Автоматизация нагрузочного тестирования: связка Jmeter + TeamCity + Grafana

Изображение: Flickr
В нашем блоге на Хабре мы продолжаем рассказывать о построении DevOps-культуры в компании — например, в одном из последних топиков мы описывали то, какие задачи решаем с помощью системы SaltStack. Сегодня речь пойдет о другой интересной теме — автоматизации нагрузочного тестирования с помощью связки нескольких готовых инструментов.
Как было раньше
Нам нужно было мониторить серверы, на которых проводилось нагрузочное тестирование — собирать метрики производительности процессора, памяти, операционной системы и т.п. Также необходимо было отслеживать состояние баз данных, шины и очередей, также иногда нужно было иногда работать с логами. Все эти задачи решались Python-скриптами нашей собственной разработки, информация хранилась в SQLite-базе, а отчеты формировались с помощью CSV-файлов.
Вот эта схема:

Минусы такого подхода:
- Все, что выделено на картинке фигурной скобкой, впоследствии мертвым грузом хранилось в артифактории, анализировать данные было крайне сложно.
- Наша функциональность позволяла строить отчет только с жесткой формой — без фильтров и отображения корреляций.
- Главный минус — отчет генерировался только по окончании теста.
Новая связка
В конечном итоге мы отказались от собственных велосипедов и решили воспользоваться плодами чужих трудов. В итоге родилась новая связка из нескольких инструментов.
Хранение данных
В качестве системы хранения данных был использован продукт InfluxDB. Это одна из немногих СУБД, созданная для хранения временных рядов (метрик производительности, аналитики, событий). Она умеет агрегировать данные на лету, также системой легко пользоваться благодаря тому, что в ней применяется SQL-like синтаксис. Из других плюсов:
- Поддержка регулярных выражений.
- Автоматическая очистка старых данных.
- Масштабируемость.
- Наличие библиотек для популярных языков.
- Легкое развертывание и администрирование.
Рассмотрим пример использования InfluxDB для измерений. Допустим, нам нужно измерить температуру машины X типа Y в интервале времени.
Для этого у нас есть параметры:
- Измерение: temperature;
- Теги: machine, type;
- Поля: internal_temperatre, external_temperature.
Теги используются для агрегации и фильтрации, в полях помещаются данные для хранения — они не индексируются, хранится только одно значение для комбинации «измерение + тег + timestamp», задается временная точность (с, мс, мкс, нс). Длительность хранения данных задается политикой очистки.
Вот как будет выглядеть измерение:
temperature, machine-unit42,type=assembly internal=32, external=100 1434055562000000035Его легко сформировать, легко передать и для этого не требуется больших затрат ресурсов.
Мониторинг
В качестве средства для мониторинга мы решили использовать Zabbix. Применяем кроссплатформенные агенты на Windows и Linux-хостах. Используются как пассивные, так и активные проверки. Через активные проверки реализован сбор метрик с хостов из закрытых сетей. Кроме того, мы активно использовали функцию autodiscovery для виртуальных машин на хостах с ESXi.
Анализ
Инструментом для анализа данных применяется открытый проект grafana — он отлично подходит для создания дашбордов, построения графиков и шаблонизации запросов и дашбордов. Система умеет строить запросы для разных источников данных — тех же InfluxDB, Zabbix, Elasticsearch и т.п. Вообще продукт действительно удобный — можно создавать подписи к записям и плейлисты, осуществлять поиск по дашбордам, производить экспорт и импорт данных.
Ну и нельзя не упомянуть интерфейс, который не заставляет глаза кровоточить (привет, Zabbix).

Конечная конфигурация
После рассмотрения элементов системы, поговорим о том, как это все в итоге работает вместе.
Все важные метрики операционной системы и железа мониторятся с помощью Zabbix, а также при помощи модернизированных скриптов-коллекторов на Python. Метрики, собранные скриптами хранятся в InfluxDB, информация отображается в Grafana.
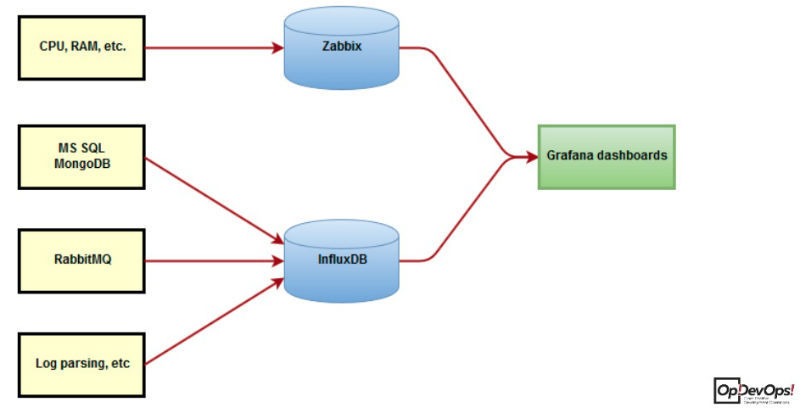
Автоматизация
Подготовив инфраструктуру, мы занялись вопросами автоматизации тестирования. Для этого был использован продукт Apache JMeter. Вот для чего он нужен:
- Он может полностью эмулировать работу реальных пользователей с системой — в нашем случае запросов между сервером и браузером.
- Система генерирует статистические данные по работе сервера — например, время обработки входящих запросов и обработки приходящих ответов.
- Отправляет результаты работы в InfluxDB и для отображения в Grafana.
На пути его внедрения необходимо было решить несколько проблем.
- Нужно было разработать простой механизм разворачивания инструмента на серверах.
- Наладить легкий процесс запуска и проведения нагрузочного тестирования.
- Разработать простую интеграцию результатов тестирования в Grafana.
- Организовать онлайн-мониторинг проведения нагрузочного тестирования.
Вот, что мы сделали для их решения:
- Разработали нагрузочный скрипт, который покрывает до 80% всех пользовательских операций.
- Внедрили механизм запуска тестирования через TeamCity.
- Реализовали отображение онлайн-статистики по работе нашего продукта MaxPatrol UI.
- Сделали простое обновление скриптов через Git.
Вот так выглядит интерфейс запуска задачи тестирования в TeamCity:

Для отправки данных в InfluxDB у Jmeter есть встроенный плагин (Backend Listener)

Итог: как все работает
В настоящий момент процесс нагрузочного тестирования представляет собой запуск задачи в TeamCity — нужно лишь выбрать нужные параметры при старте. Далее статистические данные по работе UI отображаются сразу в виде готовых интерактивных графиков. Обновленные скрипты автоматически подтягиваются через Git в TeamCity.
P.S. Рассказ о нашем опыте использования SaltStack был представлен в рамках DevOps-митапа, который состоялся осенью 2016 года в Москве.
Видео:
Слайды:
По ссылке представлены презентации 16 докладов, представленных в ходе мероприятия. Все презентации и видео выступлений добавлены в таблицу в конце этого топика-анонса.
Авторы: Иван Останин, Сергей Тихонов
