[Перевод] Как мы масштабировали Nginx и ежедневно экономим миру 54 года ожидания
«Команда @Cloudflare только что внесла изменения, которые значительно улучшили производительность нашей сети, особенно для самых медленных запросов. Насколько стало быстрее? Мы оцениваем, что экономим интернету примерно 54 года времени в день, которое иначе было бы потрачено на ожидание загрузки сайтов». — твит Мэтью Принса, 28 июня 2018 года
10 миллионов сайтов, приложений и API используют Cloudflare, чтобы ускорить загрузку контента для пользователей. В пике мы обрабатываем более 10 миллионов запросов в секунду в 151 дата-центре. За годы мы внесли много изменений в нашу версию Nginx, чтобы справиться с ростом. Эта статья об одном из таких изменений.
Nginx — одна из программ, которая использует циклы обработки событий для решения проблемы C10K. Каждый раз при поступлении сетевого события (новое соединение, запрос или уведомление на отправку большего объёма данных и т.д.) Nginx просыпается, обрабатывает событие, а затем возвращается к другой работе (это может быть обработка других событий). Когда поступает событие, данные для него уже готовы, что позволяет эффективно обрабатывать много одновременных запросов без простоев.
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
// handle event[1]: send out response to GET http://cloudflare.com/
Например, вот как может выглядеть фрагмент кода для чтения данных из файлового дескриптора:
// we got a read event on fd
while (buf_len > 0) {
ssize_t n = read(fd, buf, buf_len);
if (n < 0) {
if (errno == EWOULDBLOCK || errno == EAGAIN) {
// try later when we get a read event again
}
if (errno == EINTR) {
continue;
}
return total;
}
buf_len -= n;
buf += n;
total += n;
}
Если fd — это сетевой сокет, то будут возвращены уже полученные байты. Последний вызов вернёт EWOULDBLOCK. Это значит, что закончился локальный буфер чтения и не следует больше читать из этого сокета, пока не появятся данные.
Если fd — обычный файл в Linux, то EWOULDBLOCK и EAGAIN никогда не появляются, а операция чтения всегда ожидает чтения всего буфера, даже если файл открывается с помощью O_NONBLOCK. Как написано в руководстве open (2):
Обратите внимание, что этот флаг не действует для обычных файлов и блочных устройств.
Другими словами, приведённый выше код по сути сокращается до такого:
if (read(fd, buf, buf_len) > 0) {
return buf_len;
}
Если обработчику требуется чтение с диска, то он блокирует цикл обработки событий до завершения чтения, а последующие обработчики событий ждут.
Это нормально для большинства задач, поскольку чтение с диска обычно выполняется достаточно быстро и гораздо более предсказуемо по сравнению с ожиданием пакета из сети. Особенно теперь, когда SSD стоит у каждого, а все наши кэши на SSD. В современных SSD очень маленькая задержка, как правило, в десятки микросекунд. Кроме того, можно запускать Nginx с несколькими рабочими процессами, чтобы медленный обработчик событий не блокировал запросы в других процессах. Большую часть времени можно положиться на Nginx для быстрой и эффективной обработки запросов.
Как вы могли догадаться, эти радужные предположения не всегда верны. Если каждое чтение всегда занимает 50 мкс, то чтение 0,19 МБ в блоках по 4 КБ (а мы читаем ещё бóльшими блоками) займёт всего 2 мс. Но тесты показали, что время до первого байта иногда намного хуже, особенно в 99-м и 999-м процентиле. Другими словами, самое медленное чтение из каждых 100 (или 1000) чтений часто занимает гораздо больше времени.
Твёрдотельные накопители очень быстры, но известны своей сложностью. У них внутри компьютеры, которые ставят в очередь и переупорядочивают ввод-вывод, а также выполняют различные фоновые задачи, такие как сборка мусора и дефрагментация. Время от времени запросы заметно замедляются. Мой коллега Иван Бобров запустил несколько бенчмарков ввода/вывода и зарегистрировал задержки на чтение до 1 секунды. Более того, в некоторых из наших SSD больше таких всплесков производительности, чем в других. В будущем мы собираемся учитывать этот показатель при покупке SSD, но сейчас нужно разработать решение для существующего оборудования.
Трудно избежать одного медленного отклика на 1000 запросов, но чего мы на самом деле не хотим — так это блокировки остальных 1000 запросов на целую секунду. Концептуально Nginx способен обрабатывать много запросов параллельно, но запускает только 1 обработчик событий за один раз. Поэтому я добавил специальную метрику:
gettimeofday(&start, NULL);
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
gettimeofday(&event_start_handle, NULL);
// handle event[1]: send out response to GET http://cloudflare.com/
timersub(&event_start_handle, &start, &event_loop_blocked);
99-й процентиль (p99) event_loop_blocked превысил 50% нашего TTFB. Иными словами, половина времени при обслуживании запроса — результат блокировки цикла обработки событий другими запросами. event_loop_blocked измеряет только половину блокировки (потому что отложенные вызовы epoll_wait() не измеряются), так что фактическое соотношение заблокированного времени гораздо выше.
Каждая из наших машин запускает Nginx с 15 рабочими процессами, то есть один медленный I/O заблокирует не более 6% запросов. Но события распределены неравномерно: главный воркер получает 11% запросов.
SO_REUSEPORT может решить проблему неравномерного распределения. Марек Майковский ранее писал о недостатке такого подхода в контексте других инстансов Nginx, но здесь это можно в основном игнорировать: апстрим-соединения в кэше долговечные, поэтому можно пренебречь небольшим увеличением задержки при открытии соединения. Одно это изменение конфигурации с активацией SO_REUSEPORT улучшило пиковый p99 на 33%.
Решение проблемы — сделать read () не блокируемым. На самом деле эта функция реализована в обычном Nginx! При использовании следующей конфигурации read () и write () выполняются в пуле потоков и не блокируют цикл обработки событий:
aio threads;
aio_write on;
Но мы протестировали такую конфигурацию и вместо улучшения времени отклика в 33 раза заметили лишь небольшое изменение p99, разница в пределах погрешности. Результат нас весьма обескуражил, так что мы на время отложили этот вариант.
Есть несколько причин, почему у нас не произошло значительных улучшений, как у разработчиков Nginx. Они в тесте использовали 200 одновременных подключений для запросов файлов по 4 МБ на HDD. На винчестерах гораздо больше задержки I/O, так что оптимизация имела больший эффект.
Кроме того, мы главным образом озабочены производительностью p99 (и p999). Оптимизация средней задержки не обязательно решает проблему пиковых выбросов.
Наконец, в нашей среде типичные размеры файлов намного меньше. 90% наших попаданий в кэш — файлы менее 60 КБ. Чем меньше файлы, тем меньше случаев блокировки (обычно мы считываем весь файл за два чтения).
Посмотрим на дисковый I/O при попадании в кэш:
// мы получили запрос на https://example.com с ключом кэша 0xCAFEBEEF
fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY);
// чтение метаданных до 32 КБ и заголовков
// производится в пуле потоков, если "aio threads" включен
read(fd, buf, 32*1024);
Не всегда считывается 32 КБ. Если заголовки маленькие, то нужно прочитать только 4 КБ (мы не используем I/O напрямую, так что ядро округляет до 4 КБ). open() кажется безобидным, но на самом деле отнимает ресурсы. Как минимум ядро должно проверить, существует ли файл и есть ли у вызывающего процесса разрешение на его открытие. Ему нужно найти inode для /cache/prefix/dir/EF/BE/CAFEBEEF, а для этого придётся искать CAFEBEEF в /cache/prefix/dir/EF/BE/. Короче говоря, в худшем случае ядро выполняет такой поиск:
/cache
/cache/prefix
/cache/prefix/dir
/cache/prefix/dir/EF
/cache/prefix/dir/EF/BE
/cache/prefix/dir/EF/BE/CAFEBEEF
Это 6 отдельных чтений, которые производит open(), по сравнению с 1 чтением read()! К счастью, в большинстве случаев поиск попадает в dentry-кэш и не доходит до SSD. Но ясно, что обработка read() в пуле потоков — это лишь половина картины.
Поэтому мы внесли изменение в Nginx, чтобы open() по большей части выполнялся внутри пула потоков и не блокировал цикл обработки событий. И вот результат от неблокирующих open () и read () одновременно:
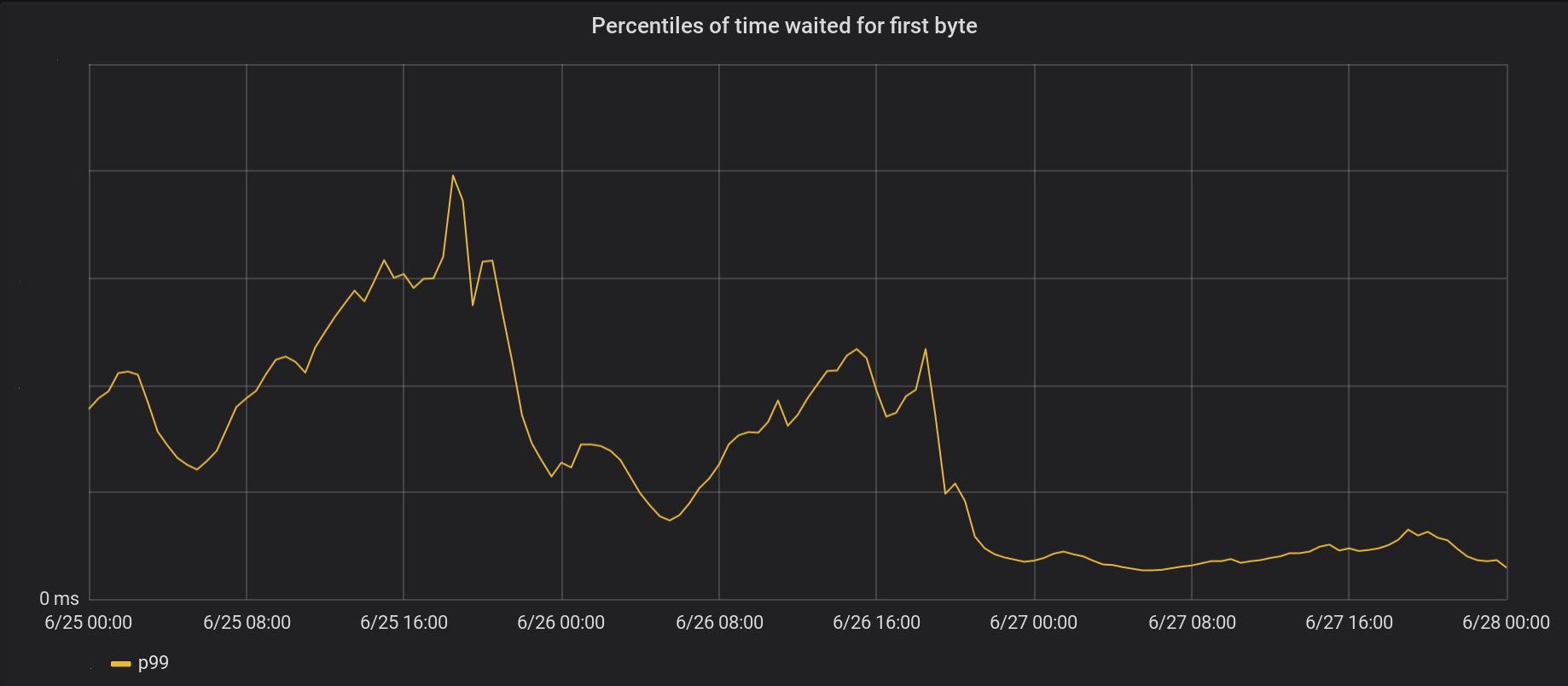
26 июня мы накатили изменения на 5 самых загруженных дата-центров, а на следующий день — на все остальные 146 дата-центров во всём мире. Общее пиковое p99 TTFB уменьшилось в 6 раз. Фактически, если суммировать всё время от обработки 8 миллионов запросов в секунду, то мы экономим интернету 54 года ожидания каждый день.
Наш цикл событий еще не полностью избавился от блокировок. В частности, блокировка по-прежнему происходит при первом кэшировании файла (и open(O_CREAT), и rename()) или при обновлении ревалидации. Но такие случаи редки по сравнению с обращениями к кэшу. В будущем мы рассмотрим возможность выноса этих элементов за пределы цикла обработки событий для дальнейшего улучшения показателя задержки p99.
Nginx — мощная платформа, но масштабирование чрезвычайно высоких нагрузок ввода/вывода на Linux может быть сложной задачей. Стандартный Nginx разгружает чтение в отдельных потоках, но в нашем масштабе часто нужно пойти на шаг дальше.
