Building client routing / semantic search at Profi.ru
TLDR
This is a very short executive summary (or a teaser) about what we managed to do in approximately 2 months in the Profi.ru DS department (I was there for a bit longer, but onboarding myself and my team was a separate thing to be done at first).
Projected goals
- Understand client input / intent and route clients accordingly (we opted for input quality agnostic classifier in the end, though we considered type-ahead char level models and language models as well. Simplicity rules);
- Find totally new services and synonyms for the existing services;
- As a sub-goal of (2) — learn to build proper clusters on arbitrary external corpuses;
Achieved goals
Obviously some of these results were achieved not only by our team, but by several teams (i.e. we obviously did not do the scraping part for domain corpuses and the manual annotation, though I believe scraping can be also solved by our team — you just need enough proxies + probably some experience with selenium).
Business goals:
- ~
88+%(vs ~60%with elastic search) accuracy on client routing / intent classification (~5kclasses); - Search is agnostic to input quality (misprints / partial input);
- Classifier generalizes, morphologic structure of the language is exploited;
- Classifier severely beats elastic search on various benchmarks (see below);
- To be on the safe side — at least
1,000new services were found + at least15,000synonyms (vs. the current state of5,000+ ~30,000). I expect this figure to double of even triple;
The last bullet is a ballpark estimate, but a conservative one.
Also AB tests will follow. But I am confident in these results.
«Scientific» goals:
- We thoroughly compared many modern sentence embedding techniques using a downstream classification task + KNN with a database of service synonyms;
- We managed to beat weakly supervised (essentially their classifier is a bag-of-ngrams) elastic search on this benchmark (see details below) using UNSUPERVISED methods;
- We developed a novel way of building applied NLP models (a plain vanilla bi-LSTM + bag of embeddings, essentially fast-text meets RNN) — this takes the morphology of the Russian language into consideration and generalizes well;
- We demonstrated that our final embedding technique (a bottle-neck layer from the best classifier) combined with state-of-the-art unsupervised algorithms (UMAP + HDBSCAN) can produce stellar clusters;
- We demonstrated in practice the possibility, feasibility and usability of:
- Knowledge distillation;
- Augmentations for text data (sic!);
- Training text-based classifiers with dynamic augmentations reduced convergence time drastically (10x) compared to generating larger static datasets (i.e. the CNN learns to generalize the mistake being shown drastically less augmented sentences);
Overall project structure
This does not include the final classifier.
Also in the end we abandoned fake RNN and triplet loss models in favour of the classifier bottleneck.

What works in NLP now?
A birds' eye view: 
Also you may know that NLP may be experiencing the Imagenet moment now.
Large scale UMAP hack
When building clusters, we stumbled upon a way / hack to essentially apply UMAP to 100m+ point (or maybe even 1bn) sized datasets. Essentially build a KNN graph with FAISS and then just rewrite the main UMAP loop into PyTorch using your GPU. We did not need that and abandoned the concept (we had only 10–15m points after all), but please follow this thread for details.
What works best
- For supervised classification fast-text meets the RNN (bi-LSTM) + carefully chosen set of n-grams;
- Implementation — plain python for n-grams + PyTorch Embedding bag layer;
- For clustering — the bottleneck layer of this model + UMAP + HDBSCAN;
Best classifier benchmarks
Manually annotated dev set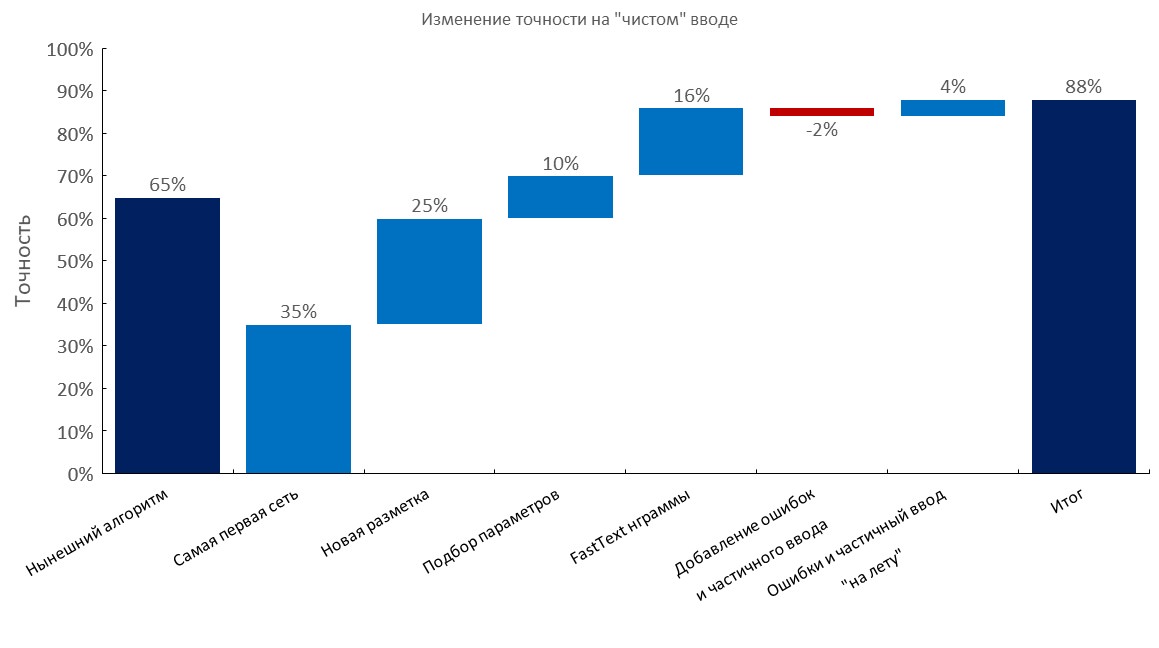
Left to right:
(Top1 accuracy)
- Current algorithm (elastic search);
- First RNN;
- New annotation;
- Tuning;
- Fast-text embedding bag layer;
- Adding typos and partial input;
- Dynamic generation of errors and partial input (training time reduced 10x);
- Final score;
Manually annotated dev set + 1–3 errors per query
Left to right:
(Top1 accuracy)
- Current algorithm (elastic search);
- Fast-text embedding bag layer;
- Adding typos and partial input;
- Dynamic generation of errors and partial input;
- Final score;
Manually annotated dev set + partial input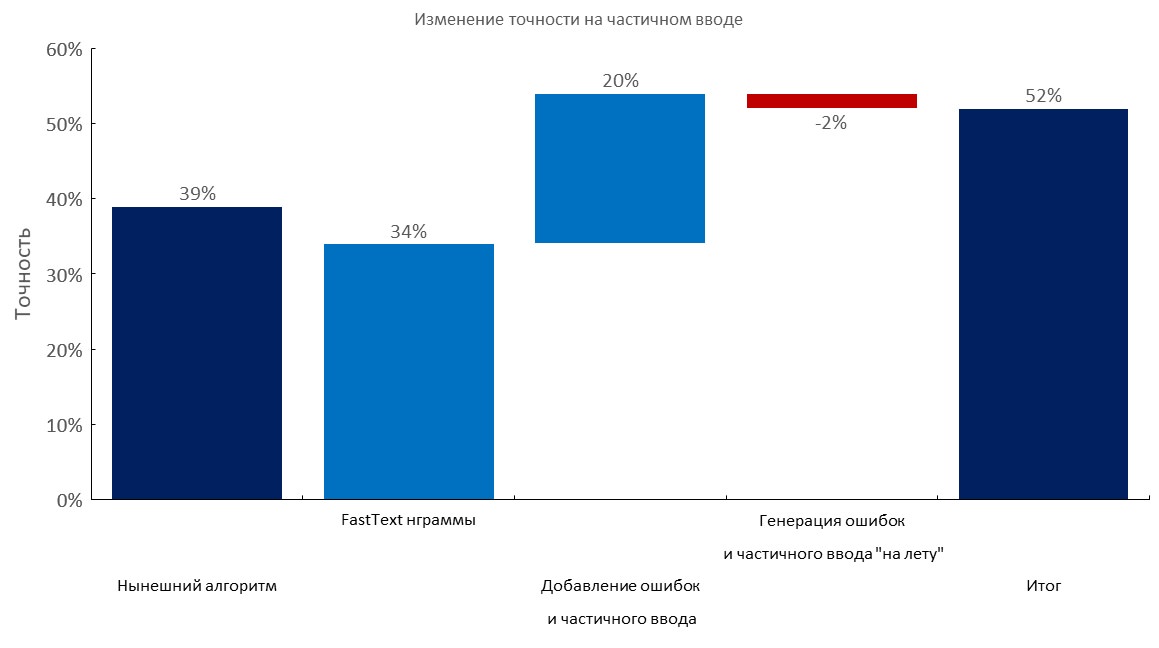
Left to right:
(Top1 accuracy)
- Current algorithm (elastic search);
- Fast-text embedding bag layer;
- Adding typos and partial input;
- Dynamic generation of errors and partial input;
- Final score;
Large scale corpuses / n-gram selection
- We collected the largest corpuses for the Russian language:
- Areneum — a processed version is available here — dataset authors did not reply;
- Taiga;
- Common crawl and wiki — please follow these articles;
- We collected a
100mword dictionary using 1TB crawl; - Also use this hack to download such files faster (overnight);
- We selected an optimal set of
1mn-grams for our classifier to generalize best (500kmost popular n-grams from fast-text trained on Russian Wikipedia +500kmost popular n-grams on our domain data);
Stress test of our 1M n-grams on 100M vocabulary: 
Text augmentations
In a nutshell:
- Take a large dictionary with errors (e.g. 10–100m unique words);
- Generate an error (drop a letter, swap a letter using calculated probabilities, insert a random letter, maybe use keyboard layout, etc);
- Check that new word is in dictionary;
We brute forced a lot of queries to services like this one (in attempt to essentially reverse engineer their dataset), and they have a very small dictionary inside (also this service is powered by a tree classifier with n-gram features). It was kind of funny to see that they covered only 30–50% of words we had on some corpuses.
Our approach is far superior, if you have access to a large domain vocabulary.
Best unsupervised / semi-supervised results
KNN used as a benchmark to compare different embedding methods.
(vector size) List of models tested:
- (512) Large scale fake sentence detector trained on 200 GB of common crawl data;
- (300) Fake sentence detector trained to tell a random sentence from Wikipedia from a service;
- (300) Fast-text obtained from here, pre-trained on araneum corpus;
- (200) Fast-text trained on our domain data;
- (300) Fast-text trained on 200GB of Common Crawl data;
- (300) A Siamese network with triplet loss trained with services / synonyms / random sentences from Wikipedia;
- (200) First iteration of embedding bag RNN’s embedding layer, a sentence is encoded as a whole bag of embeddings;
- (200) Same, but first the sentence is split into words, then each word is embedded, then average is taken;
- (300) The same as above but for the final model;
- (300) The same as above but for the final model;
- (250) Bottleneck layer of the final model (250 neurons);
- Weakly supervised elastic search baseline;
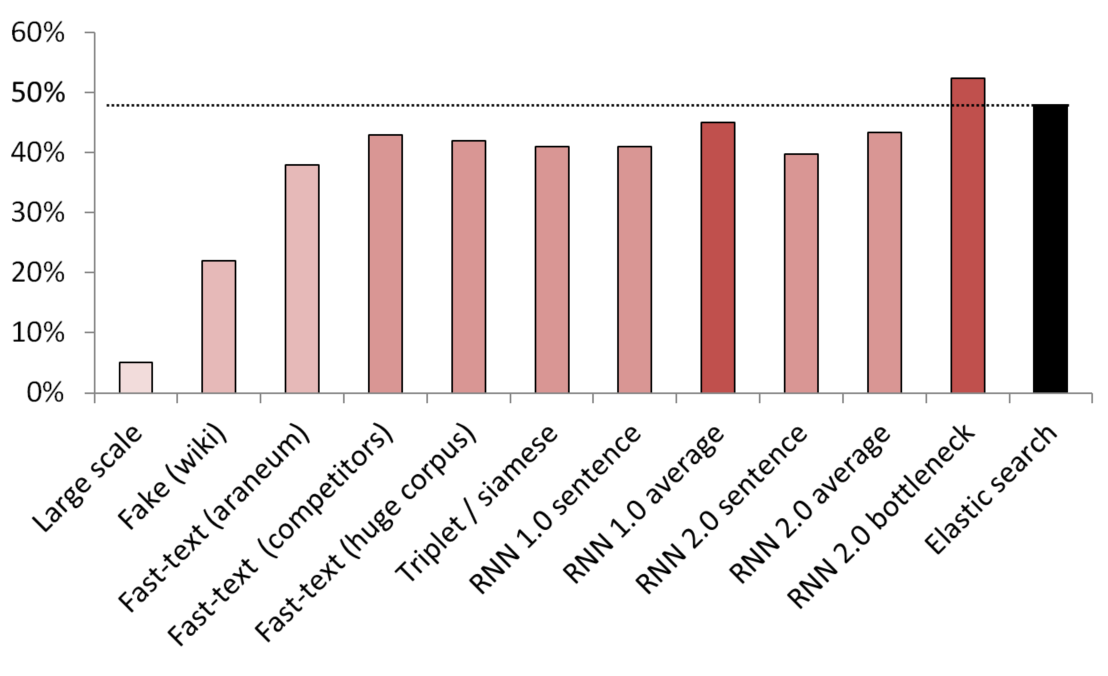
To avoid leaks, all the random sentences were randomly sampled. Their length in words was the same as the length of services / synonyms they were compared with. Also measures were taken to make sure that models did not just learn by separating vocabularies (embeddings were frozen, Wikipedia was undersampled to make sure that there was at least one domain word in each Wikipedia sentence).
Cluster visualization
3D
2D
Cluster exploration «interface»
Green — new word / synonym.
Gray background — likely new word.
Gray text — existing synonym.

Ablation tests and what works, what we tried and what we did not
- See the above charts;
- Plain average / tf-idf average of fast-text embeddings — a VERY formidable baseline;
- Fast-text > Word2Vec for Russian;
- Sentence embedding by fake sentence detection kind of works, but pales in comparison with other methods;
- BPE (sentencepiece) showed no improvement on our domain;
- Char level models struggled to generalize, despite the recant paper from google;
- We tried multi-head transformer (with classifier and language modelling heads), but on the annotation available at hand it performed roughly the same as plain vanilla LSTM-based models. When we migrated to embedding bad approaches we abandoned this line of research due to transformer’s lower practicality and impracticality of having a LM head along with embedding bag layer;
- BERT — seems to be overkill, also some people claim that transformers train literally for weeks;
- ELMO — using a library like AllenNLP seems counter productive in my opinion both in research / production and education environments for reasons I will not provide here;
Deploy
Done using:
- Docker container with a simple web-service;
- CPU-only for inference is enough;
- ~
2.5 msper query on CPU, batching not really necessary; - ~
1GBRAM memory footprint; - Almost no dependencies, apart from
PyTorch,numpyandpandas(and web server ofc). - Mimic fast-text n-gram generation like this;
- Embedding bag layer + indexes as just stored in a dictionary;
