[Из песочницы] Мониторинг работы windows-службы с помощью Zidium
Зачем мониторинг?
Сначала о том, что такое мониторинг и зачем вообще он нужен. Был у меня заказ на приложение, которое должно собирать данные с нескольких систем, выполнять аналитику, и отправлять данные в систему отчётов. Приложение я реализовал в виде windows-службы, развернул на хостинге. Заказчик передал дальнейшее сопровождение службы мне на аутсорс, то есть я отвечаю за её работоспособность и за исправление ошибок.
Но возник вопрос — как мне отслеживать возможные проблемы со службой?
Что, если служба остановится из-за внутренней ошибки или зависнет? Я об этом не узнаю, пока заказчик не предъявит мне претензию, что данные несколько дней не обновлялись. Кроме того, мне нужны данные о случающихся ошибках, логи для анализа и т.п.
Какую информацию о состоянии службы я хочу иметь:
- Отслеживание сигнала активности (так называемое «биение сердца», heartbeat). Если служба остановится, сигнал перестанет поступать и станет понятно — что-то не так.
- Сбор подробной информации об ошибках. Мне же их исправлять. Так что нужно как можно больше данных — время, сообщение, стек и т.п.
- Ведение лога в облаке. Почему не файл? Служба работает на боевом сервере, туда доступ только у админа. Админ человек занятой, логи ему некогда искать и присылать мне. Или оказывается, что логи слишком большие и не отправляются через корпоративную почту. В общем, сложно всё с файлом.
- Уведомления о проблемах по email и, хорошо бы, по sms. Мне — об ошибках, админу — об остановке службы.
- Некоторая статистика по производительности — замер времени выполнения ключевых участков обработки данных. Это мне пригодится для оптимизаций.
- Ну и крайне желательно всё это иметь в одном месте, а не в разных системах учёта.
Вот тут на помощь и приходят системы мониторинга. Для этого проекта я выбрал мониторинг Zidium. Это облачная система мониторинга, которую можно использовать совершенно бесплатно неограниченное время. У него есть всё, что мне нужно, в одном флаконе.
Как это работает
Посмотрим сначала на исходный код службы, без мониторинга. Служба написана на C# в среде VS 2015.

Тут всё стандартно для windows — поток, бесконечный цикл с прерыванием работы, некоторая задержка в конце итерации.
Цикл выполняет методы, которые собирают, обрабатывают и отправляют данные. Что конкретно они делают, для этой статьи неважно.
Подключим Zidium к проекту. Это делается с помощью Nuget-пакета. Он добавляет dll и файл zidium.xml с настройками. В xml-файле я задал параметры доступа к аккаунту. Можно не использовать файл, а задавать всё программно, но мне показалось, что такой конфиг — это более правильно.
Все примеры использования я брал из документации на сайте Zidium.
Сначала создадим вспомогательный класс, который будет соединяться с системой и получать «компонент». В моём случае компонент — это сама служба и есть. Здесь всё как рекомендуется в документации, поправил только названия.

Чтобы проверить создание компонента, я вставил получение компонента в метод запуска сервиса и вызывал у него метод IsFake (дело в том, что компонент на стороне Zidium создаётся только когда с ним будет выполнена какая-то реальная работа). Для обычной работы это не нужно, после теста этот вызов можно удалить.

После запуска в личном кабинете появился компонент.

Цвет у него серый, потому что никаких данных мы пока не передавали.
Сигнал активности (HeartBeat)
Добавим теперь сигнал активности. Для этого используются так называемые «проверки» («unittests»).
В самом начале нужно создать для «компонента» саму проверку и запомнить её в переменной.
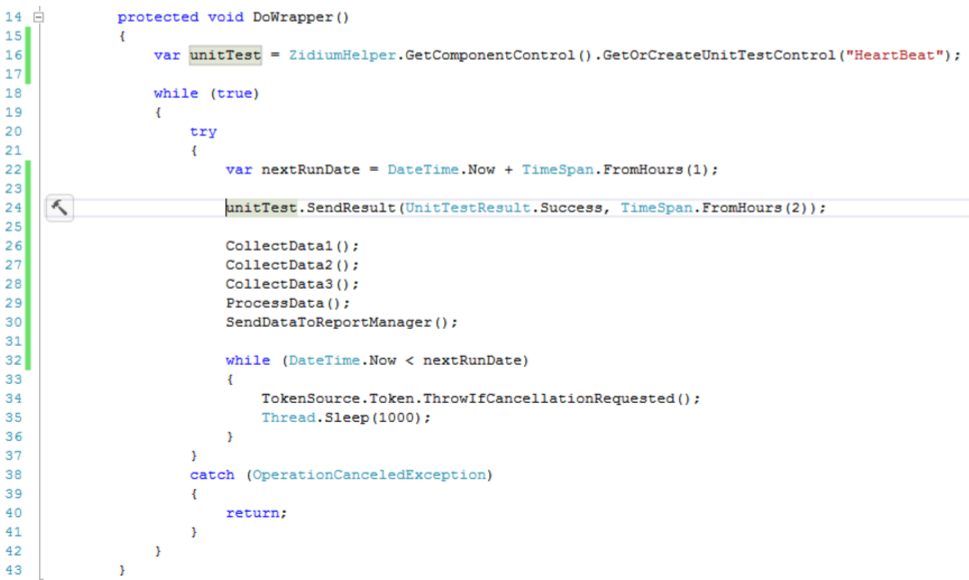
Теперь в каждой итерации рабочего цикла отправляем результат проверки, что служба работает как надо. При этом я указываю время актуальности. Это именно то время, через которое система поднимет тревогу, если очередной сигнал не поступит.
У меня данные собираются раз в час, поэтому я указал актуальность 2 часа — запас на 1 цикл работы. По хорошему, конечно, надо учитывать реальное время работы методов, но я решил не усложнять.
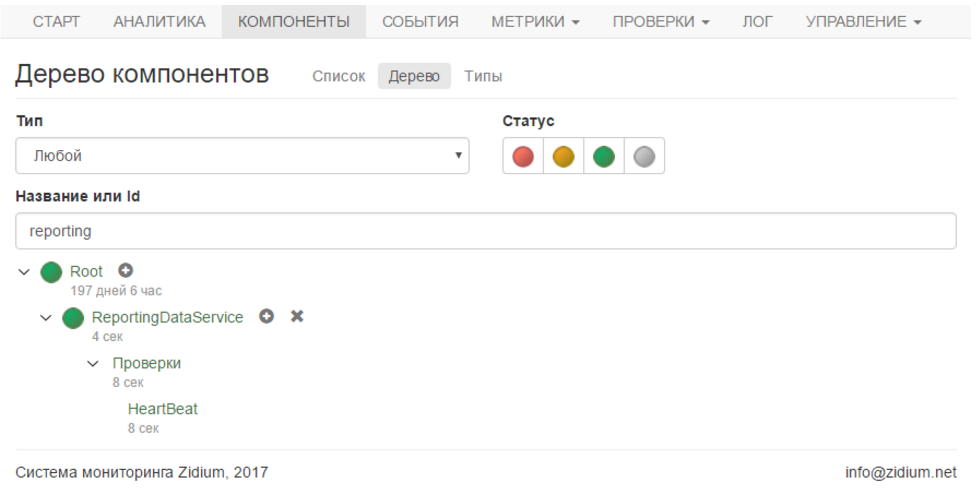
Запускаем службу, и в личном кабинете видим зелёный компонент и зелёную проверку. Всё хорошо.
Для теста я указал время актуальности 1 минуту (чтобы долго не ждать) и остановил службу.
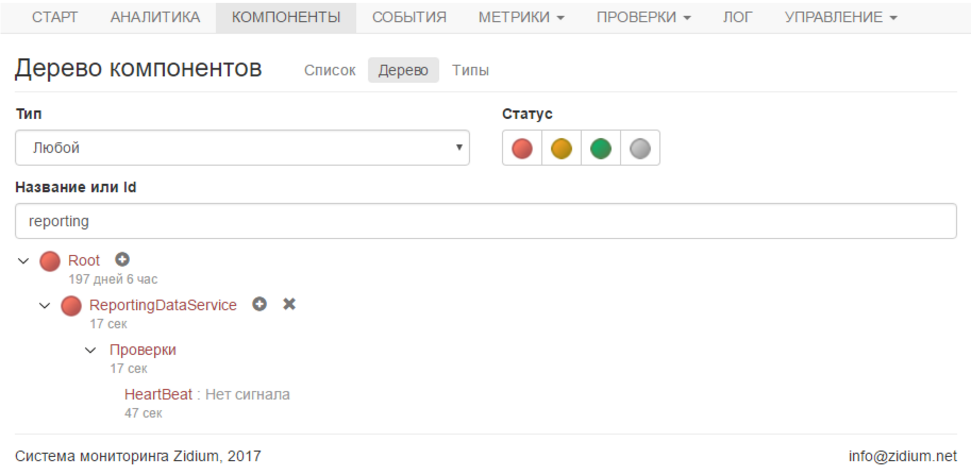
Через минуту компонент с проверкой стали красными, и мне на почту пришло письмо с уведомлением об отсутствии сигнала.
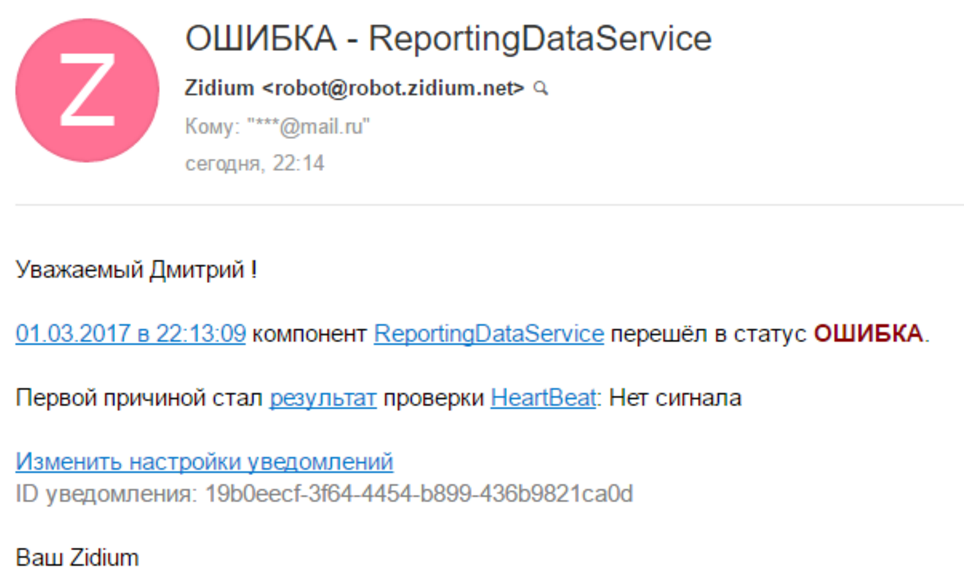
Все уведомления довольно гибко настраиваются, и можно получать их на email и по sms. У каждого пользователя свои контакты и свои настройки уведомлений. Отлично, эта задача решена.
Ошибки
Теперь разберёмся с ошибками. Здесь всё проще.
try {} и в catch отправляем ошибку. Есть удобный готовый метод, который из Exception выделяет сообщение, стек и т.п. и формирует ошибку.

Для теста я просто вызвал throw new Exception () в теле цикла. Вот как выглядит ошибка в личном кабинете:
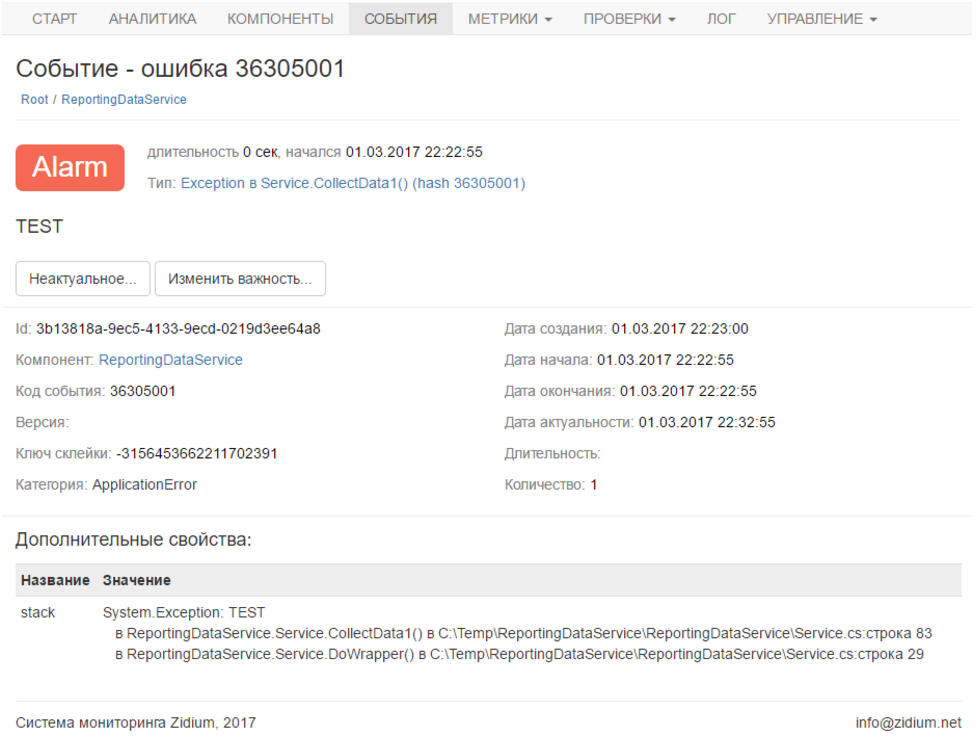
Опять же, я получаю о ней уведомление, если мне это надо.
Надо сказать, что Zidium довольно интеллектуально понимает, что несколько ошибок являются на самом деле одной и той же. Такие ошибки соединяются в одну, что очень удобно. И спама из уведомлений тоже не будет.
Лог
Далее у нас лог. Работа с логом сделана аналогично другим библиотекам логирования, таким как nLog или Log4Net. Просто пишем что хотим, указывая уровень (важность) записи.

Бонус — к каждой записи лога можно прикрепить любое количество допсвойств, в которые можно поместить что угодно — например, xml. Они не замусоривают сам лог, но их всегда можно посмотреть.
Вот так выглядит лог в личном кабинете:
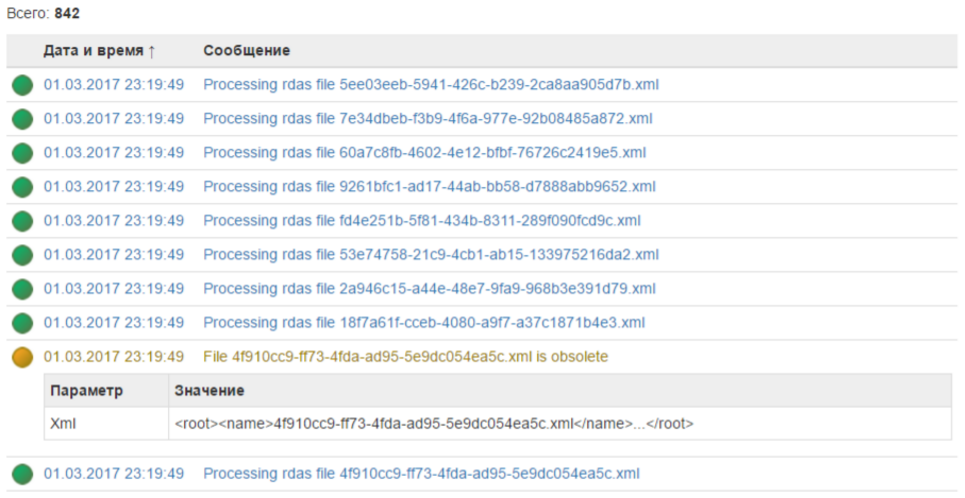
Для меня это гораздо удобнее, чем читать огромные тестовые файлы.
Помимо облачного лога, Zidium на всякий случай пишет и классический файловый лог (хотя это можно отключить). Приятно, что не надо подключать ещё и другие библиотеки логирования. Всё же файловый лог может оказать полезным в крайних случаях, например, если не было связи с облаком.
Производительность
Наконец, статистика по производительности. Для этого используются «метрики». Я замеряю общее время работы интересующих меня методов.
У метрики есть название и значение, и отправляется она так:
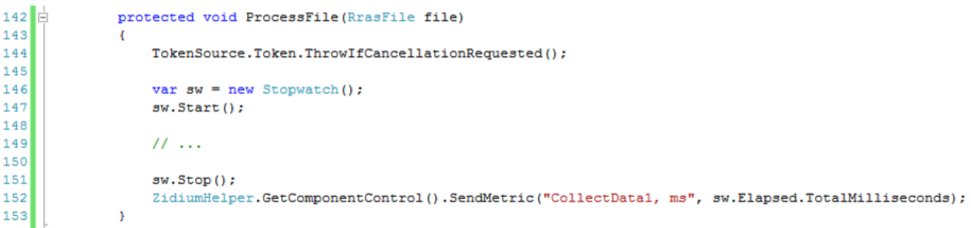
В личном кабинете можно посмотреть детально всю историю метрики.
Сразу же считаются основные агрегаты за выбранный период — максимум, минимум и среднее.
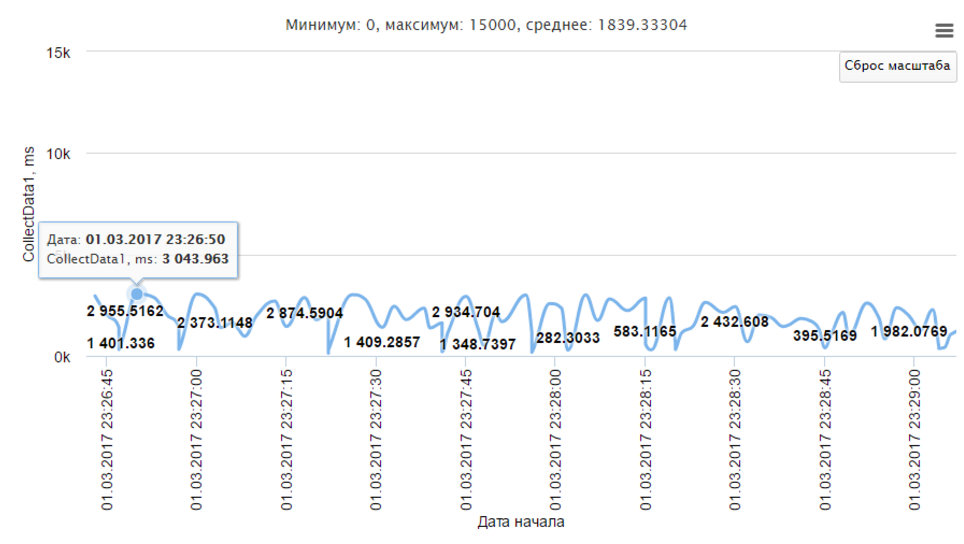
Жаль, нельзя скачать данные в формате xlsx или csv, это могло бы пригодиться для собственного анализа.
Ещё для метрик можно настраивать правила предупреждений о выходе значения за выбранный диапазон. Тогда о метриках тоже будут приходить уведомления. Но я это не использовал, мне полезно просто иметь статистику времени работы.
Итого
Моя служба посылает в мониторинг сигнал активности, собирает ошибки, пишет облачный лог и ведёт статистику производительности.
Я получу уведомление, если служба вдруг остановится или зависнет. Я получу уведомление, если возникнет любая ошибка.
Теперь я спокоен за сделанную мной работу и за выполнение обязательств перед заказчиком)
Комментарии (2)
 fsou11
fsou11
14 марта 2017 в 16:04
0↑
↓
Отличная работа. Подскажите, есть ли возможность в ЛК использовать собственные события/обработчики (action’ы)? Например, как бы вы решили задачу публикации уведомления в telegram наравне с почтой и sms?14 марта 2017 в 16:13
+1↑
↓
Помимо уведомлений по email и sms у них есть уведомления по http. Система делает post-запрос на указанный адрес и передаёт в json информацию о событии. Соответственно, можно сделать свой web-сервис, который будет принимать данные в json и публиковать в telegram.
Я сам это не пробовал, но обещают, что должно работать.
Можно если что разработчикам на сайте написать, уточнить.
