёт общего control plane. Один из коммутаторов становится основным (мастером). На нём запускается control plane, который координирует работу всех остальных устройств. Кстати, management plane активируется на нём же. «Мозг» в стеке всегда один. Аппаратные же ресурсы коммутаторов независимы. Если один из них сломается, остальные продолжат работу.
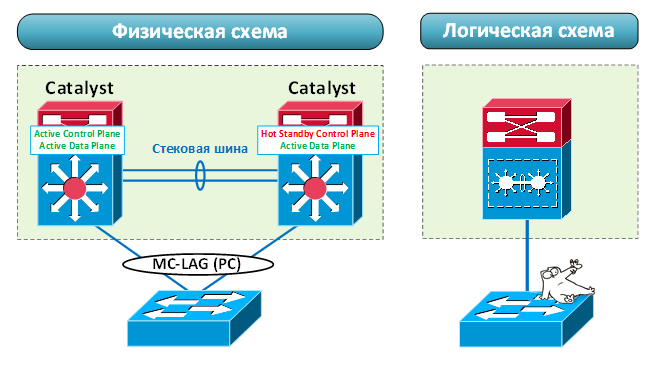
Таким образом, стекирование предполагает общий control plane и management plane. Несмотря на все достоинства, это возможная точка отказа. И хоть аппаратно коммутаторы независимы, бывают сбои (не связанные с железом), при которых стек может перестать корректно функционировать. Например, если control plane на основном коммутаторе «зависнет» из-за утечки оперативной памяти. Последствия могут быть различными: потеря управления стеком, прекращение работы различных протоколов (например, LACP). При этом стек может продолжать передавать трафик. Ведь ASIC«и заполнены необходимыми данными и фактически не зависят от работы control plane. Но все динамические агрегации (MC-LAG) «развалятся», так как пакеты LACP перестанут отправляться на соседнее устройство.
Ещё одна возможная проблема — ситуация, когда сразу несколько коммутаторов решают, что они являются активными («split brain»). Так как конфигурация у них идентичная, имеем в сети два устройства с одинаковой адресацией. Происходит это из-за разрыва управляющего канала. Конечно же, существуют технологии, направленные на борьбу с таким явлением. В этом случае коммутаторы используют дополнительные механизмы отслеживания состояния соседей. Да и управляющий канал на некоторых типах стека сложно разорвать. Но не стоит сбрасывать со счетов такую ситуацию.
Таким образом, стек — хорошее решение для сетей, где его поломка не фатальна. Да, его нельзя назвать полностью отказоустойчивым решением. Но вероятность наступления критической ситуации не так велика. И с лихвой может окупиться теми преимуществами, которые он предоставляет.
Коммутаторы Nexus позиционируются как решение для сред (в первую очередь ЦОД'ов), где очень важна отказоустойчивость. Поэтому на этих устройствах стекирование вообще отсутствует. Замечу, область применения Nexus не ограничена только ЦОДами. Они могут использоваться, в том числе, при построении корпоративной сети.
Но стекирование имеет весомые плюсы. Поэтому Nexus«ы поддерживают ряд технологий, позволяющие получить их, не объединяя коммутаторы в стек.
Для реализации функций MC-LAG используется технология virtual Port-channel (vPC). Каждый Nexus имеет свой независимый control и management plane. При этом мы можем агрегировать каналы, распределённые между двумя коммутаторам. Безусловно мы не получаем полной независимости устройств. В процессе работы коммутаторы синхронизируют между собой информацию, необходимую для работы агрегации (MAC-адреса, ARP и IGMP записи, состояние портов). Но с точки зрения отказоустойчивости это всё же лучше, чем единый control и management plane. Эта схема более надёжна. Даже если и произойдёт сбой в работе vPC, он будет менее фатален для инфраструктуры.
Однако vPC привносит особые нюансы работы. Настроить его можно только между двумя коммутаторами Nexus, и они оба должны иметь набор идентичных настроек. Некоторые функции требуют небольших дополнительных настроек, которые при работе обычного стека не нужны. Например, корректная маршрутизация трафика между двумя vPC портами предполагает наличие команды «peer-gateway». Иначе можно споткнуться об механизм предотвращения петель при передаче трафика через vPC. Работа динамической маршрутизации через vPC требует «layer3 peer-router». Казалось бы, мелочь, а нервы попортить может. Не все технологии совместимы в своей работе с vPC. Причём это зависит достаточно сильно от модели Nexus«а. Стоит внимательно смотреть configuration guide. В общем, как обычно, у всего есть свои плюсы и минусы.
В случае классического vPC синхронизация происходит через выделенный канал peer link. В случае работы vPC в рамках ACI фабрики, канал peer link не требуется. Вся синхронизация происходит через фабрику.

В плане единой точки управления всеми коммутаторами отсутствие стекирования компенсируется следующими моментами:
- Использование выносных расширителей Nexus (Fabric Extender — FEX). Это специализированные коммутаторы, в которых все функции control/management plane, а также частично data plane вынесены на основной (родительский) коммутатор.
Так как вся логика FEX«ов реализуется на родительском Nexus«е, FEX«ы и родительский коммутатор — единая точка отказа. На FEX«ах нет локальной коммутации. Пакеты между соседними портами передаются через родительское устройство. А значит имеем повышенную нагрузку на канал между ними.

- Возможность синхронизации конфигурации между двумя коммутаторами (Configuration Synchronization). В этом случае control/management plane остаются независимыми.
В итоге. В Nexus’ах стека нет. Частично это компенсируется другими технологиями. Но использовать их нужно обдуманно, так как они привносят в дизайн сети определённые риски.
Стоит помнить: чтобы решение было отказоустойчивым в нём не должно быть зависимых частей. Любые технологии, протоколы, обеспечивающие отказоустойчивость, могут также являться причиной отказов. Более того благодаря им, проблемы могут переходить с одного устройства на другое. Ни что не идеально. Поэтому если вопрос отказоустойчивости является определяющим, нужно стараться строить сеть таким образом, чтобы влияние устройств друг на друга было минимальным.
Но это уже совсем другая история.
Полезные ссылки:
- Поддерживаемые топологии FEX в связке с vPC
- Best practice по организации работы vPС (PDF, 8,7 МБ)
