[Перевод] Краткое руководство по работе с данными с помощью Miller

Привет, друзья!
Представляю вашему вниманию перевод этой замечательной статьи, в которой рассказывается о Miller — автономном, легковесном и мощном интерфейсе командной строки (Command Line Interface, CLI) для работы с данными в форматах CSV, JSON и некоторых других.
Интересно? Тогда прошу под кат.
Установка
- Linux:
apt-get install miller - macOS:
brew install miller - Windows:
choco install miller
Для того, чтобы убедиться в корректной установке Miller, открываем терминал и выполняем следующую команду:
mlr --versionРезультат:
Команда для получения помощи (списка доступных команд):
mlr help topicsСигнатура команды
Сигнатура команды Miller выглядит следующим образом:
mlr [input/output file formats] [verbs] [file]
# например
mlr --csv filter '$color != "red"' example.csvЗдесь:
--csvопределяет, что форматом входного (обрабатываемого) файла является CSV;filterопределяет операцию, выполняемую с файлом (глагол — verb). В данном случае мы удаляем строки, которые не содержат поляcolorсо значениемred. Существуют и другие глаголы, например,sortиcut(см. ниже);example.csvопределяет обрабатываемый файл.
Обзор операций
Данные
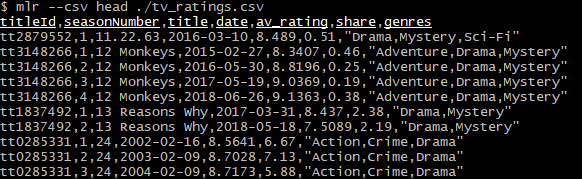
Скачиваем Рейтинг IMDb американских сериалов.
Глагол head позволяет получить первые 10 строк файла:
mlr ---csv head ./tv_ratings.csvРезультат:
Для форматирования вывода используется флаг --opprint:
mlr --csv --opprint head ./tv_ratings.csvРезультат:

Флаг --c2p является сокращением для флагов --csv --opprint.
Цепочка команд
Ключевое слово then позволяет объединять глаголы в цепочку, т.е. выполнять несколько операций за один раз (см. ниже).
Удаление колонок
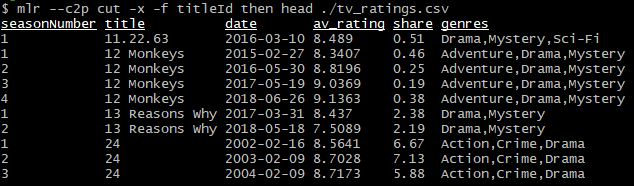
Колонка titleId не несет никакой смысловой нагрузки. Удалим ее с помощью глагола cut:
mlr --c2p cut -x -f titleId then head ./tv_ratings.csvЗдесь:
-fопределяет удаляемые поля (перечисляются через запятую);-xопределяет, что удаляемые поля исключаются из вывода, а не включаются в него (поведение по умолчанию).
Результат:
Фильтрация
Для фильтрации полей используется глагол filter. Получим первые 10 (по порядку в файле) серий первого сезона:
mlr --c2p filter '$seasonNumber == 1' then head ./tv_ratings.csvРезультат:

Сортировка
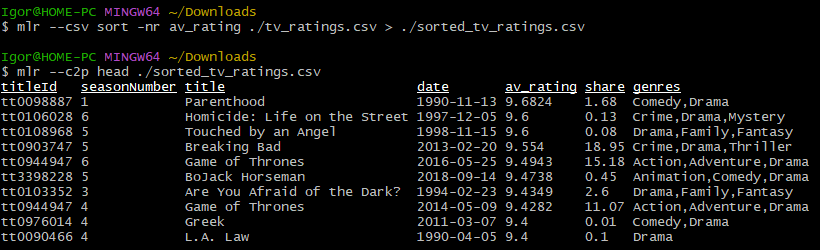
Для сортировки полей используется глагол sort. Получим первые 10 серий с самыми высокими рейтингами:
mlr --c2p sort -nr av_rating then head ./tv_ratings.csvЗдесь:
-nrопределяет числовой нисходящий (от большего к меньшему) порядок сортировки (нули сортируются первыми).
Результат:

Сохранение результата операций
Оператор > позволяет выполнять запись результата операций в файл:
mlr --csv sort -nr av_rating ./tv_ratings.csv > ./sorted_tv_ratings.csvРезультат:
Преобразование CSV в JSON
Для преобразования CSV в JSON используется флаг --c2j:
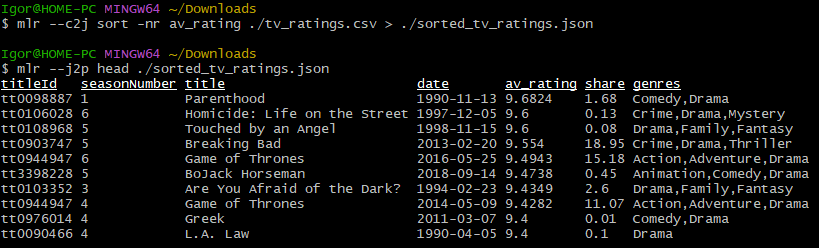
mlr --c2j sort -nr av_rating ./tv_ratings.csv > ./sorted_tv_ratings.jsonРезультат:
Задача
Рассмотрим пример практического использования Miller — получение списка 5 спортсменов, завоевавших наибольшее количество медалей на олимпиаде в Рио-де-Жанейро в 2016 году.
Скачиваем этот файл в формате CSV.
Взглянем на него:
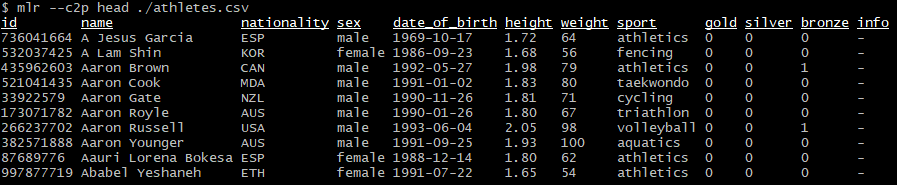
mlr --c2p head ./athletes.csvРезультат:
Удаляем лишние поля:
mlr --csv -I cut -x -f id,info,weight,height,date_of_birth ./athletes.csvЗдесь:
-Iозначает, что файл обрабатывается на месте, т.е. сначала создается временный файл, в который записывается результат операций, затем оригинальный файл перезаписывается временным.
Прим. пер.: я не буду перезаписывать оригинальный файл, а запишу результат операции в файл athletes_formatted.csv с помощью следующей команды:
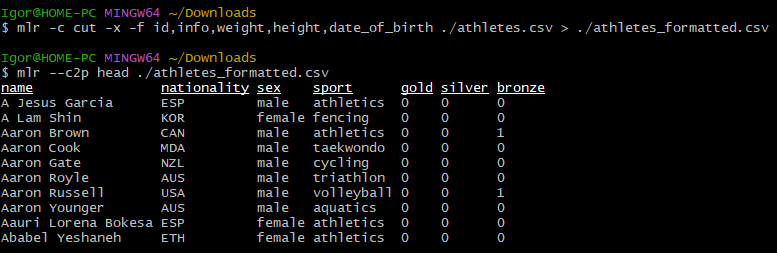
mlr -c cut -x -f id,info,weight,height,date_of_birth ./athletes.csv > ./athletes_formatted.csvЗдесь:
-c— это сокращение для--csv.
Результат:
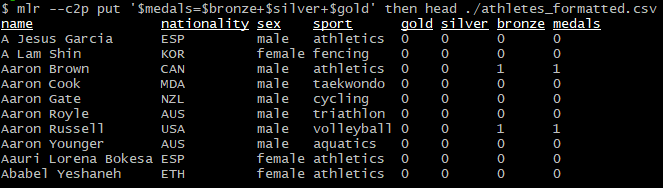
У нас имеется статистика по количеству золотых, серебряных и бронзовых медалей. Общее количество медалей можно вычислить с помощью глагола put следующим образом:
mlr --c2p put '$medals=$bronze+$silver+$gold' then head ./athletes_formatted.csvРезультат:
Сортируем список по количеству медалей от большего с меньшему:
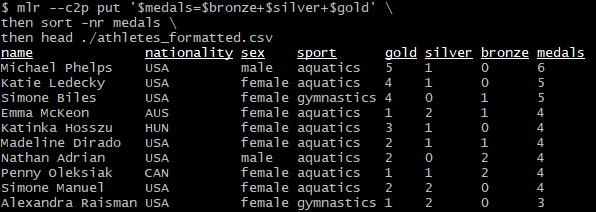
mlr --c2p put '$medals=$bronze+$silver+$gold' \
then sort -nr medals \
then head ./athletes_formatted.csvРезультат:
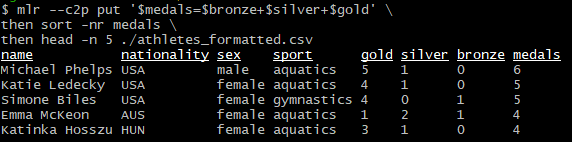
Ограничиваем вывод пятью спортсменами с помощью флага -n:
mlr --c2p put '$medals=$bronze+$silver+$gold' \
then sort -nr medals \
then head -n 5 ./athletes_formatted.csvРезультат:
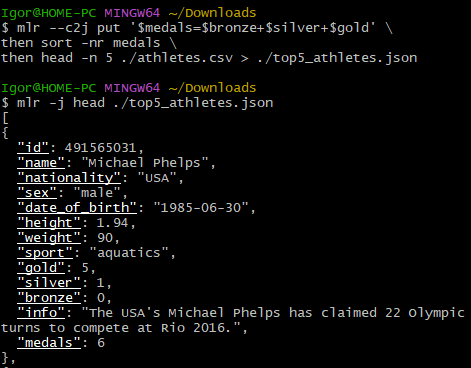
Записываем результат в JSON-файл:
mlr --c2j put '$medals=$bronze+$silver+$gold' \
then sort -nr medals \
then head -n 5 ./athletes.csv > ./top5_athletes.jsonРезультат:
Здесь:
-j— это сокращение для--json
Что если мы хотим получить пятерку лучших атлетов среди женщин? Проще простого:
mlr --c2p put '$medals=$bronze+$silver+$gold' \
then sort -nr medals \
then filter '$sex == "female"' \
then head -n 5 ./athletes_formatted.csvРезультат:

Надеюсь, что вы, как и я, узнали что-то новое и не зря потратили время.
Благодарю за внимание и happy coding!

