[Из песочницы] Собираем базу людей из открытых данных WhatsApp и VK
кадр из фильма Миссия Невыполнима II
Эта история началась пару месяцев назад, в первый день рождения моего сына. На мой телефон пришло СМС-сообщение с поздравлением и пожеланиями от неизвестного номера. Думаю, если бы это был мой день рождения мне бы хватило наглости отправить в ответ, не совсем культурное, по моему мнению, «Спасибо, а Вы кто?». Однако день рождения не мой, а узнать кто передаёт поздравления было интересно.
Первый успех
Было решено попробовать следующий вариант:
- Добавить неизвестный номер в адресную книгу телефона;
- Зайти по очереди в приложения, привязанные к номеру (Viber, WhatsApp);
- Открыть новый чат с вновь созданным контактом и по фотографии определить отправителя.
Мне повезло и в моём случае в списке контактов Viber рядом с вновь созданным контактом появилась миниатюра фотографии, по которой я, не открывая её целиком, распознал отправителя и удовлетворенный проведенным «расследованием» написал смс с благодарностью за поздравления.
Сразу же за секундным промежутком эйфории от удачного поиска в голове появилась идея перебором по списку номеров мобильных операторов составить базу [номер_телефона => фото]. А еще через секунду идея пропустить эти фотографии через систему распознавания лиц и связать с другими открытыми данными, например, фотографиями из социальных сетей.
Естественно на пункте 3 (по фотографии определить отправителя) нас может настигнуть неудача и у этой неудачи есть 6 вариантов:
- Номер не привязан к WhatsApp или Viber
- Пользователь есть, но он не устанавливал себе Фото профиля
- Фото установлено, но настроены параметры «приватности» или «конфиденциальности» («Показывать фото только моим контактам», а Вас в этом списке нет)
- Вам доступно фото, но на нём изображён кот
- На фото человек, но черт лица и/или особенностей телосложения не разобрать (отсутствие резкости, маленькое разрешение, затемнённые очки, шляпы, кепки, грим)
- На фотографии владелец номера; анфас; высокая четкость, но вспомнить этого человека вы не можете
Четвертый пункт (на фото кот) имеет множество вариантов: это и фотографии знаменитостей, и персонажи мультфильмов, и фотографии еды, автомобилей, оружия и пр.
Испытания на малых порядках.
В качестве пробы пера было решено экспериментировать на своём списке контактов. На телефонах с ОС Android фотографии контактов Viber хранит в папке /sdcard/viber/media/User photos в виде [Хэш].jpg. Файлы сохраняются только при условии, что вы общались с данным контактом или хотя бы открывали его профиль и удаляются через некоторое время. Для эксперимента вручную откроем/закроем профили 20-ти пользователей.
Часть знакомых, для которых были найдены файлы были также найдены в социальных сетях, загружены в программу Picasa с включенной опцией «Распознавать лица автоматически». Распознанные программой лица затем были названы соответственно их владельцам. На следующем шаге скармливаем Picas’e папку с фотографиями из Viber. Для схожих лиц в окне «Пользователи» появляются иконки с вопросительным знаком.
В моём случае для исходных 20 пользователей Viber Picasa обнаружила только два совпадения. Эти два случая при этом достаточно комично совпали: в каждой паре фотографии различались между собой, но были сняты в один и тот же день (для первого человека на двух фотографиях отличался поворот головы и наличие/отсутствие улыбки, для второго отличалась только улыбка).
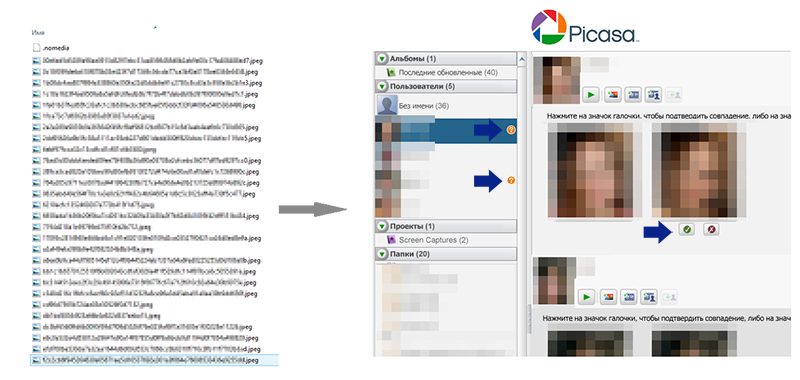
Промежуточный итог довольно успешный:
Выборка из Viber: 20 (все подряд и с котами и с едой)
Выборка из VK: 5 (только если на фото можно кого-то распознать зрительно)
Совпадений верных: 2
Совпадений ложных: 0
Начинаем перебор
Попробуем получить данные с помощью телефона. Viber берёт контакты из телефонной книги, которая в свою очередь в ОС Android связана с Google Contacts, которые имеют ограничение в 25 000 номеров на аккаунт. На сегодняшний момент количество номеров мобильных операторов, закрепленных за г. Москва — 93 311 000. Так что идея получить базу таким вот «решением в лоб» отпадает. Тем более, что даже если Viber возьмет хотя бы первую пачку в 25 000 номеров, все равно в каждый профиль нужно зайти, а потом еще связать получившийся файл [Хэш].jpg с конкретным номером (что, наверное, можно отследить по дате создания файла, но это всё равно очень трудоёмко и долго).
Решение было найдено быстро: в сети есть программная реализация другого популярного сервиса — WhatsApp. Все вызовы идут через php. Есть готовый скрипт регистрации нового пользователя и собственно пример вызова getProfilePicture. Чтобы начать процесс нужен *nix сервер и нужно понять насколько можно обнаглеть с частотой и скоростью запросов. Для эксперимента был написан php код, который авторизуется в Whatsapp и в бесконечном цикле получает/не получает для номеров +7XXXXXXXXXX getProfilePicture и выдаёт на экран временную метку. Этот код при первом и последующих запусках доходил до 220–250 номеров и уходил в timeout — пробуем после каждого 200-го делать паузу sleep (5) — не помогает, всё равно timeout. Пробуем завершить процесс и сразу запустить заново — успех. Соответственно имеем дело либо с ограничением на сервере (необходимо после 200 запросов заново авторизоваться), либо с ошибкой в этой php реализации. Экспериментировать я не стал, а убил двух зайцев, переписав php скрипт, чтобы он обрабатывал только 200 номеров и добавив управляющий скрипт на Bash, который в цикле запускает php с параметром $startPhoneNumber и дожидается его завершения.
Таким образом получили работающую схему перебора со скоростью 5,7 номеров в секунду.
Для обработки всей московской ёмкости нам потребуется:
93 311 000 (номеров) / 5.7 (номеров в секунду) / 60 (секунд) / 60 (минут) / 24 (часа) ~ 190 дней.
Многопоточность
Авторизация в WhatsApp идет через связку
username — номера телефона в формате +7XXXXXXXXXX
password — полученный через скрипт регистрации (для регистрации нужна работающая симкарта для получения кода подтверждения)
nickname — может быть любым
WhatsApp запрещает >1 авторизации на один username одномоментно. В связи с чем в официальном магазине было закуплено три SIM-карты оператора Мегафон по 200р. каждая. С одного и того же сервера на ОС Centos все три номера были зарегистрированы в WhatsApp и на всех трёх было запущено по скрипту с кусочком емкости «Билайн Бизнес». Соотношение количества номеров к сохраненным фотографиям держалось в районе 10 к 1-му; потом разница увеличилась благодаря «сотням» и «тысячам», которые видимо еще не распределены и для всего диапазона не дают ни одного изображения.
Блокировка
В лицензионном соглашении WhatsApp (с которым я соглашаюсь, когда прохожу регистрацию) сказано:
C. You agree not to use or launch any automated system, including without limitation, «robots,» «spiders,» «offline readers,» etc. or «load testers» such as wget, apache bench, mswebstress, httpload, blitz, Xcode Automator, Android Monkey, etc., that accesses the Service in a manner that sends more request messages to the WhatsApp servers in a given period of time than a human can reasonably produce in the same period by using a WhatsApp application, and you are forbidden from ripping the content unless specifically allowed. Notwithstanding the foregoing, WhatsApp grants the operators of public search engines permission to use spiders to copy materials from the website for the sole purpose of creating publicly available searchable indices of the materials, but not caches or archives of such materials. WhatsApp reserves the right to revoke these exceptions either generally or in specific cases. While we don’t disallow the use of sniffers such as Ethereal, tcpdump or HTTPWatch in general, we do disallow any efforts to reverse-engineer our system, our protocols, or explore outside the boundaries of the normal requests made by WhatsApp clients. We have to disallow using request modification tools such as fiddler or whisker, or the like or any other such tools activities that are meant to explore or harm, penetrate or test the site. You must secure our permission before you measure, test, health check or otherwise monitor any network equipment, servers or assets hosted on our domain. You agree not to collect or harvest any personally identifiable information, including phone number, from the Service, nor to use the communication systems provided by the Service for any commercial solicitation or spam purposes. You agree not to spam, or solicit for commercial purposes, any users of the Service.
«Вы соглашаетесь не использовать или не запускать автоматизированные системы, которые посылают больше запросов на сервис WhatsApp, чем способен человек…»
Все мои SIM-карты заблокировали на третий день без объяснения причин. По логам видно, что отключение произошло в 00:22 по Москве по всем картам одновременно (карты успели обработать каждая около 500 000 номеров). Что интересно сервера WhatsApp сначала стали очень долго отвечать на запросы, а потом вообще перестали авторизовывать. На попытку зарегистрировать номер заново сервер отвечает »Failed; Reason: Blocked; ». При попытке зарегистрировать WhatsApp по-человечески с телефона выскакивает сообщение: «Извините, вы больше не можете пользоваться сервисом WhatsApp.»
Кроме того, что все три запущенных скрипта делали одно то же с одной и той же скоростью у них было много общего, чтобы заблокировать их одновременно, а именно: все логинились с одним и тем же nickname «V» и работали с одного и того же IP-адреса.
Усложняем схему

Считаем, что стали чуть-чуть (а именно на 600р. потраченные на те три SIM) умней. На этот раз покупаем 10 сим карт в «неофициальном магазине» у метро по 100р. за штуку. Усложняем скрипт, создаём массив симкарт и даём каждой свой nickname согласно списку актёров одного замечательного фильма:
// username,"password","nickname"
$SIMDict = array(
"SIM1" => array(7969XXXXXXX,"123123211231231231231231231=","Zooey"),
"SIM2" => array(7916XXXXXXX,"123123211231231231231231231=","Martin"),
"SIM3" => array(7985XXXXXXX,"123123211231231231231231231=","Sam"),
"SIM4" => array(7916XXXXXXX,"123123211231231231231231231=","Bill"),
"SIM5" => array(7985XXXXXXX,"123123211231231231231231231=","Mos"),
"SIM6" => array(7985XXXXXXX,"123123123211231231231231231=","Warwick"),
"SIM7" => array(7916XXXXXXX,"123123211231231231231231231=","Anna"),
"SIM8" => array(7985XXXXXXX,"123123123123123123123123121=","John"),
"SIM9" => array(7,"","Kelly"),
"SIM10" => array(7,"","Jason")
);
В системе по умолчанию есть подсистема ip namespaces (ip netns), которая позволяет полностью виртуализировать сетевой стек. Это означает что можно создавать так называемые namespac’ы (ns), и в рамках каждого отдельного ns будут свои адреса, маршруты, правила, dns и пр. В интернете не так много статей про ip netns, а те которые есть дают разные показания по использованию физических интерфейсов — некоторые пишут, что нельзя физический интерфейс добавить в namespace отличный от default, некоторые, что можно, но только связать через tap интерфейс, некоторые, что можно и без tap.
Создать семь secondary ip (alias) и раскидать их по разным namespace у меня не вышло, ни напрямую ни через tap интерфейсы. А вот вариант создать 7 namespace’ов и к каждому привязять отдельный физический интерфейс, несмотря на заверения интернет сообщества, удалось без проблем.
ip netns add net1 && ip link set netns net1 dev eth1
ip netns exec net1 ip addr add Y.Y.Y.71/24 dev eth1
ip netns exec net1 ip link set up dev eth1
ip netns exec net1 ip route add default via Y.Y.Y.1
ip netns add net2 && ip link set netns net2 dev eth2
ip netns exec net2 ip addr add Y.Y.Y.72/24 dev eth2
ip netns exec net2 ip link set up dev eth2
ip netns exec net2 ip route add default via Y.Y.Y.1
CISCO
ip nat inside source static Y.Y.Y.71 X.X.X.71
ip nat inside source static Y.Y.Y.72 X.X.X.72
Legacy adapter не заработал вообще, поэтому остановимся на 8-ми карточках.
Теперь скрипт Bash берёт на вход startNumber, endNumber, SIM, NS, где SIM имя симкарты в массиве, NS — имя namespace в котором запустить процесс php. Пример вызова:
./run.sh 79671380000 79671780000 SIM1 net1 &
...
start=$1
last=$2
net=$4
startParam="ip netns exec $net"
./pushme.sh "$3 $4" "$start begins"
while [ $start -lt $last ]
do
$startParam php ./getProfiles.php instance=$start prefix=$start count=50 sim=$3 net=$4
#> $3.log
start=$(( $start + 50 ))
done
...
Делим емкость на кусочки меньше 2 000 номеров. Также добавляем в Bash и php скрипты Push-уведомления через Pushover (»7XXXXX start»,»7XXXXX finish», «Houston we have a problem»)
Последнее отправляем при нестандартных ответах сервера WhatsApp, либо при очень долгом (>5 секунд) отсутствии ответа.
Забегая вперёд хочу сказать, что WhatsApp хитрее меня и все эти симкарты тоже были заблокированы через некоторое время и тоже почти одновременно. В любом случае 8 000 000 телефонных номеров скрипты всё-таки успешно проработали и у нас на руках 411 279 фотографий. Соотношение 20 к 1. Что уже вполне неплохо.

Выборка из результатов обработки по г. Москва
Ненецкий автономный округ
Долгое время не было возможности активировать оставшиеся сим-карты и запустить скрипты. Наконец свободная минута появилась, а вместе с ней силы признать, что начинать перебор с Москвы (население 12 197 596 человек) — это лихо. Поэтому прячем поглубже свой юношеский максимализм и берём менее населенный субъект, например, Ненецкий автономный округ. Почему бы и нет. Запускаем скрипт — и через 12 часов перебор всех емкостей Ненецкого округа завершен. Для 169 995 номеров было найдено всего 2 208 фотографий в WhatsApp. Переходим к следующему этапу.
ВКонтакте
Задача: получить все фотографии пользователей VK, у которых указан интересующий нас город.
Немалое количество времени ушло, чтобы разобраться с VK API. И оказалось, что запрос getuser выполнить можно без проблем, не имея access-token. А вот запрос search (чтобы взять только людей из конкретного города) сработает только с токеном, причём полученным на пользователя, а не на standalone приложение. В этом нам поможет статья Как я получал access token для взаимодействия с vk api. Но даже когда мы получили этот токен — мы утыкаемся в ограничение — получить можно только 1000 пользователей (не 1000 за один запрос, а 1000 всего), при том, что, например, город Нарьян-Мар (Ненецкий АО) указан у 15 660 человек.
Пробуем пойти через get_users перебором: перебираем всех пользователей вконтакте от $id = 1 до N следующим запросом:
response=$(curl --silent "https:// api.vk.com /method/users.get?user_id=$id&fields=photo_max_orig,country,city")
В сети вконтакте на момент написания этой статьи было N = 300 000 000 пользователей. На один такой запрос без скачивания фото уходила 1 секунда.
300 000 000 (пользователей) / 1 (в секунду) / 60 (секунд) / 60 (минут) / 24 (часа) ~ 3472 дней.
Итого около 3472 дней в одном потоке, при условии, что VK не будет блокировать наши IP-адреса. Вариант отбрасываем.
Возвращаемся к users.search с ограничением на количество в выдаче, но не на «качество» запроса. Поясняю. В запросе можно бесконечно уточнять параметры: например, взять только женщин или мужчин, уменьшив выдачу в два раза, или взять только тех, у кого есть фото, и что самое удобное — взять только людей конкретного возраста, естественно в цикле от $age = 14 до 80. Итого 66 прогонов по 1000, с замечанием, что, если для некоторых возрастов мы перевалим за 1000 — такие запросы мы повторим с дополнительным разделением по полу.
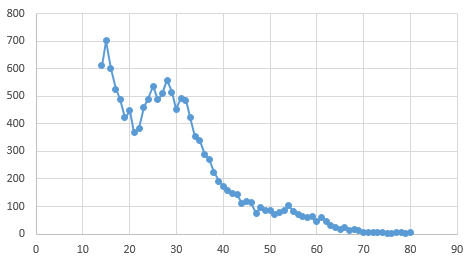
Распределение пользователей VK из г. Нарьян-Мар по возрасту
01: acc_token="abc123abc123abc123abc123abc123abc123abc123abc123"
02: vk_url="api.vk.com/method/users.search?has_photo=1&count=1000&city=2487&country=1&access_token=$acc_token&fields=photo_max_orig"
03:
04: for age in {14..80}
05: do
06: echo -n $id " " >>vk.log
07: date +"%T" >>vk.log
08: mkdir photos/$id
09: list=$(curl --silent "$vk_url&age_from=$age&age_to=$age" | jq '.response | .[] | (.uid|tostring) + " " + .photo_max_orig' | \
sed 's/^"\(.*\)"$/\1/')
10: counter=0
11: while read -r line; do
12: let counter++
13: arr=($line)
14: echo -n "$counter." >>vk.log
15: photo=${arr[1]}
16: filename=${arr[0]}$(echo $photo | sed "s/.*\(\..*\).*$/\1/")
17: wget $photo -O photos/$id/$filename
18: done <<< "$list"
19:done
Собственно, скрипт, используя полученный заранее (с того же IP) access_token запрашивает через VK API в цикле список всех людей конкретного возраста из конкретного города (city=2487).
Самое интересное здесь — строчка № 9:
Она превращает JSON ответ от вконтакте вида ({«response»:[COUNT,{«uid»: XXXXXXX, «first_name»: «Иван», «last_name»: «Иванов», «photo_max_orig»: «http:\/\/QQQ.vk.me\/ZZZ\/YYY.jpg»}) в список
id photo_url (XXXXX http:// QQQ.vk.me /ZZZ/YYY и т.д.)
Способов это реализовать масса и наверняка есть более симпатичный вариант. Но в поисках как это сделать я наткнулся на так называемый «jq is a lightweight and flexible command-line JSON processor», синтаксис которого мне приглянулся:
jq '.response | .[] | (.uid|tostring) + » » + .photo_max_orig'
Если читать с конца, то: взять текстом id пользователя (.uid|tostring) с ссылкой на фото .photo_max_orig для всех элементов массива .[] в рамках объекта response
На 19 годах VK что-то заподозрили, и стали очень медленно отвечать на запросы. Через полтора часа было скачано 13 967 изображений. У остальных 1 700 человек возраст видимо не был указан вообще. Еще 400 скачанных изображений оказались, по каким-то причинам битыми, либо очень маленькими (<10 кб).
Распознавание и сравнение лиц
Как мы уже выяснили среди полученных изображений множество котов и автомобилей, поэтому для начала хочется их отфильтровать. Поможет нам с этим OpenCV (Open Source Computer Vision Library, библиотека компьютерного зрения с открытым исходным кодом).
Существует множество реализаций, на различных языках программирования, основанных на этой библиотеке. Например, facedetect, которая определяет координаты по которым находится лицо на фото. Она же вместе с ImageMagick вырежет по координатам распознанное лицо в отдельный файл.
По распознаванию лиц на фото, есть интересная реализация от компании Betaface. У них платное API для большого количества изображений, но есть отличная демо, которая распознает всех присутствующих на загруженном фото и кроме прочего определяет пол, наличие усов, очков, улыбки и (женщинам это не понравится) показывает предположительный возраст (мне даёт 27, плюшевому кролику на холодильнике — 42).
Мы же возьмем готовые скрипты на python от английского разработчика Terence Eden. Он написал их в рамках очень интересного проекта. В его задаче стояло: скачать открытую коллекцию картин Лондонского музея «Тейт Британия», и распознать на ней изображения людей. Затем с помощью получившейся базы лиц и своей фотографии можно найти картину, на которой изображен человек максимально похожий на тебя. Web API он, к сожалению, не даёт, но все исходники есть на github.
Корректируем скрипт Тэренса — выключаем скачивание из Британской галереи и удаляем обработку по папкам.
import sys, os
import cv2
import urllib
from urlparse import urlparse
def detect(path):
img = cv2.imread(path)
cascade = cv2.CascadeClassifier("haarcascade_frontalface_alt.xml")
rects = cascade.detectMultiScale(img, 1.3, 4, cv2.cv.CV_HAAR_SCALE_IMAGE, (20,20))
if len(rects) == 0:
return [], img
rects[:, 2:] += rects[:, :2]
return rects, img
def box(rects, img, file_name):
i = 0 # Track how many faces found
for x1, y1, x2, y2 in rects:
print "Found " + str(i) + " face!" # Tell us what's going on
cut = img[y1:y2, x1:x2] # Defines the rectangle containing a face
file_name = file_name.replace('.jpg','_') # Prepare the filename
file_name = file_name + str(i) + '.jpg'
file_name = file_name.replace('\n','')
print 'Writing ' + file_name
cv2.imwrite('detected/' + str(file_name), cut) # Write the file
i += 1 # Increment the face counter
def main():
for filename in os.listdir('whphotos'):
print filename + " "
rects, img = detect("whphotos/" + filename)
box(rects, img, filename)
os.remove("whphotos/" + filename)
if __name__ == "__main__":
main()
Итог обработки:
13 500 изображений из VK => 6 427 / 5 446 лиц. (с учетом / без учёта случаев с несколькими лицами на одном фото)
2 208 из WhatsApp => 963 / 876 лиц
Проглядывается интересная закономерность — каждый второй пользователь не ставит фото на профиль.
Следом за распознанием идёт создание модели eigenfaces.xml. Скриптом предусмотрено по папке исходных фотографий сформировать XML файл, по которому в будущем будет производиться поиск. Поэтому по одному комплекту готовим такой файл, а из второго потом берём по одному элементу и ищем соответствие. Техника решила за меня какой из комплектов брать за основной: 6 400 фотографий из VK скрипт обработать не смог с ошибкой по памяти »Couldn’t allocate over 4GB». Время — 11 ночи — разбираться не охота — пропускаем через скрипт 963 фото из WhatsApp и через 20 минут имеем eigenfaces.xml размером 1.6 ГБ. Можно представить какого бы размера он был в случае с VK. Позже оказалось, переделывая скрипт под себя, я случайно удалил строку идентификации в модели, вместо неё все элементы имели идентификатор »0». Смешно бы было прождать несколько дней выполнения скрипта и только потом это обнаружить. Исправляем ошибку и ждём еще 20 минут.
Затем для каждого файла из VK запускаем скрипт проверки.
find detectedVK/ -name *.jpg -exec ./myscript.sh {} \;
#myscript.sh
python recognise.py detectedWH $1 100000 >> result
`100000` здесь — точность совпадения, при 100 — идеальное совпадение.
На одно сравнение имеем 40 секунд. 6 400×40 ~ 3 дня на одном процессоре. Оставляем на ночь; идем спать — завтра понедельник.
Сразу скажу, что у меня были мысли, что для такой маленькой выборки совпадений будет ноль. Пока работали скрипты я периодически смотрел на совпадения. С указанной мною точностью результатов было много, но при ближайшем рассмотрении даже на совпадениях порядка `3500` было множество результатов мальчик-девочка. При том создавалось ощущение, что эти двое родственники. Результат интересный, но это не совсем то, что мы искали.
Первое попадание случилось к концу первой тысячи аккаунтов. Девушка Яна из города Нарьян-Мар поставила одинаковую фотографию и в WhatsApp и в VK. Несмотря на то, что фото одинаковые (отличается только разрешение) точность совпадения ~3 000. Для всех результатов с точностью <6000 с помощью convert объединяем совпавшие изображения, чтобы зрительно окончательно принять решение
...
if [ "$precise" -lt 6000 ]
then
echo $precise $whIMG $vkIMG
convert detectedWH.bak/$whIMG detectedVK.bak/$vkIMG -append convertResults/${precise}_$whIMG$vkIMG
fi
...

Итого к окончанию вторых суток успешно распознаны и привязаны к номеру телефона 25 аккаунтов VK.
Это 2% от числа найденных лиц WhatsApp, либо 1% от всех изображений.

Результаты анализа по г. Нарьян-Мар
Я верю, что это отличный результат, и вот почему:
- У нас маленькие выборки, с большой разницей между ними (16 600 VK против 2 000 WhatsApp);
- Для поиска совпадений мы использовали только алгоритм Eigenfaces, а можно добавить, например, Fisherfaces;
- Можно увеличить шансы на распознание добавив по аналогии перебор через Viber;
- Из VK можно брать не только последнее фото профиля, но и несколько предыдущих;
- Наконец, к списку социальных сетей можно добавить Facebook, Одноклассники и пр.
Тут сложно говорить о конкретных цифрах, но можно точно сказать, что процент успешных попаданий значительно увеличится, если соблюсти все пункты. Процессорные мощности для этого конечно тоже надо увеличить в несколько раз.
Заключение
К чему это всё. Полезного для общества практического применения полученных данных я пока не придумал. Получилось небольшое исследование ради исследования.
Библиотека OpenCV отличный инструмент, используя который на полученных данных, можно провести еще ряд интересных экспериментов.
В награду дочитавшим до конца, такой, например, весёлый вариант: Собрать модель eigenfaces.xml по фотографиям известных актрис, российских и зарубежных, и провести перебор на соответствие по полученной из WhatsApp базе москвичей (у нас их на данный момент ~400 000). Не беря во внимание моральную составляющую (а именно, вопрос: культурно ли звонить незнакомым людям), набираем номер и приглашаем в кино. Прикольно ведь пойти в кино с девушкой, которая с точностью 3000 к 100 похожа на главную героиню.

Еще в качестве вывода можно было бы сказать: «Не забывайте ставить галочки в настройках приватности». Но я не большой сторонник параноидальных настроений (» Они знают где я», «Интернет-провайдер знает обо мне всё», «Большой брат следит за нами» и пр.). Меня, например, веселит, когда моя жена выключает сбор анонимных геоданных на телефоне, со словами, что её «найдут» (кто, а главное зачем она пока не придумала).
Не знаю будет ли меня когда-нибудь кто-нибудь искать — я в своей жизни вроде бы ничего не нарушал (кроме лицензионного соглашения WhatsApp).
