[Перевод] Прощай, MongoDB, здравствуй, PostgreSQL
Наш стартап Olery был основан почти 5 лет назад. Мы начали с единственного продукта, Olery Reputation, который был создан агентством, занимавшимся разработкой на Ruby. Всё это выросло в набор различных продуктов. Сегодня у нас есть ещё Olery Feedback, API для Hotel Review Data, виджеты для вставки на сайты и многое другое.Всего у нас работает 25 приложений (все на Ruby) — некоторые из них в вебе (Rails или Sinatra), но в основном это фоновые приложения для обработки данных.
Хотя нам есть, чем гордиться, есть у нас одна проблема, которая всё время висела где-то в фоне — база данных. Изначально мы использовали MySQL для важных данных (пользователи, контракты, и т.д.) и MongoDB для хранения обзоров и других данных, которые легко можно было бы восстановить в случае утери. Сначала всё работало неплохо, но по мере роста мы начали испытывать проблемы, в особенности с MongoDB. Некоторые из них возникали в сфере взаимодействия БД с приложениями, некоторые — непосредственно у самой БД.
К примеру, в какой-то момент нам надо было удалить миллион документов из MongoDB, а позже вставить. В результате работа базы застопорилась на несколько часов. Потом нам пришлось запускать repairDatabase. И сама починка тоже заняла несколько часов.В другой раз мы заметили тормоза и определили, что причиной их стал кластер MongoDB. Но мы так и не смогли разобраться, что именно тормозит в базе. Независимо от того, какие средства для отладки и сбора статистики мы пробовали. Нам пришлось (вот тут я не знаю, как перевести, подскажите в комментариях:» until we replaced the primaries of the cluster »), чтобы быстродействие вернулось в норму.
Это всего лишь два примера, а таких было много. Проблема была не только в том, что база данных капризничала, но и в том, что мы не могли понять, почему это происходит.
Проблема отсутствия схемыЕщё одна фундаментальная проблема, с которой мы столкнулись — это основная особенность MongoDB, а именно, отсутствие схемы. В некоторых случаях это даёт преимущества. Но во многих случаях это приводит к проблеме неявных схем. Они определяются не движком хранения данных, а на основании поведения приложений и прогнозов.К примеру, у вас может быть набор страниц, в которых приложение ожидает найти поле title типа string. Схема есть, хотя явно и не задана. Проблемы начинаются, если структура данных со временем меняется, а старые данные не переносятся в новую структуру (что довольно трудно сделать в случае бессхемных баз). Допустим, у вас есть такой код:
post_slug = post.title.downcase.gsub (/\W+/, '-') Это будет работать для всех документов, у которых есть поле title, возвращающее String. Если у документов есть поле с другим именем, или вообще нет строкового поля, это сломается. Для обработки подобных случаев вам надо переписать код:
if post.title post_slug = post.title.downcase.gsub (/\W+/, '-') else # … end Другой способ — задать схему в базе данных. К примеру, Mongoid, популярный MongoDB ODM для Ruby, позволяет это сделать. Но зачем задавать схему через такие инструменты, если можно задать схему в самой базе данных? Это было бы разумно и для повторного использования. Если у вас только одно приложение работает с базой данных, это не страшно. А если их дюжина, то всё это быстро превращается в кавардак.
Хранение данных без схем задумано, как облегчение вашей жизни. Вам не надо придумывать схемы. На самом деле, в этом случае на вас перекладывают ответственность за сохранение связности данных. В некоторых случаях это работает, но готов поспорить, что в большинстве случаев это только причиняет больше трудностей.
Требования к хорошей БД И мы приходим к вопросу о том, какой должна быть хорошая БД. Мы в Olery ценим следующее: — связность— данные и поведение системы видно извне— корректность и недвусмысленность— масштабируемость
Связность помогает системе обеспечить выполнение того, что от неё ожидают. Если данные всегда хранятся определённым образом, то система становится проще. Если какое-то поле необходимо, значит, приложение не должно проверять его наличие. ББ должна гарантировать завершение определённых операций даже под нагрузкой. Нет ничего более разочаровывающего, чем вставить данные и ожидать их появления в базе в течение нескольких минут.
Видимость извне описывает как саму систему, так и то, насколько из неё просто извлекать данные. Если система глючит, её должно быть просто отладить. Запросы данных также должны быть простыми.
Корректность подразумевает, что система оправдывает ожидания. Если поле определено, как числовое, у вас не должно быть возможности вставить туда текст. MySQL в этом плане крайне слаба. Вы можете вставить текст в числовое поле и получить какую-то ерунду в данных.
Масштабируемость важна не только для быстродействия, но и с финансовой точки зрения, и с точки зрения того, как система реагирует на изменяющиеся требования. Система должна хорошо работать без неразумных финансовых затрат, и не замедлять цикл разработки систем, которые от неё зависят
Уход от MongoDB Обдумав всё это, мы пошли на поиски замены для MongoDB. Поскольку наши запросы явно подходили под традиционные реляционные БД, мы обратили взоры на двух кандидатов: MySQL и PostgreSQL.MySQL был первым, в частности потому, что мы его уже использовали в кое-каких случаях. Но и у него есть свои проблемы. К примеру, задав поле как int (11), вы можете вставить туда текст, и MySQL попытается его сконвертировать. Примеры:
mysql> create table example (`number` int (11) not null); Query OK, 0 rows affected (0.08 sec)
mysql> insert into example (number) values (10); Query OK, 1 row affected (0.08 sec)
mysql> insert into example (number) values ('wat'); Query OK, 1 row affected, 1 warning (0.10 sec)
mysql> insert into example (number) values ('what is this 10 nonsense'); Query OK, 1 row affected, 1 warning (0.14 sec)
mysql> insert into example (number) values ('10 a'); Query OK, 1 row affected, 1 warning (0.09 sec)
mysql> select * from example; ±-------+ | number | ±-------+ | 10 | | 0 | | 0 | | 10 | ±-------+ 4 rows in set (0.00 sec) Хотя MySQL и выдаёт предупреждения, предупреждения часто просто игнорируются.
Вторая проблема — любое изменение в таблице приводит к её залочке на чтение и запись. Значит, после каждой операции изменений приходится ожидать её окончания. Для больших таблиц это может занимать часы, в результате чего будет тормозить весь проект. Компании вроде SoundCloud разработали из-за этого специальные инструменты типа lhm.
Поэтому мы начали присматриваться к PostgreSQL. У неё есть много преимуществ. Например, нельзя вставить текст в числовое поле:
olery_development=# create table example (number int not null); CREATE TABLE
olery_development=# insert into example (number) values (10); INSERT 0 1
olery_development=# insert into example (number) values ('wat'); ERROR: invalid input syntax for integer: «wat» LINE 1: insert into example (number) values ('wat'); ^ olery_development=# insert into example (number) values ('what is this 10 nonsense'); ERROR: invalid input syntax for integer: «what is this 10 nonsense» LINE 1: insert into example (number) values ('what is this 10 nonsen… ^ olery_development=# insert into example (number) values ('10 a'); ERROR: invalid input syntax for integer:»10 a» LINE 1: insert into example (number) values ('10 a'); У PostgreSQL также есть возможность изменения таблиц, которая не приводит к их залочке. К примеру, операция по добавлению столбца, у которого нет значения по умолчанию, и который можно заполнить NULL, не залочивает таблицу.
Есть и другие интересные особенности, а именно: индекс и поиск, основанный на триграммах, полнотекстовый поиск, поддержка JSON-запросов, поддержка запросов и хранения пар ключ-значение, поддержка pub/sub и многое другое.
А самое важное, у PostgreSQL есть баланс между быстродействием, надёжностью, корректностью и связностью.
Переход на PostgreSQL Итак, мы решили остановиться на PostgreSQL. Процесс миграции с MongoDB представлял собой непростую задачу. Мы разбили её на три этапа: — подготовка базы PostgreSQL, миграция небольшой части данных— обновление приложений, которые работают с MongoDB, для работы с PostgreSQL, включая какой-либо рефакторинг— миграция продакшена на новую БД и размещение на новой платформе
Миграция небольшой части данных Хотя и существуют инструменты для миграции, из-за особенности наших данных нам пришлось самостоятельно делать такие инструменты. Это были одноразовые Ruby-скрипты, каждый из которых занимался отдельной задачей — переносом обзоров, подчисткой кодировок, правкой основных ключей и прочего.Обновление приложений Больше всего времени ушло на обновление приложений, особенно тех, которые сильно зависели от MongoDB. Это заняло несколько недель. Процесс представлял собой следующее: — замена драйвера/кода/модели MongoDB на код для PostgreSQL— прогон тестов— исправление тестов— повторить пункт 2
Для приложений, работавших не на Rails, мы остановились на использовании Sequel. Для Rails взяли ActiveRecord. Sequel — удобный набор инструментов, поддерживающий почти все особые функции PostgreSQL. В построении запросов он выигрывает у ActiveRecord, хотя местами получается чересчур много текста.
К примеру, надо вам подсчитать количество пользователей, использующих определённую локаль в процентах к общему количеству. На простом SQL такой запрос может выглядеть так:
SELECT locale, count (*) AS amount, (count (*) / sum (count (*)) OVER ()) * 100.0 AS percentage
FROM users
GROUP BY locale ORDER BY percentage DESC; В нашем случае получится следующий результат:
locale | amount | percentage --------±-------±------------------------- en | 2779×85.193133047210300429000 nl | 386×11.833231146535867566000 it | 40×1.226241569589209074000 de | 25×0.766400980993255671000 ru | 17×0.521152667075413857000 | 7×0.214592274678111588000 fr | 4×0.122624156958920907000 ja | 1×0.030656039239730227000 ar-AE | 1×0.030656039239730227000 eng | 1×0.030656039239730227000 zh-CN | 1×0.030656039239730227000 (11 rows) Sequel позволяет написать такой запрос на чистом Ruby без строковых фрагментов (которые иногда требуются для ActiveRecord):
star = Sequel.lit ('*')
User.select (: locale) .select_append { count (star).as (: amount) } .select_append { ((count (star) / sum (count (star)).over) * 100.0).as (: percentage) } .group (: locale) .order (Sequel.desc (: percentage)) Если вам не хочется использовать Sequel.lit ('*'), можно поступить так:
User.select (: locale) .select_append { count (users.*).as (: amount) } .select_append { ((count (users.*) / sum (count (users.*)).over) * 100.0).as (: percentage) } .group (: locale) .order (Sequel.desc (: percentage)) Текста многовато, но зато их можно легко переделывать в будущем.
В планах мы хотим перевести приложения, работающие с Rails, на Sequel. Но пока непонятно, стоит ли это потраченного времени
Миграция рабочих данных Для этого есть два способа: — остановить весь проект, мигрировать данные, поднять проект— мигрировать параллельно с работающим проектом
Первый вариант подразумевает, что проект не будет работать некоторое время. Второй сложен в исполнении. Нужно учесть все те новые данные, которые будут добавлены во время миграции, чтобы не потерять их.
К счастью, в Olery всё так хитро настроено, что операции с БД происходят через примерно равные промежутки времени. Данные, которые меняются чаще, перенести легче, потому что их очень мало.
План такой:
— перенести критичные данные — пользователи, контракты, и т.д.— перенести менее критичные данные (которые потом можно пересчитать или восстановить)— проверить, что всё работает на наборе раздельных серверов— перенести продакшен на новые сервера— перенести все критичные данные, которые появились с первого шага
Второй шаг занял сутки. Первый и пятый — по 45 минут.
Заключение
Прошёл уже почти месяц, как мы перенесли все данные, и нас всё устраивает. Изменения произошли только к лучшему. Увеличилось быстродействие приложений. Время отзывов у API уменьшилось.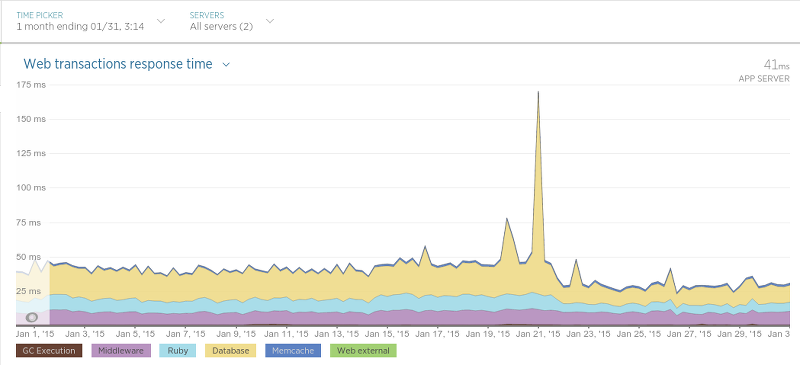
Переезжали мы 21 января. Пик на графике — рестарт приложения, приведший ко временному увеличению времени отклика. После 21 числа время отклика уменьшилось почти вдвое.
Где мы ещё заметили серьёзное увеличение быстродействия, так это в приложении, которое сохраняло данные из обзоров и рейтингов.
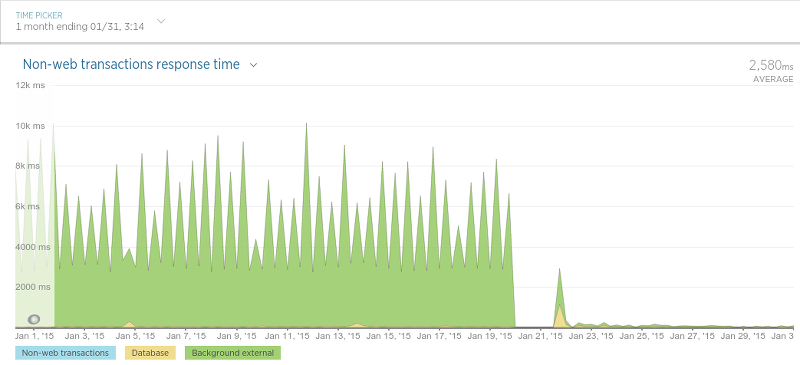
Наши сборщики данных также ускорились.
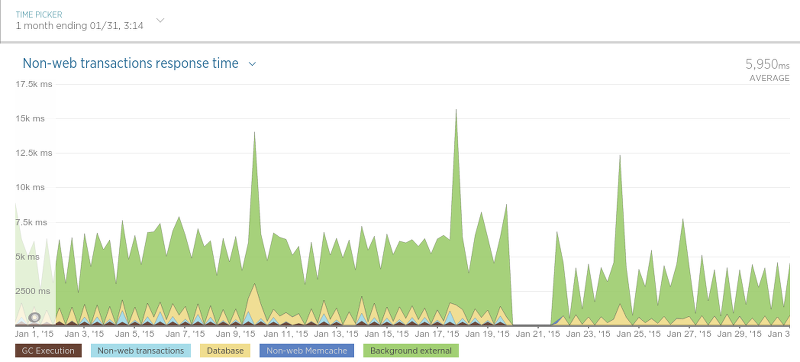
Разница вышла не такой сильной, но сборщики и не так сильно используют базу данных.
И, наконец, приложение, которое распределяет график работы сборщиков данных («scheduler»):
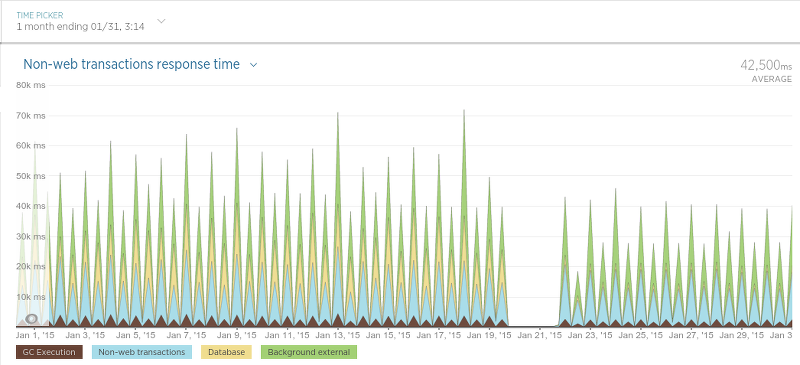
Поскольку он работает через определённые промежутки времени, график трудноват для чтения, но в целом есть явное понижение времени отклика.
Итак, мы вполне удовлетворены результатами переезда, и скучать по MongoDB не собираемся. Быстродействие отличное, инструменты для работы с базой очень удобные, запросы к данным делать стало гораздо проще, в сравнении с MongoDB. Единственный сервис, который ещё её использует, это Olery Feedback. Он работает на своём отдельном кластере. Но и его мы в будущем также собираемся перевести на PostgreSQL.
