[Перевод] Тестирование LLVM
Продолжение. Начало здесь.

Введение
Когда программа достигает определённого размера, можно гарантировать, что она слабо специфицирована и не может быть полностью понята одним человеком. Это подтверждается по много раз в день людьми, которые слабо осведомлены о работе друг друга. Программа имеет множество зависимостей, включая компилятор, операционную систему, библиотеки, каждая из которых содержит свои собственные баги, и всё это обновляется время от времени. Более того, ПО обычно должно работать на нескольких разных платформах, каждая из которых имеет свои особенности. Принимая во внимание большое количество возможностей для неверного поведения, почему вообще мы можем ожидать, что наша большая программа будет работать так, как ожидается? Одна из самых главных вещей, это тестирование. Таким образом, мы можем убедиться, что ПО работает так, как нужно в любой важной для нас конфигурации и платформе, и когда оно не работает, найдутся умные люди, которые смогут отследить и устранить проблему.
Сегодня мы обсудим тестирование LLVM. Во многих отношениях, компилятор является хорошим объектом для тестирования.
- Входной формат (исходный код) и выходной формат (ассемблерный код) хорошо понятны и имеют независимые спецификации.
- Многие компиляторы имеют промежуточное представление (IR), которое само по себе документировано и может быть выведено и распарсено, что делает более простым (хотя и не всегда), внутреннее тестирование.
- Зачастую компилятор является одной из независимых реализаций спецификации, такой, как стандарт С++, что позволяет производить дифференциальное тестирование. Даже если множество реализаций недоступно, мы часто можем протестировать компилятор путём сравнения с самим собой, сравнивая вывод различных бэкендов или различных режимов оптимизации.
- Компиляторы обычно не имеют сетевых функций, конкурентности, зависимостей от времени, и всегда взаимодействуют с внешним миром очень ограниченным способом. Более того, компиляторы обычно детерминированы.
- Компиляторы обычно не работают подолгу, и нам не нужно беспокоиться об утечках ресурсов и восстановлении после возникновения ошибок.
Но с другой стороны, компиляторы не так легко тестировать:
- Компиляторы должны быть быстры, и они часто пишутся на небезопасном языке, и имеют недостаточно ассертов. Они используют кэширование и ленивые вычисления, когда это возможно, что увеличивает их сложность. Более того, разделение функций компилятора на множество ясных, независимых маленьких проходов приводит к замедлению компилятора, и наблюдается тенденция к объединению не связанных или слабосвязанных функций, делая компилятор более трудным в понимании, тестировании, и поддержке.
- Инварианты внутренних структур данных компилятора могут быть совершенно адскими и не полностью документированными.
- Некоторые алгоритмы компиляции сложны, и почти никогда компилятор не не реализует алгоритмы из учебников в точности, но с большими или меньшими отличиями.
- Оптимизации в компиляторе взаимодействуют сложным образом.
- Компиляторы небезопасных языков не имеют каких-либо обязательств, когда компилируют неопределённое поведение, перекладывая ответственность за отсутствие UB вне пределов компилятора (и на того, кто пишет тесты для компилятора). Это усложняет дифференциальное тестирование.
- Стандарты на корректность компиляторов весьма высоки, так как программу, которая неверно скомпилирована, сложно отладить, и компилятор может незаметно добавлять уязвимости в любой компилируемый код.
Итак, зная эти базовые вещи, рассмотрим, как тестируется LLVM.
Модульные и регрессионные тесты
Первая линия обороны LLVM против багов — это набор тестов, который запускается, когда разработчик собирает цель «check». Все эти тесты должны быть пройдены перед тем, как разработчик закоммитит патч в LLVM (и, конечно, многие патчи могут включать новые тесты). На моём достаточно быстром десктопе 19267 тестов проходят за 96 секунд. Количество тестов, которые запускаются, зависит от того, какие дополнительные проекты LLVM вы скачали (compiler-rt, libcxx, и т.п.) и, в меньшей степени, от ПО, которое автоматически обнаружено на вашей машине (т.е. связки с OCaml не будут тестироваться, пока не установлен OCaml). Эти тесты должны быть быстрыми, и разработчики могут запускать их часто, как упоминается здесь. Дополнительные тесты запускаются при сборке таких целей, как check-all и check-clang.
Некоторые модульные и регрессионные тесты работают на уровне API, они используют Google Test, легкий фреймворк, который предоставляет макросы C++ для подключения тестового фрейворка. Вот пример теста:
TEST_F(MatchSelectPatternTest, FMinConstantZero) {
parseAssembly(
"define float @test(float %a) {\n"
" %1 = fcmp ole float %a, 0.0\n"
" %A = select i1 %1, float %a, float 0.0\n"
" ret float %A\n"
"}\n");
// This shouldn't be matched, as %a could be -0.0.
expectPattern({SPF_UNKNOWN, SPNB_NA, false});
}
Первый аргумент макроса TEST_F индицирует имя коллекции тестов, а второй — имя конкретного теста. Методы parseAssembly () и expectPattern () вызывают LLVM API и проверяют результат. Этот пример взят из ValueTrackingTest.cpp. В одном файле может содержаться множество тестов, ускоряя прохождение тестов благодаря отсутствию fork/exec.
Другая инфраструктура, используемая набором быстрых тестов LLVM — это lit, LLVM Integrated Tester. lit основан на shell, он выполняет команды теста, и заключает, что тест успешно пройден, если все команды успешно завершились.
Вот пример теста на lit (я взял его из начала этого файла, который содержит дополнительные тесты, которые сейчас не имеют значения):
; RUN: opt < %s -instcombine -S | FileCheck %s
define i64 @test1(i64 %A, i32 %B) {
%tmp12 = zext i32 %B to i64
%tmp3 = shl i64 %tmp12, 32
%tmp5 = add i64 %tmp3, %A
%tmp6 = and i64 %tmp5, 123
ret i64 %tmp6
; CHECK-LABEL: @test1(
; CHECK-NEXT: and i64 %A, 123
; CHECK-NEXT: ret i64
}
Этот тест проверяет, что InstCombine, проход peephole-оптимизации уровня промежуточного кода, способен заметить бесполезные инструкции: zext, shl и add здесь не нужны. Строка CHECK-LABEL находит строку, с которой начинается функция оптимизированного кода, первый CHECK-NEXT проверяет, что дальше идёт инструкция and, второй CHECK-NEXT проверяет, что дальше идёт инструкция ret (спасибо Майклу Куперсайну (Michael Kuperstein) за правильное и своевременное объяснение этого теста).
Для запуска тестов, файл интерпретируется три раза. Сначала он сканируется, и в нём ищутся строки, содержащие «RUN:», и выполняются все соответствующие команды. Далее файл интерпретируется утилитой opt, оптимизатором LLVM IR, это происходит, т.к. lit заменил переменные %s именем файла, который обрабатывается. Так как комментарии в текстовом LLVM IR начинаются с точки с запятой, директивы lit игнорируются оптимизатором. Выход оптимизатора подаётся в утилиту FileCheck, которая парсит файл снова, ищет команды, такие, как CHECK и CHECK-NEXT, они заставляют утилиту искать строку в своём stdin, и возвратить ненулевой код завершения, если любая заданная строка не найдена (CHECK-LABEL используется для разделения файла на набор логически отдельных тестов).
Важной стратегической задачей тестирования является использование инструментов анализа покрытия, чтобы найти части кодовой базы, которая не покрыта тестами. Здесь приведён свежий отчёт по покрытию LLVM, основанный на запуске модульных/регрессионных тестов. Эти данные достаточно интересны, чтобы изучить их подробнее. Давайте рассмотрим покрытие InstCombine, которое в целом очень хорошее (ссылка недоступна, к сожалению. прим. перев). Интересный проект для того, кто хочет начать работать с LLVM, это написание тестов для покрытия нетестированных частей InstCombine. Например, вот первый непокрытый тестами код (выделен красным) в InstCombineAndOrXor.cpp:
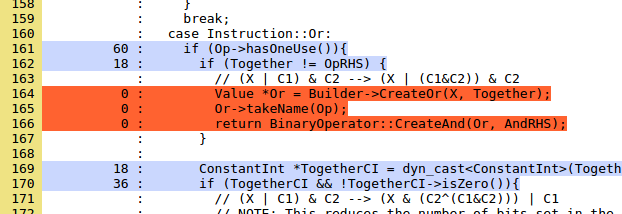
Комментарий говорит нам, что ищет проход преобразования, и должно быть довольно просто написать тест для этого кода. Код, который не может быть протестирован, мёртв, иногда мёртвый код желательно удалять, в других случаях, как в этом примере (из того же файла), код будет не мёртв только в случае появления бага:
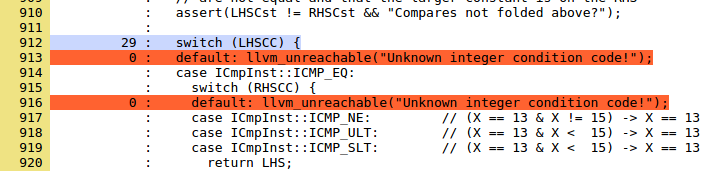
Попытка покрыть эти строки — хорошая идея, но в этом случае вы пытаетесь найти баг в LLVM, а не просто улучшить тестовый набор. Возможно, будет хорошей идеей научить инструмент анализа покрытия не сообщать нам о строках, отмеченных как недостижимые.
Набор тестов LLVM
В противоположность регрессионным/модульным тестам, которые являются частью репозитория LLVM и могут быть запущены быстро, набор тестов является внешним и занимает больше времени. Не ожидается, что разработчики будут запускать эти тесты до коммита, однако эти тесты запускаются автоматически и часто, с помощью LNT (см. следующий раздел). Набор тестов LLVM содержит целые программы, которые компилируются и запускаются, это не предназначено для каких-то определёных оптимизаций, а для подтверждения качества и корректности сгенерированного кода в целом.
Для каждого бенчмарка, набор тестов содержит тестовый ввод и соответствующий ожидаемый выход. Некоторые части тестового набора являются внешними, имеется в виду, что существует поддержка для вызова этих тестов, но сами по себе тесты не являются частью тестового набора и должны быть загружены отдельно, обычно из-за того, что используется несвободное ПО.
LNT
LNT (LLVM Nightly Test) не содержит никаких тестов, это инструмент агрегирования и анализа результатов тестов, сфокусированный на мониторинге качества кода, сгенерированного компилятором. Содержит локальные утилиты для запуска тестов и подтверждения результатов, а также серверную базу данных и веб-фронтенд, который позволяет легко просматривать результаты. Результаты NTS (Nightly Test Suite) находятся здесь.
BuildBot
Linux/Windows BuiltBot и Darwin BuiltBot (я не знаю, почему их два) используются для того, чтобы убедиться, что LLVM конфигурируется, собирается, и проходит модульные/регрессионные тесты на большом количестве разных платформ и в разнообразных конфигурациях. BuildBot имеет поддержку команды blame, для того, чтобы найти проблемный коммит и послать письмо его автору.
Эклектические усилия по тестированию
Некоторые усилия по тестированию предпринимаются вне ядра сообщества LLVM и не систематичны, в смысле того, какая версия LLVM тестируется. Эти тесты появились благодаря усилиям отдельных разработчиков, которые хотели попробовать некий особый инструмент или технику. Например, долгое время моя группа тестировала Clang+LLVM, используя Csmith и сообщала о найденных ошибках (см. высокоуровневое описание). Sam Liedes применял afl-fuzz для тестирования Clang. Zhendong Su и его группа нашла очень впечатляющее количество багов. Nuno Lopes сделал потрясающее, основанное на формальных методах тестирование проходов оптимизации, о котором я надеюсь написать в скором времени.
Тестирование в дикой природе
Последний уровень тестирования, разумеется, выполняют пользователи LLVM, которые иногда вызывают сбои и неправильную компиляцию, которую пропустили другие тестовые методы. Я часто хотел лучше понимать возникновение багов компилятора. Причины неверной компиляции пользовательского кода бывает трудно выявить, так как сложно уменьшить код так, чтобы выявить причину срабатывания бага. Однако, люди используют псевдослучайные изменения в коде в процессе дебага, справляются с проблемой благодаря случайности и вскоре забывают про неё.
Большой инновацией было бы внедрение в LLVM схемы валидации трансляции, которая бы использовала SMT-солвер для доказательства того, что выход компилятора соответствует входу. Здесь есть множество проблем, включая неопределённое поведение, и тот факт, что сложно масштабировать валидацию на большие функции, которые, на практике и вызывают ошибки в компиляции.
Чередуйте тестовые оракулы
«Тестовый оракул» — это способ определить, прошёл тест или нет. Простые оракулы включают проверки типа «компилятор завершился с кодом 0» или «скомпилированный бенчмарк выдал ожидаемый выход». Но так будет пропущено множество интересных багов, таких, как «использование после освобождения», которое не вызвало падения программы или переполнение целого (см. стр. 7 этой статьи с примером для GCC). Детекторы багов, такие, как ASan, UBSan, и Valgrind могут оснастить программу оракулами, производными от стандартов C и C++, давая много полезных возможностей для поиска багов. Для запуска LLVM под Valgrind с выполнением тестового набора, передайте -DLLVM_LIT_ARGS=»-v --vg» в CMake, но будьте готовы к тому, что Valgrind даёт ложноположительные срабатывания, которые трудно устранить. Для того, чтобы проверить LLVM с UBSan, передайте DLLVM_USE_SANITIZER=Undefined в CMake. Это замечательно, но нужно много работы, так как UBSan/ASan/MSan не отлавливают все случаи неопределенного поведения и также определённого, но неправильного поведения, такого, как переполнение беззнакового целого в GCC в примере выше.
Что происходит, если тест не проходит?
Сломанный коммит может вызвать падение теста на любом уровне. Такой коммит либо чинится (если это несложно), либо отклоняется, если имеет глубокие недостатки или нежелателен в свете новой информации, предоставленной упавшим тестом. Такое случается часто, чтобы защитить от частых изменений большую и сложную кодовую базу с множеством реальных пользователей.
Когда тест падает, и проблему трудно устранить немедленно, но она может быть устранена, когда, например, новые фичи будут закончены, тест может быть помечен как XFAIL, или «expected failure». Такие тесты учитываются инструментами тестирования отдельно, и не попадают в общий счёт упавших тестов, которые должны быть пофиксены перед тем, как патч будет принят.
Заключение
Тестирование большой, переносимой, широко используемой программной системы — трудная задача, включающая в себя много работы, если мы хотим уберечь пользователей LLVM от багов. Конечно, есть и другие очень важные вещи, которые нужны, чтобы сохранять высокое качество кода: хороший дизайн, код ревью, семантика промежуточного представления, статический анализ, периодическая переработка проблемных областей.
