Что новенького по сущностям? Новости последней конференции EMNLP
В ноябре 2021 проходила конференция EMNLP — одно из главных мероприятий для тех, кто занимается NLP. Хоть команде Домклик и не удалось провести отвязную неделю в Доминикане, я и мои коллеги смогли поучаствовать в конференции удалённо. Как рассказывают сами организаторы, претенденты на участие со всего мира весь 2021 год присылали свои статьи. Из 1500 полученных работ отобрали около 400, чтобы допущенные участники сделали десятиминутную видеопрезентацию. В итоге зрители в течение пяти дней непрерывно и концентрированно получают информацию о том, куда продвинулась наука обработки естественного языка.
Спектр тем огромен, просмотреть и понять все презентации тяжело физически. В этой статье мы подготовили для вас обзор работ только по распознаванию именованных сущностей (NER) и извлечению связей (RE).
Извлечение именованных сущностей играет ключевую роль в текстовом и голосовом боте Домклик. Например, в предложении »я вчера купил страховку жизни и загрузил её в чат, скажите, она принята? » упоминаются персона, дата, продукт, приложение, а также связи между ними: загрузить, купить. Извлечь такие данные для NLU и генерации релевантного ответа — очень сложная задача, и в разборах статей будет видно, на какие ухищрения надо пойти, чтобы добиться стабильного результата.
Мы рассмотрим три статьи с конференции и три более ранние статьи, необходимые для лучшего понимания:
Склонность моделей к запоминанию отношений (relation), ограничения обобщающей способности моделей.
Разбор алгоритмов, которые решают задачи NER и RE:
Span-based Joint Entity and Relation Extraction with Transformer Pre-training (SPERT), 2020.
A frustratingly Easy Approach for Entity and Relation Extraction (PURE), 2021.
Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders (TABTO), 2020.
Новый метод, основанный на разделении памяти на отдельные части (A Partition Filter Network for Joint Entity and Relation Extraction (SOTA end 2021)).
Методы аугментации данных (2021).
Склонность моделей к запоминанию отношений (relation), ограничения обобщающей способности моделей
Начнём сразу с самого интересного — с метрик, а точнее, со статьи, в которой предложен новый подход к измерению способности моделей обобщать знания (Separating Retention from Extraction in the Evaluation of End-to-end Relation Extraction (Bruno et al. 2021)).
Что нового предложено в статье:
Оценивать степень отличия тестовой выборки от обучающей.
Оценивать зависимость качества работы моделей от того факта, что триплеты для извлечения связей уже встречались в обучении языковых моделей.
Авторы утверждают, что ключом к хорошим метрикам в обучении языковых моделей является запоминание примеров из обучения и фактов из текстов. Для измерения качества используются:
Три набора данных: ACE05, CoNLL04, SciERC.
Три архитектуры: PURE, SPERT, TABTO (их мы разберём ниже).
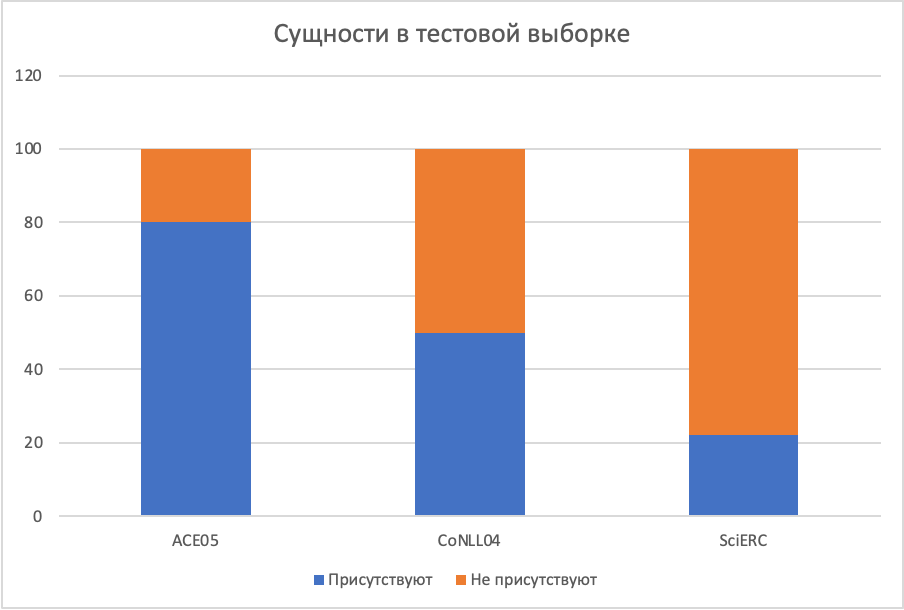
В каждом наборе данных разные соотношения повторов сущностей и связей в тестовой и обучающей выборке. Уникальность тестовой выборки измеряется следующим образом:
Для сущностей:
Присутствуют — полное совпадение с обучающей выборкой.
Отсутствуют — не встречались в обучающей выборке.
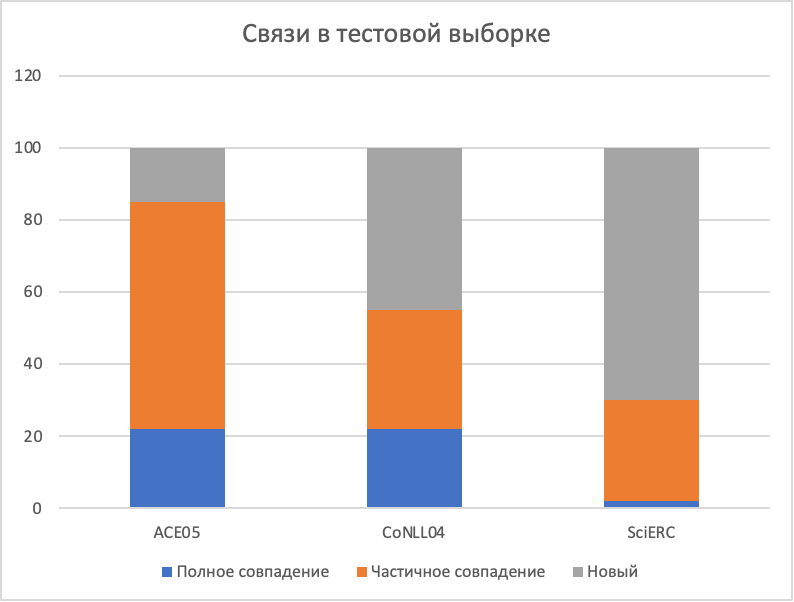
Для связей:
Полное совпадение — триплет голова-предикат-хвост полностью присутствуют в обучении.
Частичное совпадение — есть либо голова с предикатом, либо предикат с хвостом.
Новый — во всех остальных случаях.
Модели показывают следующие результаты для каждого набора данных:
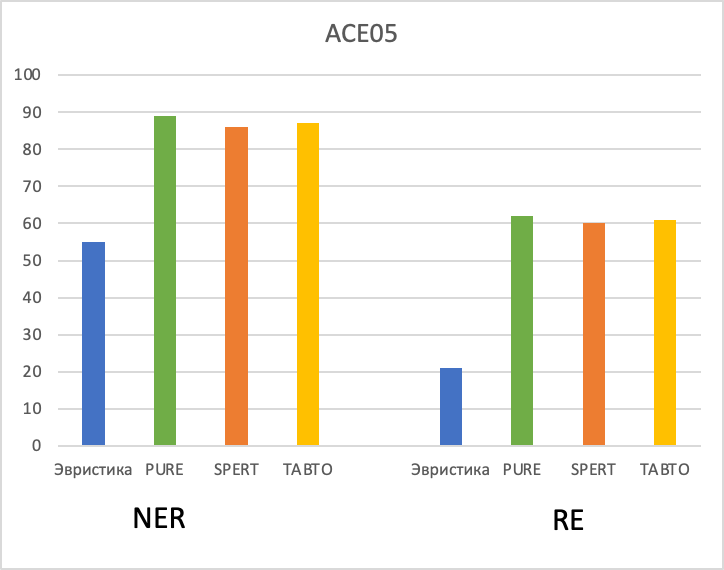 ACE05
ACE05
ACE05 имеет наибольшую долю повторов в тестовой выборке, у всех моделей очень хорошие метрики.

Для CoNLL04 ситуация немного необычная, так как у него в тестовой выборке больше новых токенов сущностей, но при этом качество даже немного вырастает по сравнению с предыдущим набором данных.

В SciERC метрики очень сильно падают. Не удивительно, так как почти все сущности и связи в тестовой выборке ни разу не встречались в обучающей. Авторы делают вывод, что запоминание сущностей и связей играет важнейшую роль для достижения хороших метрик в извлечении связей и объясняет относительно высокие метрики в наборах данных ACE05 и CoNLL04 по сравнению с SciERC.
Во второй половине своей статьи они проверяют важность запоминания моделями общеизвестных фактов. Для проверки своей гипотезы авторы в предложении меняют голову и хвост местами, например:
Освальд убил Кеннеди из винтовки → Кеннеди убил Освальда из винтовки.
Лондон находится в Великобритании → Великобритания находится в Лондоне.
Далее проверяют, какие из методов возвращают новую последовательность, а какие обратную.
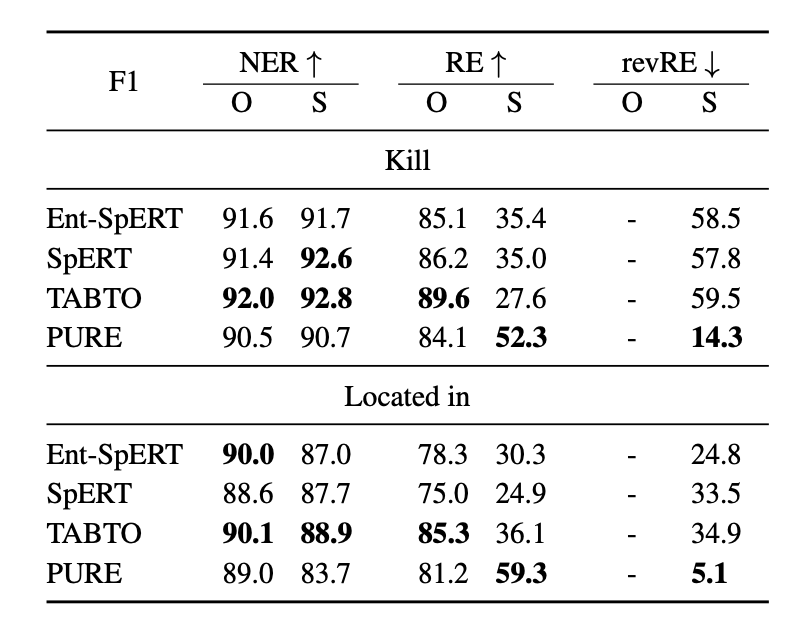
По результатам авторов модели SPERT и TABTO почти в 60% случаев возвращали триплеты в неправильном порядке. Это означает, что запоминание фактов играет ключевую роль для получения хороших метрик. Только модель PURE выдает адекватные результаты и действительно умеет обобщать свои знания.
Разбор алгоритмов статей, которые решают задачи NER и RE
После того, как мы определились с получаемыми метриками, можем разобрать и сами методы, которые использовались в алгоритме выше.
1. Span-based Joint Entity and Relation Extraction with Transformer Pre-training (SPERT) 2020.
Алгоритм относительно простой для понимания. В качестве эмбедингов текстов используется дообученный на текстах из наборов данных BERT:
Векторизуем текст.
Случайно инициализируем width embedding — это N векторов, каждый из которых конкатенируется к эмбедингу n-gram соответствующей длины который служит для подачи информации о длине исследуемой последовательности слов.
Берём из текста все варианты n-gram, конкатенируем к нему width embedding, конкатенируем выход из последнего токена и обучаем классификатор сущностей.
Поверх полученных сущностей, используя те же векторы, обучаем второй классификатор типов связей с maxpool эмбедингов токенов между сущностями.

Так, в два действия и с одной векторизацией получаем прогнозирование и сущности, и связи.
2. A frustratingly Easy Approach for Entity and Relation Extraction (PURE) 2021.
В этой статье алгоритм очень похож на предыдущий с небольшими модификациями. Он тоже в качестве NLU использует BERT, но дообученный на других данных.
Алгоритм состоит из следующих операций:
Векторизуем предложение с помощью BERT.
Делим предложение на все варианты n-gram.
Для каждой n-gram, используя соседние слова с окном шириной L, получаем вектор фиксированной длины из эмбедингов токенов.
Прогнозируем тип сущности.
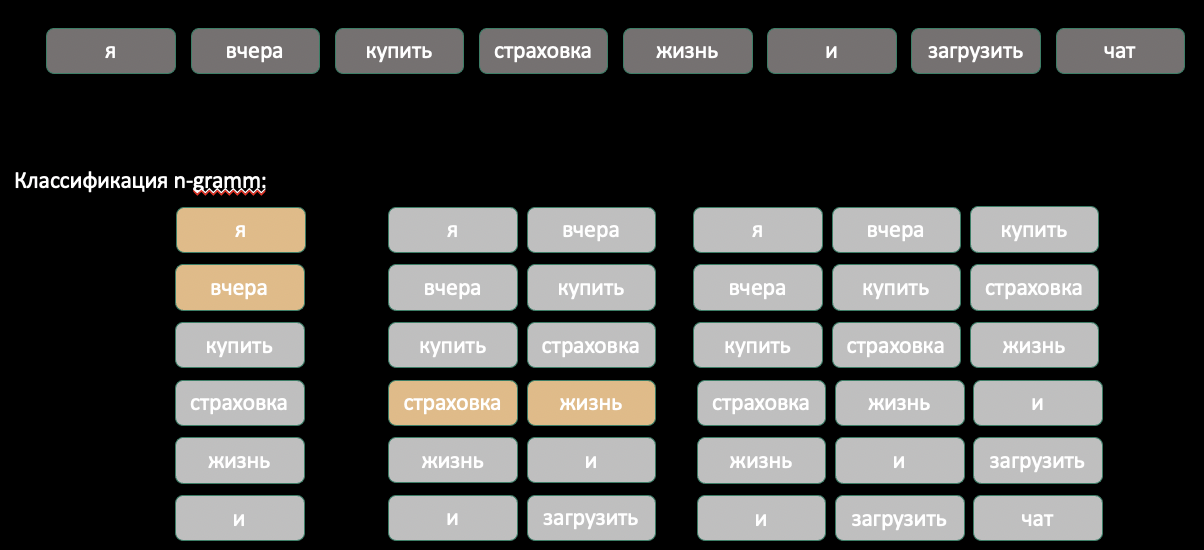
Далее для всех найденных сущностей вставляем в текст специальные токены начала и конца типа сущности (фиолетовым на схеме ниже). Получаем специальные эмбеддинги с помощью второй модели BERT, которая обучена на таких текстах. А затем второй моделью прогнозируем тип связи для каждой из пар найденных сущностей. При этом в модель также передается контекст предложения в виде окна из L токенов с каждой стороны n-gram.

A Partition Filter Network for Joint Entity and Relation Extraction (SOTA end 2021)
Три алгоритма, разобранные выше, уже были широко известны и даже воспроизведены другими командами. Следующий метод — самый новый, был представлен на EMNLP 2021. На конец 2021 у него лучшие метрики почти на всех наборах данных, но его работоспособность должна быть проверена и подтверждена другими командами.
Главное нововведение заключается в частичном разделении эмбедингов для NER и RE. Авторы утверждают, что решение двух задач одновременно на одном эмбединге ухудшает способность модели прогнозировать. Их идея в том, чтобы оставить входные данные для обеих задач одинаковыми, но при этом разделить векторы для финального прогноза. На иллюстрации показано, как авторы хотят поделить вектор состояния на три части.

Алгоритм представляется из себя LSTM, в котором рекуррентно передается информация от одного объекта последовательности к другому. На выходе из рекуррентного блока мы должны получить векторы ht и ct:
ht — это вектор скрытого состояния нейрона. Он использует долгосрочную память и новую полученную информацию для отображения текущего состояния.
ct — это вектор памяти. Он передаёт предыдущий опыт далее по временному ряду.
Для прогнозирования типа связи и сущности используется вектор ht. Чтобы убрать конфликт между двумя задачами, вектор ht делят на части довольно хитрым способом:
Находят две точки отреза для разделения эмбеддингов на подзадачи:

![cumsum([x1, x2, x3]) = [x1, x1 + x2, x1 + x2 + x3]](https://habrastorage.org/getpro/habr/upload_files/f52/f6f/a66/f52f6fa66f48973c4364e59aff9b9cd3.svg)
![\widetilde{e} = cummax(Linear([x_{t}; h_{t-1}]))](https://habrastorage.org/getpro/habr/upload_files/1ed/2ce/448/1ed2ce44847fba67f1e9e05c4e450d61.svg)

Подробнее разберём механизм разделения. Векторы е и r представляют из себя ряд чисел от 0 до 1, но отраженных зеркально. Например, если е = [0, 0, 0.1, 0.5, 0.7, 0.8, 1, 1], то r = [1, 1, 0.9, 0.5, 0.3, 0.2, 0, 0], и переход из 0 в 1 делает их отображающими разные части вектора, но в то же время оставляет эти функции дифференцируемыми.
Зададим:

Получим:
![\rho_{s} = [0, 0, 0.09, 0.25, 0.21, 0.16, 0, 0]\\ \rho_{e} = [0, 0, 0.01, 0.25, 0.49, 0.64, 1, 1]\\ \rho_{r} = [1, 1, 0.81, 0.25, 0.09, 0.04, 0, 0]](https://habrastorage.org/getpro/habr/upload_files/ec4/ba9/374/ec4ba9374cc53f479bc686761427801d.svg)
Причем сумма этих векторов меньше 1, что гарантирует, что при проходе по рекуррентной сети у нас не будет бесконечно растущих значений в скрытых векторах, это схоже с механизмом «забывания» в LSTM.
Для расчета векторов ht и ct нам понадобится вектор Ct. Он считается относительно просто:
![\widetilde{C}_{t} = tanh(Linear([x_{t}; h_{t-1}]))](https://habrastorage.org/getpro/habr/upload_files/ad2/aab/ad9/ad2aabad9491753d09ef6137c8baf74b.svg)
Далее, используя вектор Ct получим три разделения отдела памяти:

Авторы предлагают три разных отдела памяти: для извлечения сущностей, для извлечения связей и общую память. Таким образом информация, которая нужна для поиска связей, никак не будет мешать определению сущностей, и наоборот.

И теперь уже вычисляем скрытые вектора Сt и Ht, которые будут переданы в следующий шаг рекуррентной сети и использованы для финальной задачи
![c_{t} = Linear([\mu_{e,t}; \mu_{r,t}; \mu_{s,t}])\\ h_{t} = tanh(c_{t})](https://habrastorage.org/getpro/habr/upload_files/18b/3b3/bf5/18b3b3bf5168ea712c83a7c0920e7356.svg)
А для формирования самого прогноза используются вектора hr и he:

Чтобы было легче понять формулы, приложу схему из статьи:
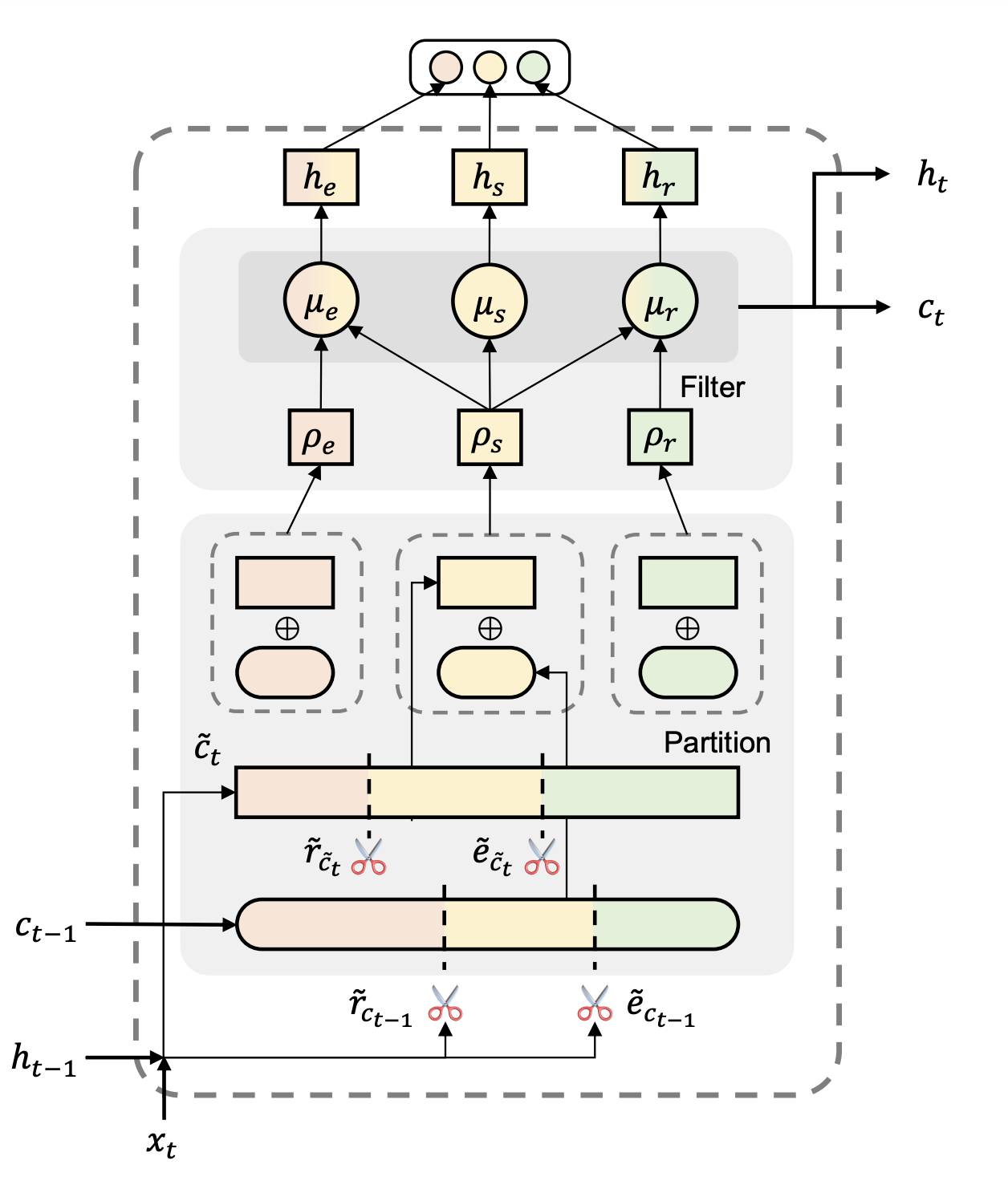
До прогнозирования типа сущности необходимо сделать ещё две операции:
Добавить глобальный контекст, который считается как hg = maxpool (h1…hL).
Взять векторы двух слов, которые являются претендентами на начало и конец сущности, их векторы конкатенировать и пропустить через полносвязный слой.
Схожим образом определяется, есть ли связь между двумя сущностями: берут два токена начала сущностей и конкатенируют их. Причём прогноз делается не softmax-активацией, а sigmoid-активацией, и используется BCE loss, а не CCE loss, как во всех примерах выше.
Методы дополнения данных
На конференции была статья «Distantly Entity Recognition with Noise Robust Learning and Language Model Augmented Self-Training». Авторы пытаются решить проблему ошибок в разметке при дополнении данных. Они предложили перейти от log loss к MAE, что позволит уменьшить loss при ошибках в разметке.

Но при этом авторы используют не обычный MAE, а модифицированный гиперпараметром q, то есть подбирают что-то среднее между log loss и MAE. При q → 0 мы получаем log loss, при q → 1 получаем MAE.
Если использовать модифицированный loss, то можно использовать прямой метод дополнения, который выполняется следующим образом:
Берём конечный список токенов, которые точно являются сущностями, ищем токены из указанного списка в неразмеченном наборе данных и получаем первую разметку.
Обучаем модель на этой разметке с модифицированным loss.
Вводим гиперпаметр τ, и все токены, вероятность которых быть сущностью больше, чем τ, добавляем в наш список токенов — сущностей.
Обучаем финальную модель на оригинальном и дополненном наборе данных.
Метрики, получаемые в этом случае, довольно внушительные: 0,8 — 0,85 F1. Также авторы подобрали q и τ:

И получили, что нужно использовать значения 0,7 и 0,7 для обоих гиперпараметров.
Также хотел бы подсветить ещё один метод дополнения данных, при котором сначала определяем, является ли токен сущностью, а уже потом прогнозируем тип сущности (TEBNER: Domain Specific Named Entity Recognition with Type Expanded Boundary-aware Network).
Выводы
Пока ещё у читателей не закипела голова от избытка информации, надо заканчивать. Конференция очень интересная и полезная. Если вы хотите быть в курсе самых свежих исследований в области NLP, то определённо стоит участвовать. Если же вам интересны прикладное применение NLP, то в России и на русском есть аналог — конференция Conversations-AI (в которой Домклик тоже активно участвует).
Что касается задач NER и RE, то стабильно находить в тексте сущности и связи всё ещё очень и очень трудно. На больших наборах данных и с лучшими моделями можно добиться ~85–88% F1. Если для решения бизнес-задачи вам нужно извлекать из текста именованные сущности, то придётся потратиться и на создание релевантной разметки, и на время специалистов, разрабатывающих алгоритм. Есть несколько методов, которые помогут с искусственным увеличением набора данных, но и их разработка и отладка занимает время, не говоря уже о том, что почти каждый алгоритм требует наличия BERT в контуре компании.
Если вам нужно быстро проверить гипотезу о целесообразности использования сущностей в задачах, то примените алгоритм из второй статьи «Span-based Joint Entity and Relation Extraction with Transformer Pre-training» — он самый лёгкий для понимания, но при этом выдаёт результат всего на 2% ниже, чем SOTA. Также уделите внимание размеру обучающей выборки, она должна стремиться покрывать 100% реальных данных.
