[Из песочницы] Отчет о старте Atos IT Challenge
Есть ли у вас та штука, что называется pet project или side project? Тот самый проект, который бы вы делали в свое удовольствие и для себя, для саморазвития или расширения портфолио. Лично у меня долгое время не было ничего, что можно было бы показать. Однако, в рамках стартовавшего этой осенью конкурса Atos IT Challenge 2018, у меня как раз появилась возможность начать такой проект.
О конкурсе
Объясню: уже седьмой год подряд Atos выбирает некоторую горячую в мире IT тему и предлагает командам студентов всего мира придумать и реализовать идею, этой теме посвященную. Конкурс достаточно значителен: студенты, прошедшие в основной тур, будут работать полгода под руководством опытного ментора, и лишь в июне узнают о результатах. Призовой фонд на фоне такого объема работ не сногсшибателен: 10 000, 5 000 и 3 000 евро расположились на призовых ступеньках, но да, собственно, привлекают прежде всего не деньги.
Главным я считаю возможность прокачаться в новой для себя области, заодно применив это в реальном проекте. И претворяя это все в жизнь в компании своих товарищей, конечно.
О теме этого года
«Чат-боты для жизни и бизнеса» — вот то ядро, на основе которого нужно придумать свою идею. «Чат» значит общение, речь и текст. Поэтому и без знаний NLP — «natural language processing», или «обработки естественного языка» — никуда.
Как известно, студенты лучше всего воспринимают информацию в ночь перед экзаменом, и мы, руководствуясь той же логикой, решаем участвовать, а знания NLP совершенствовать по ходу. Такие вещи, как простая классификация текстов, нам уже давно подвластна, но в рамках конкурса нам предстоит разобраться и в Q&A-системах, алгоритмах реферирования, — в общем, все становится интереснее.
О заявках
До первого декабря участники подавали заявки с описаниями идей, и, надо сказать, составить заявку оказалось делом непростым. От нас попросили и бизнес-модель будущего приложения, и техническую осуществимость, и архитектуру, и конечную выгоду для пользователей и наших партнеров.
Мы — классические студенты-технари, и с бизнес-моделями были до конкурса и не знакомы толком. Однако, благодаря хорошей книге Остервальдера и Пинье «Построение бизнес-моделей» смогли изобразить что-то похожее на правду.
Заявки, конечно, видят, только судьи, однако участникам видны название и описание — summary — идей соперников.
О нас
Мы — четверо студентов Воронежского госуниверситета. Четверо достаточно творческих людей, любящих искусство и музыку. Возможно, поэтому мы и стали отталкиваться не от бизнес-применений чатботов, а от далекой для денежной выгоды темы: живописи.
Было бы вам интересно поговорить с роботом о картине, что видите? Обсудить детали, поделиться впечатлениями?
Для нас ответ очевиден: конечно, было бы интересно! Отлично, а как лучше всего общаться с системой, если не хочется смотреть в телефон? Конечно, голосом.
Так и была сформирована первичная идея: бот, с которым вы говорите об искусстве и том, что видите.
Совершенство любого интерфейса в его отсутствии. Вы просто говорите, что думаете, и получаете ответ. Нет сценария, рамок или команд. Словом, «дзен», — и в этом мы видим ценность и будущее подобного рода систем и приложений.
О других
До 1 декабря заявки были поданы, и через неделю, 7 декабря, нам был открыт список идей других команд. Их оказалось очень много: 204.
Вот некоторые, которые нам понравились:
- Составление фоторобота по описанию внешности подозреваемого. Здесь вроде и диалоговая часть понятна, и применение очевидно.
- Виртуальный учитель. Команда утверждает, что будут делать голограмму, которая рассказывала бы материал и отвечала на вопросы.
А вот… странные:
- Получение диагнозов по симптомам, вызов мужа на час, — словом, много сервисов, упакованных в чат-боты не совсем понятно, зачем.
- Чат-боты как чат-боты: чтобы говорить. И все. (вот или вот)
- И, наконец, наш фаворит: приложение, которое срабатывает, как будильник, при достижении некоторой локации. Где здесь бот? Мы не нашли. Зато «работает на iOS, Android, Windows Phone и BlackBerry».
Читать описание каждой из идей, конечно, лень. А если программисту что-то делать лень, то он пишет для этого программу, не так ли?
Первичный анализ данных
Получение данных
Сначала все просто: импортируем библиотеки и скачиваем данные с сайта.
import requests as rq
import bs4 as bs
from toolz.functoolz import excepts
root = 'https://www.atositchallenge.net/students-ideas/'
soup = bs.BeautifulSoup(rq.get(root).text, 'html5lib')
data = soup.select('div.ideas-wrapper a')
len(data) # -> 204
mk_safe = lambda f: excepts(Exception, f, lambda _: np.NaN)
def extract_short_info(r):
get_href = mk_safe(lambda x: x['href'])
get_title = mk_safe(lambda x: x.select_one('div.caption-container h3').text)
get_uni = mk_safe(lambda x: x.select_one('div.caption-container p.university').text)
get_flag = mk_safe(lambda x: x.select_one('img.flag')['alt'])
return {
'url': get_href(r),
'title': get_title(r),
'university': get_uni(r),
'country': get_flag(r)
}
df = pd.DataFrame([extract_short_info(x) for x in data])
df.country = df.country.str.split(' ').apply(lambda x: x[-1])
df.country = df.country.map({'Turkey': 'Турция', 'China': 'Китай', 'Singapore': 'Сингапур', 'India': 'Индия', 'Kong': 'Гонконг',
'France': 'Франция', 'States': 'США', 'Taiwan': 'Тайвань', 'Kingdom': 'Великобритания',
'Senegal': 'Сенегал', 'Philippines': 'Филипины', 'Malaysia': 'Малайзия', 'Canada': 'Канада',
'Brazil': 'Бразилия', 'Russia': 'Россия', 'Romania': 'Румыния', 'Belgium': 'Бельгия', 'Japan': 'Япония',
'Germany': 'Германия', 'Cameroon': 'Камерун', 'Poland': 'Польша','Netherlands': 'Нидерланды',
'Spain': 'Испания','Egypt': 'Египет', 'Mexico': 'Мексика','Morocco': 'Морокко','Austria': 'Австрия'})Наш промежуточный результат:
df.head()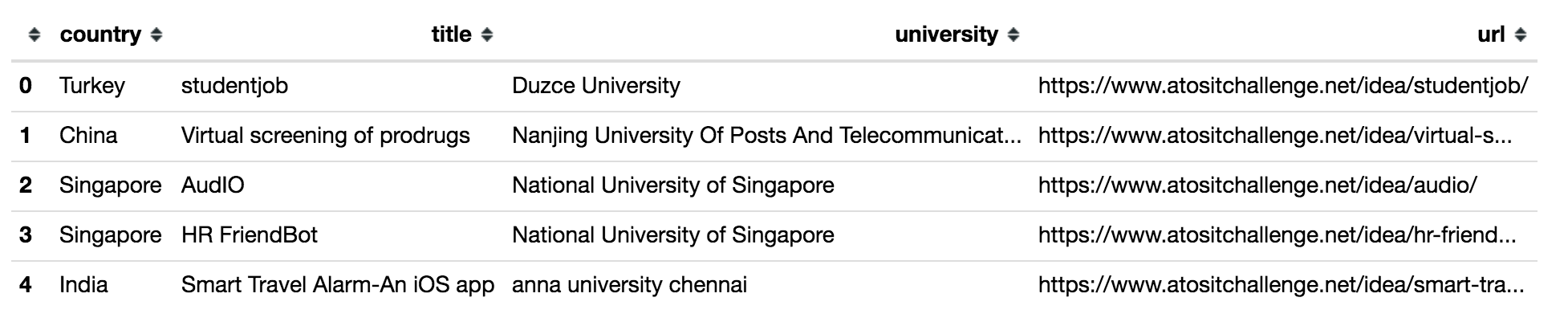
В колонке url как раз содержатся странички с каждой из идей. На них, впрочем, новой информации немного: состав команды и текст описания. Скачаем и их и присоединим к нашему исходному dataframe:
def download_description(title, url):
try:
soup = bs.BeautifulSoup(rq.get(url).text, 'html5lib')
get_summary = mk_safe(lambda x: x.select_one('p.summary').text)
get_members = mk_safe(lambda x: x.select('p.members')[0].text)
summary = get_summary(soup)
members = get_members(soup)
except:
return None
return {
'title': title,
'summary': summary,
'members': members
}
results = list(df.apply(lambda row: download_description(row['title'], row['url']), axis=1))
df_summaries = pd.DataFrame(list(results))
df = df.merge(df_summaries)И финальный результат — в студию!
df.head()
Визуализация
Ну что, посмотрим, с чем имеем дело? Что у нас со странами?
counts = df.country.value_counts()
counts.plot.bar();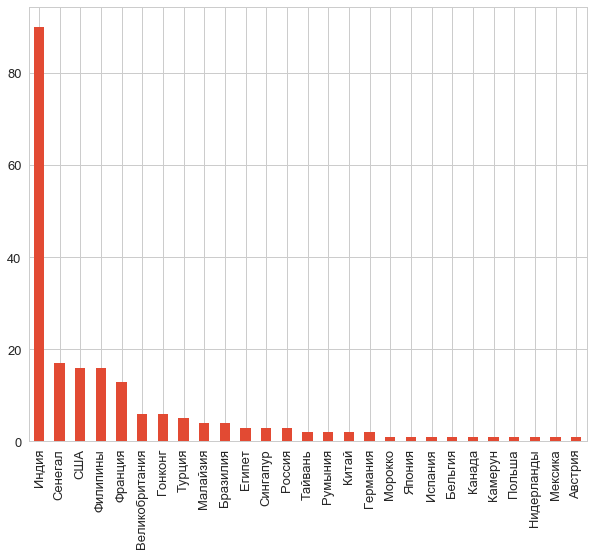
Ну и дела! Студентов из Индии не в пример больше.
india_part = pd.Series(data=[counts[0], counts[1:].sum()], index=['Индия', 'Все остальные страны'])
f, ax = plt.subplots(1, 1, figsize=(10, 10))
india_part.plot.pie(ax=ax);
ax.set_ylabel('');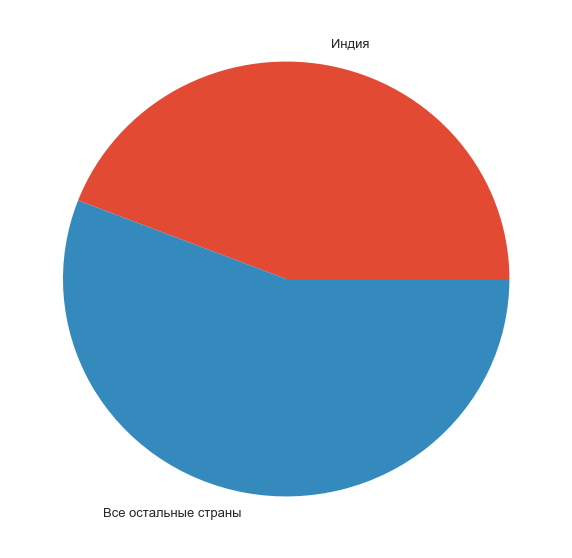
Действительно: почти половина всех участников — ребята из страны священных коров и экономичных космических программ.
Доли остальных участников по странам распределились вот так:
f, ax = plt.subplots(1, 1, figsize=(11, 11))
counts[1:].plot.pie(ax=ax);
ax.set_ylabel('');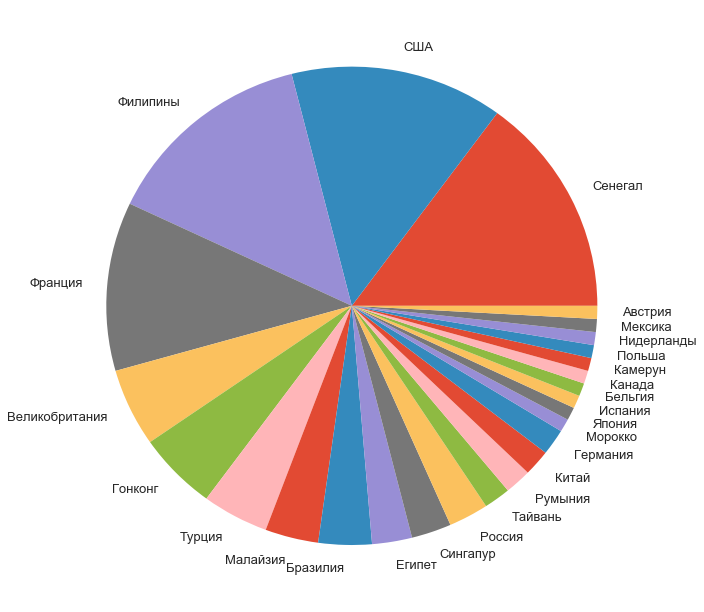
А как дела с университетами?
university_counts = df.groupby('country')[['university']]\
.agg('nunique')\
.sort_values(by='university', ascending=False)
university_counts\
.plot.bar(colors=['#ffea2d' if k != 'Россия' else '#ff2d2d' \
for k in university_counts.index]);
plt.gca().legend_.remove()
plt.ylabel('Количество участвующих университетов');
plt.xlabel('Страна');
y_ticks = list(plt.yticks()[0])
y_ticks.remove(0)
plt.yticks(y_ticks + [1]);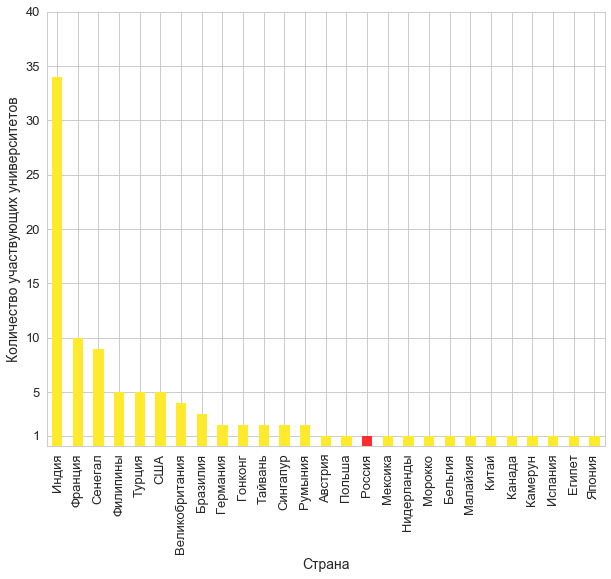
Да. Вот так. Неутешительно. Все три команды-участника из России из одного и того же университета — нашего. Где вы все, ребята, ну как так?…
df['number_of_members'] = df.members.str.split('|').apply(lambda x: len(x))
avg_members = df.groupby('country').agg('mean').sort_values(by='number_of_members', ascending=False)
avg_members.plot.bar(colors=['r' if x=='Россия' else ('#2dbcff' if x != 'Индия' else '#ffea2d') for x in avg_members.index]);
plt.gca().legend_.remove()
plt.xlabel('Страна');
plt.ylabel('Среднее количество участников');
Индию нам лишь удалось обойти лишь в силе дружбы: на графике видно, что наши команды в среднем более полные.
Ну что, приступим к самому мясному, — к тексту?
Анализ текста
Названия команд
Как бота назовешь, о том он говорить и будет. Может, тренды этого года в тематиках ботов будут видны еще из названий проектов? Давайте посмотрим:
import re
from nltk import word_tokenize
from nltk.corpus import stopwords
from nltk import FreqDist
titles = ' '.join(df.title.values)
tokens = [x.lower() for x in word_tokenize(titles) if re.match("[a-zA-Z\d]+", x) is not None]
tokens = [x for x in tokens if x not in stopwords.words('english')]Уберем очевидно не относящиеся к теме слова, которые, однако, наверняка будут всплывать («chat», «chatbot», «intelligent», «system» и другие) и построим частотный словарь:
fd = FreqDist(tokens)
[fd.pop(x) for x in ['chatbot', 'bot', 'service', 'ai', 'virtual', 'companion', 'system',
'app', 'intelligent', 'chatbots', 'robot', 'assistant', 'smart', 'solutions']];
len(fd) # 328
plt.figure(figsize=(18, 3));
fd.plot(40, cumulative=False)
Правда уже проглядывается: в этом году популярны боты, призванные помогать со здоровьем. Их догоняют боты, посвященные путешествиям и покупкам. Очевидное ли применение? Здравое? Хорошая реализация проектов покажет.
Описания идей
Приступим теперь к обработке текстов описаний идей.
from nltk import SnowballStemmer
summaries = '. '.join(df.summary)
sbs = SnowballStemmer('english')
tokens = [x.lower() for x in word_tokenize(summaries) if re.match("[a-zA-Z\d]+", x) is not None]
tokens = [x for x in tokens if x not in stopwords.words('english')] # 18546
tokens = [sbs.stem(x) for x in tokens]
len(tokens) # 18623
fd = FreqDist(tokens)
len(fd) # -> 3301, без стемминга 4877
plt.figure(figsize=(18, 3));
fd.plot(40, cumulative=False)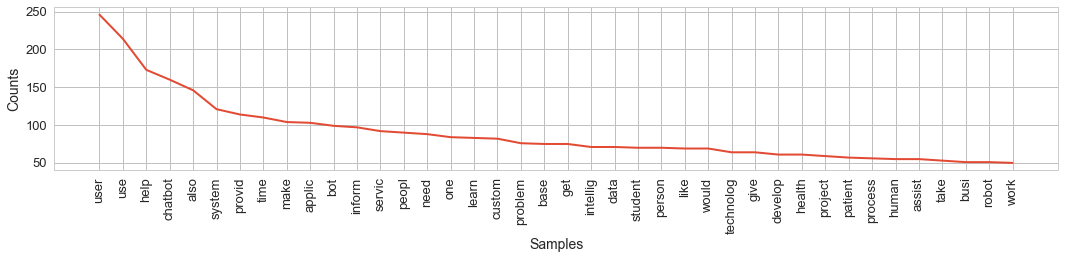
Из возникающих слов попарно образуются смешные, но, в общем-то, правильные утверждения: «пользователи используют», «чатбот помогает» и «также система предоставляет». Обращая внимание на самые встречаемые слова, можно легко представить, как выглядит средний текст с описанием: он о том, что проблемы решаются с помощью бота, проект технологичный и служит людям. Все правильно! Но надеюсь, что судьям хватит терпения дочитать эти две сотни альтруистских од, …
Краткий пересказ
…, если же терпения не хватит, с помощью знаменитой gensim можно попросить вывести краткое содержание всей этой массы:
from gensim.summarization import summarize, keywords
print(summarize(summaries, word_count=150))Its a virtual travel assistant that provides on demand feed, notifications and data according to customization (location, eating preferences, age etc.)It takes the necessary data and takes the interests from the social media of a person and provides the chat to him in the same manner Chatbot serves the data ranging from flight details, cab facility to location (precise timings, photos, guide, weather etc which makes the travel more sensible and by pinning points and tracking journey it saves a lot of money too), markets (helps to walk through markets and worth buying prices)or it may be a nightlife .
И ключевые слова:
ks = keywords(summaries, words=30, lemmatize=True)
for i, x in enumerate(ks.split('\n')):
ending = '\t' if (i+1) % 4 != 0 else '\n'
print(x.ljust(14), end=ending)users likely inform helped
basing provider chatbotics servicing
humanity persons people data
timings uses learns news
medications health differences applicability
technological customization problems businesses
bots foods student experiences
needed И тут Остапа понесло
А потом я подумал, что могу заставить генеративные модели сделать новые описания новых идей! Погнали!
import markovify
markov = markovify.Text(summaries)
for i in range(10):
print(markov.make_sentence())You will have a voice controlled, barrier free, and machine designed to adapt the use of Ai-City, users will be presented to farmers in touch with in years it is get incorporate AI in the form of a bundle of reviews in a specific time of the Clients are Available Here by using the Machine Learning Algorithms which will be backed by a continuous analysis of recorded visual material which will help them to prioritize which crop has to be treated there.
Well archiBOT is your loyal helper, which can make naive practitioner to take your pills, pick up the user queries.
But due to their preferences like location, price range, seating capacity, etc. There will be presented in the child’s online activities and alert if the Cric Query is put to the services of hospitals, health institutes and drugstore access.
BEWARE it knows everything about you, but there is a critical skill requirement to access and use a planner type third party.
A text-based daily conversation buddy model will be free of charges for the restaurants compared to current general personality tests.
Based on the part of the disease.
Though the Talking Glossary is available in the field or farms.
No more waiting for a very cheap subscription.
AgriBud is a possibility to profit booking services for an individual, finding the right path so that he did panick for nothing.
We believe that automated demand response applications that can be classified in the university.
Особо классные моменты так и бросаются в глаза:
BEWARE it knows everything about you
После того, как результаты настолько заинтриговали, можно найти оригинал идеи и посмотреть, в чем же состоит ее суть.
Our idea is to create a personal chat bot like a friend-bot who knows everything about you Whenever you feel lonely or you are sad and no one is there to talk to you and due to some reason you cant approach your parents you can just talk to this bot. it can help you in any issue. It is going to track user’s current mood, asks a few simple questions. These questions are based on Cognitive Behavioral Therapy which is considered as the best form of talk therapy. Although a bot can never replace a real therapist, it digs deeper into the user’s mood and recommends to do something to cheer him/her up. More the user talks to the bot, better help he is going to get. BEWARE it knows everything about you, but there is nothing to worry about as it is not going to tell it anyone.:)
Облако слов
Так как все любят облака слов (и не говорите, что вы не один из таких!), я не мог его вам не сделать.
from wordcloud import WordCloud
from PIL import Image
mask_image = Image.open("mask.png")
mask = np.array(mask_image)
wordcloud = WordCloud(background_color="white", colormap='plasma',
width=mask_image.width, height=mask_image.height,
max_words=2000, mask=mask,
stopwords=stopwords.words('english'))
wordcloud.generate(summaries);
wordcloud.to_file("cloud.png");
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Заключение
Впереди нас ждет еще много работы, и мы надеемся, что ее результатом мы не будем разочарованы. Судьям предстоит не менее сложная работа: в заявленных темах встречаются и здравоохранение, и рекрутинг, и шопинг, и образование, и путешествия, и даже трейдинг и биткоины!
А пока мы на позиции низкого старта. Подготовили твиттер-аккаунт для того, чтобы писать туда заметки о проходящей разработке. Кстати, рекламный мини-видеоролик даже сняли, если вам будет интересно.
Буду рад выслушать любую критику, комментарии к вашим услугам.
