[Перевод] Пирамида тестов на практике
 Об авторе: Хэм Фокке — разработчик и консультант ThoughtWorks в Германии. Устав от деплоя в три ночи, он добавил в свой инструментарий средства непрерывной доставки и тщательной автоматизации. Сейчас налаживает такие системы другим командам для обеспечения надёжной и эффективной поставки программного обеспечения. Так он экономит компаниям время, которое эти надоедливые людишки тратили на свои выходки.
Об авторе: Хэм Фокке — разработчик и консультант ThoughtWorks в Германии. Устав от деплоя в три ночи, он добавил в свой инструментарий средства непрерывной доставки и тщательной автоматизации. Сейчас налаживает такие системы другим командам для обеспечения надёжной и эффективной поставки программного обеспечения. Так он экономит компаниям время, которое эти надоедливые людишки тратили на свои выходки.
«Пирамида тестов» — метафора, которая означает группировку тестов программного обеспечения по разным уровням детализации. Она также даёт представление, сколько тестов должно быть в каждой из этих групп. Несмотря на то, что концепция тестовой пирамиды существует довольно давно, многие команды разработчиков по-прежнему пытаются неправильно реализовать её на практике должным образом. В этой статье рассматривается первоначальная концепция тестовой пирамиды и показано, как её воплотить в жизнь. Она показывает, какие виды тестов следует искать на разных уровнях пирамиды, и даёт практические примеры, как их можно реализовать.
Примечания

Перед выпуском программное обеспечение нужно тестировать. По мере взросления софтверной отрасли созрели и подходы к тестированию. Вместо мириадов живых тестировщиков разработчики перешли к автоматизации большей части тестов. Автоматизация тестов позволяет узнать о баге в считанные секунды и минуты после его внесения в код, а не через несколько дней или недель.
Резко сокращённый цикл обратной связи, подпитываемый автоматизированными тестами, идёт рука об руку с гибкими практиками разработки, непрерывной доставкой и культурой DevOps. Эффективный подход к тестированию обеспечивает быструю и уверенную разработку.
В этой статье рассматривается, как должен выглядеть хорошо сформированный набор тестов, чтобы быть гибким, надёжным и поддерживаемым — независимо от того, создаете ли вы архитектуру микросервисов, мобильные приложения или экосистемы IoT. Мы также детально рассмотрим создание эффективных и удобочитаемых автоматизированных тестов.
Программное обеспечение стало неотъемлемой частью мира, в котором мы живём. Оно переросло первоначальную единственную цель увеличить эффективность бизнеса. Сегодня каждая компания стремится стать первоклассной цифровой компанией. Все мы каждый день выступаем пользователями всё большего количества ПО. Скорость инноваций возрастает.
Если хотите идти в ногу со временем, нужно искать более быстрые способы доставки ПО, не жертвуя его качеством. В это может помочь непрерывная доставка — это практика, которая автоматически гарантирует, что ПО может быть выпущено в продакшн в любое время. При непрерывной доставке используется конвейер сборки для автоматического тестирования ПО и его развёртывания в тестовой и рабочей средах.
Вскоре сборка, тестирование и развёртывание постоянно растущего количества ПО вручную становится невозможной — если только вы не хотите тратить всё своё время на выполнение вручную рутинных задач вместо доставки рабочего софта. Единственный путь — автоматизировать всё, от сборки до тестирования, развёртывания и инфраструктуры.

Рис. 1. Использование конвейеров сборки для автоматического и надёжного ввода ПО в эксплуатацию
Традиционно тестирование требовало чрезмерной ручной работы через развертывание в тестовой среде, а затем тестов в стиле чёрного ящика, например, кликанием повсюду в пользовательском интерфейсе с наблюдением, появляются ли баги. Часто эти тесты задаются тестовыми сценариями, чтобы гарантировать, что тестировщики всё последовательно проверят.
Очевидно, что тестирование всех изменений вручную занимает много времени, оно однообразное и утомительное. Однообразие скучно, а скука приводит к ошибкам.
К счастью, есть прекрасный инструмент для однообразных задач: автоматизация.
Автоматизация однообразных тестов изменит вашу жизнь как разработчика. Автоматизируйте тесты, и вам больше не придётся бездумно следовать клик-протоколам, проверяя корректность работы программы. Автоматизируйте тесты, и вы не моргнув глазом измените кодовую базу. Если вы когда-либо пробовали делать крупномасштабный рефакторинг без надлежащего набора тестов, я уверен, вы знаете, в какой ужас это может превратиться. Как вы узнаете, если случайно сделаете ошибку в процессе? Ну, придётся щёлкать вручную по всем тестовым случаям, как же ещё. Но будем честными: вам это действительно нравится? Как насчёт того, чтобы даже после крупномасштабных изменений любые баги проявляли себя в течение нескольких секунд, пока вы пьёте кофе? По-моему, это гораздо приятнее.
Если серьёзно подходить к автоматическим тестам, то есть одна ключевая концепция: пирамида тестов. Её представил Майк Кон в своей книге «Scrum: гибкая разработка ПО» (Succeeding With Agile. Software Development Using Scrum). Это отличная визуальная метафора, наталкивающая на мысль о разных уровнях тестов. Она также показывает объём тестов на каждом уровне.
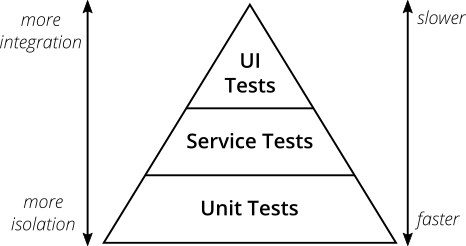
Рис. 2. Пирамида тестов
Оригинальная пирамида тестов Майка Кона состоит из трёх уровней (снизу вверх):
- Юнит-тесты.
- Сервисные тесты.
- Тесты пользовательского интерфейса.
К сожалению, при более тщательном концепция кажется недостаточной. Некоторые утверждают, что либо именования, либо некоторые концептуальные аспекты пирамиды тестов Майка Кона не идеальны, и я должен согласиться. С современной точки зрения пирамида тестов кажется чрезмерно упрощённой и поэтому может вводить в заблуждение.
Тем не менее, из-за своей простоты суть тестовой пирамиды представляет хорошее эмпирическое правило, когда дело доходит до создания собственного набора тестов. Из этой пирамиды главное запомнить два принципа:
- Писать тесты разной детализации.
- Чем выше уровень, тем меньше тестов.
Придерживайтесь формы пирамиды, чтобы придумать здоровый, быстрый и поддерживаемый набор тестов. Напишите много маленьких и быстрых юнит-тестов. Напишите несколько более общих тестов и совсем мало высокоуровневых сквозных тестов, которые проверяют приложение от начала до конца. Следите, что у вас в итоге не получился тестовый рожок мороженого, который станет кошмаром в поддержке и будет слишком долго выполняться.
Не привязывайтесь слишком сильно к названиям отдельных уровней пирамиды тестов. На самом деле они могут ввести в заблуждение: термин «сервисный тест» трудно понять (сам Кон заметил, что многие разработчики полностью игнорируют этот уровень). В наше время фреймворков для одностраничных приложений вроде React, Angular, Ember.js и других становится очевидным, что тестам UI не место на вершине пирамиды — вы прекрасно можете протестировать UI во всех этих фреймворках.
Учитывая недостатки оригинальных названий в пирамиде, вполне нормально придумать другие имена для своих уровней тестов. Главное, чтобы они соответствовали вашему коду и терминологии, принятой в вашей команде.
- JUnit: для запуска тестов
- Mockito: для зависимостей имитаций
- Wiremock: для заглушек внешних сервисов
- Pact: для написания CDC-тестов
- Selenium: для написания сквозных тестов UI
- REST-assured: для написания сквозных тестов REST API
Я написал простой микросервис с тестами из разных уровней пирамиды.
Это пример типичного микросервиса. Он предоставляет интерфейс REST, общается с БД и извлекает информацию из стороннего сервиса REST. Он реализован на Spring Boot и должен быть понятен даже если вы никогда не работали со Spring Boot.
Обязательно проверьте код на Github. В файле readme инструкции для запуска приложения и автоматических тестов на вашем компьютере.
Функциональность
У приложения простая функциональность. Оно обеспечивает интерфейс REST с тремя конечными точками:
GET /hello
Возвращает "Hello World". Всегда.
GET /hello /{lastname}
Ищет человека с указанной фамилией. Если человек известен, возвращает «Hello {Firstname} {Lastname}».
GET /weather
Возвращает текущие погодные условия в Гамбурге, Германия.
Высокоуровневые структуры
На высоком уровне у системы следующая структура:

Рис. 3. Высокоуровневая структура микросервиса
Наш микросервис обеспечивает интерфейс REST по HTTP. Для некоторых конечных точек сервис получает информацию из БД. В других случаях обращается по HTTP к внешнему API для получения и отображения текущей погоды.
Внутренняя архитектура
Изнутри у Spring Service типичная архитектура для Spring:
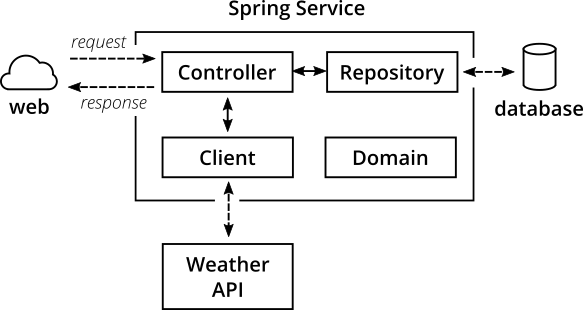
Рис. 4. Внутренняя структура микросервиса
- Классы
Controllerпредоставляют конечные точки REST, обрабатывают запросы HTTP и ответы. - Классы
Repositoryвзаимодействуют с базой данных, отвечают за запись и чтение данных в/из постоянного хранилища. - Классы
Clientвзаимодействуют с другими API, в нашем случае — забирают данные JSON по HTTPS с погодного API на darksky.net. - Классы
Domainзахватывают модель домена, включая логику домена (которая, честно говоря, в нашем случае довольно тривиальна).
Опытные разработчики Spring могут заметить, что здесь отсутствует часто используемый слой: многие вдохновлённые проблемно-ориентированным проектированием разработчики создают слой сервисов, состоящий из классов сервисов. Я решил не включать его в приложение. Одна из причин в том, что наше приложение достаточно простое, а слой сервисов станет ненужным уровнем косвенности. Другая причина в том, что на мой взгляд люди часто переусердствуют с этими слоями. Нередко приходится видеть кодовые базы, где классы сервисов охватывают всю бизнес-логику. Модель домена становится просто слоем для данных, а не для поведения (анемичная модель домена). Для каждого нетривиального приложения так теряются большие возможности для хорошей структуризации кода и тестируемости, а также не в полной мере используется мощь объектной ориентации.
Наши репозитории просты и обеспечивают простую функциональность CRUD. Для простоты кода я использовал Spring Data. Он даёт простую и универсальную реализацию репозитория CRUD, а также заботится о том, чтобы развернуть для наших тестов БД в памяти, а не использовать реальную PostgreSQL, как это было бы в продакшне.
Взгляните на кодовую базу и познакомьтесь с внутренней структурой. Это полезно для следующего шага: тестирования приложения!
Основа вашего набора тестов состоит из юнит-тестов (модульных тестов). Они проверяют, что отдельный юнит (тестируемый субъект) кодовой базы работает должным образом. Модульные тесты имеют максимально узкую область среди всех тестов в наборе тестов. Количество юнит-тестов в наборе значительно превышает количество любых других тестов.

Рис. 5. Обычно юнит-тест заменяет внешних пользователей тестовыми дублями
Что такое юнит?
Если вы спросите трёх разных людей, что означает «юнит» в контексте юнит-тестов, то вероятно получите четыре разных, слегка отличающихся ответа. В определённой степени это вопрос вашего собственного определения — и это нормально, что здесь нет общепринятого канонического ответа.
Если вы пишете на функциональном языке, то юнитом скорее всего будет отдельная функция. Ваши юнит-тесты вызовут функцию с различными параметрами и обеспечат возврат ожидаемых значений. В объектно-ориентированном языке юнит может варьироваться от отдельного метода до целого класса.
Общительные и одинокие тесты
Некоторые утверждают, что всех участников (например, вызываемые классы) тестируемого субъекта следует заменить на имитации (mocks) или заглушки (stubs), чтобы создать идеальную изоляцию, избежать побочных эффектов и сложной настройки теста. Другие утверждают, что на имитации и заглушки следует заменять только участников, которые замедляют тест или проявляют сильные побочные эффекты (например, классы с доступом к БД или сетевыми вызовами).
Иногда эти два вида юнит-тестов называют одинокими (solitary) в случае тотального применения имитаций и заглушек или общительными (sociable) в случае реальных коммуникаций с другими участниками (эти термины придумал Джей Филдс для книги «Эффективная работа с юнит-тестами»). Если у вас есть немного свободного времени, можете спуститься в кроличью нору и разобраться в преимуществах и недостатках разных точек зрения.
Но в итоге не имеет значения, какой тип тестов вы выберете. Что реально важно, так это их автоматизация. Лично я постоянно использую оба подхода. Если неудобно работать с реальными участниками, я буду обильно использовать имитации и заглушки. Если чувствую, что привлечение реального участника даёт больше уверенности в тесте, то заглушу только самые дальние части сервиса.
Имитации и заглушки
Имитации (mocks) и заглушки (stubs) — это два разных типа тестовых дублёров (вообще их больше). Многие используют термины взаимозаменяемо. Думаю, что лучше соблюдать точность и держать в уме конкретные свойства каждого из них. К объектам из продакшна тестовые дублёры создают реализацию для тестов.
Проще говоря, вы заменяете реальную вещь (например, класс, модуль или функцию) поддельной копией. Подделка выглядит и действует как оригинал (даёт такие же ответы на те же вызовы методов), но это заранее установленные ответы, которые вы сами определяете для юнит-теста.
Тестовые дублёры используются не только в юнит-тестах. Более сложные дублёры применяются для контролируемой имитации целых частей вашей системы. Однако в юнит-тестах используется особенно много имитаций и заглушек (в зависимости от того, предпочитаете вы общительные или одиночные тесты) просто потому что множество современных языков и библиотек позволяют легко и удобно их создавать.
Независимо от выбранной технологии, в стандартной библиотеке вашего языка или какой-то популярной сторонней библиотеке уже есть элегантный способ настройки имитаций. И даже для написания собственных имитаций с нуля достаточно всего лишь написать поддельный класс/модуль/функцию с той же подписью, что и реальная, и настройки имитации для теста.
Ваши юнит-тесты будут работать очень быстро. На приличной машине можно прогнать тысячи модульных тестов за нескольких минут. Тестируйте изолированно небольшие фрагменты кодовой базы и избегайте контактов с БД, файловой системой и HTTP-запросов (ставя здесь имитации и заглушки), чтобы сохранить высокую скорость.
Поняв основы, со временем вы начнёте всё более свободно и легко писать юнит-тесты. Заглушка внешних участников, настройка входных данных, вызов тестируемого субъекта — и проверка, что возвращаемое значение соответствует ожидаемому. Посмотрите на разработку через тестирование (TDD), и пусть юнит-тесты направляют вашу разработку; если они применяются правильно, это поможет попасть в мощный поток и создать хорошую поддерживаемую архитектуру, автоматически выдавая всеобъемлющий и полностью автоматизированный набор тестов. Но это не универсальное решение. Попробуйте и посмотрите сами, подходит ли TDD в вашем конкретном случае.
Что тестировать?
Хорошо, что юнит-тесты можно писать для всех классов кода продакшна, независимо от их функциональности или того, к какому уровню внутренней структуры они принадлежат. Юнит-тесты подходят для контроллеров, репозиториев, классов предметной области или программ считывания файлов. Просто придерживайтесь практического правила один тестовый класс на один класс продакшна.
Юнит-тест должен как минимум протестировать открытый интерфейс класса. закрытые методы всё равно нельзя протестировать, потому что их нельзя вызвать из другого тестового класса. Защищённые или доступные лишь в пределах пакета (package-private) методы доступны из тестового класса (учитывая, что структура пакета тестового класса такая же, как на продакшне), но тестирование этих методов может уже зайти слишком далеко.
Когда дело доходит до написания юнит-тестов, есть тонкая черта: они должны гарантировать, что проверены все нетривиальные пути кода, включая дефолтный сценарий и пограничные ситуации. В то же время они не должны быть слишком тесно привязаны к реализации.
Почему так?
Тесты, слишком привязанные к коду продакшна, быстро начинают раздражать. Как только вы осуществляете рефакторинг кода (то есть изменяете внутреннюю структуру кода без изменения внешнего поведения), модульные тесты сразу ломаются.
Таким образом, вы теряете важное преимущество юнит-тестов: действовать в качестве системы безопасности для изменений кода. Вы скорее устанете от этих глупых тестов, которые падают каждый раз после рефакторинга, принося больше проблем, чем пользы; чья вообще была эта дурацкая идея внедрить тесты?
Чем же делать? Не отражайте в модульных тестах внутреннюю структуру кода. Тестируйте наблюдаемое поведение. Например:
если я введу значения x и y, будет ли результат z?
вместо этого:
если я введу x и y, то обратится ли метод сначала к классу А, затем к классу Б, а затем сложит результаты от класса А и класса Б?
Как правило, закрытые методы следует рассматривать как деталь реализации. Вот почему даже не должно появляться желание их проверить.
Часто я слышу от противников модульного тестирования (или TDD), что написание юнит-тестов становится бессмысленным, если нужно проверить все методы для большого охвата тестирования. Они часто ссылаются на сценарии, где чрезмерно нетерпеливый тимлид заставил писать модульные тесты для геттеров и сеттеров и прочего тривиального кода, чтобы выйти на 100% тестового покрытия.
Это совершенно неправильно.
Да, вы должны протестировать публичный интерфейс. Но ещё более важно не тестировать тривиальный код. Не волнуйтесь, Кент Бек это одобряет. Вы ничего не получите от тестирования простых геттеров или сеттеров или других тривиальных реализаций (например, без какой-либо условной логики). И вы сэкономите время, так что сможете посидеть ещё на одном совещании, ура!
Но мне очень нужно проверить этот закрытый метод
Если вы когда-нибудь окажетесь в ситуации, когда вам очень-очень нужно проверить закрытый метод, нужно сделать шаг назад и спросить себя: почему?Уверен, что здесь скорее проблема дизайна. Скорее всего, вы чувствуете необходимость протестировать закрытый метод, потому что он сложный, а тестирование метода через открытый интерфейс класса требует слишком неудобной настройки.
Всякий раз, когда я оказываюсь в такой ситуации, я обычно прихожу к выводу, что тестируемый класс переусложнён. Он делает слишком много и нарушает принцип единой ответственности — один из пяти принципов SOLID.
Для меня часто работает решение разделить исходный класс на два класса. Часто после минуты-другой размышлений находится хороший способ разбить большой класс на два меньших с индивидуальной ответственностью. Я перемещаю закрытый метод (который срочно надо протестировать) в новый класс и позволяю старому классу вызвать новый метод. Вуаля, неудобный для тестирования закрытый метод теперь публичен и легко тестируется. Кроме того, я улучшил структуру кода, внедрив принцип единой ответственности.
Cтруктура теста
Хорошая структура всех ваших тестов (не только модульных) такова:
- Настройка тестовых данных.
- Вызов тестируемого метода.
- Проверка, что возвращаются ожидаемые результаты.
Есть хорошая мнемоника для запоминания этой структуры: три A (Arrange, Act, Assert). Можно использовать и другую мнемонику с корнями в BDD (разработка, основанная на описании поведения). Это триада дано, когда, тогда, где «дано» отражает настройку, «когда» — вызов метода, а «тогда» — утверждение.
Этот шаблон можно применить и к другим, более высокоуровневым тестам. В каждом случае они гарантируют, что тесты остаются лёгкими и читаемыми. Кроме того, написанные с учётом этой структуры тесты обычно короче и выразительнее.
Реализация юнит-теста
Теперь мы знаем, что именно тестировать и как структурировать юнит-тесты. Пришло время посмотреть на реальный пример.
Возьмем упрощённую версию класса ExampleController.
@RestController
public class ExampleController {
private final PersonRepository personRepo;
@Autowired
public ExampleController(final PersonRepository personRepo) {
this.personRepo = personRepo;
}
@GetMapping("/hello/{lastName}")
public String hello(@PathVariable final String lastName) {
Optional foundPerson = personRepo.findByLastName(lastName);
return foundPerson
.map(person -> String.format("Hello %s %s!",
person.getFirstName(),
person.getLastName()))
.orElse(String.format("Who is this '%s' you're talking about?",
lastName));
}
}
Юнит-тест для метода hello(lastname) может выглядеть таким образом:
public class ExampleControllerTest {
private ExampleController subject;
@Mock
private PersonRepository personRepo;
@Before
public void setUp() throws Exception {
initMocks(this);
subject = new ExampleController(personRepo);
}
@Test
public void shouldReturnFullNameOfAPerson() throws Exception {
Person peter = new Person("Peter", "Pan");
given(personRepo.findByLastName("Pan"))
.willReturn(Optional.of(peter));
String greeting = subject.hello("Pan");
assertThat(greeting, is("Hello Peter Pan!"));
}
@Test
public void shouldTellIfPersonIsUnknown() throws Exception {
given(personRepo.findByLastName(anyString()))
.willReturn(Optional.empty());
String greeting = subject.hello("Pan");
assertThat(greeting, is("Who is this 'Pan' you're talking about?"));
}
}
Мы пишем юнит-тесты в JUnit, стандартном фреймворке тестирования Java. Используем Mockito для замены реального класса PersonRepository на класс с заглушкой для теста. Эта заглушка позволяет указать предустановленные ответы, которые вернёт метод-заглушка. Подобный подход делает тест более простым и предсказуемым, позволяя легко настроить проверку данных.
Следуя структуре «трёх А» пишем два юнит-теста для положительного и отрицательного случаев, когда искомое лицо не может быть найдено. Положительный тестовый случай создаёт новый объект person и сообщает имитации репозитория возвращать этот объект, когда параметр lastName вызывается со значением Pan. Затем тест вызывает тестируемый метод. Наконец, он сравнивает ответ с ожидаемым.
Второй тест работает аналогично, но тестирует сценарий, в котором тестируемый метод не находит объект person для данного параметра.
Специализированные тестовые хелперы
Замечательно, что вы можете писать юнит-тесты для всей кодовой базы независимо от уровня архитектуры вашего приложения. Пример ниже показывает простой юнит-тест для контроллера. К сожалению, когда дело доходит до контроллеров Spring, у этого подхода есть недостаток: контроллер Spring MVC интенсивно использует аннотации с объявлениями прослушиваемых путей, используемых команд HTTP, параметров парсинга URL, параметров запросов и так далее. Простой вызов метода контроллера в юнит-тесте не проверит все эти важные вещи. К счастью, сообщество Spring придумало хороший тестовый хелпер, который можно использовать для улучшенного тестирования контроллера. Обязательно посмотрите MockMVC. Это даст отличный DSL для генерации поддельных запросов к контроллеру и проверки, что всё работает отлично. Я включил пример в код. Во многих фреймворках есть тестовые хелперы для упрощения тестов конкретных частей кода. Ознакомьтесь с документацией по своему фреймворку и посмотрите, предлагает ли там какие-либо полезные хелперы для ваших автоматизированных тестов.
Все нетривиальные приложения интегрированы с некоторыми другими частями (базы данных, файловые системы, сетевые вызовы к другим приложениям). В юнит-тестах вы обычно имитируете их для лучшей изоляции и повышения скорости. Тем не менее, ваше приложение будет реально взаимодействовать с другими частями — и это следует протестировать. Для этого предназначены интеграционные тесты. Они проверяют интеграцию приложения со всеми компонентами вне приложения.
Для автоматизированных тестов это означает, что нужно запустить не только собственное приложение, но и интегрируемый компонент. Если вы тестируете интеграцию с БД, то при выполнении тестов надо запустить БД. Чтобы проверить чтение файлов с диска нужно сохранить файл на диск и загрузить его в интеграционный тест.
Я ранее упоминал, что юнит-тесты — неопределённый термин. Ещё в большей степени это относится к интеграционным тестам. Для кого-то «интеграция» означает тестирование всего стека вашего приложения в комплексе с другими. Мне нравится более узкое определение и тестирование каждой точки интеграции по отдельности, заменяя остальные сервисы и базы данных тестовыми дублёрами. Вместе с контрактным тестированием и выполнением контрактных тестов на дублёрах и реальных реализациях можно придумать интеграционные тесты, которые быстрее, более независимы и обычно проще в понимании.
Узкие интеграционные тесты живут на границе вашего сервиса. Концептуально они всегда запускают действие, которое приводит к интеграции с внешней частью (файловой системой, базой данных, отдельным сервисом). Тест интеграции БД выглядит следующим образом:

Рис. 6. Тест на интеграцию БД интегрирует ваш код с реальной базой данных
- Запуск базы данных.
- Подключение приложения к БД.
- Запуск функции в коде, которая записывает данные в БД.
- Проверка, что ожидаемые данные записаны в базу путём их чтения из БД.
Другой пример. Тест интеграции вашего сервиса с отдельной службой через REST API может выглядеть следующим образом:
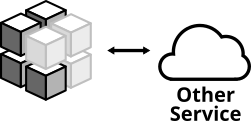
Рис. 7. Этот вид интеграционного теста проверяет, что приложение способно правильно взаимодействовать с отдельными службами
- Запуск приложения.
- Запуск инстанса отдельной службы (или тестового дублёра с тем же интерфейсом).
- Запуск функции в коде, которая считывает данные из API внешней службы.
- Проверка, что приложение правильно разбирает ответ.
Как и модульные тесты, ваши интеграционные тесты можно делать вполне прозрачно (whitebox). Некоторые фреймворки позволяют одновременно запустить и ваше приложение, и имитации отдельных его частей для проверки правильного взаимодействия.
Напишите интеграционные тесты для всех фрагментов кода, где выполняется сериализация или десериализация данных. Это происходит чаще, чем вы думаете. Подумайте о следующем:
- Вызовы REST API своих сервисов.
- Чтение и запись в БД.
- Вызовы API других приложений.
- Чтение из очереди и запись туда.
- Запись в файловую систему.
Написание интеграционных тестов вокруг этих границ гарантирует, что запись данных и чтение данных от этих внешних участников работает нормально.
При написании узких интеграционных тестов стремитесь локально запускать внешние зависимости: локальную базу данных MySQL, тест на локальной файловой системе ext4. Если интегрируетесь с отдельной службой, то или запустите экземпляр этой службы локально, или создайте и запустите поддельную версию, которая имитирует поведение реальной службы.
Если нет возможности локально запустить стороннюю службу, то лучше запустить выделенный тестовый инстанс и указать на него в интеграционным тесте. В автоматизированных тестах избегайте интеграции с реальной системой продакшна. Запуск тысяч тестовых запросов на систему продакшна — верный способ разозлить людей, потому что вы забиваете их логи (в лучшем случае) или просто ддосите их сервис (в худшем случае). Интеграция с сервисом по сети — типичное свойство широкого интеграционного теста. Обычно из-за неё тесты труднее писать и они медленнее работают.
Что касается пирамиды тестов, то интеграционные тесты находятся на более высоком уровне, чем модульные. Интеграция файловых систем и БД обычно гораздо медленнее, чем выполнение юнит-тестов с их имитациями. Их также труднее писать, чем маленькие изолированные модульные тесты. В конце концов, нужно думать о работе внешней части теста. Тем не менее, они имеют преимущество, потому что дают уверенность в правильной работе приложения со всеми внешними частями, с какими нужно. Юнит-тесты тут бесполезны.
Интеграция БД
PersonRepository — единственный класс репозитория во всей кодовой базе. Он опирается на Spring Data и не имеет фактической реализации. Он просто расширяет интерфейс CrudRepository и предоставляет единственный заголовок метода. Остальное — магия Spring.
public interface PersonRepository extends CrudRepository {
Optional findByLastName(String lastName);
}
Через интерфейс CrudRepository Spring Boot предоставляет полностью функциональное хранилище CRUD с методами findOne, findAll, save, update и delete. Наше собственное определение метода findByLastName () расширяет эту базовую функциональность и даёт возможность получать людей, то есть объекты Person, по их фамилиям. Spring Data анализирует возвращаемый тип метода, имя метода и проверяет его на соответствие конвенциям именования для выяснения, что он должен делать.
Хотя Spring Data выполняет большую работу по реализации репозиториев БД, я всё равно написал тест интеграции БД. Вы можете сказать, что это тест фреймворка, которого следует избегать, ведь мы тестируем чужой код. Тем не менее, я считаю, что здесь очень важно наличие хотя бы одного интеграционного теста. Во-первых, он проверяет нормальную работу нашего метода findByLastName. Во-вторых, это доказывает, что наш репозиторий правильно использует Spring и способен подключиться к БД.
Чтобы облегчить выполнение тестов на вашем компьютере (без установки базы данных PostgreSQL), наш тест подключается к базе данных в памяти H2.
Я определил H2 как тестовую зависимость в файле build.gradle. Файл application.properties в каталоге теста не определяет никаких свойств spring.datasource. Это указывает Spring Data использовать базу данных в памяти. Поскольку он находит H2 в пути к классу, то просто использует H2.
Реальное приложение с профилем int (например, после установки в качестве переменной среды SPRING_PROFILES_ACTIVE=int) будет подключаться к базе данных PostgreSQL, как определено в application-int.properties.
Понимаю, что здесь нужно знать и понимать кучу особенностей Spring. Придётся перелопатить кучу документации. Финальный код простой с виду, но его трудно понять, если вы не знаете конкретных особенностей Spring.
Кроме того, работа с базой данных в памяти — рискованное дело. В конце концов, наши интеграционные тесты работают с БД другого типа, чем в продакшне. Попробуйте и решите сами, предпочесть ли магию Spring и простой код — или явную, но более подробную реализацию.
Ну, хватит объяснений. Вот простой интеграционный тест, который сохраняет объект Person в базу данных и находит его по фамилии.
@RunWith(SpringRunner.class)
@DataJpaTest
public class PersonRepositoryIntegrationTest {
@Autowired
private PersonRepository subject;
@After
public void tearDown() throws Exception {
subject.deleteAll();
}
@Test
public void shouldSaveAndFetchPerson() throws Exception {
Person peter = new Person("Peter", "Pan");
subject.save(peter);
Optional maybePeter = subject.findByLastName("Pan");
assertThat(maybePeter, is(Optional.of(peter)));
}
}
Как видите, наш интеграционный тест следует той же структуре «трёх А», что и юнит-тесты. Говорил же, что это универсальная концепция!
Интеграция с отдельными сервисами
Наш микросервис получает погодные данные с darksky.net через REST API. Конечно, мы хотим убедиться, что сервис правильно отправляет запросы и разбирает ответы.
При выполнении автоматических тестов желательно избежать взаимодействия с настоящими серверами darksky. Лимиты на нашем бесплатном тарифе — лишь одна из причин. Главное — это отвязка. Наши тесты должны запускаться независимо от того, какие справляются со своей работой милые люди в darksky.net. Даже если наша машина не может достучаться до серверов darksky или они закрылись на обслуживание.
Чтобы избежать взаимодействия с реальными серверами darksky, мы для интеграционных тестов запускаем собственный, поддельный сервер darksky. Это может показаться очень трудной задачей. Но она упрощается благодаря таким инструментам, как Wiremock. Смотрите сами:
@RunWith(SpringRunner.class)
@SpringBootTest
public class WeatherClientIntegrationTest {
@Autowired
private WeatherClient subject;
@Rule
public WireMockRule wireMockRule = new WireMockRule(8089);
@Test
public void shouldCallWeatherService() throws Exception {
wireMockRule.stubFor(get(urlPathEqualTo("/some-test-api-key/53.5511,9.9937"))
.willReturn(aResponse()
.withBody(FileLoader.read("classpath:weatherApiResponse.json"))
.withHeader(CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.withStatus(200)));
Optional weatherResponse = subject.fetchWeather();
Optional expectedResponse = Optional.of(new WeatherResponse("Rain"));
assertThat(weatherResponse, is(expectedResponse));
}
}
Для Wiremock создаем инстанс WireMockRule на фиксированном порту (8089). С помощью DSL можно настроить сервер Wiremock, определить конечные точки для прослушивания и предустановленные ответы.
Далее вызываем тестируемый метод — тот, который обращается к сторонней службе — и проверяем, что результат правильно парсится.
Важно понимать, как тест определяет, что должен обратиться к поддельному сервер Wiremock вместо реального API darksky. Секрет в файле application.properties, который располагается в src/test/resources. Его Spring загружает при выполнении тестов. В этом файле мы переопределяем конфигурацию вроде ключей API и URL-адресов со значениями, подходящими для тестов. В том числе назначаем вызов поддельного сервера Wiremock вместо реального:
weather.url = http://localhost:8089
Обратите внимание, что определённый здесь порт должен быть тем же, что мы указали при создании инстанса WireMockRule для тест
