Чтобы распознавать картинки, не нужно распознавать картинки
Посмотрите на это фото.
Это совершенно обычная фотография, найденная в гугле по запросу «железная дорога». И сама дорога тоже ничем особенным не отличается.
Что будет, если убрать это фото и попросить вас нарисовать железную дорогу по памяти?
Если вы ребенок лет семи, и никогда раньше не учились рисовать, то очень может быть, что у вас получится что-то такое:  Упс. Кажется, что-то пошло не так.
Упс. Кажется, что-то пошло не так.
Давайте еще раз вернемся к рельсам на первой картинке и попробуем понять, что не так.На самом деле, если долго разглядывать ее, становится понятно, что она не совсем точно отображает окружающий мир. Главная проблема, о которую мы немедленно споткнулись — там, например, пересекаются параллельные прямые. Ряд одинаковых (в реальности) фонарных столбов на самом деле изображен так, что каждый следующий столб имеет все меньшие и меньшие размеры. Деревья вокруг дороги, у которых поначалу различимы отдельные ветки и листья, сливаются в однотонный фон, который еще и вдобавок почему-то приобретает отчетливо-фиолетовый оттенок.Все это — эффекты перспективы, последствия того, что трехмерные объекты снаружи проецируются на двумерную сетчатку внутри глаза. Ничего отдельно магического в этом нет — разве что немного любопытно, почему эти искажения контуров и линий не вызывают у нас никаких проблем при ориентации в пространстве, но вдруг заставляют мозг напрячься при попытке взяться за карандаш.
Еще один замечательный пример — как маленькие дети рисуют небо.
 Небо должно быть наверху — вот она, синяя полоска, пришпиленная к верхнему краю. Середина листа при этом остается белой, заполнена пустотой, в которой плавает солнце.
Небо должно быть наверху — вот она, синяя полоска, пришпиленная к верхнему краю. Середина листа при этом остается белой, заполнена пустотой, в которой плавает солнце.
И так происходит всегда и везде. Мы знаем, что куб состоит из квадратных граней, но посмотрите на картинку, и вы не увидите там ни одного прямого угла — более того, эти углы постоянно меняются, стоит сменить угол обзора. Как будто где-то в голове у нас сохранена грубая схема правильного, трехмерного объекта, и именно к ней мы обращаемся в процессе рисования рельс, не сразу успевая сопоставить результат с тем, что видим своими глазами.
На самом деле все еще хуже. Каким образом, например, на самой первой картинке с дорогой мы определяем, какая часть дороги расположена ближе к нам, а какая дальше? По мере удаления предметы становятся меньше, ок —, но вы уверены, что кто-то не обманул вас, коварно разместив друг за другом последовательно уменьшающиеся шпалы? Далекие объекты обычно имеет бледно-голубоватый оттенок (эффект, который называется «атмосферная перспектива») —, но предмет может быть просто окрашен в такой цвет, и в остальном казаться совершенно нормальным. Мост через железнодорожные пути, который едва видно отсюда, кажется нам находящимся позади, потому что его заслоняют фонари (эффект окклюзии) —, но опять-таки, как вы можете быть уверены, что фонари просто не нарисованы на его поверхности? Весь этот набор правил, с помощью которых вы оцениваете трехмерность сцены, во многом зависит от вашего опыта, и возможно, генетического опыта ваших предков, обученных выживать в условиях нашей атмосферы, падающего сверху света и ровной линии горизонта.
Сама по себе, без помощи мощной аналитической программы в вашей голове, наполненной этим визуальным опытом, любая фотография говорит об окружающем мире ужасно мало. Изображения — это скорее такие триггеры, заставляющие вас мысленно представить себе сцену, большая часть знаний о которой уже есть у вас в памяти. Они не содержат реальных предметов — только ограниченные, сплющенные, трагически двумерные представления о них, которые, к тому же, постоянно меняются при движении. В чем-то мы с вами — такие же жители Флатландии, которые могут увидеть мир только с одной стороны и неизбежно искаженным.
больше перспективы Вообще мир вокруг прямо-таки полон свидетельств того, как перспектива все искажает. Люди, поддерживающие пизанскую башню, фотографии с солнцем в руках, не говоря уже про классические картины Эшера, или вот совершенно прекрасный пример — Комната Эймса. Тут важно понять, что это не какие-то единичные подлянки, специально сделаные для того, чтобы обманывать. Перспектива всегда показывает нам неполноценную картинку, просто как правило, мы способны ее «раскодировать». Попробуйте выглянуть в окно и подумать, что то, что вы видите — обман, искажение, безнадежная неполноценность.
Представьте, что вы — нейронная сеть.Это не должно быть очень сложно — в конце концов, как-о так оно и есть на самом деле. Вы проводите свободное время за распознаванием лиц на документах в паспортном столе. Вы — очень хорошая нейронная сеть, и работа у вас не слишком сложная, потому что в процессе вы ориентируетесь на паттерн, строго характерный именно для человеческих лиц — взаимное расположение двух глаз, носа и рта. Глаза и носы сами по себе могут различаться, какой-то один из признаков иногда может оказаться на фотографии неразличимым, но вам всегда помогает наличие других. И вдруг вы натыкаетесь вот на такое:

Хм, думаете вы. Вы определенно видите что-то знакомое — по крайней мере, в центре, кажется, есть один глаз. Правда, странной формы — он похож на треугольник, а не на заостренный овал. Второго глаза не видно. Нос, который должен располагаться посередине и между глаз, уехал куда-то совсем в край контура, а рта вы вообще не нашли — опредленно, темный уголок снизу-слева совсем на него не похож. Не лицо — решаете вы, и выбрасываете картинку в мусорное ведро.
Так бы мы думали, если бы наша зрительная система занималась простым сопоставлением паттернов в изображениях. К счастью, думает она как-то по-другому. У нас не вызывает никакого беспокойства отсутствие второго глаза, от этого лицо не становится менее похожим на лицо. Мы мысленно прикидываем, что второй глаз должен находиться по ту сторону, и форма его обусловлена исключительно тем, что голова на фото повернута и смотрит в сторону. Кажется невозможно тривиальным, когда пытаешься это объяснить на словах, но кое-кто с вами бы на полном серьезе не согласился.
Самое обидное, что не видно, как можно решить этот вопрос механическим способом. Компьютерное зрение сталкивалось с соответствующими проблемами очень давно, с момента своего появления, и периодически находило эффективные частные решения — так, мы можем опознать сдвинутый в сторону предмет, последовательно передвигая свой проверочный паттерн по всему изображению (чем успешно пользуются сверточные сети), можем справляться с отмасштабированными или повернутыми картинками с помощью признаков SIFT, SURF и ORB, но эффекты перспективы и поворот предмета в пространстве сцены — похоже, вещи качественно другого уровня. Здесь нам нужно знать, как предмет выглядит со всех сторон, получить его истинную трехмерную форму, иначе нам не с чем работать. Поэтому чтобы распознавать картинки, не нужно распознавать картинки. Они лживы, обманчивы и заведомо неполноценны. Они — не наши друзья.
Итак, важный вопрос — как бы нам получать трехмерную модель всего, что мы видим? Еще более важный вопрос — как при этом обойтись без необходимости покупать лазерный пространственный сканер (сначала я написал «чертовски дорогой лазерный сканер», а потом наткнулся на этот пост)? Даже не столько по той причине, что нам жалко, а потому, что животные в процессе эволюции зрительной системы явно каким-то образом обошлись без него, одними только глазами, и было бы любопытно выяснить, как они так.Где-то в этом месте часть аудитории обычно встает и выходит из зала, ругаясь на топтание по матчасти — все знают, что для восприятия глубины и пространства мы пользуемся бинокулярным зрением, у нас для этого два специальных глаза! Если вы тоже так думаете, у меня для вас небольшой сюрприз — это неправда. Доказательство прекрасно в своей простоте — достаточно закрыть один глаз и пройтись по комнате, чтобы убедиться, что мир внезапно не утратил глубины и не стал походить на плоский аналог анимационного мультфильма. Еще один способ — вернуться и снова посмотреть на фотографию с железной дорогой, где замечательно видно глубину даже при том, что она расположена на полностью плоской поверхности монитора.
Вообще с двумя глазами все не так просто Для некоторых действий они, похоже, и правда приносят пользу с точки зрения оценки пространственного положения. Возьмите два карандаша, закройте один глаз и попытайтесь сдвигать эти карандаши так, чтобы они соприкоснулись кончиками грифелей где-то вблизи вашего лица. Скорее всего, грифели разойдутся, причем ощутимо (если у вас получилось легко, поднесите их еще ближе к лицу), при этом со вторым открытым глазом такого не происходит. Пример взят из книги Марка Чангизи «Революция в зрении» — там есть целая глава о стереопсисе и бинокулярном зрении с любопытной теорией о том, что два смотрящих вперед глаза нужны нам для того, чтобы видеть сквозь мелкие помехи вроде свисающих листьев. Кстати, забавный факт — на первом месте в списке преимуществ бинокулярного зрения в Википедии стоит «It gives a creature a spare eye in case one is damaged».
Итак, бинокулярное зрение нам не подходит — и вместе с ним мы отвергаем стереокамеры, дальномеры и Kinect. Какой бы ни была способость нашей зрительной системы воссоздавать трехмерные образы увиденного, она явно не требует наличия двух глаз. Что остается в итоге?
Я ни в коем случае не готов дать точный ответ применительно к биологическом зрению, но пожалуй, для случая абстрактного робота с камерой вместо глаза остался один многообещающий способ. И этот способ — движение.
Вернемся к теме поездов, только на этот раз выглянем из окна:

То, что мы при этом видим, называется «параллакс движения», и вкратце он заключается в том, что когда мы двигаемся вбок, близкие предметы смещаются в поле зрения сильнее, чем далекие. Для движения вперед/назад и поворотов тоже можно сформулировать соответствующие правила, но давайте их пока проигнорируем. Итак, мы собираемся двигаться, оценивать смещения предметов в кадре и на основании этого определять их расстояние от наблюдателя — техника, которая официально называется «structure-from-motion». Давайте попробуем.
Прежде всего —, а не сделали ли все, случайно, до нас? Страница «Structure from motion» в Википедии предлагает аж тринадцать инструментов (и это только опенсорсных) для воссоздания 3D-моделей из видео или набора фотографий, большинство из них пользуются подходом под названием bundle adjustment, а самым удобным мне показался Bundler (и демо-результаты у него крутые). К сожалению, тут возникает проблема, с которой мы еще столкнемся — Bundler для корректной работы хочет знать от нас модель камеры и ее внутренние параметры (в крайнем случае, если модель неизвестна, он требует указать фокусное расстояние).Если для вашей задачи это не проблема — можете смело бросать чтение, потому что это самый простой и одновременно эффективный метод (а знаете, кстати, что примерно таким способом делались модели в игре «Исчезнование Итана Картера»?). Для меня, увы, необходимость быть привязанным к модели камеры — это условие, которого очень хотелось бы избежать. Во-первых, потому что у нас под боком полный ютуб визуального видео-опыта, которым хотелось бы в будущем пользоваться в качестве выборки. Во-вторых (и это, может быть, даже важнее), потому что наш с вами человеческий мозг, похоже, если и знает в цифрах внутренние параметры камеры наших глаз, то прекрасно умеет приспосабливаться к любым оптическим искажениями. Взгляд через объектив широкофокусной камеры, фишай, просмотр кино и ношение окулусрифта совершенно не разрушает ваших зрительных способностей. Значит, наверное, возможен и какой-то другой путь.
Итак, мы печально закрыли страницу с Итаном Картером википедии и опускаемся на уровень ниже — в OpenCV, где нам предлагают следующее:
1. Взять два кадра, снятые с откалиброванной камеры.2. Вместе с параметрами калибровки (матрицей камеры) положить их оба в функцию stereoRectify, которая выпрямит (ректифицирует) эти два кадра — это преобразование, которое искажает изображение так, чтобы точка и ее смещение оказывались на одной горизонтальной прямой.3. Эти ректифицированые кадры мы кладем в функцию stereoBM и получаем карту смещений (disparity map) — такую картинку в оттенках серого, где чем пиксель ярче, тем большее смещение он выражает (по ссылке есть пример).4. Полученную карту смещений кладем в функцию с говорящим названием reprojectImageTo3D (понадобится еще и матрица Q, которую в числе прочих мы получим на шаге 2). Получаем наш трехмерный результат.
Черт, похоже, мы наступаем на те же грабли — уже в пункте 1 от нас требуют откалиброванную камеру (правда, OpenCV милостиво дает возможность сделать это самому). Но погодите, здесь есть план Б. В документации прячется функция с подозрительным названием stereoRectifyUncalibrated…
План Б:
1. Нам нужно оценить примерную часть смещений самим — хотя бы для ограниченного набора точек. StereoBM здесь не подойдет, поэтому нам нужен какой-то другой способ. Логичным вариантом будет использовать feature matching — найти какие-то особые точки в обоих кадрах и выбрать сопоставления. Про то, как это делается, можно почитать здесь.2. Когда у нас есть два набора соответствующих друг другу точек, мы можем закинуть их в findFundamentalMat, чтобы получить фундаментальную матрицу, которая понадобится нам для stereoRectifyUncalibrated.3. Запускаем stereoRectifyUncalibrated, получаем две матрицы для ректификации обоих кадров. 4. И…, а дальше непонятно. Выпрямленные кадры у нас есть, но нет матрицы Q, которая была нужна для завершающего шага. Погуглив, я наткнулся примерно на такой же недоумения пост, и понял, что либо я что-то упустил в теории, либо в OpenCV этот момент не продумали.
OpenCV: мы — 2:0.
4.1 Меняем план Но погодите. Возможно, мы с самого начала пошли не совсем правильным путем. В предыдущих попытках мы, по сути, пытались определить реальное положение трехмерных точек — отсюда необходимость знать параметры камеры, матрицы, ректифицировать кадры и так далее. По сути, это обычная триангуляция: на первой камере я вижу эту точку здесь, а на второй здесь — тогда нарисуем два луча, проходящих через центры камер, и их пересечение покажет, как далеко точка от нас находится.Это все прекрасно, но вообще говоря, нам не нужно. Реальные размеры предметов интересовали бы нас, если бы наша модель использовалась потом для промышленных целей, в каких-нибудь 3d-принтерах. Но мы собираемся (эта цель слегка уже расплылась, правда) запихивать полученные данные в нейросети и им подобные классификаторы. Для этого нам достаточно знать только относительные размеры предметов. Они, как мы все еще помним, обратно пропорциональны смещениям параллакса — чем дальше от нас предмет, тем меньше смещается при нашем движении. Нельзя ли как-то найти эти смещения еще проще, просто каким-то образом сопоставив обе картинки?
Само собой, можно. Привет, оптический поток.
Это замечательный алгоритм, который делает ровно то, что нам нужно. Кладем в него картинку и набор точек. Потом кладем вторую картинку. Получаем на выходе для заданных точек их новое положение на второй картинке (приблизительное, само собой). Никаких калибровок и вообще никаких упоминаний о камере — оптический поток, несмотря на название, можно рассчитывать на базе чего угодно. Хотя обычно он все-таки используется для слежения за объектами, обнаружения столкновений и даже дополненной реальности.
Для наших целей мы (пока) хотим воспользоваться «плотным» потоком Гуннара Фарнебака, потому что он умеет рассчитывать поток не для каих-то отдельных точек, а для всей картинки сразу. Метод доступен с помощью calcOpticalFlowFarneback, и первые же результаты начинают очень-очень радовать — смотрите, насколько оно выглядит круче, чем предыдущий результат stereoRectifyUncalibrated + stereoBM.
 Большое спасибо замечательной игре Portal 2 за возможность строить собственные комнаты и играть в кубики. I’m doin' Science!
Большое спасибо замечательной игре Portal 2 за возможность строить собственные комнаты и играть в кубики. I’m doin' Science!
Код для для этой маленькой демонстрации # encoding: utf-8
import cv2 import numpy as np from matplotlib import pyplot as plt
img1 = cv2.imread ('0.jpg', 0) img2 = cv2.imread ('1.jpg', 0)
def stereo_depth_map (img1, img2): # 1: feature matching orb = cv2.ORB () kp1, des1 = orb.detectAndCompute (img1, None) kp2, des2 = orb.detectAndCompute (img2, None)
bf = cv2.BFMatcher (cv2.NORM_HAMMING, crossCheck=True) matches = bf.match (des1, des2) matches = sorted (matches, key=lambda x: x.distance)
src_points = np.vstack ([np.array (kp1[m.queryIdx].pt) for m in matches]) dst_points = np.vstack ([np.array (kp2[m.trainIdx].pt) for m in matches])
# 2: findFundamentalMat F, mask = cv2.findFundamentalMat (src_points, dst_points)
# 3: stereoRectifyUncalibrated _, H1, H2 = cv2.stereoRectifyUncalibrated (src_points.reshape (src_points.shape[ 0], 1, 2), dst_points.reshape (dst_points.shape[0], 1, 2), F, img1.shape)
rect1 = cv2.warpPerspective (img1, H1, (852, 480)) rect2 = cv2.warpPerspective (img2, H2, (852, 480))
# 3.5: stereoBM stereo = cv2.StereoBM (cv2.STEREO_BM_BASIC_PRESET, ndisparities=16, SADWindowSize=15) return stereo.compute (rect1, rect2)
def optical_flow_depth_map (img1, img2): flow = cv2.calcOpticalFlowFarneback (img1, img2, 0.5, 3, 20, 10, 5, 1.2, 0) mag, ang = cv2.cartToPolar (flow[…, 0], flow[…, 1]) return mag
def plot (title, img, i): plt.subplot (2, 2, i) plt.title (title) plt.imshow (img, 'gray') plt.gca ().get_xaxis ().set_visible (False) plt.gca ().get_yaxis ().set_visible (False)
plot (u’Первый кадр', img1, 1) plot (u’Второй кадр (шаг вправо)', img2, 2) plot (u’stereoRectifyUncalibrated', stereo_depth_map (img1, img2), 3) plot (u’Первый кадр', optical_flow_depth_map (img1, img2), 4)
plt.show () Итак, отлично. Смещения у нас есть, и на вид неплохие. Как теперь нам получить из них координаты трехмерных точек?
4.2 Часть, в которой мы получаем координаты трехмерных точек
Эта картинка уже мелькала на одной из ссылок выше.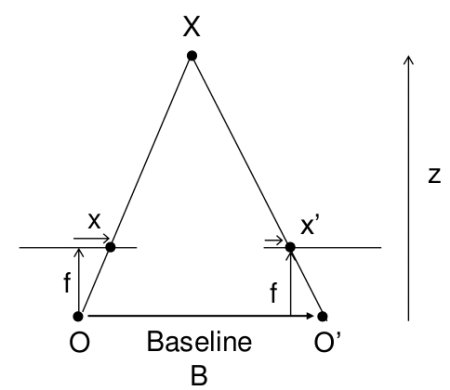
Расстояние до объекта здесь рассчитывается методом школьной геометрии (подобные треугольники), и выглядит так: 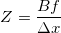 . А координаты, соответственно, вот так:
. А координаты, соответственно, вот так: 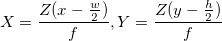 . Здесь w и h — ширина и высота картинки, они нам известны, f — фокусное расстояние камеры (расстояние от центра камеры до поверхности ее экрана), и B — камеры же шаг. Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
. Здесь w и h — ширина и высота картинки, они нам известны, f — фокусное расстояние камеры (расстояние от центра камеры до поверхности ее экрана), и B — камеры же шаг. Кстати, обратите внимание, что мы тут слегка нарушаем общепринятые названия осей, когда Z направлена вверх — у нас Z смотрит «вглубь» экрана, а X и Y — соответственно, направлены по ширине и высоте картинки.
Ну, насчет f все просто — мы уже оговаривали, что реальные параметры камеры нас не интересуют, лишь бы пропорции всех предметов изменялись по одному закону. Если подставить Z в формулу для X выше, то можно увидеть, что X от фокусного расстояния вообще не зависит (f сокращается), поэтому разные его значения буду менять только глубину — «вытягивать» или «сплющивать» нашу сцену. Визуально — не очень приятно, но опять же, для алгоритма классификации — совершенно все равно. Так что зададим фокусное расстояние интеллектуальным образом — просто придумаем. Я, правда, оставляю за собой право слегка изменить мнение дальше по тексту.
Насчет B чуть посложнее — если у нас нет встроенного шагомера, мы не знаем, на какую дистанцию переместилась камера в реальном мире. Так что давайте пока немного считерим и решим, что движение камеры происходит примерно плавно, кадров у нас много (пара десятков на секунду), и расстояние между двумя соседними примерно одинаковое, т.е.  . И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
. И опять же, дальше мы слегка уточним эту ситуацию, но пока пусть будет так.
Настало время написать немного кода import cv2 import numpy as np
f = 300 # раз мы занимаемся визуализацией, фокус я все-таки подобрал так, чтобы сцена выглядела условно реальной B = 1 w = 852 h = 480
img1 = cv2.imread ('0.jpg', 0) img2 = cv2.imread ('1.jpg', 0)
flow = cv2.calcOpticalFlowFarneback (img1, img2, 0.5, 3, 20, 10, 5, 1.2, 0) mag, ang = cv2.cartToPolar (flow[…, 0], flow[…, 1])
edges = cv2.Canny (img1, 100, 200)
result = [] for y in xrange (img1.shape[0]): for x in xrange (img1.shape[1]): if edges[y, x] == 0: continue delta = mag[y, x] if delta == 0: continue Z = (B * f) / delta X = (Z * (x — w / 2.)) / f Y = (Z * (y — h / 2.)) / f point = np.array ([X, Y, Z]) result.append (point)
result = np.vstack (result)
def dump2ply (points): # сохраняем в формат .ply, чтобы потом открыть Блендером with open ('points.ply', 'w') as f: f.write ('ply\n') f.write ('format ascii 1.0\n') f.write ('element vertex {}\n'.format (len (points))) f.write ('property float x\n') f.write ('property float y\n') f.write ('property float z\n') f.write ('end_header\n') for point in points: f.write ('{:.2f} {:.2f} {:.2f}\n'.format (point[0], point[2], point[1]))
dump2ply (result) Вот так выглядит результат. Надеюсь, эта гифка успела загрузиться, пока вы дочитали до этого места.
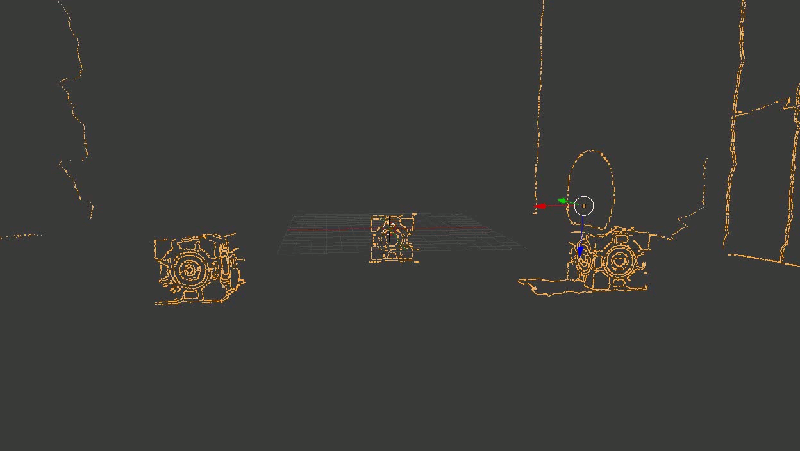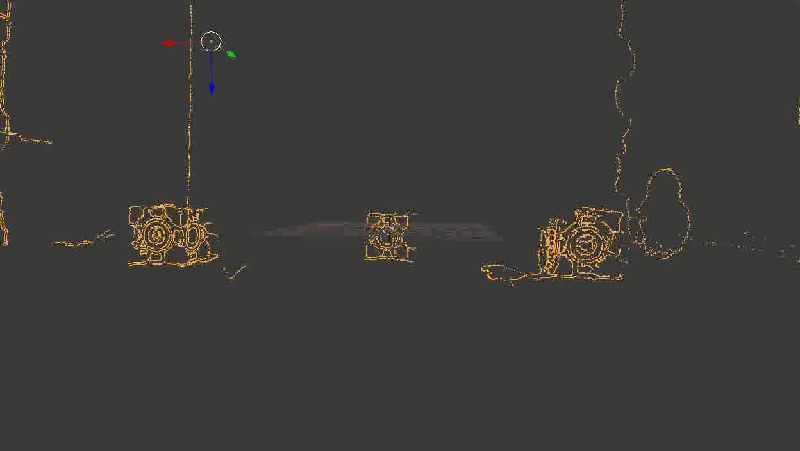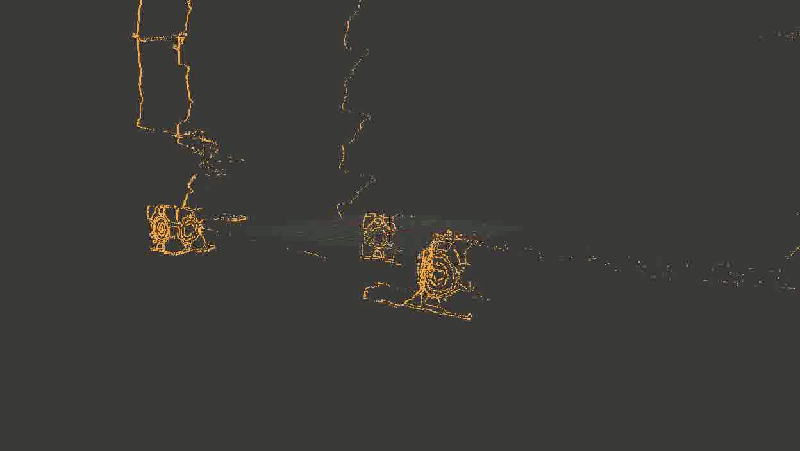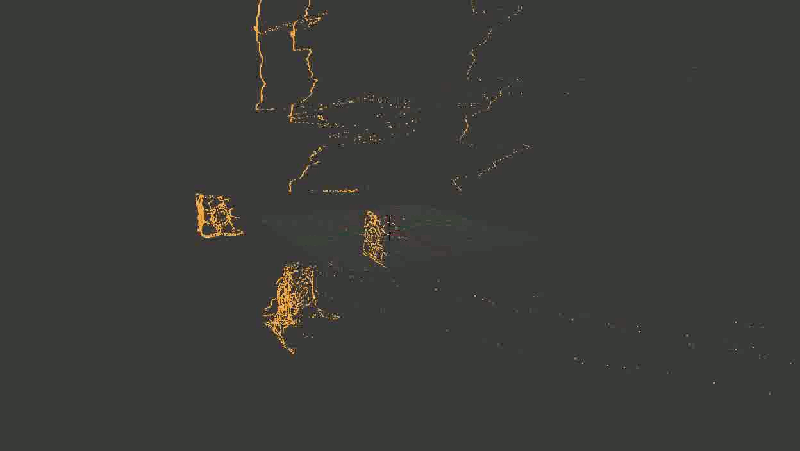 Для наглядности я взял не все точки подряд, а только границы, выделенные Canny-детектором
Для наглядности я взял не все точки подряд, а только границы, выделенные Canny-детектором
С первого взгляда (во всяком случае, мне) все показалось отличным — даже углы между гранями кубиков образовали симпатичные девяносто градусов. С предметами на заднем плане получилось похуже (обратите внимание, как исказились контуры стен и двери), но хэй, наверное, это просто небольшой шум, его можно будет вылечить использованием большего количества кадров или чем-нибудь еще.
Из всех возможных поспешных выводов, которые можно было здесь сделать, этот оказался дальше всех от истины.
В общем, основная проблема оказалась в том, что какая-то часть точек довольно сильно искажалась. И — тревожный знак, где уже пора было заподозрить неладное — искажалась не случайным образом, а примерно в одних и тех же местах, так что исправить проблему путем последовательного наложения новых точек (из других кадров) не получалось.Выглядело это примерно так:
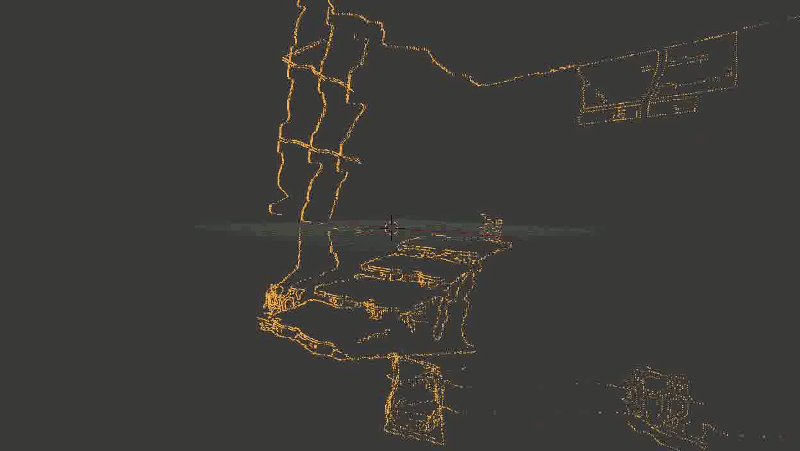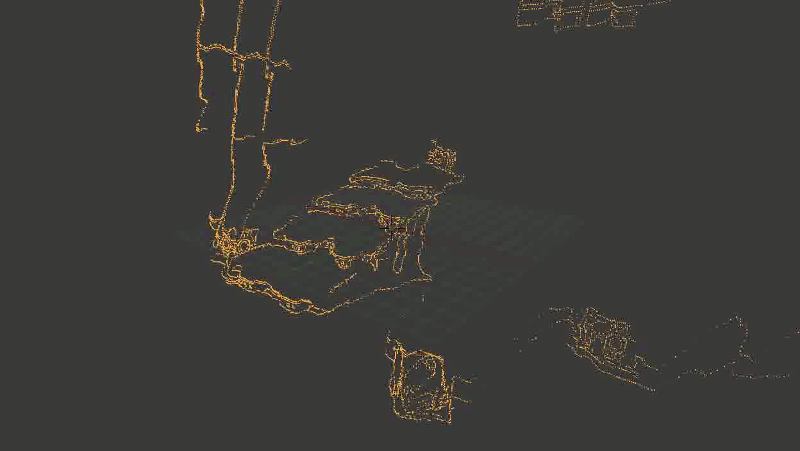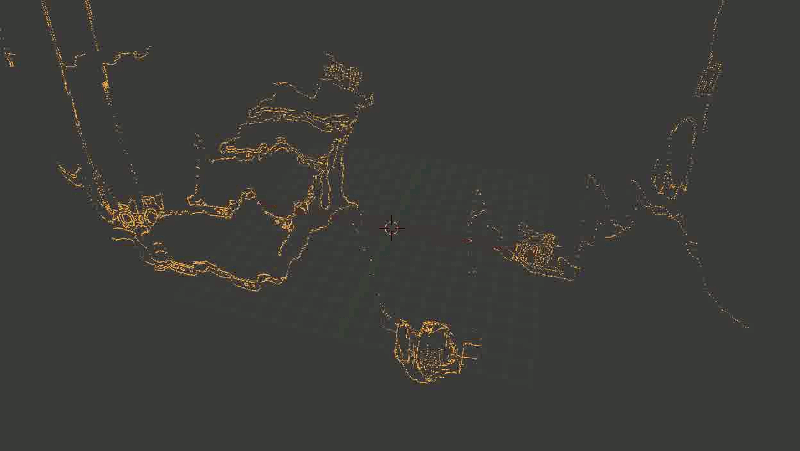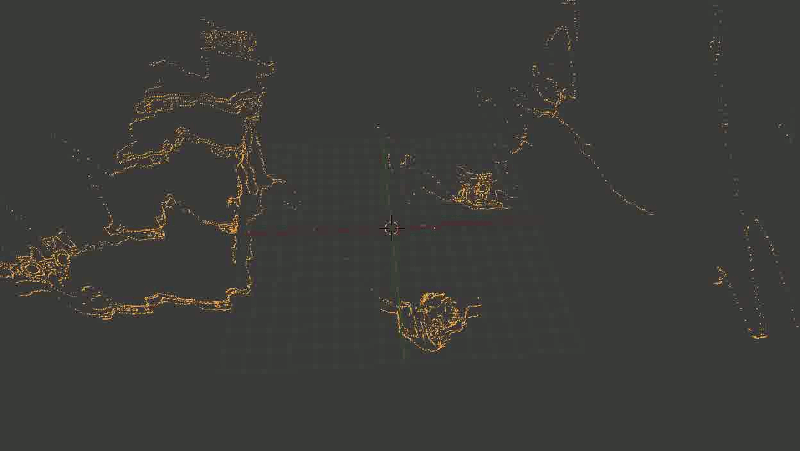 Лестница сминается, местами превращаясь в аморфный кусок непонятно-чего.
Я очень долго пытался это починить, и за это время перепробовал следующее:
Лестница сминается, местами превращаясь в аморфный кусок непонятно-чего.
Я очень долго пытался это починить, и за это время перепробовал следующее:
— сглаживать каринку с оптическим потоком: размытие по Гауссу, медианный фильтр и модный билатеральный фильтр, который оставляет четкими края. Бесполезно: предметы наоборот, еще сильнее расплывались.— пытался находить на картинке прямые линии с помощью Hough transform и переносить их в неизменном прямом состоянии. Частично работало, но только на границах — поверхности по-прежнему оставались такими же искаженными; плюс никуда не получалось деть мысль в духе «а что если прямых линий на картинке вообще нет».— я даже попытался сделать свою собственную версию оптического потока, пользуясь OpenCVшным templateMatching. Работало примерно так: для любой точки строим вокруг нее небольшой (примерно 10×10) квадрат, и начинаем двигать его вокруг и искать максимальное совпадение (если известно направление движения, то «вокруг» можно ограничить). Получилось местами неплохо (хотя работало оно явно медленнее оригинальной версии):  Слева уже знакомый поток Фарнебака, справа вышеописаный велосипед
Слева уже знакомый поток Фарнебака, справа вышеописаный велосипед
С точки зрения шума, увы, оказалось ничуть не лучше.
В общем, все было плохо, но очень логично. Потому что так оно и должно было быть.
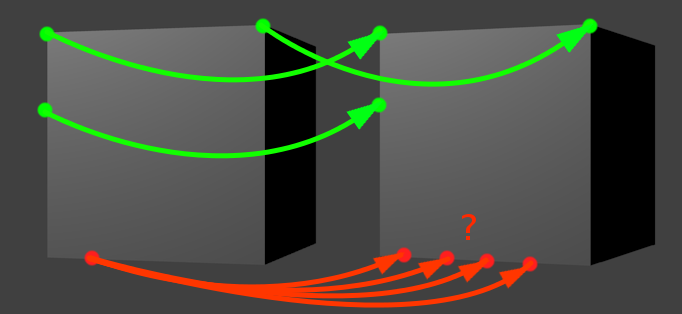 Иллюстрация к проблеме. Движение здесь — по-прежнему шаг вправо
Иллюстрация к проблеме. Движение здесь — по-прежнему шаг вправо
Давайте выберем какую-нибудь зеленую точку из картинки выше. Предположим, мы знаем направление движения, и собираемся искать «смещенного близнеца» нашей зеленой точки, двигаясь в заданном направлении. Когда мы решаем, что нашли искомого близнеца? Когда наткнемся на какой-нибудь «ориентир», характерный участок, который похож на окружение нашей начальной точки. Например, на угол. Углы в этом отношении легко отслеживать, потому что они сами по себе встречаются довольно редко. Поэтому если наша зеленая точка представляет собой угол, и мы находим похожий угол в заданой окрестности, то задача решена.
Чуть сложнее, но все еще легко обстоит ситуация с верикальной линией (вторая левая зеленая точка). Учитывая, что мы двигаемся вправо, вертикальная линия встретится нам только один раз за весь период поиска. Представьте, что мы ползем своим поисковым окном по картинке и видим однотонный фон, фон, снова фон, вертикальный отрезок, опять фон, фон, и снова фон. Тоже несложно.
Проблема появляется, когда мы пытаемся отслеживать кусок линии, расположенной параллельно движению. У красной точки нет одного четко выраженного кандидата на роль смещенного близнеца. Их много, все они находятся рядом, и выбрать какого-то одного тем методом, что мы пользуемся, просто невозможно. Это функциональное ограничение оптического потока. Как нас любезно предупреждает википедия в соответствующей статье, «We cannot solve this one equation with two unknown variables», и тут уже ничего не сделаешь.
Совсем-совсем ничего? Вообще, если честно, то это, наверное, не совсем правда. Вы ведь можете найти на правой картинке соответствие красной точке? Это тоже не очень сложно, но для этого мы мысленно пользуемся каким-то другим методом — находим рядом ближайшую «зеленую точку» (нижний угол), оцениваем расстояние до нее и откладываем соответствующее расстояние на второй грани куба. Алгоритмам оптического потока есть куда расти — этот способ можно было бы и взять на вооружение (если этого еще не успели сделать).
На самом деле, как подсказывает к этому моменту запоздавший здравый смысл, мы все еще пытаемся сделать лишнюю работу, которая не важна для нашей конечной цели — распознавания, классификации и прочего интеллекта. Зачем мы пытаемся запихать в трехмерный мир все точки картинки? Даже когда мы работаем с двумерными изображениями, мы обычно не пытаемся использовать для классификации каждый пиксель — большая их часть не несет никакой полезной информации. Почему бы не делать то же самое и здесь? Собственно, все оказалось вот так просто. Мы будем рассчитывать тот же самый оптический поток, но только для «зеленых», устойчивых точек. И кстати, в OpenCV о нас уже позаботились. Нужная нам штука называется поток Лукаса-Канаде.
Приводить код и примеры для тех же самых случаев будет слегка скучно, потому что получится то же самое, но с гораздо меньшим числом точек. Давайте по дороге сделам еще чего-нибудь: например, добавим нашему алгоритму возможность обрабатывать повороты камеры. До этого мы двигались исключительно вбок, что в реальном мире за пределами окон поездов встречается довольно редко.
С появлением поворотов координаты X и Z у нас смешиваются. Оставим старые формулы для расчета координат относительно камеры, и будем переводить их в абсолютные координаты следующим образом (здесь 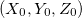 — координаты положения камеры, альфа — угол поворота):
— координаты положения камеры, альфа — угол поворота):
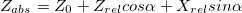
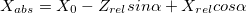

(игрек — читер; это потому, что мы считаем, что камера не двигается вверх-вниз)
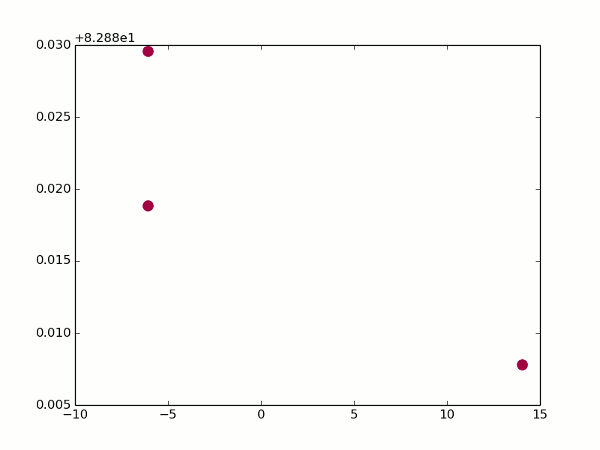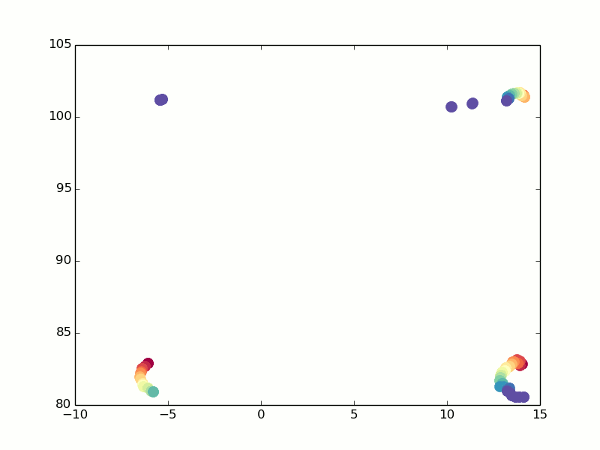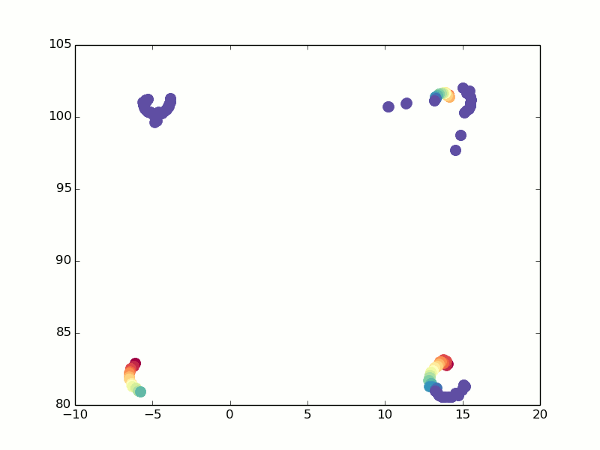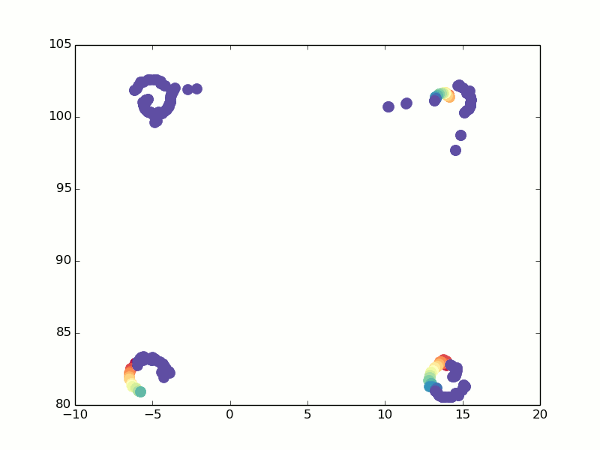
Где-то здесь же у нас появляются проблемы с фокусным расстоянием — помните, мы решили задать его произвольным? Так вот, теперь, когда у нас появилась возможность оценивать одну и ту же точку с разных углов, он начал иметь значение — именно за счет того, что координаты X и Z начали мешаться друг с другом. На самом деле, если мы запустим код, аналогичный предыдущему, с произвольным фокусом, мы увидим примерно вот что:
 Неочевидно, но это попытка устроить обход камеры вокруг обычного кубика. Каждый кадр — оценка видимых точек после очередного поворота камеры. Вид сверху, как на миникарте.
Неочевидно, но это попытка устроить обход камеры вокруг обычного кубика. Каждый кадр — оценка видимых точек после очередного поворота камеры. Вид сверху, как на миникарте.
К счастью, у нас все еще есть оптический поток. При повороте мы можем увидеть, какие точки переходят в какие, и рассчитать для них координаты с двух углов зрения. Отсюда несложно получить фокусное расстояние (просто возьмите две вышеприведенных формулы для разных значений альфа, приравняйте координаты и выразите f). Так гораздо лучше:
 Не то что бы все точки легли идеально одна в другую, но можно хотя бы догадаться о том, что это кубик.
Не то что бы все точки легли идеально одна в другую, но можно хотя бы догадаться о том, что это кубик.
И, наконец, нам нужно как-то справляться с шумом, благодаря которому наши оценки положения точек не всегда совпадают (видите на гифке сверху аккуратные неровные колечки? вместо каждого из них, в идеале, должна быть одна точка). Тут уже простор для творчества, но наиболее адекватный способ мне показался таким: — когда у нас есть подряд несколько сдвигов в сторону, объединяем информацию с них вместе — так для одной точки у нас будет сразу несколько оценок глубины; — когда камера поворачивается, мы пытаемся совместить два набора точек (до поворота и после) и подогнать один к другому. Эта подгонка по-правильному называется «регистрацией точек» (о чем вы бы никогда не догадались, услышав термин в отрыве от контекста), и для нее я воспользовался алгоритмом Iterative closest point, нагуглив версию для питона + OpenCV; — потом точки, которые лежат в пределах порогового радиуса (определяем методом ближайшего соседа), сливаются вместе. Для каждой точки мы еще отслеживаем что-то типа «интенсивности» — счетчик того, как часто она объединялась с другими точками. Чем больше интенсивность — тем больше шанс на то, что это честная и правильная точка.
Результат может и не такой цельный, как в случае с кубиками из Портала, но по крайней мере, точный. Вот пара воссозданных моделей, которые я сначала загрузил в Блендер, покрутил вокруг них камеру и сохранил полученные кадры:
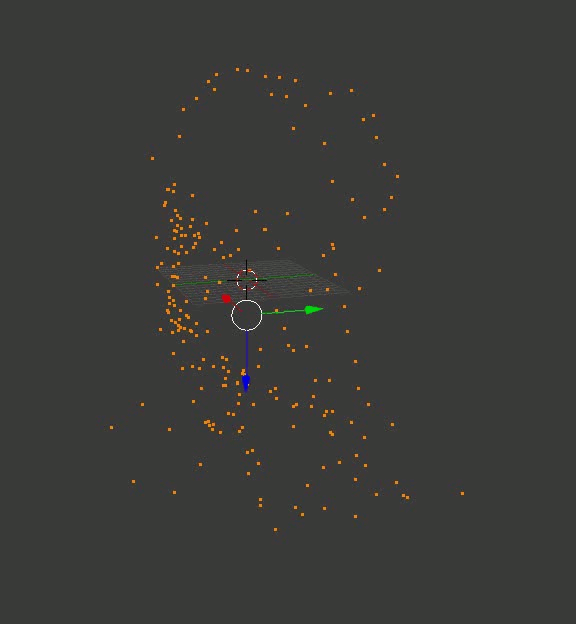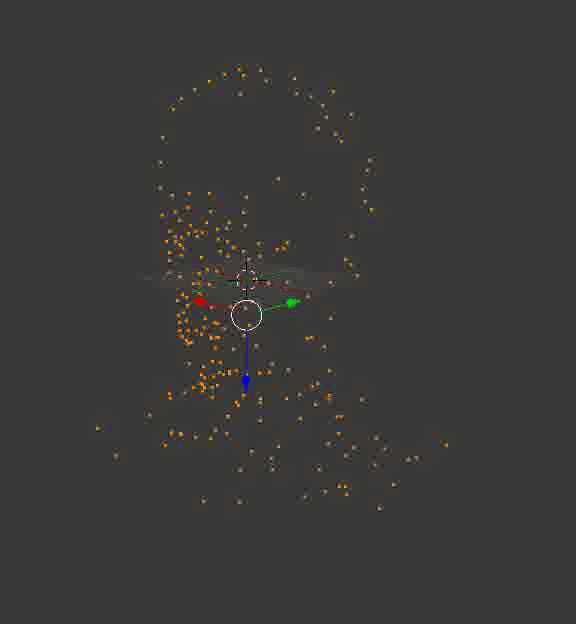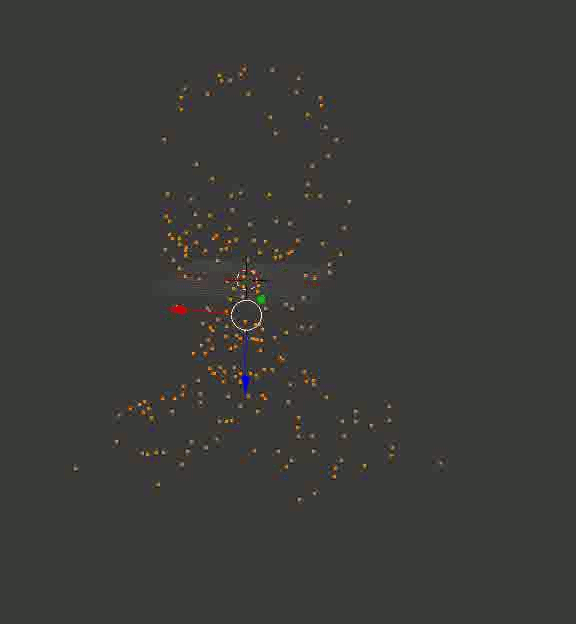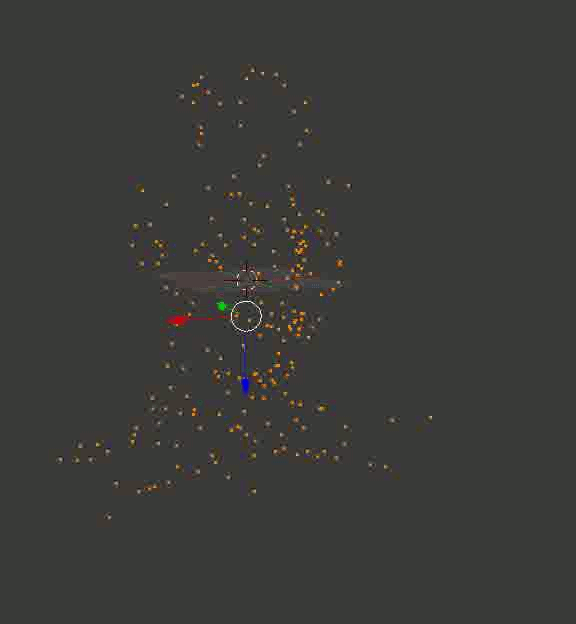 Голова профессора Доуэля
Голова профессора Доуэля
 Какая-то рандомная машина
Какая-то рандомная машина
Бинго! Дальше нужно их все запихать в распознающий алгоритм и посмотреть, что получится. Но это, пожалуй, оставим на следующую серию.
Слегка оглянемся назад и вспомним, зачем мы это все делали. Ход рассуждений был такой: — нам нужно уметь распознавать вещи, изображенные на картинках—, но эти картинки каждый раз, когда мы меняем положение или смотрим на одну и ту же вещь с разных углов, меняются. Иногда до неузнаваемости— это не баг, а фича: следствие того, что наши ограниченые сенсоры глаз видят только часть предмета, а не весь предмет целиком— следовательно, нужно как-то объединить эти частичные данные от сенсоров и собрать из них представление о предмете в его полноценной форме.Вообще говоря, это ведь наверняка проблема не только зрения. Это скорее правило, а не исключение — наши сенсоры не всемогущи, они постоянно воспринимают информацию об объекте частями —, но любопытно, насколько все подобные случаи можно объединить в какой-то общий фреймворк? Скажем (возвращаясь к зрению), ваши глаза сейчас постоянно совершают мелкие и очень быстрые движения — саккады — перескакивая между предметами в поле зрения (а в промежутках между этими движениями ваше зрение вообще не работает — именно поэтому нельзя увидеть собственные саккады, даже уставившись в зеркало в упор). Мозг постоянно занимается упорной работой по «сшиванию» увиденных кусочков. Это — та же самая задача, которую мы только что пытались решить, или все-таки другая? Восприятие речи, когда мы можем соотнести десяток разных вариантов произношения слова с одним его «идеальным» написанием — это тоже похожая задача? А как насчет сведения синонимов к одному «образу» предмета?
Если да — то возможно, проблема несколько больше, чем просто местечковый алгоритм зрительной системы, заменяющий нашим недоэволюционировавшим глазам лазерную указку сканера.
Очевидные соображения говорят, что когда мы пытаемся воссоздать какую-то штуку, увиденную в природе, нет смысла слепо копировать все ее составные части. Чтобы летать по воздуху, не нужны машущие крылья и перья, достаточно жесткого крыла и подъемной силы; чтобы быстро бегать, не нужны механические ноги — колесо справится гораздо лучше. Вместо того, чтобы копировать увиденное, мы хотим найти принцип и повторить его своими силами (может быть, сделав это проще/эффективней). В чем состоит принцип интеллекта, аналог законов аэродинамики для полета, мы пока не знаем. Deep learning и Ян Лекун, пророк его (и вслед за ним много других людей) считают, что нужно смотреть в сторону способности строить «глубокие» иерархии фич из получаемых данных. Может быть, мы сможем добавить к этому еще одно уточнение — способность объединять вместе релевантные куски данных, воспринимая их как части одного объекта и размещая в новом измерении?
