[Из песочницы] Как я считал рукопожатия или «Уверен ли ты, что хочешь знать друзей друзей друзей друзей»
Заголовок, конечно же, лживый. Считал я не рукопожатия, а пользователей между двумя заданными. Хотя, никто не мешает добавить единичку.Для затравки оставлю здесь картинку:
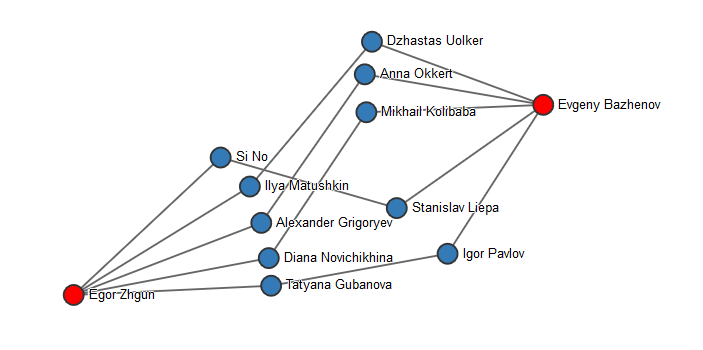 От безделья передо мной стояла задача: есть два пользователя vk.com, необходимо найти цепочку других пользователей, через которых они знакомы. Ну и, конечно, предоставить результат в удобном виде.
От безделья передо мной стояла задача: есть два пользователя vk.com, необходимо найти цепочку других пользователей, через которых они знакомы. Ну и, конечно, предоставить результат в удобном виде.
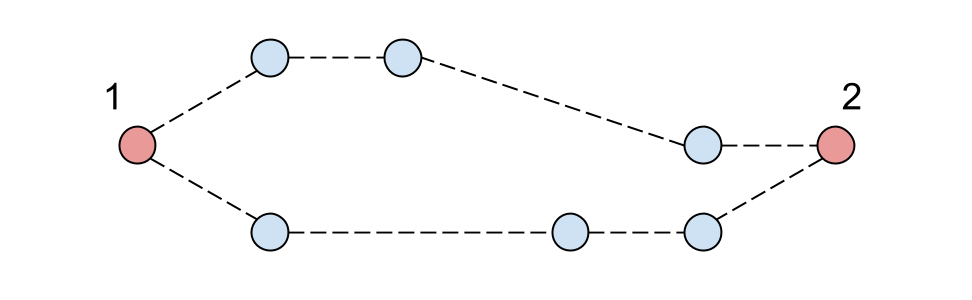
Должно было получиться что-то вроде:
1. Первое, что приходит в голову — это рекурсивно построить деревья друзей для каждого пользователя. Но для моей задачи достаточно одного дерева. Второе будет только кушать память.
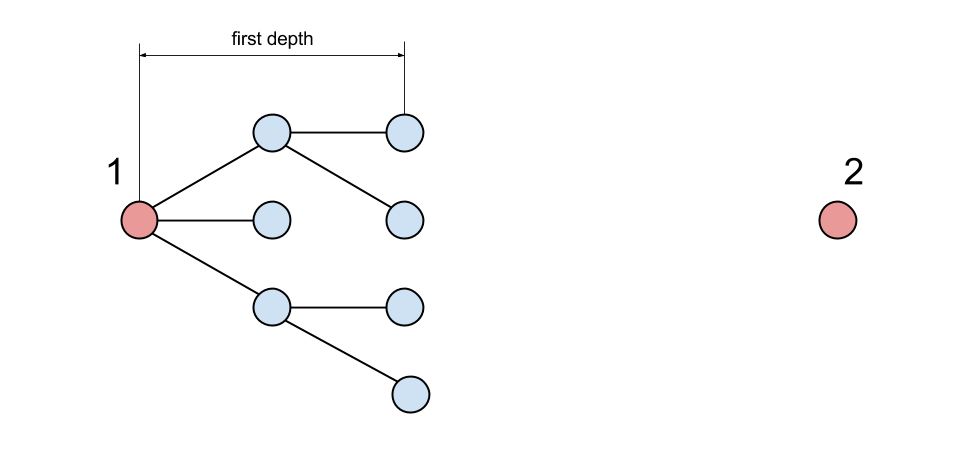
Вытянем через VK API для первого пользователя его друзей, друзей друзей и т. д. до глубины поиска (first depth), которую примем за 3. Три — удобная величина, потому что два — мало, а четыре заставят браузер ощутимо залипать. Строя такие структуры, надо помнить, что с увеличением глубины на единицу число пользователей увеличивается на два порядка (число Данбара).
2. Затем можно сделать то же самое со вторым, но не сохраняя результат в памяти. Всё, что нужно — это проверять, находится ли каждый найденный пользователь в дереве из п.1.
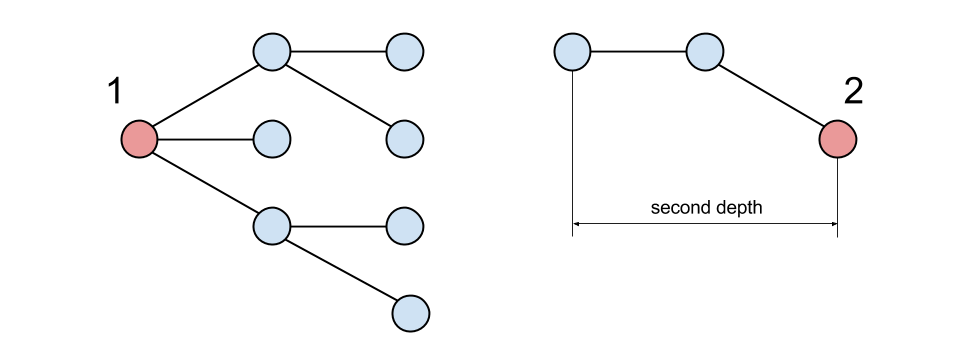 *second depth — это, как можно догадаться, глубина поиска для второго. Её величина во многом определяет скорость работы, об этом ниже
*second depth — это, как можно догадаться, глубина поиска для второго. Её величина во многом определяет скорость работы, об этом ниже
3. В случае совпадения вся цепочка сохраняется:
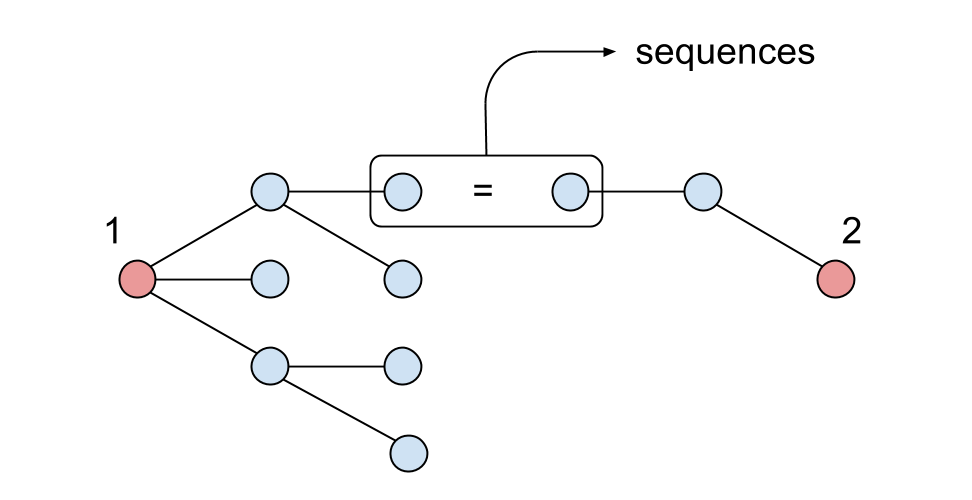
4. На выходе имеем последовательности идентификаторов пользователей между двумя заданными, включая их:
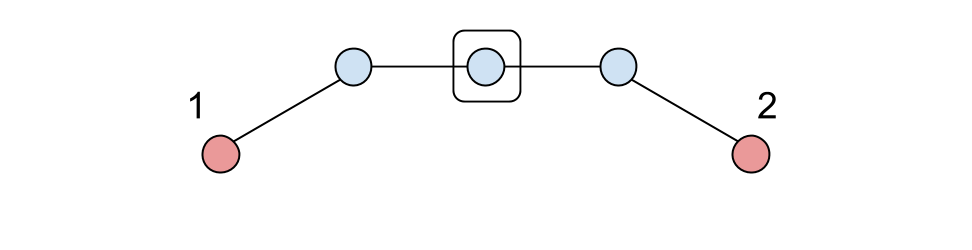 *обведён общий из п.2.
*обведён общий из п.2.
5. С полученным массивом последовательностей остаётся сделать всего лишь две вещи: оставить последовательности минимальной длины и удалить дубликаты.
6. PROFIT! В работе попробовать можно здесь: artfultom.github.io/whom-i-know
Задача решена IMHO «в лоб», реализацию можно пощупать, работает с приемлемой скоростью. Небольшие замечания:
Слабым местом является функция для поиска идентификатора из дерева второго пользователя в дереве первого (п.2). Поэтому чем меньше она используется, тем быстрее можно увидеть результат. А она используется тем меньше, чем меньше глубина поиска для второго (second depth). В этом легко убедиться, если в приложении по приведённой мной ссылке поменять максимальную длину цепочки. Для длины 4: first depth равна 3, а second depth — 2. Для длины 5 обе равны 3; На практике самым интересным вариантом является самый простой с длиной цепочки 4. Для больших значений результаты «слишком многословны» и включают множество пользователей-тысячников; Сложно найти пользователей, не знакомых через троих.
