Continuous integration в Яндексе
Поддержка огромной кодовой базы с одновременным обеспечением высокой производительности большого числа разработчиков — это серьезный вызов. В течение последних 5 лет в Яндексе идет разработка особой системы непрерывной интеграции. В данной статье мы расскажем про масштаб кодовой базы Яндекса, про перенос разработки в единый репозиторий с trunk-based подходом к разработке, про то, какие задачи должна решать система непрерывной интеграции для эффективной работы в таких условиях.

Много лет назад в Яндексе никаких особенных правил в разработке сервисов не было: каждый отдел мог использовать любые языки, любые технологии, любые системы деплоя. И как показала практика, такая свобода не всегда помогала двигаться вперед быстрее. В то время для решения одних и тех же задач часто существовало несколько собственных или open-source разработок. С ростом компании такая экосистема работала всё хуже. При этом мы хотели остаться одним большим Яндексом, а не разделиться на множество независимых компаний, потому что это дает массу преимуществ: много людей делают одни похожие задачи, результаты их труда можно использовать повторно. Начиная от разнообразных структур данных, типа распределённых хеш-таблиц и lock-free очередей, и заканчивая множеством разного специализированного кода, который мы написали за 20 лет.
Многие задачи, которые мы решаем, не решают в open-source мире. Там нет MapReduce, хорошо работающего на наших объёмах (5000+ серверов) и наших задачах, там нет трекера задач, который способен обрабатывать все наши десятки миллионов тикетов. Это и привлекательно в Яндексе — можно делать по-настоящему большие вещи.
Но у нас серьёзно падает эффективность, когда мы решаем заново те же задачи, переделываем готовые решения, затрудняя интеграции между компонентами. Хорошо и удобно всё делать только для себя в своём уголке, можно не думать о других до поры до времени. Но как только сервис станет достаточно заметным, у него появятся зависимости. Только кажется, что различные сервисы слабо зависят друг от друга, на самом деле — связей между различными частями компании очень много. Многие сервисы доступны через приложение Яндекса / Браузер / и т.д., либо встраиваются друг в друга. Например, Алиса появляется в Браузере, с помощью Алисы можно заказать Такси. Все мы используем общие компоненты: YT, YQL, Нирвана.
В старой модели разработки были существенные проблемы. Из-за наличия множества репозиториев обычному разработчику, тем более новичку, трудно узнать:
- где лежит компонент?
- как он работает: нет возможности «взять и почитать»
- кто его сейчас разрабатывает и поддерживает?
- как его начать использовать?
В результате возникала проблема взаимного использования компонентов. Компоненты почти не могли использовать другие компоненты, потому что представляли друг для друга «чёрные ящики». Это негативно влияло на компанию, так как компоненты не только не переиспользовались, но и часто не улучшались. Многие компоненты дублировались, сильно рос объем кода, который приходилось поддерживать. Мы в целом двигались медленнее, чем могли бы.
Единый репозиторий и инфраструктура
5 лет назад мы начали проект по переносу разработки в единый репозиторий, с едиными системами сборки, тестирования, деплоя и мониторинга.
Основная цель, которую мы хотели достичь — убрать помехи, препятствующие интеграции чужого кода. Система должна обеспечивать простой доступ к готовому работающему коду, понятную схему его подключения и использования, собираемость: проекты всегда собираются (и проходят тесты).
В результате проекта возник единый для компании стек инфраструктурных технологий: хранение исходного кода, система code review, система сборки, система непрерывной интеграции, деплой, мониторинг.
Сейчас большая часть исходного кода проектов Яндекса хранится в едином репозитории, либо находится в процессе переезда в него:
- над проектами трудятся более 2000 разработчиков.
- более 50 000 проектов и библиотек.
- размер репозитория превышает 25 Гб.
- в репозиторий уже совершено более 3 000 000 коммитов.
Плюсы для компании:
- любой проект из репозитория получает готовую инфраструктуру:
- система для просмотра и навигации по исходному коду и система code-review.
- система сборки и распределенная сборка. Это отдельная большая тема, и мы обязательно ее раскроем в следующих статьях.
- система непрерывной интеграции.
- деплой, интеграция с системой мониторинга.
- совместное использование кода, активное взаимодействие команд.
- весь код общий, вы можете прийти в другой проект и сделать там нужные вам изменения. Это особенно важно в большой компании, поскольку у другой команды, от которой вам что-то надо, может не быть ресурсов. С общим кодом у вас появляется возможность сделать часть работы самим и «помочь случиться» нужным вам изменениям.
- появляется возможность проводить глобальный рефакторинг. Вам не надо поддерживать старые версии вашего API или библиотеки, вы можете изменить их и поменять те места, где они используются в других проектах.
- код становится менее «разнообразным». У вас есть набор способов, чтобы решать проблемы, и нет необходимости добавлять еще один способ, делающий примерно то же самое, но с небольшими отличиями.
- в соседнем с вами проекте, скорее всего, не будет совсем экзотичных языков и библиотек.
Следует также понимать, что у такой модели разработки есть недостатки, которые нужно учитывать:
- общий репозиторий требует отдельной особой инфраструктуры.
- нужной вам библиотеки может не быть в репозитории, но она есть в open-source. Есть затраты на ее добавление и обновление. Сильно зависит от языка и библиотеки, где-то почти бесплатно, где-то очень дорого.
- нужно постоянно работать над «здоровьем» кода. Это включает в себя как минимум борьбу с лишними зависимостями и с «мертвым» кодом.
Наш подход к общему репозиторию накладывает общие правила, которые всем нужно соблюдать. В случае использования единого репозитория накладываются ограничения на используемые языки, библиотеки, способы деплоя. Но зато в соседнем проекте всё будет так же или очень похоже на ваш, и вы там даже сможете что-нибудь исправить.
К модели общего репозитория тяготеют все большие компании. Монолитный репозиторий — большая и хорошо изученная и обсуждаемая тема, поэтому сейчас мы не будем в нее сильно углубляться. Если вам хочется узнать больше, то в конце статьи вы найдете несколько полезных ссылок, более подробно раскрывающих данную тему.
Условия, в которых работает система непрерывной интеграции
Разработка ведется по модели Trunk based development. Большинство пользователей работает с HEAD или наиболее свежей копией репозитория, полученной из основной ветви, называемой trunk, в которой идет разработка. Фиксация изменений в репозитории осуществляются последовательно. Сразу после коммита новый код виден и может использоваться всеми разработчиками. Разработка в отдельных ветках не приветствуется, хотя ветки могут использоваться для релизов.
Проекты зависят по исходному коду. Проекты и библиотеки образуют сложный граф зависимостей. А это означает то, что изменения, сделанные в одном проекте, потенциально влияют на весь остальной репозиторий.
В репозиторий идет большой поток коммитов:
- более 2000 коммитов в день.
- до 10 изменений в минуту в часы пик.
В кодовой базе содержится более 500 000 целей сборки и тестов.
Без особой системы непрерывной интеграции в таких условиях было бы очень сложно быстро двигаться вперед.
Система непрерывной интеграции
Система непрерывной интеграции осуществляет запуск сборок и тестов на каждое изменение:
- Прекоммитные проверки. Позволяют проверить код до коммита и избежать поломки тестов в trunk. Сборки и тесты при этом запускаются поверх HEAD. В данный момент прекоммитные проверки запускаются добровольно. Для особо важных проектов прекоммитные проверки обязательны.
- Посткоммитные проверки после коммита в репозиторий.
Сборки и тесты запускаются параллельно на больших кластерах, состоящих из сотен серверов. Сборки и тесты запускаются на разных платформах. Под основной платформой (linux) собираются все проекты и запускаются все тесты, под остальными платформами — некоторое подмножество, настраиваемое пользователями.
После получения и анализа результатов сборок и прогона тестов пользователь получает обратную связь, например, если изменения ломают какие-либо тесты.

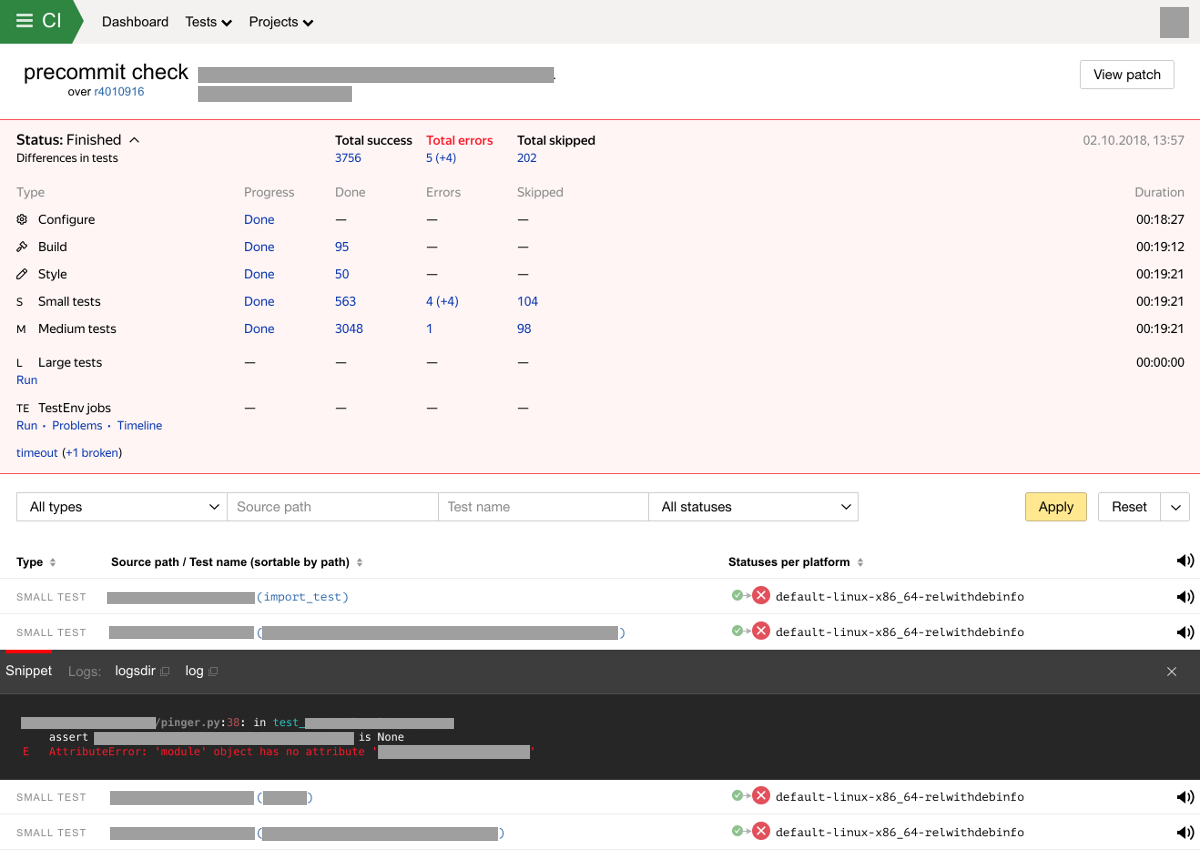
В случае обнаружения новых поломок сборки или тестов мы отправляем уведомление владельцам тестов и автору изменений. Система также хранит и отображает результаты проверок в специальном интерфейсе. Веб-интерфейс системы интеграции отображает прогресс и результат выполнения проверки с разбиением по типам тестов. Экран с результатами проверки сейчас может выглядеть так:
Особенности и возможности системы непрерывной интеграции
Решая различные проблемы, стоящие перед разработчиками и тестировщиками, мы развивали нашу систему непрерывной интеграции. Система уже решает множество задач, но предстоит еще многое улучшить.
Типы и размеры тестов
Существует несколько типов целей, которые может запускать система непрерывной интеграции:
- configure. Этап конфигурации, выполняемый системой сборки. Конфигурация включает в себя анализ конфигурационных файлов системы сборки, определение зависимостей между проектами и параметров сборки и запуска тестов.
- build. Сборка библиотек и проектов.
- style. На данном этапе проверяется соответствие стиля кода заданным требованиям.
- test. Тесты разбиты на стадии согласно их таймауту на время работы и требованиям к вычислительным ресурсам.
- small. < 1 мин.
- medium. < 10 мин.
- large. > 10 мин. Кроме того, могут быть особые требования к вычислительным ресурсам.
- extra large. Это особый тип тестов. Такие тесты характеризуются набором из следующих характеристик: долгое время работы, большое потребление ресурсов, большой объем входных данных, им могут требоваться особые доступы и самое главное — поддержка сложных сценариев тестирования, описанных ниже. Таких тестов намного меньше чем других типов тестов, но они очень важны.
Частота запуска тестов и бинарный поиск поломок
На тестирование в Яндексе выделяются огромные ресурсы — сотни мощных серверов. Но даже при большом количестве ресурсов, мы не можем запускать все тесты на каждое затрагивающее их изменение. Но при этом нам очень важно всегда помогать разработчику локализовать место поломки теста, особенно в таком большом репозитории.
Как мы поступаем. На каждое изменение для всех затронутых проектов запускаются сборки, проверки стиля и тесты с размером small и medium. Остальные тесты запускаются не на каждый влияющий коммит, а с некоторой периодичностью, при наличии влияющих на тесты коммитов. В некоторых случаях пользователи могут управлять периодичностью запуска, в остальных случаях периодичность запуска задается системой. При обнаружении поломки теста запускается процесс поиска ломающего тест коммита. Чем реже запускается тест, тем дольше будем искать ломающий коммит после обнаружения поломки.

При запуске прекоммитных проверок также запускаем только сборки и легкие тесты. Далее пользователь может вручную инициировать запуск тяжелых тестов, выбрав из предоставленного системой списка затронутых изменениями тестов.
Обнаружение мигающих тестов
Мигающие тесты — это такие тесты, результат запуска (Passed/Failed) которых на том же самом коде может зависеть от различных факторов. Причины возникновения мигающих тестов могут быть разными: sleep в коде теста, ошибки при работе с многопоточностью, инфраструктурные проблемы (недоступность каких-либо систем) и т.д. Мигающие тесты представляют серьезную проблему:
- Приводят к тому что система непрерывной интеграции спамит ложными уведомлениями о поломках тестов.
- Загрязняют результаты проверок. Становится сложнее принять решение об успешности результатов проверки.
- Задерживают релизы продуктов.
- Сложно детектировать. Тесты могут мигать очень редко.
Разработчики могут игнорировать мигающие тесты при анализе результатов проверки. Иногда некорректно.
Полностью устранить мигающие тесты невозможно, это должно учитываться в системе непрерывной интеграции.
На текущий момент на каждую проверку мы запускаем все тесты дважды для обнаружения мигающих тестов. Также мы учитываем жалобы от пользователей (получателей уведомлений). Если мы обнаруживаем мигание, мы помечаем тест особым флагом (muted) и информируем владельца теста. После этого уведомления о поломках теста будут получать только владельцы теста. Далее мы продолжаем запускать тест в обычном режиме, при этом анализируя историю его запусков. Если тест не мигал в определенном временном окне, автоматика может принять решение о том, что тест перестал мигать и можно сбросить флаг.
Наш текущий алгоритм достаточно простой и в этом месте планируется много улучшений. Прежде всего, мы хотим использовать гораздо больше полезных сигналов.
Автоматическое обновление входных данных тестов
При тестировании самых сложных систем Яндекса в дополнение к другим методикам тестирования часто используется тестирование по стратегии чёрного ящика + data-driven тестирование. Для обеспечения хорошего покрытия таким тестам требуется большой набор входных данных. Данные можно отобрать из production кластеров. Но возникает проблема с тем, что данные быстро устаревают. Мир не стоит на месте, наши системы постоянно развиваются. Устаревшие тестовые данные со временем не будут обеспечивать хорошее тестовое покрытие, а затем и вовсе приведут к поломке теста из-за того, что программы начинают использовать новые данные, которые отсутствуют в устаревших тестовых данных.
Для того чтобы данные не устаревали, система непрерывной интеграции умеет обновлять их автоматически. Как это работает.
- Тестовые данные хранятся в специальном хранилище ресурсов.
- Тест содержит метаданные с описанием требуемых входных данных.
- Соответствие между требуемыми входными данными теста и ресурсами хранится в системе непрерывной интеграции.
- Разработчик обеспечивает регулярную доставку свежих данных до хранилища ресурсов.
- Система непрерывной интеграции ищет новые версии тестовых данных в хранилище ресурсов и осуществляет переключение входных данных.
Важно произвести обновление данных так, чтобы при этом не произошло ложное срабатывание теста. Нельзя просто взять и, начиная с определенного коммита, начать использовать новые данные, т.к. в случае поломки теста будет непонятно, кто виноват — коммит или новые данные. Также это сделает неработоспособными diff-тесты (описаны ниже).

Поэтому мы делаем так, что есть некоторый небольшой интервал коммитов, на котором тест запускается как со старой, так и с новой версиями входных данных.

Diff-тесты
Diff-тестами мы называем особый тип data-driven тестов, которые отличаются от общепринятого подхода тем что тест не имеет эталонного результата, но при этом нам нужно находить в каких коммитах тест изменил свое поведение.
Стандартный подход в data-driven тестировании заключается в следующем. У теста есть эталонный результат, полученный при первом запуске теста. Эталонный результат может храниться в репозитории рядом с тестом. Последующие запуски теста должны приводить к одному и тому же результату.

Если результат отличается от эталонного, разработчик должен решить ожидаемое ли это изменение или ошибка. Если изменение ожидаемое, разработчик должен обновить эталонный результат одновременно с фиксацией изменений в репозитории.
Есть сложности при использовании такого подхода в большом репозитории с большим потоков коммитов:
- Тестов может быть много и тесты могут быть очень тяжелыми. У разработчика нет возможности запустить все затронутые тесты в рабочем окружении.
- После внесения изменений тест может сломаться, если эталонный результат не был обновлен одновременно с внесением изменений к код. Далее другой разработчик может внести изменения в тот же компонент и результат теста изменится еще раз. Получаем наложение одной ошибки на другую. С такими проблемами очень сложно разбираться, это отнимает время у разработчиков.
Как поступаем мы. Diff-тесты состоят из 2-х частей:
- Check-составляющая.
- Запускаем тест и сохраняем в хранилище ресурсов полученный результат.
- Не сравниваем результат с эталонным.
- Можем поймать часть ошибок, например, программа не запускается / не завершается, падения, программа не отвечает. Также может выполняться валидация результата: наличие каких-либо полей в ответе и т.д.
- Diff-составляющая.
- Сравниваем результаты, полученные на разных запусках и строим diff. В самом простом случае это функция, принимающая 2 параметра и возвращающая diff.
- Внешний вид diff’а зависит от теста, но это должно быть что-то понятное для того, кто будет смотреть на diff. Обычно diff представляет из себя html файл.
Запуском check и diff составляющих управляет система непрерывной интеграции.

Если система непрерывной интеграции обнаруживает diff, то сперва выполняется бинарный поиск вызвавшего изменения коммита. После получения уведомления у разработчика появляется возможность изучить diff и принять решение о том, что делать дальше: признать diff ожидаемым (для этого нужно выполнить специальное действие) или починить / «откатить» свои изменения.
Продолжение следует
В следующей статье мы расскажем про то, как устроена система непрерывной интеграции.
Ссылки
Монолитный репозиторий, Trunk-based development
Data-driven testing
