Docker swarm mode (режим роя)

На хабре уже писали про Docker swarm mode (режим роя), который является новой фичей версии 1.12. Данная опция внесла небольшую путаницу в головы тех, кто знаком с отдельно стоящей реализацией Docker Swarm имевшей распространение ранее и не отличавшейся удобством настройки и использования. Однако, после добавления Swarm в коробку с Docker все стало намного проще, очевиднее и функциональнее.
Подробнее о том, как устроен новый кластер Docker контейнеров с точки зрения пользователя, а также о простом и удобном способе разворачивания сервисов Docker на произвольной инфраструктуре далее под катом.
Для начала, как я и обещал в предыдущей статье, с небольшой задержкой, но все же выпущен релиз Fabricio с поддержкой сервисов Docker. При этом по-прежнему сохраняется возможность работать с отдельными контейнерами, плюс, остались неизменными интерфейс пользователя и разработчика конфигурации, что значительно упрощает переход от конфигураций, основанных на отдельных контейнерах к отказоустойчивым и горизонтально масштабируемым сервисам.
Активация Docker swarm mode
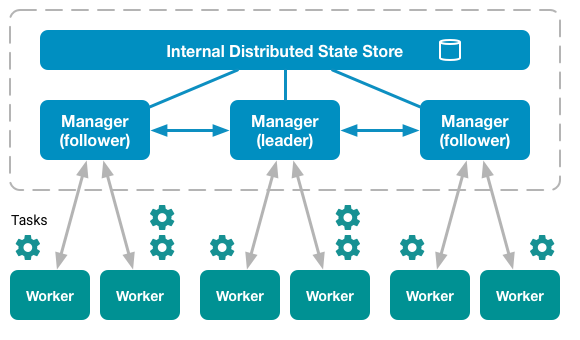
В режиме swarm все ноды делятся на два типа: manager и worker. При этом полноценный кластер может обходиться без рабочих нод вообще, то есть менеджеры по-умолчанию являются также и рабочими.
Среди менеджеров всегда присутствует один, который на данный момент является лидером кластера. Все управляющие команды, которые выполняются на других менеджерах автоматически перенаправляются на него.
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
6pbqkymsgtnahkqyyw7pccwpz * docker-1 Ready Active Leader
avjehhultkslrlcrevaqc4h5f docker-2 Ready Active Reachable
cg1maoa11ep7h14f2xciwylf3 docker-3 Ready Active Reachable
Для включения режима swarm достаточно выбрать хост, который будет начальным лидером в будущем кластере, и выполнить на нем всего одну команду:
docker swarm init
После того, как «рой» инициализирован, он уже готов для запуска не нем любого количества сервисов. Правда, состояние такого кластера будет неконсистентным (консистентное состояние достигается при количестве менеджеров не менее 3). И конечно ни о каком масштабировании и отказоустойчивости в этом случае речи также быть не может. Для этого к кластеру нужно подключить еще хотя бы две управляющие ноды. Узнать о том, как это сделать, можно выполнив на лидере следующие команды:
$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-1yptom678kg6hryfufjyv1ky7xc4tx73m8uu2vmzm1rb82fsas-c12oncaqr8heox5ed2jj50kjf \
172.28.128.3:2377
$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-1yptom678kg6hryfufjyv1ky7xc4tx73m8uu2vmzm1rb82fsas-511vapm98iiz516oyf8j00alv \
172.28.128.3:2377
Добавлять и удалять ноды можно в любой момент жизни кластера — это никаким серьезным образом не влияет на его работоспособность.
Создание сервиса
Создание сервиса в Docker принципиально не отличается от создания контейнера:
docker service create --name nginx --publish 8080:80 --replicas 2 nginx:stable-alpine
Отличия, как правило, заключаются в различном наборе опций. Например, у сервиса нет опции --volume, но есть опция --mount — эти опции позволяют подключать к контейнерам локальные ресурсы нод, но делают это по-разному.
Обновление сервиса
Здесь начинается самое большое отличие работы контейнеров от работы кластера контейнеров (сервиса). Обычно, чтобы обновить одиночный контейнер, приходится останавливать текущий и запускать новый. Это приводит хоть и к незначительному, но существующему времени простоя вашего сервиса (если вы не озаботились о том, чтобы обрабатывать такие ситуации при помощи других инструментов).
При использовании сервиса с количеством реплик не менее 2 простоя сервиса в большинстве случаев не присходит. Это достигается за счет того, что Docker обновляет контейнеры сервиса по очереди. То есть в один и тот же момент времени всегда есть хотя бы один работающий контейнер, который может обслужить запрос пользователя.
Для обновления (в том числе добавления и удаления) свойств сервиса, которые могут иметь несколько значений (например, --publish или --label), Docker предлагает использовать специальные опции, оканчивающиеся суффиксами -add и -rm:
# добавление в сервис новой метки
docker service update --label-add foo=bar nginx
Удаление некоторых опций, однако, менее тривиально и часто зависит от самой опции:
# метки удаляются по имени
docker service update --label-rm foo nginx
# порты удаляются по значению порта назначения (target port)
docker service update --publish-rm 80 nginx
Подробности о каждой опции можно узнать в описании команды docker service update.
Масштабирование и балансировка
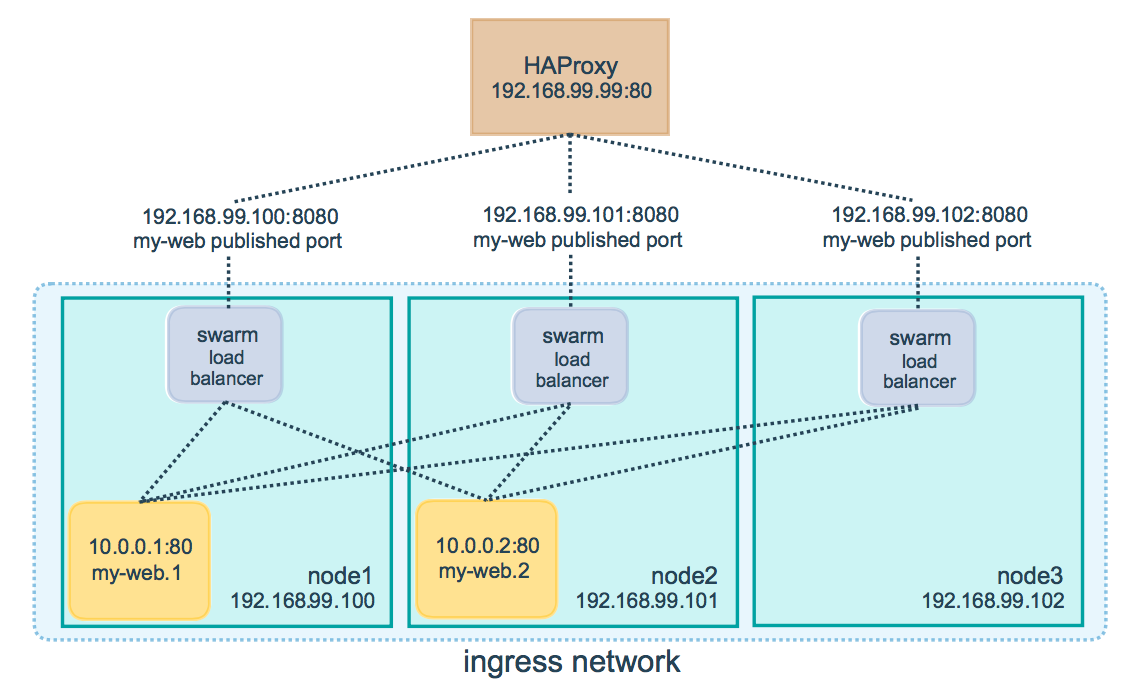
Для распределения запросов между имеющимися нодами Docker используется схема называемая ingress load balacing. Суть этого механизма заключается в том, что на какую бы из нод не пришел запрос пользователя, он сначала пройдет через внутренний механизм балансировки, а затем будет перенаправлен на ту ноду, которая в данный момент может обслужить такой запрос. То есть, любая нода способна обработать запрос к любому из сервисов кластера.
Масштабирование сервиса Docker достигается за счет указания необходимого количества реплик. В тот момент, когда вам необходимо увеличить (или уменьшить) количество нод, обслуживающих запросы от клиента, вы просто обновляете свойства сервиса с указанием нужного значения опции --replicas:
docker service update --replicas 3 nginx
В этом случае надо не забыть предварительно убедиться, что количество доступных нод не меньше, чем количество реплик, которые вы хотите использовать. Хотя ничего страшного не произойдет даже если нод меньше, чем реплик — просто некоторые ноды запустят у себя более одного контейнера одного и того же сервиса (в противном случае Docker будет стараться запускать реплики одного сервиса на разных нодах).
Отказоустойчивость

Отказоустойчивость сервиса гарантируется самим Docker. Это достигается в том числе за счет того, что в кластере могут одновременно работать несколько управляющих нод, которые могут в любой момент заменить вышедшего из строя лидера. Если говорить более подробно, то используется так называемый алгоритм поддержания распределенного консенсуса — Raft. Интересующимся рекомендую посмотреть эту замечательную визуальную демонстрацию: Raft в работе.
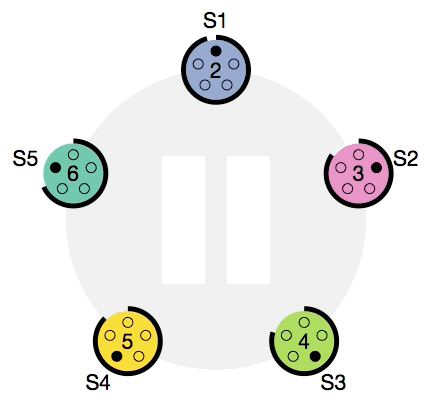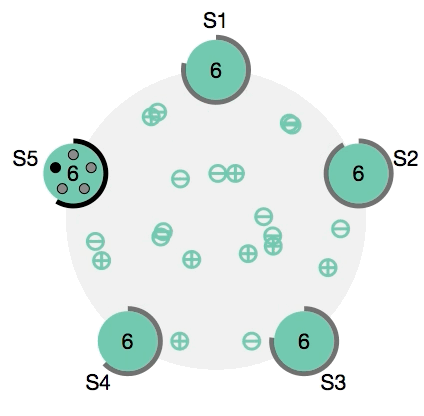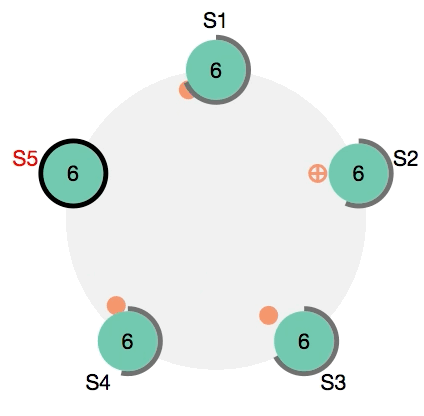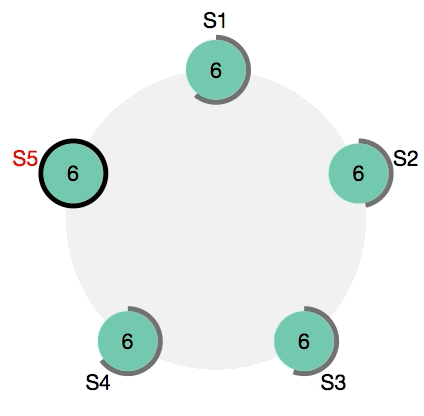
Автоматический деплой
Деплой новой версии приложения на боевые сервера всегда сопровождается риском того, что что-то пойдет не так. Именно поэтому считается плохой приметой выкатывать новую версию приложения перед выходными и праздниками. Причем, перед длительными праздниками, вроде новогодних каникул, любые изменения на боевой инфраструктуре прекращаются за неделю, а то и за две до их начала.
Несмотря на то, что сервисы Docker предлагают вполне надежный способ запуска и обновления приложения, довольно часто быстрый откат к предыдущей версии затруднен по той или иной причине, что может служить причиной недоступности вашего сервиса пользователям в течении многих часов.
Самый надежный способ избежать проблем при обновлении приложения — автоматизация и тестирование. Именно для этого разрабатываются системы автоматического деплоя. Важной частью таких систем, как правило, является возможность быстрого обновления и отката к предыдущей версии на любой выбранной инфраструктуре.
Fabricio
Большинство инструментов для автоматизации деплоя предлагают описывать конфигурацию при помощи популярных языков разметки вроде XML или YAML. Некоторые идут дальше и разрабатывают свой собственный язык описания таких конфигураций (например, HCL или Puppet language). Я же не вижу необходимости идти ни по одному из этих путей по следующим причинам:
- XML/YAML никогда не сравнятся по возможностям расширения и использования с полноценными языками программирования, а стремление упростить конфигурирование через использование упрощенной разметки часто наоборот, лишь все усложняет Плюс, мало кто из программистов захочет программировать на XML/YAML, а ведь конфигурирование — это и есть частный случай программирования.
- Разработка своего собственного языка программирования — чрезвычайно сложный и утомительный процесс, чаше всего нестоящий затрачиваемых на него усилий.
Поэтому Fabricio для описания конфигураций использует обычный Python и часть надежных и проверенных временем библиотек (среди них небезизвестный Fabric).
Конечно, многие могут возразить по этому поводу, что мол не все разработчики и DevOps знают Python. Ну, во-первых, Python (так же как и Bash) входит в джентльменский набор скриптовых языков, которые должен знать каждый уважающий себя DevOps (ну или почти каждый). А во-вторых, как это не парадоксально, знать Python практически необязательно. В подтверждение своих слов привожу пример конфигурации сервиса основанного на Django для Fabricio:
from fabricio import tasks
from fabricio.apps.python.django import DjangoService
django = tasks.DockerTasks(
service=DjangoService(
name="django",
image="project/django",
options={
"publish": "8080:80",
"env": "DJANGO_SETTINGS_MODULE=my_settings",
"replicas": 3,
},
),
hosts=["user@manager1", "user@manager2", "user@manager3"],
)
Согласитесь, что этот пример не сложнее, чем аналогичное описание на YAML. Человек, владеющий хотя бы одним языком программирования, разберется в данном конфиге без особых проблем.
Но довольно лирики.
Процесс деплоя
Схематически процесс деплоя сервиса при помощи Fabricio выглядит так, как представлено на рисунке ниже (после выполнения команды fab django для описанного выше конфига):

Рассмотрим каждый пункт по порядку. Для начала, сразу хочу заметить, что представленная схема актуальна при включенном режиме параллельного выполнения (с указанной опцией --parallel). Отличие последовательного режима только в том, что все действия в нем выполняются строго последовательно.
Сразу после запуска команды деплоя последовательно начинают выполняться следующие шаги:
- pull, одновременно на всех нодах запускается процесс скачивания нового образа Docker. Замечу, что в конфигурации достаточно указать только адреса управляющих нод (менеджеров), при этом даже необязательно перечислять всех имеющихся менеджеров — неуказанные ноды будут автоматически обновлены самим Docker. Хотя ничто не мешает указать в конфигурации в том числе и воркеров (в некоторых случаях это бывает необходимо, например, при использовании SSH туннеля).
- migrate, следующий шаг — применение миграций. Важно, чтобы этот шаг одновременно выполнялся только на одной из текущих нод, поэтому Fabricio в этом случае использует специальный механизм, гарантирующий, что процесс миграции будет запущен только на одной ноде и выполнится только один раз.
- update, так как для обновления всех контейнеров сервиса команду update достаточно выполнить только один раз, то Fabricio на этом шаге также следит за тем, чтобы она не была выполнена дважды.
Каждую команду (pull, migrate, update) в случае необходимости можно выполнить отдельно. В процесс деплоя также можно включить дополнительные шаги (prepare, push, backup) как описано в этой более ранней обзорной статье про Fabricio.
Все команды Fabricio (кроме backup и restore) являются идемпотентными, то есть безопасными при повторном выполнении с теми же самыми параметрами.
$ fab --parallel nginx
[vagrant@172.28.128.3] Executing task 'nginx.pull'
[vagrant@172.28.128.4] Executing task 'nginx.pull'
[vagrant@172.28.128.5] Executing task 'nginx.pull'
[vagrant@172.28.128.5] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.4] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.3] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.3] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.3] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.3] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.3] out:
[vagrant@172.28.128.4] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.4] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.4] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.4] out:
[vagrant@172.28.128.5] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.5] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.5] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.5] out:
[vagrant@172.28.128.3] Executing task 'nginx.migrate'
[vagrant@172.28.128.4] Executing task 'nginx.migrate'
[vagrant@172.28.128.5] Executing task 'nginx.migrate'
[vagrant@172.28.128.5] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.4] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] Executing task 'nginx.update'
[vagrant@172.28.128.4] Executing task 'nginx.update'
[vagrant@172.28.128.5] Executing task 'nginx.update'
[vagrant@172.28.128.5] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.4] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.3] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.3] run: docker inspect --type container nginx_current
[vagrant@172.28.128.3] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.4] run: docker inspect --type container nginx_current
[vagrant@172.28.128.3] run: docker service inspect nginx
[vagrant@172.28.128.4] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] No changes detected, update skipped.
[vagrant@172.28.128.4] No changes detected, update skipped.
[vagrant@172.28.128.5] run: docker inspect --type container nginx_current
[vagrant@172.28.128.5] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.5] No changes detected, update skipped.
Done.
Disconnecting from vagrant@127.0.0.1:2222... done.
Disconnecting from vagrant@127.0.0.1:2200... done.
Disconnecting from vagrant@127.0.0.1:2201... done.
$ fab nginx
[vagrant@172.28.128.3] Executing task 'nginx.pull'
[vagrant@172.28.128.3] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.3] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.3] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.3] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.3] out:
[vagrant@172.28.128.4] Executing task 'nginx.pull'
[vagrant@172.28.128.4] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.4] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.4] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.4] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.4] out:
[vagrant@172.28.128.5] Executing task 'nginx.pull'
[vagrant@172.28.128.5] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.5] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.5] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.5] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.5] out:
[vagrant@172.28.128.3] Executing task 'nginx.migrate'
[vagrant@172.28.128.3] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.4] Executing task 'nginx.migrate'
[vagrant@172.28.128.4] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.5] Executing task 'nginx.migrate'
[vagrant@172.28.128.5] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] Executing task 'nginx.update'
[vagrant@172.28.128.3] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.3] run: docker inspect --type container nginx_current
[vagrant@172.28.128.3] run: docker service inspect nginx
[vagrant@172.28.128.3] No changes detected, update skipped.
[vagrant@172.28.128.4] Executing task 'nginx.update'
[vagrant@172.28.128.4] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.4] run: docker inspect --type container nginx_current
[vagrant@172.28.128.4] No changes detected, update skipped.
[vagrant@172.28.128.5] Executing task 'nginx.update'
[vagrant@172.28.128.5] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.5] run: docker inspect --type container nginx_current
[vagrant@172.28.128.5] No changes detected, update skipped.
Done.
Disconnecting from vagrant@172.28.128.3... done.
Disconnecting from vagrant@172.28.128.5... done.
Disconnecting from vagrant@172.28.128.4... done.
Откат к предыдущей версии
Откат к предыдущей версии (команда fab django.rollback для ранее описанной конфигурации) во многом аналогичен процессу деплоя:
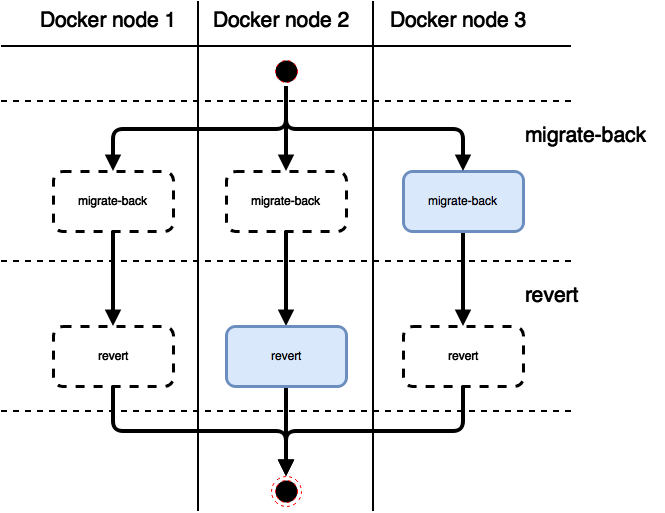
И откат миграций, и откат самого сервиса к предыдущему состоянию выполняются строго один раз на одной из менеджерских нод.
Заключение
За контейнерезацией будущее серверной разработки. Те, кто этого еще не осознал, скоро будут поставлены перед свершившимся фактом. Контейнеры — удобное, простое и мощное оружие в руках разработчиков и DevOps.
С выходом Docker 1.12 у сторонников Kubernetes практически не осталось аргументов в пользу использования последнего. Сервисы Docker не только обеспечивают все те же возможности, что и сервисы Kubernetes, но при этом обладают даже рядом преимуществ, благодаря простоте настройки на любой ОС (Linux, macOS, Windows) и отсутствию необходимости установки и запуска дополнительных компонентов (контейнеров).
Fabricio — инструмент, помогающий в разработке, тестировании и выкладке новых версий приложений на боевые и тестовые сервера при помощи Docker — теперь поддерживает разворачивание масштабируемых и отказоустойчивых сервисов. С различными вариантами использования Fabricio можно познакомиться на странице с примерами и рецептами (все примеры подробно описаны и автоматизированы при помощи Vagrant).
Подробно о Fabricio я надеюсь рассказать на мероприятии DevOpsDays в Москве. Приходите, будет о чем пообщаться и узнать много нового.
Комментарии (3)
12 января 2017 в 18:09
0↑
↓
>>> С выходом Docker 1.12 у сторонников Kubernetes практически не осталось аргументов в пользу использования последнего. Сервисы Docker не только обеспечивают все те же возможности, что и сервисы KubernetesНе вовдите людей в заблуждение, попробуйте в swarm mode сделать аналог куберовского пода, это первое что в голову пришло.
Второе, docker run дает куда более большее колличество ручек, чем docker service create, отсюда классический swarm, который просто обвертка для апи докера, позволяет делать куда более гибкие вещи, вернемся к аналогу пода кубернетовского, у docker run есть ключики --ipc и --network, через которые можно шарить один неймспейс для нескольких контейнеров.
Ну это так, на вскидку, не вдаваясь в дебри renskiy
renskiy
12 января 2017 в 18:25 (комментарий был изменён)
0↑
↓
попробуйте в swarm mode сделать аналог куберовского пода
Исходя из этого описания пода, я так понимаю, что это не более чем логическая группа контейнеров со своими «namespaces and shared volumes». Так чего же из этого нет сейчас в Docker?
12 января 2017 в 18:24
+1↑
↓
Спасибо! Планирую использовать фабрицио для деплоя текущего проекта.
Ждем новых плюшек. Еще раз спасибо, желаю уверенного развития тулзы.
