[Перевод] Чему робототехника может научить игровой ИИ
Я исследователь-робототехник и в то же время моё хобби — разработка игр. Моя специализация — планирование многомерного движения манипуляторов роботов. Планирование движения — это очень важная тема для разработчиков игр, она пригождается каждый раз, когда нужно переместить управляемого ИИ персонажа из одной точки в другую.
В процессе изучения разработки игр я находил множество туториалов, в которых рассказывалось о планировании движения (обычно в литературе по разработке игр оно называется «поиском пути»), но большинство из них не вдавалось в подробности того, в чём заключается планирование движения с теоретической точки зрения. Насколько я могу судить, в большинстве игр редко используется какое-то иное планирование движения, кроме одного из трёх серьёзных алгоритмов: поиск по сеткам A*, графы видимости и поля течения. Кроме этих трёх принципов, существует ещё целый мир теоретических исследований планирования движения, и некоторые из них могут быть полезными разработчикам игр.
В этой статье я хотел бы рассказать о стандартных техниках планирования движения в своём контексте и объяснить их преимущества и недостатки. Также я хочу представить основные техники, которые обычно не используются в видеоиграх. Надеюсь, они прольют свет на то, как их можно применять в разработке игр.
Движение из точки A в точку B: агенты и цели
Давайте начнём с того, что у нас в игре есть управляемый ИИ персонаж, например, враг в шутере или юнит в стратегической игре. Мы будем называть этого персонажа агентом (Agent). Агент находится в определённом месте мира, называемом его «конфигурацией». В двух измерениях конфигурацию агента можно представить всего двумя числами (обычно x и y). Агент хочет добраться до какого-то другого места мира, которое мы будем называть целью (Goal).
Давайте представим агента в виде круга, живущего в плоском двухмерном мире. Предположим, что агент может перемещаться в любом нужном ему направлении. Если между агентом и его целью нет ничего, кроме пустого пространства, то агент может просто двигаться по прямой линии из своей текущей конфигурации к цели. Когда он достигает цели, то останавливается. Мы можем назвать это «алгоритмом Walk To».
Алгоритм: WALK TO
Если не цель:Двигаться к цели.
Иначе: Остановиться.

Если мир совершенно пуст, то это подходит идеально. Может казаться очевидным, что нам нужно двигаться из начальной конфигурации в конфигурацию цели, но стоит учесть, что агент мог двигаться совершенно иным способом, чтобы добраться из текущей конфигурации до цели. Он мог циклически перемещаться вокруг, пока не достигнет цели или отойти от неё на пятьдесят километров, прежде чем вернуться и остановиться на цели.
Так почему мы считаем прямую линию очевидной? Потому что в каком-то смысле это «наилучший» способ движения. Если принять, что агент может двигаться только с постоянной скоростью в любом направлении, то прямая — кратчайший и самый быстрый способ добраться из одной точки в другую. В этом смысле алгоритм Walk To оптимален. В этой статье мы много будем говорить об оптимальности. В сущности, когда мы говорим об оптимальности алгоритма, мы имеем в виду, что он «лучше всех» при определённом критерии «лучшести». Если вы хотите добраться из точки A в точку B как можно быстрее и на пути ничего нет, то ничто не сравнится с прямой линией.
И на самом деле, во многих играх (я бы сказал, даже в большинстве игр), алгоритм движения по прямой Walk To идеально подходит для решения задачи. Если у вас есть мелкие 2D-враги, находящиеся в коридорах или комнатах, которым не нужно блуждать по лабиринтам или следовать приказам игрока, то вам никогда не понадобится ничего сложнее.
Но если на пути вдруг что-то оказалось?

В этом случае объект на пути (называемый препятствием (Obstacle)) блокирует путь агента к цели. Так как агент больше не может двигаться напрямую к цели, он просто останавливается. Что здесь произошло?
Хотя алгоритм Walk To и оптимален, он не полон. «Полный» алгоритм способен решить все решаемые задачи в своей области за конечное время. В нашем случае область — это круги, двигающиеся по плоскости с препятствиями. Очевидно, что простое перемещение прямо к цели не решает все задачи в этой области.
Чтобы решить все задачи в этой области и решить их оптимально, нам нужно что-то более изощрённое.
Реактивное планирование: алгоритм жука
Что бы мы стали делать при наличии препятствия? Когда нам нужно добраться до цели (например, до двери), а на пути что-то есть (например, стул), то мы просто обходим его и продолжаем двигаться к цели. Такой тип поведения называется «избеганием препятствий». Этот принцип можно использовать для решения нашей задачи перемещения агента к цели.
Одним из простейших алгоритмов избегания препятствий является алгоритм жука. Он работает следующим образом:
Алгоритм : BUG
Рисуем прямую линию от агента до цели. Назовём её M-линией.Агент делает единичный шаг вдоль M-линии пока не будет соблюдаться одно из следующих условий:Если агент достиг цели, то остановиться.Если агент касается препятствия, то следовать вдоль препятствия по часовой стрелке, пока мы снова не попадём на M-линию, если при этом мы ближе к цели, чем были изначально до достижения M-линии. Когда мы достигаем M-линии, продолжить с шага 2.
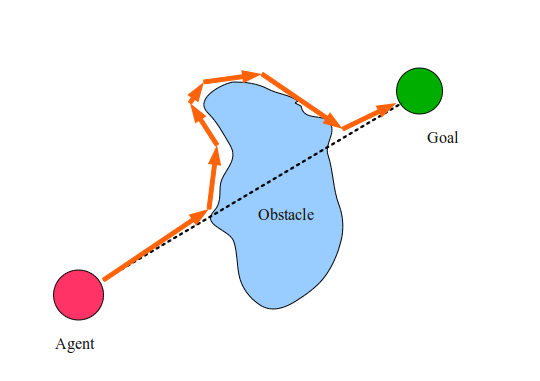
Шаг 2.2 требует объяснений. По сути, агент запоминает все случаи встречи с M-линией для текущего препятствия, и покидает препятствие, только находясь на M-линии и ближе к цели, чем в любой другой момент до этого. Это нужно, чтобы избежать попадания агента в бесконечный цикл.
На рисунке выше пунктирной линией показана M-линия, а оранжевыми стрелками обозначены шаги, совершаемые нашим агентом до достижения цели. Они называются траекторией агента. Удивительно, но алгоритм жука очень просто решает множество задач подобного типа. Попробуйте нарисовать кучу безумных фигур и убедитесь, насколько хорошо он работает! Но работает ли алгоритм жука для каждой задачи? И почему он работает?
Простой алгоритм жука имеет очень много интересных особенностей и демонстрирует множество ключевых концепций, к которым мы будем снова возвращаться в этой статье. Этими концепциями являются: траектория, политика, эвристика, полнота и оптимальность.
Мы уже упоминали концепцию траектории, которая является простой последовательностью конфигураций или движений, совершаемых агентом на своём пути. Алгоритм жука можно считать планировщиком траектории (Trajectory Planner), то есть алгоритмом, получающим начальную конфигурацию и конфигурацию цели, и возвращающим траекторию от начала до цели. (В литературе по разработке игр он также иногда называется «планировщиком пути» (path planner)).
Но мы также должны упомянуть концепцию политики. Если мы не будем интерпретировать алгоритм жука как возвращающий полную траекторию от начала до цели, а интерпретируем его как передающий агенту набор инструкций, которые позволяют добраться до цели из любой точки, просто используя в качестве руководства собственную конфигурацию, то тогда алгоритм жука можно назвать политикой управления (Control Policy). Политика управления — это просто набор правил, который исходя из состояния агента определяет, какие действия агент должен совершить далее.
В алгоритме жука M-линия является чётким индикатором того, где далее должен находиться агент. Почему мы выбрали следование M-линии, а не, допустим, линию из текущего положения агента к цели? Ответ заключается в том, что M-линия — это просто эвристика. Эвристика — это общее правило, используемое, чтобы сообщить о следующем этапе алгоритма. Это правило наделяет некими человеческими знаниями об алгоритме. Выбор эвристики часто является важной частью разработки такого алгоритма. При выборе неверной эвристики алгоритм может оказаться полностью неработоспособен.
Верьте или нет (я поначалу не верил), но алгоритм жука решает все решаемые задачи в области двухмерных кругов, двигающихся от начала до цели. Это значит, что вне зависимости от расположения агента или цели, если агент может достичь цели, то алгоритм жука позволит ему это сделать. Доказательство этого выходит за рамки этой статьи, но при желании вы можете об этом почитать. Если алгоритм может решать все задачи в своей области, для которых есть решения, то он называется полным алгоритмом.
Но несмотря на то, что алгоритм жука может решать все задачи этого типа, создаваемые им траектории не всегда лучшие возможные категории, которыми агент может достигнуть цели. На самом деле, алгоритм жука иногда может заставить агента заниматься довольно глупыми вещами (просто попробуйте создать препятствие, малое в направлении по часовой стрелке и огромное в другом направлении, и вы поймёте, о чём я. Если мы определим «лучший» как «занимающий кратчайшее время», то алгоритм жука ни в коем случае не является оптимальным.
Оптимальное планирование: граф видимости
А если нам нужно решить задачу движения кругов среди препятствий по оптимальному (кратчайшему) пути? Для этого мы можем привлечь геометрию, чтобы прикинуть, каким должен быть оптимальный алгоритм решения этой задачи. Для начала заметим следующее:
- На двухмерных евклидовых плоскостях кратчайшей траекторией между двумя точками является прямая линия.
- Длина последовательности прямолинейных траекторий является суммой длин каждой из линий.
- Поскольку многоугольник состоит из прямых линий (или рёбер), то кратчайший путь, полностью обходящий выпуклый многоугольник, содержит все рёбра многоугольника.
- Для обхода невыпуклого многоугольника кратчайший путь содержит все рёбра выпуклой оболочки многоугольника.
- Точка, находящаяся ровно на ребре многоугольника, касается этого многоугольника
Понимание определений «выпуклости», «невыпуклости» и «выпуклой оболочки» не очень важно для понимания этой статьи, но этих определений достаточно для создания планировщика оптимальной траектории. Давайте сделаем следующие допущения:
- Наш агент — это двухмерная точка бесконечно малого размера.
- Все препятствия мира можно свести к замкнутым многоугольникам.
- Наш агент может двигаться в любом направлении по прямой линии.
Тогда мы можем найти оптимальный план достижения агентом цели, создав то, что называется графом видимости мира. Кроме геометрии, нам также нужно немного узнать о графах. Теория графов не является темой этой статьи, но по сути своей графы — это просто группы абстрактных объектов (называемых узлами), соединённых с другими узлами абстрактными объектами под названием рёбра. Мы можем использовать мощь графов для описания мира, в котором живёт агент. Мы можем сказать, что узел — это любое место, в котором агент может находиться, ничего не касаясь. Ребро — это траектория между узлами, по которой может двигаться агент.
Учтя это, мы можем определить планировщик графа видимости следующим образом:
Алгоритм: VISIBILITY GRAPH PLANNER
Создаём пустой граф с названием G.Добавляем агента как вершину графа G.Добавляем цель как вершину графа G.Помещаем все вершины всех многоугольников мира в список.Соединяем все вершины многоугольников в граф G в соответствии с их рёбрами.Для каждой вершины V списка:Пытаемся соединить V с агентом и целью. Если прямая линия между ними не пересекает ни один из многоугольников, то добавляем эту линию как ребро в граф G.Каждую другую вершины в каждом другом многоугольнике пытаемся соединить прямой линией с V. Если линия не пересекает ни один из многоугольников, то добавляем линию как ребро графа G.Теперь выполняем планировщик графов (например, алгоритм Дейкстры или A*) для графа видимости, чтобы найти кратчайший путь от агента до цели.
Граф видимости выглядит следующим образом: (пунктирные линии)

А конечный путь выглядит так:
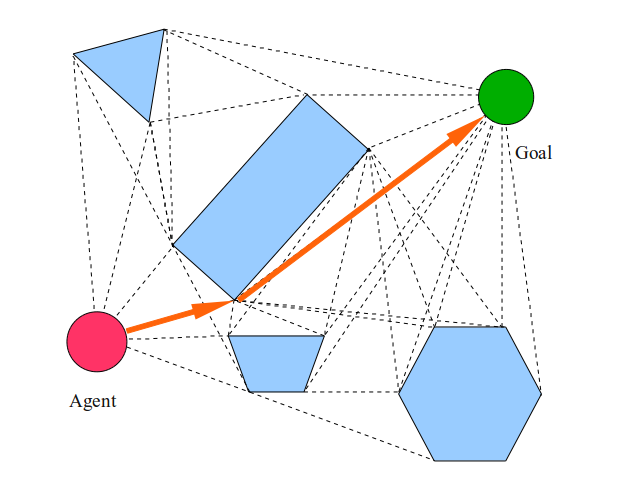
Из-за допущений, согласно которым агент является бесконечно малой точкой, способной перемещаться по прямым линиям из любой одной локации в любую другую, у нас получилась траектория, ровно проходящая через углы, грани и свободное пространство, чётко минимизирующая расстояние, которое должен пройти агент до цели.
Но что, если наш агент не является точкой? Заметьте, как оранжевый путь проводит агента между трапецоидом и прямоугольником. Очевидно, что агент не сможет протиснуться в этом пространстве, поэтому нам нужно решить эту задачу как-то иначе.
Одно из решений заключается в том, чтобы допустить, что агент — это не точка, а диск. В таком случае мы можем просто раздуть все препятствия на радиус агента, а затем планировать, как будто агент является точкой в этом новом раздутом мире.
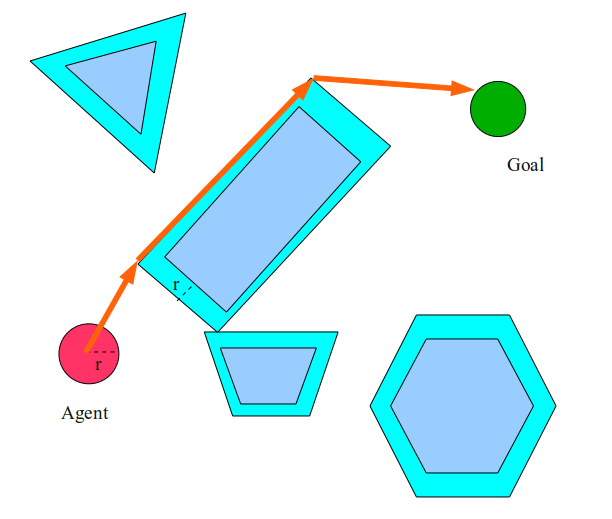
В этом случае агент выберет путь слева, а не справа от прямоугольника, потому что он просто не поместится в пространство между трапецоидом и прямоугольником. Эта операция «раздувания» на самом деле невероятно важна. В сущности, мы изменили мир так, чтобы наше допущение о том, что агент является точкой, оставалось истинным.
Эта операция называется вычислением конфигурационного пространства мира. Конфигурационное пространство (или C-Space) — это система координат, в которой конфигурация нашего агента представлена одной точкой. Препятствие в рабочем пространстве преобразуется в препятствие в конфигурационном пространстве размещением агента в обусловленную конфигурацию и проверкой коллизий агента. Если в такой конфигурации агент касается препятствия в рабочем пространстве, то она становится препятствием в конфигурационном пространстве. Если у нас есть некруглый агент, то для раздувания препятствий мы используем так называемую сумму
Минковского.
В случае двухмерного пространства это может казаться скучным, но именно это мы и делаем для «раздувания» препятствий. Новое «раздутое» пространство на самом деле является конфигурационным пространством. В более многомерных пространствах всё становится сложнее!
Планировщик графа видимости — отличная штука. Он и оптимален, и полон, к тому же он не полагается ни на какую эвристику. Ещё одно большое преимущество планировщика графа видимости — его умеренная возможность мультизапросов. Планировщик с мультизапросами способен повторно использовать старые вычисления при работе с новыми целями. В случае графа видимости при изменении местоположения цели или агента нам достаточно только перестроить рёбра графа от агента и от цели. Эти преимущества делают такой планировщик чрезвычайно привлекательным для программистов игр.
И в самом деле, во многих современных играх для планирования используются графы видимости. Популярной разновидностью принципа графа видимости является Nav (igation) Mesh. В Nav Mesh иногда в качестве основы используются графы видимости (вместе с другими эвристиками для расстояния до врагов, предметов и т.д.). Nav Mesh могут изменяться дизайнерами или программистами. Каждый Nav Mesh хранится как файл и используется для каждого отдельного уровня.
Вот скриншот Nav Mesh, использованного в видеоигре Overlord:
Несмотря на все свои преимущества, методы графов видимости обладают и существенными недостатками. Например, вычисление графа видимости может быть достаточно затратной операцией. С увеличением количества препятствий размер графа видимости значительно разрастается. Затраты на вычисление графа видимости растут как квадрат от количества вершин. Кроме того, при изменении любых препятствий для сохранения оптимальности скорее всего потребуется полный перерасчёт графа видимости.
Программисты игр изобрели всевозможные ухищрения для ускорения создания графов с помощью эвристик выбора узлов, к которым нужно пытаться присоединиться через рёбра. Также дизайнеры игр могут давать алгоритму графа видимости подсказки, чтобы он определил, какие узлы соединять в первую очередь. Все эти хитрости приводят к тому, что граф видимости перестаёт быть оптимальным и иногда требует монотонной работы программистов.
Однако самая серьёзная проблема графов видимости (по моему мнению) в том, что они плохо обобщаются. Они решают одну задачу (планирование на 2D-плоскости с препятствиями-многоугольниками), и решают её невероятно хорошо. Но что, если мы не на двухмерной плоскости? Что, если нашего агента нельзя представить в виде круга? Что, если мы не знаем, какими будут препятствия, или их нельзя представить в виде многоугольников? Тогда мы не сможем без ухищрений использовать графы видимости для решения нашей задачи.
К счастью, существуют другие методы, более близкие к принципу «запустил и забыл», которые решают некоторые из этих проблем.
Поиск по решётке: A* и его вариации
Графы видимости работают потому, что используют оптимизирующие качества поиска по абстрактным графам, а также фундаментальные правила евклидовой геометрии. Евклидова геометрия даёт нам «фундаментально верный» граф для поиска. А сам абстрактный поиск занимается оптимизацией.
Но что, если мы полностью откажемся от евклидовой геометрии и просто будем решать всю задачу поиском по абстрактным графам? Таким образом мы сможем устранить посредника в лице геометрии и решать множество разных видов задач.
Проблема в том, что мы можем использовать множество различных подходов для переноса нашей задачи в область поиска по графам. Какими будут узлы? Что именно считать рёбрами? Что значит соединение одного узла с другим? От того, как мы ответим на эти вопросы, в значительной степени зависит производительность нашего алгоритма.
Даже если алгоритм поиска по графам даёт нам «оптимальный» ответ, он является «оптимальным» с точки зрения только его собственной внутренней структуры. Это не подразумевает, что «оптимальный» согласно алгоритму поиска по графам ответ является нужным нам ответом.
Учитывая это, давайте определим граф наиболее распространённым способом: как решётку. Вот, как это работает:
Алгоритм: DISCRETIZE SPACE
Допустим, что конфигурационное пространство имеет постоянный размер во всех измерениях.Дискретизируем каждое изменение так, чтобы в нём было постоянное количество ячеек.Каждую ячейку, центр которой находится в конфигурационном пространстве внутри препятствия, пометим как непроходимую.Аналогично, каждую ячейку, центр которой не находится в препятствии, пометим как проходимую.Теперь каждая проходимая ячейка становится узлом.Каждый узел соединяется со всеми смежными проходимыми соседями в графе.
«Смежный» — это ещё один аспект, с которым нужно быть внимательным. Наиболее часто он определяется как »любая ячейка, имеющая хотя бы один общий угол с текущей ячейкой» (это называется «евклидовой смежностью») или как »любая ячейка, имеющая хотя бы одну общую грань с текущей ячейкой» (это называется «смежностью Манхэттена»). От выбора определения смежности очень сильно зависит ответ, возвращаемый алгоритмом поиска по графам.
Вот как будет выглядеть этап дискретизации на нашем учебном примере:
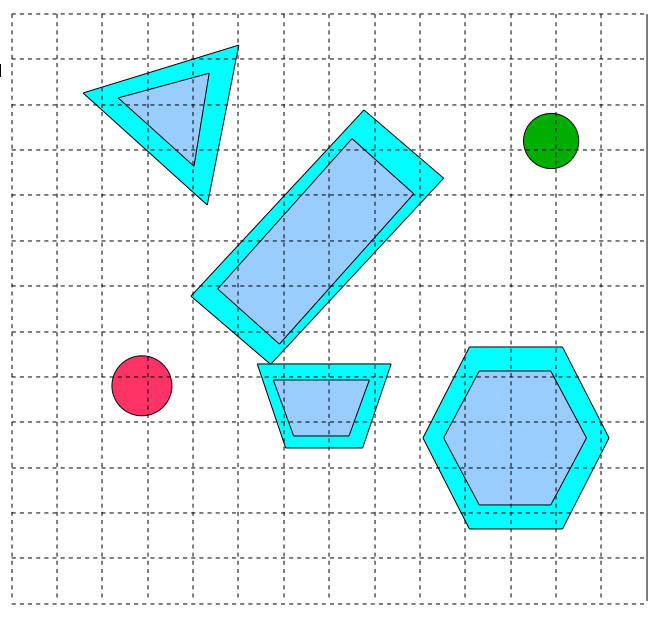
Если мы будем выполнять поиск по этому графу согласно метрике евклидовой смежности, то получим примерно такой результат:
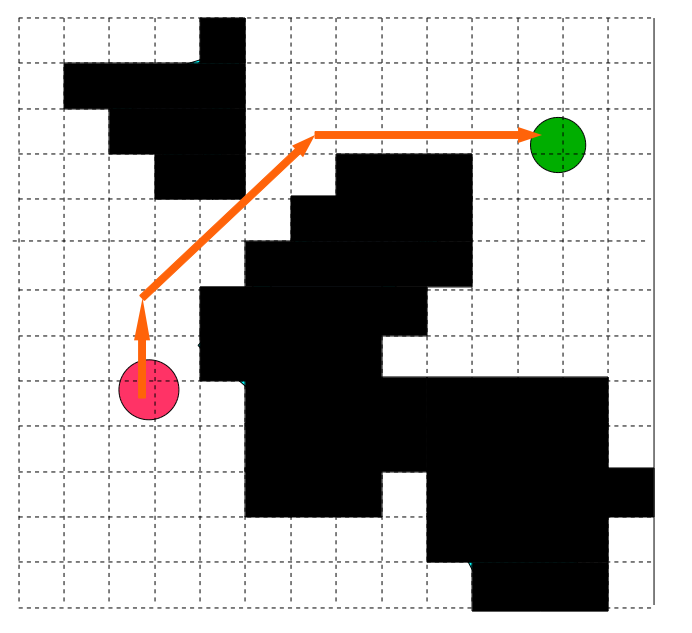
Существует множество других алгоритмов поиска по графам, которые можно использовать для решения задачи поиска по решётке, но самым популярным является A*. A* является родственным алгоритму Дейкстры, который выполняет поиск по узлам с помощью эвристики, начиная с начального узла. A* хорошо исследован во множестве других статей и туториалов, так что я не буду объяснять его здесь.
A* и другие методы поиска по графам-решёткам — это одни из самых распространённых в играх алгоритмов планирования, а дискретизированная решётка — это один из самых популярных способов структурирования A*. Для многих игр этот метод поиска является идеальным, потому что во многих играх для представления мира всё равно используются тайлы или воксели.
Методы поиска по графам на дискретной решётке (в том числе и A*) являются согласно их внутренней структуре оптимальными. Также они являются резолюционно-полными. Это более слабая форма полноты, которая гласит, что при стремлении мелкости решётки к бесконечности (т.е. при стремлении ячеек к бесконечно малому размеру) алгоритм решает всё больше и больше решаемых задач.
В нашем конкретном примере метод поиска по решётке является однозапросным, а не мультизапросным, потому что поиск по графу обычно не может повторно использовать старую информацию при обобщении до новых конфигураций цели и начала. Однако этап дискретизации, естественно, может использоваться повторно.
Ещё одним ключевым преимуществом (по моему мнению, главным) методов на основе графов является то, что они совершенно абстрактны. Это значит, что дополнительные затраты (такие как обеспечение безопасности, гладкости, близости нужных объектов и т.д.) могут быть учтены и автоматизированы автоматически. Кроме того, для решения совершенно различных задач можно использовать один и тот же абстрактный код. В игре DwarfCorp мы используем один планировщик A* и для планирования движения, и для планирования символических действий (используемого для представления действий, которые могут совершать агенты, в виде абстрактного графа).
Однако поиск по решёткам имеет по крайней мере один серьёзный недостаток: он невероятно требователен к памяти. Если каждый узел наивным образом строится с начала, то с увеличением размеров мира у вас очень быстро закончится память. Большая часть проблемы заключается в том, что решётка должна хранить в себе большие объёмы пустого пространства. Для минимизации этой проблемы существуют техники оптимизации, но в фундаментальном плане при увеличении размера мира и количества измерений задачи чудовищно возрастает объём памяти в решётке. Поэтому такой метод неприменим для множества более сложных задач.
Ещё одним серьёзным недостатком метода является то, что поиск по графам сам по себе может занимать достаточно больше время. Если в мире движутся одновременно несколько тысяч агентов или изменяет своё положение множество препятствий, то поиск по решётке может быть неприменим. В нашей игре DwarfCorp планированию уделено несколько потоков. Оно отъедает кучу процессорного времени. В вашем случае такое тоже может быть!
Политики управления: потенциальные функции и поля течения
Ещё один способ решения задачи планировки движения — перестать думать о ней в категориях планирования траекторий и начать воспринимать её в категориях политикой управления. Помните, мы говорили, что алгоритм жука можно воспринимать и как планировщик траектории, и как политику управления? В том параграфе мы определили политику как набор правил, который получает конфигурацию и возвращает действие (или «входной сигнал управления»).
Алгоритм жука можно воспринимать как простую политику управления, которая просто говорит агенту двигаться по направлению к цели, пока он не наткнётся на препятствие, а затем обходить препятствие по часовой стрелке. Агент в буквальном смысле может следовать этим правилам, двигаясь по своему пути к цели.
Ключевые преимущества политики управления в том, что они в общем случае не полагаются на агента, имеющего что-то больше, чем локальное знание о мире, и в том, что они невероятно быстры в вычислениях. Одной и той же политике управления запросто могут следовать тысячи (или миллионы) агентов.
Можем ли мы придумать какие-нибудь политики управления, работающие лучше, чем алгоритм жука? Стоит рассмотреть одну из них, очень полезную »политику потенциального поля». Она выполняет симуляцию агента в виде заряженной частицы, притягиваемой к цели и отталкиваемой препятствиями:
Алгоритм: POTENTIAL FIELD POLICY
Определяем вещественные константы a и bНаходим вектор в конфигурационном пространстве от агента до цели и обозначаем его как g.Находим ближайшую точку препятствия в конфигурационном пространстве и обозначаем его как o.Находим вектор от o до агента и обозначаем его как r.Входной сигнал управления имеет вид u = a * g^ + B * r^, где v^ обозначает нормализованный вектор v.Перемещаем агента согласно входному сигналу управления.
Понимание этой политики требует некоторых знаний линейной алгебры. В сущности, входной сигнал управления является взвешенной суммой двух членов: члена притяжения и члена отталкивания. Выбор весов в каждом члене значительно влияет на конечную траекторию агента.

С помощью политики потенциального поля можно заставить агентов двигаться невероятно реалистичным и плавным образом. Также можно легко добавить дополнительные условия (близость к нужному объекту или расстояние до врага).
Так как политика потенциального поля чрезвычайно быстро рассчитывается при параллельных вычислениях, этим способом можно очень эффективно контролировать тысячи и тысячи агентов. Иногда эта политика управления вычисляется предварительно и сохраняется в сетке для каждого уровня, после чего может изменяться дизайнером нужным ему способом (тогда она обычно называется полем течения).
В некоторых играх (особенно в стратегических) такой метод используется с огромной эффективностью. Вот пример полей течения, используемых в стратегической игре Supreme Commander 2, чтобы юниты естественным образом избегали друг друга, сохраняя построение:

Разумеется, функции полей течения и потенциальных полей имеют серьёзные недостатки. Во-первых, они ни в коем случае не оптимальны. Агенты будут распространяться полем течения вне зависимости от того, сколько времени займёт добирание до цели. Во-вторых (и, по-моему, это наиболее важно), они ни в коем случае не полны. Что, если входной сигнал управления обнулится до того, как агент достигнет цели? В этом случае мы скажем, что агент достиг »локального минимума». Вы можете подумать, что такие случаи достаточно редки, но на самом деле их довольно легко сконструировать. Достаточно просто поместить перед агентом большое U-образное препятствие.
Наконец, поля течения и другие политики управления очень сложно настраивать. Как нам подобрать веса каждого из членов? В конце концов для получения хороших результатов они требуют ручной настройки.
Обычно дизайнерам приходится вручную настраивать поля течения, чтобы избежать локальных минимумов. Такие проблемы ограничивают возможную полезность в общем случае полей течения. Тем не менее, во многих случаях они полезны.
Конфигурационное пространство и проклятие размерности
Итак, мы обсудили три наиболее популярных алгоритма планирования движения в видеоиграх: решётки, графы видимости и поля течения. Эти алгоритмы чрезвычайно полезны, просты в реализации и достаточно хорошо изучены. Они идеально работают в случае двухмерных задач с круглыми агентами, движущимися во всех направлениях плоскости. К счастью, к этому случаю относятся практически все задачи в видеоиграх, а остальные можно имитировать хитрыми трюками и тяжким трудом дизайнера. Неудивительно, что их так активно используют в игровой отрасли.
А чем же исследователи планирования движения занимались последние несколько десятилетий? Всем остальным. Что, если ваш агент не является кругом? Что, если он не находится на плоскости? Что, если он может двигаться в любом направлении? Что, если цели или препятствия постоянно меняются? Ответить на эти вопросы не так просто.
Давайте начнём с очень простого случая, который, похоже, достаточно просто решить с помощью уже описанных нами методов, но который на самом деле невозможно решить этими методами, кардинально не изменив их.
Что, если агент является не кругом, а прямоугольником? Что, если важен поворот агента? Вот как выглядит описываемая мной картина:

В показанном выше случае агент (красный) похож на магазинную тележку, которая может двигаться в любом направлении. Мы хотим переместить агента таким образом, чтобы он оказался ровно поверх цели и был повёрнут в нужном направлении.
Здесь мы предположительно можем использовать алгоритм жука, но нам нужно будет внимательно обращаться с поворотами агента, чтобы он не сталкивался с препятствиями. Мы быстро запутаемся в хаосе правил, которые будут совсем не так элегантны, как для случая с круглым агентом.
А что, если попробовать использовать граф видимости? Для этого нужно, чтобы агент был точкой. Помните, как мы сделали трюк и раздули объекты для круглого агента? Возможно, и в этом случае удастся сделать нечто подобное. Но насколько нам нужно раздуть объекты?
Простым решением будет выбор «наихудшего сценария» и вычисление планирования с таким расчётом. В этом случае мы просто берём агента, определяем описывающий его круг и принимаем агента равному кругу этого размера. Затем мы раздуваем препятствия до нужного размера.

Это сработает, но нам придётся пожертвовать полнотой. Появится множество задач, которых мы не сможем решить. Возьмём например такую задачу, в которой длинный и тонкий агент должен для достижения цели пробраться через «замочную скважину»:

В этом сценарии агент может добраться до цели, проникнув в скважину, повернув на 90 градусов, затем дойти до следующей скважины, повернуть на 90 градусов и выйти из неё. При консервативной аппроксимации агента через описывающий круг эту задачу решить будет невозможно.
Проблема в том, что мы не учли правильным образом конфигурационное пространство агента. До этого момента мы обсуждали только 2D-планирование в окружении 2D-препятствий. В таких случаях конфигурационное пространство хорошо преобразуется из двухмерных препятствий в другую двухмерную плоскость и мы наблюдаем эффект «раздувания» препятствий.
Но на самом деле здесь происходит следующее: мы добавили в нашу задачу планирования ещё одно измерение. У агента есть не только позиция по x и y, но и поворот. Наша задача на самом деле является задачей трёхмерного планирования. Теперь преобразования между рабочим и конфигурационным пространствами становятся гораздо более сложными.
Можно воспринимать это следующим образом: представьте, что агент выполнил определённый поворот (который мы обозначим «тета»). Теперь мы перемещаем агента в каждой точки рабочего пространства с заданным поворотом, и если агент касается препятствия, то мы считаем эту точку коллизией в конфигурационном пространстве. Такие операции для препятствий-многоугольников тоже можно реализовать с помощью сумм Минковского.
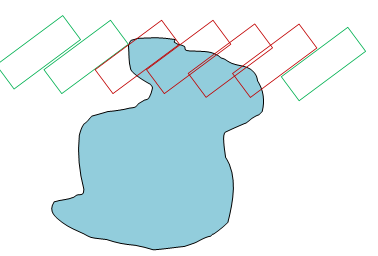
На представленной выше схеме у нас имеется одно прохождение агента через препятствие. Красными контурами агента показаны конфигурации, находящиеся в коллизии, а зелёными контурами показаны конфигурации без коллизий. Это естественным образом приводит к ещё одному «раздуванию» препятствий. Если мы выполним его для всех возможных положений (x, y) агента, то создадим двухмерный срез конфигурационного пространства.
Теперь мы просто увеличим тету на некую величину и повторим операцию, получив ещё один двухмерный срез.

Теперь мы можем наложить срезы один на другой, выровняв их координаты x и y, как бы сложили листы миллиметровой бумаги:

Если мы будем нарезать тету бесконечно тонко, то в результате получим трёхмерное конфигурационное пространство агента. Это непрерывный куб, а тета поворачивается вокруг него снизу вверх. Препятствия превращаются в странные цилиндрические фигуры. Агент и его цели становятся просто точками в этом новом странном пространстве.
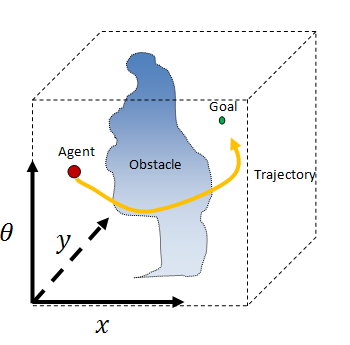
Это довольно сложно уложить в г
