Достижения в глубоком обучении за последний год

Привет, Хабр. В своей статье я расскажу вам, что интересного произошло в мире машинного обучения за последний год (в основном в Deep Learning). А произошло очень многое, поэтому я остановился на самых, на мой взгляд, зрелищных и/или значимых достижениях. Технические аспекты улучшения архитектур сетей в статье не приводятся. Расширяем кругозор!
1. Текст
1.1. Google Neural Machine Translation
Почти год назад Google анонсировала запуск новой модели для Google Translate. Компания подробно описала архитектуру сети — Recurrent Neural Network (RNN) — в своей статье.
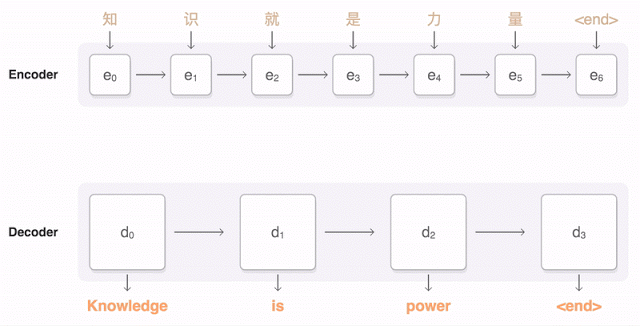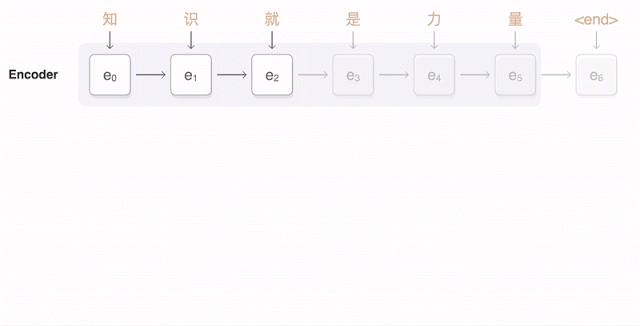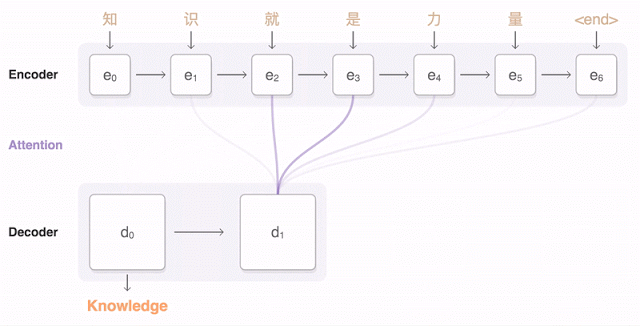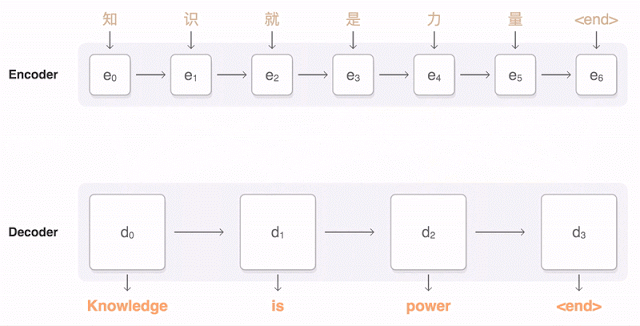
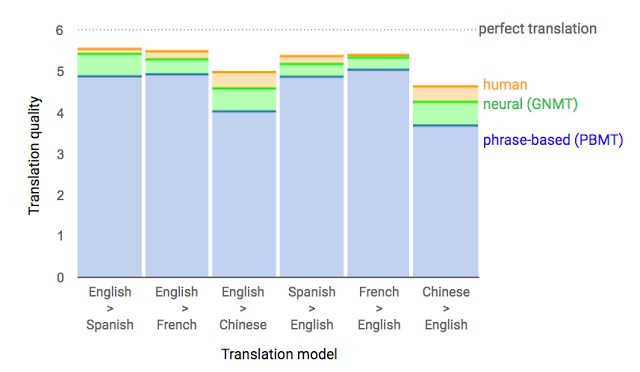
Основной результат: сокращение отставания от человека по точности перевода на 55—85% (оценивали люди по 6-балльной шкале). Воспроизвести высокие результаты этой модели сложно без огромного датасета, который имеется у Google.
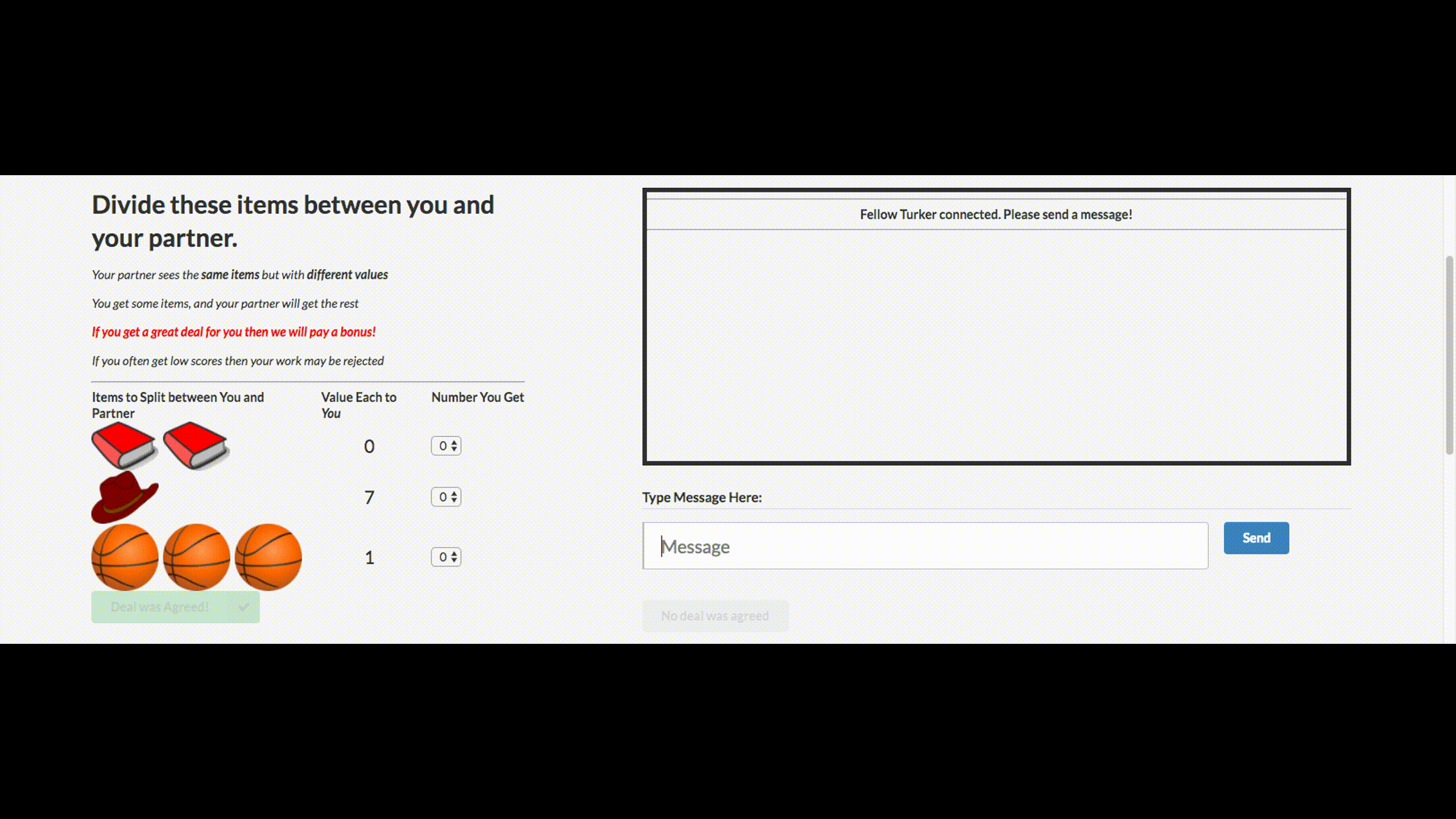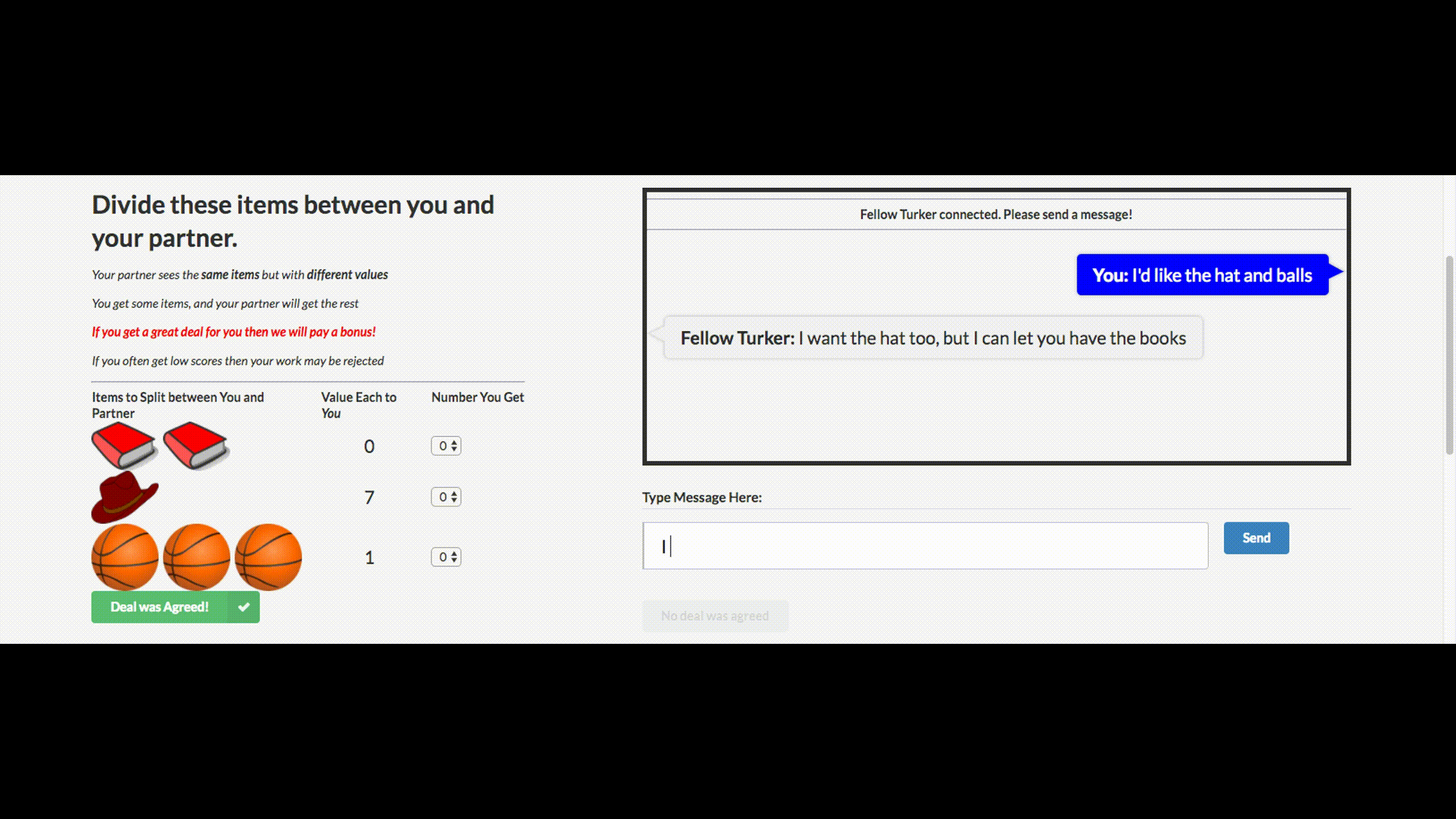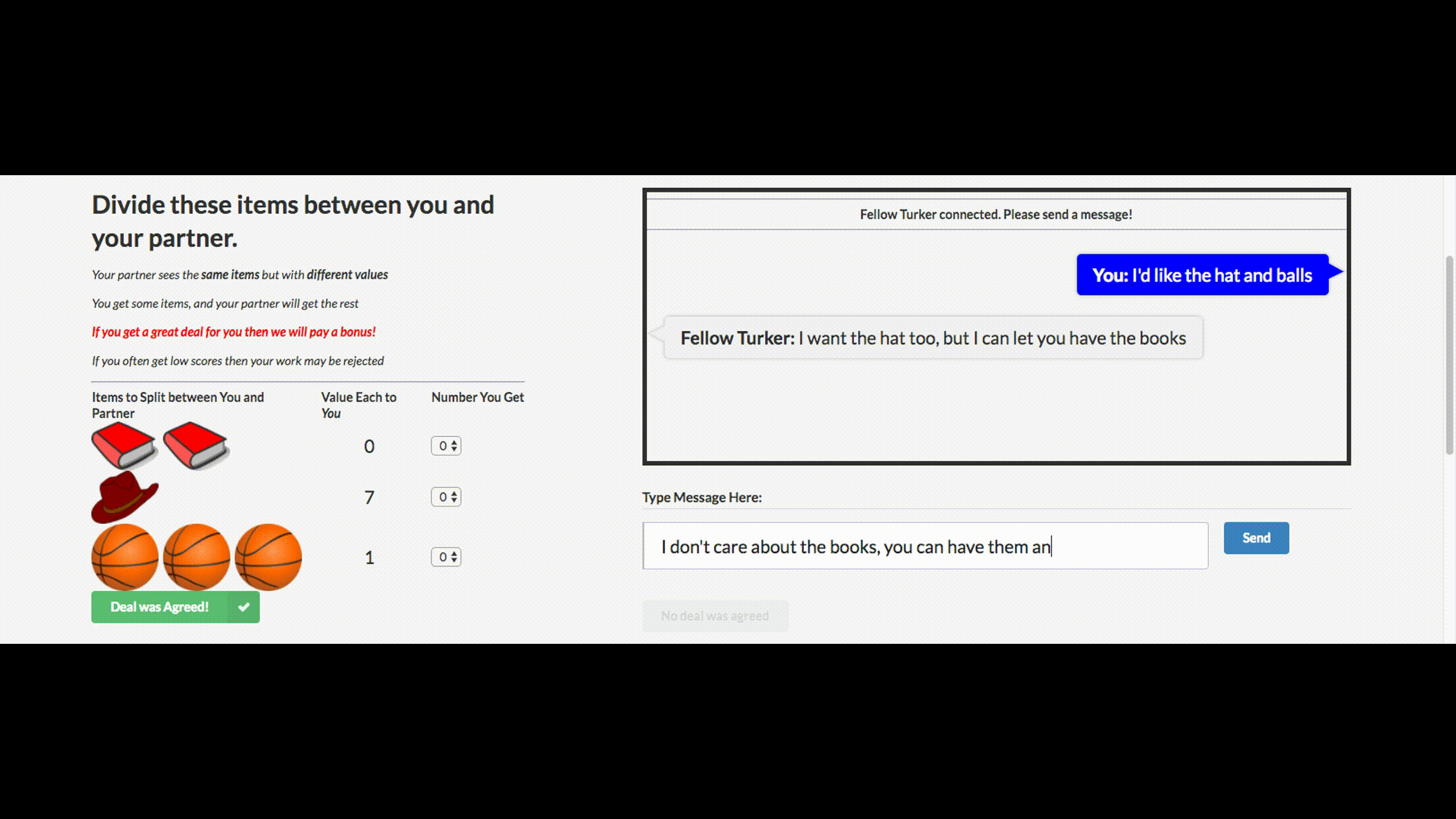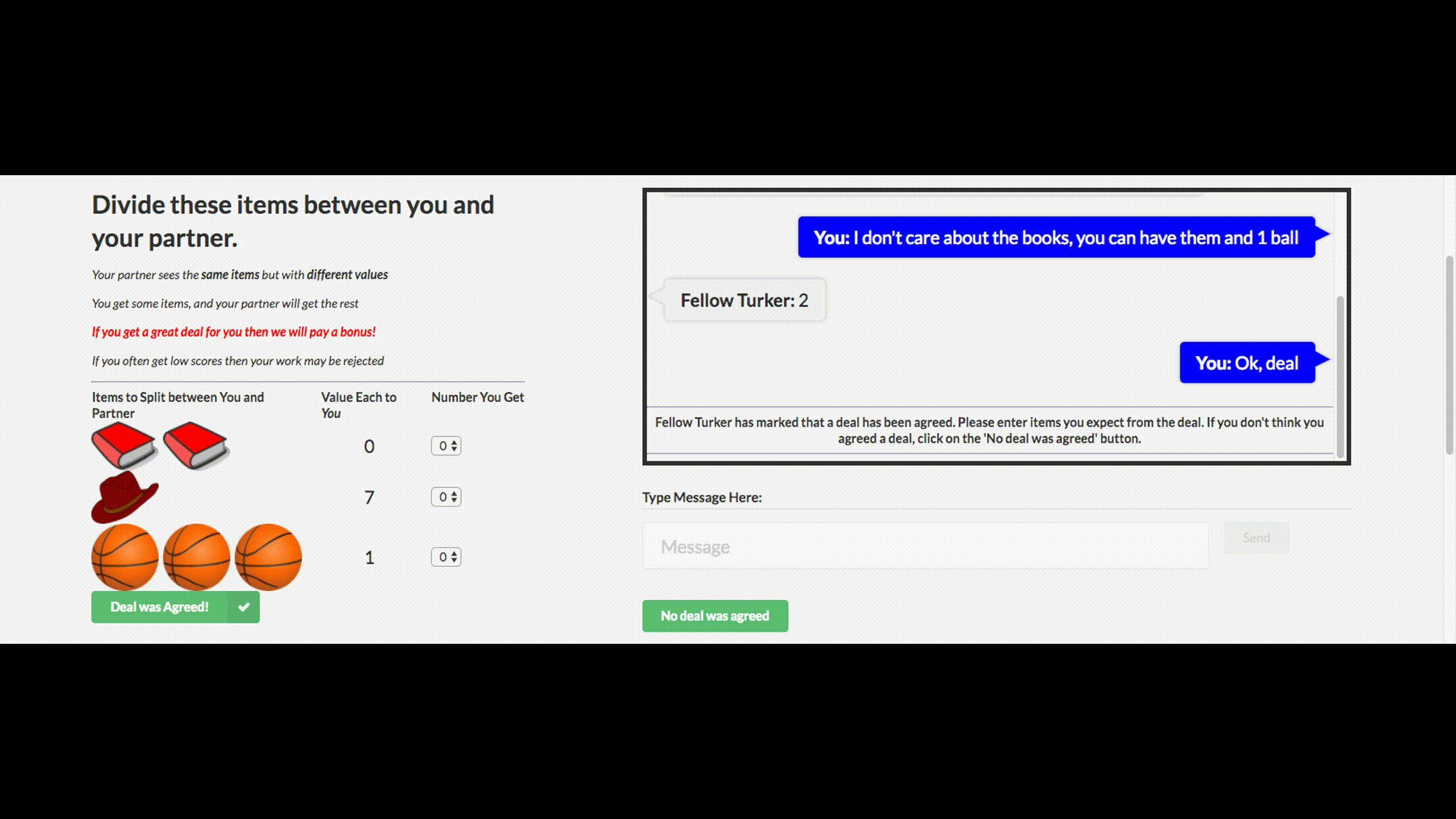
2.1. Переговоры. Будет сделка?
Вы могли слышать дурацкие новости о том, что Facebook выключила своего чат-бота, который вышел из-под контроля и выдумал свой язык. Этого чат-бота компания создала для переговоров. Его цель — вести текстовые переговоры с другим агентом и достичь сделки: как разделить на двоих предметы (книги, шляпы…). У каждого агента своя цель в переговорах, другой ее не знает. Просто уйти с переговоров без сделки нельзя.
Для обучения собрали датасет человеческих переговоров, обучили supervised рекуррентную сеть, далее уже обученного агента с помощью reinforcement learning (обучения с подкреплением) тренировали переговариваться с самим собой, поставив ограничение: похожесть языка на человеческий.
Бот научился одной из стратегий реальных переговоров — показывать поддельный интерес к некоторым аспектам сделки, чтобы потом по ним уступить, получив выгоду по своим настоящим целям. Это первая попытка создания подобного переговорного бота, и довольно удачная.
Подробности — в статье, код выложен в открытый доступ.
Разумеется, новость о том, что бот якобы придумал язык, раздули на пустом месте. При обучении (при переговорах с таким же агентом) отключили ограничение похожести текста на человеческий, и алгоритм модифицировал язык взаимодействия. Ничего необычного.
За последний год рекуррентные сети активно развивали и использовали во многих задачах и приложениях. Архитектуры рекуррентных сетей сильно усложнились, однако по некоторым направлениям похожих результатов достигают и простые feedforward-сети — DSSM. Например, Google для своей почтовой фичи Smart Reply достигла такого же качества, как и с LSTM до этого. А Яндекс запустил новый поисковый движок на основе таких сетей.
2. Речь
2.1. WaveNet: генерирующая модель для необработанного аудио
Сотрудники DeepMind (компания, известная своим ботом для игры в го, ныне принадлежащая Google) рассказали в своей статье про генерирование аудио.
Если коротко, то исследователи сделали авторегрессионную полносверточную модель WaveNet на основе предыдущих подходов к генерированию изображений (PixelRNN и PixelCNN).

Сеть обучалась end-to-end: на вход текст, на выход аудио. Результат превосходный, разница с человеком сократилась на 50%.
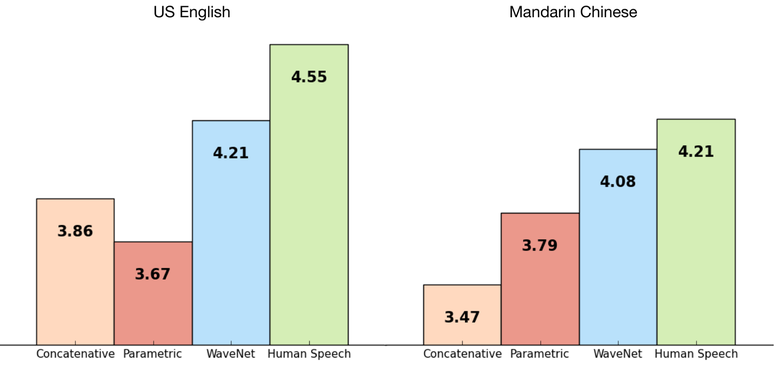
Основной недостаток сети — низкая производительность, потому что из-за авторегрессии звуки генерируются последовательно, на создание одной секунды аудио уходит около 1—2 минут.
Английский: пример
Если убрать зависимость сети от входного текста и оставить только зависимость от предыдущей сгенерированной фонемы, то сеть будет генерировать подобные человеческому языку фонемы, но бессмысленные.
Генерирование голоса: пример
Эту же модель можно применить не только к речи, но и, например, к созданию музыки. Пример аудио, сгенерированного моделью, которую обучили на датасете игры на пианино (опять же без всякой зависимости от входных данных).
Пример пианино
Подробности — в статье.
2.2. Чтение по губам
Еще одна победа машинного обучения над человеком ;) На этот раз — в чтении по губам.
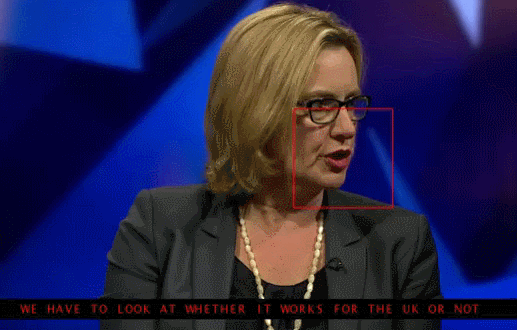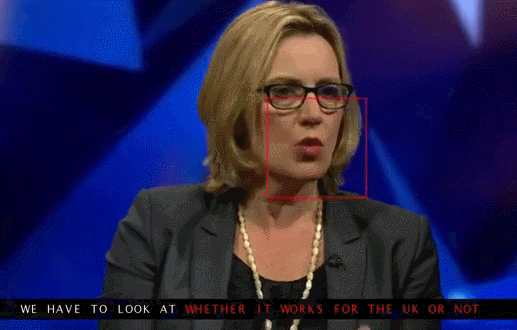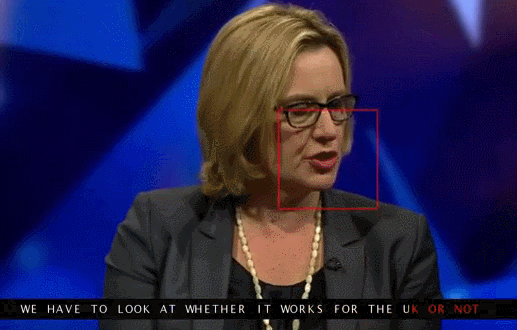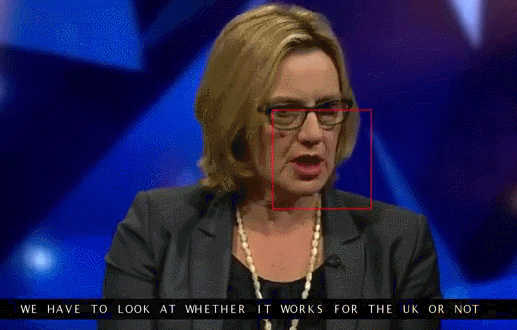
Google Deepmind в сотрудничестве с Оксфордским университетом рассказывают в статье «Lip Reading Sentences in the Wild», как их модель, обученная на телевизионном датасете, смогла превзойти профессионального lips reader«а c канала BBC.

В датасете 100 тыс. предложений с аудио и видео. Модель: LSTM на аудио, CNN + LSTM на видео, эти два state-вектора подаются в итоговую LSTM, которая генерирует результат (characters).
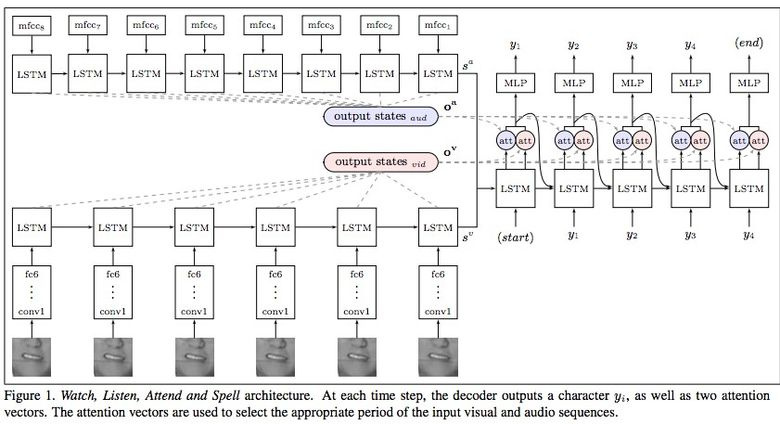
При обучении использовались разные варианты входных данных: аудио, видео, аудио + видео, то есть модель «омниканальна».
2.3. Синтезируя Обаму: синхронизация движения губ с аудио
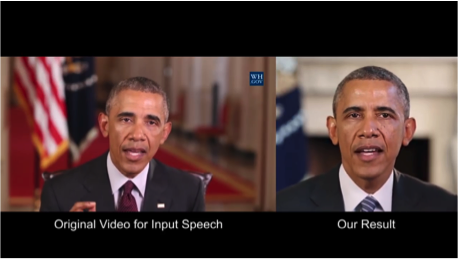
Университет Вашингтона проделал серьезную работу по генерированию движения губ бывшего президента США Обамы. Выбор пал на него в том числе из-за огромного количества записей его выступления в сети (17 часов HD-видео).
Одной сетью обойтись не удалось, получалось слишком много артефактов. Поэтому авторы статьи сделали несколько костылей (или трюков, если угодно) по улучшению текстуры и таймингам.
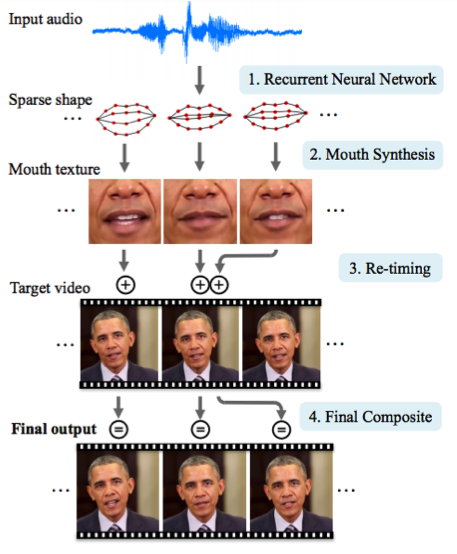
Результат впечатляет. Скоро нельзя будет верить даже видео с президентом ;)
3. Компьютерное зрение
3.1. OCR: Google Maps и Street View
В своих посте и статье команда Google Brain рассказывает, как внедрила в свои Карты новый движок OCR (Optical Character Recognition), с помощью которого распознаются указатели улиц и вывески магазинов.


В процессе разработки технологии компания составила новый FSNS (French Street Name Signs), который содержит множество сложных кейсов.
Сеть использует для распознавания каждого знака до четырех его фотографий. С помощью CNN извлекаются фичи, взвешиваются с помощью spatial attention (учитываются пиксельные координаты), а результат подается в LSTM.
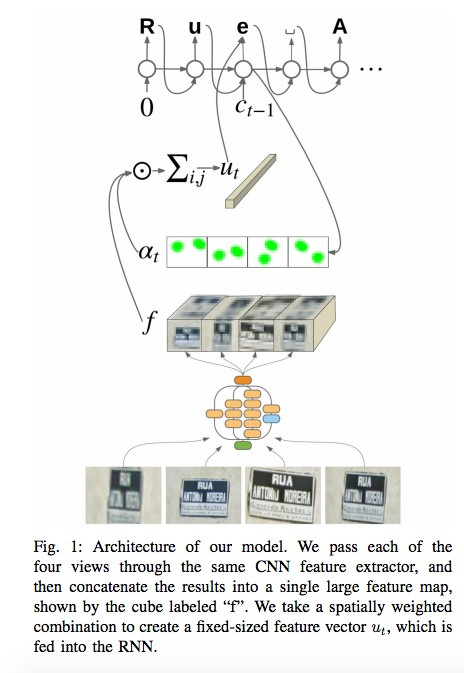
Тот же самый подход авторы применяют к задаче распознавания названий магазинов на вывесках (там может быть много «шумовых» данных, и сеть сама должна «фокусироваться» в нужных местах). Алгоритм применили к 80 млрд фотографий.
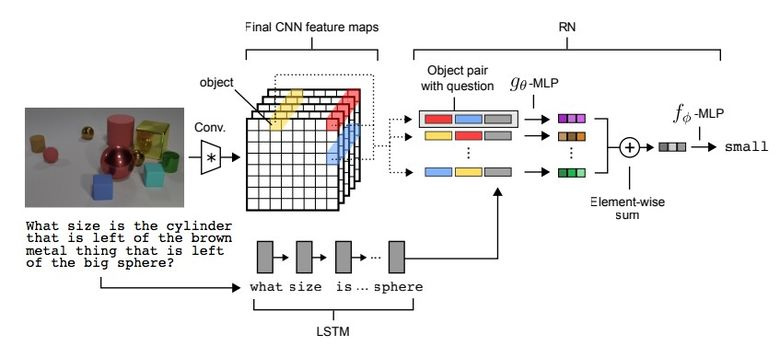
3.2. Visual Reasoning
Существует такой тип задач, как Visual Reasoning, то есть нейросеть должна по фотографии ответить на какой-то вопрос. Например: «Есть ли на картинке резиновые вещи того же размера, что и желтый металлический цилиндр?» Вопрос и правда нетривиальный, и до недавнего времени задача решалась с точностью всего лишь 68,5%.

И вновь прорыва добилась команда из Deepmind: на датасете CLEVR они достигли super-human точности в 95,5%.
Архитектура сети весьма интересная:
- По текстовому вопросу с помощью pretrained LSTM получаем embedding (представление) вопроса.
- По картинке с помощью CNN (всего четыре слоя) получаем feature maps (фичи, характеризующие картинку).
- Далее формируем попарные комбинации покоординатных slice«ов feature maps (желтые, синие, красные на картинке ниже), добавляем к каждой координаты и текстовый embedding.
- Прогоняем все эти тройки через еще одну сеть, суммируем.
Полученное представление прогоняем через еще одну feedforward-сеть, которая уже на софтмаксе выдает ответ.
3.3. Pix2Code
Интересное применение нейросетям придумала компания Uizard: по скриншоту от дизайнера интерфейсов генерировать код верстки.

Крайне полезное применение нейросетей, которое может облегчить жизнь при разработке софта. Авторы утверждают, что получили 77% точности. Понятно, что это пока исследовательская работа и о боевом применении речи не идет.
Кода и датасета в open source пока нет, но обещают выложить.
3.4. SketchRNN: учим машину рисовать
Возможно, вы видели страничку Quick, Draw! от Google с призывом нарисовать скетчи различных объектов за 20 секунд. Корпорация собирала этот датасет для того, чтобы обучить нейросеть рисовать, о чем Google рассказала в своем блоге и статье.

Собранный датасет состоит из 70 тыс. скетчей, он был в итоге выложен в открытый доступ. Скетчи представляют собой не картинки, а детализированные векторные представления рисунков (в какой точке пользователь нажал «карандаш», отпустил, куда провел линию и так далее).
Исследователи обучили Sequence-to-Sequence Variational Autoencoder (VAE) c использованием RNN в качестве механизма кодирования/декодирования.
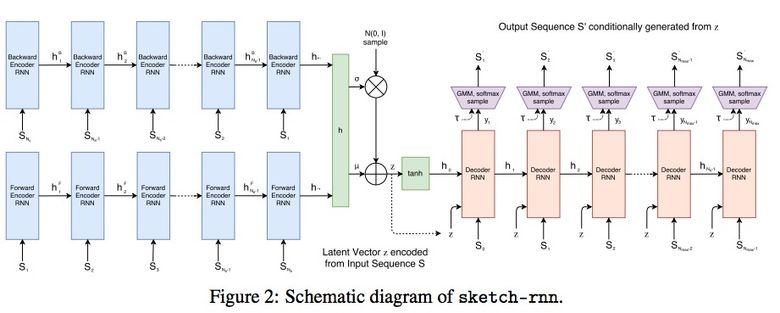
В итоге, как и положено автоенкодеру, модель получает латентный вектор, который характеризует исходную картинку.

Поскольку декодер умеет извлекать из этого вектора рисунок, то можно его менять и получать новые скетчи.

И даже выполнять векторную арифметику, чтобы соорудить котосвина:
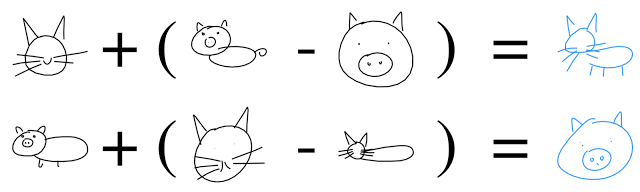
3.5. GAN
Одна из самых горячих тем в Deep Learning — Generative Adversarial Networks (GAN). Чаще всего эту идею используют для работы с изображениями, поэтому объясню концепцию именно на них.
Суть идеи состоит в соревновании двух сетей — Генератора и Дискриминатора. Первая сеть создает картинку, а вторая пытается понять, реальная это картинка или сгенерированная.
Схематично это выглядит так:
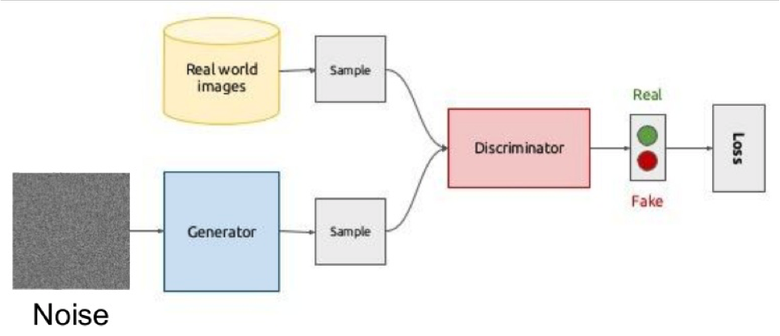
Во время обучения генератор из случайного вектора (шума) генерирует изображение и подает на вход дискриминатору, который говорит, фальшивка это или нет. Дискриминатору также подаются реальные изображения из датасета.
Обучать такую конструкцию часто тяжело из-за того, что трудно найти точку равновесия двух сетей, чаще всего дискриминатор побеждает и обучение стагнирует. Однако преимущество системы в том, что мы можем решать задачи, в которых нам тяжело задать loss-функцию (например, улучшение качества фотографии), мы это отдаем на откуп дискриминатору.
Классический пример результата обучения GAN — картинки спален или лиц.


Ранее мы рассматривали автокодировщики (Sketch-RNN), которые кодируют исходные данные в латентное представление. С генератором получается то же самое.
Очень наглядно идея генерирования изображения по вектору на примере лиц показана тут (можно изменять вектор и посмотреть, какие выходят лица).

Работает все та же арифметика над латентным пространством: «мужчина в очках» минус «мужчина» плюс «женщина» равно «женщина в очках».

3.6. Изменение возраста лица с помощью GAN
Если при обучении подсунуть в латентный вектор контролируемый параметр, то при генерировании его можно менять и так управлять нужным образом на картинке. Этот подход именуется Conditional GAN.
Так поступили авторы статьи «Face Aging With Conditional Generative Adversarial Networks». Обучив машину на датасете IMDB с известным возрастом актеров, исследователи получили возможность менять возраст лица.
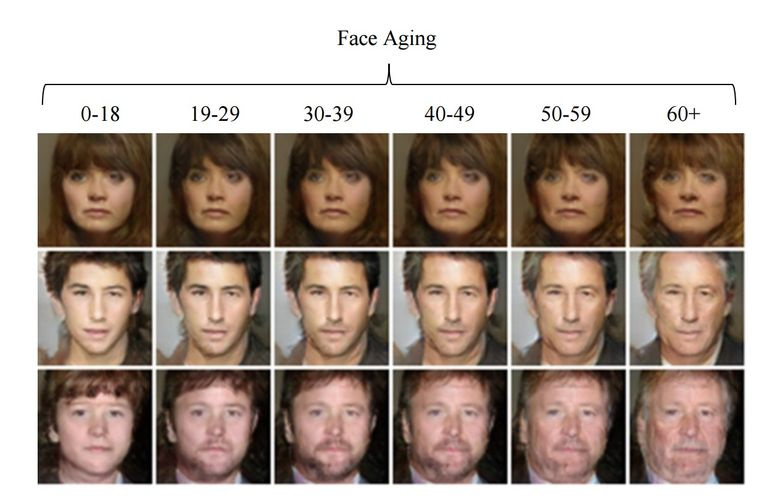
3.7. Фотографии профессионального уровня
В Google нашли еще одно интересное применение GAN — выбор и улучшение фотографий. GAN обучали на датасете профессиональных фотографий: генератор пытается улучшить плохие фотографии (профессионально снятые и ухудшенные с помощью специальных фильтров), а дискриминатор — различить «улучшенные» фотографии и реальные профессиональные.
Обученный алгоритм прошелся по панорамам Google Street View в поиске лучших композиций и получил некоторые снимки профессионального и полупрофессионального качества (по оценкам фотографов).


3.8. Синтезирование из текстового описания в изображение
Впечатляющий пример использования GAN — генерирование картинок по тексту.

Авторы статьи предлагают подавать embedding текста на вход не только генератору (conditional GAN), но и дискриминатору, чтобы он проверял соответствие текста картинке. Чтобы дискриминатор научился выполнять свою функцию, дополнительно в обучение добавляли пары с неверным текстом для реальных картинок.
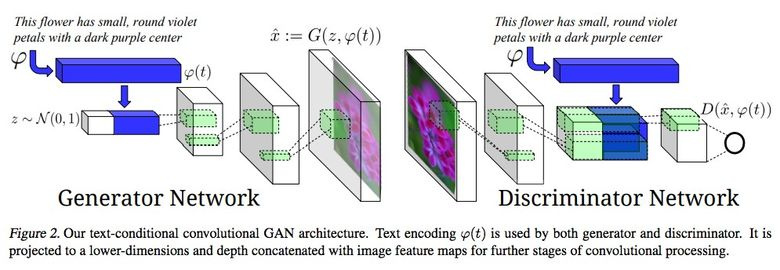
3.9. Pix2pix
Одна из ярких статей конца 2016 года — «Image-to-Image Translation with Conditional Adversarial Networks» Berkeley AI Research (BAIR). Исследователи решали проблему image-to-image генерирования, когда, например, требуется по снимку со спутника создать карту или по наброску предметов — их реалистичную текстуру.
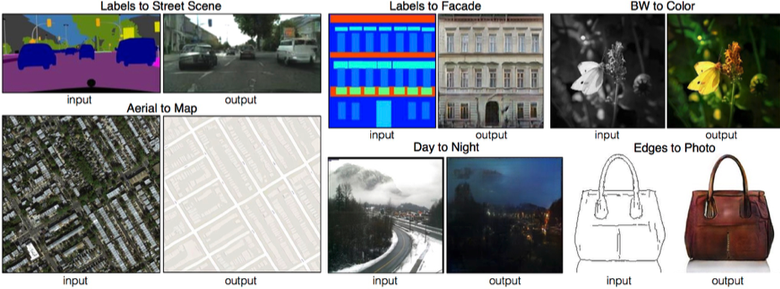
Это еще один пример успешной работы conditional GAN, в данном случае condition идет на целую картинку. В качестве архитектуры генератора использовалась UNet, популярная в сегментации изображений, а для борьбы с размытыми изображениями в качестве дискриминатора взяли новый классификатор PatchGAN (картинка нарезается на N патчей, и предсказание fake/real идет по каждому из них в отдельности).
Авторы выпустили онлайн-демо своих сетей, что вызвало огромный интерес у пользователей.
Исходный код.
3.10. CycleGAN
Чтобы применить Pix2Pix, требуется датасет с соответствующими парами картинок из разных доменов. В случае, например, с картами собрать такой датасет не проблема. Но если хочется сделать что-то более сложное вроде «трансфигурирования» объектов или стилизации, то пар объектов не найти в принципе. Поэтому авторы Pix2Pix решили развить свою идею и придумали CycleGAN для трансфера между разными доменами изображений без конкретных пар — Unpaired Image-to-Image Translation.

Идея состоит в следующем: мы учим две пары генератор-дискриминатор из одного домена в другой и обратно, при этом мы требуем cycle consistency — после последовательного применения генераторов должно получиться изображение, похожее на исходное по L1 loss«у. Цикличный loss требуется для того, чтобы генератор не начал просто транслировать картинки одного домена в совершенно не связанные с исходным изображением.
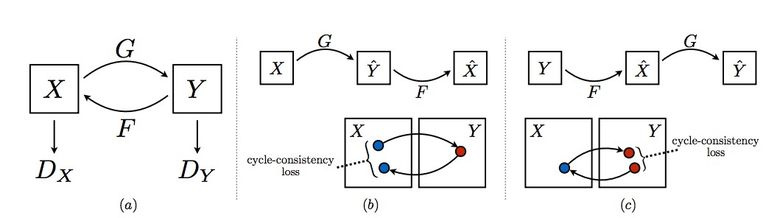
Такой подход позволяет выучить маппинг лошади –> зебры.

Такие трансформации работают нестабильно и часто создают неудачные варианты:

Исходный код.
3.11. Разработка молекул в онкологии
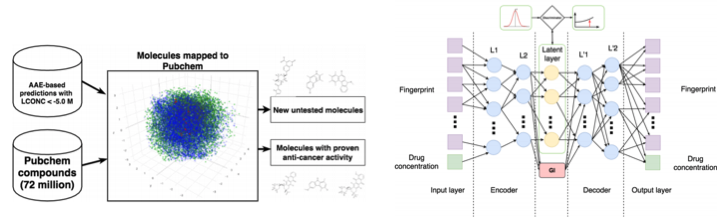
Машинное обучение сейчас приходит и в медицину. Помимо распознавания УЗИ, МРТ и диагностики его можно использовать для поиска новых лекарств для борьбы с раком.
Мы уже подробно писали об этом исследовании тут, поэтому коротко: с помощью Adversarial Auto Encoder (AAE) можно выучить латентное представление молекул и дальше с его помощью искать новые. В результате нашли 69 молекул, половина из которых применяются для борьбы с раком, остальные имеют серьезный потенциал.
3.12. Adversarial-атаки
Сейчас активно исследуется тема с adversarial-атаками. Что это такое? Стандартные сети, обучаемые, например, на ImageNet, совершенно неустойчивы к добавлению специального шума к классифицируемой картинке. На примере ниже мы видим, что картинка с шумом для человеческого глаза практически не меняется, однако модель сходит с ума и предсказывает совершенно иной класс.

Устойчивость достигается с помощью, например, Fast Gradient Sign Method (FGSM): имея доступ к параметрам модели, можно сделать один или несколько градиентных шагов в сторону нужного класса и изменить исходную картинку.
Одна из задач на Kaggle к грядущему NIPS как раз связана с этим: участникам предлагается создать универсальные атаки/защиты, которые в итоге запускаются все против всех для определения лучших.
Зачем нам вообще исследовать эти атаки? Во-первых, если мы хотим защитить свои продукты, то можно добавлять к капче шум, чтобы мешать спамерам распознавать ее автоматом. Во-вторых, алгоритмы все больше и больше участвуют в нашей жизни — системы распознавания лиц, беспилотные автомобили. При этом злоумышленники могут использовать недостатки алгоритмов. Вот пример, когда специальные очки позволяют обмануть систему распознавания лиц и «представиться» другим человеком. Так что модели надо будет учить с учетом возможных атак.

Такие манипуляции со знаками тоже не позволяют правильно их распознать.

Набор статей от организаторов конкурса.
Уже написанные библиотеки для атак: cleverhans и foolbox.
4. Обучение с подкреплением
Reinforcement learning (RL), или обучение с подкреплением, — также сейчас одна из интереснейших и активно развивающихся тем в машинном обучении.
Суть подхода заключается в выучивании успешного поведения агента в среде, которая при взаимодействии дает обратную связь (reward). В общем, через опыт — так же, как учатся люди в течение жизни.
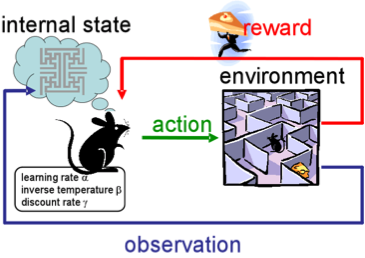
RL активно применяют в играх, роботах, управлении системами (трафиком, например).
Разумеется, все слышали о победах AlphaGo от DeepMind в игре го над лучшими профессионалами. Статья авторов была опубликована в Nature «Mastering the game of Go». При обучении разработчики использовали RL: бот играл сам с собой для совершенствования своих стратегий.
4.1. Обучение с подкреплением с неконтролируемыми вспомогательными задачами
В предыдущие годы DeepMind научился с помощью DQN играть в аркадные игры лучше человека. Сейчас алгоритмы учат играть в более сложные игры типа Doom.
Много внимания уделено ускорению обучения, потому что наработка опыта агента во взаимодействии со средой требует многих часов обучения на современных GPU.
Deepmind в своем блоге рассказывает о том, что введение дополнительных loss«ов (auxiliary tasks, вспомогательных задач), таких как предсказание изменения кадра (pixel control), чтобы агент лучше понимал последствия действий, существенно ускоряет обучение.
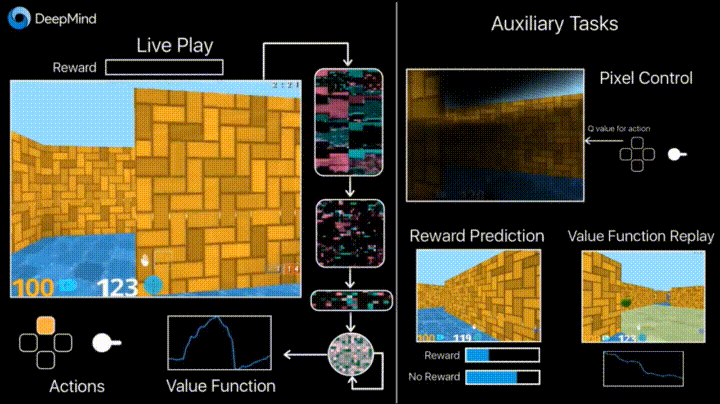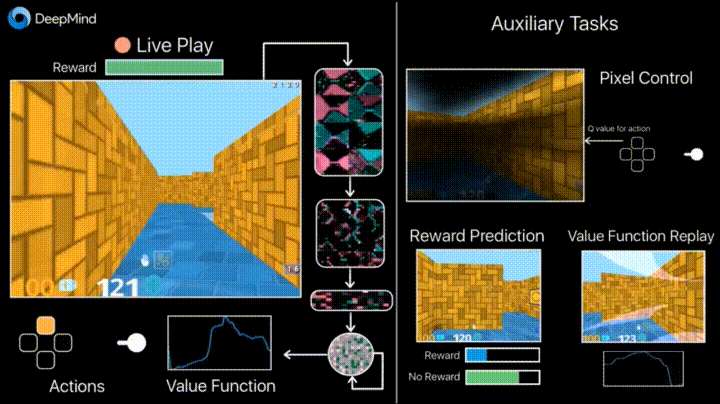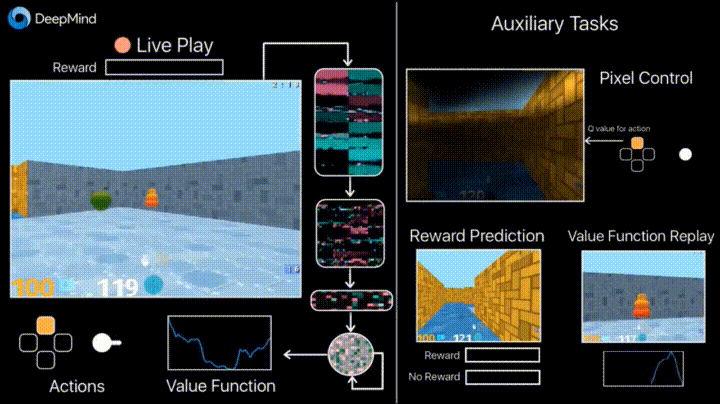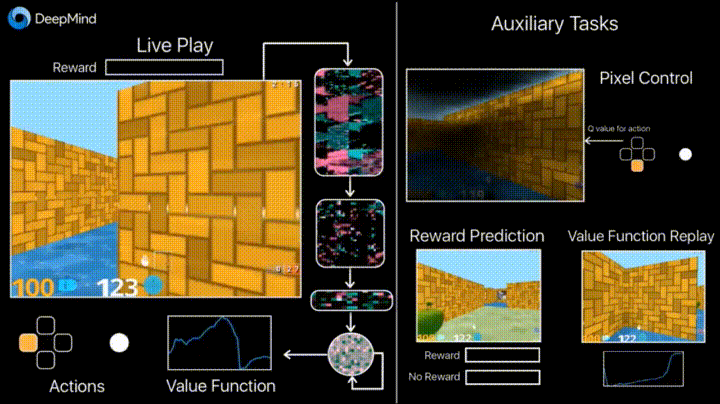
Результаты обучения:
4.2. Обучающиеся роботы
В OpenAI активно исследуют обучение человеком агента в виртуальной среде, что более безопасно для экспериментов, чем в реальной жизни ;)
В одном из исследований команда показала, что one-shot learning возможно: человек показывает в VR, как выполнить определенную задачу, и алгоритму достаточно одной демонстрации, чтобы выучить ее и далее воспроизвести в реальных условиях.

Эх, если бы с людьми было так просто ;)
4.3. Обучение на человеческих предпочтениях
Работа OpenAI и DeepMind на ту же тему. Суть состоит в следующем: у агента есть некая задача, алгоритм предоставляет на суд человеку два возможных варианта решения, и человек указывает, какой лучше. Процесс повторяется итеративно, и алгоритм за 900 бит обратной связи (бинарной разметки) от человека выучился решать задачу.


Как всегда, человеку надо быть осторожным и думать, чему он учит машину. Например, оценщик решил, что алгоритм действительно хотел взять объект, но на самом деле тот лишь имитировал это действие.
4.4. Движение в сложных окружениях
Еще одно исследование от DeepMind. Чтобы научить робота сложному поведению (ходить/прыгать/…), да еще и похожему на человеческое, нужно сильно заморочиться с выбором функции потерь, которая будет поощрять нужное поведение. Но хотелось бы, чтобы алгоритм сам выучивал сложное поведение, опираясь на простые reward.
Исследователям удалось этого добиться: они научили агентов (эмуляторы тел) совершать сложные действия с помощью конструирования сложной среды с препятствиями и с простым reward за прогресс в передвижении.

Впечатляющее видео с результатами. Но оно гораздо забавнее с наложенным звуком ;)
Напоследок дам ссылку на опубликованные недавно алгоритмы обучения RL от OpenAI. Теперь можно использовать более современные решения, чем уже ставший стандартным DQN.
5. Прочее
5.1. Охлаждение дата-центра
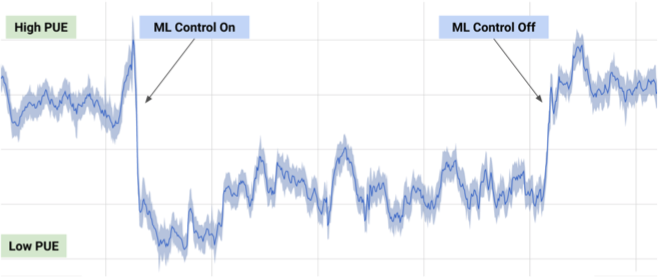
В июле 2017-го Google рассказала, что воспользовалась разработками DeepMind в машинном обучении, чтобы сократить энергозатраты своего дата-центра.
На основе информации с тысяч датчиков в дата-центре разработчики Google натренировали ансамбль нейросетей для предсказания PUE (Power Usage Effectiveness) и более эффективного управления дата-центром. Это впечатляющий и значимый пример практического применения ML.
5.2. Одна модель на все задачи
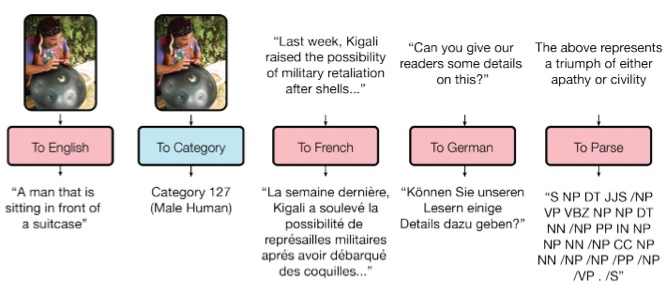
Как вы знаете, обученные модели плохо переносятся от задачи к задаче, под каждую задачу приходится обучать/дообучать специфичную модель. Небольшой шаг в сторону универсальности моделей сделала Google Brain в своей статье «One Model To Learn Them All».
Исследователи обучили модель, которая выполняет восемь задач из разных доменов (текст, речь, изображения). Например, перевод с разных языков, парсинг текста, распознавание изображений и звука.
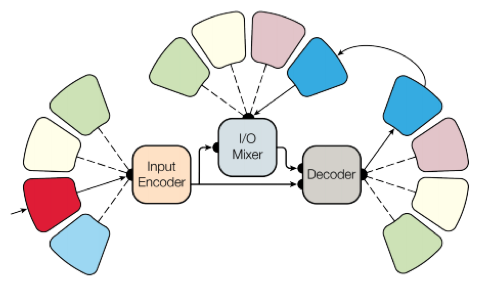
Для достижения этой цели сделали сложную архитектуру сети с различными блоками для обработки разных входных данных и генерирования результата. Блоки для encoder/decoder делятся на три типа: сверточные, attention, gated mixture of experts (MoE).
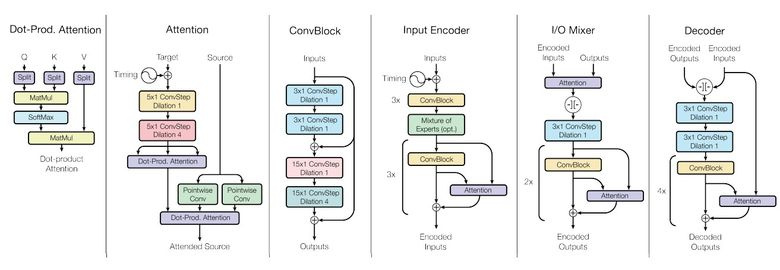
Основные итоги обучения:
- получились почти совершенные модели (авторы не делали тонкой настройки гиперпараметров);
- происходит передача знаний между разными доменами, то есть на задачах с большим количеством данных производительность будет почти такой же. А на маленьких задачах (например, на парсинге) — лучше;
- блоки, нужные для разных задач, не мешают друг другу и даже иногда помогают, например, MoE — для Imagenet-задачи.
Кстати, эта модель есть в tensor2tensor.
5.3. Обучение на Imagenet за один час
В своем посте сотрудники Facebook рассказали, как их инженеры смогли добиться обучения модели Resnet-50 на Imagenet всего за один час. Правда, для этого потребовался кластер из 256 GPU (Tesla P100).
Для распределенного обучения использовали Gloo и Caffe2. Чтобы процесс шел эффективно, пришлось адаптировать стратегию обучения при огромном батче (8192 элемента): усреднение градиентов, фаза прогрева, специальные learning rate и тому подобное. Подробнее в статье.
В итоге удалось добиться эффективности 90% при масштабировании от 8 к 256 GPU. Теперь исследователи из Facebook могут экспериментировать еще быстрее, в отличие от простых смертных без такого кластера ;)
6. Новости
6.1. Беспилотные автомобили
Сфера беспилотных автомобилей интенсивно развивается, и машины активно тестируют в боевых условиях. Из относительно недавних событий можно отметить покупку Intel«ом MobilEye, скандал вокруг Uber и украденных экс-сотрудником Google технологий, первую смерть при работе автопилота и многое другое.
Отмечу один момент: Google Waymo запускает бета-программу. Google — пионер в этой области, и предполагается, что их технология очень хороша, ведь машины наездили уже более 3 млн миль.
Также совсем недавно беспилотным автомобилям разрешили колесить по всем штатам США.
6.2. Здравоохранение
Как я уже говорил, современный ML начинает внедряться в медицину. Например, Google сотрудничает с медицинским центром для помощи диагностам.
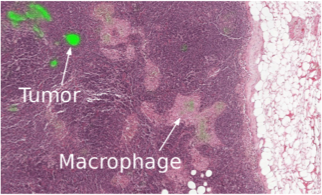
Deepmind создал даже отдельное подразделение.

В этом году в рамках Data Science Bowl был проведен конкурс по предсказанию рака легких через год на основе подробных снимков, призовой фонд — один миллион долларов.
6.3. Инвестиции
Сейчас много и усердно инвестируют в ML, как до этого — в BigData.
КНР вкладывает 150 млрд долларов в AI, чтобы стать мировым лидером индустрии.
Для сравнения, в Baidu Research работает 1300 человек, а в том же FAIR (Facebook) — 80. На последнем KDD сотрудники Alibaba рассказывали про свой parameter server KungPeng, который работает на 100 миллиардных выборках при триллионе параметров, что «становится обычной задачей» ©.

Делайте выводы, изучайте ML. Так или иначе со временем все разработчики будут использовать машинное обучение, что станет одной из компетенций, как сегодня — умение работать с базами данных.
