[Перевод] Блокировки работают не так уж медленно
Действительно, блокировки могут работать медленно на некоторых платформах, или в сверх-конкурентном коде. И, если вы разрабатываете многопоточное приложение, то вполне возможно, что рано или поздно натолкнётесь на ситуацию, когда какая-нибудь одна блокировка будет съедать очень много ресурсов (скорее всего из-за ошибки в коде, приводящей к слишком частому её вызову). Но всё это частные случаи, не имеющие в общем случае отношения к утверждению «блокировки работают медленно». Как мы увидим ниже, код с блокировками может работать весьма производительно.
Одна из причин заблуждений о скорости работы блокировок состоит в том, что многие программисты не отличают понятия «легковесный мьютекс» и «мьютекс, как объект ядра ОС». Всегда используйте легковесные мьютексы. К примеру, если вы программируете на С++ под Windows, то ваш выбор это критические секции.
 Второй причиной заблуждений могут служить, как это ни парадоксально, бенчмарки. К примеру, далее в этой статье мы будем измерять производительность блокировок под высокой нагрузкой: каждый поток будет требовать блокировку для выполнения любого действия, а сами блокировки будут очень короткими (и, в результате, очень частыми). Это нормально для эксперимента, но такой способ написания кода — это не то, что вам нужно в реальном приложении.
Второй причиной заблуждений могут служить, как это ни парадоксально, бенчмарки. К примеру, далее в этой статье мы будем измерять производительность блокировок под высокой нагрузкой: каждый поток будет требовать блокировку для выполнения любого действия, а сами блокировки будут очень короткими (и, в результате, очень частыми). Это нормально для эксперимента, но такой способ написания кода — это не то, что вам нужно в реальном приложении.
Блокировки критикуются и по другим причинам. Есть целое семейство алгоритмов и технологий, называемых «lock-free» программированием. Это невероятно захватывающий и вызывающий способ разработки, который способен принести огромный прирост производительности в целый ряд приложений. Я знаю программистов, которые тратили недели на полировку своих «lock-free»-алгоритмов, писали на них миллион тестов — и всё лишь для того, чтобы поймать редкий баг, связанный с определённой комбинацией таймингов, несколькими месяцами позже. Эта комбинация опасности и награды за неё может быть очень привлекательной для некоторых программистов (в том числе и меня). С мощью «lock-free» классические блокировки начинают казаться скучными, устаревшими и тормозящими.
Но не спешите сбрасывать их со счетов. Одним из хороших примеров, где блокировки часто используются и показывают хорошую производительность, являются аллокаторы памяти. Популярная реализация malloc от Doug Lea часто используется в геймдеве. Но она однопоточна, так что нам необходимо защитить её блокировками. Во время активной игры у нас вполне может возникнуть ситуация, когда несколько потоков обращаются к аллокатору с частотой, скажем, 15 000 раз в секунду. Во время загрузки игры эта цифра может доходить и до 100 000 раз в секунду. Как вы увидите дальше, это совершенно не является проблемой для кода с блокировками.
Бенчмарк
В этом тесте мы запустим поток, который будет генерировать случайные числа с помощью алгоритма вихря Мерсенна. По ходу работы он будет регулярно захватывать и освобождать объект синхронизации. Время между захватом и освобождением будет случайно, но в среднем оно будет стремиться к заданной нами величине. К примеру, представим, что мы хотим использовать блокировку 15 000 раз в секунду и удерживать её 50% времени. Вот как в этом случае будет выглядеть таймлайн. Красный цвет означает время, когда блокировка захвачена, серый — когда свободна.

Это, по сути, процесс Пуасона. Если мы знаем среднее количество времени для генерации одного случайного числа (а это, например, 6.349 наносекунд на процессоре 2.66 GHz quad-core Xeon) — мы можем измерить количество выполненной работы в некоторый юнитах, а не в секундах. Мы можем использовать технику, описанную в другой моей статье, для определения количества юнитов работы между захватом и освобождением объекта синхронизации. Вот реализация на С++. Я опустил некоторые несущественные детали, но вы можете скачать полный исходный код здесь.
QueryPerformanceCounter(&start);
for (;;)
{
// Выполняем некоторую работу без блокировки
workunits = (int) (random.poissonInterval(averageUnlockedCount) + 0.5f);
for (int i = 1; i < workunits; i++)
random.integer(); // выполняем один юнит работы
workDone += workunits;
QueryPerformanceCounter(&end);
elapsedTime = (end.QuadPart - start.QuadPart) * ooFreq;
if (elapsedTime >= timeLimit)
break;
// Выполняем некоторую работу с блокировкой
EnterCriticalSection(&criticalSection);
workunits = (int) (random.poissonInterval(averageLockedCount) + 0.5f);
for (int i = 1; i < workunits; i++)
random.integer(); // выполняем один юнит работы
workDone += workunits;
LeaveCriticalSection(&criticalSection);
QueryPerformanceCounter(&end);
elapsedTime = (end.QuadPart - start.QuadPart) * ooFreq;
if (elapsedTime >= timeLimit)
break;
}
Теперь давайте представим, что мы запустили два таких потока, каждый на своём ядре процессора. Каждый поток будет удерживать блокировку 50% времени своей работы, но если один поток попытается получить доступ к критической секции в то время, когда она удерживается другим потоком, то он будет вынужден ждать. Классический случай борьбы за разделяемый ресурс.

Я думаю, что это достаточно приближенный к реальности пример того, как блокировки используются в реальных приложениях. Когда мы запустим вышеуказанный код в двух потоках, то обнаружим, что каждый поток проводит около 25% времени в ожидании и лишь 75% времени выполняя реальную работу. Вместе два потока увеличивают производительность в 1.5 раза по сравнению с однопоточным решением.
Я запускал этот тест с разными вариациями на процессоре 2.66 GHz quad-core Xeon — в 1 поток, в 2 потока, в 4 потока, каждый на своём ядре. Я также вариировал длительность захвата блокировки от вырожденного случая, где блокировка освобождалась незамедлительно, до противоположной грани, когда блокировка занимала 100% времени работы потока. Во всех случаях частота захвата оставалась константной — 15 000 раз в секунду.
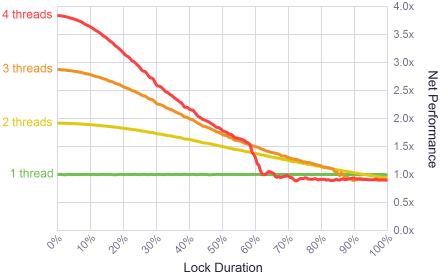
Результаты были достаточно интересными. Для короткой длительности захвата (я бы сказал до 10% времени), система показывала крайне высокую степень параллелизма. Не идеально, но близко к этому. Блокировки работают быстро!
Для оценки результатов в плане практического применения я проанализировал работу аллокатора памяти в многопоточной игре с помощью профайлера. По ходу игры происходило около 15 000 вызовов аллокатора из трёх потоков, блокировки занимали около 2% общей производительности приложения. Эта величина находится в «зоне комфорта» в левой части графика.
Данные результаты показывают также, что как только длительность работы кода внутри блокировки переходит грацину в 90% общего времени — больше нет смысла писать многопоточный код. Однопоточное приложение в данном случае будет работать быстрее. Что ещё более удивительно — это резкий скачёк вниз производительности 4-ех потоков в районе 60%. Это было похоже на аномалию, так что я повторил тест несколько раз, пробовал запускать тесты в другом порядке. Но каждый раз получалось одно и то же. Моя лучшая догадка состоит в том, что данная комбинация числа потоков, длительности блокировок и нагрузки на процессор вывели планировщик Windows в некоторый экстремальный режим работы, но я не исследовал это глубже.
Бенчмарк частоты захвата блокировки
Даже легковесный мьютекс несёт с собой некоторые накладные расходы. Пара операций lock/unlock для критической секции в Windows работает около 23.5 наносекунд (на вышеуказанном процессоре). Таким образом, даже 15 000 блокировок за секунду не несут какой-то существенной нагрузки, влияющей на производительность. Но что будет, если мы повысим частоту?
Вышеуказанный алгоритм предлагает очень удобные средства контроля количества работы, выполняемой между захватами блокировки. Я провёл ещё одну серию тестов: от 10 наносекунд до 31 микросекунды между блокировками, что соответствует примерно 32 000 блокировкам за секунду. В каждом тесте использовались два потока.

Как вы могли предположить, при очень высокой частоте накладные расходы на блокировки начинают влиять на общую производительность. На таких частотах внутри блокировки выполняется всего несколько инструкций, что сравнимо по времени с самим захватом\освобождением объекта синхронизации. Хорошие новости состоят в том, что для таких коротких (а значит, простых) операций вполне вероятно можно разработать и использовать некоторый lock-free алгоритм.
В то же время результаты показали, что вызов блокировок до 320 000 раз в секунду (3.1 микросекунд между блокировками) может быть вполне эффективным. В геймдеве аллокатор памяти может нормально работать на подобных частотах во время загрузки игры. Вы всё ещё получаете до 1.5х прироста от многопоточности в данном случае (но только если длительность самой блокировки будет небольшой).
Мы рассмотрели широкий спектр различных случаев использования блокировок: от очень высокой их производительности, до случаев, когда сама идея многопоточности теряет смысл. Пример с аллокатором памяти в игровом движке показал, что в реальных приложениях высокая частота использования блокировок вполне допустима при выполнении некоторых условий. С такими аргументами никто уже не сможет просто голословно сказать, что «блокировки работают медленно». Да, блокировки можно использовать неэффективным образом, но жить с этим страхом не стоит — к счастью у нас есть профайлеры, которые легко определяют подобные проблемы. Каждый раз, когда вы захотите броситься с головой в омут захватывающего и опасного lock-free программирования — вспомните данную статью и тот факт, что и блокировки могут работать достаточно быстро.
Целью этой статьи было вернуть блокировкам немного того уважения, которое они справедливо заслуживают. Я понимаю, что при всём богатстве вариантов использования блокировок в промышленном ПО, программистов сопровождали как успехи, так и болезненные неудачи в процессе поиска баланса производительности. Если у вас есть пример того или другого — расскажите об этом в комментариях.
