Быстрый старт: обзор основных Deep Learning фреймворков
Здесь, в SVDS, наш R&D отдел изучает различные технологии Deep Learning: от распознавания изображений поездов, до расшифровки человеческой речи. Перед нами стояла цель построить непрерывный процесс обработки данных, создания модели и оценки ее качества. Однако, начав изучение доступных технологий, мы так не смогли найти подходящего руководства по запуску нового Deep Learning проекта.
Тем не менее, стоит отдать должное сообществу энтузиастов, которые занимаются разработкой и улучшением Deep Learning технологий с открытым исходным кодом. Следуя их примеру, необходимо помогать другим оценивать и выбирать эти инструменты, делиться собственным опытом. В таблице ниже указаны критерии выбора тех или иных фреймворков Deep Learning:
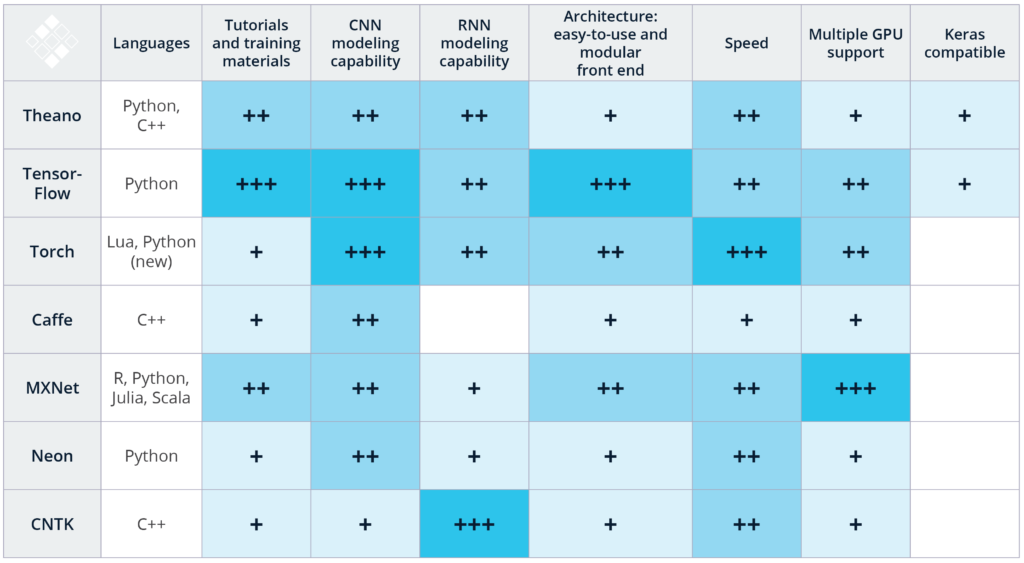
Получившийся рейтинг основан на комбинации нашего опыта применения вышеуказанных технологий для распознавания изображений и речи, а также изучения опубликованных сравнительных исследований. Стоит отметить, что данный список включает не все доступные Deep Learning инструменты, большее количество которых можно найти здесь. В ближайшие месяцы нашей команде не терпится протестировать DeepLearning4j, Paddle, Chainer, Apache Signa, и Dynet.
Теперь перейдем к более подробному описанию нашей системы оценивания:
Языки программирования: Начиная работать с Deep Learning, лучше всего использовать наиболее удобный для вас язык программирования. К примеру, Caffee (C++) и Torch (Lua) имеют обёртки для своей API на Python, однако использование данных инструментов рекомендуется, только если вы на должном уровне владеете C++ или Lua соответственно. Для сравнения, TensorFlow и MXNet поддерживают множество языков программирования, что делает возможным использования данного инструментария, даже если вы не профессионал в C++. Замечание: К сожалению, у нас пока не было возможности протестировать новую Python обертку для Torch, PyTorch, выпущенную Facebook AI Research (FAIR) в январе 2017 года. Данный фреймворк был создан для того, чтобы Python-разработчики могли совершенствовать построение нейронных сетей в Torch.
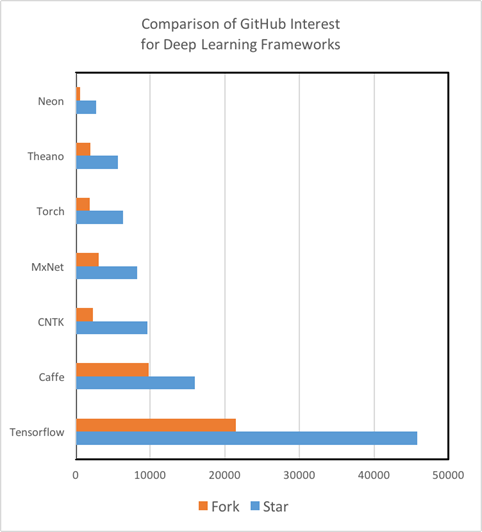
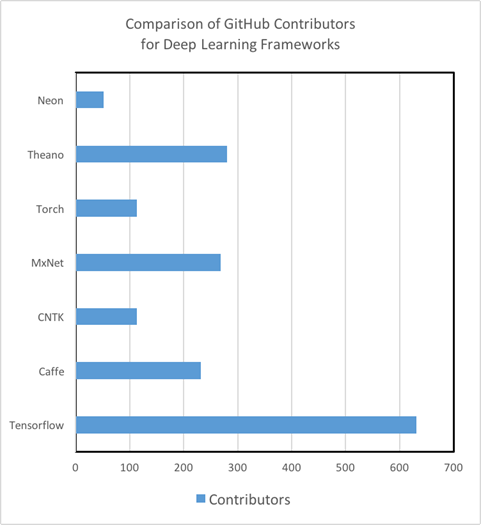
Руководства для изучения: Что касается качества и количества руководств для изучения и тренировочных материалов, то здесь существуют серьезные различия среди инструментов Deep Learning. Так, Theano, TensorFlow, Torch и MXNet обладают отлично написанными туториалами, их легко понять и использовать на практике. С другой стороны, мы не смогли найти руководства для начинающих работать с CNTK от Microsoft и Nervana Neon от Intel, достаточно продвинутыми инструментами анализа. Более того, мы выяснили, что степень вовлеченности GitHub сообщества — достоверный показатель не только будущего развития инструментария, но и того, с какой скоростью/вероятностью вы сможете исправить баг или ошибку в коде с помощью StackOverflow или Git Issues. Важно отметить, что сейчас TensorFlow — это Кинг-Конг в мире Deep Learning по части количества туториалов, материалов для самообучения, разработчиков, и, наконец, пользователей.
Возможности для моделирования CNN: Сверточные нейронные сети используются для распознавания изображений, рекомендательных систем, а также обработки естественного языка (NLP). CNN состоят из набора различных слоев, преобразующих входные данные в оценки для зависимой переменной с заранее известными классами. (Для дополнительной информации прочитайте обзор архитектур нейронных сетей от Eugenio Culurciello). CNN также могут быть использованы для решения задач регрессии, например, расчета угла поворота руля у машин на автопилоте. Мы провели оценку фреймворков в зависимости от наличия определенных возможностей для моделирования CNN: доступность встроенных слоев нейронных сетей, наличие инструментов и функций для соединения этих слоев между собой. В результате анализа, легкость в построении моделей используя TensorFlow и его InceptionV3, а также easy-to-use временная верстка CNN в Torch выделяют данные фреймворки среди остальных.
Возможности для моделирования RNN: Рекуррентные нейронные сети (RNN) используются для распознавания речи, прогнозирования временных рядов, захвата изображений и решения других задач, в которых требуется обработка последовательной информации. В связи с тем, что встроенные RNN модели не так распространены среди фреймворков как CNN, при реализации Deep Learning проекта важно изучить другие open-source проекты, использующие подходящую вам технологию. К примеру, Caffe имеет минимальное количество возможностей для RNN моделирования, в то время как Microsoft CNTK и Torch обладают богатыми наборами документаций и встроенных моделей. Tensorflow так же имеет некоторый набор материалов по RNN, а TFLearn и Keras включают в себя большое количество примеров RNN, использующих TensorFlow.
Архитектура и easy-to use модульный пользовательский интерфейс: Для того, чтобы создавать и обучать новые модели, фреймворк должен иметь легкий в использовании, модульный пользовательский интерфейс. TensorFlow, Torch и MXNet, например, им обладают, создавая интуитивно понятную среду для разработки. Для сравнения, такие фреймворки как Caffe требуют значительных усилий для создания нового слоя сети. Мы также выяснили, что, в частности, TensorFlow легко отлаживается не только во время, но и после обучения, благодаря TensorBoard GUI.
Скорость: Torch и Nervana показали наилучшие результаты при тестировании производительности сверточных нейронных сетей. TensorFlow прошел испытания с сопоставимыми результатами, а Caffe и Theano значительно отстали от лидеров. В свою очередь, Microsoft CNTK показал себя наилучшим образом при обучении рекуррентных нейронных сетей (RNN). Авторы другого исследования, сравнивая Theano, Torch и TensorFlow, выбрали Theano победителем по части обучения RNN.
Поддержка множества GPU: Большинство алгоритмов Deep Learning требуют невероятного количества FLOPS (floating point operations). К примеру, DeepSpeech, модель распознавания образов от Baidu, требует 10 экзафлопсов для обучения, а это более чем 10e18 вычислений! Учитывая, что один из лидеров рынка графических процессоров, NVIDIA`s Pascal TitanX может выполнять 11е9 флопсов в секунду, потребуется больше недели, чтобы обучить достаточно большой массив данных. Для того, чтобы уменьшить время создания модели, необходимо использовать различные GPU на различных системах. К счастью, большинство вышеуказанных инструментов предоставляют такую возможность. В частности, считается, что MXNet обладает одним из самых оптимизированных движков для работы с несколькими видеокартами.
Совместимость с Keras: Keras — это высокоуровневая библиотека для быстрой реализации Deep Learning алгоритмов, которая отлично подходит для знакомства аналитиков с областью. На данный момент Keras поддерживает 2 back-end-а, TensorFlow и Theano и в будущем будет получать официальную поддержку от TensorFlow. Более того, в пользу Keras говорит тот факт, что библиотека, по словам ее автора, продолжит выступать в качестве пользовательского интерфейса, который может быть использован с несколькими back-end-ами.
Таким образом, если вы заинтересованы в том, чтобы развиваться в области Deep Learning, я бы рекомендовал сперва оценить способности и требования вашей команды и проекта соответственно. Например, для распознавания изображений командой разработчиков на Python, оптимальным вариантом будет использовать TensorFlow, учитывая его обширную документацию, высокую производительность и отличный инструментарий для проектирования. С другой стороны, для реализации проекта на основе RNN с командой профессионалов в Lua, наилучший вариант — это Torch и его невероятная скорость вкупе с возможностями моделирования рекуррентных сетей.
Биография: Мэтью Рубашкин наряду с солидным бэкграундом в оптической физике и биомедицинских исследованиях обладает опытом разработки, управления базами данных и предиктивной аналитики.
===
В своей программе Deep Learning, которая 8 апреля стартует уже во второй раз, мы используем две библиотеки: Keras и Caffe. Как было отмечено, Keras является более высокоуровневой библиотекой и позволяет быстро прототипировать. Это является плюсом, поскольку на программе не придется тратить время на то, чтобы узнать, как работать с тем же TensorFlow, а сразу взять и попробовать на практике разные вещи.
Caffe — также довольно понятная в использовании, хоть и не очень удобная, но при этом она может использоваться в production-решениях. В обзоре она не отмечена как самая быстрая. Если перейти по ссылке на исходный анализ скорости, то можно увидеть примечание: «может показаться, что TensorFlow и Chainer быстрее, чем Caffe, но на самом деле это может быть не так, поскольку указанные фреймворки тестировались на CuDNN, а Caffe на своем дефолтном движке».
