[Перевод] Врываемся в 2018 год с очередным большим релизом: выпуск версии 11.3 языка Wolfram Language и Mathematica

Перевод блог-поста Стивена Вольфрама (Stephen Wolfram) «Roaring into 2018 with Another Big Release: Launching Version 11.3 of the Wolfram Language & Mathematica».
Содержание
— Поток выпуска версий
— Что нового?
— Блокчейн
— Системное моделирование
— Новое в ноутбуках
— Документация рабочего процесса
— Инструменты для презентаций
— Wolfram Чат
— Удобства языка
— Обновления визуализации
— Чтение текста
— Вычисления по лицам
— Нейронные сети
— Асимптотический анализ
— «Элементарная» алгебра
— Доказательства
— Растущая база знаний
— Сообщения и почта
— Операции на системном уровне
— Что не упоминалось
Поток выпуска версий
В сентябре прошлого года мы выпустили версию 11.2 языка Wolfram Language и Mathematica — с различным новым функционалом, включая более 100 совершенно новых функций. Версия 11.2 была большой версией. Но сегодня у нас есть еще больший релиз: версия 11.3, которая, помимо прочего, включает почти 120 совершенно новых функций.
23 июня будет 30 лет с момента выпуска версии 1.0, и я очень горжусь тем, что мы смогли поддерживать ускоряющиеся темпы инноваций и развития теперь не менее трех десятилетий. Ключевым моментом в этом является тот факт, что мы используем язык Wolfram Language для разработки языка Wolfram Language — и действительно, большинство вещей, которые мы теперь можем добавить в версию 11.3, возможны только потому, что мы используем огромный стек технологий, который мы систематически строим более 30 лет.
Мы постоянно работаем над большим потоком R&D проектов, и наша стратегия для версий .1 заключается в том, чтобы использовать их для выпуска всего, что готово в определенный момент времени. Иногда то, что находится в версии .1, может не полностью заполнить новую область, а некоторые из функций могут быть помечены как «экспериментальные». Но наша цель с релизами версий .1 заключается в том, чтобы как можно быстрее предоставить последние результаты наших исследований и разработок. Целочисленные версии (.0) — более систематичны и обеспечивают полный охват новых областей, завершая то, что было добавлено постепенно в версиях .1.
В дополнение ко всем новым функциям в 11.3, в наш процесс вошел новый элемент. Начиная пару месяцев назад, мы начали проводить живую трансляцию наших совещаний по просмотру дизайна, которые я начал проводить, когда мы работали над версией 11.3. Поэтому для тех, кто интересуется «тем, как производится колбаса», в настоящее время собрано почти 122 часа записанных собраний, из которых вы можете точно узнать, как изначально были изобретены некоторые из вещей, которые вы теперь видите в версии 11.3. И в этом блог-посте я собираюсь делать ссылки к определенным записанным живым трансляциям, связанными с функциями, которые я обсуждаю.
Что нового?
ОК, так что нового в версии 11.3? Ну, много чего. И, кстати, версия 11.3 доступна сегодня как на рабочем столе (Mac, Windows, Linux), так и на Wolfram Cloud. (И да, для достижения одновременных выпусков такого рода требуется крайне нетривиальная разработка программного обеспечения, управление и обеспечение качества.)
В общем, версия 11.3 не только добавляет некоторые совершенно новые направления, но также расширяет и укрепляет то, что уже существует. Усиливается основная функциональность: еще более автоматизированное машинное обучение, более надежный импорт данных, предварительная выборка базы знаний, дополнительные возможности визуализации и т. д. Существуют всевозможные новые удобства: более легкий доступ к внешним языкам, непосредственная вводная информация, прямое каррирование, и т. д. И мы также продолжаем агрессивно расширять горизонты во всех областях, где мы особенно активно развивались в последние годы: машинное обучение, нейронные сети, аудио, асимптотическое исчисление, вычисление внешнего языка и т. д.
Вот облако тегов новых функций, добавленных в версии 11.3:

Блокчейн
Нужно рассказать так много вещей о 11.3 что трудно понять, с чего начать. Но начнем с чего-то актуального: блокчейн. Как я буду объяснять в будущих блог-постах, язык Wolfram Language с его встроенной способностью говорить о реальном мире оказывается уникальным для определения и выполнения вычислительных умных контрактов. Фактическое вычисление языка Wolfram Language для этих контрактов будет (на данный момент) происходить без блокчейн, но важно, чтобы язык мог подключаться к блокчейну, и это то, что добавляется в версии 11.3. [Живая трансляция обсуждения дизайна]
Первое, что мы можем сделать, это просто спросить о блокчейнах, которые есть в мире. К примеру, здесь показан последний блок, добавленный в главную цепочку Ethereum:
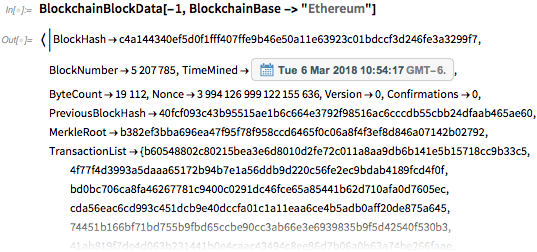
Теперь мы можем взять одну из транзакций в этом блоке и изучить ее:

И тогда мы можем начать работать с данными или провести какой-либо анализ о структуре и содержании блокчейн. Для первоначального выпуска версии 11.3 мы поддерживаем Bitcoin и Ethereum, хотя вскоре будут добавлены другие открытые блокчейны.
Но уже в версии 11.3 мы поддерживаем частный (основанный на Bitcoin) Wolfram Blockchain, который размещен в нашем Wolfram Cloud. Мы будем периодически публиковать хэши из этого блокчейна в мир (возможно, в таких вещах, как физические газеты). И также можно будет запускать его версии в частных облаках Wolfram Cloud.
Очень легко написать что-то в Wolfram Blockchain (и, да, он взимает небольшое количество Cloud Credits):

Результатом является хеш транзакции, который затем можно найти в блокчейне:
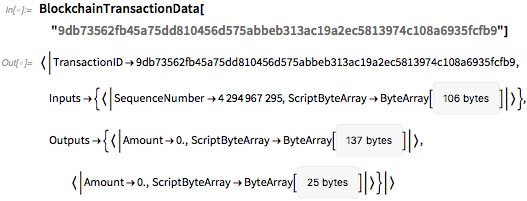
Вот круг назад из блокчейна:

Кстати, функция Hash в языке Wolfram Language была расширена в 11.3, чтобы немедленно поддерживать виды хэшей (к примеру «RIPEMD160SHA256»), которые используются в блокчейнах криптовалюты. И, используя Encrypt и связанные с ним функции, можно начать создавать некоторые сложные вещи в блокчейне — и вскоре их будет еще больше.
Системное моделирование
Хорошо, теперь давайте поговорим о чем-то действительно большом и новом — по крайней мере, в экспериментальной форме в версии 11.3. Одна из наших долгосрочных целей в языке Wolfram Language — это возможность вычислить что угодно в мире. И в версии 11.3 мы добавляем новый класс вещей, которые мы можем вычислить: сложные инженерные (и другие) системы. [Живая трансляция наших совещаний по просмотру дизайна 1 и 2]
Еще в 2012 году мы выпустили Wolfram SystemModeler: среду моделирования промышленного применения, которая использовалась для моделирования таких вещей, как реактивные двигатели с десятками тысяч компонентов. SystemModeler позволяет запускать симуляции моделей и разрабатывать модели с использованием комплексного графического интерфейса.
То, что мы добавляем (экспериментально) в версии 11.3, является встроенной возможностью для языка Wolfram Language для запуска моделей из SystemModeler — или фактически любой модели, описанной на языке Modelica.
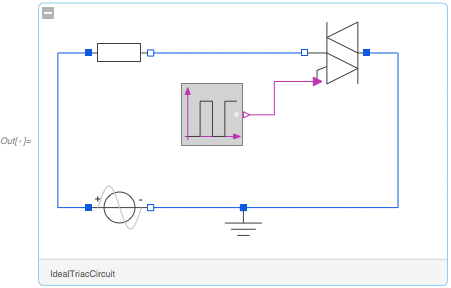
Начнем с простого примера. Это извлекает определенную модель из нашего встроенного репозитория моделей:

Если вы нажмете [+], вы увидите более подробную информацию:
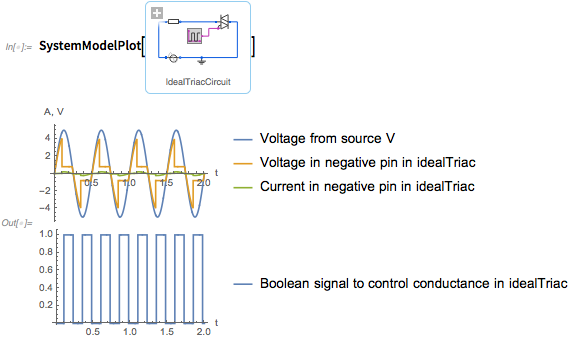
Но место, где это становится действительно интересным — то, что вы действительно можете запустить эту модель. SystemModelPlot создает график «стандартной симуляции» модели:
Какова на самом деле модель внутри? Это набор уравнений, описывающих динамику поведения компонентов системы. И для такой простой системы эти уравнения уже довольно сложны:

Часть работы моделирования реальных систем состоит, как правило, из работы со множеством компонентов и сложных взаимодействий. SystemModeler настроен таким образом, чтобы люди проектировали произвольно сложные системы графически, иерархически соединяя вместе компоненты, представляющие физические или другие объекты. Но большая новость заключается в том, что как только у вас будет модель, то в версии 11.3 вы сможете сразу работать с ней на языке Wolfram Language.
Каждая модель имеет множество свойств:

Одно из этих свойств дает переменные, которые характеризуют систему. И да, даже в очень простой системе, подобной этой, их уже много:

Вот пример того, как одна из этих переменных ведет себя в симуляции:
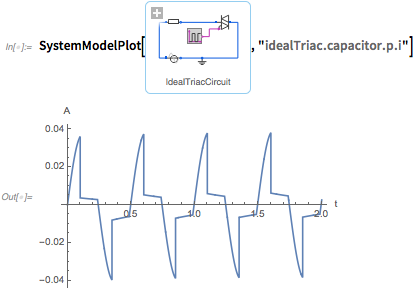
Типичная вещь, которую нужно сделать, это исследовать как система ведет себя при изменении параметров. Это производит симуляцию системы с измененным параметром, затем создает график:

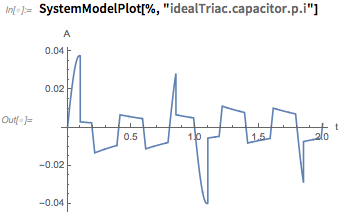
Мы могли бы перейти отсюда к выборке множества различных возможных вводов или значений параметров и делать такие вещи, как изучение устойчивости системы к изменениям. Версия 11.3 обеспечивает очень богатую среду для выполнения всех этих задач как интегрированной части языка Wolfram Language.
В 11.3 уже включено более 1000 готовых моделей — электрических, механических, тепловых, гидравлических, биологических и других систем. Вот более сложный пример — основная часть автомобиля:

Если вы разворачиваете значок, вы можете навести указатель мыши на части, чтобы узнать, что они собой представляют:
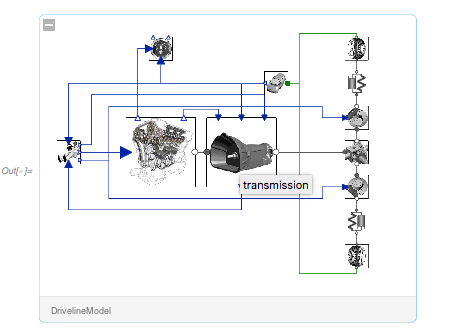
Это дает краткий обзор модели, показывающей, что она включает в себя 1110 переменных:

В дополнение к готовым к работе моделям также имеется более 6000 компонентов, включенных в 11.3, из которых могут быть построены модели. SystemModeler предоставляет полную графическую среду для сборки этих компонентов. Но это также можно сделать исключительно с помощью кода языка Wolfram Language, используя такие функции, как ConnectSystemModelComponents (которые в основном определяют график подключения соединителей разных компонентов):

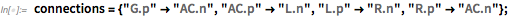
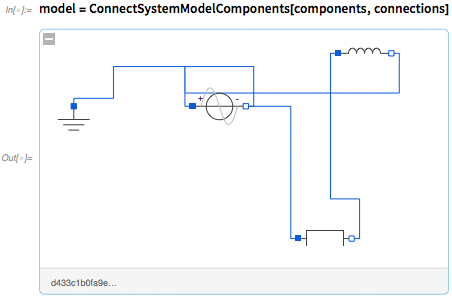
Вы также можете создавать модели непосредственно из своих основных уравнений, а также делать «модели черного ящика» исключительно из данных или эмпирических функций (скажем, от машинного обучения).
Потребовалось много времени, чтобы построить все возможности моделирования систем, которые мы представляем в 11.3. И они опираются на множество сложных особенностей языка Wolfram Language, в том числе на крупномасштабные символические манипуляции, умение эффективно решать системы дифференциально-алгебраических уравнений, обработку величин и единиц и многое другое. Но теперь, когда системное моделирование интегрировано в язык Wolfram Language, оно открывает всевозможные важные новые возможности — не только в области разработки, но и во всех областях, которые могут быть легко смоделированы многокомпонентными системами реального мира.
Новое в ноутбуках
Мы впервые представили ноутбуки в версии 1.0 еще в 1988 году, поэтому к настоящему времени мы отлаживаем их работу не менее 30 лет. В версии 11.3 представлен ряд новых функций. Простым примером являются закрытые группы ячеек, которые теперь по умолчанию имеют «открывающую кнопку», а также их можно открывать с помощью скобок их ячеек:

Я нахожу это полезным, потому что в противном случае я иногда не замечаю закрытых групп с дополнительными ячейками внутри. (И да, если вам это не нравится, вы всегда можете отключить его в стилевом оформлении.)
Другим небольшим, но полезным изменением является введение «неопределенных меток In / Out». В ноутбуке, подключённом к работающему ядру, последовательные ячейки помечены как In [1], Out [1] и т. д. Но если вы больше не подключены к одному и тому же ядру (скажем, потому что вы сохранили и снова открыли ноутбук), In/Out нумерация больше не имеет смысла. Таким образом, в прошлом не было показано никаких меток In, Out. Но с версии 11.3 все еще есть метки, но они неактивны, и в них нет явных цифр:
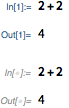
Еще одна новая функция в версии 11.3 — Iconize. Вот основная проблема, которую она решает. Допустим, у вас есть большой объем данных или другой ввод, который вы хотите сохранить в ноутбуке, но вы не хотите, чтобы он визуально заполнял ноутбук. Одна вещь, которую вы можете сделать, это поместить ее в закрытые ячейки. Но тогда для использования данных вам нужно сделать что-то вроде создания переменной и так далее. Iconize обеспечивает простой встроенный способ сохранения данных в ноутбуке.
Вот как вы делаете свернутую версию выражения:
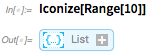
Теперь вы можете использовать эту свернутую форму вместо всего выражения; он сразу же выдает результат полного выражения:

Еще одно удобное использование Iconize — сделать код более удобным для чтения, но при этом все еще выполнимым. Например, рассмотрим что-то вроде этого:
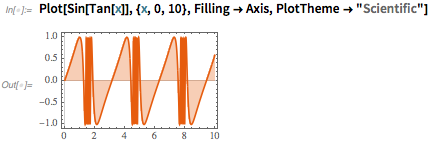
Вы можете выбрать здесь варианты, затем перейти в контекстное меню и свернуть их:

В результате получается более простой для чтения фрагмент кода, который по-прежнему выполняется так же, как и раньше:

В версии 11.2 мы представили ExternalEvaluate для выполнения кода на внешних языках (первоначально Python и JavaScript) непосредственно из языка Wolfram Language. (Это поддерживается на десктопе и в частных облаках, по соображениям безопасности и выделения ресурсов открытого Wolfram Cloud работает только с чистым кодом языка Wolfram Language.)
В версии 11.3 теперь стало еще проще вводить внешний код в ноутбуки. Просто запустите ячейку ввода с помощью >, и вы получите внешнюю ячейку кода (вы можете легко выбрать нужный язык):

И да, то, что возвращается, является выражением языка Wolfram Language, которое вы можете вычислить:

Документация рабочего процесса
Мы уделяем большое внимание документированию языка Wolfram Language — и традиционно у нас в нашей документации было три вида компонентов: «справочные страницы», которые охватывают одну функцию, «страницы-руководство», в которых содержится сводка с ссылками на многие функции, и «учебные пособия», которые предоставляют повествовательные введения в области функциональности. С версии 11.3 есть четвертый вид компонента: (рабочий процесс) workflows — это куда вас ведут новые опции на сером фоне в нижней части «корневой справочной страницы».
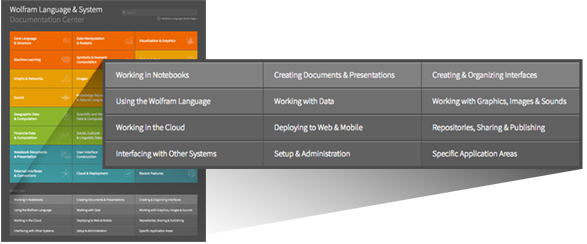
Когда все, что вы делаете, представлено явным кодом языка Wolfram Language, парадигма In/Out ноутбуков — отличный способ показать, что происходит. Но если вы щелкаете мышью или, что еще хуже, используете внешние программы, этого недостаточно. И вот где подойдут workflows, потому что они используют всевозможные графические устройства для представления последовательности действий, которые не просто вводят в язык Wolfram Language.
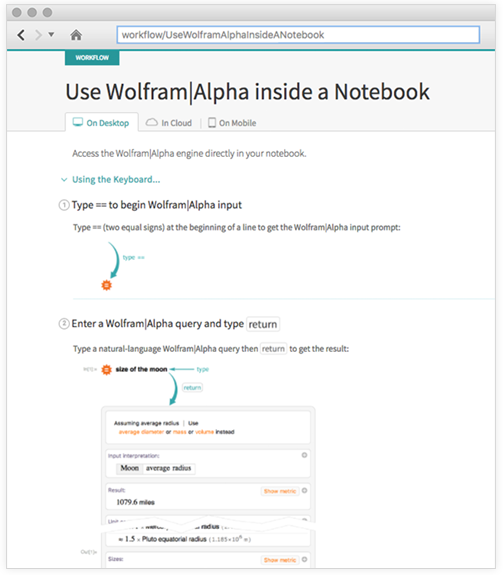
Поэтому, если вы получаете координаты графика или развертываете сложную форму в интернете или добавляете баннер в ноутбук, то ожидается следование нашей новой документации workflow. И, кстати, вы найдете ссылки на соответствующие workflows со справочных страниц для функций.
Инструменты для презентаций
Еще одна важная вещь, связанная с интерфейсом в версии 11.3, — это Presenter Tools — полная среда для создания и запуска презентаций, которые включают интерактивную интерактивность. Что делает Presenter Tools возможными — это богатая система ноутбуков, которую мы создали за последние 30 лет. Но то, что они помогают делать, это добавить все функции, которые нужны для удобного создания и запуска презентаций.
Люди используют наш предыдущий формат SlideShow, для презентаций с ноутбуками Wolfram в течении 20 лет. Но это никогда не было полным решением. Да, это давало нам удобные функции ноутбука, такие как живое вычисление в среде слайд-шоу, но не использовало такие вещи как «в PowerPoint», такие как автоматическое масштабирование контента до разрешения экрана. Справедливости ради отметим, что мы ожидали, что операционные системы будут просто решать проблемы, такие как масштабирование контента. Но прошло уже 20 лет, и этого все еще нет. Итак, теперь мы создали новые Presenter Tools, которые решают такие проблемы, и добавляют целый ряд возможностей для создания отличных презентаций с ноутбуками как можно проще.
Для начала просто выберите File > New > Presenter Notebook. Затем выберите свой шаблон и тему, и начинайте работу:
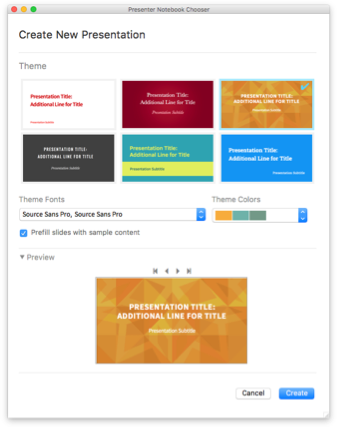
Вот как это выглядит, когда вы редактируете презентацию (и вы можете менять темы, когда захотите):
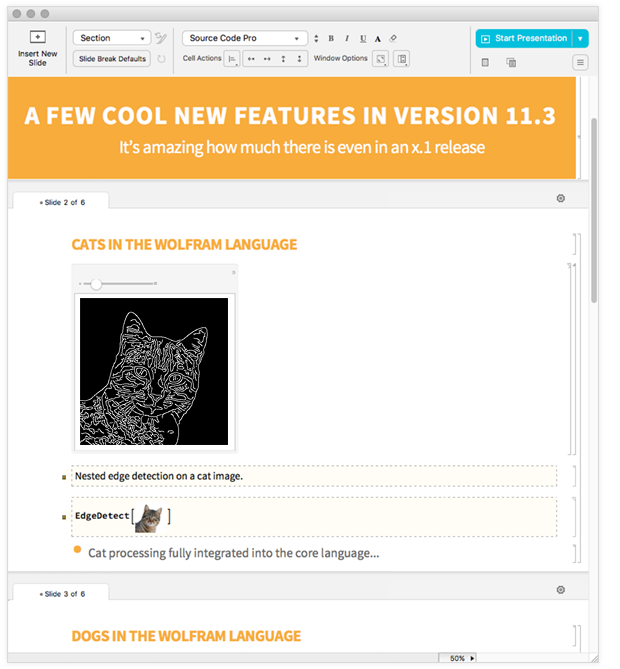
Когда вы будете готовы, просто нажмите «Начать презентацию». Все идет в полноэкранном режиме и автоматически масштабируется до разрешения экрана, который вы используете. Но вот большое отличие от PowerPoint-подобных систем: все живое, интерактивное, редактируемое и прокручиваемое. Например, вы можете иметь Manipulate прямо внутри слайда, и вы можете немедленно взаимодействовать с ним. (О, и все может быть динамичным, скажем, воссоздать графику на основе данных, которые импортируются в реальном времени.) Вы также можете использовать такие вещи, как группы ячеек для организации контента в слайдах. И вы можете редактировать то, что находится на слайде, и, например, делать livecoding, запуская свой код на ходу.
Когда вы будете готовы перейти на новый слайд, просто нажмите клавишу (или ваш пульт сделает это за вас). По умолчанию эта клавиша Page Down (поэтому вы можете использовать клавиши со стрелками при редактировании), но вы можете установить другой ключ, если хотите. Вы можете заставить Presenter Tools показывать слайды на одном дисплее, а затем отображать заметки и элементы управления на другом дисплее. Когда вы делаете слайды, вы можете включить SideNotes и SideCode. SideNotes — текстовые заметки, похожие на PowerPoint. Но SideCode — это нечто другое. На самом деле это основано на том, что я делал на своих собственных презентациях годами. Это код, который вы заранее подготовили, и можете «волшебством» вставить в слайд в режиме реального времени во время презентации, и если желаете, с моментальным выводом результата.
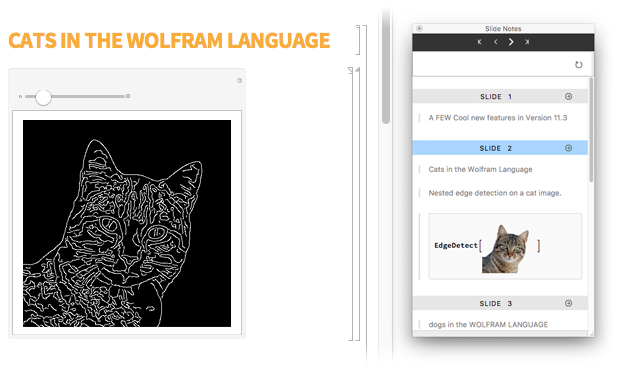
На протяжении многих лет я дал огромное количество презентаций с помощью ноутбуков Wolfram. Несколько раз я использовал формат SlideShow, но в основном я делал все в обычном ноутбуке, часто записывая заметки на отдельном устройстве. Но теперь я очень рад, что в версии 11.3 у меня есть именно те инструменты, которые мне нужны для подготовки и проведения презентаций. Я могу предварительно определить часть контента и структуры, но живая презентация может быть очень динамичной и спонтанной — с живым редактированием, живым кодированием и всеми видами интерактивности.
Wolfram Чат
Пока мы обсуждаем возможности интерфейса, вот еще одна: Wolfram Chat. Когда люди интерактивно работают над чем-то, обычно слышно, что кто-то говорит «позвольте мне просто отправить вам часть кода» или «позвольте мне отправить вам Manipulate». Теперь, в версии 11.3 теперь есть очень удобный способ сделать это, и это встроено непосредственно в систему ноутбуков Wolfram, что и называется Wolfram Chat. [Живая трансляция совещания]
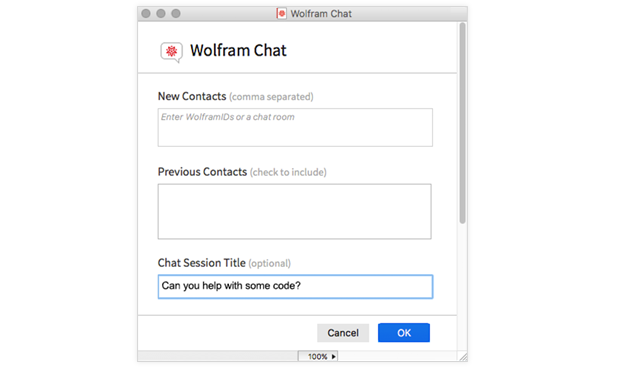
Просто выберите File > New > Chat; вас спросят, с кем вы хотите «пообщаться», и это может быть кто угодно и где угодно с Wolfram ID (хотя, конечно, они должны принять ваше приглашение):
Затем вы можете начать сеанс чата и, например, поставить его рядом с обычным ноутбуком:
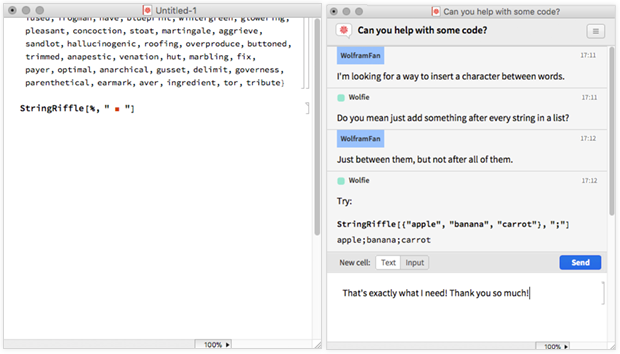
Здорово то, что вы можете отправлять все, что может появиться в ноутбуке, включая изображения, код, динамические объекты и т. Д. (Хотя это «песочница», так что люди не могут отправлять «кодовые бомбы» друг другу).
Существует много очевидных приложений Wolfram Chat не только в сотрудничестве, но и в таких вещах, как учебные аудитории и техническая поддержка. И есть и другие приложения. Например, для livecoding соревнований. И на самом деле одним из способов, которым мы проводили нагрузочные испытания Wolfram Chat во время его разработки, это используя его для участия в livecoding соревновании на конференции Wolfram технологий прошлой осенью.
Можно подумать, что чат — это нечто простое и ясное. Но на самом деле это удивительно сложно, с поражающим количеством различных ситуаций и случаев для рассмотрения. Под капотом Wolfram Chat использует как Wolfram Cloud, так и новую структуру pub-sub channel, которую мы ввели в версии 11.0. В версии 11.3 Wolfram Chat поддерживается только для настольных ноутбуков Wolfram, но скоро они появятся в ноутбуках в интернете и на мобильных устройствах.
Удобства языка
Мы всегда совершенствуем язык Wolfram Language, чтобы сделать его более удобным и продуктивным в использовании. И один из способов сделать это — это добавить новые «удобные функции» в каждой версии языка. Зачастую эти функции делают простые вещи; задача (которая часто занимает много лет) заключается в том, чтобы придумать для них красивый и простой дизайн. (Вы можете увидеть довольно много обсуждений новых удобных функций в версии 11.3 в недавних живых трансляциях.)
Вот функция (удивительно, что мы не сделали ее раньше), которая просто строит выражение из ее головы и аргументов:

Чем это полезно? Ну, это может сохранить явное построение чистых функций с Function или &, например, в таком случае:

Другая функция, которая на каком-то уровне очень проста (но выбор имени этой функции был мучительным), является Curry. Curry (названный в честь «currying», который, в свою очередь, назван в честь Ха́скелл Брукс Ка́рри) по существу делает операторные формы, а Curry [f, n] «currying in» n аргументов:

Однопараметрическая форма самого Curry такова:
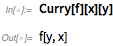
Почему это полезно? Ну, некоторые функции (например, Select) имеют встроенные «операторные формы», в которых вы даете один аргумент, затем вы «curry in» другие:

Но что, если вы хотите создать оператор самостоятельно? Ну, вы всегда можете явно построить его с помощью Function или &. Но с Curry вам не нужно это делать. Например, это операторная форма D, в которой второй аргумент задан как x:
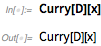
Теперь мы можем применить эту операторную форму для дифференцирования по x:
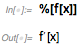
Да, Curry на каком-то уровне довольно абстрактна. Но это приятное удобство, если вы это понимаете, и понимание этого — хорошее упражнение в понимании символической структуры языка Wolfram Language.
Кстати, говоря об операторных формах, NearestTo является аналогом операторной формы Nearest (однопараметрическая форма самого Nearest генерирует NearestFunction):

Вот пример того, почему это полезно. Это находит 5 химических элементов, плотность которых близка к 10 г / см3:

В версии 10.1 в 2015 году мы представили множество функций, которые работают с последовательностями в списках. Версия 11.3 добавляет еще пару таких функций. Одна из них — SequenceSplit. Это похоже на StringSplit для списков: он разбивает списки в позициях определенных последовательностей:
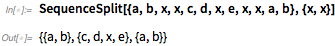
Также новым в «Sequence family» является функция SequenceReplace:
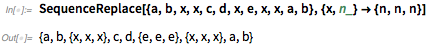
Обновления визуализации
Так же, как мы всегда совершенствуем основные функциональные возможности программирования в языке Wolfram Language, мы также всегда совершенствуем такие вещи, как визуализация.
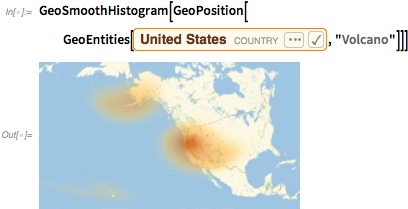
В версии 11.0 мы добавили GeoHistogram, здесь показана «плотность вулканов» в США:

В версии 11.3 мы добавили GeoSmoothHistogram:
Также новым в версии 11.3 являются выноски (callouts) в 3D-графиках, здесь случайные слова отмечают случайные точки (но обратите внимание как расположены слова чтобы не перекрывать друг друга):

Мы можем сделать несколько более значимый график слов в 3D, используя новый FeatureSpacePlot3D на основе машинного обучения (обратите внимание, например, что «vocalizing» и «crooking» (означающие примерно одно и тоже — переводчик) соответственно заканчиваются вместе):

Чтение текста
Говоря о машинном обучении, версия 11.3 продолжает нашу агрессивную разработку автоматизированного машинного обучения, создавая как общие инструменты, так и конкретные функции, которые используют машинное обучение.
Интересным примером новой функции является FindTextualAnswer, который берет фрагмент текста и пытается найти ответы на текстовые вопросы. Здесь мы используем статью Википедии о «носороге», спрашивая, сколько весит носорог:
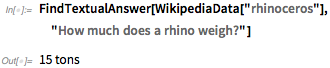
Это похоже на волшебство. Конечно, это не всегда работает и может делать то, что мы, люди, будем считать довольно глупым. Но это использует самую современную методологию машинного обучения, а также множество уникальных данных для обучения, основанных на Wolfram|Alpha. Мы можем видеть немного больше того, что это делает, если мы спросим не только о первом ответе о весе носорогов, но о 5:

Хммм. Итак, что является окончательным ответом? Ну, для этого мы можем использовать нашу курированную базу знаний:

Или в тоннах:

FindTextualAnswer не заменяет всю нашу обработку данных и стратегию по вычисляемым данным. Но это может быть полезным как способ быстро получить первое предположение об ответе, даже из полностью неструктурированного текста. И, да эта функция должна хорошо справляться с критическими упражнениями по чтению и, вероятно, может быть сделан для того, чтобы преуспеть в Jeopardy!
Вычисления по лицам
Мы много реагируем на человеческие лица, и с современным машинным обучением можно делать всевозможные вычисления, связанные с лицом, и в версии 11.3 мы добавили для этого систематические функции. Здесь FindFaces находит лица (известных физиков) с фотографии:

FacialFeatures использует методы машинного обучения для оценки различных атрибутов лиц (таких как наглядный возраст, наглядный пол и эмоциональное состояние):

Эти функции можно, например, использовать в качестве критериев в FindFaces, здесь выделяют физиков, которые выглядят моложе 40 лет:

Нейронные сети
В языке Wolfram Language существуют всевозможные функции, которые основаны на нейронных сетях (например, FacialFeatures). Но в течение нескольких лет мы также энергично строили целую подсистему на языке Wolfram Language, чтобы люди могли работать напрямую с нейронными сетями. Мы строим сверх низкоуровневых библиотек (в частности, MXNet, для которых мы были большими вкладчиками), поэтому мы можем использовать все новейшие графические процессоры и другие оптимизации. Но наша цель — создать символический слой высокого уровня, который позволяет максимально упростить вычисления нейронной сети. [Живая трансляция совещания 1, 2 и 3]
Это состоит из многих частей. Настройка автоматического кодирования и декодирования на стандартные конструкции языка Wolfram Language для текста, изображений, аудио и т. д. Быть в состоянии автоматически объединить отдельные операции нейронной сети, особенно те, которые касаются таких вещей как последовательность. Возможность максимально автоматизировать обучение, включая автоматическую оптимизацию гиперпараметров.
Но есть что-то еще более важное: наличие большой библиотеки существующих, обученных (и необученных) нейронных сетей, которые могут использоваться как непосредственно для вычислений, так для передачи обучения или как экстракторы признаков. И для этого мы создали наш репозиторий Neural Net Repository:

Здесь есть сети, которые делают всевозможные замечательные вещи. И мы добавляем новые сети каждую неделю. Каждая сеть имеет свою собственную страницу, которая включает примеры и подробную информацию. Сети хранятся в облаке. Но все, что вам нужно сделать чтобы вывести их в свои вычисления — это использовать NetModel:
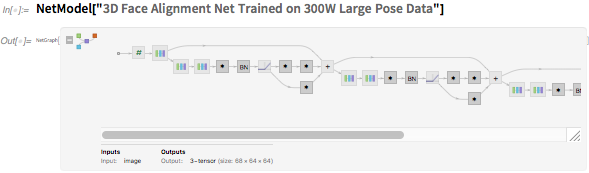
Вот сеть, которую использует FindTextualAnswer:
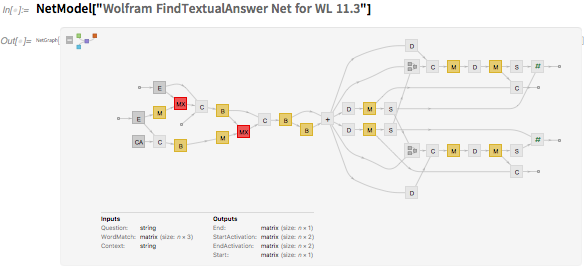
Одна из новинок в версии 11.3 — это графическое представление, которое мы используем для сетей. Мы оптимизировали его, чтобы дать вам хороший общий обзор структуры сетевых графиков, но затем разрешить интерактивное развёртывание до любого уровня детализации. И когда вы тренируете нейронную сеть, появляющиеся интерактивные панели имеют несколько новых возможностей — и с NetTrainResultsObject мы теперь сделали сам процесс обучения вычисляемым.
В версии 11.3 есть некоторые новые типы слоев, такие как CTCLossLayer (особенно для поддержки аудио), а также множество обновлений и улучшений для существующих типов слоев (10-кратное ускорение LSTM на графических процессорах, автоматические свертки переменной длины, расширения многих слоев для поддержки произвольно-размерных вводов и т. д.). В версии 11.3 мы уделяли особое внимание рекуррентным сетям и генерации последовательности. И чтобы поддержать это, мы внедрили такие вещи, как NetStateObject, что в основном позволяет сети иметь персистентное состояние, которое обновляется в результате ввода данных, которые получает сеть.
При разработке нашей символической структуры нейронной сети мы на самом деле идем в двух направлениях. Во-первых, мы делаем все более автоматизированным, чтобы можно было проще и проще настроить системы нейронных сетей. Но во-вторых — иметь возможность легко обрабатывать все больше нейронных сетевых структур. И в версии 11.3 мы добавляем целую коллекцию функций «сетевой хирургии», таких как NetTake, NetJoin и NetFlatten, чтобы вы могли входить, настраивать и взламывать нейронные сети, как пожелаете. Конечно, наша система спроектирована так, что даже если вы это сделаете, вся наша автоматизированная система — с обучением и т. д. — продолжит отлично работать.
Асимптотический анализ
Более 30 лет наша миссия состоит в том, чтобы сделать как много больше математики вычислительной. И в версии 11.3 мы наконец-то раскусили важную, давно ожидаемую область: асимптотический анализ.
Вот простой пример: найти приближенное решение дифференциального уравнения вблизи x = 0:
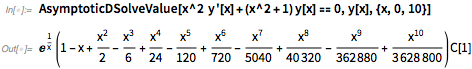
Сначала это может выглядеть как решение в виде степенного ряда. Но будьте внимательнее: присутствует e (1 / x) фактор, который просто даст бесконечность в каждом порядке как степенной ряд по x. Но с версией 11.3 мы теперь получили функции асимптотического анализа, которые обрабатывают всевозможные масштабы роста и колебаний, а не только порядка.
В прошлом, когда я зарабатывал на жизнь будучи физиком, всегда казалось, что все самые темные силы сосредотачивались на методах возмущения. Были регулярные возмущения и сингулярные возмущения. Были такие вещи, как метод WKB, и метод пограничного слоя. Суть всегда заключалась в том, чтобы вычислить разложение по некоторому небольшому параметру, но для достижения этой цели в различных случаях всегда требовались различные хитрости. Но теперь, после нескольких десятилетий работы, наконец в версии 11.3 у нас имеется систематический способ решения этих проблем. Вот дифференциальное уравнение, где мы ищем решение для малого ε:
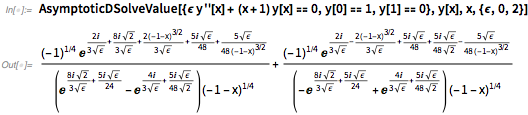
Еще в версии 11.2, мы добавили множество вариантов для решения более сложных ограничений. Но с помощью наших м
