[Перевод] Организация безопасного тестирования в продакшене. Часть 1
В этой статье рассматриваются различные виды тестирования в продакшене и условия, при которых каждый из них наиболее полезен, а также рассказывается о способах организации безопасного тестирования различных сервисов в продакшене.
Стоит заметить, что содержание этой статьи касается только тех сервисов, развёртывание которых контролируют разработчики. Кроме того, следует сразу предупредить, что применение любого из описанных здесь видов тестирования — нелёгкая задача, которая зачастую требует внесения серьёзных изменений в процессы проектирования, разработки и тестирования систем. И, несмотря на заголовок статьи, я не считаю, что какой-либо из видов тестирования в продакшене абсолютно надёжен. Есть лишь мнение, что такое тестирование позволяет значительно снизить уровень рисков в будущем, а вложенные затраты будут обоснованными.
(Прим. пер.: поскольку оригинальная статья — лонгрид, для удобства читателей она разделена на две части).
Зачем нужно тестирование в продакшене, если его можно выполнять на стейджинге?
I«m more and more convinced that staging environments are like mocks — at best a pale imitation of the genuine article and the worst form of confirmation bias.
It«s still better than having nothing — but «works in staging» is only one step better than «works on my machine».
— Cindy Sridharan (@copyconstruct) March 16, 2018
Значение стейджинг-кластера (или стейджинговой среды) разными людьми воспринимается по-разному. Для многих компаний развёртывание и тестирование продукта на стейджинге — неотъемлемый этап, предшествующий его финальному выпуску.
Многие известные организации воспринимают стейджинг как миниатюрную копию рабочей среды. В таких случаях возникает необходимость обеспечивать их максимальную синхронизацию. При этом обычно необходимо обеспечивать работу отличающихся экземпляров stateful-систем, таких как базы данных, и регулярно синхронизировать со стейджингом данные из продакшен-среды. Исключением является только конфиденциальная информация, позволяющая установить личность пользователя (это необходимо для соблюдения требований GDPR, PCI, HIPAA и прочих регламентов).
Проблема этого подхода (по моему опыту) заключается в том, что отличие состоит не только в использовании отдельного экземпляра базы данных, содержащей актуальные данные продакшен-среды. Зачастую отличие распространяется на следующие аспекты:
- Размер стейджинг-кластера (если это можно назвать «кластером» — иногда это просто один сервер под видом кластера);
- Тот факт, что на стейджинге обычно используется кластер гораздо меньшего масштаба, также означает, что параметры конфигурации почти для каждого сервиса будут различаться. Это относится к конфигурациям балансировщиков нагрузки, баз данных и очередей, например, числу дескрипторов открытых файлов, числу открытых подключений к базе данных, размеру пула потоков и пр. Если конфигурация хранится в базе данных или хранилище данных типа «ключ-значение» (например, Zookeeper или Consul), эти вспомогательные системы тоже должны присутствовать в стейджинговой среде;
- Число оперативных подключений, обрабатываемых stateless-службой, или способ повторного использования TCP-соединений прокси-сервером (если эта процедура вообще выполняется);
- Недостаток мониторинга на стейджинге. Но даже если мониторинг осуществляется, некоторые сигналы могут оказаться совершенно неточными, так как отслеживается среда, отличная от рабочей. Например, даже если выполняется мониторинг задержки запроса MySQL или времени отклика, трудно определить, содержит ли новый код запрос, который может инициировать полное сканирование таблицы в MySQL, так как гораздо быстрее (а иногда даже предпочтительнее) выполнить полное сканирование маленькой таблицы, используемой в тестовой базе данных, нежели производственной базы данных, где запрос может иметь совершенно другой профиль производительности.
Хотя справедливо предположить, что все указанные выше отличия не являются серьёзными аргументами против использования стейджинга как такового, в отличие от антипаттернов, которых следует избегать. В то же время стремление всё сделать правильно зачастую требует огромных трудовых затрат инженеров в попытке обеспечить соответствие сред. Продакшен постоянно меняется и подвержен влиянию различных факторов, поэтому попытка достичь указанного соответствия похожа на путь в никуда.
Более того, даже если условия на стейджинге будут максимально похожи на рабочую среду, есть и другие виды тестирования, применять которые лучше на основе реальной производственной информации. Хорошим примером может быть soak-тестирование, при котором надёжность и устойчивость сервиса проверяется в течение продолжительного периода времени при реальных уровнях многозадачности и нагрузки. Оно используется для выявления утечек памяти, определения продолжительности пауз в работе GC, уровня загрузки процессора и прочих показателей за определённый период времени.
Ничто из написанного выше не предполагает, что стейджинг абсолютно бесполезен (это станет очевидно после прочтения раздела, посвящённого теневому дублированию данных при тестировании сервисов). Это лишь свидетельствует о том, что довольно часто на стейджинг полагаются в большей степени, чем это необходимо, и во многих организациях он остаётся единственным видом тестирования, выполняемого до полного выпуска продукта.
Искусство тестирования в продакшене
Так исторически сложилось, что с понятием «тестирование в продакшене» связаны определённые стереотипы и негативные коннотации («партизанское программирование», недостаток или отсутствие юнит- и интеграционного тестирования, небрежность или невнимание к восприятию продукта конечным пользователем).
Тестирование в продакшене, безусловно, будет заслуживать такой репутации, если оно выполняется небрежно и некачественно. Оно ни в коей мере не заменяет тестирования на этапе пре-продакшена и ни при каких условиях не является простой задачей. Более того, я утверждаю, что для успешного и безопасного тестирования в продакшене требуется значительный уровень автоматизации, хорошее понимание сложившихся практик, а также проектирование систем с изначальной ориентацией на этот вид тестирования.
Чтобы организовать комплексный и безопасный процесс эффективного тестирования сервисов в продакшене, важно не расценивать его как обобщающий термин, обозначающий набор разных инструментов и методик. Эта ошибка, к сожалению, была допущена и мной — в моей предыдущей заметке была представлена не совсем научная классификация методов тестирования, а в разделе «Тестирование в продакшене» оказались сгруппированы самые разные методологии и инструменты.

Из заметки Testing Microservices, the sane way («Разумный подход к тестированию микросервисов»)
С момента публикации заметки в конце декабря 2017 года я обсуждала её содержание и вообще тему тестирования в продакшене с несколькими людьми.
В ходе этих дискуссий, а также после ряда отдельных бесед мне стало ясно, что тему тестирования в продакшене нельзя свести к нескольким пунктам, перечисленным выше.
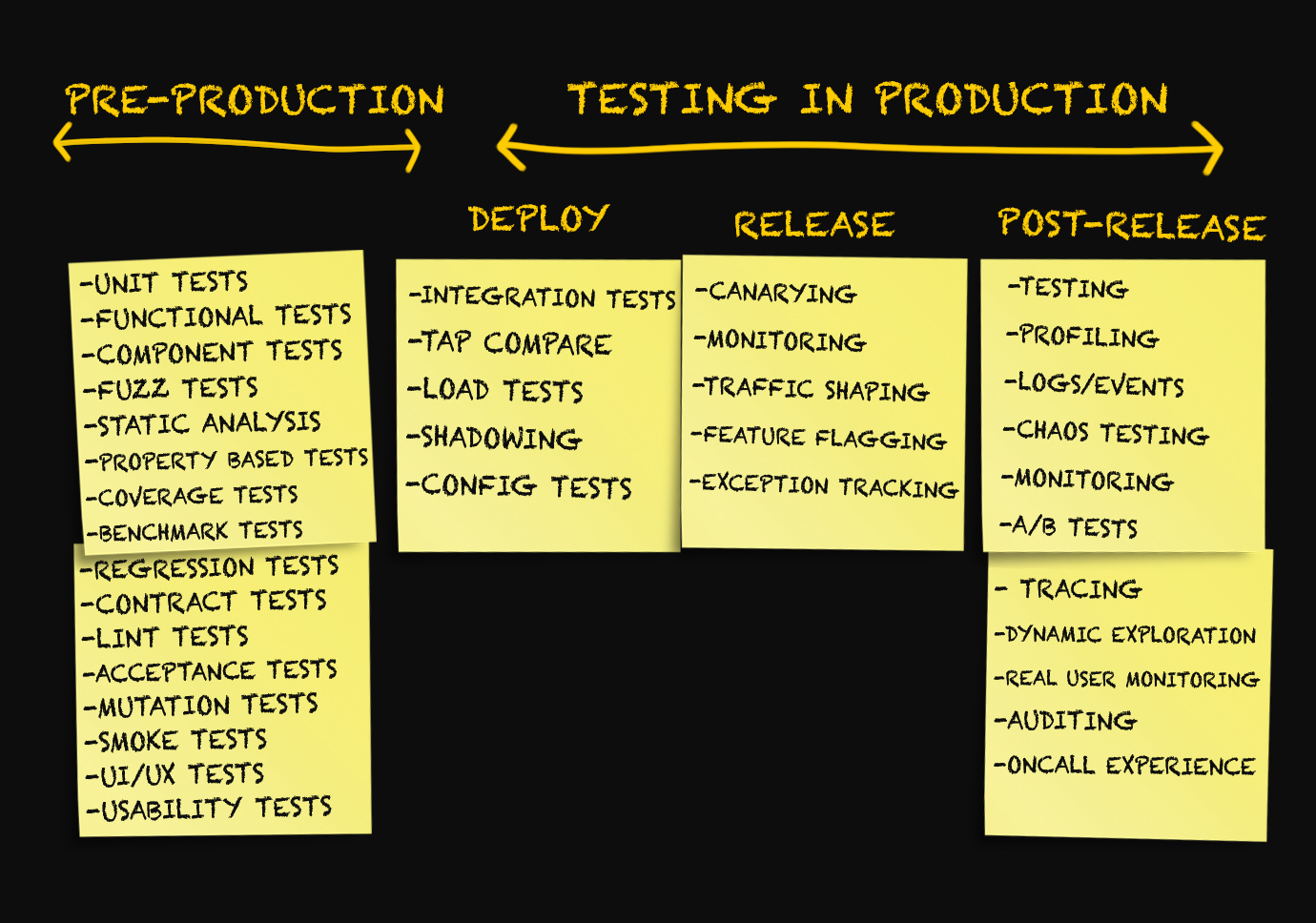
Понятие «тестирование в продакшене» включает в себя целый спектр методик, применяемых на трёх различных этапах. Каких именно — давайте разбираться.
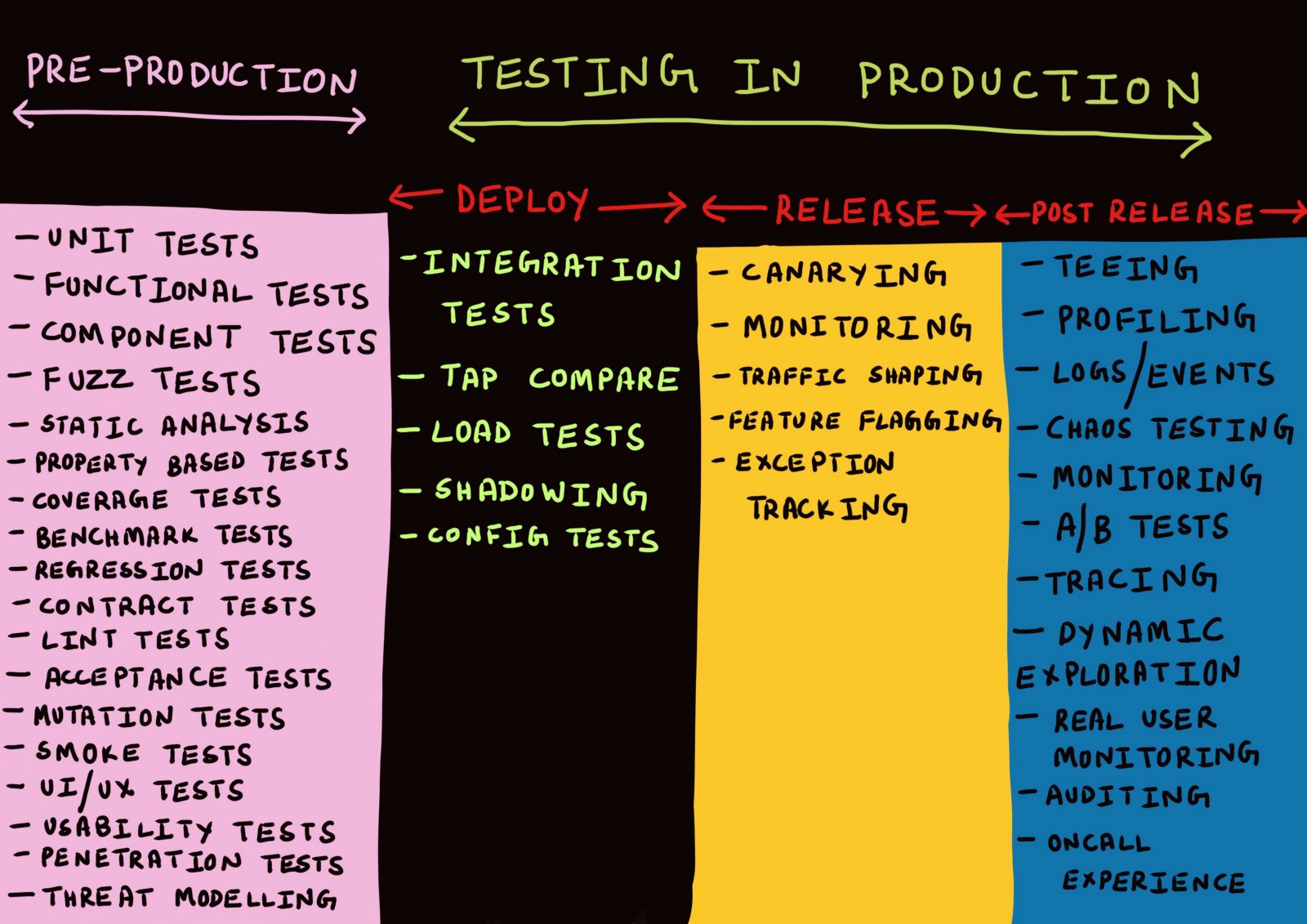
Три стадии продакшена
Обычно дискуссии о продакшене ведутся только в контексте развёртывания кода в продакшен, мониторинга или авральных ситуаций, когда что-то пошло не так.
Я сама до сих пор использовала в качестве синонимов такие термины, как «развёртывание», «релиз», «доставка» и т. д., мало задумываясь об их значении. Ещё несколько месяцев назад все попытки разграничить эти термины были бы отвергнуты мной как что-то несущественное.
Поразмыслив над этим, я пришла к идее, что существует реальная необходимость разграничить различные этапы продакшена.
Этап 1. Развёртывание
Когда тестирование (даже в продакшене) является проверкой достижения наилучших из возможных показателей, точность тестирования (да и вообще любых проверок) обеспечивается лишь при условии, что способ выполнения тестов в максимальной степени схож со способом реального использования сервиса в продакшене.
Другими словами, тесты необходимо выполнять в среде, которая наилучшим образом имитирует рабочую среду.
И наилучшей имитацией рабочей среды является… сама рабочая среда. Для выполнения максимально возможного количества тестов в рабочей среде необходимо, чтобы неудачный результат любого из них не влиял на конечного пользователя.
Это, в свою очередь, возможно, только если при развёртывании сервиса в рабочей среде пользователи не получают непосредственный доступ к этому сервису.
В этой статье я решила использовать терминологию из статьи Deploy!= Release («Развёртывание — не релиз»), написанной сотрудниками компании Turbine Labs. В ней термину «развёртывание» даётся следующее определение:
«Развёртывание — это установка рабочей группой новой версии программного кода сервиса в инфраструктуру продакшена. Когда мы говорим, что новая версия программного обеспечения развёрнута, то имеем в виду, что она выполняется где-то в рамках рабочей инфраструктуры. Это может быть новый экземпляр EC2 в AWS или контейнер Docker, выполняемый в поде в кластере Kubernetes. Сервис успешно запустился, прошёл проверку работоспособности и готов (вы надеетесь!) к обработке данных продакшен-среды, но может не получать данные на самом деле. Это важный момент, я ещё раз подчеркну его: для развёртывания не нужно, чтобы пользователи получали доступ к новой версии вашего сервиса. Если учесть это определение, развёртывание можно назвать процессом с почти нулевым риском».
Слова «процесс с нулевым риском» — просто бальзам на душу множества людей, которые настрадались от неудачных развёртываний. Возможность установки ПО в реальной среде без допуска пользователей к нему несёт ряд преимуществ, когда дело касается тестирования.
Во-первых, сводится к минимуму (а может и совсем исчезнуть) необходимость поддерживать отдельные среды для разработки, тестирования и стейджинга, которые неизбежно приходится синхронизировать с продакшеном.
Кроме того, на этапе проектирования сервисов возникает необходимость изолировать их друг от друга таким образом, чтобы неудачное тестирование конкретного экземпляра сервиса в продакшене не привело к каскадным или затрагивающим пользователей отказам других сервисов. Одним из решений, позволяющих это обеспечить, может быть такое проектирование модели данных и схемы базы данных, при котором неидемпотентные запросы (в основном операции записи) могут:
- Выполняться в отношении базы данных продакшен-среды при любом тестовом запуске сервиса в продакшене (я предпочитаю этот подход);
- Быть безопасно отклонены на уровне приложения до достижения ими уровня записи или сохранения;
- Быть выделены или изолированы на уровне записи или сохранения каким-нибудь способом (например, путём сохранения дополнительных метаданных).
Этап 2. Релиз
В заметке Deploy!= Release термину «релиз» даётся следующее определение:
«Когда мы говорим, что состоялся релиз версии сервиса, то имеем в виду, что она обеспечивает обработку данных в продакшен-среде. Иными словами, релиз — это процесс, направляющий данные продакшен-среды в новую версию ПО. С учётом этого определения все риски, которые мы связываем с отправкой новых потоков данных (перебои в работе, недовольство клиентов, ядовитые заметки в The Register), относятся к релизу нового ПО, а не его развёртыванию (в некоторых компаниях этот этап также называют выпуском. В этой статье мы будем использовать термин релиз)».
В книге Google об SRE термин «выпуск» используется в главе, посвящённой организации релиза ПО, для его описания.
»Выпуск — это логический элемент работы, состоящий из одной или нескольких отдельных задач. Наша цель — согласовать процесс развёртывания с профилем риска данного сервиса.
В окружениях разработки или пре-продакшена мы можем выполнять сборку ежечасно и автоматически рассылать выпуски после прохождения всех тестов. Для крупных сервисов, ориентированных на пользователей, мы можем начать релиз с одного кластера, а затем увеличивать его масштабы, пока не обновим все кластеры. Для важных элементов инфраструктуры мы можем увеличить срок внедрения до нескольких дней и выполнять его по очереди в разных географических регионах».
В данной терминологии слова «релиз» и «выпуск» обозначают то, что в общей лексике понимается под «развёртыванием», а термины, часто используемые для описания различных стратегий развёртывания (например, blue-green развёртывание или канареечное развёртывание), относятся к релизу нового программного обеспечения.
Более того, неудачный релиз приложений может стать причиной частичных или существенных перебоев в работе. На этом этапе также выполняется откат или хотфикс, если выясняется, что выпущенная новая версия сервиса работает нестабильно.
Процесс выпуска лучше всего работает, когда он автоматизирован и выполняется инкрементно. Точно так же откат или хотфикс сервиса приносят больше пользы, когда частота появления ошибок и частота запросов автоматически соотносятся с базовыми показателями.
Этап 3. После релиза
Если релиз прошёл гладко и новая версия сервиса обрабатывает данные продакшен-среды без очевидных проблем, мы можем считать его успешным. За успешным релизом следует этап, который можно назвать «после релиза».
i like thinking of this as the «fourth trimester» — when software leaves its cozy artificial environs and slams into real users, data, and services.
it’s traumatic. but your work as a code-parent ain’t done til it can stand on its own two legs, without your constant support. https://t.co/FnUWou0qoN
— Charity Majors (@mipsytipsy) February 9, 2018
Любая достаточно сложная система всегда будет находиться в состоянии постепенной потери производительности. Это не означает, что обязательно требуется откат или хотфикс. Вместо этого необходимо отслеживать такие ухудшения (для различных операционных и рабочих целей) и при необходимости выполнять отладку. По этой причине тестирование после релиза больше похоже не на привычные процедуры, а на отладку или сбор аналитических данных.
Вообще, я считаю, что каждый компонент системы должен создаваться с учётом того факта, что ни одна крупная система не работает безупречно на все 100% и что сбои в работе должны быть осознаны и учитываться на этапах проектирования, разработки, тестирования, развёртывания и мониторинга программного обеспечения.
Теперь, когда мы определили три этапа продакшена, давайте рассмотрим различные механизмы тестирования, доступные на каждом из них. Не у всех есть возможность работать над новыми проектами или переписывать код с нуля. В этой статье я постаралась чётко выделить методики, которые лучше всего покажут себя при разработке новых проектов, а также рассказать о том, что ещё мы можем сделать, чтобы воспользоваться преимуществами предлагаемых методик, не внося существенных изменений в работающие проекты.
Тестирование в продакшене на этапе развёртывания
Мы отделили друг от друга этапы развёртывания и релиза, а теперь рассмотрим некоторые виды тестирования, которые можно применять после развёртывания кода в продакшен-среде.
Интеграционное тестирование
Обычно интеграционное тестирование выполняется сервером непрерывной интеграции в изолированной тестовой среде для каждой ветки Git. Копия всей топологии сервиса (включая базы данных, очереди, прокси-серверы и т. п.) разворачивается для тестовых наборов всех сервисов, которые будут работать совместно.
Я полагаю, что это не особенно эффективно по нескольким причинам. Прежде всего, тестовую среду, как и стейджинговую, невозможно развернуть так, чтобы она была идентична реальной продакшен-среде, даже если тесты запускаются в том же контейнере Docker, который будет использоваться в продакшене. Это особенно справедливо, когда единственное, что запускается в тестовой среде, — это сами тесты.
Вне зависимости от того, выполняется ли тест как контейнер Docker или процесс POSIX, он, вероятнее всего, осуществляет одно или несколько подключений к вышестоящему сервису, базе данных или кешу, что бывает редко, если сервис находится в продакшен-среде, где он может одновременно обрабатывать несколько параллельных соединений, зачастую повторно используя неактивные TCP-соединения (это называется повторным использованием HTTP-соединений).
Также проблемы вызывает тот факт, что большая часть тестов при каждом запуске создаёт новую таблицу базы данных или пространство ключей кеша на том же узле, где этот тест выполняется (таким образом тесты изолируются от сбоев сети). Этот вид тестирования в лучшем случае может показать, что система работает корректно при очень конкретном запросе. Он редко эффективен при имитации серьёзных, хорошо распространённых видов отказов, не говоря уже о различных видах частичных отказов. Существуют исчерпывающие исследования, подтверждающие, что распределённые системы часто демонстрируют непредсказуемое поведение, которое невозможно предвидеть с помощью анализа, выполняемого иначе, чем для всей системы целиком.
Но это не подразумевает, что интеграционное тестирование в принципе бесполезно. Можно лишь сказать, что выполнение интеграционных тестов в искусственной, полностью изолированной среде, как правило, не имеет смысла. Интеграционное тестирование по-прежнему следует выполнять, чтобы проверить, что новая версия сервиса:
- Не нарушает взаимодействие с вышестоящими или нижестоящими сервисами;
- Не оказывает негативного влияния на цели и задачи вышестоящих или нижестоящих сервисов.
Первое можно в какой-то мере обеспечить с помощью контрактного тестирования. Благодаря одному только обеспечению правильной работы интерфейсов между сервисами контрактное тестирование является эффективным методом разработки и тестирования отдельных сервисов на этапе пре-продакшена, который не требует развёртывания всей топологии сервиса.
Клиентоориентированные платформы тестирования контрактов, например Pact, в настоящее время поддерживают взаимодействие между сервисами только посредством RESTful JSON RPC, хотя, скорее всего, идёт работа и над поддержкой асинхронного взаимодействия через веб-сокеты, внесерверные приложения и очереди сообщений. В будущем, вероятно, добавится поддержка протоколов gRPC и GraphQL, но сейчас она пока отсутствует.
Однако перед релизом новой версии может возникнуть необходимость проверить не только правильную работу интерфейсов. А, например, убедиться, что продолжительность RPC-вызова между двумя сервисами укладывается в допустимый предел при изменении интерфейса между ними. Также необходимо бывает проверить, что коэффициент попадания в кеш остаётся постоянным, например, при добавлении дополнительного параметра во входящий запрос.
Как оказалось, интеграционное тестирование не является опциональным, его цель — гарантировать, что тестируемое изменение не приведёт к серьёзным, широко распространённым видам отказа системы (обычно к таким, для которых назначены алерты).
В связи с этим возникает вопрос: как безопасно провести интеграционное тестирование в продакшене?
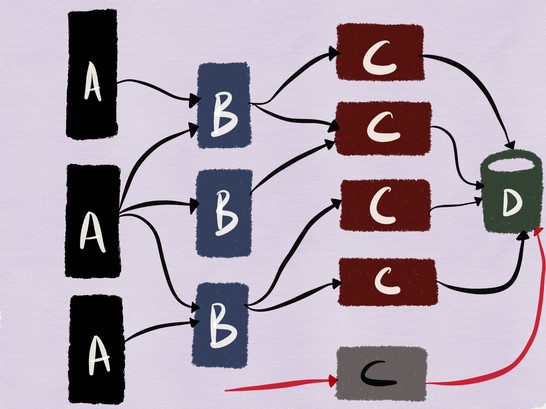
Для этого рассмотрим следующий пример. На рисунке ниже — архитектура, с которой я работала пару лет назад: наши мобильные и веб-клиенты подключались к веб-серверу (сервис C) на базе MySQL (сервис D) с клиентской частью в виде кластера memcache (сервис B).
Несмотря на то, что это довольно традиционная архитектура (и её не назовёшь микросервисной), объединение stateful- и stateless-сервисов делает эту систему хорошим примером для моей статьи.
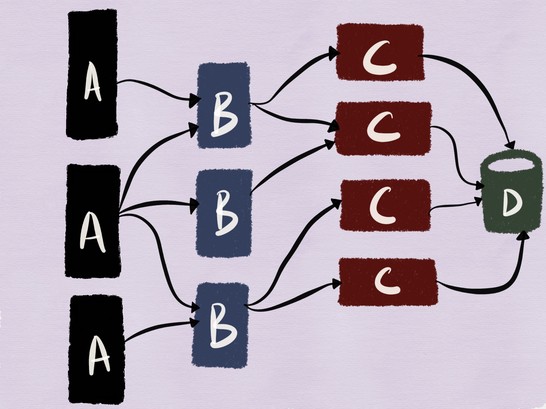
Отделение релиза от развёртывания означает, что мы можем безопасно развернуть новый экземпляр сервиса в рабочей среде.
Современные service discovery утилиты позволяют сервисам с одинаковыми именами получать теги (или метки), с помощью которых можно отличать выпущенную и развёрнутую версию сервиса с одним и тем же именем. Благодаря этой возможности клиенты могут подключаться только к выпущенной версии нужного сервиса.
Предположим, что мы развёртываем новую версию сервиса C в продакшене.
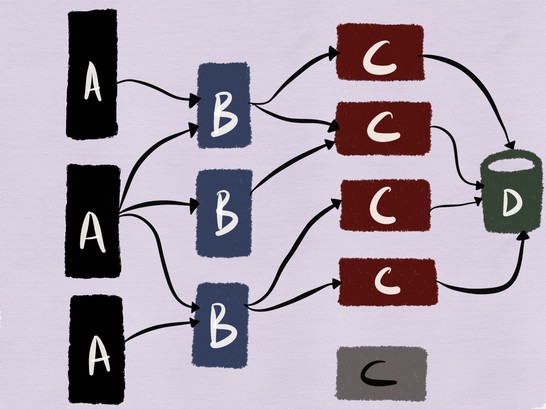
Чтобы проверить, что развёрнутая версия работает правильно, мы должны иметь возможность запустить её и убедиться, что ни один из контрактов не нарушается. Главное преимущество слабосвязанных сервисов в том, что они позволяют рабочим группам заниматься разработкой, развёртыванием и масштабированием независимо друг от друга. Кроме того, обеспечивается возможность независимо выполнять тестирование, что парадоксальным образом применимо и к интеграционному тестированию.
В блоге Google есть статья под названием Just Say No to More End-to-End Tests («Пришла пора отказаться от дополнительного сквозного тестирования»), где интеграционные тесты описываются следующим образом:
»В ходе интеграционного теста небольшой набор модулей (обычно два) тестируется на предмет согласованности их работы. Если два модуля не интегрируются должным образом, зачем писать сквозной тест? Можно написать гораздо меньший по объёму и более узконаправленный интеграционный тест, который может выявить те же ошибки. Хотя в целом следует мыслить шире, нет нужды гнаться за масштабом, когда речь идёт лишь о том, чтобы проверить совместную работу модулей».
Далее говорится о том, что интеграционное тестирование в продакшене должно следовать той же философии: оно должно быть достаточным и очевидно полезным только для комплексной проверки небольших групп модулей. При правильном проектировании все вышестоящие зависимости должны быть в достаточной степени изолированы от тестируемого сервиса, чтобы плохо сформированный запрос от сервиса A не приводил бы к каскадному сбою в архитектуре.
Для нашего примера это означает, что должно выполняться тестирование развёрнутой версии сервиса C и его взаимодействия с MySQL, как показано на рисунке ниже.
Тестирование операций чтения в большинстве случаев должно быть прямолинейным (если только поток данных, читаемых тестируемым сервисом, не приводит к заполнению кеша с его последующим «отравлением» данными, используемыми выпущенными сервисами). При этом тестирование взаимодействия развёрнутого кода с MySQL становится более сложным, если используются неидемпотентные запросы, которые могут привести к изменению данных.
Мой выбор — выполнять интеграционное тестирование с применением базы данных продакшен-среды. Раньше я вела белый список клиентов, которым разрешалось отправлять запросы тестируемому сервису. Некоторые рабочие группы поддерживают специальный набор пользовательских учётных записей для выполнения тестов в продакшен-системе, чтобы любое сопутствующее изменение данных было ограничено небольшой опытной серией.
Но если абсолютно необходимо, чтобы данные продакшен-среды ни при каких условиях не изменялись во время выполнения теста, то операции записи/изменения:
- Необходимо отклонять запросы на уровне приложения C или записывать в другую таблицу/коллекцию в базе данных;
- Необходимо регистрировать в базе данных в виде новой записи, помеченной как «созданная» при выполнении теста.
Если во втором случае необходимо выделить тестовые операции записи на уровне базы данных, то для поддержки этого вида тестирования схему базы данных следует спроектировать заранее (например, добавив дополнительное поле).
В первом случае отклонение операций записи на уровне приложения может происходить, если приложение способно определить, что запрос не следует отрабатывать. Это возможно либо путём проверки IP-адреса клиента, отправляющего тестовый запрос, либо по идентификатору пользователя, содержащемуся во входящем запросе, либо путём проверки запроса на наличие заголовка, который, как ожидается, должен быть задан клиентом, работающим в тестовом режиме.
То, что я предлагаю, похоже на мок или стаб, но на уровне сервиса, и это не слишком далеко от истины. Этому подходу сопутствует изрядное число проблем. В информационной брошюре для Facebook, посвящённой Kraken, говорится следующее:
»Альтернативное проектное решение — это использование теневого потока данных, когда входящий запрос регистрируется и воспроизводится в тестовой среде. В случае веб-сервера большая часть операций имеет побочные эффекты, которые распространяются вглубь системы. Теневые тесты не должны активировать эти побочные эффекты, так как это может повлечь изменения для пользователя. Использование стабов для побочных эффектов в теневом тестировании не только нецелесообразно из-за частого изменения логики работы сервера, но также снижает точность теста, так как не нагружаются зависимости, которые в ином случае подверглись бы воздействию».
Несмотря на то, что новые проекты могут разрабатываться так, чтобы побочные эффекты были сведены к минимуму, предотвращены или даже полностью устранены, применение стабов в готовой инфраструктуре может принести больше проблем, чем пользы.
Сетчатая архитектура сервиса в какой-то мере может помочь с этим. При использовании архитектуры service mesh сервисы ничего не знают о топологии сети и ждут подключений на локальном узле. Всё взаимодействие между сервисами осуществляется через дополнительный прокси-сервер. Если каждый переход между узлами осуществляется через прокси-сервер, то архитектура, описанная выше, будет выглядеть следующим образом:
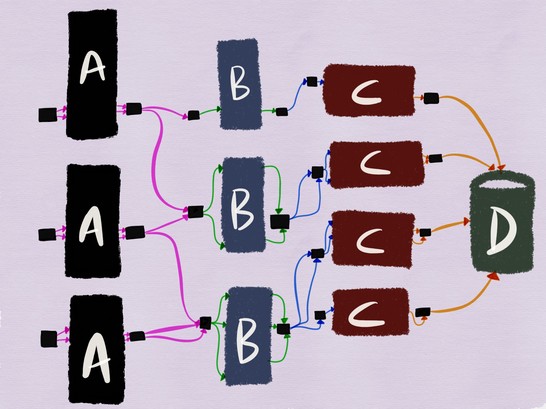
Если мы тестируем сервис B, его исходящий прокси-сервер можно настроить на добавление специального заголовка X-ServiceB-Test в каждый тестовый запрос. При этом входящий прокси-сервер вышестоящего сервиса C сможет:
- Обнаружить этот заголовок и отправить стандартный ответ сервису B;
- Сообщить сервису C, что запрос является тестовым.
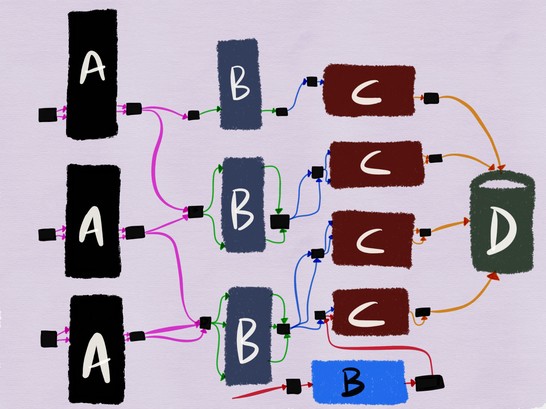
Интеграционное тестирование взаимодействия развёрнутой версии сервиса B с выпущенной версией сервиса C, где операции записи никогда не достигают базы данных
Выполнение интеграционного тестирования таким способом также обеспечивает тестирование взаимодействия сервиса B с вышестоящими сервисами, когда они обрабатывают обычные данные продакшен-среды, — вероятно, это более близкая имитация того, как будет вести себя сервис B при релизе в продакшен.
Также было бы неплохо, если бы каждый сервис в этой архитектуре поддерживал реальные вызовы API в тестовом или макетном режиме, позволяя тестировать выполнение контрактов сервиса с нижестоящими сервисами без изменения реальных данных. Это было бы равноценно контрактному тестированию, но на уровне сети.
Теневое дублирование данных (тестирование тёмного потока данных или зеркалирование)
Теневое дублирование (в статье из блога Google оно называется тёмным запуском, а в Istio применяется термин зеркалирование) во многих случаях имеет больше преимуществ, чем интеграционное тестирование.
В «Принципах хаотичного проектирования» (Principles of Chaos Engineering) говорится следующее:
»Системы ведут себя по-разному в зависимости от среды и схемы передачи данных. Так как режим использования может измениться в любое время, выборка реальных данных является единственным надёжным способом зафиксировать путь запросов».
Теневое дублирование данных представляет собой метод, с помощью которого поток данных продакшен-среды, поступающий в данный сервис, захватывается и воспроизводится в новой развёрнутой версии сервиса. Этот процесс может выполняться либо в режиме реального времени, когда входящий поток данных разделяется и направляется как на выпущенную, так и на развёрнутую версии сервиса, либо асинхронно, когда копия ранее захваченных данных воспроизводится в развёрнутом сервисе.
Когда я работала в imgix (стартап со штатом из 7 инженеров, из которых только четверо были системными инженерами), тёмные потоки данных активно использовались для тестирования изменений в нашей инфраструктуре визуализации изображений. Мы регистрировали определённый процент всех входящих запросов и отправляли их в кластер Kafka — передавали журналы доступа HAProxy на конвейер heka, который в свою очередь передавал проанализированный поток запросов в кластер Kafka. Перед стадией релиза новая версия нашего приложения для обработки изображений тестировалась на захваченном тёмном потоке данных — это позволяло убедиться, что запросы обрабатываются правильно. Однако наша система визуализации изображений была по большому счету stateless-сервисом, который особенно хорошо подходил для этого вида тестирования.
Некоторые компании предпочитают захватывать не часть потока данных, а передавать новой версии приложения полную копию этого потока. Маршрутизатор McRouter компании Facebook (memcached прокси-сервер) поддерживает этот вид теневого дублирования потока memcache-данных.
»Во время тестирования новой инсталляции для кеша мы обнаружили, что очень удобно иметь возможность перенаправлять полную копию потока данных от клиентов. McRouter поддерживает гибкую настройку теневого дублирования. Можно выполнять теневое дублирование пула различных размеров (рехешировав пространство ключей), копировать только часть пространства ключей или динамически менять параметры в процессе работы».
Отрицательный аспект теневого дублирования всего потока данных для развёрнутого сервиса в продакшен-среде заключается в том, что если оно выполняется в момент максимальной интенсивности передачи данных, то для него может понадобиться в два раза большая мощность.
Такие прокси-серверы, как Envoy, поддерживают теневое дублирование потока данных на другой кластер в режиме fire-and-forget. В его документации написано:
»Маршрутизатор может выполнять теневое дублирование потока данных с одного кластера на другой. В настоящий момент реализован режим fire-and-forget, при котором прокси-сервер Envoy не ждёт ответа от теневого кластера перед возвратом ответа от основного кластера. Для теневого кластера собираются все обычные статистические данные, что полезно для целей тестирования. При теневом дублировании в заголовок host/authority добавляется параметр -shadow. Это полезно для ведения журналов. Например, cluster1 превращается в cluster1-shadow».
Однако зачастую нецелесообразно или невозможно создать синхронизированную с продакшеном реплику кластера для тестирования (по той же причине, по которой проблематично организовать синхронизированный стейджинг-кластер). Если теневое дублирование используется для тестирования нового развёрнутого сервиса, имеющего множество зависимостей, оно может инициировать непредусмотренные изменения состояния вышестоящих по отношению к тестируемому сервисов. Теневое дублирование суточного объёма пользовательских регистраций в развёрнутой версии сервиса с записью в производственную базу данных может привести к повышению частоты ошибок до 100% из-за того, что теневой поток данных будет восприниматься как повторные попытки регистрации и отклоняться.
Мои личный опыт говорит о том, что теневое дублирование лучше всего подходит для тестирования неидемпотентных запросов или stateless-сервисов со стабами серверной части. В этом случае теневое дублирование данных чаще применяется для тестирования нагрузки, устойчивости и конфигураций. При этом с помощью интеграционного тестирования или стейджинга можно протестировать, как сервис взаимодействует со stateful-сервером при работе с неидемпотентными запросами.
TAP-сравнение
Единственное упоминание этого термина есть в статье из блога Twitter, посвященной запуску сервисов с высоким уровнем качества предоставления услуг.
«Для проверки правильности новой реализации существующей системы мы использовали метод под названием tap-сравнение. Наш инструмент tap-сравнения воспроизводит образец данных продакшена в новой системе и сравнивает полученные ответы с результатами старой. Полученные результаты помогли нам найти и исправить ошибки в системе ещё до того, как с ними столкнулись конечные пользователи».
В другой статье из блога Twitter даётся такое определение tap-сравнения:
«Отправка запросов в экземпляры сервиса как в продакшен-, так и в стейджинг-средах с проверкой правильности результатов и оценкой характеристик производительности».
Различие между tap-сравнением и теневым дублированием заключается в том, что в первом случае ответ, возвращаемый выпущенной версией, сравнивается с ответом, возвращаемым развёрнутой версией, а во втором — запрос дублируется в развёрнутую версию в автономном режиме по типу fire-and-forget.
Ещё один инструмент для работы в этой области — библиотека scientist, доступная на GitHub. Этот инструмент был разработан для тестирования кода на языке Ruby, но затем был портирован на несколько других языков. Он полезен для некоторых видов тестирования, но имеет ряд нер
