[Перевод] Файловая система и Hadoop: Опыт Twitter (Часть 1)
Примечание переводчика:В нашем блоге мы много пишем о построении облачного сервиса 1cloud, но немало интересного можно почерпнуть и из опыта по работе с инфраструктурой других компаний. Сегодня мы представляем вашему вниманию первую часть адаптированного перевода заметки инженерной команды Twitter о создании файловой системы для работы с кластерами Hadoop.

Twitter использует множество крупных кластеров Hadoop, которые являются одними из самых крупных в мире. Hadoop формирует ядро платформы работы с данных сервиса микроблогов и обеспечивает объёмное хранилище аналитической информации о действиях пользователей Twitter. В сегодняшнем материале мы расскажем о работе с ViewFs, client-side файловой системой Hadoop.
ViewFS облегчает взаимодействие компонентов HDFS-инфраструктуры Twitter, формируя единое пространство имен, охватывающее все дата-центры и кластеры. Масштабировать файловую систему помогает HDFS Federation, а NameNode High Availability помогает повысить надежность внутри пространства имен. Совместное использование этих функций вносит значительную сложность в процесс управления и использования нескольких Hadoop-кластеров различных версии. VewFS позволяет инженерам Twitter помнить сложные URI, вместо этого используются простые обозначения путей.
При масштабе Twitter, конфигурирование ViewFs само по себе является сложной задачей, поэтому специалисты компании разработали собственную версию файловой системы — TwitterViewFs. Она динамически генерирует новую конфигурацию, что позволяет добиваться целостного взгляда на состояние файловой системы.
Hadoop и Twitter: масштабируемость и совместимость
Файловые системы Hadoop, использующиеся в Twitter, хранят больше 300 петабайт данных, которые расположены на десятках тысяч серверов. Инженерная команда сервиса масштабирует HDFS с помощью федерализации многочисленных пространств имен. Этот подход позволяет поддерживать большой HDFS-объект без необходимости использования большой кучи Java, которая бы страдала от длинных GS-пауз и невозможности использования сжатых обычных указателей на объект (ordinary object pointer, oop).
Данный подход хорош для масштабирования, но его сложно использовать, поскольку у каждого члена пространства имен в федерации есть свой собственный URI. Команда Twitter использует ViewFs для создания иллюзии единого пространства имен внутри одного кластера. График ниже показывает, что под одним логическим URI инженеры создают монтированную таблицу ViewFs со ссылками на точки в пространстве имен, подходящие для путей, которые начинаются с /user, /tmp, and /logs,
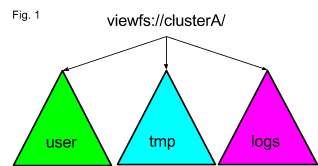
Конфигурация представления, показанная на графике, транслируется в длинную конфигурацию таблицы монтирования (mount table) под названием clusterA. Логически о ней можно думать, как о наборе символических ссылок. Такие ссылки сокращаются просто как /logs->hdfs://logNameSpace/logs. По ссылке представлена более подробная информация о расширении TwitterViewFs, которое обрабатывает URI и hdfs://, и viewfs:// на стороне клиента, чтобы поддерживать работу сотен Hadoop 1-приложений без изменения кода.
Клиентские и серверные узлы Hadoop в Twitter хранят конфигурации всех кластеров. Инженеры компании не используют команду hadoop напрямую. Вместо этого они применяют мультиверсионный враппер hadoop, который обращается к разных установкам Hadoop на основе маппинга из конфигурационной директории к подходящей версии. Конфигурация кластера C хранится в дата-центре DC, сокращенно C@DC в локальной директории /etc/hadoop/hadoop-conf-C-DC, также создается симлинк на главную конфигурационную директорию для данного узла: /etc/hadoop/conf.
Рассмотрим DistCP от источника к пункту назначения. Если Hadoop 2 — это конечный кластер (в ходе миграции так часто и бывает), то ссылаться на начальный кластер нужно через read-only Hftp вне зависимости от версии кластера. В случае исходника Hadoop 1, Hftp используется, поскольку клиент Hadoop 1 не совместим с помощью проводов с Hadoop 2 (wire-compatible). В случае источника Hadoop 2, Hftp используется из-за отсутствия HDFS URI, которое влечет федерализация. Более того, в случае DistCp необходимо использовать конфигурацию конечного кластера для отправки задачи (job). Однако конечная конфигурация не содержит информацию о HA и федерации на стороне начального кластера.
Предыдущиее решение Twitter включало реализацию серии редиректов на правильный NameNode, чего недостаточно для покрытия всех сценариев, которые могут возникнуть при использовании системы в продакшене. Поэтому сейчас все кластерные конфигурации «мержатся» на стороне клиента, чтобы создать одну валидную конфигурацию для HDFS HA и ViewFs для всех дата-центров Twitter. Подробнее об этом ниже.
«Дружелюбные» пути вместо длинных URI
Инженеры Twitter разработали user-friendly пути вместо длинных идентификаторов ресурса (URI) и организовали нативный доступ к HDFS. Это решение позволило избавиться от огромного количества разных URI и значительно повысить доступность данных. При использовании мультикластерных приложений, нужно справляться с полноразмерными URI, которые могут содержать длинную авторизационную часть, представленную NameNode CNAME.
Кроме того, если смешанный кластер включает несовметсимые друг с другом Hadoop 1 и Hadoop 2, необходимо запоминать, к какому кластеру обращаться через совместимым URI Hftp файловой системы. Количество сложностей, которые эта схема вызывала у сотрудников Twitter, побудила инженеров решить эту проблему на стороне Hadoop 2. Стало понятно, что поскольку в системе разные пространства имен уже представляются в качестве единого вида внутри кластера, стоит сделать то же самое со всеми кластерами внутри дата-центра или даже в разных дата-центрах. Идея заключается в том, что путь /path/file в кластере C1 в дата-центре DC1 должен быть смонтирован ViewFs в каждый кластер в качестве /DC1/C1/path/file, как показано на граифке ниже. Благодаря этому никогда не нужно будет указывать полный URI или помнить нужна ли Hftp, поскольку можно будет прозрачно ссылаться через Hftp внутри ViewFs:
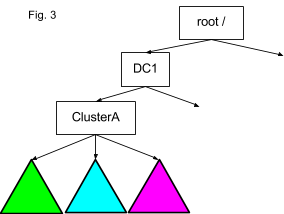
Растущее количество кластеров и числа пространств имен внутри каждого кластера сделало бы очень трудной ручную поддержку отдельных монтировочных таблиц в каждом кластерной конфигурации, что привело бы к проблеме O(n2). Другими словами, если изменить конфигурацию только одного кластера, нужно было бы затронуть все n кластерных конфигураций только для ViewFs. Также нужо поддерживать конфигурацию HDFS-клиента для служб имен, иначе DFSClient не сможет разрешить URI точек монтирования.
Распространена практика, при которой существует один логический кластер в разных дата-центрах для задач балансировки нагрузки и доступности: C1@DC1, C1@DC2 и т.д. Поэтому инженеры Twitter решили добавить в TwitterViewFs новую функциональность. Вместо заполнения конфигураций административными методами, специальный код при автоматической инициализации файловой системы добавляет ключи конфигураций, которые нужны для поддержания глобального взгляда, охватывающего все дата-центры. По-умолчанию файловая система сканирует file:/etc/hadoop/hadoop-conf-*.
Пространство имен TwitterViewFs конструируется за несколько шагов. Когда Hadoop-клиент начинает работу с конкретной конфигурационной директории кластера C-DC, в ходе инициализации TwitterViewFs из других C’-DC’ директорий добавляются следующие ключи:
- Если в C’-DC’ есть ViewFs монтировочная ссылка вида /path->hdfs://nameservice/path, то добавляется ссылка /DC’/C’/path->hdfs://nameservice/path. Для первого графика, представленного выше, для всех конфигураций добавилось бы: /dc/a/user=hdfs://dc-A-user-ns/user.
- Аналогично, для поддержания целостности, все обычные ссылки /path->hdfs://nameservice/path для C-DC дублируются для C-DC as /DC/C/path->hdfs://nameservice/path. Это позволяет использовать одну нотацию вне зависимости от того, идет ли работы с кластером C-DC по умолчанию или удаленным кластером.
- Также можно легко узнать, является ли C’-DC’ конфигурацию, которую предстоит динамически слить, является наследуемым кластером Hadoop 1. Для Hadoop 1 ключ fs.defaultFS указывает на hdfs:// URI, а для Hadoop 2 он указывает на viewfs:// URI. Кластеры Twitte Hadoop 1 состоят из единого именного пространства namespace/NameNode, так что можно прозрачно заменить hftp-схему для схемы hdfs и просто добавить ссылку: /DC/C’/->hftp://hadoop1nn/
Теперь пространство имен TwitterViewFs определено. Однако на это стадии DFSClient еще не может использовать ссылки ViewFs, указывающие на имена сервисов hdfs. Чтобы сделать возможным разрешение URI служб имен HA, нужно слить соответствующую конфигурацию HDFS-клиента из всех файлов hdfs-site.xml в директориях C'-DC'. Вот как это можно сделать:
- HDFS использует ключ dfs.nameservices для хранения разделенного запятыми списка всех служб имен, которые DFSClient должен разрешить. Нужно добавить значения всех C’-DC’ к значению dfs.nameservices текущего кластера. Обычно в кластере 3-4 пространства имен.
- Все относящиеся к конкретному пространству имен параметры HDFS содержатся в его суффиксе. Имена пространств имен в Twitter уникальны и достаточно мнемоничны для того, чтобы хватало простого эвристического копирования все пар ключ-значение из C’-DC’, где название ключа начинается с “dfs” и содержит одну из служб имен из Шага А.
Теперь есть работающая TiwtterViewFs, где все кластеры достижимы через принятый путь /DC/C/path вне зависимости от того, является ли конкретная C кластером Hadoop 1 или Hadoop 2. Мощный пример этой схемы заключается в проверке доли домашних директорий во всех кластерах с помощью одной команды: hadoop fs -count ‘/{dc1,dc2}/*/user/gera’
Также можно запустить fsck на любом из пространств имен без необходимости запоминать конкретный сложный URI: hadoop fsck /dc1/c1/user/gera
Работа с локальной файловой системой и HDFS должна осуществляться похожим образом. Гораздо проще запомнить привычные команды вроде cp чем сложные инструкции «синтаксического сахара» вроде copyFrom/ToLocal, put, get и т.п. Обычная команда hadoop cp требует полный file:/// URI, что и призваны облегчить сложные команды синтаксического сахара. При монтировании через ViewFs это не нужно. Аналогично тому, как осуществлялось добавление ссылок ViewFs в кластер /DC/cluster, происходит добавление ссылок ViewFs в конфигурацию TwitterViewFs:
/local/user/<user>->file:/home/<user>/local/tmp->file:/${hadoop.tmp.dir}
Затем, копирование файла из кластера в локальную директорию будет выглядеть так:
hadoop fs -cp /user/laurent/debug.log /local/user/laurent/
Такой простой и уницфицированный подход к работе с фрагментированными пространствами имен Hadoop понравился внетренним пользователям и вызвал определенный интерес в экспертных кругах.
Продолжение следует….
