[Из песочницы] Генератор проектов
В последующих разделах статьи мы рассмотрим некоторые технические аспекты нашего подхода к инструментальному обеспечению разработки больших программно-информационных комплексов, причем с учетом исторического развития наших собственных взглядов на эту проблематику. Той части аудитории, которой это наше «самокопание» покажется чересчур усердным, мы предлагаем сразу переходить к разделу «Текущая ситуация», где мы, резюмируя весь материал, постараемся максимально четко сформулировать, что именно мы предлагаем оценить и обсудить широкому сообществу разработчиков.
Исторический экскурс для понимания мотивации разработчиков
Генератор проектов был заложен более четверти века назад, когда коллектив разработчиков вынужден был по известным причинам завершить работы над проектами в авиационных КБ и начать искать применение приобретенного опыта в других областях.
Работая над несколькими проектами в банковской сфере получилось так, что нам пришлось писать несколько систем, состоящих из множества однотипных элементов, отличающихся только составом параметров. Разрабатываемые системы строились по тогда еще новой технологии двухуровневый клиент-сервер: рабочее место — сервер — база данных. Каждый элемент системы на клиентском рабочем месте в общем виде реализовал экран с формой ввода данных, несколько таблиц и несколько кнопок или пунктов меню для выполнения некоторых действий и, возможно, перехода к другому экрану. В протоколе клиент-сервер нужно было запрограммировать передачу соответствующих данных и прием ответа сервера. На сервере предусматривалась процедура получения параметров запроса, их анализ, выполнение требуемых запросов к базе данных, передача результатов в виде ответа на запрос клиента.
Таким образом работа выполнялась как бы в двух измерениях. Одно из них — это разработка новых таких фрагментов, которые мы назвали процедурами. Новые процедуры появлялись по мере разработки, а также при уточнении задачи. Старые процедуры модифицировались.
Здесь слово «процедура» используется не в смысле, к примеру, языка Паскаль, т.е. нечто вроде подпрограммы, функции и т. п. Скорее это некий шаблон программного кода.
Второе измерение — это сама технология реализации процедур. Изменялся протокол, подключались различные подсистемы безопасности, что приводило к необходимости изменения программного кода сразу все реализованных ранее процедур, причем как в клиентских, так и в серверных программах.
Кроме того, при большом количестве процедур стало проблемой поддержание целостности проекта в части соответствия клиентских и серверных программ протоколу их взаимодействия. Например, если в некотором запросе добавлялся новый параметр, то соответствующие правки надо выполнять согласованно в двух разных программах — в клиенте и в сервере.
В связи с изложенным возникла идея автоматизировать этот процесс. У нас к тому времени был опыт реализации программ синтаксического анализа сложных языков (система концептуального программирования Факир с иерархическим описанием алгебраических моделей, аналитическими формульными вычислениями и прочими сейчас неактуальными задачами).
В результате был разработан язык описания проектов, состоящий из заголовка с различными параметрами проекта и набора описаний процедур. Каждая процедура имела уникальное имя, список входных параметров, перечень запросов к серверу со спецификацией входных и выходных параметров и типом ответа — таблица или один комплект, а также перечень предусмотренных действий, которые могут быть выполнены в контексте данной процедуры.
Именованные типы данных, используемые в процедурах, задавались как часть проекта в его описании. Естественным образом производился контроль описания на предмет соответствия разных компонент по составу типам.
Такое описание подавалось на вход генератора проектов, который строил модель проекта в памяти, ее анализ на предмет целостности. Далее на основе модели производилась генерация текстов программ, реализующих клиентские и серверные программные модули.
Клиентские программы в простейшем случае генерировались в законченном виде, но в особых случаях можно было заказать программные вставки ручной работы для выполнения специальных действий, не предусмотренных в описанной простой модели проекта.
Сами программы проекта реализовывались на языке Си. Сервер в те времена был на платформе VAX VMS, клиентские программы на IBM PC под управлением MS DOS (но предусматривались и на VAX VMS). Серверные запросы писались на препроцессоре над Си, который понимал встроенные в текст Си-программы SQL-запросы.
Описание проекта предусматривало также описание таблиц базы данных в терминах описанных типов. Это позволяло в описании проекта формулировать упрощенные запросы к базе на некотором подмножестве языка SQL с полным их синтаксическим анализом на предмет соответствия заданной схеме базы. Более сложные запросы реализовывались в серверных программах средствами препроцессора.
Описанная технология прижилась и выдержала испытание временем в течение десятилетия. С ее помощью было сделано изрядное количество проектов в разных областях.
Модель проекта совершенствовалась, усложнялась. Менялись программно-аппаратные платформы. Клиенты и серверы стали функционировать в MS Windows и Linux.
Разработка в упомянутых двух измерениях позволяла отделить работу аналитиков от работы системных программистов. Аналитик концентрировался на прикладных задачах, а системный программист на операционных системах, протоколах, языках и пр.
Главное достоинство такой технологии — существенное сокращение кода, который пишет разработчик системы. Описание одной процедуры может занимать несколько десятков строк, а сгенерированный программный код на Си как правило на порядок больше. Изменение системных программных средств мало затрагивает код прикладного разработчика, такие изменения учитываются в новых версиях генератора.
Использование генератора проектов позволило реализовывать сложные объемные проекты минимальным количеством разработчиков, зачастую одним человеком, причем этим занимались люди, не сведущие в тонкостях программирования, а имеющие математическую подготовку и опыт разработки систем. Т.е. не программист, а аналитик мог самостоятельно заложить сложный проект и довести его до рабочего состояния без привлечения системных программистов.
Для обеспечения удобства разработки в генераторе постоянно совершенствовались различные вспомогательные функции оформления проекта. Кроме текста программ генерировались многочисленные командные файлы для выполнения трансляции и сборки всех компонент программ для разных платформ. Генерировались утилиты создания и модификации базы данных. Автоматизировалась процедура формирования инсталляционных пакетов для передачи заказчику.
Следует отметит небольшую терминологическую путаницу. Описанный выше язык описания проектов часто обозначался, как непроцедурный язык, в том смысле, что в нем не было программных операторов, как в Си, Паскаль и т. п. А упомянутые процедуры в языке проектов — это совсем другие понятия.
Переход от непроцедурной модели проекта к универсальному языку программирования
По мере роста аппетита во время еды в начале 2000-х годов созрело понимание, что надо используемую технологию разработки проектов совершенствовать далее.
Во-первых, стали тесными рамки самой модели проекта, как комплекта типов, базы данных и набора процедур с запросами.
Во-вторых, использования языка Си в серверных, а иногда и в клиентских программах, стало утомлять. Слишком низкий уровень для аналитика — копаться в деталях и тонкостях передачи параметров, указателей, зеро-байтах и пр.
С другой стороны, появились проекты, в которых пришлось писать не простые запросы к базе на потребу банковской бухгалтерии, а объемные программы со сложными структурами данных. В таких проектах эффект автоматической генерации программного текста снижался, так как приходилось писать много ручного кода.
С переходом на оконный интерфейс появилась возможность, а, как следствие, и необходимость изображать в клиентских программах не только таблицы с текстами и числами, но и всяческое другое содержимое в виде картинок, чертежей.
В связи с этим потребовалось усложнить протокол взаимодействия клиент-сервер. Все это стало стимулом к разработке совершенно нового генератора проектов.
В основу новой разработки была заложена концепция структурного документа. Документ в контексте генератора проектов занимает одно из центральных понятий. На разговорном уровне документ — это база данных сетевой структуры в памяти программы.
Сетевая структура документа (базы данных) предполагает, что в нем хранятся таблицы, между строками которых установлены связи типа «один ко многим». Это старая, позабытая концепция баз данных сетевой структуры, которую мы использовали в давних разработках.
Основная идея заключалась в том, что клиентская программа получает информацию от сервера не в виде нескольких кортежей и таблиц, а в виде произвольного документа зафиксированной для данного запроса структуры. И, симметрично, клиент, выполняя запрос, тоже присылает в общем виде документ.
Таким образом, на сервере необходимо уметь прочитать входной документ из протокола, восстановив его структуру в памяти. Далее, на основании полученного документа выполнить некую программу, именуемую сейчас бизнес-логикой, в которой предполагается взаимодействие с базой данных (настоящей, не в памяти). В результате программа должна сформировать выходной документ для передачи его в клиентскую программу по протоколу.
В клиентской программе следует предусмотреть программу формирования содержимого окна приложения на основе полученных данных.
Изначальный проект предполагал, как и предыдущие версии генератора, использование языка Си для написания тел серверных запросов, а также программ формирования содержимого окна приложения. В качестве экспериментального средства был разработан относительно простой язык программирования, призванный в простейших случаях заменить собой язык Си. Это язык был частью языка описания проекта в целом и получил условное название базового языка генератора.
Ниже перечислены основные понятия базового языка.
Описание именованного типа данных — строка заданной фиксированной длины, числа разной разрядности, перечислимый тип, масочный тип (битовая маска с именованными компонентами), структура, и, наконец, документ, упомянутый выше.
Процедура (аналог функции в Си) с параметрами указанных типов, в том числе и документов.
Основные стандартные операторы — присваивание, условный оператор, цикл for, цикл while, вызов процедуры, выражения. Все очень похоже на обычные стандартные языки. Для типа-документа автоматически становятся доступны процедуры манипулирования его компонентами.
Результат был сокрушительным — через некоторое время в текущих проектах доля программ на языке Си стремительно уменьшилась до незначительных размеров. Как-то само собой получилось, что разработчики проектов стали писать исключительно на данном языке не только модель проекта, но и все программы как на клиенте, так и на сервере.
Апофеозом этого неожиданного процесса стало написание самого генератора на его базовом языке.
Архитектуры генератора проектов на разных этапах его разработки
Изначально структура генератора предполагала на входе описание проекта, набор текстов ручных программ на языке Си и препроцессоре базы данных для Си. На выходе совокупность результирующих программ на Си и скрипты трансляции, сборки, формирования дистрибутива и прочих полезных действий.
Структура генератора на этом этапе разработки имела вид на приведенном ниже рисунке.

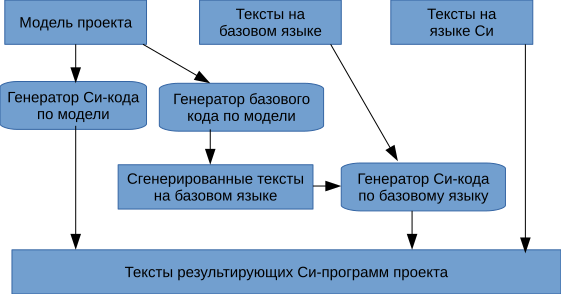
С появлением базового языка структура генератора стала следующей. В генераторе выделились две компоненты — генератор Си-кода из модели проекта и генератор Си-кода из текстов на базовом языке.
Модель проекта содержит сущности высокого уровня, такие как сервер, приложение, порт сервера, подсистема безопасности, тип окна приложения, диалог, и много всяких других полезных вещей. Все эти модельные сущности в процессе генерации проекта порождают реализующие их программы на языке Си.
Разработчик также пишет свои куски Си-программ, котрые по определенным правилам включаются в результирующий комплект Си-программ проекта.
Теперь часть ручных Си-программ стало возможным заменить на эквивалентные программы на базовом языке, которые легче интегрируются с моделью проекта.
Таким образом с появлением базового языка структура генератор приобрела вид, изображенный на следующем рисунке.

В процессе развития базового языка объем входных текстов на нем рос, а на Си — уменьшался. А по мере развития языка описания модели уменьшался и объем кода на базовом языке, заменяясь на короткие и емкие описания модельных сущностей.
Вследствие усложнения модельной компоненты описания проекта возникла идея генерировать по модели не сразу Си-код, а код на базовом языке. Это упростило сам генератор, так как отпала необходимость следить за тонкостями адресации в Си для реализации модельных сущностей. За всем этим следит транслятор базового языка в Си.
В результате структура генератора стала следующей.
Основные понятия базового языка генератора
Базовый язык — это часть генераторного языка описания проекта, реализующая универсальный язык программирования. Разработчик с помощью генератора проектов имеет возможность писать обычные программы на этом языке, но в составе некоторого проекта.
В отличие от Си здесь нет возможности написать и оттранслировать отдельную программу на базовом языке. Даже если ваша программа состоит из нескольких десятков операторов, все равно вы должно описать некий проект, в котором в качестве единственной компоненты будет ваша программа, как пакет типа утилиты — консольное приложение.
В более сложном случае программа на базовом языке может состоять из нескольких пакетов.
Пакет — одно из основных понятий генераторного (и базового) языка. Пакет имеет уникальное в пределах проекта имя, заявлен как пакет некоторого типа и, как правило представлен в виде отдельного файла с текстом программы пакета.
Описание проекта — это файл описания проекта с заголовком и упорядоченным перечнем пакетов.
В составе генератора есть большой набор так называемых системных пакетов разного типа, которые написаны разработчиками генератора и могут быть использованы явно или неявно через модельные сущности в ваших проектах. Пакеты разработчика не должны совпадать по именам с системными пакетами.
Приведем пример простейшего проекта типа «Hello world». Мы здесь не будем рассматривать структуру директорий проекта. В нашем случае мы должны создать два файла — описание проекта и описание утилиты в составе проекта, придумав для них имена.
Пусть имя проекта — hello, имя утилиты в составе проекта — world. Тогда мы должны создать два текстовых файла hello.gen и world.utility.
Файл hello.gen:
project hello
/version="01.001"
utility world
Файл world.utility:
utility world:"world"
main
{ dprint("Hello world!");
}
В результате генерации и сборки такого проекта будет получен исполняемый модуль world.exe (для MS Window) или world (для Unix). При запуске программа напечатает в консоли строку «Hello world!».
Рассмотрим более сложный пример, в котором кроме пакета утилиты используется простой пакет типа package.
Файл pkgexample.gen:
project pkgexample
/version="01.001"
package mypkg
utility myutl
Файл mypkg.package:
package mypkg
type t_myint : int;
fprocdecl sum(t_myint a,t_myint b,out t_myint c);
implementation
fproc localsum(t_myint x,t_myint y,out t_myint z)
{ z := x+y;
}
fprocdecl sum(t_myint a,t_myint b,out t_myint c)
{ call localsum(a,b,c);
}
Файл myutl.utility:
utility myutl:"myutl"
main
{ var
mypkg.t_myint p := 3,
mypkg.t_myint q := 5,
mypkg.t_myint r;
call mypkg.sum(p,q,r);
dprint("p=",p," q=",q," r=",r,"\n");
}
В данном случае мы в составе проекта имеем два пакета — программный пакет mypkg и утилиту myutl.
В пакете mypkg в разделе внешних спецификаций (до ключевого слова implementation) дано описание типа t_myint, выведенного из базового типа int (целое 32-х разрядное число), и спецификация процедуры sum с двумя входными параметрами a, b типа t_myint и одним выходным параметром с того же типа.
Все, что написано после ключевого слова implementaion, доступно только внутри пакета.
Процедура localsum имеет похожий заголовок, как и у внешней процедуры sum, но начинается с ключевого слова fproc, что означает, что это локальный объект. После заголовка вместо точки с запятой располагается блок операторов в фигурных скобках, очень похожий на таковой в языке Си. Внутри блока имеется один оператор присваивания. В отличие от вульгарного равенства присваивание здесь задается символами »:=».
Разработчикам генератора, как людям с базовым математическим образованием, было больно смотреть на такие конструкции в Си-подобных языках, как a=a+1. Было принято решение использовать алголо-паскальную нотацию в таких операторах.
После локальной процедуры localsum располагается тело декларированной в разделе спецификаций внешней процедуры sum. Описание ранее специфицированной процедуры похожа на описание локальной процедуры, но с ключевым словом fprocdecl и точной копией параметров. Далее идет блок тела процедуры, в котором располагается вызов локальной процедуры localsum.
В пакете myutl по-прежнему есть единственный раздел main с операторным блоком в фигурных скобках. Раздел main должен быть в утилите ровно в одном экземпляре в конце пакета. Это аналог функции main в языке Си. Операторы этого блока выполняются при запуске утилиты.
В блоке расположены три оператора. Первый оператор — описание трех переменных p, q, r, причем первые две инициализируются константными выражениями. Типы переменных заданы в виде имени пакета, за которым через точку идет имя типа, определенное в этом пакете.
Второй оператор — вызов процедуры sum из пакета mypkg, заданной, как и типы, точечным выражением.
Третий оператор — отладочная печать в консоль.
Столь вычурное программирование вычисления суммы двух целочисленных констант сделано исключительно с целью продемонстрировать как можно больше возможностей базового языка с минимальным размером предъявленного на суд публики текста.
Более сложный пример демонстрирует работу с типом-документом.
Файл docexample.gen:
project docexample
/version="01.001"
package doc
utility doctest
Файл doc.package:
package doc
type t_orgname : char8[100];
type t_addr : char8[100];
type t_phone : char8[30];
type t_empname : char8[100];
type orgs : dqueue
(
record org
( t_orgname orgname,
t_addr addr,
t_phone phone
);
record emp
( t_empname empname1,
t_empname empname2,
t_empname empname3,
t_addr addr,
t_phone phone
);
set orgs_org member org;/oper=(mem,next)
set org_emp owner org member emp;/oper=(mem,next)
);
procdecl fill(orgs porgs);
implementation
procdecl fill(orgs porgs)
{ var
int iorg;
rand.init();
for ( iorg := 0; iorg < 6; iorg += 1 )
{ var
org xorg,
int iemp;
org_cre(porgs,xorg);
rand_test.firm8(xorg.orgname);
rand_test.addr8(false,xorg.addr);
rand_test.phone(xorg.phone);
orgs_org_ins(porgs,xorg,-1);
for ( iemp := 0; iemp < 8; iemp += 1 )
{ var
emp xemp;
emp_cre(xorg.xdoc,xemp);
rand_test.name8(xemp.empname1,xemp.empname2,xemp.empname3);
rand_test.addr8(true,xemp.addr);
rand_test.phone(xemp.phone);
org_emp_ins(xorg,xemp,-1);
}
}
}
Файл doctest.utility:
utility doctest:"doctest"
proc test(doc.orgs porgs)
{ call doc.fill(porgs);
{ var
doc.org xorg;
doc.orgs_org_mem(porgs,0,xorg);
while ( isnotnull(xorg) )
{ dprint("\n");
dprint(U"Наименование: ",xorg.orgname,"\n");
dprint(U"Адрес: ",xorg.addr,"\n");
dprint(U"Телефон: ",xorg.phone,"\n");
var
doc.emp xemp;
doc.org_emp_mem(xorg,0,xemp);
while ( isnotnull(xemp) )
{ dprint("\n");
dprint(U" Фамилия: ",xemp.empname1,"\n");
dprint(U" Имя: ",xemp.empname2,"\n");
dprint(U" Отчество: ",xemp.empname3,"\n");
dprint(U" Адрес: ",xemp.addr,"\n");
dprint(U" Телефон: ",xemp.phone,"\n");
doc.org_emp_next(xemp);
}
doc.orgs_org_next(xorg);
}
}
}
main
{ varobj
doc.orgs porgs;
call test(porgs);
}
В проекте docexample представлены два пакета — doc.package и doctest.utility.
В пакете doc описаны символьные типы t_orgname, t_addr, t_phone, t_empname в кодировке UTF-8 с указанными длинами.
Тип orgs — документ (ключевое слово dqueue). В нем описаны два типа записей org и emp — организация и сотрудник. В скобках перечисленные компоненты записей указанных типов. В сущности это аналогично описанию базы данных с двумя таблицами и заданными колонками в них.
Сетевая структура задается отношениями между записями типа «один ко многим». Такие связи вводятся как наборы (set). Так, набор org_emp вводит связь между организацией и сотрудником, в организации может работать много сотрудников, но каждый сотрудник работает не более чем в одной организации. Ключевое слово owner (владелец набора) задает тип записи-владельца набора. Ключевое слово member (член набора) задает тип записи-члена набора.
Набор без владельца (в нашем случае orgs_org) называется сингулярным, существует в единственном экземпляре в документе (его владельцем условно является весь документ/база данных).
Декларация типа-документа автоматически декларирует типы-записи такого документа с именами, совпадающими с именами записей. При этом следует помнить об уникальности имен типов в пределах пакета.
Кроме того, для каждой записи и для каждого набора автоматически генерируются и становятся доступными процедуры манипулирования этими объектами.
Так, для записи org создается процедура org_cre с двумя параметрами: ссылка на документ, выходная переменная типа запись для получения ссылки на создаваемый экземпляр записи.
Для набора org_emp создается процедура org_emp_ins с тремя параметрами: ссылка на экземпляр типа org — записи-владельца набора, ссылка на экземпляр типа emp — записи-члена набора, целое число — позиция в наборе (отрицательные числа — нумерация с конца набора).
Для набора org_emp создается также процедура org_emp_mem с тремя параметрами: ссылка на экземпляр типа org — записи-владельца набора, целое число — позиция в наборе, выходной параметр — ссылка на экземпляр типа emp — записи-члена набора.
Для набора org_emp создается процедура org_emp_next с одним параметром типа emp (входной и выходной) для перемещения на следующий элемент набора.
Многофункциональные выражения isnull (…) и isnotnull (…) применимы к переменным типа записей документа.
В данном проекте задействованы системные пакеты rand и rand_test для генерации случайных тестовых данных.
Для демонстрации возможностей синтаксического анализа рассмтрим еще один пример проекта.
Файл calc.gen:
project calc
/version="01.001"
utility calc
Файл calc.utility:
utility calc:"Calculator"
type t_double : double;
/frac=6
procspec syn_add(string7 buf,tlex.t_lex xlex,out t_double dval);
proc syn_fact(string7 buf,tlex.t_lex xlex,out t_double dval)
{ dval := 0.0;
if ( tlex.sample(buf,xlex,"(") )
{ call syn_add(buf,xlex,dval);
tlex.sample_err(buf,xlex,")");
}
else if ( tlex.double(buf,xlex,NOSIGN,NOFRAC,NOEXPON,dval) )
;
else
tlex.message(buf,xlex,"syntax error");
}
proc syn_mul(string7 buf,tlex.t_lex xlex,out t_double dval)
{ call syn_fact(buf,xlex,dval);
for ( ; ; )
{ var
t_double dval1;
if ( tlex.sample(buf,xlex,"*") )
{ call syn_fact(buf,xlex,dval1);
dval *= dval1;
}
else if ( tlex.sample(buf,xlex,"/") )
{ call syn_fact(buf,xlex,dval1);
dval /= dval1;
}
else
break;
}
}
proc syn_add(string7 buf,tlex.t_lex xlex,out t_double dval)
{ var
bool minus;
if ( tlex.sample(buf,xlex,"+") )
;
else if ( tlex.sample(buf,xlex,"-") )
minus := true;
call syn_mul(buf,xlex,dval);
if ( minus )
dval := -dval;
for ( ; ; )
{ var
t_double dval1;
if ( tlex.sample(buf,xlex,"+") )
{ call syn_mul(buf,xlex,dval1);
dval += dval1;
}
else if ( tlex.sample(buf,xlex,"-") )
{ call syn_mul(buf,xlex,dval1);
dval -= dval1;
}
else
break;
}
}
proc syn(string7 buf,tlex.t_lex xlex,out t_double dval)
{ call syn_add(buf,xlex,dval);
tlex.eof_err(buf,xlex);
}
main
{ if ( utl.argc(xutl.yutl) <> 2 )
error U"Не задан параметр";
var
tlex.t_lex xlex,
t_double dval;
call syn(utl.argv7(xutl.yutl,1),xlex,dval);
dprint("result=",dval,"\n");
}
Демонстрируется разработка утилиты калькулятора, на вход которого подается выражение, на выходе — вычисленное значение выражения.
Использование системного пакета синтаксического разбора tlex позволяет решить задачу разбора выражения очень просто и минимальным объемом кода, используя широкие встроенные возможности этого пакета. В данном примере видно, как легко и компактно можно решать вопросы синтаксического разбора.
В проекте задействован системный пакет tlex — лексический разбор в строке. Синтаксический разбор производится методом рекурсивного спуска. Каждому нетерминальному символу грамматики соответствует процедура в программе разбора.
Грамматика должна быть приведена к такому виду, чтобы по результатам выяснения, какой терминальный символ расположен в позиции чтения, можно было принять решение, какое правило грамматики применить для разбора. Приведение к такому виду для большинства существующих языков не составляет труда. Для этого достаточно определить надъязык, допускающий некорректные с точки зрения исходной грамматики тексты. В дальнейшем на основе построенного дерева разбора (в том или ином виде) можно проверить корректность.
По сути дела это в реальных трансляторах производится всегда, так как реальные программы не описываются контекстно-свободными грамматиками. КС-грамматика вряд ли может описать язык, в котором запрещено использование самых разных объектов (типов, процедур, переменных) без их описания. Так что такого рода проверки делаются в любом случае.
В нашем случае разбор выполняется в утилите calc для входной строки-параметра вызова программы в консоли. Если не задан ровно один параметр, то выдается сообщение об ошибке. Если параметр задан, то производится его синтаксический анализ с вычислением результата. При успешном анализе в консоли печатается результат вычисления. При ошибке выдается диагностическое сообщение с информацией, в какой позиции текста обнаружена ошибка.
Грамматика на словах. Аддитивное выражение — это последовательность мультипликативных выражений, разделенных знаками операций + или -. Мультипликативное выражение — последовательность множителей, разделенных знаками операций * или /. Множитель — аддитивное выражение в круглых скобках или число.
Аддитивное выражение соответствует процедуре syn_add, мультипликативное выражение — syn_mul, множитель — syn_fact.
Параметры синтаксических процедур: buf — анализируемый текст, xlex — контекст лексического анализа (в том числе позиция чтения), dval — выходной параметр — вычисленное значение.
Используемые лексические процедуры пакета tlex.
Функция tlex.sample — проверяет в текущей позиции наличие предъявленного в параметре образца. Если образец начинается с буквы, то распознаваемый текст должен целиком совпадать с образцом, а не содержать образец в качестве подстроки. Т.е. если мы проверяем наличие образца proc, то текст procdecl в позиции чтения не даст утвердительного результата. При распознавании любой лексемы пропускаются все символы пробелов, концы строк, табуляторы и пр. Пропускаются также комментарии в стиле языка Си и Си++.
Процедура tlex.sample_err — проверяет процедурой tlex.sample наличие образца, при отсутствии инициирует фатальную ошибку с текстом сообщения, содержащим информацию о позиции чтения анализируемой строки.
Такие пары функций/процедур присутствуют в пакете tlex для многих видов лексем. Функция позволяет проверить наличие лексемы, процедура проверяет и при отсутствии инициирует ошибку.
Процедура tlex.double — проверяет в текущей позиции наличие десятичного числа в виде 123.456. Параметр NOSIGN запрещает на уровне лексики знак ±, эти знаки мы распознаем на уровне грамматики. Параметр NOFRAC разрешает числа как с десятичной точкой, так и без нее.
Промежуточные итоги
В предыдущем разделе приведены примеры проектов, демонстрирующие некоторые возможности базового языка. Отметим, что это не справочник, не руководство по языку и даже не набор примеров для обучения. Это всего лишь ознакомительный текст.
Если читатель добрался до этого места, у него возникает вполне логичный вопрос — что в этом базовом языке такого, чего нет в других языках, и зачем понадобилось тратить силы и средства для его реализации?
Во-первых, базовый язык является часть полного генераторного языка описания проектов. В генераторном языке существует много разнообразных конструкция для описания таких модельных сущностей, как база данных, sql-запрос, сервер, порт сервера, приложение, макет экрана приложения, диалог, конфигурационный файл, json-преобразование для произвольных типов данных, абстрактный набор связанных таблиц для отображения в разных средах (dom-модель, gtk, qt) и т. п. Этот список постоянно обновляется, устаревшие сущности отмирают, появляются новые. И все эти конструкции реализуются в основном на базовом языке. На ранних этапах разработки генератора модельные конструкции реализовывались непосредственно на Си. Использование базового языка облегчило интеграцию моделей и языка.
Во-вторых, генератор предназначен (и только тогда дает существенные преимущества) для реализации больших проектов, когда объем программного кода измеряется сотнями тысяч строк. Работа надо объемными проектами принципиально отличается от разработки маленьких программ размером до нескольких тысяч строк. В маленькой программе разработчик может удерживать в голове всю информацию о ее структуре. В большой программе это невозможно. В процессе модификации таких программ неизбежно нарастает избыточный неиспользуемый код. Для противодействия этому процессу в генераторе предпринимаются многочисленные средства и проверки кода.
В заголовках процедур формальные параметры специфицируются как входные, входные и выходные, только выходные. В процессе трансляции тела процедуры эта спецификация проверяется на корректность. Например, если некий параметр объявлен выходным, а в теле процедуры есть путь в дереве операторов, в котором переменная используется на чтение раньше, чем ей присваивается значение, то такая ситуация приводит к диагностике об ошибке. При этом используется информация о входах-выходах других процедур, вызываемых в данной процедуре. Если переменная имеет тип структуры, то такой анализ проводится для каждой ее компоненты любого уровня.
Для структурных документов можно заказать полный комплект все операций, предусмотренных для всех его записей и наборов. Это приведет к значительному избыточному коду. Можно (и нужно) в явном виде задавать перечень всех требуемых операций для каждой записи и набора. В этом случае операции, которые не использовались в проекте, будут выявлены, и будет выдана соответствующая диагностика. Более того, если, например, не используется операция создания записи, то это тоже трактуется, как ошибка. Или для набора есть операция включения в набор и больше никакие не используются, то тоже выдается ошибка.
На момент написания этого текста как раз был процесс удаления некоторых устаревших сущностей в модели проекта (старые серверы и приложения замещаются новыми). В документе, представляющем в коде генератора модель проекта на момент одновременного существования старых и новых объектов было около 250 типов записей и более 800 типов наборов. После удаления старых сущностей количество записей снизилось до 190, наборов до 580. Понятно, что вручную отследить используемость стольких объектов и операций с ними чрезвычайно затруднительно.
В качестве иллюстрации приведем данные по одному реальному, но уже завершенному, проекту в области финансовой деятельности. Проект на генераторе содержал 1294 файла суммарно 203829 строк. В результирующем программном коде на Си было 4605 файлов с 2608812 строк. В проекте 23 разного типа серверов, 29 портов, через которые они принимают запросы, 11 приложений, 27 утилит (консольных программ), и это только в одном, но самом крупном проекте в составе всей системы. В составе этой системы было 7 проектов, объединенных между собой средствами экспорта-импорта отдельных пакетов. Разбиение системы на 7 разных генераторных проектов было сделано для сокращения их объема. Управляться таким хозяйством без параноидальных средств проверки целостности весьма проблематично.
Текущая ситуация
Генератор проектов в течение всего времени работы над ним развивался, как внутренний проект в коллективе разработчиков. В процессе работы над прикладными проектами наши заказчики в некоторых случаях имели возможность использовать генератор для своих собственных разработок, тем или иным способом связанными с нашим проектом (а может и не только, это проконтролировать трудно). По мере работы над проектами уточнялась постановка задачи, возникали новы потребности в инструменте, которые реализовывались в очередных версиях генератора. Как это было сказано вначале, это была разработка в двух измерениях, прикладном и инструментальном. Т.е. генератор развивался вместе с очередным (очередными) проектом. Периодически возникали разговоры на предмет того, чтобы сам генератор сделать программным продуктом для широкой публики. Данный текст в некотором смысле является попыткой предъявить этой самой публике нашу систему.
На текущий момент в генераторе имеются средства работы с системами управления базами данных Oracle, Postgres, MySql, MS Sql, Sqlite разных версий. Работа с базами предполагает описание схемы базы средствами генератора, написание sql-запросов на специальном языке (используется достаточно представительное подмножество sql) с полным синтаксическим и семантическим контролем текста запроса схеме базы данных. Есть средства задания альтернатив для разных типов баз. И можно писать так называемых динамические запросы
