Безопасное взаимодействие в распределенных системах

Привет Хабр!
Меня зовут Алексей Солодкий, я PHP-разработчик в компании Badoo. И сегодня я поделюсь текстовой версией моего доклада для первого Badoo PHP Meetup. Видео этого и других докладов с митапа можно найти здесь.
Любая система, состоящая хотя бы из двух компонентов (а если у вас есть и PHP, и база данных, то это уже два компонента), сталкивается с целыми классами рисков во взаимодействии между этими компонентами.
Отдел платформы, в котором я работаю, интегрирует новые внутренние сервисы с нашим приложением. И решая эти задачи, мы накопили опыт, которым я и хочу поделиться.
Наш бекенд — это PHP-монолит, взаимодействующий со множеством сервисов (самописных из них сейчас порядка пятидесяти). Между собой сервисы взаимодействуют редко. Но проблемы, о которых я говорю в статье, также актуальны для микросервисной архитектуры. Ведь в этом случае сервисы очень активно взаимодействуют друг с другом, а чем больше у вас взаимодействия, тем больше у вас проблем.
Рассмотрим, что делать, когда сервис падает или тупит, как организовать сбор метрик и что делать, когда всё вышесказанное вас не спасёт.
Падение сервиса
Рано или поздно сервер, на котором стоит ваш сервис, упадет. Это точно случится, и вы не сможете от этого защититься — только уменьшить вероятность. Вас может подвести железо, сеть, код, неудачный деплой — что угодно. И чем больше у вас серверов, тем чаще такое будет происходить.
Как сделать так, чтобы ваши сервисы выживали в мире, в котором постоянно падают сервера? Общий подход к решению этого класса проблем — резервирование.
Резервирование используется повсеместно на разных уровнях: от железа до целых дата-центров. Например, RAID1 для защиты от отказа винчестера или резервный блок питания у вашего сервера, на случай выхода из строя первого. Также эта схема широко применяется и к базам данных. Например, для этого можно использовать master-slave.
Рассмотрим типовые проблемы с резервированием на примере простейшей схемы:
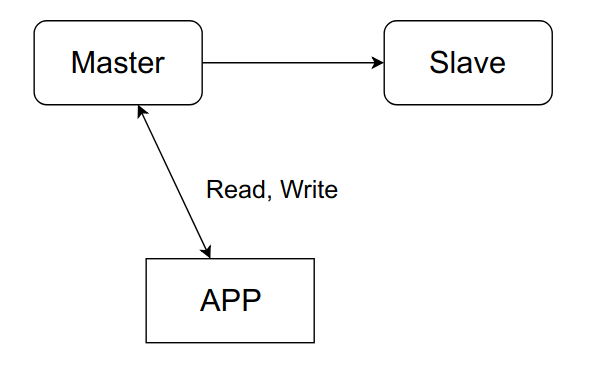
Приложение общается исключительно с мастером, при этом в фоновом режиме, асинхронно, данные передаются в слейв. Когда мастер упадёт, мы переключимся на слейв и продолжим работать.

После восстановления мастера мы просто сделаем из него новый слейв, а старый превратится в мастера.
Схема простая, но даже у нее есть много нюансов, характерных для любых схем с резервированием.
Нагрузка
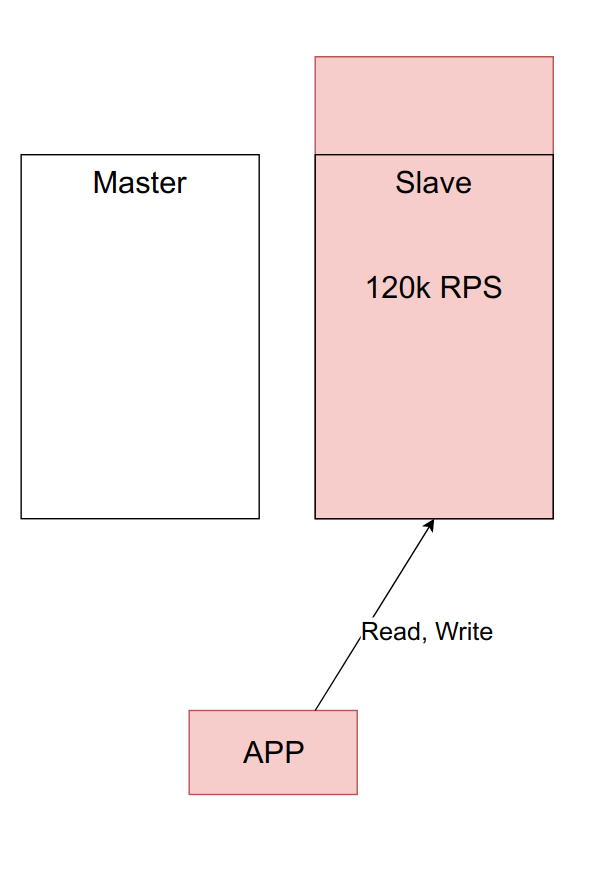
Допустим, что один сервер из примера выше может выдержать примерно 100к RPS. Сейчас нагрузка составляет 60к RPS, и всё работает как часы.
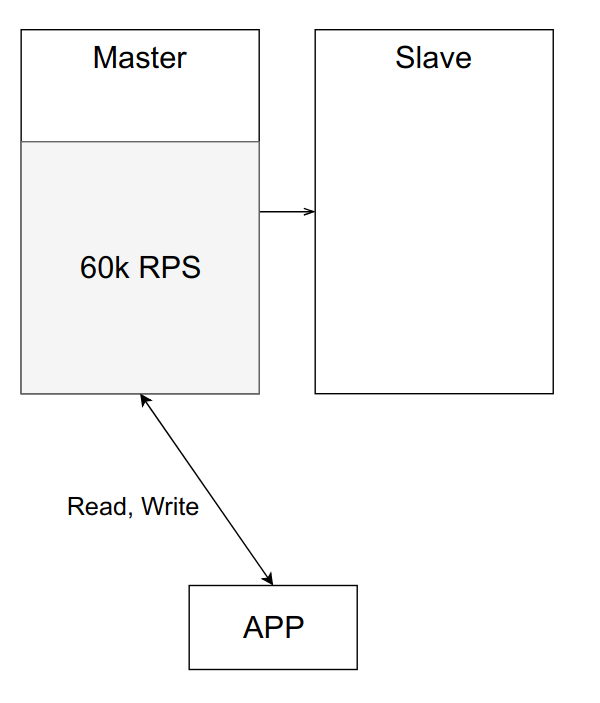
Но со временем нагрузка на приложение, а значит и нагрузка на мастер, увеличивается. Вы можете захотеть её балансировать, переведя часть чтения на слейв.
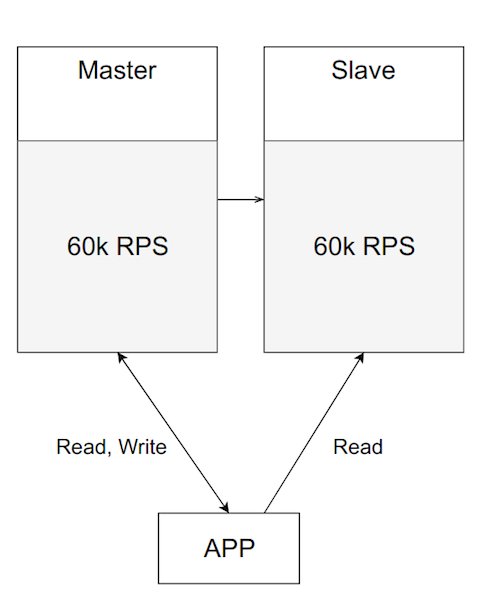
Выглядит вроде неплохо. Нагрузку держит, сервера больше не простаивают. Но это плохая идея. Важно помнить, зачем вы изначально подняли слейв — для переключения на него в случае проблем с основным. Если вы начали нагружать оба сервера, то когда ваш мастер упадет —, а он рано или поздно упадет, — вам придется переключить основной трафик с мастера на резервный сервер, а он и так уже нагружен. Подобная перегрузка либо сделает вашу систему ужасно медленной, либо полностью выведет её из строя.
Данные
Главная проблема при добавлении отказоустойчивости к сервису — это локальное состояние. Если ваш сервис stateless, т. е. не хранит никаких изменяемых данных, то его масштабирование не представляет проблемы. Просто поднимаем столько инстансов, сколько нам необходимо, и балансируем запросы между ними.
В случае же когда сервис stateful, мы так поступить уже не можем. Нужно думать о том, как хранить одни и те же данные на всех инстансах нашего сервиса, чтобы они оставались консистентными.
Для решения этой проблемы применяется один из двух подходов: либо синхронная, либо асинхронная репликация. В общем случае я советую использовать асинхронный вариант, так как он в целом проще и быстрее на запись, и уже по обстоятельствам смотреть, нужно ли переходить на синхронную.
Важный нюанс, который стоит учитывать при работе с асинхронной репликацией, — eventual consistency. Это значит, что в конкретный момент времени на разных слейвах данные могут отставать от мастера на непредсказуемые и разные интервалы времени.
Соответственно, вы не можете читать данные каждый раз со случайного сервера, поскольку тогда на одни и те же запросы пользователя могут приходить разные ответы. Для обхода этой проблемы применяется механизм sticky-сессий, который гарантирует, что все запросы одного пользователя идут на один инстанс.
Плюсы синхронного подхода в том, что данные всегда находятся в согласованном состоянии, и риск потерять данные ниже (т. к. они считаются записанными только после того как это сделали все сервера). Однако за это приходится платить скоростью записи и сложностью самой системы (например, различные алгоритмы кворумов для защиты от split-brain).
Выводы
- Резервируйте. Если важны сами данные и доступность конкретного сервиса, то убедитесь, что ваш сервис переживёт падение конкретной машины.
- При расчёте нагрузки учитывайте падение части серверов. Если в вашем кластере четыре сервера, убедитесь, что когда один упадёт, три оставшихся потянут нагрузку.
- Выбирайте тип репликации в зависимости от задач.
- Не кладите все яйца в одну корзину. Убедитесь, что вы достаточно далеко разносите резервные сервера. В зависимости от критичности доступности сервиса, ваши сервера могут быть как в разных стойках в одном дата-центре, так и в разных дата-центрах в разных странах. Всё зависит от того, насколько глобальную катастрофу вы хотите и готовы пережить.
Тупка сервиса
В какой-то момент ваш сервис может начать очень медленно работать. Эта проблема может возникнуть по множеству причин: чрезмерная нагрузка, лаги сети, проблемы с железом или ошибки в коде. Выглядит как не слишком страшная проблема, но на самом деле она коварней, чем кажется.
Представим: пользователь запрашивает некую страничку. Мы синхронно и последовательно обращаемся к четырем демонам, чтобы отрисовать её. Они быстро отвечают, всё работает хорошо.
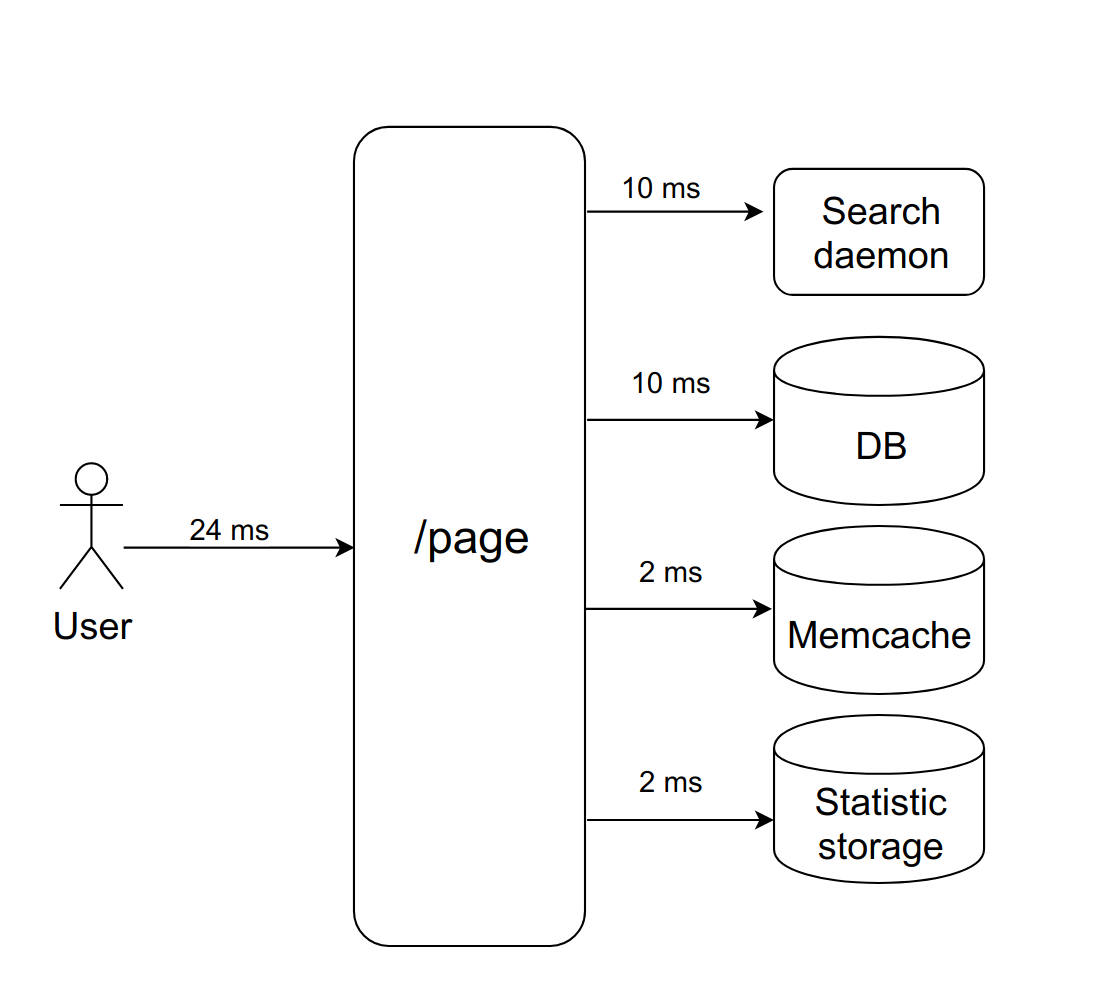
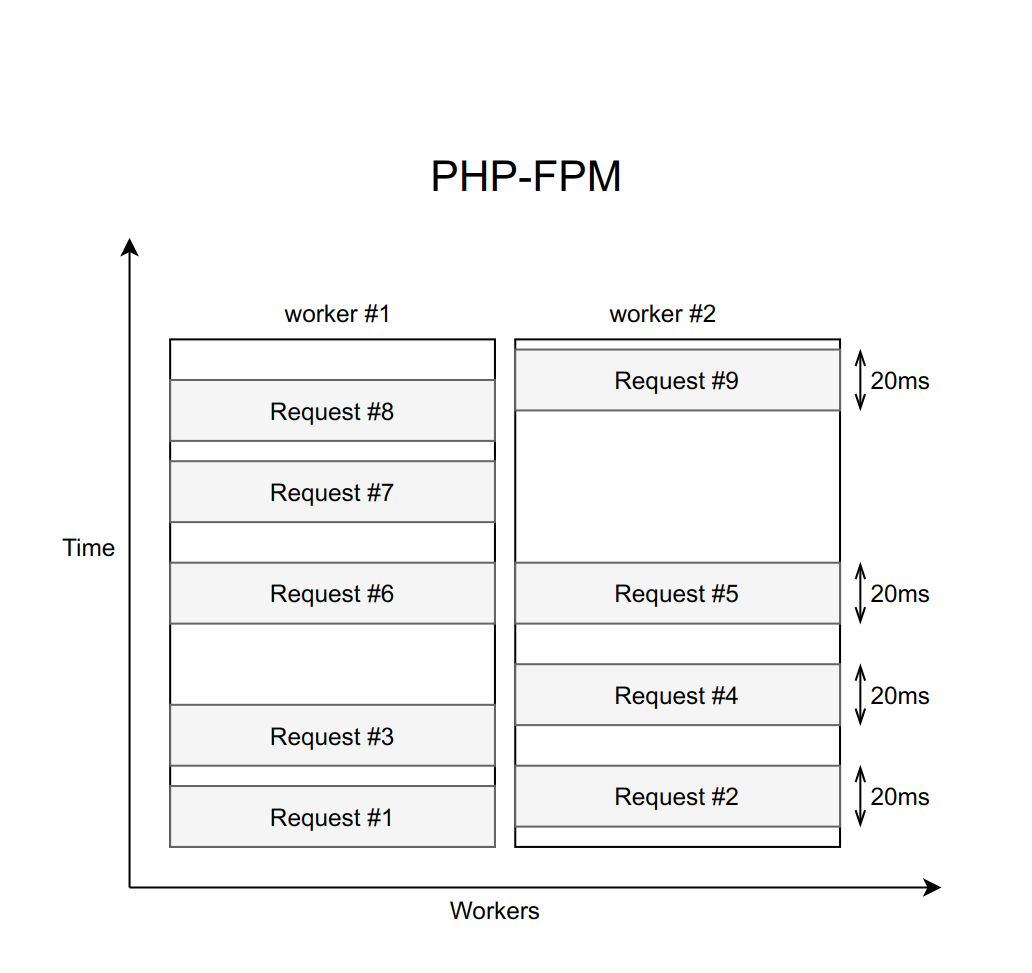
Допустим, это дело обрабатывается с помощью nginx с фиксированным количеством PHP FPM воркеров (с десятью, например). Если каждый запрос обрабатывается примерно 20 мс, то с помощью несложных вычислений можно понять, что наша система способна обработать около пятисот запросов в секунду.
Что случится, когда один из этих четырех сервисов начнёт подтупливать, и обработка запросов к нему возрастет с 20 мс до таймаута в 1000 мс? Здесь важно помнить, что когда мы работаем с сетью, задержка может быть бесконечно большой. Поэтому необходимо всегда ставить таймаут (в данном случае он равен секунде).
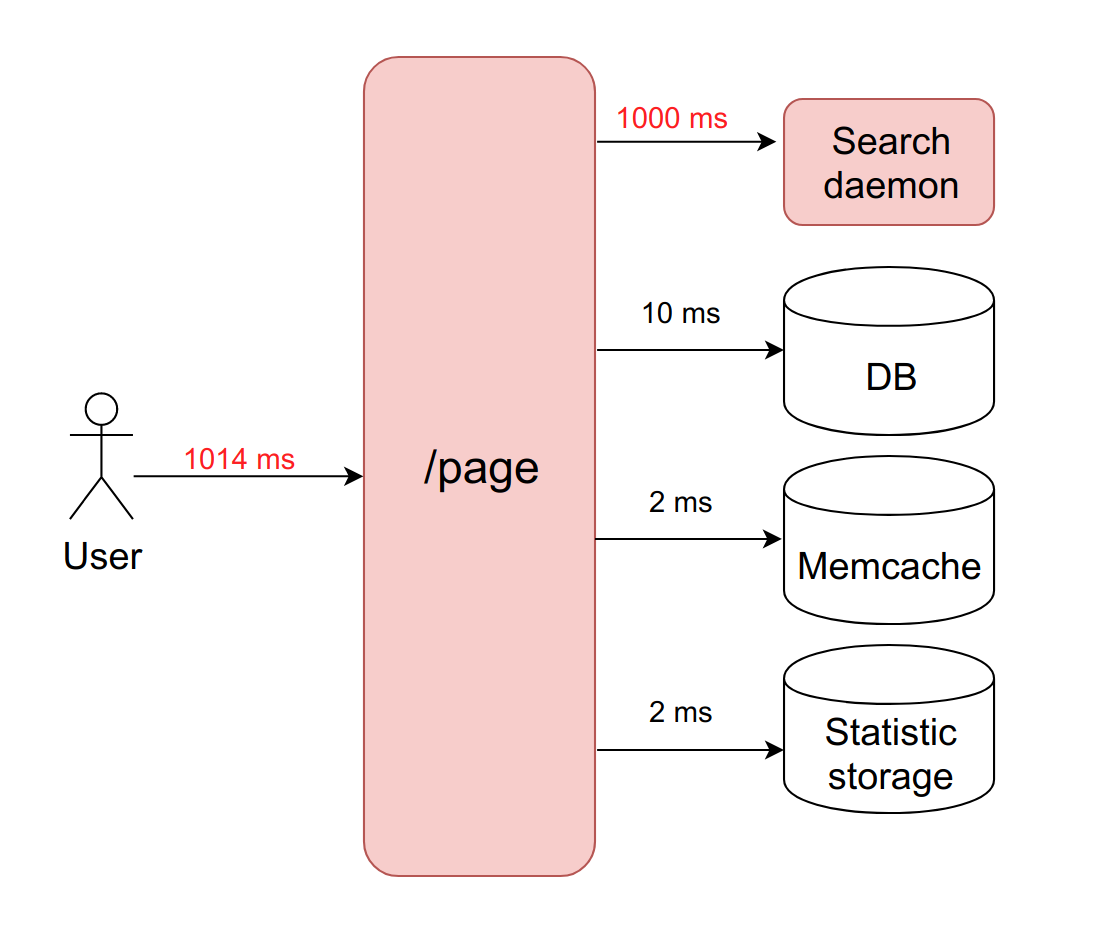
Получается, что бекенд вынужден ждать истечения таймаута, чтобы получить и обработать ошибку от демона. А это значит, что пользователь получает страницу через одну секунду вместо десяти миллисекунд. Медленно, но не фатально.
Но в чём здесь на самом деле проблема? Дело в том, что когда у нас каждый запрос обрабатывается секунду, пропускная способность трагически падает до десяти запросов в секунду. И одиннадцатый по счёту пользователь уже не сможет получить ответ, даже если он запрашивал страницу, никак не связанную с тупящим сервисом. Просто потому что все десять воркеров заняты ожиданием таймаута, и не могут обрабатывать новые запросы.
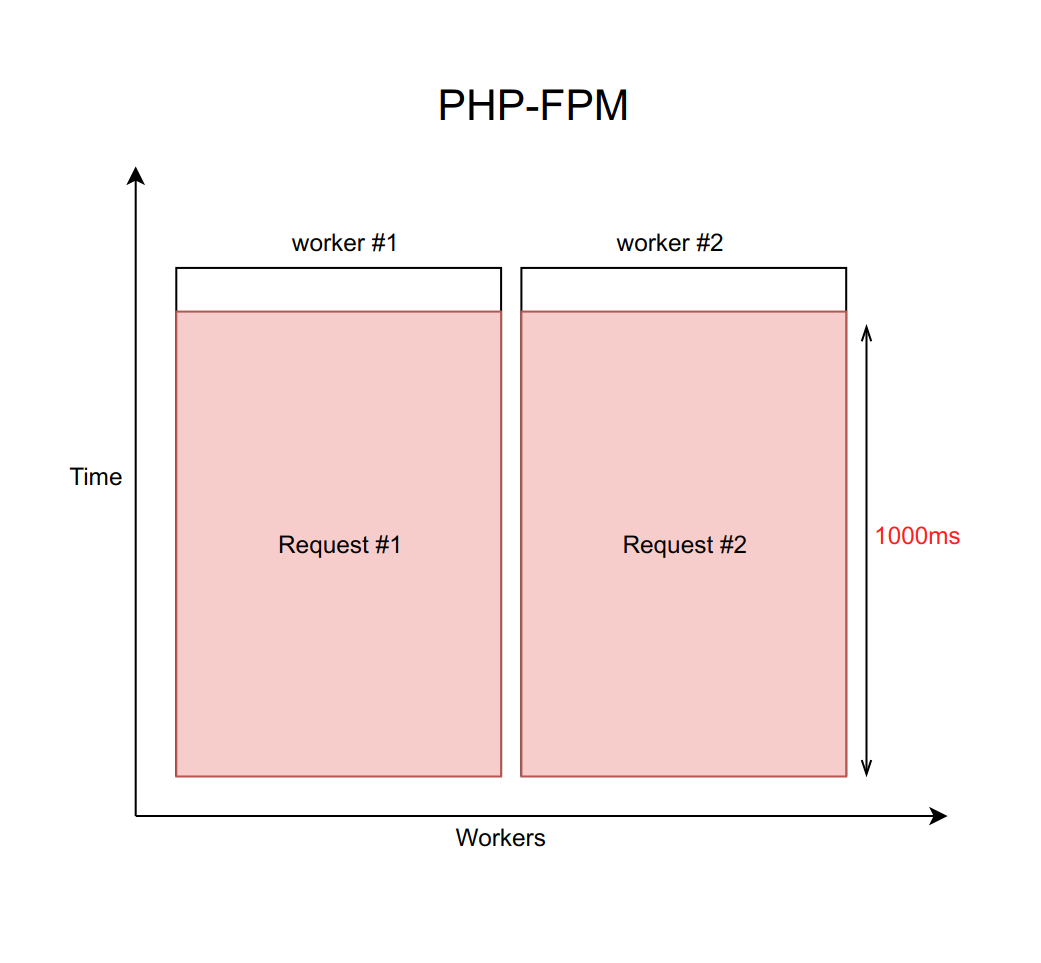
При этом важно понимать, что увеличением количества воркеров эта проблема не решается. Ведь каждый воркер требует для своей работы определённое количество оперативной памяти, даже если он не выполняет реальную работу, а просто висит в ожидании таймаута. Поэтому если вы не ограничите количество воркеров в соответствии с возможностями вашего сервера, то поднятие всё новых и новых воркеров положит сервер целиком. Этот случай — пример каскадного отказа, когда падение какого-то одного, пусть даже не критичного для пользователя сервиса, вызывает отказ всей системы.
Решение
Существует паттерн под названием circuit breaker. Его задача довольно проста: он должен в какой-то момент времени вырубить тупящий сервис. Для этого между сервисом и воркерами ставится некая прокся. Это может быть как PHP-код с хранилищем, так и демон на локальном хосте. Важно отметить, что если у вас несколько инстансов (ваш сервис реплицирован), то эта прокся должна отдельно отслеживать каждый из них.
Мы написали свою реализацию этого паттерна. Но не потому что очень любим писать код, а потому что когда много лет назад мы решали эту проблему, готовых решений ещё не было.
Сейчас я в общих чертах расскажу о нашей реализации и как она помогает избежать этой проблемы. А подробнее о ней и её отличиях от других решений можно услышать в докладе Михаила Курмаева на Highload Siberia в конце июня. Расшифровка его доклада также будет в этом блоге.
Выглядит всё примерно так:
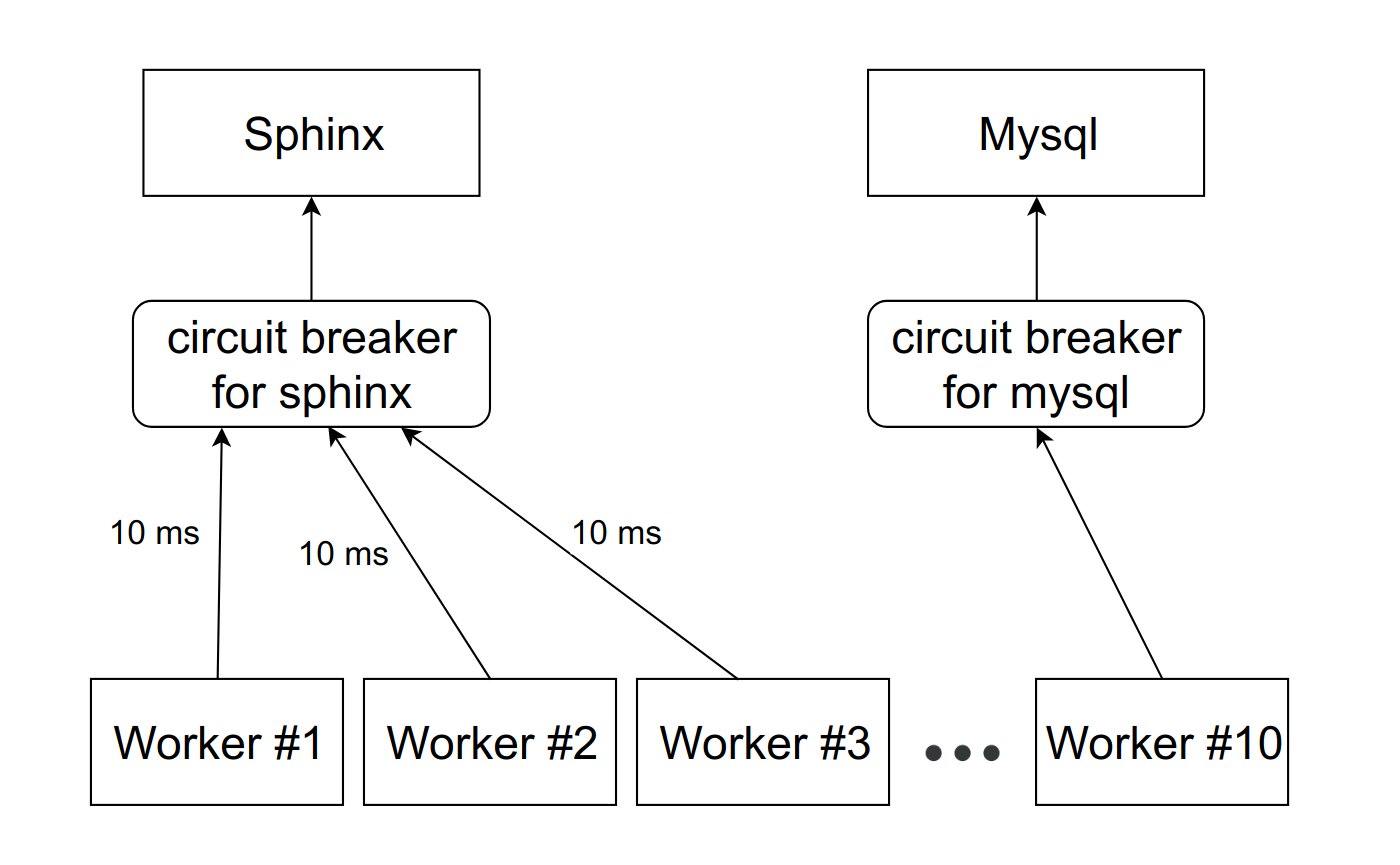
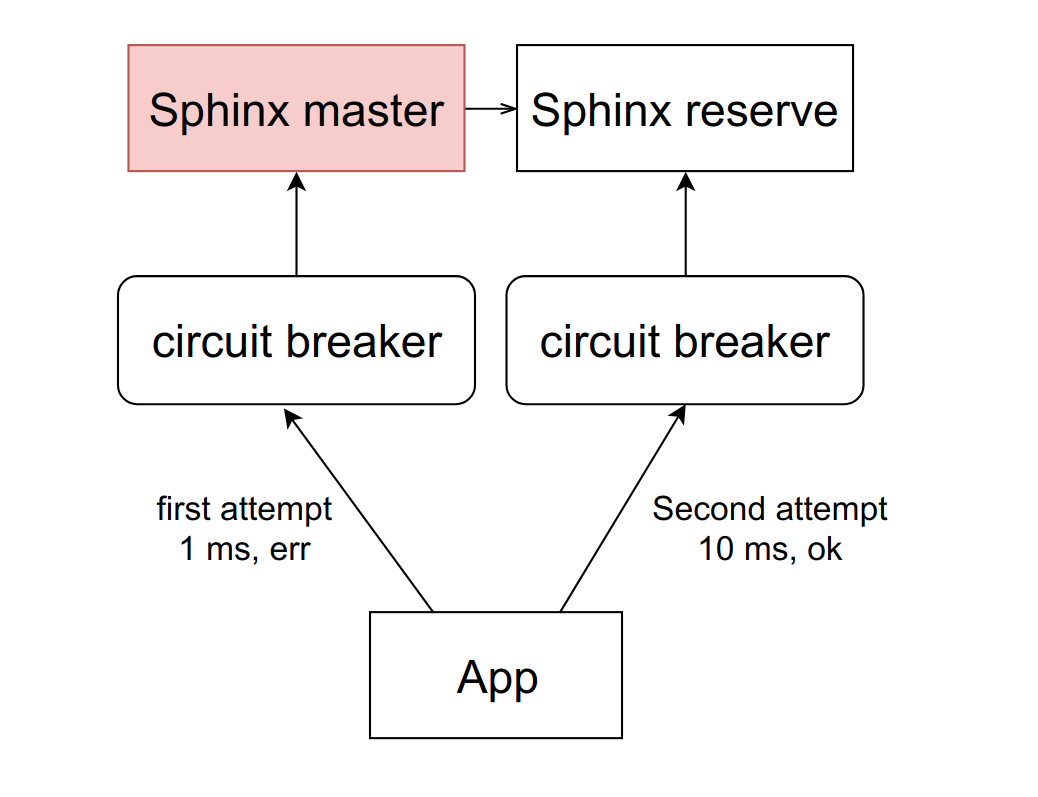
Есть абстрактный сервис Sphinx, перед которым стоит circuit breaker. Circuit breaker хранит количество активных подключений к конкретному демону. Как только это значение достигает порога, который мы устанавливаем в проценте от доступных FPM-воркеров на машине, мы считаем, что сервис начал притормаживать. При достижении первого порога мы отправляем уведомление ответственному за сервис. Такая ситуация — либо признак того, что нужно пересмотреть лимиты, либо предвестник проблем с тупкой.
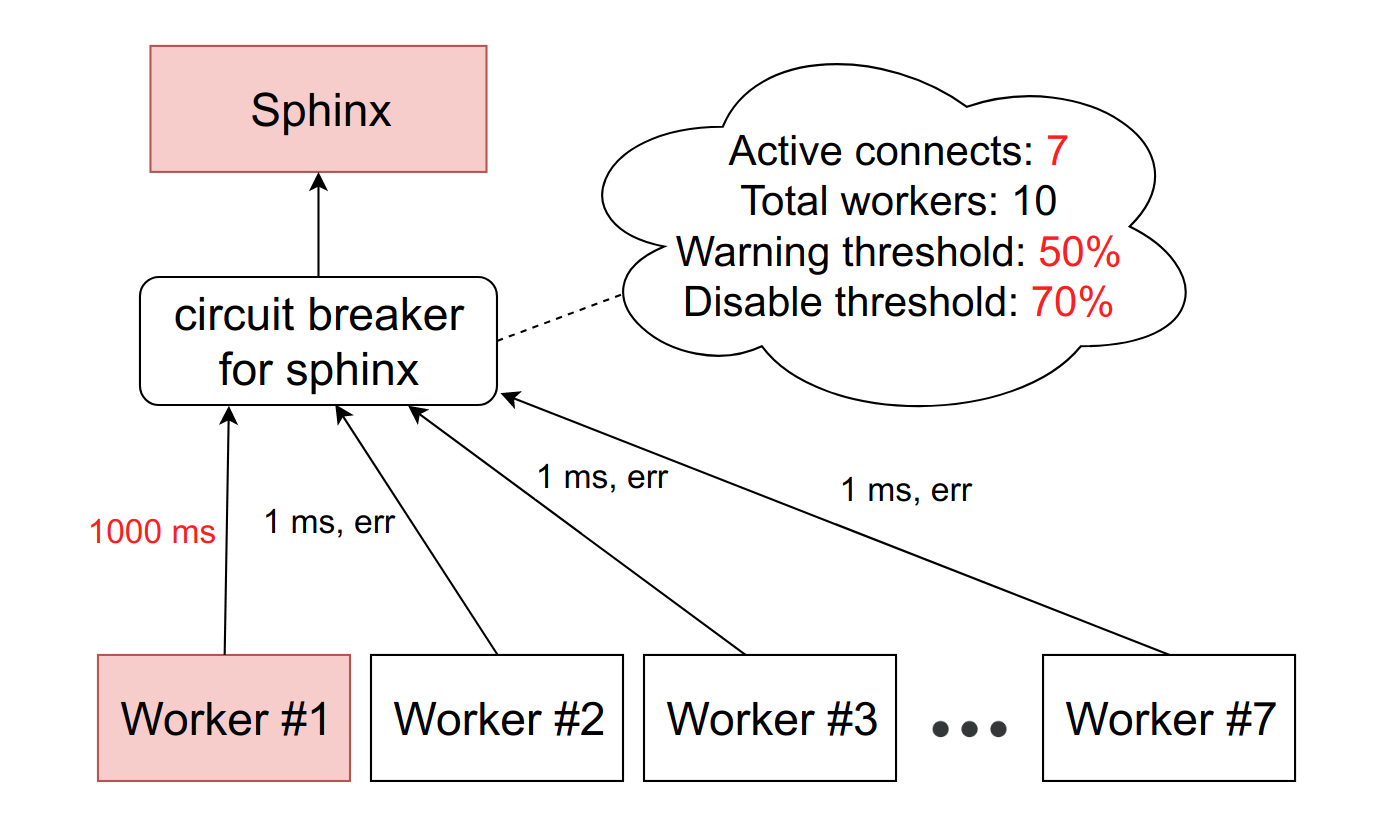
Если ситуация ухудшается, и количество тормозящих воркеров достигает второго порогового значения — у нас в production это около 10%, — мы вырубаем этот хост полностью. Точнее, сервис фактически продолжает работать, но мы перестаём слать ему запросы. Circuit brеaker их отбрасывает и сразу отдаёт воркерам ошибку, как будто бы сервис лежит.
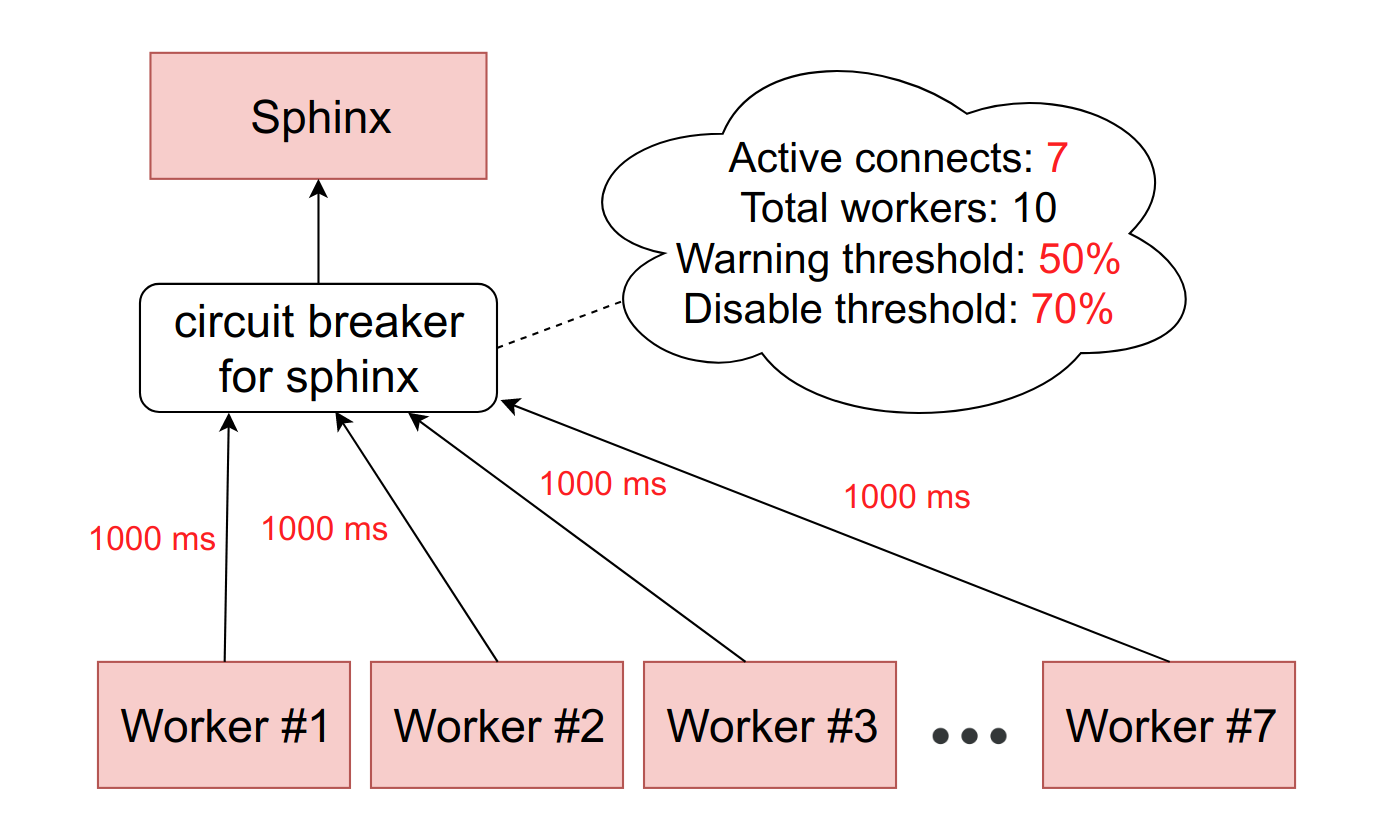
Время от времени мы автоматически пропускаем запрос от какого-нибудь воркера, чтобы посмотреть, не ожил ли всё-таки сервис. Если он отвечает адекватно, то мы снова включаем его в работу.
Всё это делается для того, чтобы свести ситуацию к предыдущей схеме с репликацией. Вместо того чтобы ждать секунду, перед тем как понять, что хост недоступен, мы сразу получаем ошибку и переходим на резервный хост.
Реализации
К счастью, Open Source не стоит на месте, и сегодня вы можете взять готовое решение на Github.
Существуют два основных подхода реализации circuit breaker: библиотека, работающая на уровне кода, и отдельно стоящий демон, который проксирует через себя запросы.
Вариант с библиотекой больше подходит, если у вас есть один основной монолит на PHP, который взаимодействует с несколькими сервисами, а сервисы друг с другом почти не общаются. Вот несколько доступных реализаций:
Если же у вас много сервисов на разных языках, и все они друг с другом взаимодействуют, то вариант на уровне кода придется дублировать на всех этих языках. Это неудобно в поддержке, и в конечном итоге приведёт к расхождениям реализаций.
Поставить один демон в этом случае гораздо проще. При этом вам не придётся особо править код. Демон старается сделать взаимодействие прозрачным. Однако этот вариант сильно сложнее архитектурно.
Вот несколько вариантов (функциональность там богаче, но circuit brеaker тоже есть):
Выводы
- Не полагайтесь на сеть.
- Все сетевые запросы должны иметь таймаут, потому что сеть может отдавать бесконечно долго.
- Используйте circuit breaker, если хотите избежать каскадного отказа приложения из-за того, что тормозит один маленький сервис.
Мониторинг и телеметрия
Что это даёт
- Предсказуемость. Важно прогнозировать, какая нагрузка сейчас, а какая будет через месяц, чтобы своевременно увеличивать количество инстансов сервиса. Это особенно актуально, если вы имеете дело с железной инфраструктурой, так как заказ новых серверов занимает время.
- Расследование инцидентов. Рано или поздно всё равно что-то пойдёт не так, и вам придется это расследовать. И важно иметь достаточно данных, чтобы разобраться в проблеме и уметь предотвращать такие ситуации в будущем.
- Предотвращение аварий. В идеале вы должны понимать, какие паттерны приводят к авариям. Важно отслеживать эти паттерны и своевременно уведомлять о них команду.
Что мерить
Интеграционные метрики
Так как мы говорим о взаимодействии между сервисами, то мониторим всё, что можно, применительно к общению сервиса с приложением. Например:
- количество запросов;
- время обработки запроса (включая перцентили);
- количество ошибок логики;
- количество системных ошибок.
Важно отличать ошибки логики от системных ошибок. Если сервис падает, это штатная ситуация: просто переключаемся на второй. Но это не так страшно. Если у вас начинаются какие-то ошибки логики, например, странные данные поступают в сервис или уходят из него, то это уже нужно расследовать. Скорее всего, ошибка связана с багом в коде. Сама она не пройдёт.
Внутренние метрики
По умолчанию сервис представляет собой черный ящик, который делает свою работу непонятно как. Желательно всё-таки разобраться и собрать максимум данных, которые сервис может предоставить. Если сервис представляет собой специализированную базу данных, которая хранит какие-то данные вашей бизнес-логики, отслеживайте, сколько именно данных, какого они типа и прочие метрики содержимого. Если у вас асинхронное взаимодействие, то важно также отслеживать те очереди, через которые общается ваш сервис: их скорость прихода и ухода, время на разных этапах (если у вас несколько промежуточных точек), количество событий в очереди.
Посмотрим, какие метрики можно собирать на примере memcached:
- соотношение hit/miss;
- время ответа по разным операциями;
- RPS разных операций;
- разбивка этих же данных по разным ключам;
- топ нагруженных ключей;
- все внутренние метрики, которые отдаёт команда stats.
Как это делать
Если у вас небольшая компания, небольшой проект и мало серверов, то хорошим решением будет подключить какой-нибудь SaaS для сбора и просмотра — это проще и дешевле. При этом обычно SaaS обладают обширной функциональностью, и не придётся заботиться о многих вещах. Примеры таких сервисов:
В качестве альтернативы вы всегда можете установить на собственную машину Zabbix, Grafana или любое другое self-hosted решение.
Выводы
- Собирайте все метрики, какие можете. Данные лишними не бывают. Когда вам придется что-то расследовать, вы скажете себе спасибо за предусмотрительность.
- Не забывайте об асинхронном взаимодействии. Если у вас есть какие-то очереди, которые доезжают постепенно, важно понимать, насколько быстро они доезжают, что происходит с вашими событиями на стыке между сервисами.
- Если вы пишете свой сервис, научите его отдавать статистику о работе. Часть данных можно измерить на слое интеграции, когда мы общаемся с этим сервисом. Остальное сервис должен уметь отдавать по условной команде stats. К примеру, во всех наших сервисах на Go эта функциональность является стандартной.
- Настраивайте триггеры. Графики — это хорошо, но лишь пока вы на них смотрите. Важно, чтобы у вас была настроенная система, которая сообщит вам, если что-то пойдёт не так.
Memento Mori
А теперь немного о грустном. Может сложиться ощущение, что вышеописанное — панацея, и теперь ничто никогда не будет падать. Но даже если вы примените всё описанное выше, всё равно что-нибудь когда-нибудь упадет. Важно это учитывать.
Причин падения множество. Например, вы могли выбрать недостаточно параноидальную схему репликации. В ваш дата-центр упал метеорит, а потом и во второй. Или вы просто развернули код с хитрой ошибкой, которая неожиданно всплыла.
Например, в Badoo есть страничка «Люди рядом». Там пользователи ищут других людей поблизости, чтобы с ними пообщаться.
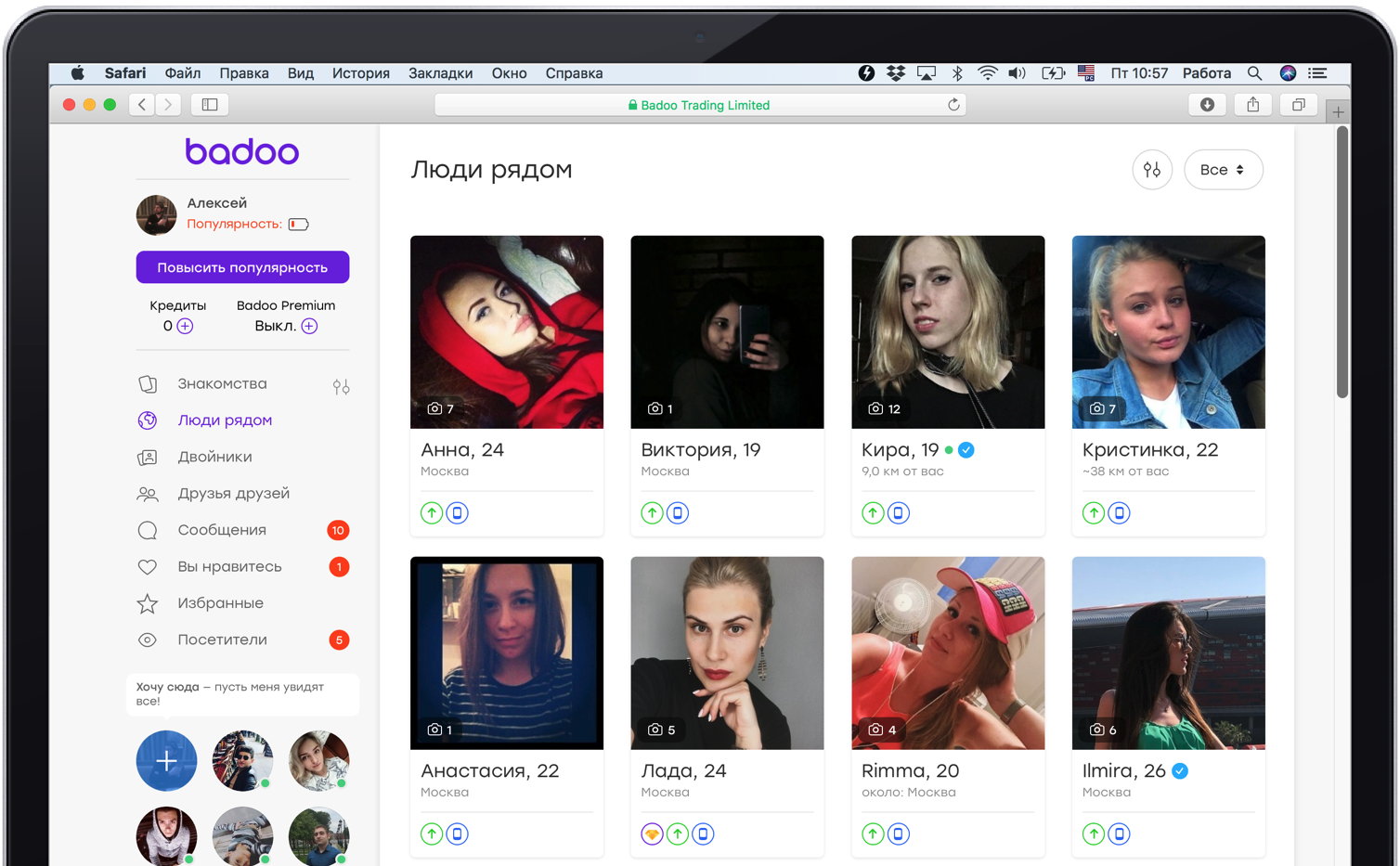
Сейчас для отрисовки страницы бекенд делает синхронные обращения в примерно семь сервисов. Для наглядности уменьшим это количество до двух. Один сервис отвечает за отрисовку центрального блока с фотографиями. Второй — за блок рекламы слева внизу. Туда могут попасть те, кто хотят стать более заметными. Если у нас падает сервис, который отображает эту рекламу, то блок просто исчезает.
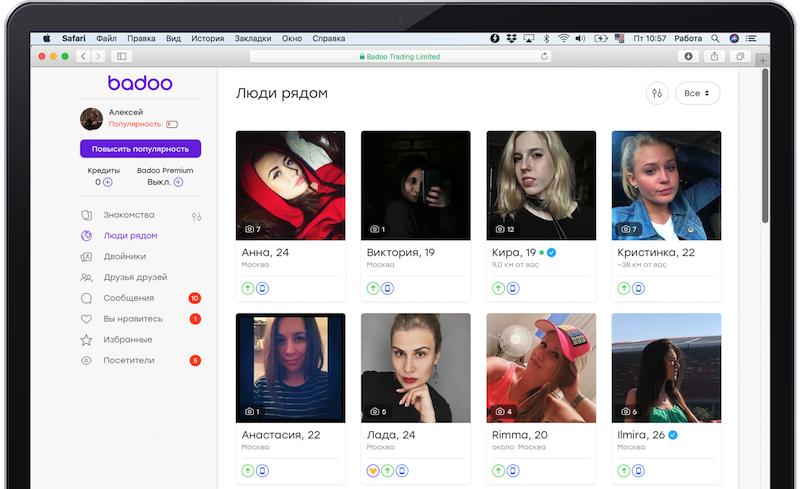
Большинство пользователей даже не узнают об этом факте: наша команда реагирует быстро, и вскоре блок просто появляется снова.
Но не каждую функциональность мы можем незаметно убрать. Если у нас упадет сервис, отвечающий за центральную часть страницы, это не получится скрыть. Поэтому важно сказать пользователю на его языке, что происходит.
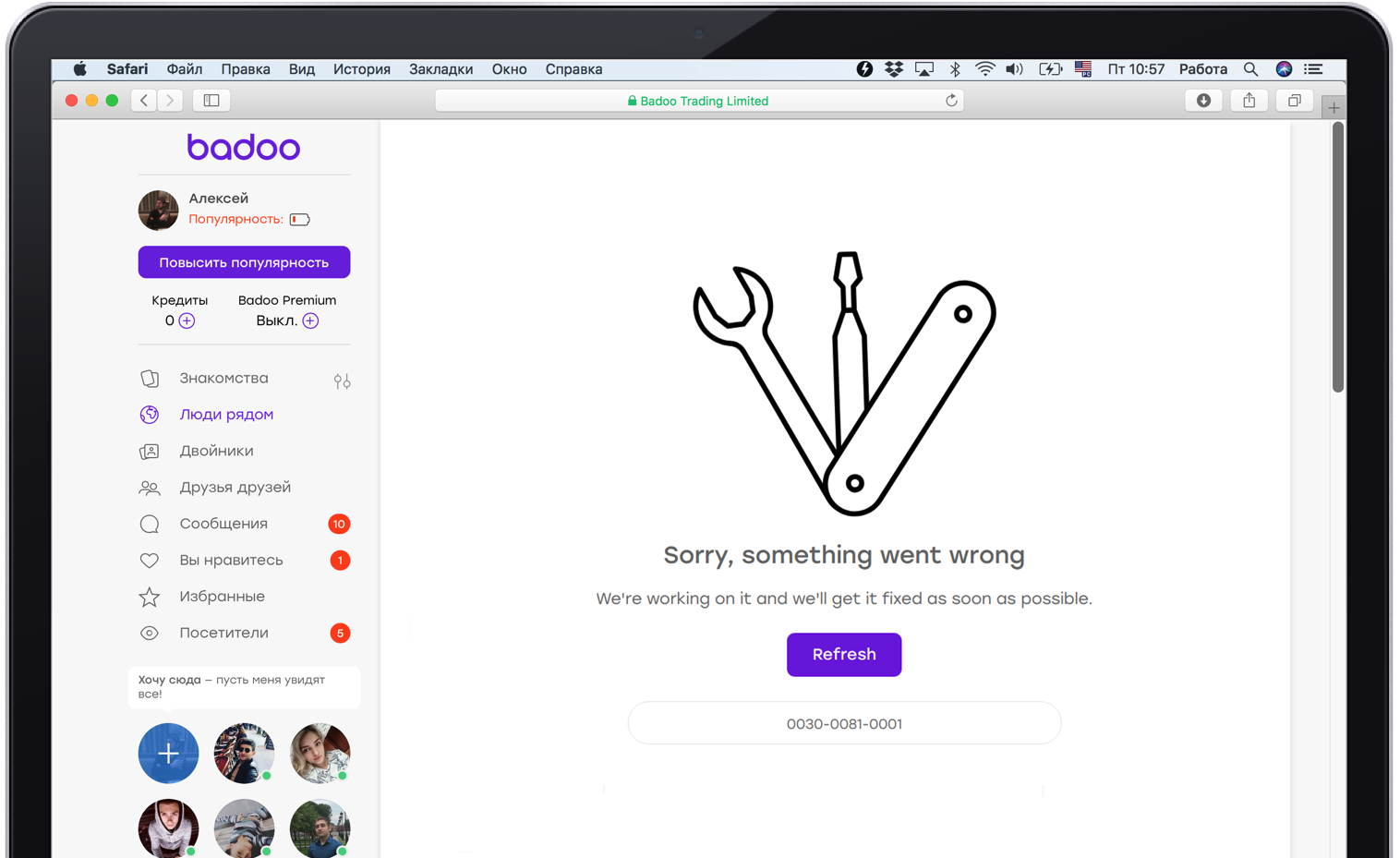
Также желательно, чтобы отказ одного сервиса не привёл к каскадному отказу. Для каждого сервиса должен быть написан код, который обрабатывает его падение, иначе приложение может упасть целиком.
Но и это не всё. Иногда падает что-то такое, без чего вы не можете жить вообще никак. Например, центральная база данных или сервис сессий. Важно корректно это отработать и показать пользователю что-то адекватное, как-то его развлечь, сказать, что всё под контролем. При этом важно, чтобы всё действительно было под контролем, и мониторщики были оповещены о проблеме.
Умирать, так правильно
- Будьте готовы к падению. Серебряной пули нет, поэтому всегда стелите соломку на случай полного падения сервиса, даже если у вас используется резервирование.
- Не допускайте каскадных отказов, когда проблемы с одним из сервисов убивают всё приложение.
- Отключайте некритичную для пользователя функциональность. Это нормально. Многие сервисы используются только для внутренних нужд и не влияют на предоставляемый функционал. Например, сервис статистики. Пользователю вообще неважно, собирается у вас статистика или нет. Ему важно, чтобы сайт работал.
Итоги
Чтобы надёжно интегрировать новый сервис в систему, мы в Badoo пишем вокруг него специальную обёртку-API, которая берёт на себя следующие задачи:
- балансировка нагрузки;
- таймауты;
- логика failover;
- circuit breaker;
- мониторинг и телеметрия;
- логика авторизации;
- сериализация и десериализация данных.
Лучше убедиться, что в вашем слое интеграции также покрыты все эти пункты. Тем более, если вы используете готовый Open-Source API-клиент. Важно помнить, что слой интеграции — это источник повышенного риска каскадного отказа вашего приложения.
Спасибо за внимание!
Литература
